
Amazon DataZoneのワークショップをやってみて理解した概念をまとめてみる
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
データ事業本部ビッグデータチームのkasamaです。
今回はAmazon DataZoneのハンズオンワークショップを一通り実施して、そこから理解したAmazon DataZoneの概念をまとめていきたいと思います。私の現状の理解で記載した内容が多くあるので、AWSの公式ページの内容と相違がある場合は、AWS側を正しいものとしてください。間違いがあればご指摘お願いします。
全体フロー
- ドメイン作成
- プロデューサー側、コンシューマー側のプロジェクト作成
- プロデューサー側、コンシューマー側の環境作成
- プロデューサー側データソース作成
- プロデューサー側データアセット作成
- プロデューサー側データプロダクト作成
- プロデューサー側でデータプロダクト公開
- コンシューマー側で作成したデータプロダクトに対してのサブスクライブリクエストを行う。
- プロデューサー側でリクエストを承認する。
- コンシューマー側でデータプロダクトが閲覧でき、Athenaでクエリを実行できる。
詳細なフローを見る前にAmazon DataZoneの概要と用語をまとめておきたいと思います。
概要
Amazon DataZone は、 AWS、オンプレミス、およびサードパーティーのソースに保存されているデータのカタログ化、検出、共有、管理を迅速かつ簡単に行うことができるデータ管理サービスです。
amazon.comの製品ページのように特定の製品ページを見ると、製品について購入するかどうかを決定する前にすべてを理解できます。同様の体験を、DataZoneで提供したいという想いがありました。機能としては、「データアクセスの管理」、「データの検索・共有」、「機械学習を使用してデータ検出とカタログ化の自動化」 の大きく分けて3点になります。
- データの管理
- ビジネスデータカタログ(テクニカルメタデータ + ビジネスメタデータ)を集中管理できます。また、サブスクリプション、公開のワークフローで、公開範囲を制御できます。裏側では、AWS Lake Formationのアクセス許可の仕組みでアクセス管理しています。
- データの検索・共有
- チーム間でシームレスにコラボレーションし、データと分析ツールへのセルフサービスアクセスを提供することで、ビジネスチームの効率を高めることができます。S3のデータはAthena、Glue Data Catalog経由で参照、RedshiftはRedshift Query Editorによりデータ参照が可能になります。
- 機械学習を使用してデータ検出とカタログ化の自動化
- Amazon Bedrock の大規模言語モデルを活用し、ビジネスデータを自動生成してくれます。また、データ品質に関する統計情報を使用すると、データの利用者は AWS Glue Data Quality またはサードパーティーのシステムからのデータ品質に関するメトリクスを確認できます。そのほかにも流れを確認できるデータリネージもプレビュー機能としてあります。
