
Athena のパーティションが分からなかったのでやってみた
Athena の パーティションという概念がよくわからなかったので、やってみました。
Athena パーティションとは?
パーティションとは、S3 オブジェクトがきちんとフォルダ分けしてある状態のことです。
- パーティションなしの状態 -> オブジェクトがフォルダ分けされておらず、同じ階層に保存されている
s3://<バケット名>/sample_data_1.csv
s3://<バケット名>/sample_data_2.csv
s3://<バケット名>/sample_data_3.csv
s3://<バケット名>/sample_data_4.csv
- パーティションありの状態 -> オブジェクトがきちんとフォルダ分けされている(以下の例だと、月毎に分類されている)
s3://<バケット名>/2025/06/sample_data_1.csv
s3://<バケット名>/2025/06/sample_data_2.csv
s3://<バケット名>/2025/07/sample_data_3.csv
s3://<バケット名>/2025/08/sample_data_4.csv
上記のように、フォルダ分けすることをパーティション化と呼んでいます。パーティションが英語で Partition (訳:分割) という意味なので、本当にそのままですね。
オブジェクトをパーティションに区切って保存するということです。
パーティションに分けるメリット
パーティションに分けることで、Athena からのスキャン量を削減できるというメリットがあります。
パーティション化されていない場合、S3 の調べたい階層のデータを全てスキャンする必要があります。一方で階層分けされていれば、その階層だけ絞り込んで検索することが可能になります。
結果的にスキャン量が減り、コストも削減できます。フォルダ分割するだけで結構なメリットがあるんですね。
なお、パーティショニングについての説明は、以下公式ドキュメントにも記載がありますのでご参照ください。
クエリを実行する際に Athena がスキャンする必要があるデータ量を減らすための 2 つの方法として、パーティション化とバケット化があります。... スキャンするデータ量を減らすことは、パフォーマンスの向上とコストの削減につながります。
パーティショニングとは、データの特定のプロパティに基づいて、Amazon S3 上のディレクトリ(または「プレフィックス」)にデータを整理することを意味します。このようなプロパティはパーティションキーと呼ばれます。一般的なパーティションキーは、日付、または年や月などの時間単位です。
やってみた
S3 バケット作成
デフォルト設定で S3 バケットを作成します。
