![[レポート]ペタバイト級データ基盤のDataMesh化とAI/MLを用いたデータ活用の高度化 #SWTTokyo25](https://images.ctfassets.net/ct0aopd36mqt/4c23cKcRWSfL7fbZjZSEYa/9a2f285542f7937bedd49a78ad421a45/eyecatch_snowflakeworldtourtokyo2025_1200x630.png?w=3840&fm=webp)
[レポート]ペタバイト級データ基盤のDataMesh化とAI/MLを用いたデータ活用の高度化 #SWTTokyo25
2025.09.12
さがらです。
2025年9月11日~2025年9月12日に、「SNOWFLAKE WORLD TOUR 2025 - TOKYO」が開催されました。
本記事はセッション「ペタバイト級データ基盤のDataMesh化とAI/MLを用いたデータ活用の高度化」のレポートブログとなります。
登壇者
-
松原 侑哉 氏
- 株式会社NTTドコモ
- R&Dイノベーション本部サービスイノベーション部ビッグデータ基盤担当 兼 ネットワーク本部ネットワーク部技術企画部門
- Principal Data Engineer
-
成清 修平 氏
- 株式会社NTTドコモ
- R&Dイノベーション本部サービスイノベーション部ビッグデータ基盤担当
-
上野 正暉 氏
- 株式会社NTTドコモ
- R&Dイノベーション本部サービスイノベーション部ビッグデータ基盤担当

データ分析基盤の高度化
- 扱うデータの種類
- 社外秘情報含めて、種類が豊富にある
- データ分析基盤の軌跡
- オンプレミス⇛Redshift⇛Redshift&BigQuery⇛Snowflake
- これまでのデータ分析基盤
- 中央チームで管理していたが、スケール性など課題が出てきた
- Data Meshへの移行
- セルフサービス型の分散管理
- Data Ownerは所有するデータの品質も含めて管理
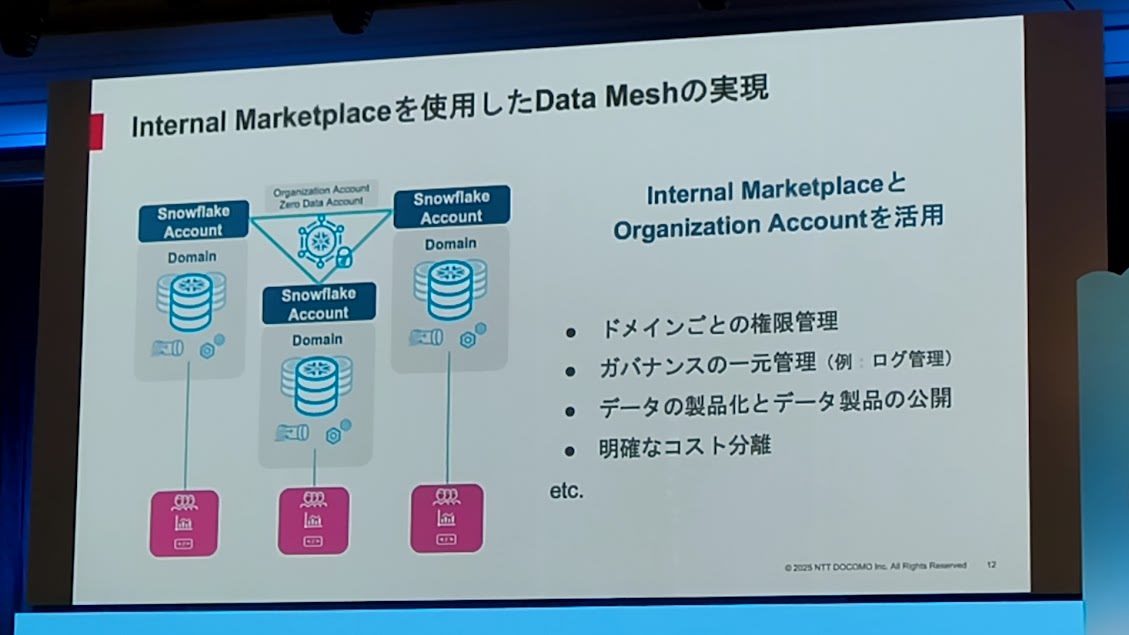
- どうやってData Meshを実現したか?