Amazon DataZoneが無いと複数AWSアカウントやリージョン間での組織全体のアセット管理やビジネスメタデータの登録、検索などの設定が難しかったり、データエンジニア以外の分析業務に携わる人が容易にデータカタログへアクセスできなかったりするので、大規模な組織で様々なチームがデータ分析する場合は、便利なサービスだと思います。
Amazon DataZoneのサービスページがとてもわかりやすいので、こちらも参考までに。
用語
- Amazon DataZone ポータル (データポータル)
- セルフサービス方式でデータをカタログ化、検出、管理、共有、分析できるブラウザベースのウェブアプリケーションです。データポータルはAWS IAM Identity Center (後継 へ AWS SSO)、または IAM認証情報を使用して、ユーザーを認証できます。
- コンシューマーとして必要なのは、DataZoneによって生成されるURLだけです。ユーザーはSSOを使用してデータポータルにアクセスできます。IAMユーザーやIAMロールは必要ありません。データポータルのリンクとSSOユーザーだけで、このUIにアクセスできます。
- プロデューサー
- データソースを提供するユーザー。
- データソースに保存されているデータから Amazon DataZone カタログにデータアセットを発行できます。
- コンシューマー
- データを閲覧するユーザー。
- コンシューマーツール(Amazon Athena または Amazon Redshift クエリエディタ)を使用して、データアセットにアクセスして分析できます。
- Amazon DataZone ドメイン
- 組織が監視および規制するデータの明確な分野または分類。企業の組織構造に合わせてドメインを作成します。今回のワークショップでは会社単位でドメインを作成しています。
- Amazon DataZone ドメインユニット
- 企業の組織構造やビジネスユニットに合わせて作成できます。例えば、営業、マーケティング、財務などの部門ごとにドメインユニットを設定できます。
- 階層構造を持つことができ、親子関係を表現できます。例えば、「営業」の下に「国内営業」と「海外営業」を設定するなど、組織の複雑な構造を反映できます。
- 各ドメインユニットには独自の承認ポリシーを設定でき、部門やチームごとに適切なデータアクセス権限を管理できます。これにより、セキュリティとコンプライアンスを維持しながら、必要な人に必要なデータへのアクセスを提供できます。
- ドメインユニット内でプロジェクトやデータアセットを整理できます。これにより、ユーザーは特定の部門や事業領域に関連するデータを簡単に検索・発見できるようになります。
- 各ドメインユニットに所有者を割り当てることができます。所有者はそのドメインユニット内のデータとポリシーを管理する責任を持ち、データガバナンスの責任所在を明確にします。
- ドメインユニットを通じて、部門間やチーム間のデータ共有とコラボレーションが促進されます。これにより、組織全体でのデータ活用が進み、データドリブンな意思決定が可能になります。
