手間をかけず上手に歌わせたい!ワガママ心に寄り添うボーカルシンセサイザー「NEUTRINO」
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
今年も早くも敗北宣言の予感です。

▲ 助けて!既に花粉が辛いの!
春一番が吹き荒んだあの日、私の負けは確定していたのかもしれません。
こんにちは。AWS事業本部のShirotaです。
子どもの頃は花粉症で目をかきすぎて角膜が剥がれた事があります。あの頃に比べると、随分と大人になりました。
ニューラルネットワークで良い感じに歌を歌わせられる時代がやってきた?
さて、そんな春一番が吹いた2020年2月22日(猫の日!)、 一つの驚くべきサービスが公開されました。
ニューラルネットワークを用いて、歌詞とメロディーを入力するだけで良い感じに歌を歌わせる事ができるボーカルシンセサイザー、その名も「 NEUTRINO 」です。
NEUTRINO -Neural singing synthesizer-
「本ソフトの名称はまだ聞いたことのないような楽曲・ジャンルを開拓してほしいという思いを込めて名付けました。あなたの創作・発見の一助になれれば幸いです。」と公式サイトに記載があるように、「ニュートリノ」というまだ研究が続いている素粒子の名前を冠しているところからも 非常にワクワクさせられますね。
今まであったボーカルシンセサイザーとの違い
ボーカルシンセサイザーと言えば、VOCALOIDが有名なので、どんなものかは何となく知っているという人も多いのではないかと思います。
実際に触った事がある人もそれなりにいるのではないでしょうか。
触った事のある人なら分かると思いますが、歌詞とメロディーを入力するだけで歌を出力できる便利さがボーカルシンセサイザーの強みであると言えます。
ただ、ボーカルシンセサイザーは俗に「調教」と呼ばれる調声をしてあげる必要があり、これをしないとどこか機械じみた抑揚の無い発声をしてしまったり、また人間ならあり得ないような滑らかさの無いガクガクとした発声をしてしまう事があります。
この調教が、ボーカルシンセサイザーに手を出すハードルになってしまう事が今まではあったと思います。
ニュートリノはニューラルネットワークを用いて、楽譜から調教に用いるパラメータを推定してくれて、調教済みの状態で発声を行なう仕組みを採用しています。
ざっくりまとめると、基本的な歌を良い感じに歌わせるところの機構が違います。
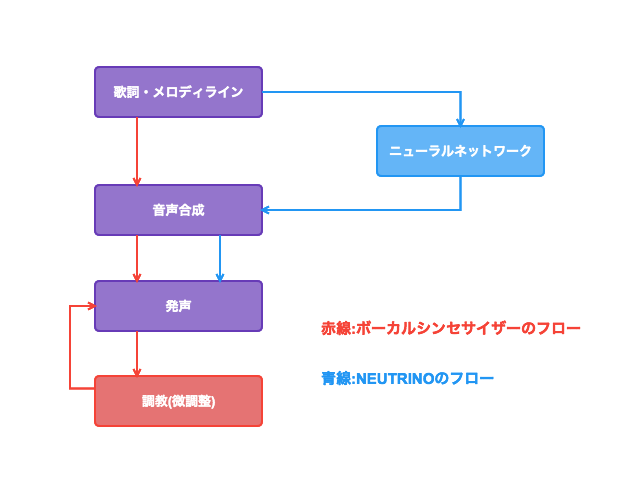
▲ ざっくりまとめてみた
ここで一つ誤解を避けたい事をお話ししておきます。
NEUTRINOで用意されているニューラルネットワークの推定を挟む事で 「何もしなくても、どんな曲でもやって欲しいように歌ってくれる」という事では無い という事です。
用意されているニューラルネットワークに推定してもらう事で、ある程度「良い感じに歌ってもらう」事は可能になってはいます。
ですが、自分が望む通りに歌わせる為にはニューラルネットワークのパラメータを調整して「学習」させる事が必要となります。
つまり、用意されているニューラルネットワークと現在提供されている音声ライブラリをそのまま用いるだけだと苦手なタイプの歌というのがどうしても発生してしまうという事です。
例えば、今までのボーカルシンセサイザーでやらせていた「人間を超えた歌い方」が備わっていない状態だと、いくらNEUTRINOにその楽譜や歌詞を正確に入力したところで上手く歌ってはくれません。
ただ、「ある程度よくある、人間が歌っているような曲」の場合は歌詞と譜面を入力したところで上手く歌ってくれる可能性は高いです。
なので、まずは手軽に触ってみてある程度動く事を確認した後で勘所を押さえていく使い方が一番手っ取り早く楽しくNEUTRINOを使える方法では無いかと思います。
と言うわけで、早速NEUTRINOを触っていきましょう!
