
LambdaからDuckDBを使って、S3 TablesのIcebergテーブルにアクセスしてみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ事業本部の笠原です。
DuckDBがApache Iceberg REST Catalogをプレビューサポートしました。
以下のページでは、S3 Tablesへのアクセス方法が記載されています。
先日公開された「Amazon S3 Tables Iceberg REST endpoint」を利用しています。
また、AWSブログにも、DuckDBを使ってS3 Tablesへアクセスする方法が記載されています。
こちらは、「Amazon SageMaker Lakehouse Iceberg REST endpoint (Glue Iceberg REST endpoint)」を利用しています。
今までPyIcebergを使ってLambdaから各エンドポイントへの接続を試してきたので、今回はDuckDBを使ってLambdaから各エンドポイントへの接続を試して、S3 TablesのIcebergテーブルにアクセスしてみたいと思います。
なお、DuckDBからはRead Onlyなので、SELECTクエリのみがサポートされています。
S3 Tablesの準備
まずはS3 Tablesのテーブルバケット・ネームスペース・テーブルを作成します。
今回も、東京リージョンでテーブルバケットを作成します。
「AWS 分析サービスとの統合」を有効化していない場合は、マネジメントコンソールから「統合を有効にする」をクリックして有効化しておきましょう。
マネジメントコンソール上からでも、AWS CLIからでも、お好きな方法でテーブルバケット・ネームスペース・テーブルを作成しましょう。
私はいつも通りCLIで作成します。
## テーブルバケット作成
aws s3tables create-table-bucket \
--name duckdb-sample-bucket
## ネームスペース作成
## 今回のネームスペースは 'ducks'
aws s3tables create-namespace \
--table-bucket-arn "arn:aws:s3tables:ap-northeast-1:<AWS_ACCOUNT_ID>:bucket/duckdb-sample-bucket" \
--name ducks
## テーブル作成
## 今回のテーブルは 'duck_species'
aws s3tables create-table \
--table-bucket-arn "arn:aws:s3tables:ap-northeast-1:<AWS_ACCOUNT_ID>:bucket/duckdb-sample-bucket" \
--namespace ducks \
--name duck_species \
--format 'ICEBERG' \
--metadata '{"iceberg":{"schema":{"fields":[{"name":"id","type":"int"},{"name":"english_name","type":"string"},{"name":"latin_name","type":"string"}]}}}'
今回は初期データを1件だけ登録しておきます。
Athenaのマネジメントコンソール画面から以下のクエリを実行すると簡単です。
INSERT INTO duck_species VALUES (0, 'Anas nivis', 'Snow duck');
私はCLIでクエリ実行しました。
aws athena start-query-execution \
--query-execution-context Database=ducks,Catalog=s3tablescatalog/duckdb-sample-bucket \
--query-string "INSERT INTO duck_species VALUES (0, 'Anas nivis', 'Snow duck');"
QueryExecutionId が表示されるので、以下のコマンドで実行ステータスが SUCCEEDED になっていることを確認します。
aws athena get-query-execution \
--query-execution-id <Query Execution Id>
権限設計
IAMロールやLake Formationで権限設定を行います。
IAMロール
まずは、S3 Tablesのエンドポイントに接続しようと思います。