データセットの作成
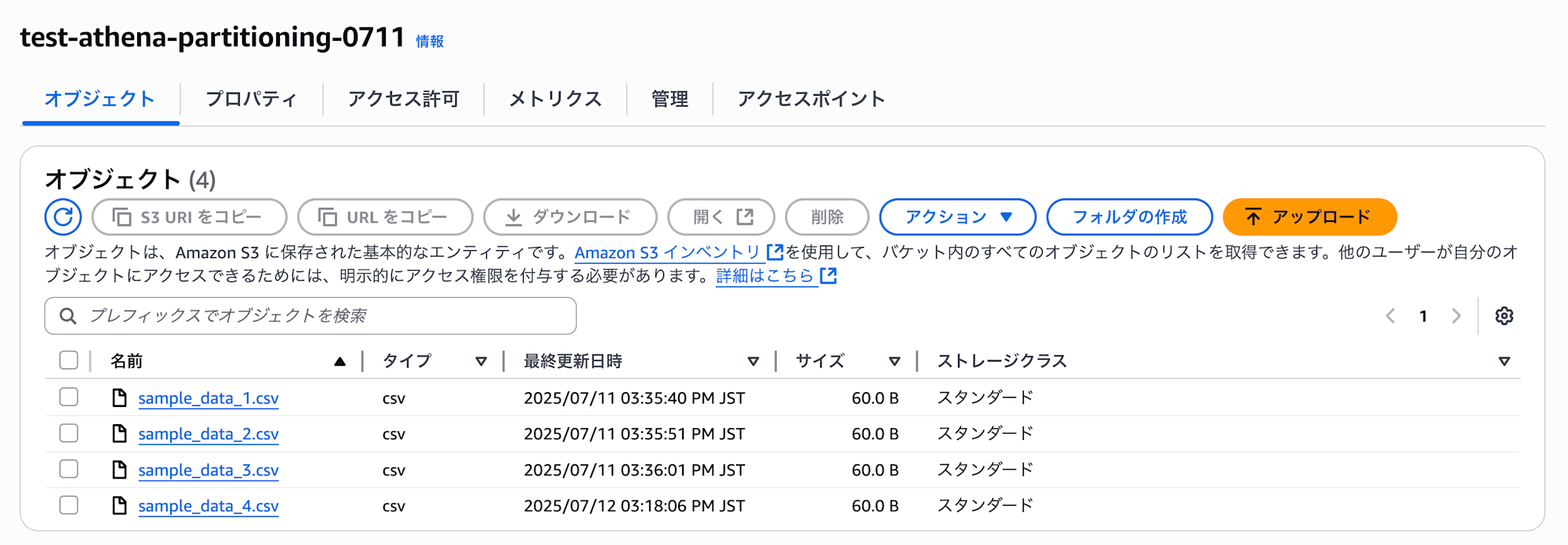
以下 4 つのサンプルデータを用意します。
TeamID,prefecture,point
TEAM_A,okinawa,100
TEAM_B,tokyo,200
TeamID,prefecture,point
TEAM_C,okinawa,300
TEAM_D,tokyo,400
TeamID,prefecture,point
TEAM_E,okinawa,500
TEAM_F,tokyo,600
TeamID,prefecture,point
TEAM_G,okinawa,700
TEAM_H,tokyo,800
作成したサンプルデータを S3 にアップロードしておきます。なお、現時点ではフォルダを作らず、バケット直下にオブジェクトを配置します。
Athena からクエリしてみる
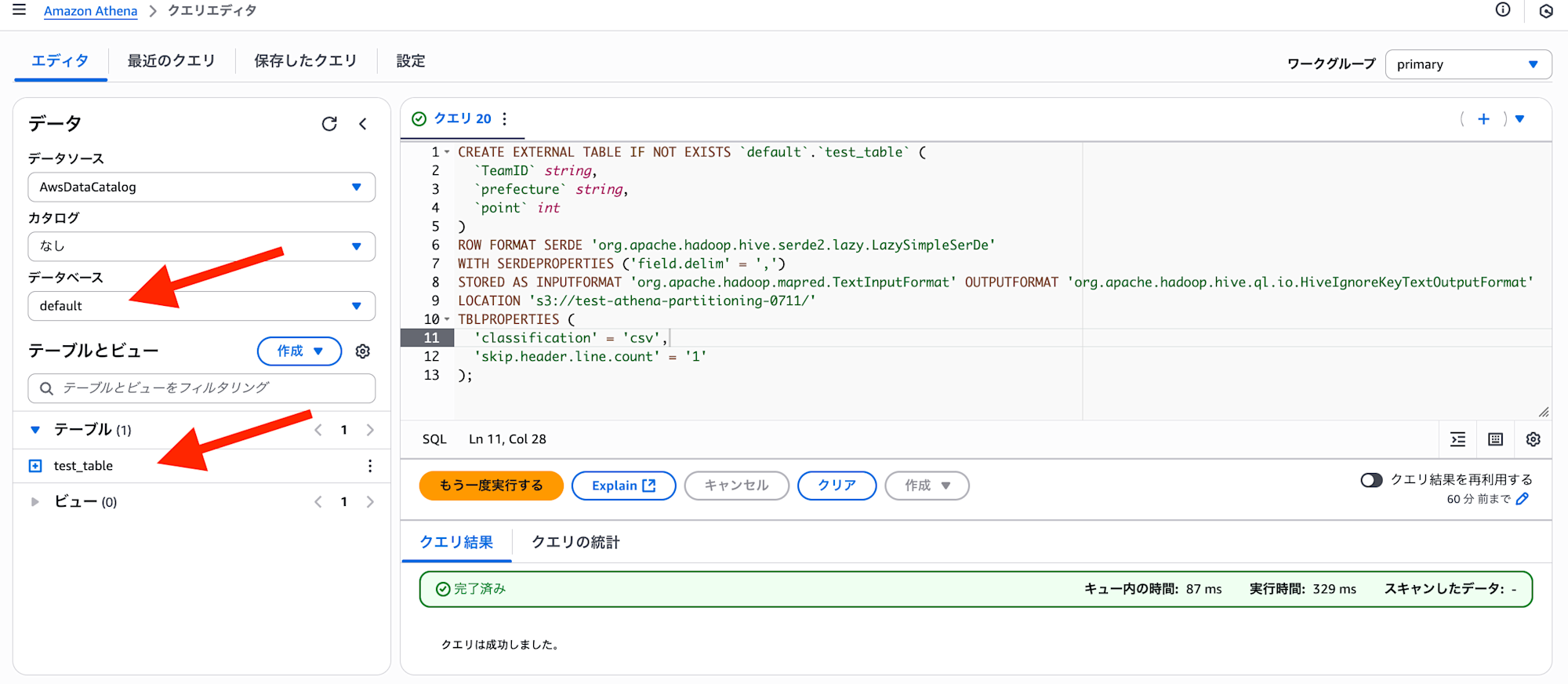
Athena クエリエディタにて以下の CREATE TABLE 文を実行します。
本クエリは、Athena の default データベースにテーブル test_table を作成するスクリプトになります。
LOCATION 句 には前項で作成済みの S3 バケット(test-athena-partitioning-0711) を指定しています。
CREATE EXTERNAL TABLE IF NOT EXISTS `default`.`test_table` (
`TeamID` string,
`prefecture` string,
`point` int
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES ('field.delim' = ',')
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://test-athena-partitioning-0711/'
TBLPROPERTIES (
'classification' = 'csv',
'skip.header.line.count' = '1'
);
※補足:上記の CREATE TABLE 文はコンソールからも作成できます。試される場合は下記ブログをご参照ください。
上記クエリを実行後、default データベースに test_table が作成されていることが確認できました。
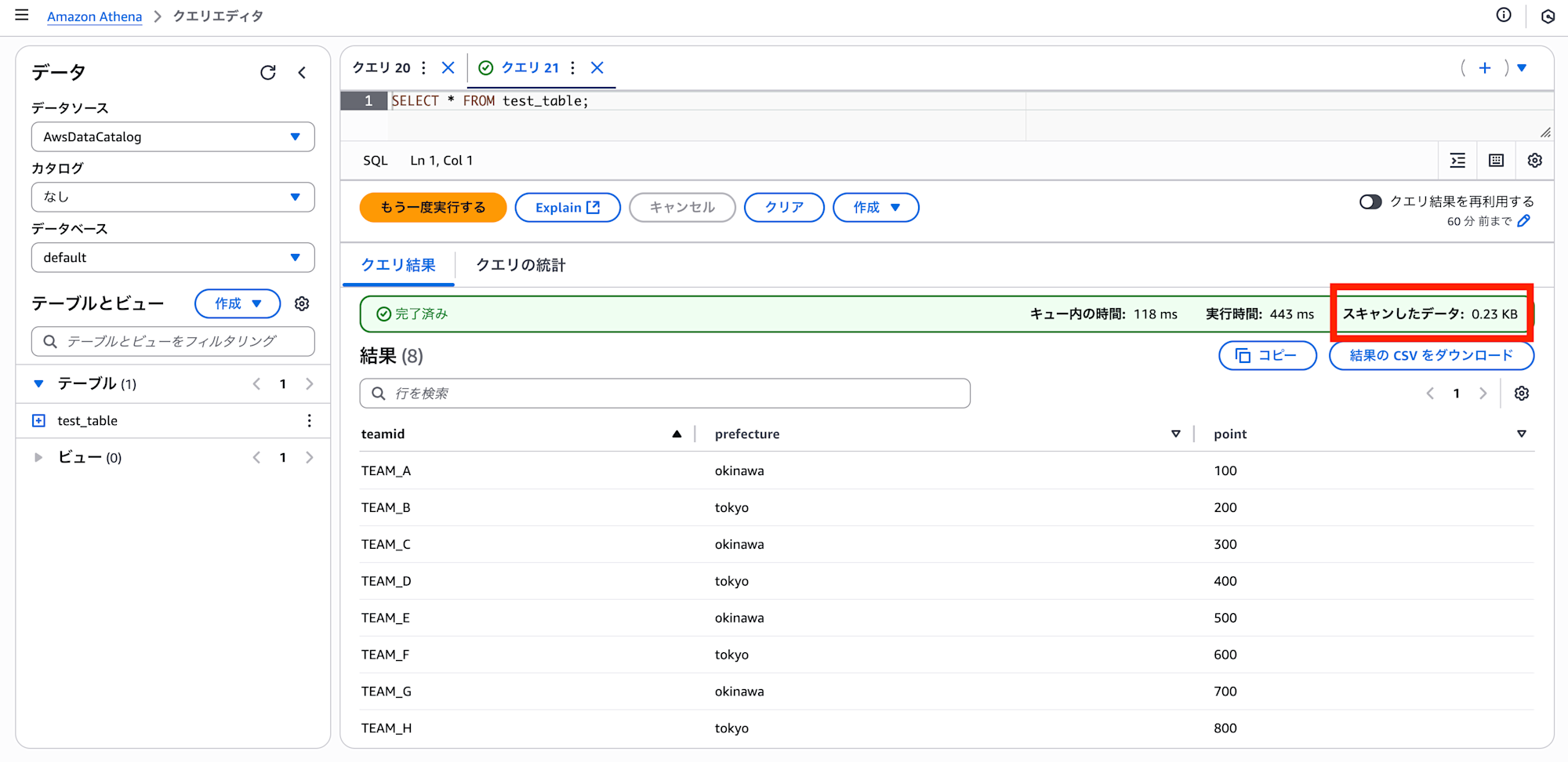
Athena から S3 をクエリするためのテーブルが作成できたので、SELECT で test_table を全クエリしてみます。