NEUTRINOで歌を歌わせる~準備編~
まず、NEUTRINOのディレクトリ構成を見て、そこから歌を歌わせるのに必要となる要素について説明していきます。
Windows版のNEUTRINOをダウンロードしてきて解凍すると、以下のようなディレクトリが展開されます。
. ├── LICENSE_Sinsy.txt ├── LICENSE_WORLD.txt ├── README.txt ├── Run.bat ├── bin │ ├── NEUTRINO.exe │ ├── WORLD.exe │ ├── libgcc_s_seh-1.dll │ ├── libgomp-1.dll │ ├── libstdc++-6.dll │ ├── libwinpthread-1.dll │ └── musicXMLtoLabel.exe ├── model │ ├── KIRITAN │ │ ├── LICENSE_KIRITAN.txt │ │ ├── model_acoustic.bin │ │ ├── model_timing.bin │ │ ├── stats_acoustic.bin │ │ └── stats_timing.bin │ └── YOKO │ ├── COPYING_NIT-SONG070-F001.txt │ ├── model_acoustic.bin │ ├── model_timing.bin │ ├── stats_acoustic.bin │ └── stats_timing.bin ├── output ├── score │ ├── label │ │ ├── full │ │ ├── mono │ │ └── timing │ └── musicxml │ ├── sample1.musicxml │ ├── sample2.musicxml │ ├── sample3.musicxml │ └── sample4.musicxml ├── settings │ └── dic │ ├── japanese.euc_jp.conf │ ├── japanese.euc_jp.table │ ├── japanese.macron │ ├── japanese.shift_jis.conf │ ├── japanese.shift_jis.table │ ├── japanese.utf_8.conf │ └── japanese.utf_8.table └── 利用規約.txt
この構成図を頭の隅に留めておいてもらって、この後の話を読んでみて下さい。
必要となるもの
Windowsでの実行ファイルが動かせる環境
NEUTRINOは核として動くファイル群が/bin/配下のexeファイルとして用意されています。
また、そのファイル群を動かす為に用意されているRun.batファイルもWindowsで動くファイルとなっています。
ですので基本的にはWindowsが動く環境、もしくはWindowsアプリが動く環境を用意すればNEUTRINOを利用する事ができます。
Linux(Ubuntu)での実行ファイルが動かせる環境
……と、ブログを書いていたところ、なんと 2020年2月26日、NEUTRINOのVersion.0.102アップデートが発表されましてLinux(Ubuntu)でもNEUTRINOが利用できるようになりました!!! 嬉しい!