Lambda関数にアタッチするロールのポリシーは、 AWSLambdaBasicExecutionRole に加えて、以下のポリシーを設定します。今回は s3tables のアクションと該当テーブルバケットリソースへの権限が必要です。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"s3tables:GetTableBucket",
"s3tables:ListTableBuckets",
"s3tables:GetNamespace",
"s3tables:ListNamespaces",
"s3Tables:GetTable",
"s3Tables:ListTables",
"s3Tables:GetTableData",
"s3Tables:PutTableData",
"s3Tables:GetTableMetadataLocation",
"s3Tables:UpdateTableMetadataLocation"
],
"Resource": [
"arn:aws:s3tables:ap-northeast-1:<AWS_ACCOUNT_ID>:bucket/duckdb-sample-bucket",
"arn:aws:s3tables:ap-northeast-1:<AWS_ACCOUNT_ID>:bucket/duckdb-sample-bucket/*"
],
"Effect": "Allow"
},
{
"Action": "lakeformation:GetDataAccess",
"Resource": "*",
"Effect": "Allow"
}
]
}
Lake Formation
上記のIAMロールのS3Tablesへのアクセス権限を付与します。
## データベースへの権限付与
## AWS_PRINCIPAL_ARN は、Lambda関数にアタッチするIAMロールのARN
aws lakeformation grant-permissions \
--catalog-id "${AWS_ACCOUNT_ID}" \
--principal "{\"DataLakePrincipalIdentifier\": \"${AWS_PRINCIPAL_ARN}\"}" \
--resource "{\"Database\": {\"CatalogId\": \"${AWS_ACCOUNT_ID}:s3tablescatalog/${TABLE_BUCKET_NAME}\", \"Name\": \"ducks\" }}" \
--permissions "ALL"
## テーブルへの権限付与
aws lakeformation grant-permissions \
--catalog-id "${AWS_ACCOUNT_ID}" \
--principal "{\"DataLakePrincipalIdentifier\": \"${AWS_PRINCIPAL_ARN}\"}" \
--resource "{\"Table\": {\"CatalogId\": \"${AWS_ACCOUNT_ID}:s3tablescatalog/${TABLE_BUCKET_NAME}\", \"DatabaseName\": \"ducks\", \"TableWildcard\": {} }}" \
--permissions "ALL"
Lambda関数
duckdbをLambda Layerに入れて、以下のようなLambda関数を用意します。
import os
import shutil
import duckdb
def handler(event, context):
home_dir = "/tmp/duckdb"
extensions_dir = "/tmp/duckdb/my_extensions"
secrets_dir = "/tmp/duckdb/my_secrets"
if os.path.exists(home_dir):
shutil.rmtree(home_dir)
os.makedirs(home_dir)
os.makedirs(extensions_dir)
os.makedirs(secrets_dir)
con = duckdb.connect()
con.sql(f"SET home_directory='{home_dir}';")
con.sql(f"SET secret_directory='{secrets_dir}';")
con.sql(f"SET extension_directory='{extensions_dir}';")
con.install_extension("aws", repository="core_nightly", force_install=True)
con.install_extension("httpfs", repository="core_nightly", force_install=True)