その結果、以下画像の通り、4つのサンプルデータのすべてのレコード(合計8レコード)が取得できました。また、スキャン量は 0.23 KB であることがわかります。
パーティショニングする
それでは続いて、パーティショニングして Athena からクエリを実行してみます。
まずは S3 をフォルダ分けします。フォルダ階層は以下のように月毎に分けてみました。
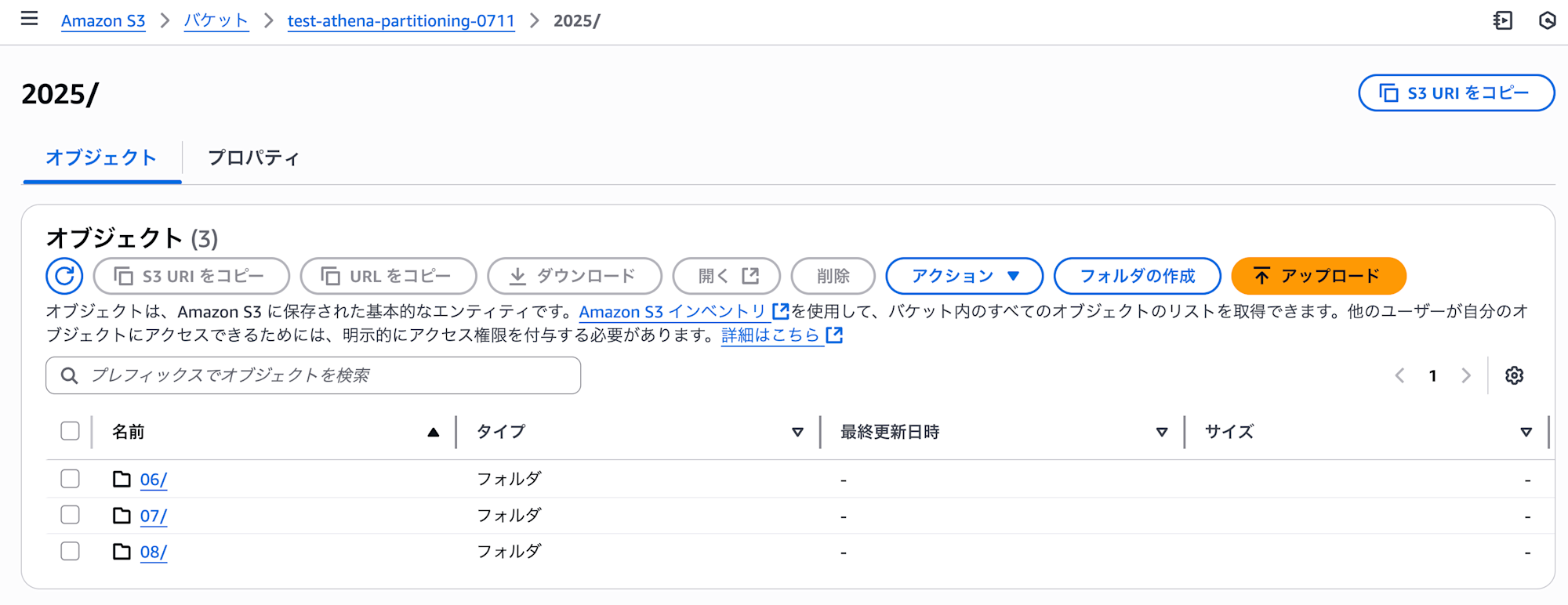
s3://test-athena-partitioning-0711/2025/06/sample_data_1.csv
s3://test-athena-partitioning-0711/2025/06/sample_data_2.csv
s3://test-athena-partitioning-0711/2025/07/sample_data_3.csv
s3://test-athena-partitioning-0711/2025/08/sample_data_4.csv
ちなみに、このフォルダ分けした状態で全クエリしても、全てのサンプルデータ情報(合計8レコード)が返却されます。
一方で、以下のように特定の月に絞って検索しようとするとエラーとなり、現時点では絞り込み検索が行えません。
select * from test_table where year=2025 AND month=07;

月毎に絞ってクエリするとエラーになる
それでは Athena 側にパーティションの設定を行い、上記のような絞り込み検索を実行できるようにしてみます。
既存テーブルにパーティションを追加する方法としては、以下ブログで紹介されているような ALTER TABLE ADD PARTITION を用いる手法があります。
しかし現時点では、この手法でパーティション設定を追加しようとしても以下のようにエラーになります。
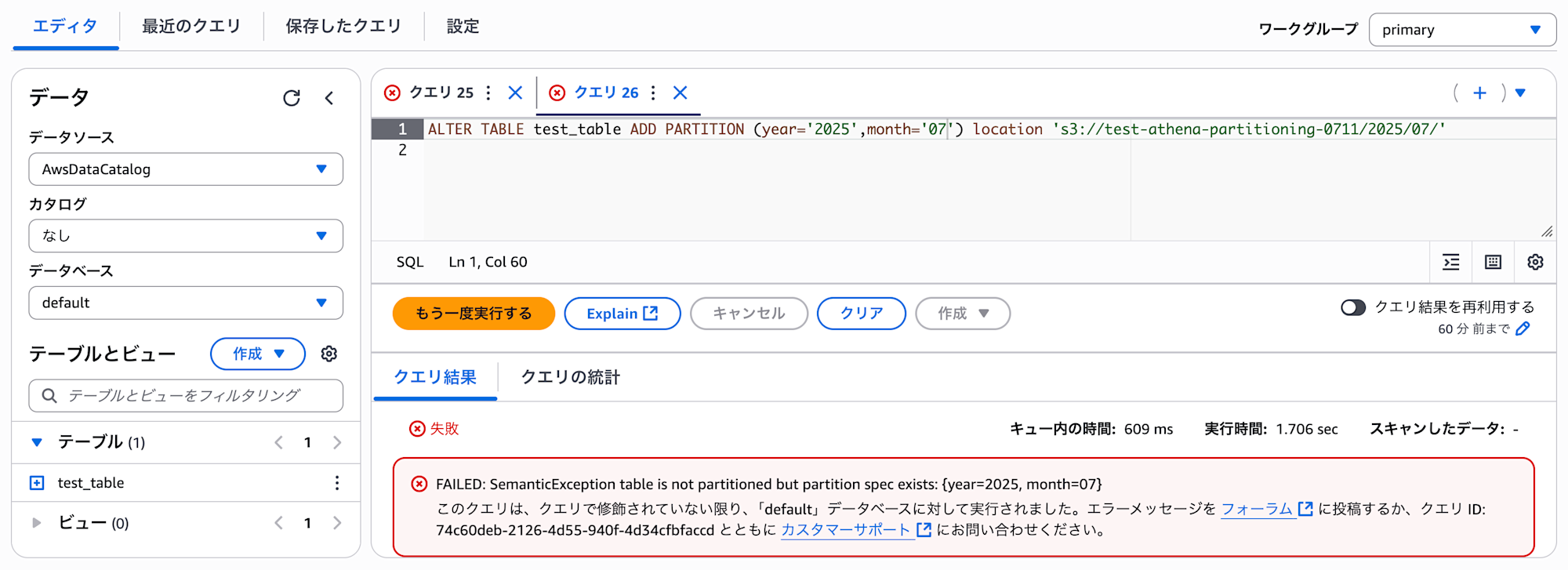
ALTER TABLE test_table ADD PARTITION (year='2025',month='07') location 's3://test-athena-partitioning-0711/2025/07/'
FAILED: SemanticException table is not partitioned but partition spec exists: {year=2025, month=07}
上記エラーは、Athena テーブル(本ブログだと test_table)作成時にそもそもパーティション用のカラムが設定されていないために起こります。
詳細は下記 AWS 公式ブログをご参照ください。
SemanticException
...
