
QuickSight 計算フィールドを使って擬似的に UNION を実現してみた
QuickSight では 2025/8 現在、異なる 2 つのデータソースのデータセットを UNION で結合する方法がサポートされていません。
一方で、どうしても UNION 結合したい時もあります。
今回は、以下 QuickSight Community 記事にて計算フィールドを使って擬似的に UNION する方法があったためやってみます。
やってみた
以下 2 つのサンプルデータを準備します。
UserId,UserName
1-A,Gouki
1-B,Honda
UserId,UserName
1-C,Ryu
1-D,Mai
sample_data1.csv をアップロードし、QuickSight のデータセット編集画面を開きます。
その後、右上の「データを追加」より sample_data_2.csv をアップロードします。
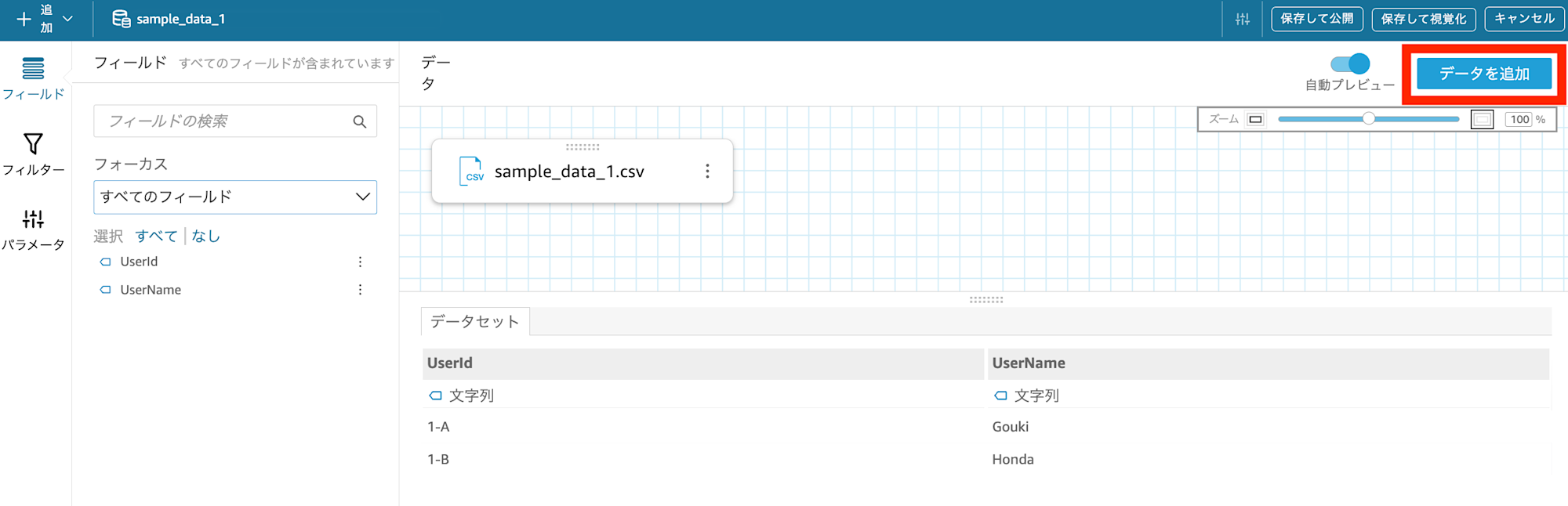
アップロードしたら、sample_1 と sample_2 で全く何も一致しない列同士で FULL JOIN を実行します。
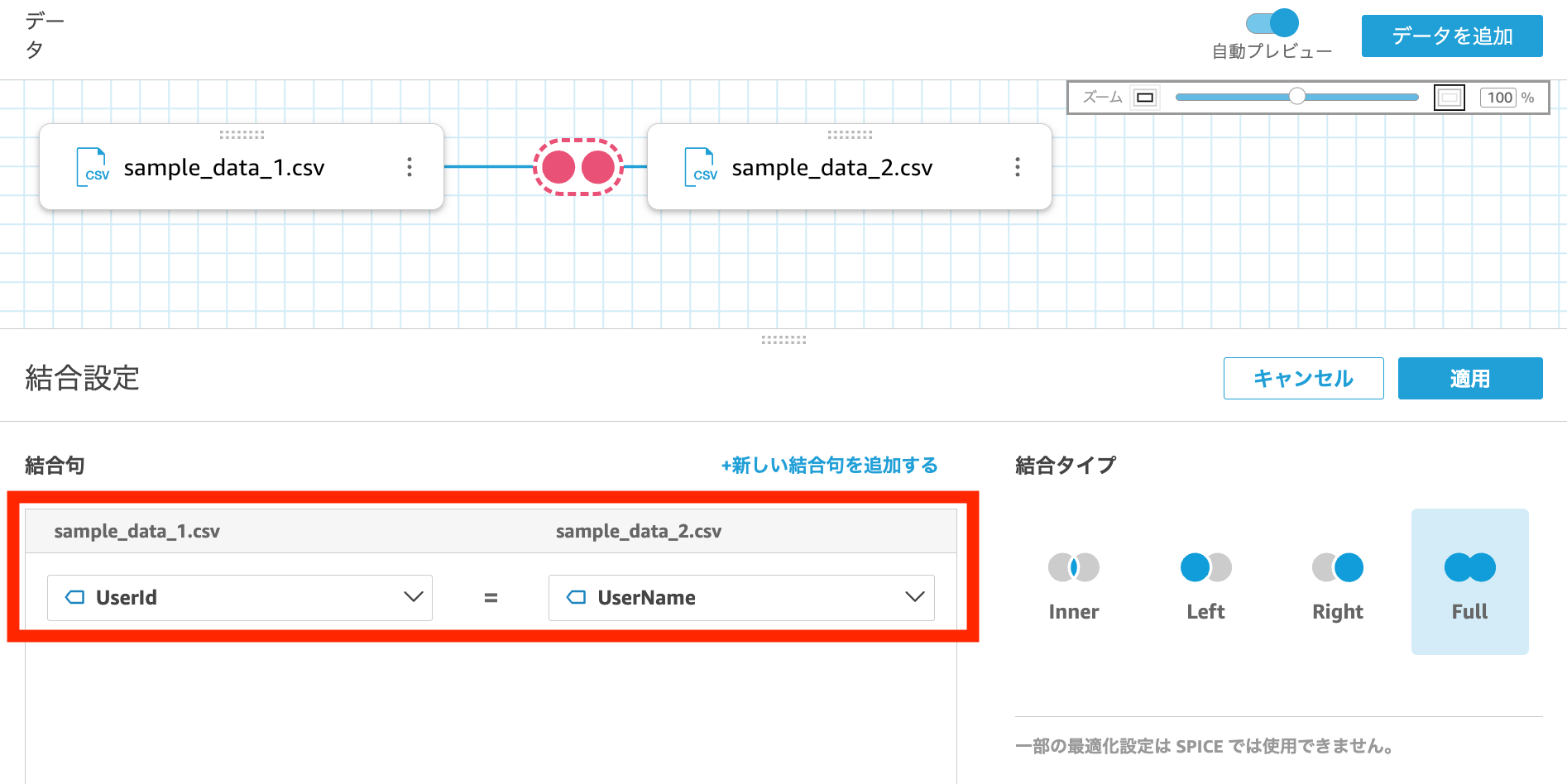
すると以下のように、sample_1 と sample_2 の合計 4 行がプレビューされます。
一方で、各行に null があり UNION 結合になっていません。