- SnowflakeのInternal Marketplaceの活用
- 外部のData Lake/Data Warehouseとの連携に課題が出てきた
- データの重複保持は最小限にしたい
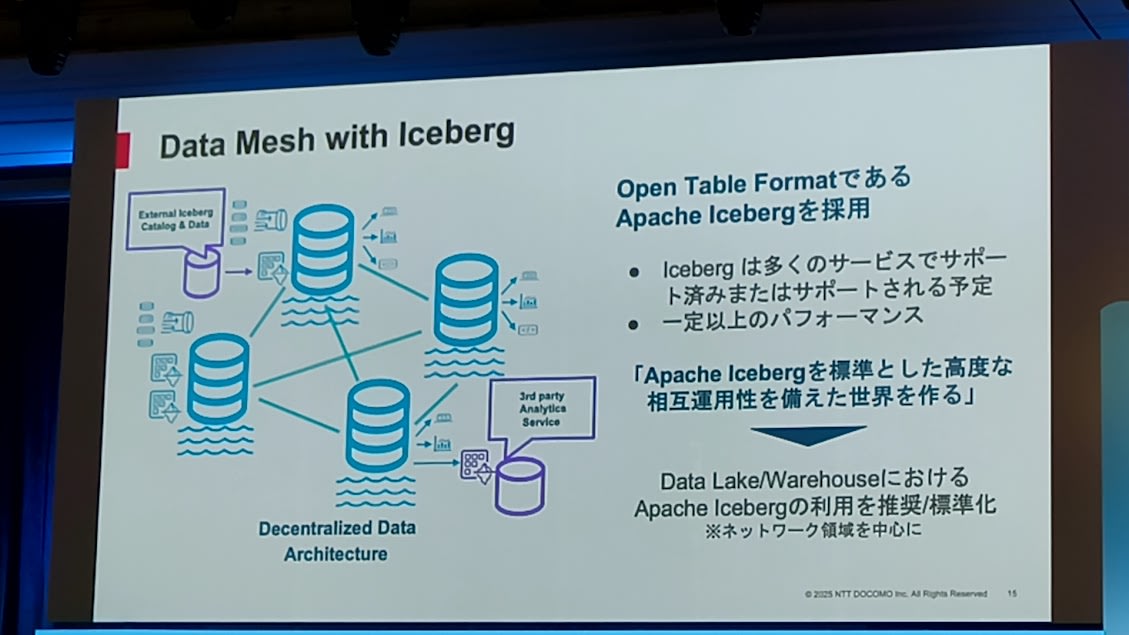
- Data Mesh×Apache Icebergの採用
- Apache Icebergを標準とすることで、高度な相互運用性を実現
- SnowflakeにおけるApache Icebergの活用と性能
- 10TB、1兆レコードの内容でも特に性能差はなかった

- 中央チームの仕事はどう変わった?
- 立法・監査などのCoE活動になった
大規模データを用いたAI/ML活用/分析例
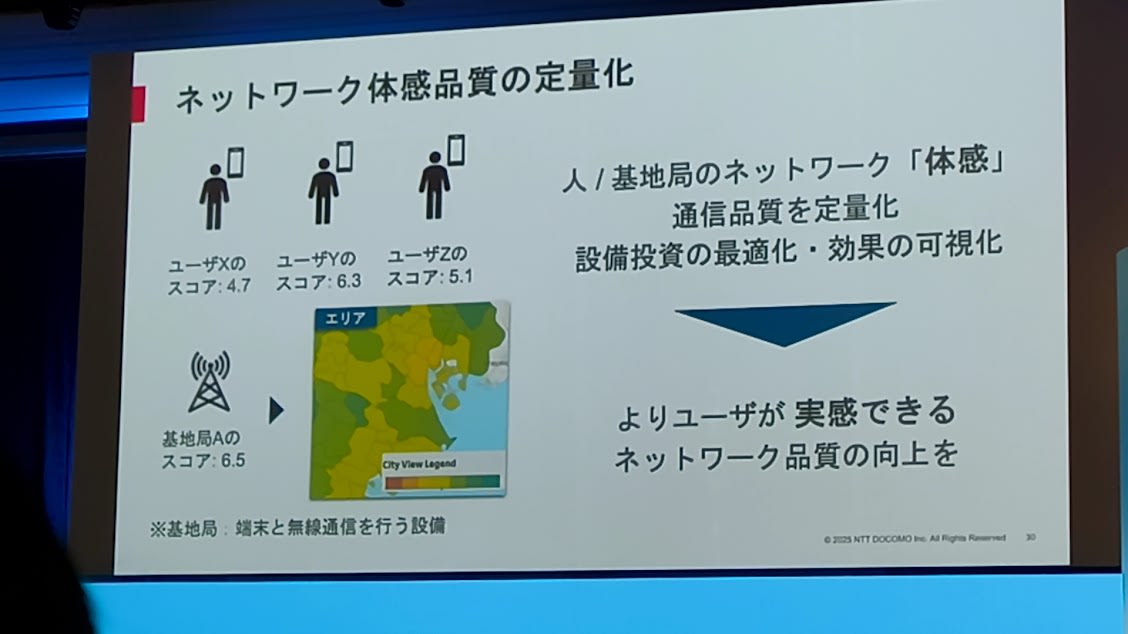
- ネットワーク体感品質の定量化
- 人/基地局のネットワークの通信品質を定量化
- ユーザー体験の向上を目指すための取り組み