AWS上でもEC2を立ててNEUTRINOが動かせる環境が簡単に作れるようになった、と考えてみると結構ワクワクします。
Version.0.102アップデート | NEUTRINO
歌声のライブラリ
/model/配下にデフォルトの歌声ライブラリが現在2種類用意されています。それぞれのライブラリの利用規約や歌唱データ、音声合成に利用されるラベリングなどのデータが入っています。
もし、自分で用意した歌声ライブラリを利用したい場合はここに配置して後述しますRun.bat内でそれを指定してあげる必要があります。
試しにNEUTRINOを触ってみる場合、用意されている歌声ライブラリで十分やりたい事はやれると思います。
利用する際には、それぞれのライブラリの利用規約を把握して利用しましょう。
歌わせたい曲の楽譜
/score/musicxml/配下に楽譜を配置します。
この際、楽譜表記の為のXML形式である MusicXML で楽譜を作成する必要があります。
「楽譜の書き方はピンとこないけどMIDI形式なら作成できる」と言った場合には、楽譜作成ソフト「MuseScore」を用いてMIDI形式のデータを楽譜に変換する事も可能ですので、楽譜を書いた事が無くても楽譜が作成できる可能性があります。
MusicXML、またMusicXML形式で楽譜をエクスポートするのに便利な楽譜作成ソフト「MuseScore」については、NEUTRINOの公式ブログの以下のエントリを読むと分かりやすいです。
NEUTRINOで歌を歌わせる~実践編~
早速、前提として必要なものを用意して歌を歌わせてみます。
今回、歌声ライブラリは「東北きりたん」の「KIRITAN」を、歌わせる曲として童謡の「うれしいひなまつり」の譜面を作成しました。
選曲理由としてはそろそろシーズンだったのと、曲自体の著作権が切れているからです。ひなまつりREMIXにも参加できそうですよね
歌わせる曲の楽譜を作成する
私は楽譜を書く事に関しては慣れている為、前述しましたMuseScoreでNEUTRINOに入力する為の楽譜を作成しました。

▲ 歌詞に関する著作権が心配なので伏せておきます
今回歌詞を打ち込んだ事で、子どもの頃から若干ちゃんと歌詞が分かっていなかった部分を理解する事ができました。成長です。にしても「ボーリン林の笛太鼓」は流石に自分でも意味不明だった
譜面が読める人なら、若干この音符の配列を見て「そうなる?」と思われた部分もあるかもしれませんが一旦ここでは特に触れません。
後ほど譜面作りについてはちょっと触れたいと思います。
楽譜を配置する
楽譜を/score/musicxml/配下に配置します。
MuseScoreでは、「ファイル」→「エクスポート」の順に選択するとMusicXML形式で作成した楽譜をエクスポートできます。

▲ 直球な名前の楽譜を配置
バッチファイルを編集する
前述しましたが、exeファイル群を動かすバッチファイル「Run.bat」が存在します。
これを編集し、今回作成した楽譜で歌を歌うようにします。
: Project settings set BASENAME=hinamatsuri set NumThreads=0
今回作成した「hinamatsuri.musicxml」をset BASENAMEで指定します。
ここでは特に編集しませんでしたが、set NumThreadsの数を変更する事でプロセッサ数を変更する事ができます。
歌唱データ作成時にPCのリソースなどを見て、適宜編集する事をオススメします。
また、今回は特に歌声についてパラメータを調製していない為、その他の箇所は編集しません。
実際に歌わせる
お待たせしました。歌って頂きましょう。
Run.batを実行すると、以下のような動作をします。
2020/02/26 22:51:46.68 : start MusicXMLtoLabel
Convert MusicXML to label -> score\musicxml\hinamatsuri.musicxml
[WARN] The first note is not rest
output full label -> score\label\full\hinamatsuri.lab
output mono label -> score\label\mono\hinamatsuri.lab
2020/02/26 22:51:47.07 : start NEUTRINO
Linguistic feature (duration) : 0 [msec]
Predict timing : 151 [msec]
Linguistic feature (acoustic) : 1243 [msec]
Predict acoustic features (Load) : 1256 [msec]
Predict acoustic features (Forward) : 11145 [msec]
Finish : 178974 [msec]
Generation rate : 0.175333 [gen/sec]
-----中略-----
2020/02/26 22:54:52.76 : end
/bin/配下のexeファイルが順番に実行されていき、正常に終了すると/output/配下に歌のwavファイルが作成されます。
私が用意した譜面を入力した結果、出てきた音声はこんな感じになりました。
特にパラメータを弄っていないニューラルネットワークの推定で音声を合成してもらって、このクオリティです!