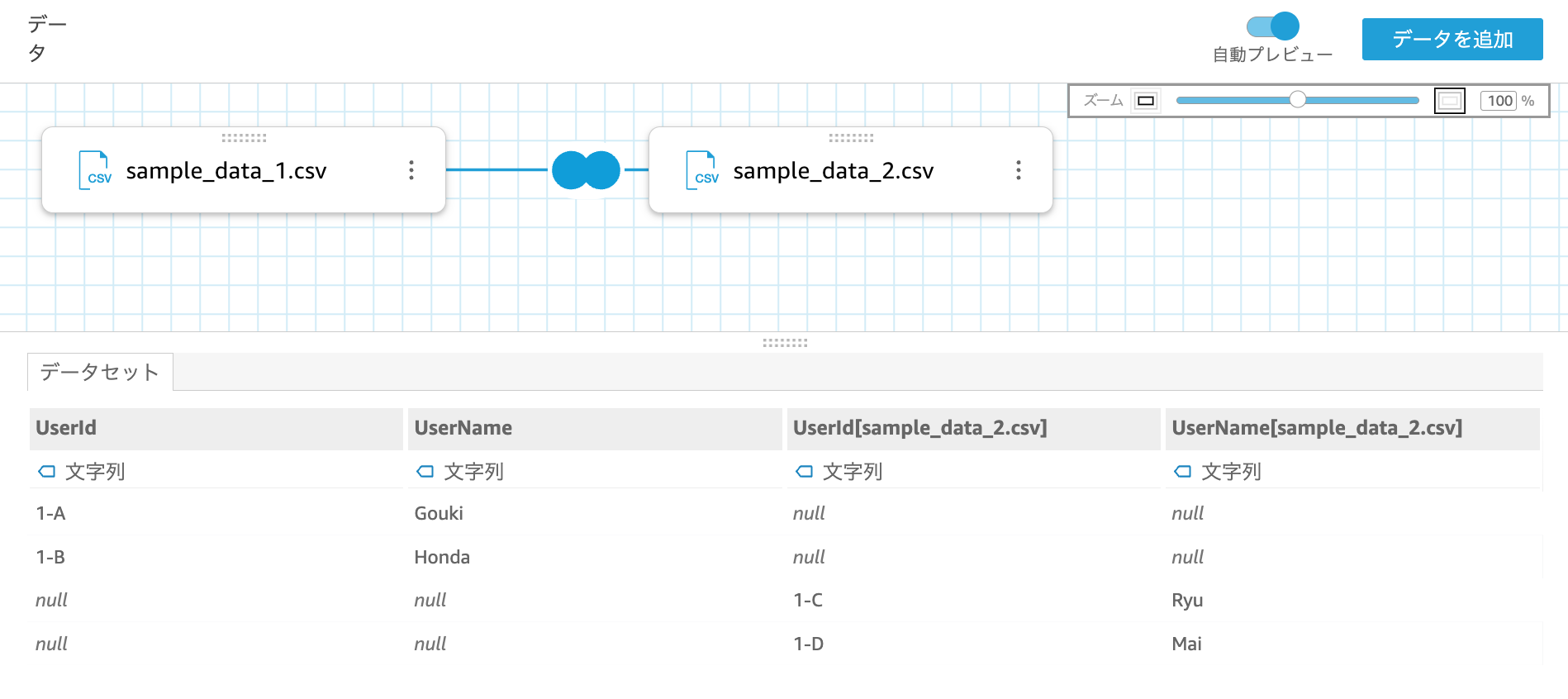
上記画像の null を QuickSight の計算フィールドを使って削除し、縦結合を実現していきます。具体的には計算フィールドにて coalesce 関数を使用します。
coalesce は 2 つ以上の引数を取り、Null ではない最初の引数を返す関数です。
例えば coalesce(A, B) と書くと、A が Null でなければ(ちゃんと値が入っていれば)A を返し、A が Null ならば、その次の B を返すというものです。
詳細は下記ドキュメントをご参照ください。
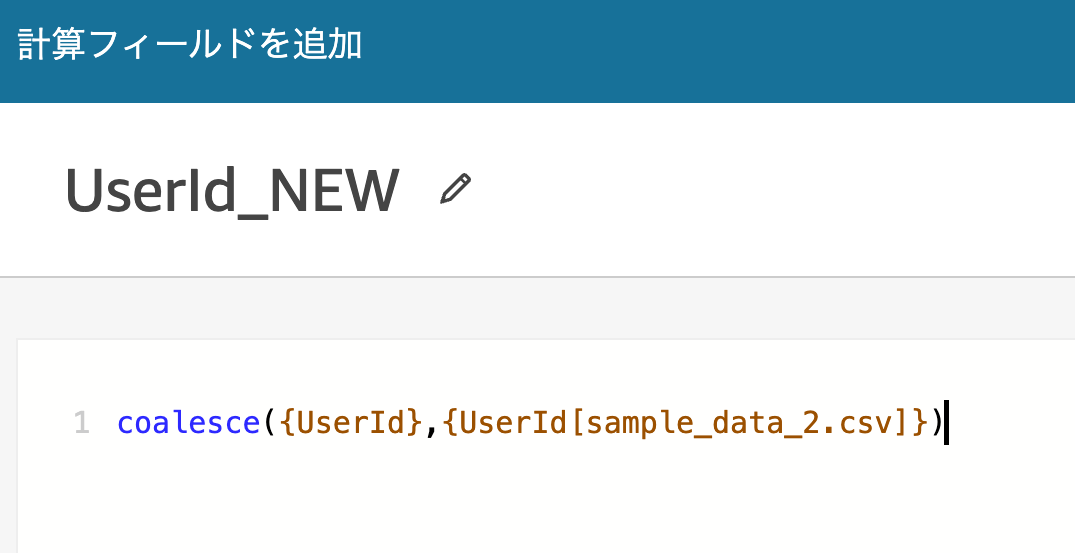