- 組織の成長や変化に合わせて、新しいドメインユニットを追加したり、既存の構造を変更したりできます。これにより、ビジネスの変化に柔軟に対応できます。
- ドメインユニット内でメタデータフォームや用語集を作成・管理できます。これにより、データの意味や使用方法に関する共通理解を組織全体で構築できます。
- プロジェクト
- ユーザー、データアセット、分析ツールをビジネスユースケースに基づいてグループ化したものです。プロジェクトのユーザーが共同作業したり、データやアーティファクトを交換したりできるコラボレーションスペースを提供します。プロジェクトは保護されており、プロジェクトに明示的に追加されたユーザーのみがプロジェクト内のデータやツールにアクセスできます。
- デプロイされると、プロジェクトはプロジェクトで選択した機能 (データレイクなど) に基づいて IAMロールを作成し、ユーザーに業務に必要なアクセスを提供します。プロジェクトでは、同じアカウント内で作業を分離できるほか、セキュリティ境界 (セキュリティグループと IAM ロール) も設定されます。 プロジェクト内のデータを操作するために、環境を作成できます。環境は、作業に必要なアクセスをユーザーに提供するツールと機能 (データレイクなど) に基づいて IAM ロールを作成します。
- 会社でいう部署の中にプロジェクトの単位で作成するイメージです。
- 環境
- 特定のAWSリソースとそれらにアクセスできるユーザーの設定をまとめたものです。これには、S3バケット、AWS Glueデータベース、Amazon Athenaワークグループ、AmazonRedshiftクエリエディターなどのリソースと、それらを操作できるIAMプリンシパルが含まれます。環境の主な目的は、DataZone以外のAWSサービスとの連携を容易にし、プロジェクトメンバーに特定のリソースへのアクセスを提供することです。環境は、AWS サービス、外部IDE、コンソールへの実用的なリンクを保存できるように設計されており、プロジェクトメンバーはこれらのディープリンクを通じて必要なツールに直接アクセスできます。
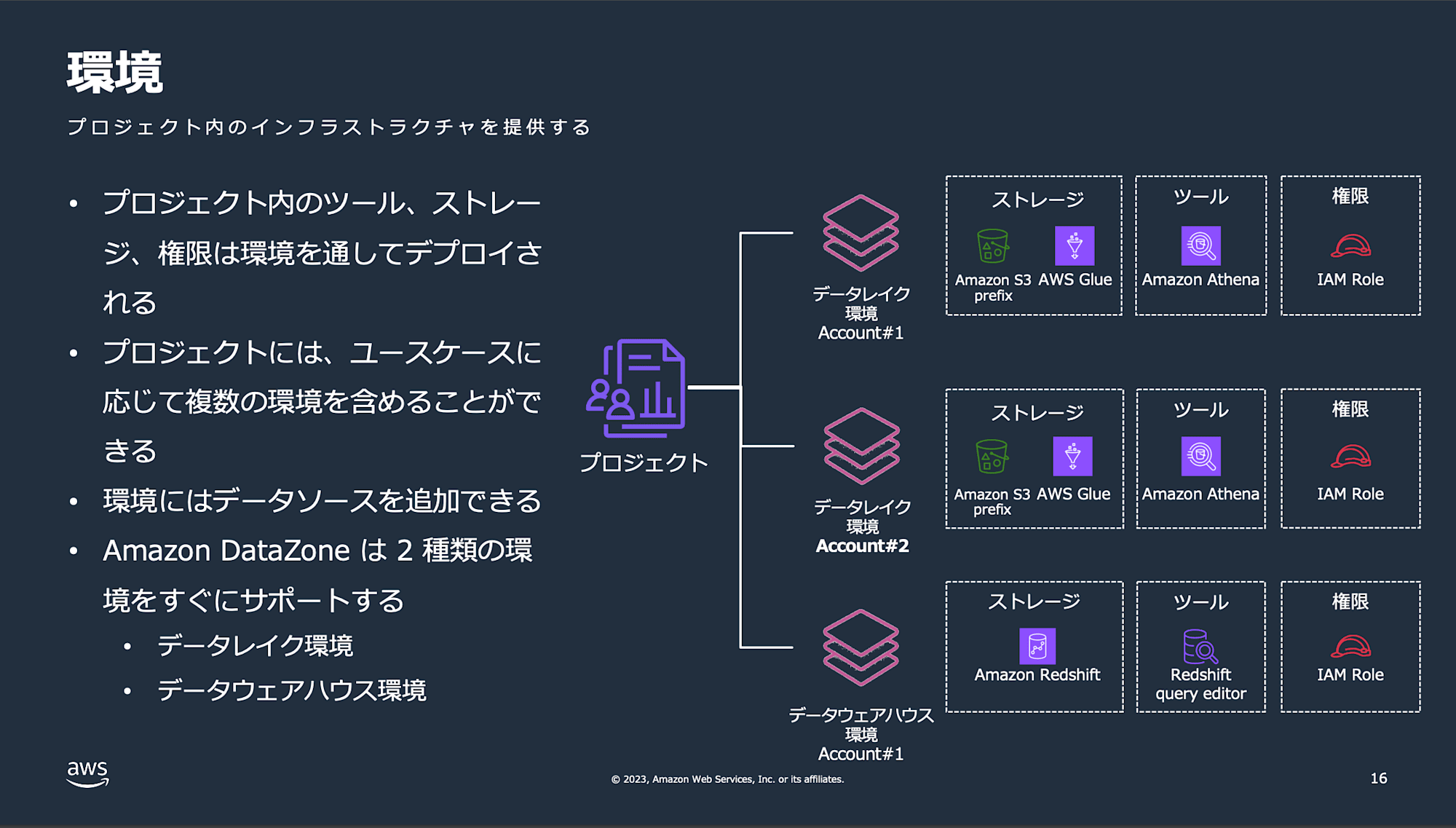
AWS Black Belt Online Seminar Amazon DataZone Overview 16スライド参照
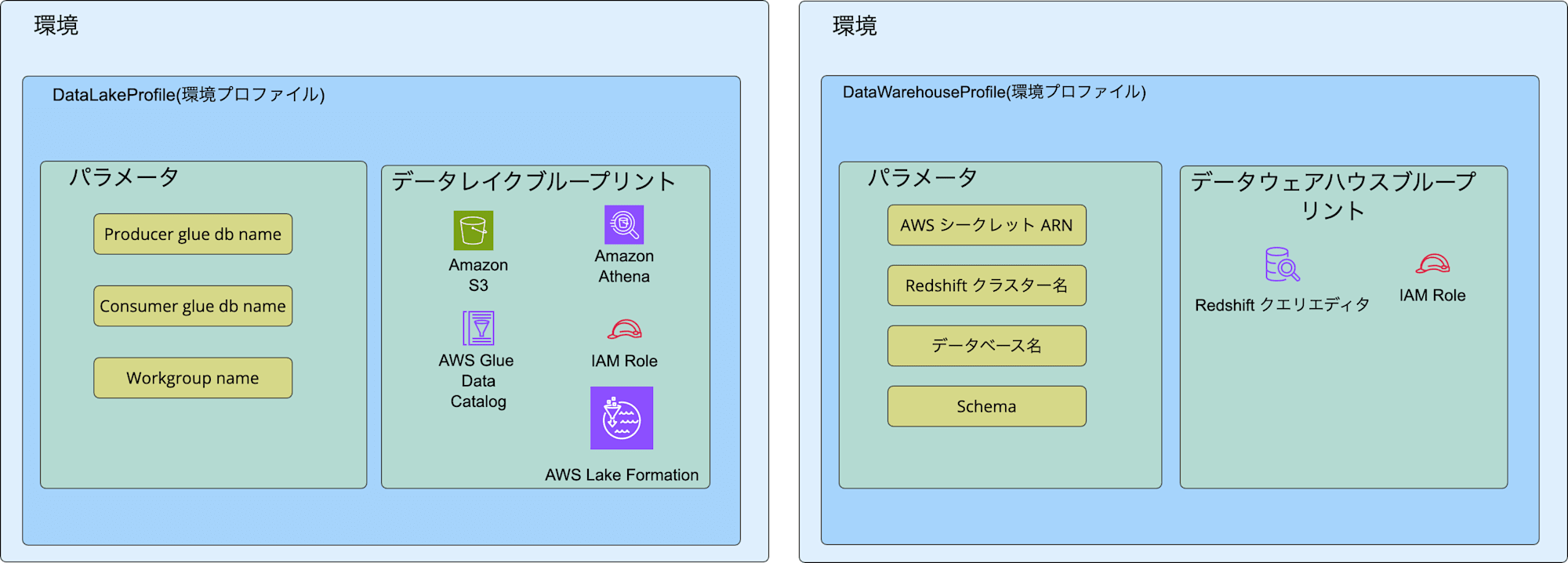
環境、環境プロファイル、ブループリントの関係を図にしてみました。以降の説明はこれを念頭に記載します。
- 環境プロファイル
- 環境の作成に使用できるテンプレートです。デフォルトの環境プロファイルとして2つあります。
- DataLakeProfile
- このプロファイルではパラメータとデータレイクブループリントを使用して、データレイク環境を作成します。パラメータはオプションですが、作成されるAWSリソースの名前を指定できます。
- DataWarehouseProfile
- このプロファイルではパラメータとデータウェアハウスブループリントを使用して、データウェアハウス環境を作成します。パラメータは、Redshift接続の認証情報を保存したAWS Secret ManagerのARNとRedshiftクラスター名、データベース名を設定します。Schema名はオプションです。