このエラーは、CREATE TABLE ステートメントでパーティションを定義しなかった場合に発生します。このエラーを解決するには、次のいずれかの操作を行います:
・テーブルを再作成し、PARTIONED BY を使用してパーティションキーを定義します。
・テーブルスキーマを編集します。
エラーを解消するにはテーブル再作成が必要ですが、やや面倒なので、今回はテーブルスキーマを編集する方法で解消します。
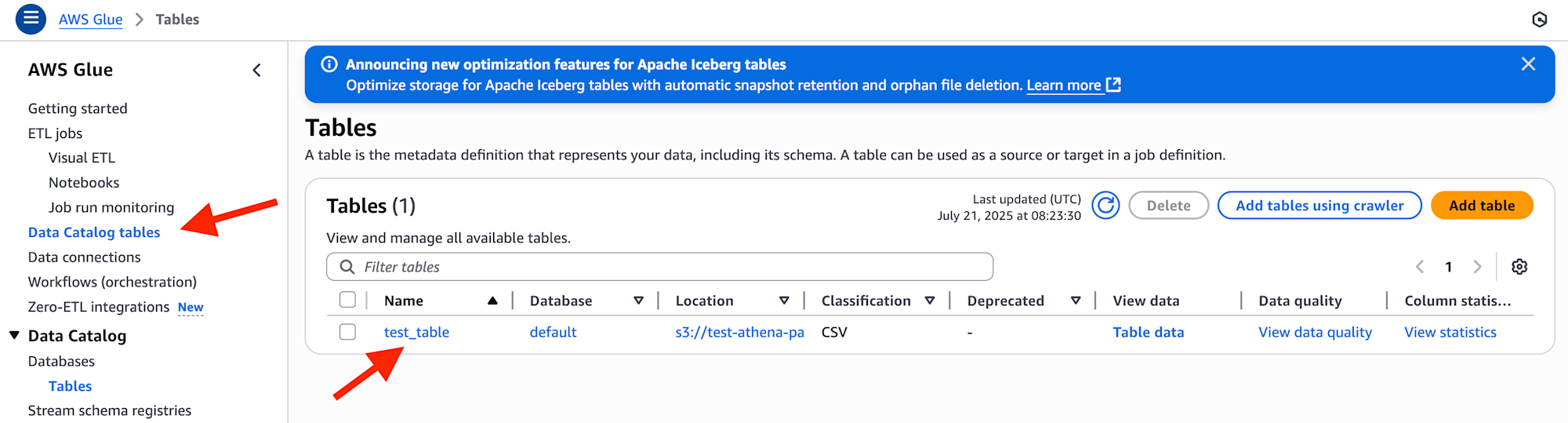
Athena は、内部的には AWS Glue Data Catalog を使用しているため、Glue コンソールからテーブルスキーマ編集を行います。