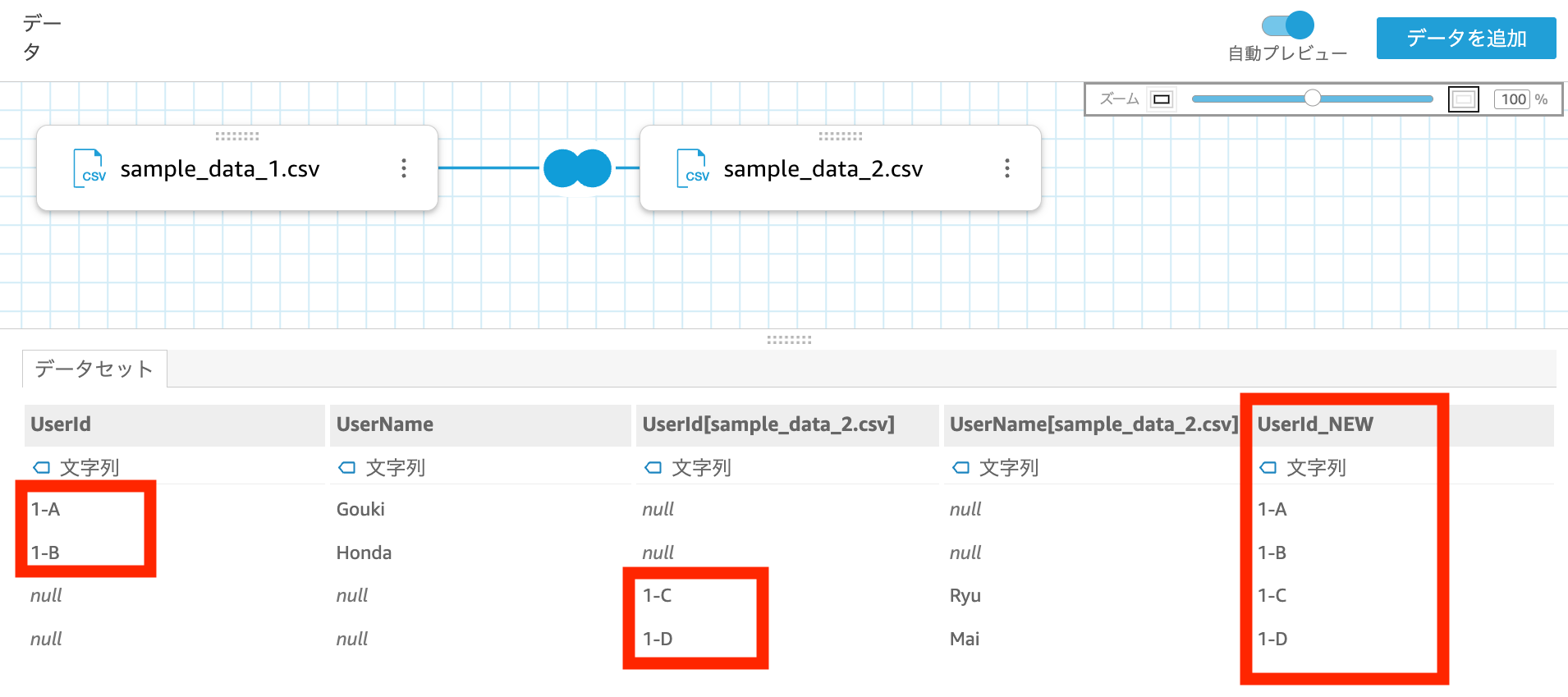
UserId_NEW という名前の計算フィールドを追加します。計算式は以下のように指定します。
coalesce({UserId},{UserId[sample_data_2.csv]})
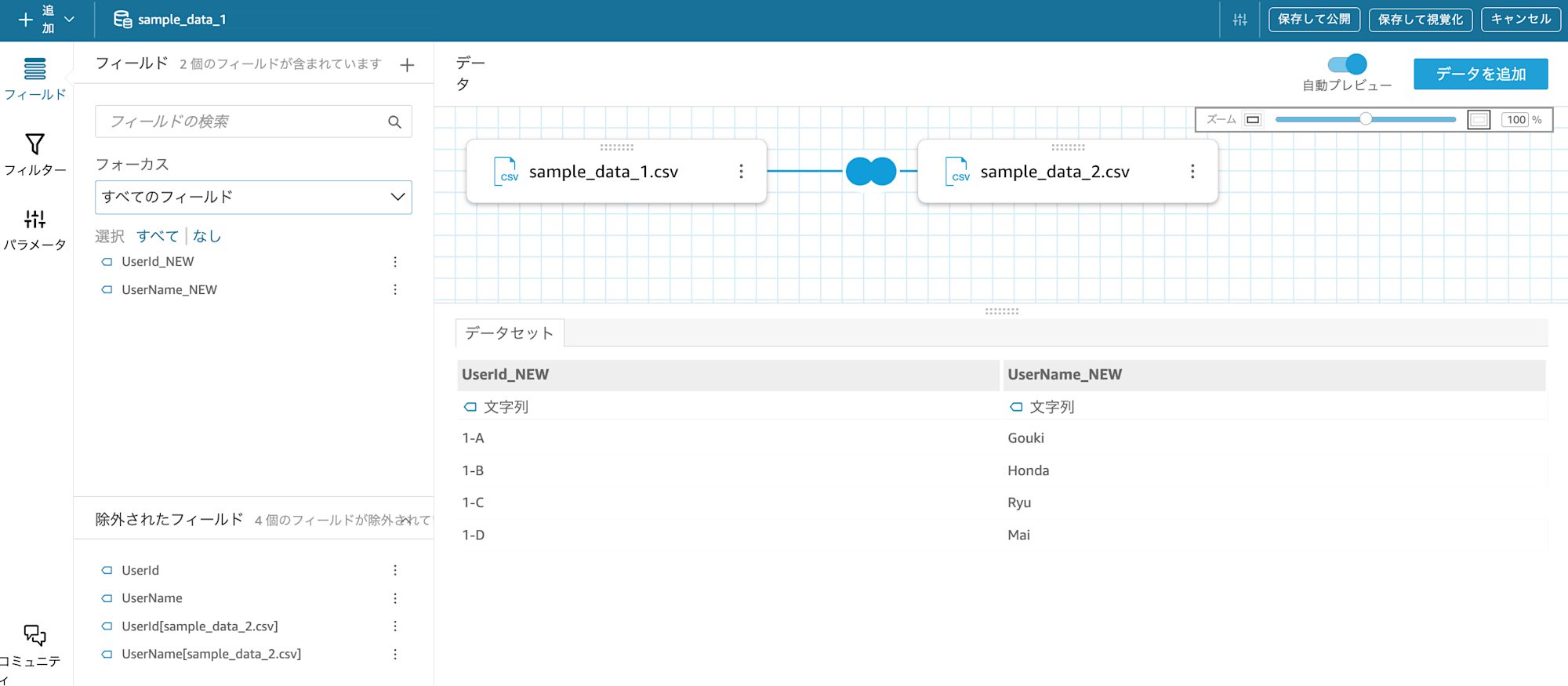
UserId_NEW カラムが追加されました。null はなく、縦結合が実現できています。
coalesce を使うことで、sample_1 の UserId カラムと sample_2 の UserId カラムから null を除いた値を取得することができました。
同様の処理を UserName カラムに対しても行います。