- カスタム環境プロファイル
- デフォルトの環境プロファイルとは別に、ユーザーでカスタマイズした設定パラメータとリソースを定義できます。AWSアカウントやリージョン、許可するプロジェクトなど、細かな設定を定義できるのが特徴です。
- ブループリント
- 環境のプロジェクトのメンバーが使用できるツールとサービスを定義します。templateとして、データレイクブループリント、データウェアハウスブループリント、Sagemakerブループリント、カスタムブループリントがあります。
- データレイクブループリント
- Data Lake プロデューサーとコンシューマーサービスを起動できるようにします。作成リソースとツールは以下になります。
- Amazon S3: プロジェクトが管理するデータの保存場所。プロデューサーがデータを書き込み、コンシューマーが読み取るための中央ストレージを作成します。
- AWS Glue Data Catalog: プロデューサー用の「作成」および「付与」の Lake Formation アクセス許可を持つデータベース、
コンシューマー用の「読み取り専用」の Lake Formation アクセス許可を持つデータベースを作成します。 - Amazon Athena: ユーザーが クエリするためのAthena ワークグループを作成します。
- IAM Role: コンシューマー用の「読み取り専用」のIAMアクセス許可、プロデューサー用の「読み取り」および「書き込み」のIAMアクセス許可、S3、Glue、Athena リソースへのアクセスを制御を作成します。
- データウェアハウスブループリント
- Amazon Redshift データウェアハウスでデータを公開、購読、利用できるようにします。Amazon Redshift クエリエディタへのアクセス、Amazon DataZone カタログからサブスクライブされたデータソースへの「読み取り」アクセス、設定された Amazon Redshift クラスターにローカルアセットを作成します。こちらについては今回検証していないため、詳細は割愛します。
- SageMakerブループリント
- データおよび ML アセットを検索、サブスクライブ、公開できる Amazon SageMaker ドメインを作成できます。こちらについても今回検証していないため、詳細は割愛します。
- カスタムブループリント
- 管理者は既存の IAM ロールを使用して Amazon DataZone をデータパイプラインに組み込み、それらのロールが所有する既存のデータアセットをカタログに公開できます。こちらについても今回検証していないため、詳細は割愛します。
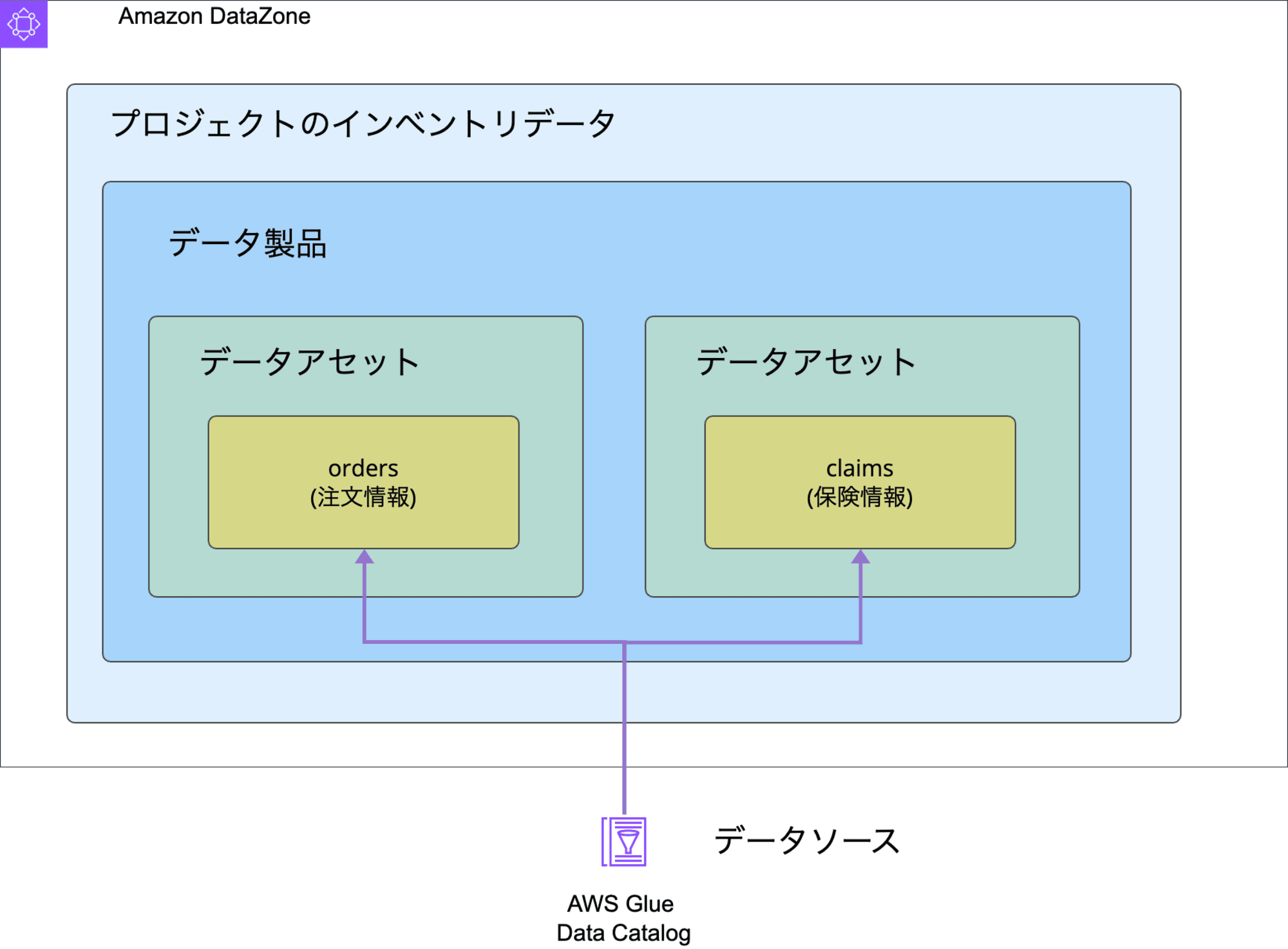
-
プロジェクトのインベントリデータ
- Inventory。英語で
在庫、一覧表という意味。プロジェクトが所有するすべてのアセットとデータ製品のリストです。
- Inventory。英語で
-
データ製品