Glue コンソールに移動し、ナビゲーションペインから 「Data Catalog tables」 を選択、その後、前項にて作成済みのテーブル test_table を選びます。
テーブルの詳細画面から、Schema タブの 「Edit schema」を選択します。
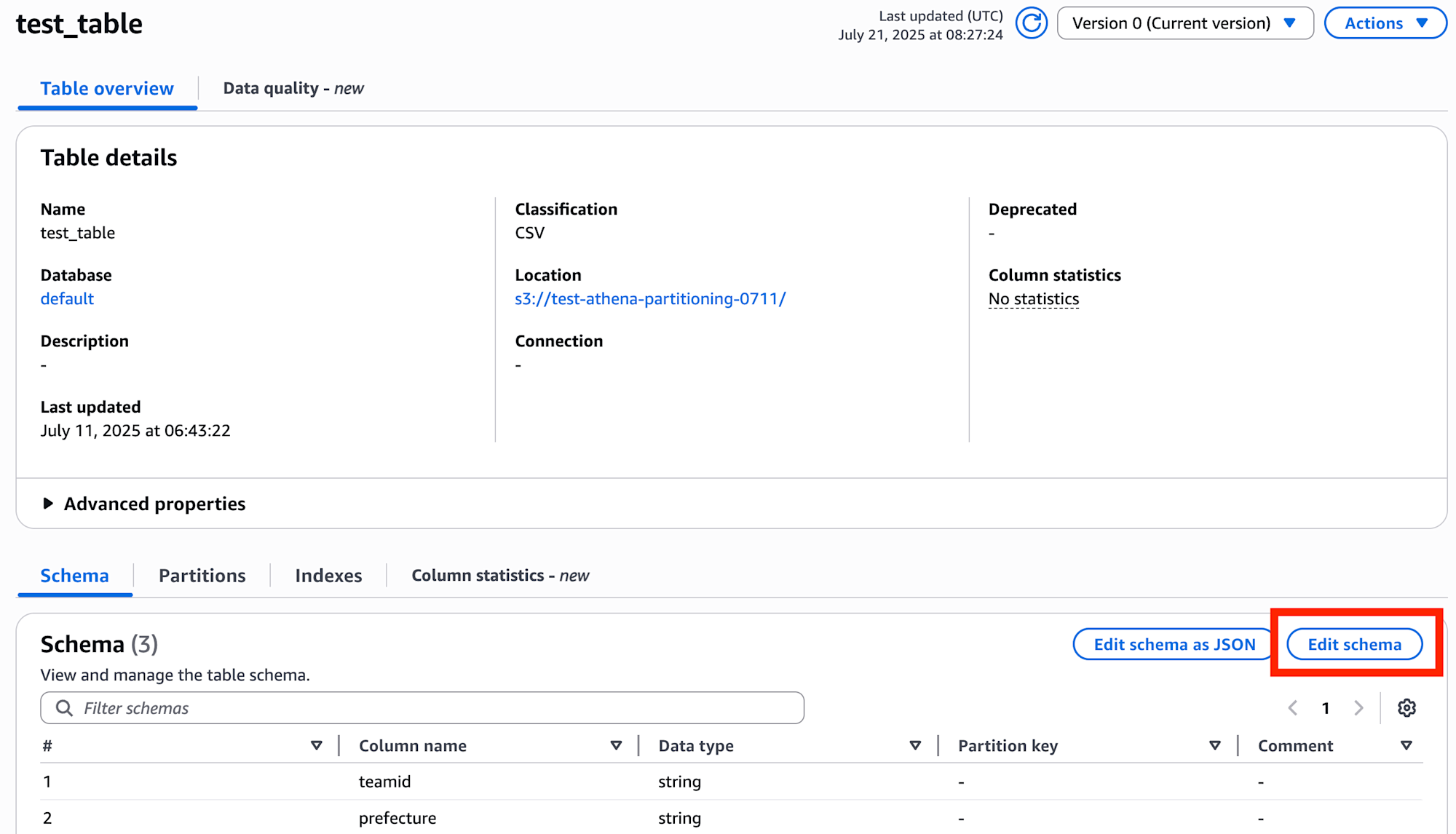
右上の ADD ボタンを選択。
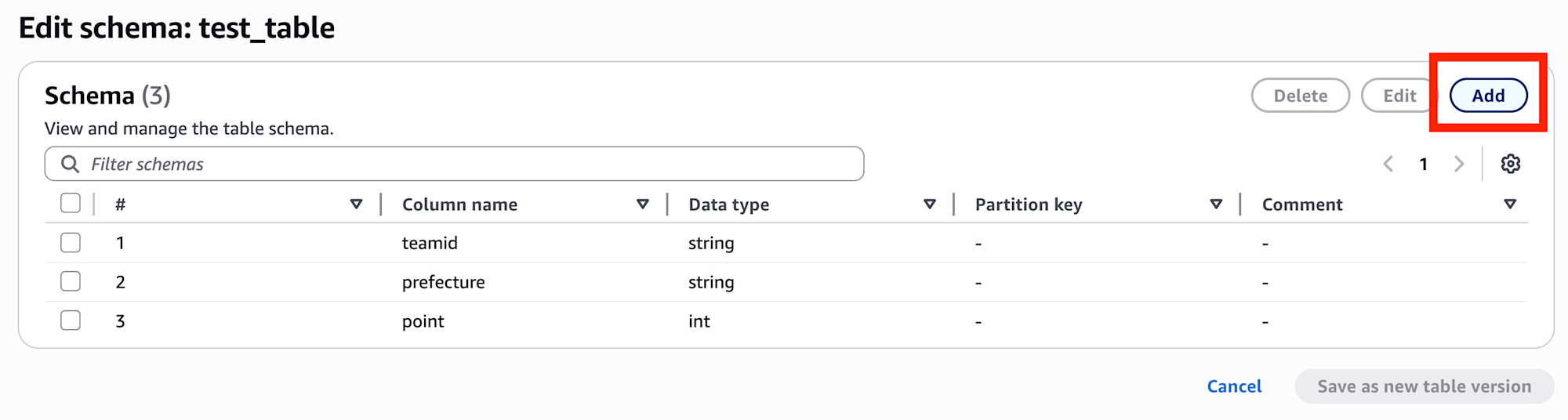
以下のように year カラムを追加します。「Set as partion key?」のチェックも忘れずに入れます。
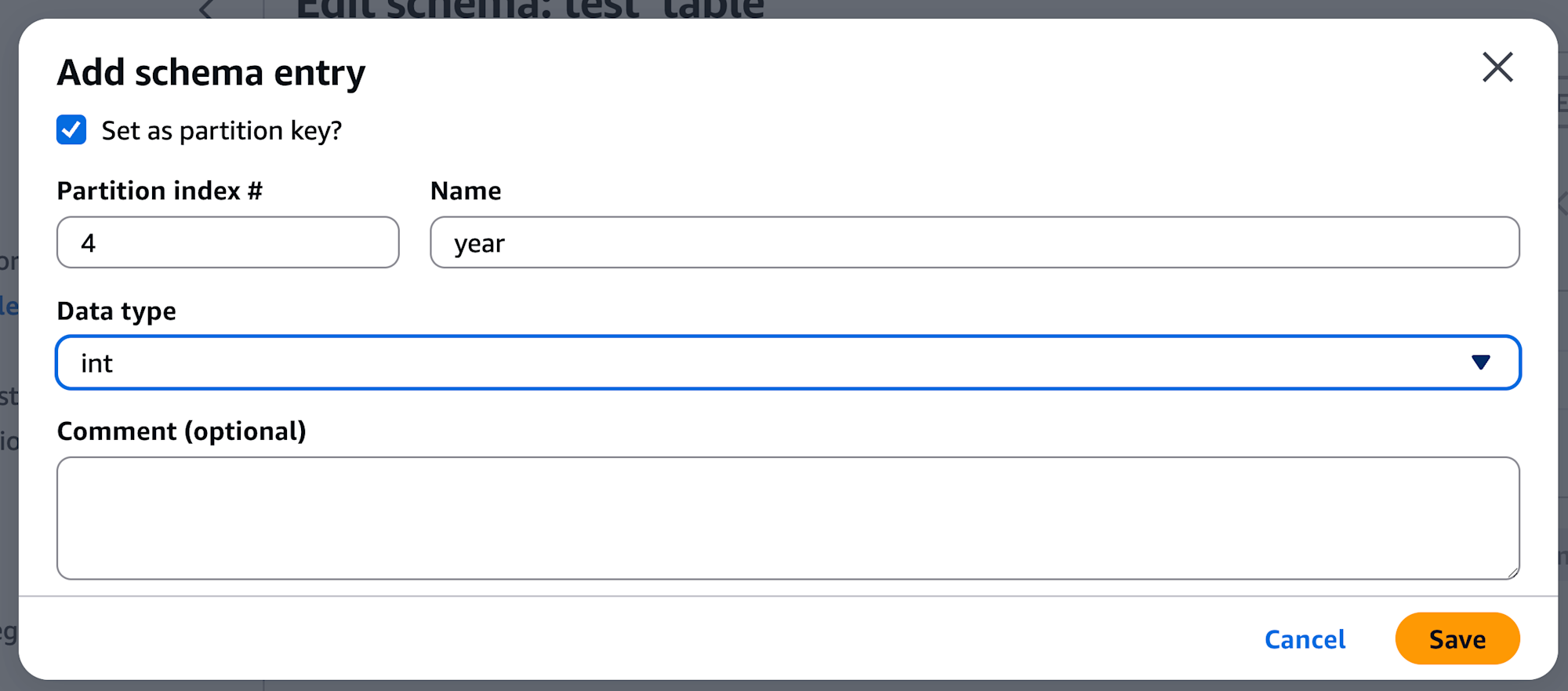
month カラムも同様に設定します。

2つ設定したら、右下のボタンから設定を保存します。

