![[アップデート] AWS Step FunctionsのDistributed Mapでデータオプションが拡張されました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-5f8ac6d1392d52f09eefb00a5ad1b303/fceee02f9b8607d60014a828933bc45b/aws-step-functions?w=3840&fm=webp)
[アップデート] AWS Step FunctionsのDistributed Mapでデータオプションが拡張されました
こんにちは。サービス開発室の武田です。
AWS Step Functionsで、Distributed Mapに関するアップデートが発表されました。
今回のアップデートでは、新しいデータソースオプションの追加、可観測性メトリクスの強化など、複数の機能が追加されています。中でも注目すべきは「LOAD_AND_FLATTEN」という新しいTransformationモードです。この機能により、S3に保存された大量のデータファイルを直接処理できるようになり、大規模な分析・ETLワークフローの構築が大幅に簡素化されます。
この記事では、LOAD_AND_FLATTEN機能に焦点を当てて、その概要と実際の活用方法について解説します。
LOAD_AND_FLATTENとは
LOAD_AND_FLATTENは、Distributed MapのItemReaderに追加された新しいTransformationモードです。S3のListObjectsV2 APIで取得したオブジェクトのメタデータではなく、ファイルの実際の内容を直接読み込んで処理 できるようになりました。
従来の課題
従来のDistributed Mapでは、次のような制約がありました。
- S3オブジェクトのメタデータ(キー、サイズなど)のみを処理対象としていた
- 実際のファイル内容を処理するためには、ネストしたDistributed Mapを使用する必要があった
- データの前処理として、別のプロセスでマニフェストファイルを作成する必要があった
LOAD_AND_FLATTENによる改善
LOAD_AND_FLATTEN機能を使用することで、次の利点があります。
- S3に保存されたCSV、JSON、JSONL、Parquetファイルを直接処理できる
- カスタムの前処理プロセスが不要
- ネストしたDistributed Mapの構成を削減できる
- 並行処理によるスケーラビリティが向上する
- アクティブなマップ実行数を削減できる
技術的な詳細
基本的な設定
LOAD_AND_FLATTENを使用するItemReaderの設定例は次のとおりです。
{
"ItemReader": {
"Resource": "arn:aws:states:::s3:listObjectsV2",
"ReaderConfig": {
"InputType": "JSON",
"Transformation": "LOAD_AND_FLATTEN"
},
"Arguments": {
"Bucket": "my-data-bucket",
"Prefix": "input-data/"