- データアセットを特定のビジネスユースケースに合わせて定義されたパッケージ (データ製品) にグループ化することで、カタログ作成を効率化し、データコンシューマーがデータを簡単に検出してサブスクライブできるようにします。これにより、データコンシューマーが特定のユースケースに必要なすべてのデータアセットを見つけるプロセスが簡素化されます。
-
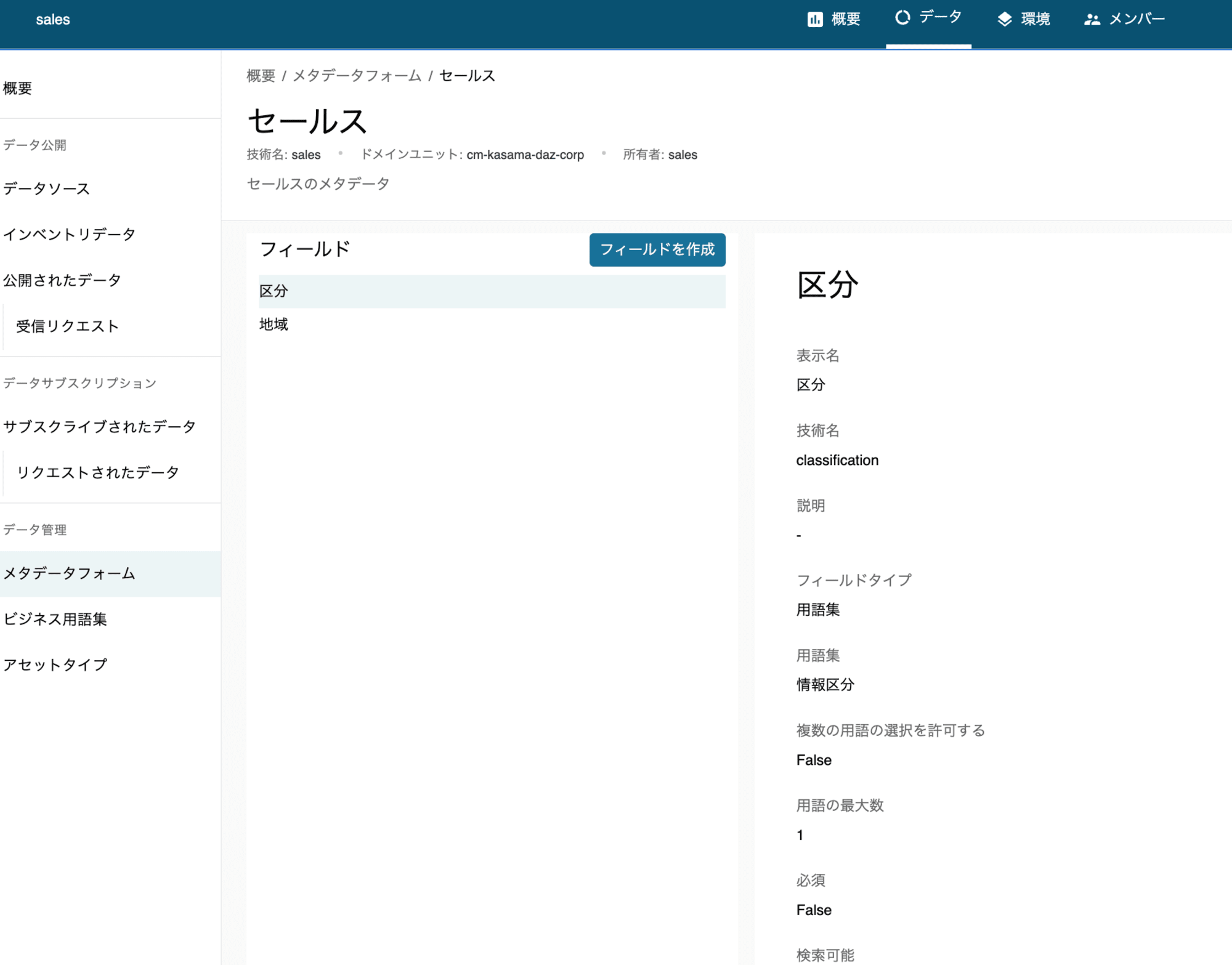
データアセット
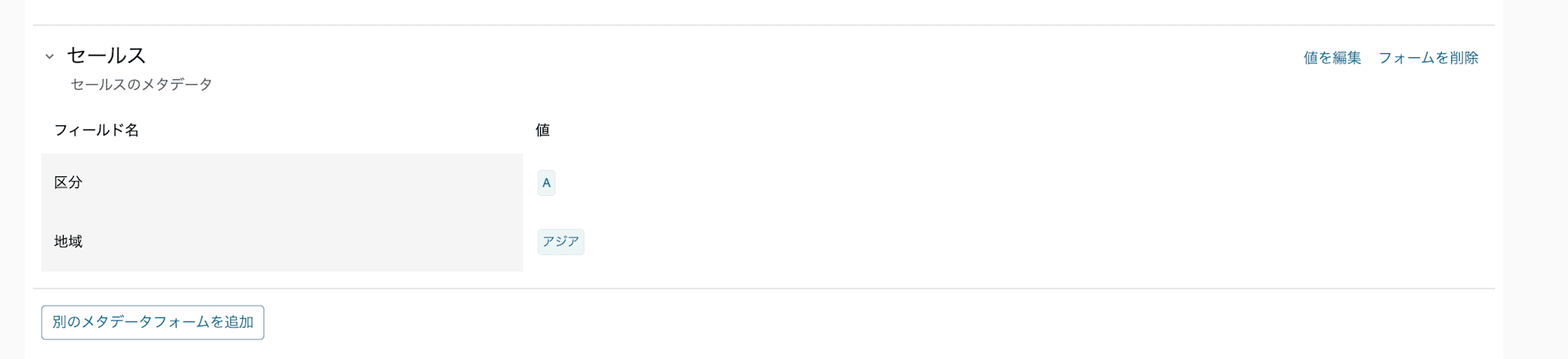
- 単一の物理データオブジェクト (テーブル、ダッシュボード、ファイルなど) または仮想データオブジェクト (ビューなど) を表示するエンティティです。ビジネスメタデータとテクニカルメタデータを参照できます。
- ビジネスメタデータは、手動入力、もしくはメタデータフォームの使用、もしくはAI レコメンデーションの説明機能を使用して作成できます。
- データソースから
データソースの実行をすることでテクニカルメタデータを取り込み、データアセットが作成される。 - AWS Glue Data Quality との統合では、データソースを使用してデータ品質スコアをスケジュールに基づいて取り込むことができます。
-
データソース
- テクニカルメタデータを DataZoneにインポートする元となるGlue Data CatalogやAmazon Redshiftを指します。
-
メタデータ
- 簡単に言えば
データに関するデータです。つまり、実際のデータの内容ではなく、そのデータの特性や属性を記述した情報のことを指します。Amazon DataZoneの文脈では、メタデータは主に2つの種類に分けられます。テクニカルメタデータとビジネスメタデータです。 ビジネスメタデータはビジネスユーザー向け、テクニカルメタデータは技術者向けになります。
- 簡単に言えば
-
ビジネスメタデータ
- データの意味、コンテキスト、ビジネス上の重要性を記述するメタデータです。これは主にビジネスユーザーや意思決定者が理解し、使用します。Amazon Datazoneによる自動生成か手動生成が可能です。
- 例)
- テーブルの説明
- テーブルのユースケース
- データのビジネス的な分類や適用範囲
- 各フィールドの詳細な説明文
- 例)
- データの意味、コンテキスト、ビジネス上の重要性を記述するメタデータです。これは主にビジネスユーザーや意思決定者が理解し、使用します。Amazon Datazoneによる自動生成か手動生成が可能です。
-
テクニカルメタデータ
- テクニカルメタデータは、データの技術的な特性、構造、格納方法を記述するメタデータです。これは主にIT部門やデータエンジニアが使用します。Glue Data CatalogやRedshiftなどから自動で生成します。
- 例)
- テーブル名(order)
- データの保存場所(S3バケットのパス)
- 最終更新時間
- AWS リージョン
- Glue データカタログ ID
- テーブル ARN(Amazon Resource Name)
-
データパブリッシュ