思った通りに歌っていない箇所があった場合には、元の譜面を調製したりRun.batを走らせると作成されるラベルを弄ったりする必要が出てきます。
今回は手っ取り早くNEUTRINOで歌を歌わせてみる事が目的だったのですが、「ちょっと良い感じに歌う可能性が上がるコツ」をまとめてみました。
ちょっと良い感じに歌って欲しい時にやれる事
歌い方の癖を把握して楽譜を調製する
歌わせてみて、「思ったように歌ってくれない……」という箇所が出てくる事があるかと思います。
NEUTRINOが他のボーカルシンセサイザーと歌を生成する仕組みが違った事を思い出して頂ければ分かるのですが、歌を調製したい場合は「楽譜を弄る」か「パラメータを弄る」必要があります。
まずは、楽譜を作る事ができた人なら手軽に行える「楽譜を弄る」方向でのアプローチについて考えてみました。
音程を変える
音程の高低を変える事で、発音が変わる事があります。
今回の曲で言うと、初めは1オクターブ高い音で歌わせてみましたところ、後半の曲の中で一番高い音が出てくるところで、ずっとかすれ声が鳴るようになってしまいました。
実際の人間が高音部になるとかすれたり裏声になるのと同じような状態です。
逆に低い音の方が人間の声域に当てはまっていたりもするので、かすれ声で上手く発声しない場合は音程を下げてみると上手くいく可能性が高くなると思います。
歌詞を発声に近い言葉に置き換える
機械に発声をさせた事があるとイメージしやすいのですが、入力された「は」を助詞の「は」と認識して「ha」ではなく「wa」と発声させる技術はまだ殆ど無いのではないかと思います。それこそ自然言語処理などが深く関わってくるものであり、難しいものである事も薄々感じて頂けているのではないかと思います。
他にも、「っ」のような促音という、それ自身は音を成さないが後につく文字の子音を伸ばすような言葉が存在していたり、歌詞をベタ打ちで入力したものをそのまま読むと違和感が生じてしまう言い回しに出会う事があるでしょう。
その際は、違和感があった箇所を発声に近い言葉に置き換える事で対応できる事があります。
例えば、
- 今日(きょ う ) は → きょ お わ
- や っ てくる → や あ 無声音(pau) てくる(無声音もしくは「っ」自身でも上手く発音できる可能性あり)
と言ったように歌詞を書き換えるだけでタイミングが良い感じに認識されれば歌わせたい通りに出力させる事も可能です。
日本語はあまり口を動かさなくても発音できてしまう言語なので、母音が一致していればそれっぽく聞こえてしまう可能性もあるので、聞き取りづらさを狙って歌詞を書いてみる事もオススメします。
私も「ルール」を「るうる」と打っても原曲の感じで上手く発音してくれず、「るるる」と打ったらそれっぽく聞こえた事がありました。
かすれ・無声音として認識されてしまう音の前に「っ」を入力する
先ほど、促音である「っ」の説明をしました。
その際にお話ししたように、促音にはその後の子音を伸ばす効果があります。(あさって→asa tt e のように)
これを利用して、タイミングが合わず上手く発声しなかった音を伸ばして発声させられるかもしれない事があります。
それでも微妙ならパラメータを弄ってしまえ
楽譜でのアプローチだけでも多岐に渡りますが、それでもどうしてもしっくりこない事もあるでしょう。歌声ライブラリ、音声合成にも限界というものがあります。
それでも望むタイミングにどうしても発声させたい!という思いがあるなら 譜面から生成されたタイミングファイルを弄ってしまう のも一つの手段です。
一度でも楽譜を入力して実行した事がある場合、/score/label/配下にタイミングラベルが生成されている筈なのでそれを弄って調整しましょう。
ただ、ここまでくると歌声ライブラリに手を加える作業に近しいものになってきてしまいます。
「とりあえずそれっぽく歌わせる事が目標」だった場合には、ある程度のクオリティで折り合いをつけた方が幸せになれる事も多いのではないかと思います。
「よしなに創作」の足音は確実に近づいてきている
ベースの入力をすると良い感じの出力を出してくれる……今回、その一つのサービスとして「NEUTRINO」について紹介してきました。
ところで、どこかで似たようなサービスを聞いた事がありませんか? AWS方面で 。
そのサービスは、 キーボードでメロディを入力する と、 トレーニング済みの様々なジャンルのモデルを利用して手軽に楽曲が作成できる と言ったものでした。
そう、去年の12月にre:Inventで発表された Deep Composer です。
このまま進歩が進めば、簡単な鼻歌にコードがつき、歌がついてあっという間に一つの作品が生まれるまでに至る可能性もあり得る訳です。
また、今までは創作足り得なかった「ネタ」がこういったサービスを使う事によって「作品」にまで昇華されるハードルがグッと下がってきているようにも感じます。
今、私たちは様々な機械学習のモデルが多種多様な成果を生み出す可能性やその現場に立ち会うという、もの凄く貴重でワクワクする時代を生きているのではないでしょうか。
この記事が、誰かの創作意欲を爆裂に促進していくきっかけになれば幸いです。