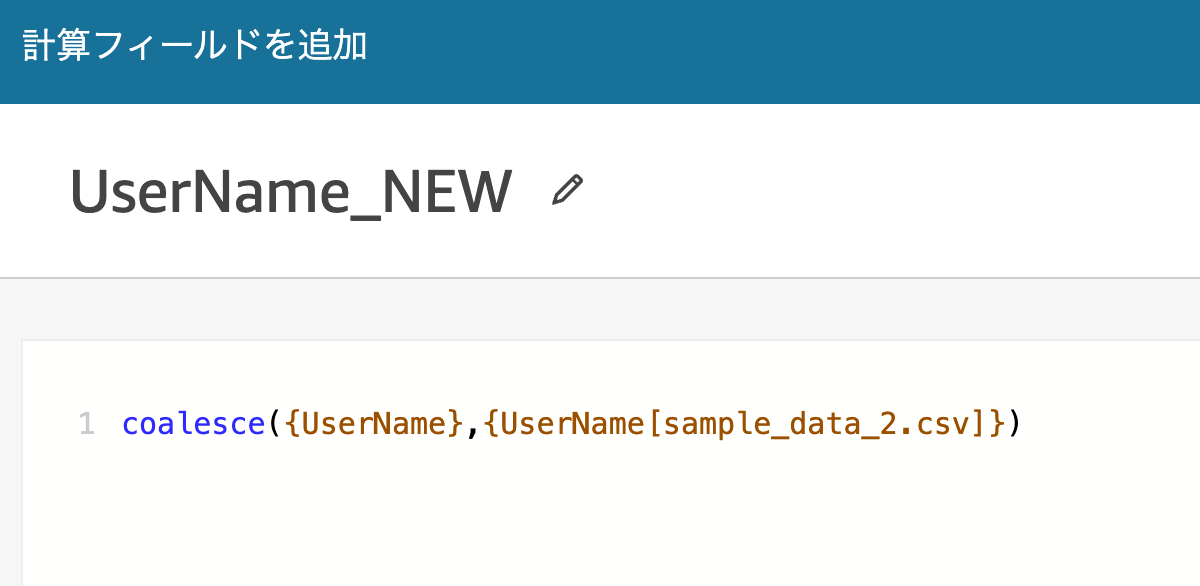
計算フィールドで UserName_NEW の名前で、coalesce 関数を使用します。
coalesce({UserName},{UserName[sample_data_2.csv]})
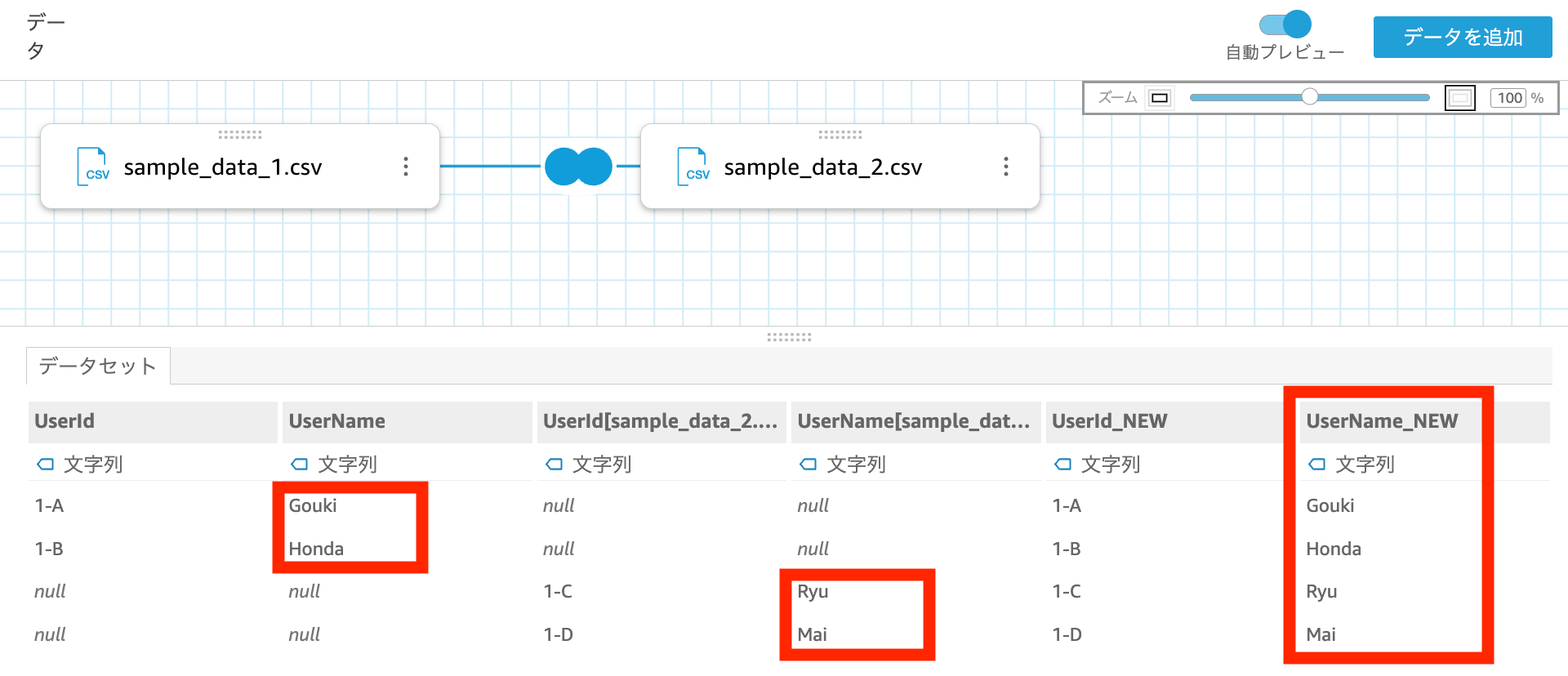
すると以下の通り、sample_data_1 と sample_data_2 から UserName を抜き出して新規の列 UserName_NEW として定義できました。
あとは、既存のフィールドの横にある縦の 3 点リーダーから「フィールドを除外」を選び、前述の UserId_NEW, UserName_NEW 以外のフィールドを除外します。