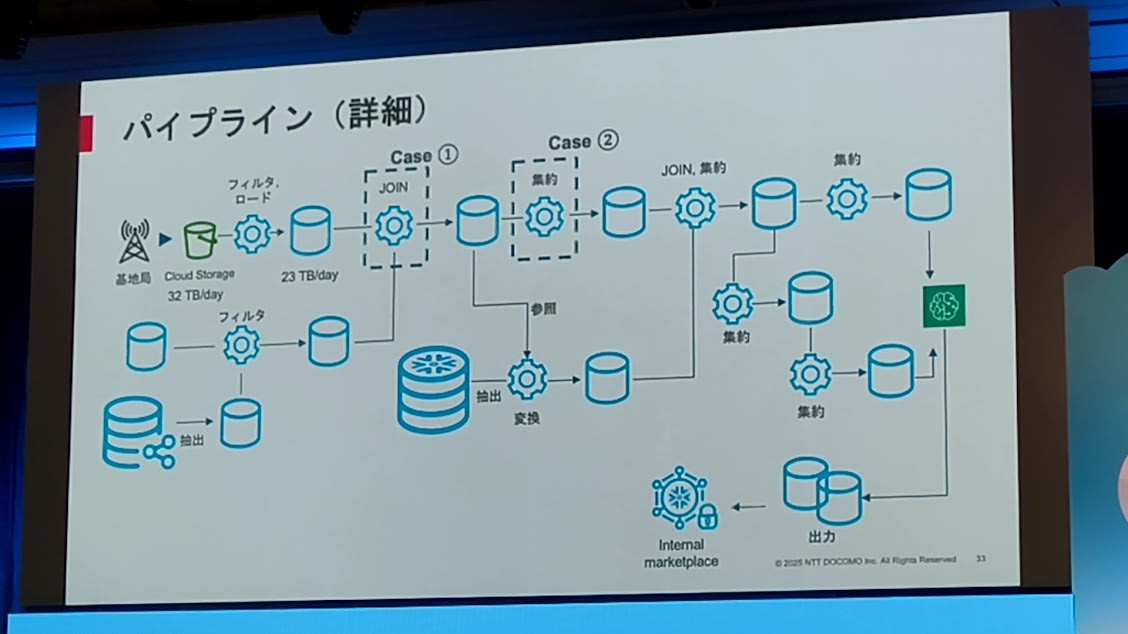
- データパイプライン
- 基地局やユーザーの属性情報を用いて特徴量を生成し、MLで推論し、スコアを算出してデータプロダクトとして出品
- 基地局のデータは一日32TB。このためコストを削減する必要が出てきた

- コスト削減:Warehouseの最適化
- 具体的には4XLのサイズは変えずに、Gen 2のウェアハウスに変更した。これによりクレジット換算で40%コスト削減
- 4XLSnowpark-optimizedに変更。(6XLではメモリが足りないことがあった)
- コスト削減:その他の例
- CTEを実テーブル参照に変更。上流におけるデータフィルタリング。
- ノウハウ
- Spillが多いケースでは、Snowparkを使わなくてもSnowpark-optimizedが有用
- Gen 2にすることでコスト削減できる可能性がある
- CTEが必ずしも高速化につながるとは限らない
生成AIの活用
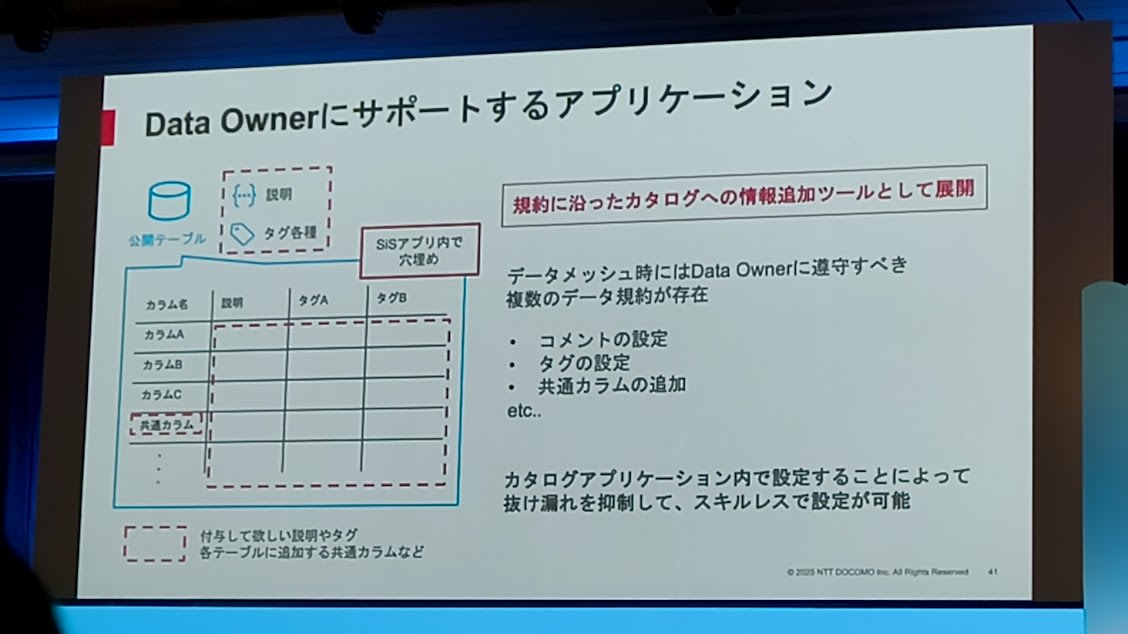