con.install_extension("iceberg", repository="core_nightly", force_install=True)
con.load_extension("aws")
con.load_extension("httpfs")
con.load_extension("iceberg")
## connection s3tables.
con.sql("""\
CREATE SECRET (
TYPE s3,
PROVIDER credential_chain
);
""").show()
con.sql(f"""\
ATTACH '{os.environ.get("S3TABLE_BUCKET_ARN")}'
AS s3_tables_db (
TYPE iceberg,
ENDPOINT_TYPE s3_tables
);
""")
## show s3tables tables.
con.sql("SHOW ALL TABLES;").show()
## select all data.
con.sql("SELECT * from s3_tables_db.ducks.duck_species;").show()
## alternative
con.sql("USE s3_tables_db.ducks;")
con.sql("SELECT * from duck_species;").show()
con.close()
DuckDBを利用する際は、環境変数 $HOME にホームディレクトリを設定する必要があります。
今回は環境変数ではなく、クエリで SET home_directory='/tmp/duckdb' のように指定しています。
ついでに、extensionとsecretのディレクトリも指定しています。
続いて、今回必要なエクステンションをドキュメントに従って導入しています。
レポジトリは core_nightly です。
con.install_extension("aws", repository="core_nightly", force_install=True)
con.install_extension("httpfs", repository="core_nightly", force_install=True)
con.install_extension("iceberg", repository="core_nightly", force_install=True)
con.load_extension("aws")
con.load_extension("httpfs")
con.load_extension("iceberg")
その後、DuckDBのSecretManagerに、AWSへ接続するためのシークレットを作成します。
CREATE SECRET (
TYPE s3,
PROVIDER credential_chain
);
シークレット作成後、S3 TablesのテーブルバケットARNをアタッチすることで、接続できるようになります。
テーブルバケットのARNは、マネジメントコンソール上でも確認できます。
ATTACH 'arn:aws:s3tables:ap-northeast-1:<AWS ACCOUNT ID>:bucket/duckdb-sample-bucket'
AS s3_tables_db (
TYPE iceberg,
ENDPOINT_TYPE s3_tables
);
これで、DuckDBのデータベース s3_tables_db 、スキーマ ducks (Icebergのネームスペース)、テーブル duck_speices にアクセスできます。
SELECT * from s3_tables_db.ducks.duck_species;
USE ステートメントを使って以下のようにしても同様です。
USE s3_tables_db.ducks;
SELECT * from duck_species;
確認
Lambda関数を実行して、データが取得できていることを確認しましょう。
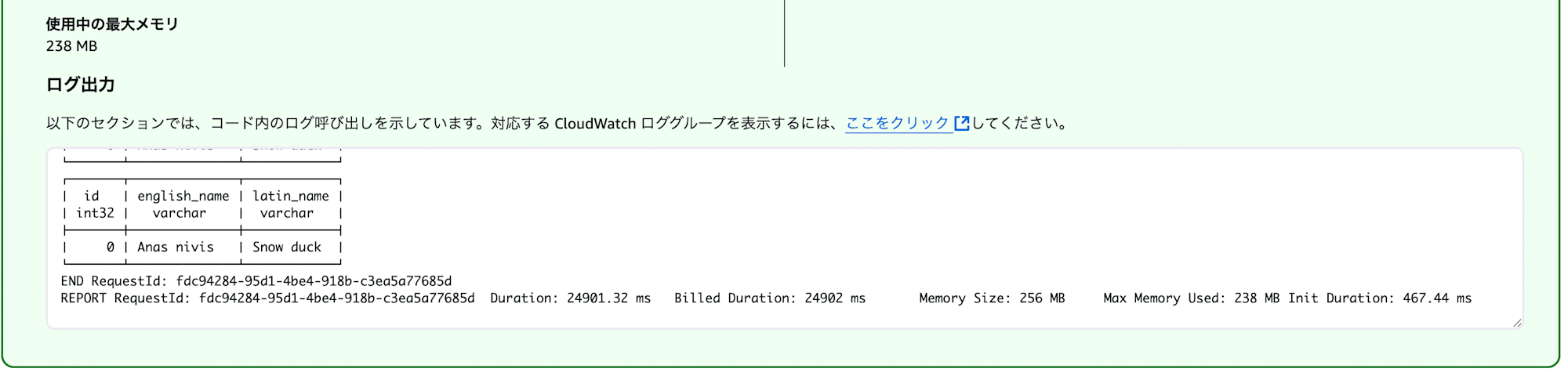
Amazon SageMaker Lakehouse (AWS Glue Data Catalog) Iceberg REST Catalog endpoint を使う
S3 TablesのCatalogエンドポイントではなく、SageMaker LakehouseのCatalogエンドポイントを利用する場合は、以下を変更します。
IAMロール
IAMロールは s3tables のアクションではなく、 glue のアクションを許可します。