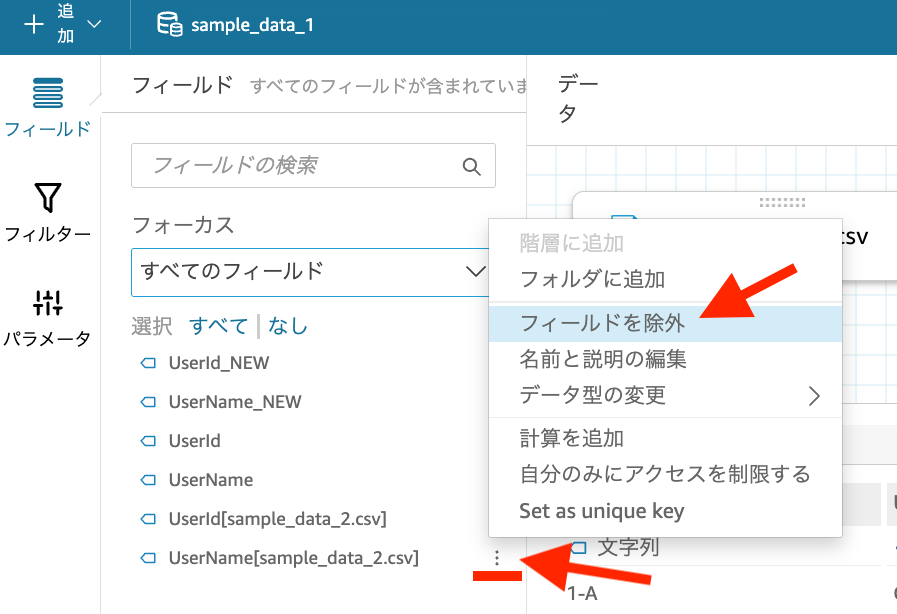
すると以下の通り、sample_data_1 と sample_data_2 を UNION したデータを作ることができました。
終わりに
今回は QuickSight にて擬似的に UNION をする方法があったため、やってみました。計算フィールドの関数を使うことで実現ができることがわかって一安心です。一方で、今後は標準機能にて UNION が実装されるとより嬉しいですね。
なお、UNION については今回の方法以外にも Athena を利用する方法やそもそも QuickSight に読み込む前にスクリプト等で結合しておくなども別案としてあるかと思います。
以下公式ドキュメントやブログに実装のヒントとなる情報について記載されておりますため、こちらも適宜ご参照いただけますと幸いです。
複数の Amazon S3 ファイルに基づいてデータセットを作成する
・マニフェストを使用してファイルを結合する
・マニフェストを使用せずにファイルを統合する - マニフェストを使用せずにファイルを統合する - 複数のファイルを、マニフェスト内に個別にリスト化せずに、1 個に統合するときは、Athena を使用します。
・スクリプトを使用してファイルをインポートする前に添付する - ファイルをアップロードする前に、結合用に設計されたスクリプトを使用します。
...
複数の Amazon S3 ファイルに基づいてデータセットを作成する
複数のファイル(データ)を効率よく可視化するためには、Athena を経由して QuickSight に連携させる方法が一般的です。今回は S3 に保存した複数の CSV ファイルを QuickSight で可視化するまでの方法を検証し、その過程を備忘録としてまとめました。
また、QuickSight ではこんな機能があったらいいなについて、日本語で検索してもなかなか見つからない時があります。
その時は Google 英語検索や QuickSight Community 記事で探すと意外な解決法が見つかったりするため、ぜひお試しください。
本記事がどなたかのお役に立てば幸いです。
参考情報