- データを公開すること。データが公開されると、ドメインユーザーの誰もが検索できるようになります。
-
メタデータフォーム
- データアセットに関連付けることができる、メタデータを定義するテンプレート。
- キーと値のペアのようなフォームです。これを使ってアセットを強調し、コンテキストを構築し、アセットに一貫性を持たせることができます。
-
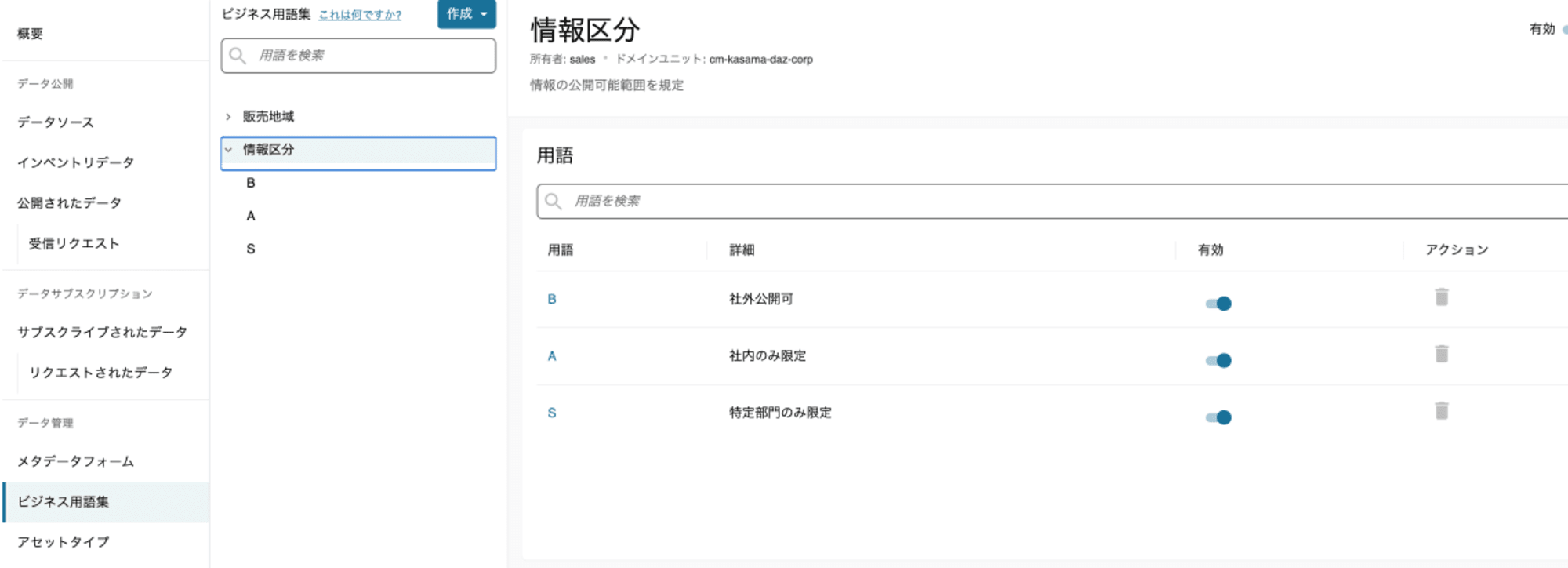
用語集
- 技術用語をビジネス用語に翻訳したり、アセットにタグのように紐づけられる用語をまとめるビジネス用語集です。自身で画面上から登録します。READMEでは用語の関係を記載できます。
- 用語集はアセットに関連付けられているメタデータフォームのフィールドの値タイプとして選択できます。アセットのメタデータフォームフィールドの値として特定の用語を選択すると、ユーザーはビジネス用語集の用語を検索し、関連するアセットを検索できます。
メタデータフォームと用語集の例
データアセットのメタデータ設定
詳細フロー
用語を理解したところで改めて詳細な処理の流れをまとめておきます。
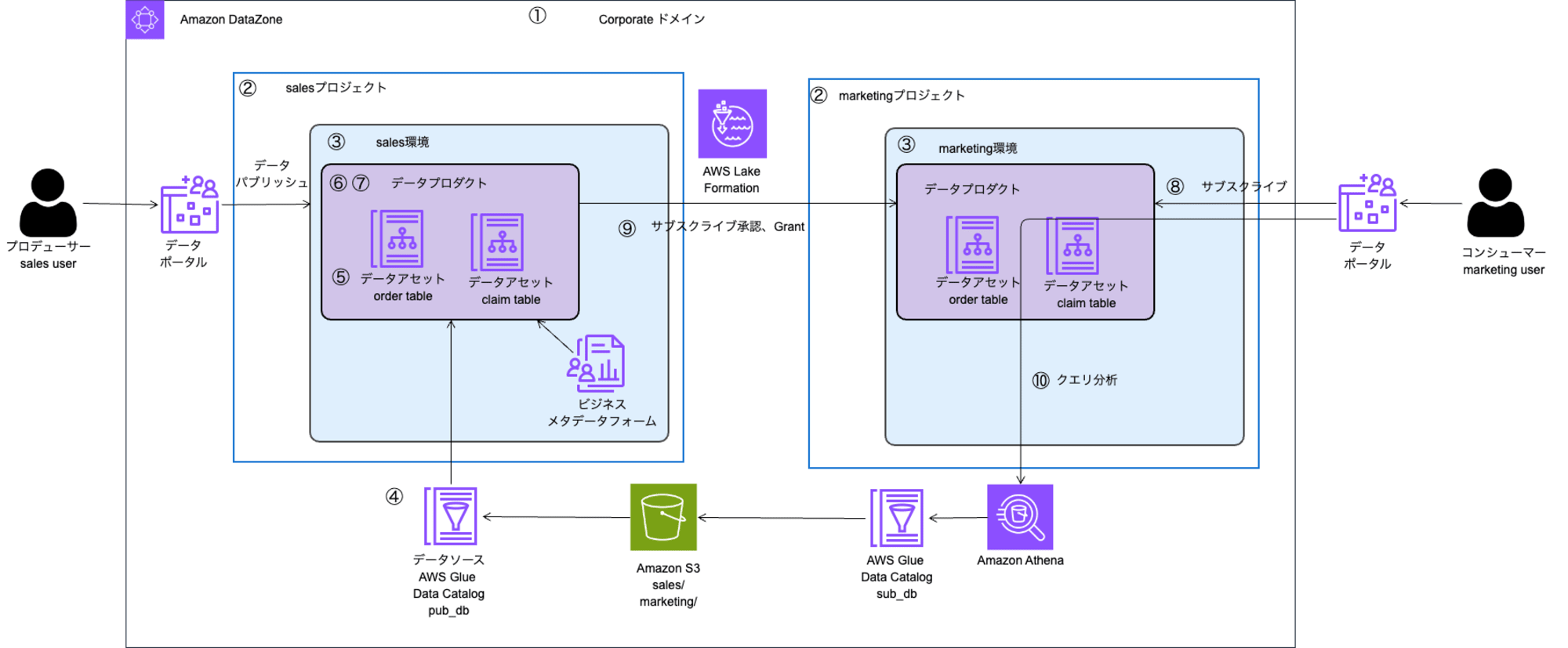
- ドメイン作成
- ドメインを1つ作成します。その際にドメイン実行ロール、Glue 管理アクセスロール、Redshift管理ロール、プロビジョニングロール、データレイク用の Amazon S3 バケットをクイックセットアップで作成します。
- プロデューサー側(sales)、コンシューマー側(marketing)のプロジェクト作成
- データをパブリッシュして提供するプロデューサー側とそのデータを参照するコンシューマー側のプロジェクトをそれぞれ作成します。
- プロデューサー側、コンシューマー側の環境作成
- 作成した両方のプロジェクトに
DataLakeProfileを使用した環境を作成します。裏側ではDataZone-Env-<環境ID>という名のCloudFormationスタックが作成され、以下のリソースが環境ごとに作成されます。 - Athena ワークグループ
- クエリの実行と管理のために作成されています。
- CloudWatch ロググループ
- ログの収集と監視のために設定されています。
- Glue データベース(プロデューサー側とコンシューマー側)
- プロデューサー側 (sales_environment_pub_db) 、コンシューマー側 (sales_environment_sub_db)
- これらはデータカタログとメタデータの管理に使用されます。
- Lake Formation 権限設定
- Glue データベースへのアクセス権限
- S3バケットへのアクセス権限
- テーブルへのアクセス権限
- これらの権限設定により、適切なIAMロールがデータにアクセスできるようになります。
- IAM ポリシーとロール
- 3つのIAMマネージドポリシー
- 1つのIAMロール
datazone_usr_<環境ID> - DataZone環境内でのアクセス制御と権限管理に使用されます。DataZoneでは、ドメインで作成したS3 Bucketに対し、環境作成時に環境ID名がフォルダ名となり、フォルダ配下を管理するための許可ポリシーを設定します。そのほかにも環境作成時に作成されたAWSリソースを操作するための許可ポリシーを作成します。