リソースはテーブルバケットではなく、カタログ・データベース・テーブルを指定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"glue:CreateTable",
"glue:GetCatalog",
"glue:GetCatalogs",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:GetTable",
"glue:GetTables",
"glue:UpdateTable"
],
"Resource": [
"arn:aws:s3tables:ap-northeast-1:<AWS_ACCOUNT_ID>:catalog",
"arn:aws:s3tables:ap-northeast-1:<AWS_ACCOUNT_ID>:catalog/s3tablescatalog",
"arn:aws:s3tables:ap-northeast-1:<AWS_ACCOUNT_ID>:catalog/s3tablescatalog/duckdb-sample-bucket",
"arn:aws:s3tables:ap-northeast-1:<AWS_ACCOUNT_ID>:database/s3tablescatalog/duckdb-sample-bucket/ducks",
"arn:aws:s3tables:ap-northeast-1:<AWS_ACCOUNT_ID>:table/s3tablescatalog/duckdb-sample-bucket/ducks/*"
],
"Effect": "Allow"
},
{
"Action": "lakeformation:GetDataAccess",
"Resource": "*",
"Effect": "Allow"
}
]
}
Lambda関数
Lambda関数内では、アタッチする箇所の設定方法が異なるだけで、他は変わりありません。
テーブルバケットのARNではなく、テーブルバケットのカタログ名を指定します。
con.sql(f"""\
ATTACH '{account_id}:s3tablescatalog/duckdb-sample-bucket'
AS s3_tables_db (
TYPE iceberg,
ENDPOINT_TYPE glue
);
""")
おまけ
Icebergテーブル側のネームスペースが main の場合、DuckDBからアクセスしようとすると main ネームスペースを認識できなくてエラーになってしまいます。( SHOW ALL TABLES; では認識できています)
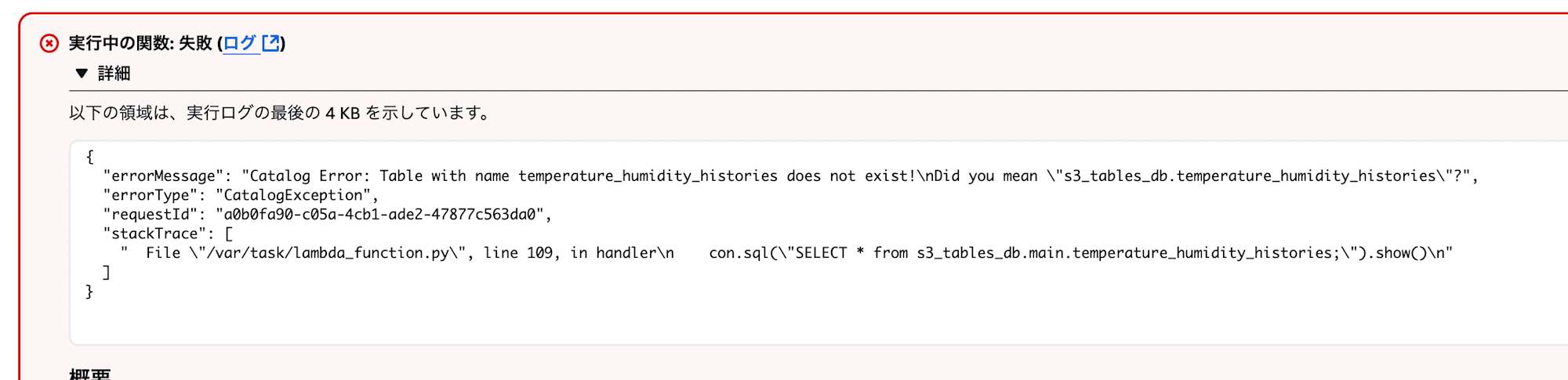
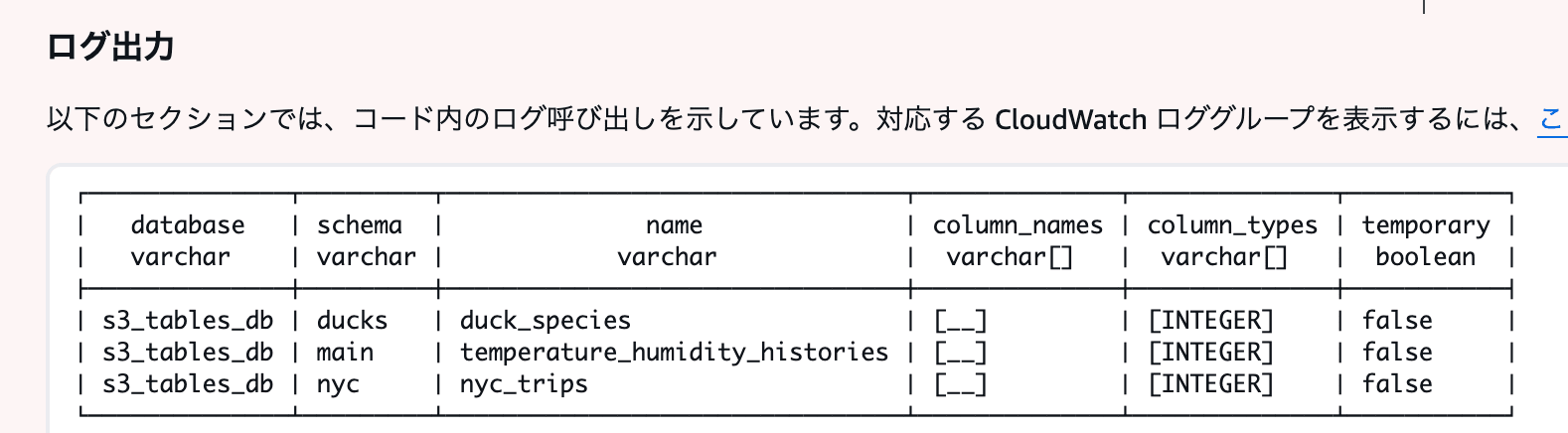
リソースリンクで回避できるか試しましたが、リソースリンクを認識してくれないので使えませんでした。
とりあえずの回避策としては、新たなネームスペースを作成して、 rename-table コマンドで main ネームスペースにある各テーブルを新たなネームスペースに移動させることで、新たなネームスペースから参照することができます。
変更する際は、Lake Formationでの権限追加を忘れずに行いましょう。
# `new_main` という新たなネームスペースを作成
aws s3tables create-namespace \
--table-bucket-arn "arn:aws:s3tables:ap-northeast-1:<AWS_ACCOUNT_ID>:bucket/duckdb-sample-bucket" \
--name new_main
# `main` から `new_main` にネームスペースを変更
aws s3tables rename-table \
--table-bucket-arn "arn:aws:s3tables:ap-northeast-1:<AWS_ACCOUNT_ID>:bucket/duckdb-sample-bucket" \
--namespace main \
--name temperature_humidity_histories \
--new-namespace-name new_main
ただし、変更対象テーブルへ書き込みを行っている場合は、その書き込みクエリに対しても新しいネームスペースのテーブルに書き込むように変更しなければなりませんので、ご注意ください。本番環境で使われているテーブルに対しては、良い回避方法ではありません。
まとめ
いかがでしたでしょうか。
DuckDBからIcebergテーブルを参照することができるようになったので、DuckDBの使い方が広がりますね。
SQLクエリで参照したい場合の選択肢の一つとして、今後も活用していきましょう。