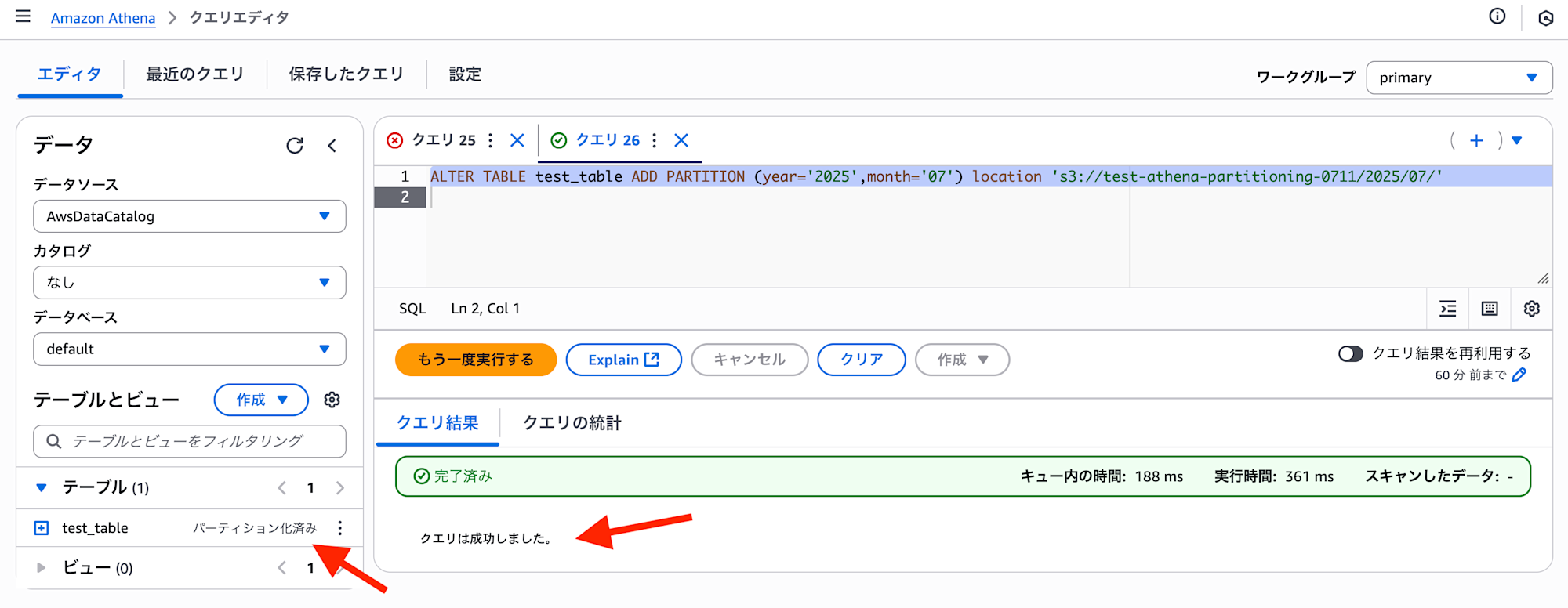
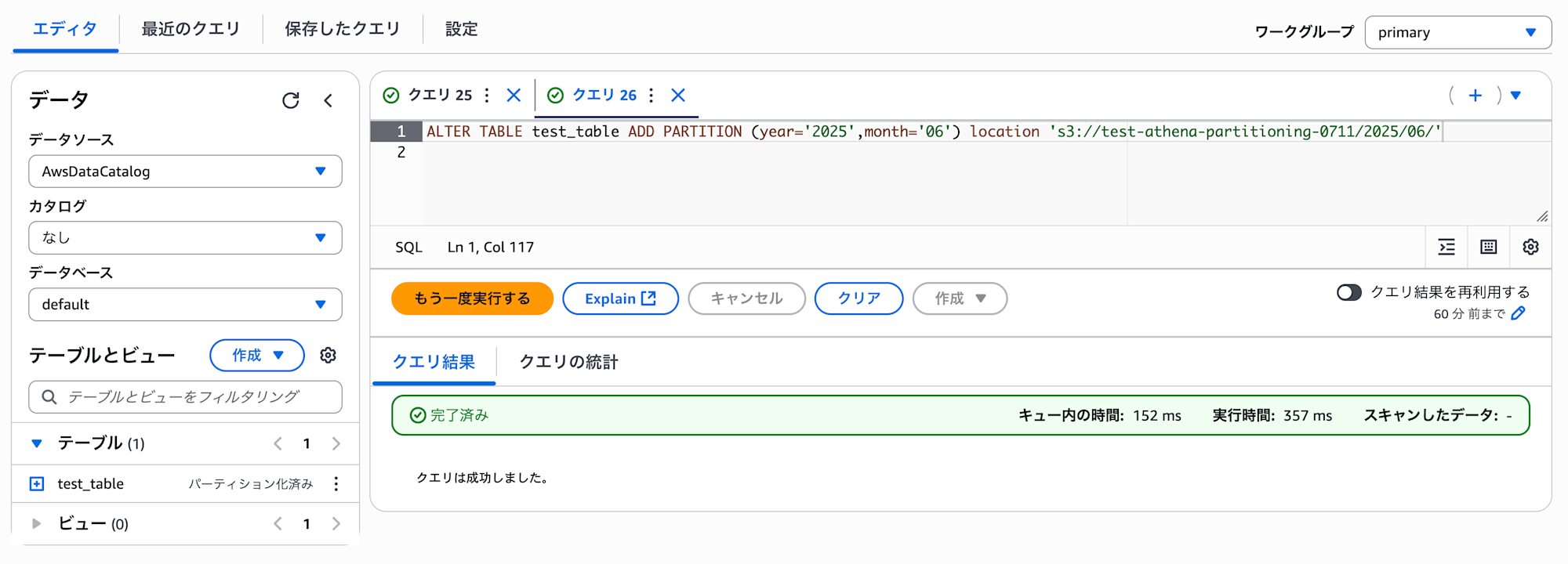
そうすると先ほどの ALTER TABLE ADD PARTITION クエリの実行が成功します。
またクエリが成功すると、テーブルの右横にパーティション化済みと表示されていることがわかります。
以上で、パーティション設定はできているはずなので、先ほど失敗した絞り込み検索のクエリを実行してみます。
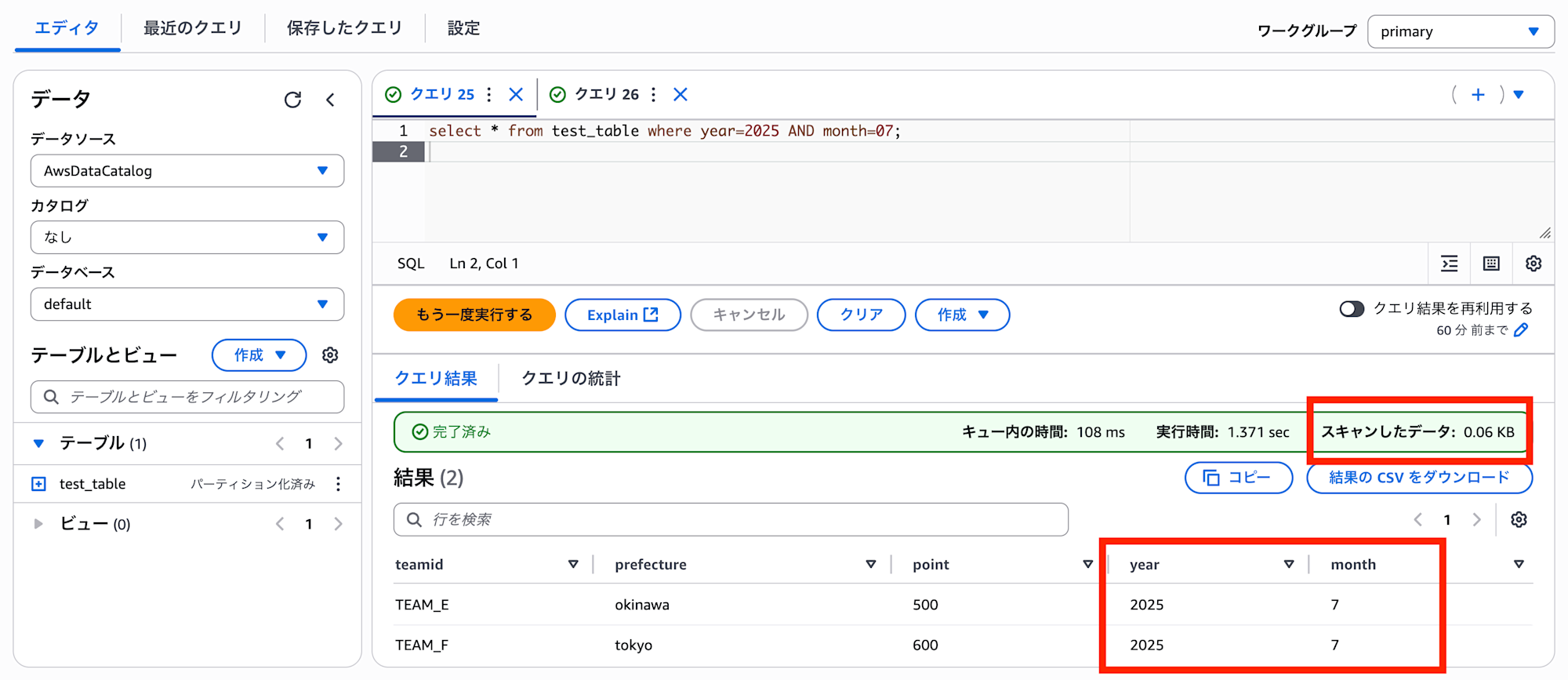
select * from test_table where year=2025 AND month=07;
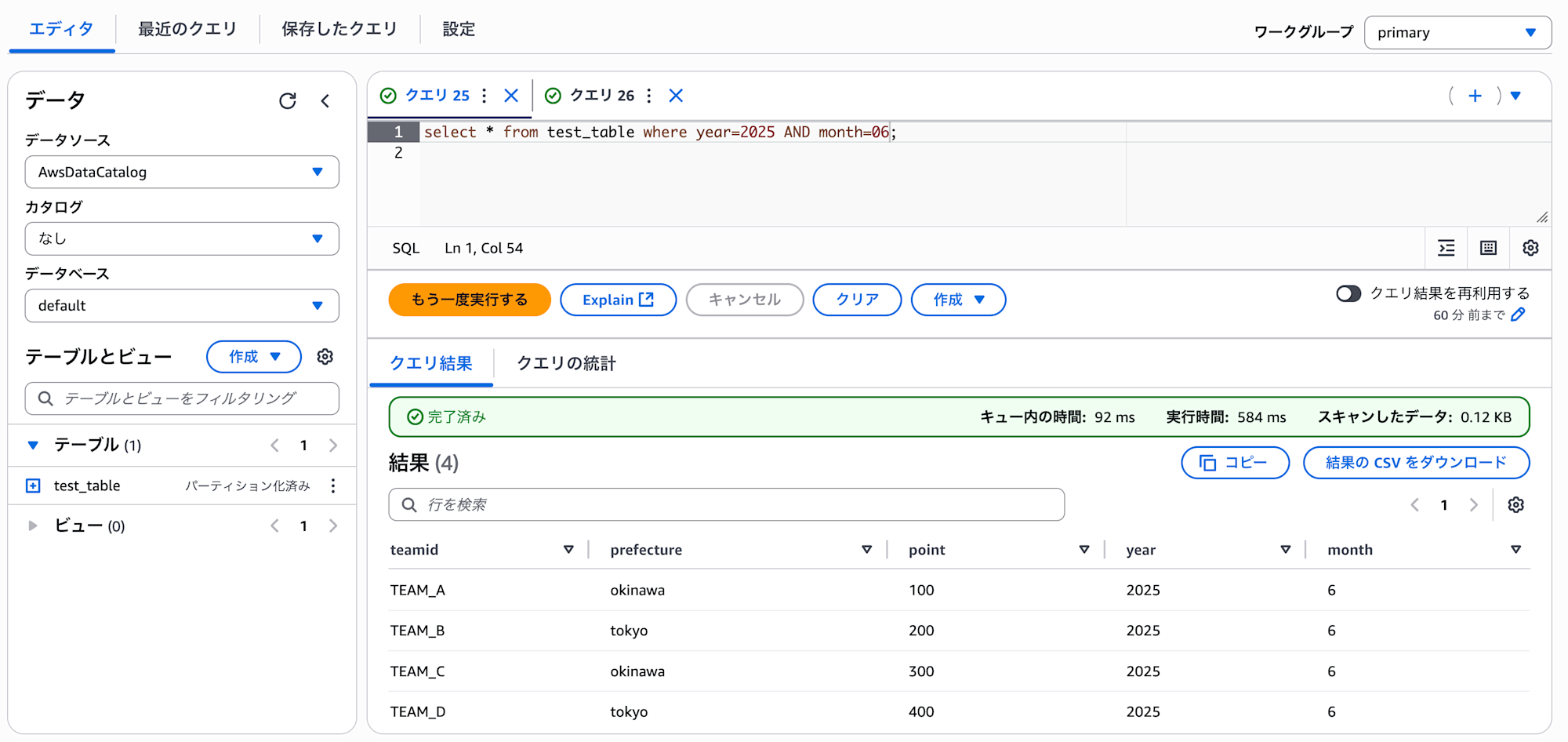