- プロデューサー側データソース作成
- ワークショップですと、CloudFormationテンプレートからcsvファイルを格納していますが、今回は手動で動作を確認したいので、環境作成時に指定された環境ID名のフォルダ内にorderフォルダを作成し、sampleファイルを格納します。
s3://amazon-datazone-<AWS_ACCOUNT_ID>-ap-northeast-1-<randomな数字>/<ドメインID>/datazone/<環境ID>/order/
- 格納したファイルをDBに登録し、tableを作成するためのAWS Glue Crawlerを作成します。作成手順は、ワークショップ
オプション:手作業でのデータカタログ作成を参考にしました。 - Clawlerを作成後、AWS Lake FormationでCrawlerのIAM Roleが
sales_environment_sub_dbに対してcreate tableするpermissionをGrantします。 - その後、Clawlerを実行すると
sales_environment_sub_dbにordertableが作成されます。 - 同様の手順で
claimデータも作成します。 salesプロジェクトで、データソースを作成します。
- プロデューサー側データアセット作成
- 作成したデータソースの
実行をすることでデータアセットが作成されます。
- プロデューサー側データプロダクト作成
orderとclaimの2つのアセットをまとめて管理するために、データプロダクトを作成します。インベントリデータの新しいデータ製品を作成から作成できます。
- プロデューサー側でデータプロダクト公開
- 公開することですべてのドメインユーザーがデータ製品を検索/閲覧できるようになります。
-
コンシューマー側で作成したデータプロダクトに対してのサブスクライブリクエストを行う。
-
プロデューサー側でリクエストを承認する。
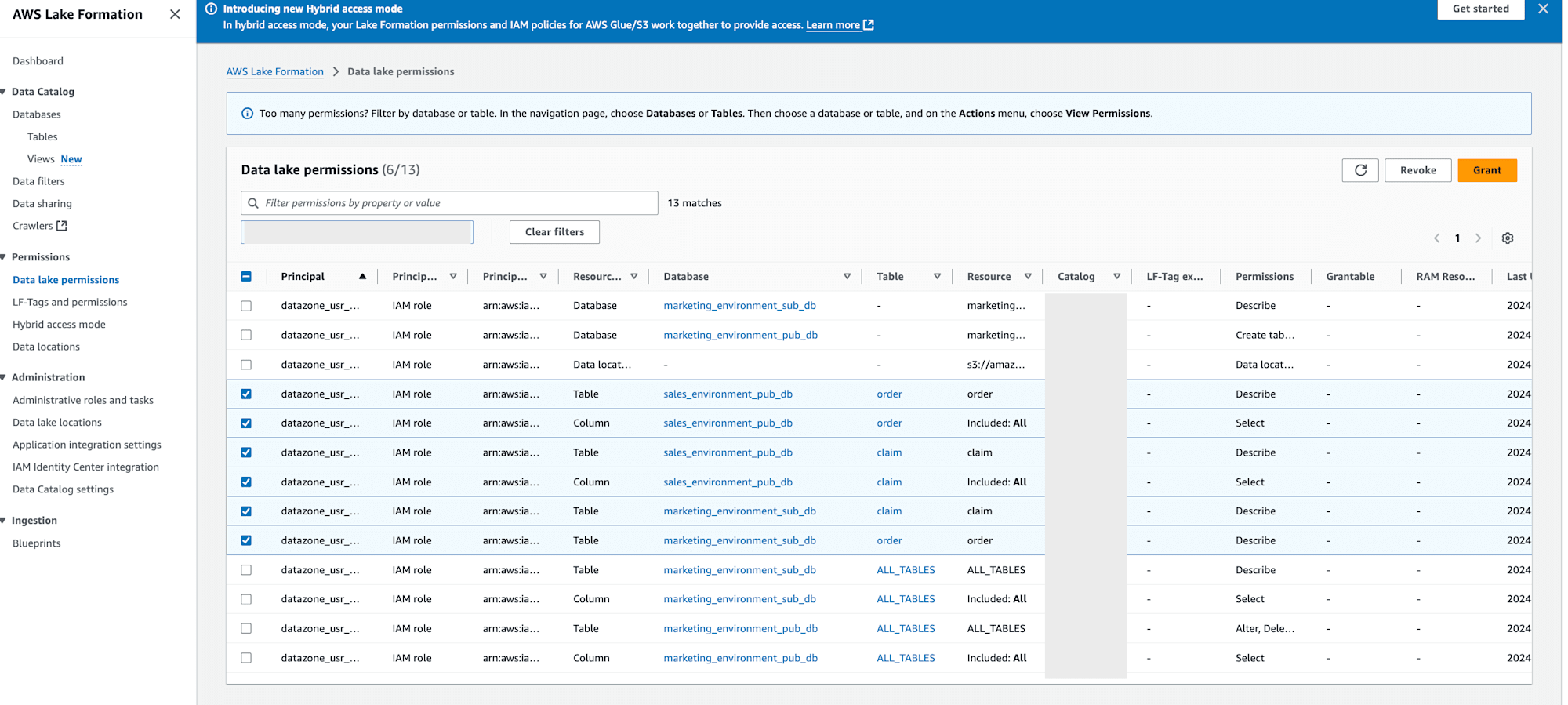
- 承認すると
- AWS Glue databaseの
marketing_environment_sub_dbにclaimとordertableが作成されます。 - AWS Lake Formationの
Data lake permissionsでmarketing環境のIAM Roleに対して、sales_environment_pub_dbのorder,claimtableに対するtable、カラムへのSelect,Describe許可、marketing_environment_sub_dbののorder,claimtableに対するtable、カラムへのDescribe許可がGrantされます。
- AWS Glue databaseの
- コンシューマー側でデータプロダクトが閲覧でき、Athenaでクエリを実行できる。
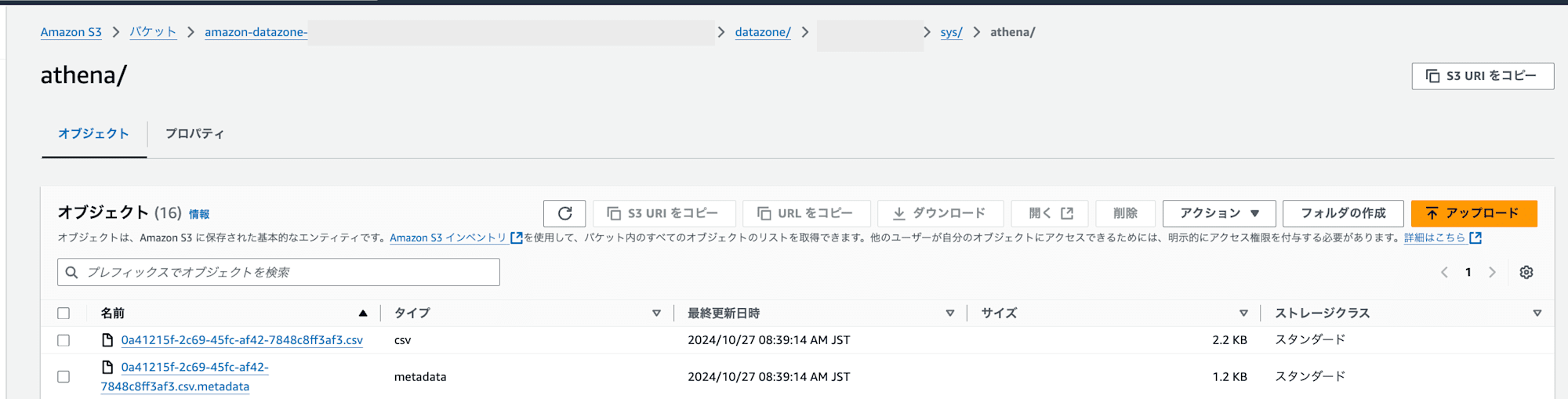