- 社内データカタログアプリケーション
- Streamlit in Snowflakeを活用
- Data Ownerをサポートするアプリケーション
- 説明、タグ、をStreamlit in Snowflakeのアプリで穴埋め
- 出てきた課題
- Data Ownerはメタデータを1つ1つ手動更新
- この課題の解決策として、生成AIを活用した自動的なメタデータ更新を考えた
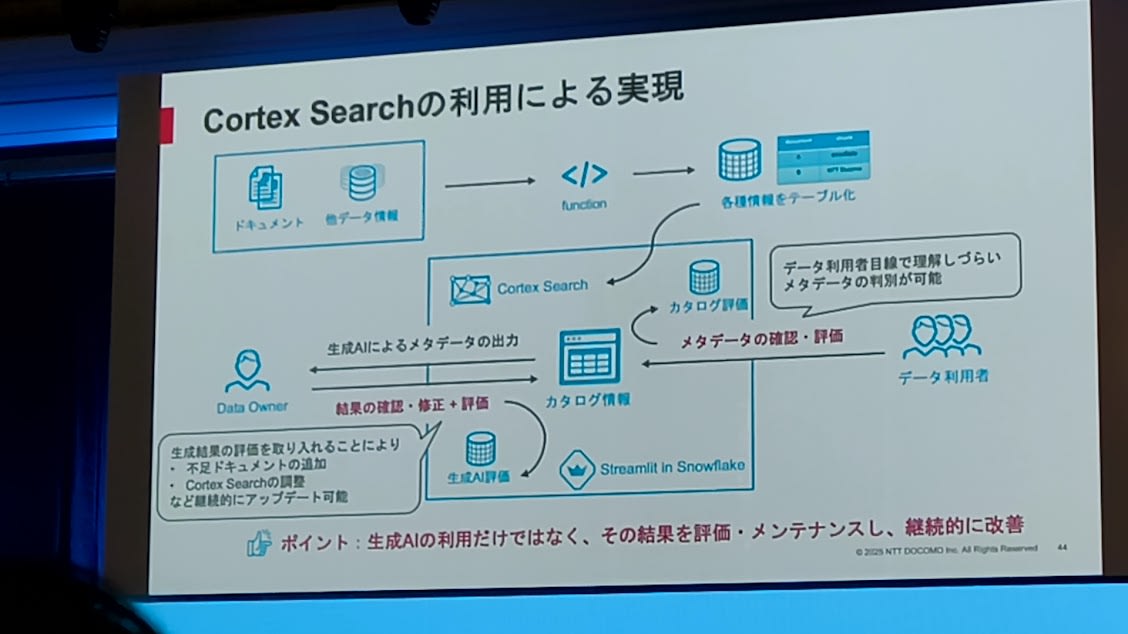
- Cortex Searchの利用
- ドキュメントや他のデータを読ませて情報をテーブル化し、Cortex Search経由でメタデータを生成
- ポイントは、一度生成するだけでなくて、その結果を継続的に評価・メンテナンスしていること
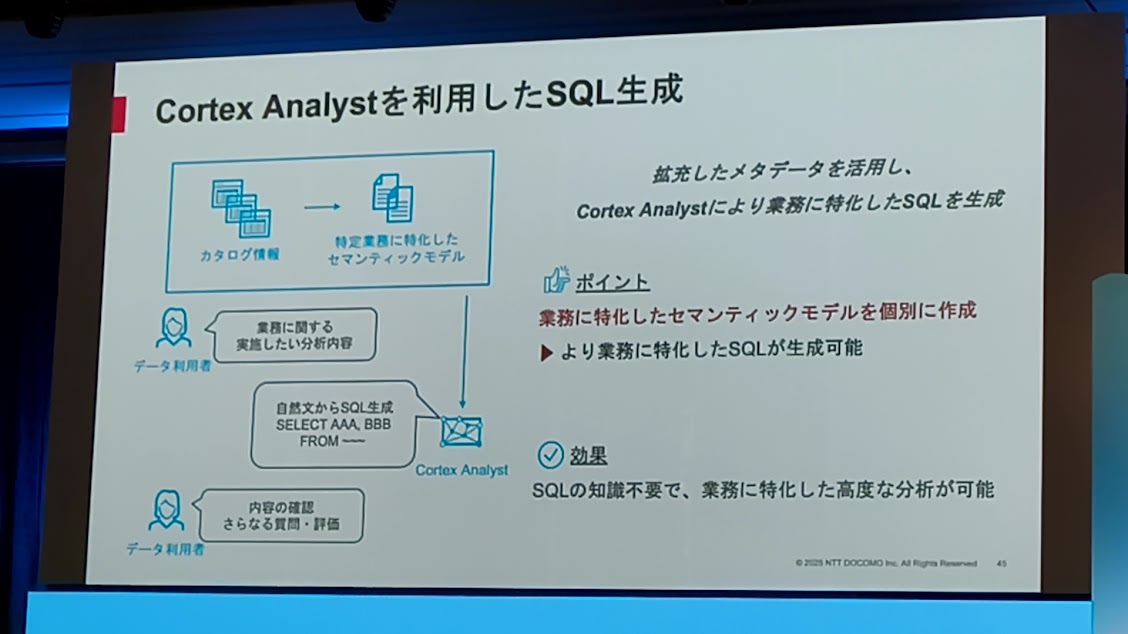
- 生成したメタデータを用いたSQLの生成
- Cortex Analystにより、業務に特化したSQLを生成
まとめ
- AI Ready
- これまでは「人」が何かをするケースが多かった
- 今後は、AIが自分で判断して自律的に動いていくことが想定される。このためにAI-Readyとなるデータ基盤が必要
所感
本セッションでは、Apache IcebergをData Meshアーキテクチャの核に据えている点と、Cortex Searchを活用してメタデータ生成を自動化している点が特に印象に残りました。
より具体的には、Apache Icebergが10TB1兆レコードであっても従来のSnowflakeと比べてパフォーマンスに遜色がないこと、社内ドキュメントという非構造化データに対してCortex Search Serviceを構築してSnowflakeのメタデータを生成AIで作っているというアイデア、がとても参考になりました。
Icebergも生成AIも使い手のアイデア次第でより活かすことができると感じたセッションでしたので、より頭を柔らかくして発想を変えていかないといけないですね…!