今度は成功しました。絞り込みを行ったことでスキャン量が全クエリの時と比較して減少していることがわかります。また、テーブル構造も新たに year と month カラムが設定されており、7月のデータのみクエリできていることがわかります。
ちなみに今の状態では他の月はクエリすることができません。(ALTER TABLE ADD PARTITION を行なっていないため。)
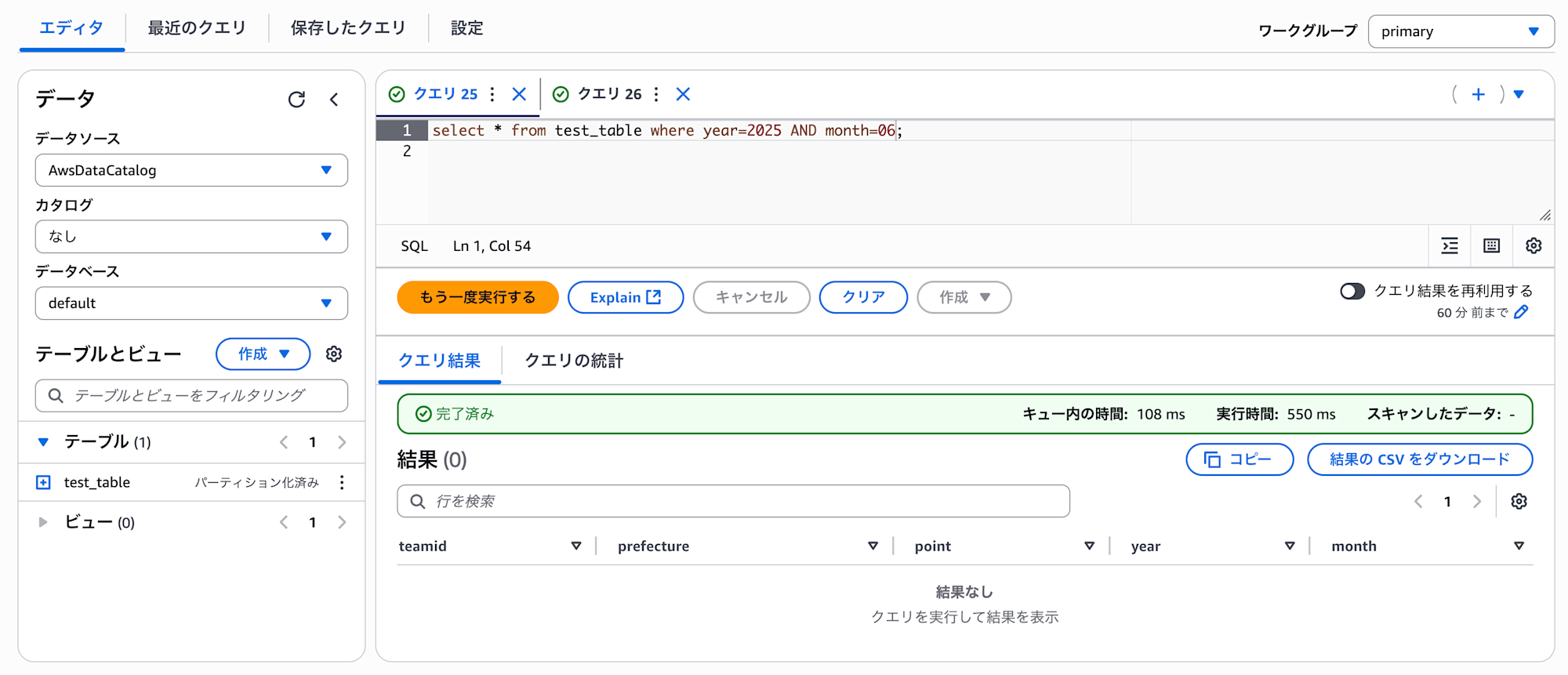
クエリは成功しているが、6月のデータが取得できていない
他の月も絞り込み検索するには、再度パーティションを手動追加する必要があります。
ALTER TABLE test_table ADD PARTITION (year='2025',month='06') location 's3://test-athena-partitioning-0711/2025/06/'
上記設定が終わると、6月のデータも絞り込み検索できるようになります。以上で検証は終わりです。お疲れ様でした〜
終わりに
今回は Athena のパーティションを実際に設定してみました。パーティションに分けることによって、絞り込み検索が可能になり、結果としてスキャン量が減りコストも減るというドキュメントに書かれていることがやっと理解できました。
業務でパーティションという単語が出てくるとよく分からなかったので怖かったのですが、これからは少し勇気を持てそうです。
本ブログが、パーティションについて自分のように初めて触る方の理解の助けになれば幸いです。
参考情報