- Athenaで、
marketing_environment_sub_dbのtableをクエリすると、DataZoneのS3 Bucketの以下パスにcsvファイルとメタデータが生成されます。s3://amazon-datazone-<AWS_ACCOUNT_ID>-ap-northeast-1-<randomな数字>/<ドメインID>/datazone/<marketing環境ID>/sys/athena/
- Athenaでクエリを実行するたびに新たなファイルが生成されています。詳細な情報が確認できなかったので推測ですが、上記
athena/に生成されるcsvファイルはAthenaでのクエリ結果を格納しているのみで、実態としては、sales_environment_pub_dbのs3://amazon-datazone-<AWS_ACCOUNT_ID>-ap-northeast-1-<randomな数字>/<ドメインID>/datazone/<環境ID>/order/を参照していると考えています。試しに元データ10件以上のデータに対してlimit 1で抽出したところ、athena/配下に出力されたcsvファイルの行も1件になっていました。また、AWS Lake Formationの設定でもmarketing環境のIAM Roleに対してsales_environment_pub_dbのorder,claimtableに対するtable、カラムへのSelect権限を付与していることからもデータソースに直接クエリしていると考えています。
疑問点
ここでは、私が触ってみてと疑問に思ったことをまとめます。
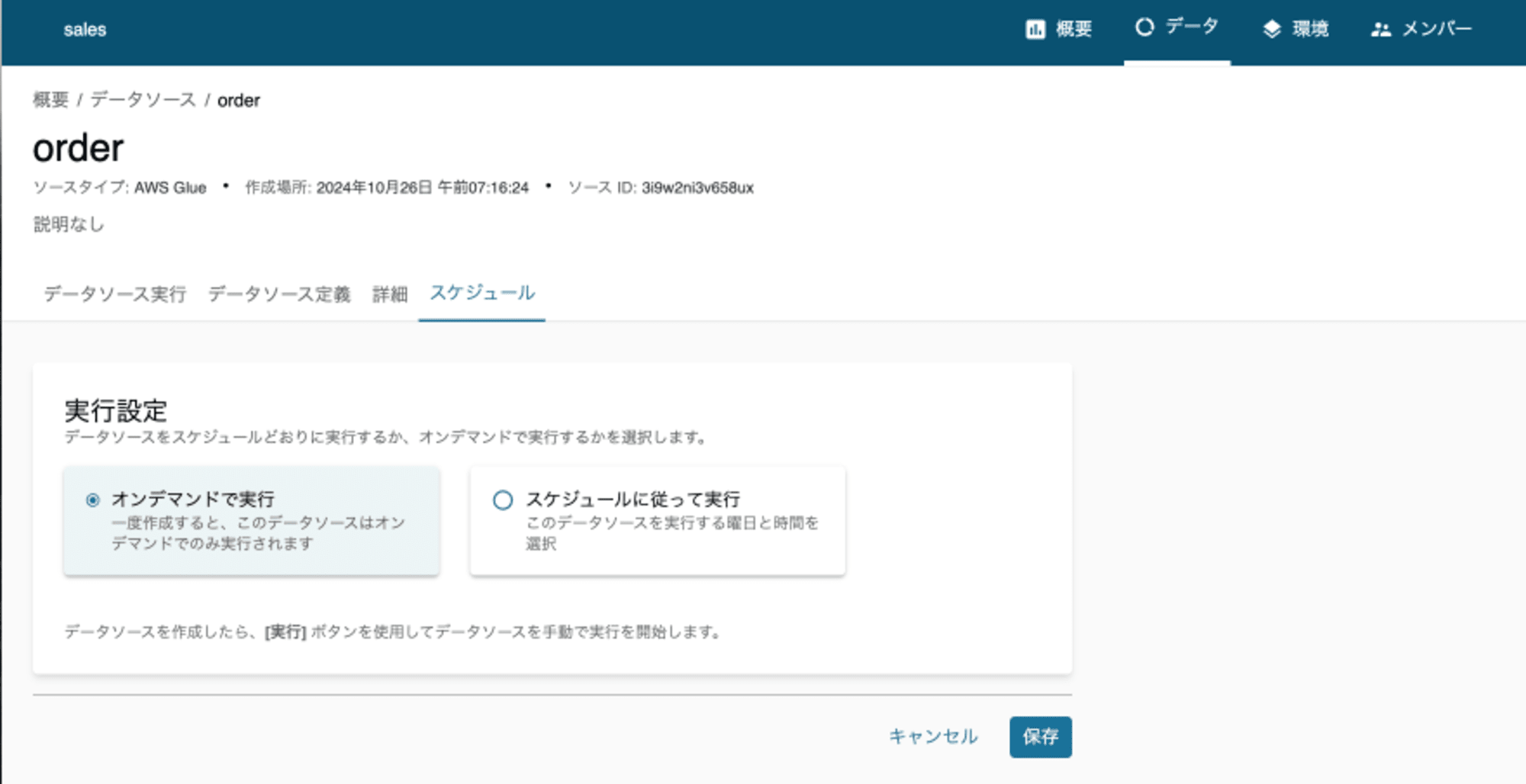
- Glue catalogのスキーマ変更があった場合は、DataZoneへの上での取り込み処理が必要ですが、自動更新できますか?
- スケジュール更新があるのでスケジュールを設定した自動更新ができます。
- AWSアカウントはまたぐ共有は可能ですか?
- 可能です。以下ブログが参考になりました。
-
既存のS3 Bucketに対して設定をする場合はどうすれば良いでしょうか?
- デフォルトの
DataLakeProfileで作成する場合、DataZoneで管理されるS3 Bucketと格納Pathは固定となってしまうので、環境ごとのIAM RoleやAWS Lake Formationの許可設定を追加する必要があると思います。別途検証してみたいと思います。
- デフォルトの
-
S3、Redshift以外のデータソースはどうすれば?
- AWS Glue コネクタを通じて、AWS、サードパーティーのサービス、オンプレミス、および Amazon AppFlow を介したその他のサービスのデータにアクセスできます。以下はSnowflakeの例になります。Athenaでデータを参照はできるかわかりませんが、Glue Data Catalogに登録してテクニカルメタデータの連携はできそうです。
参考資料
最後に
カスタム設定や既存資産との連携など、実際に触ってみないと分からないことが多いので、引き続き検証していきたいと思います。