}
}
}
サポートされるファイル形式
次の4つの形式がサポートされています。
- CSV: カンマ区切りテキストファイル
- JSON: 標準的なJSON配列
- JSONL: 改行区切りのJSON(JSON Lines)
- Parquet: Apache Parquet形式
やってみた
実際にLOAD_AND_FLATTENを使ってみました。S3バケットに適当なJSONファイルをアップロードし、LOAD_AND_FLATTENの有無でどのように動作が変わるのかを確認します。
まずは従来のDistributed Mapを定義してみます。「変換」という設定項目がありますが、ここは「なし」とします。
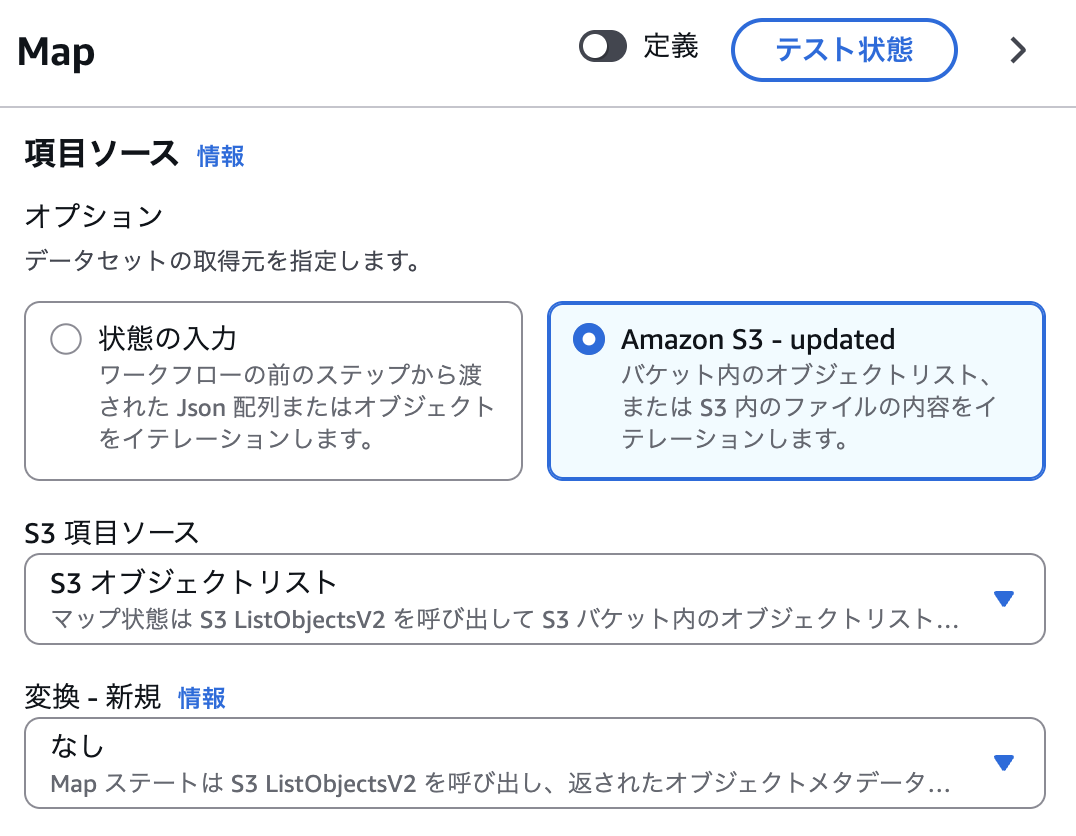
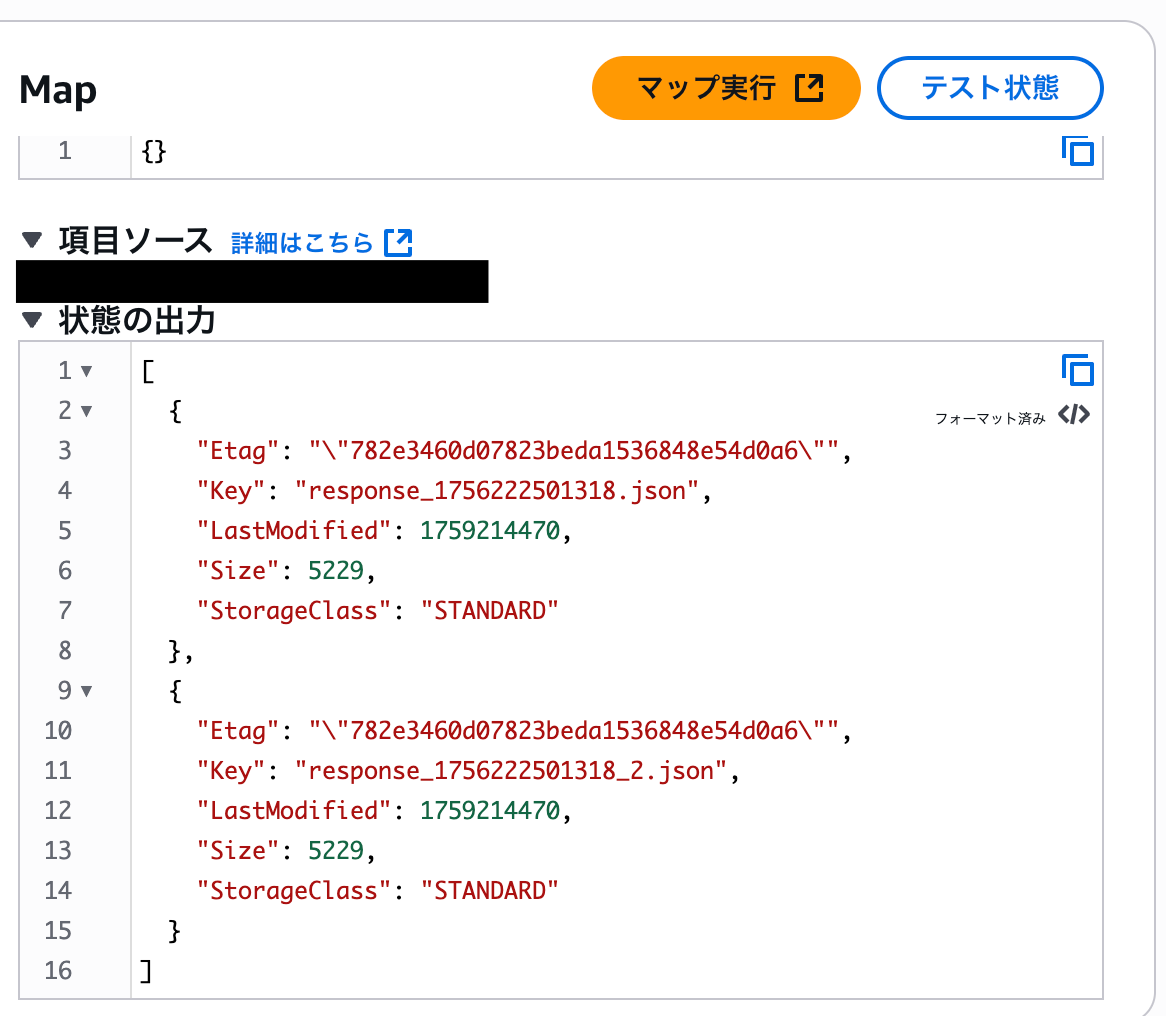
このステートマシンを実行すると、次のように、取得したリストのメタデータが取得されます。各イテレーターには、このメタデータがそれぞれ渡されることになります。
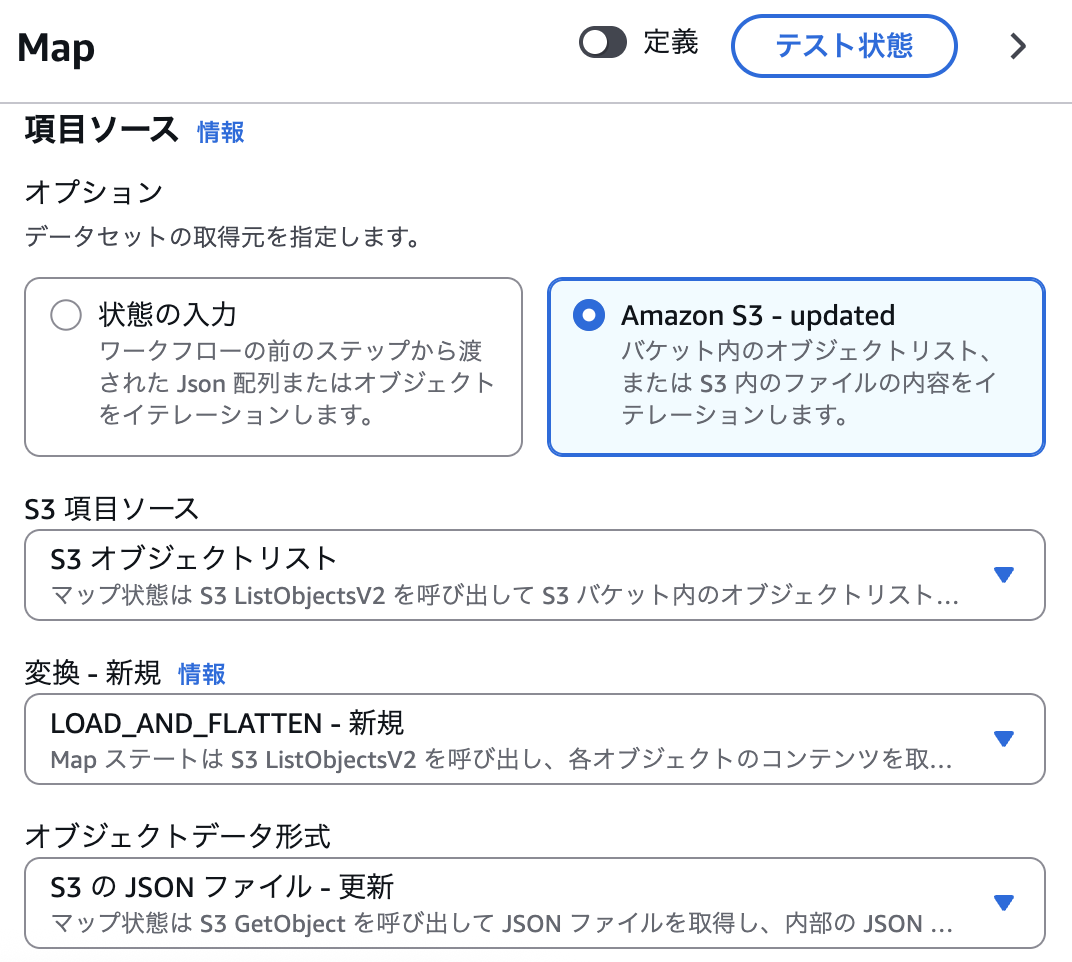
続いて、「変換」の設定項目をLOAD_AND_FLATTENに設定します。この設定をする場合、「オブジェクトデータ形式」の指定が必須となります。今回は、アップロードしたファイルはJSON形式ですので、JSONファイルを指定します。
このステートマシンを実行すると、次のような出力が確認できます。先ほどとは異なり、リストのメタデータではなくファイルの中身が展開され各イテレーターにそれぞれ渡されます。
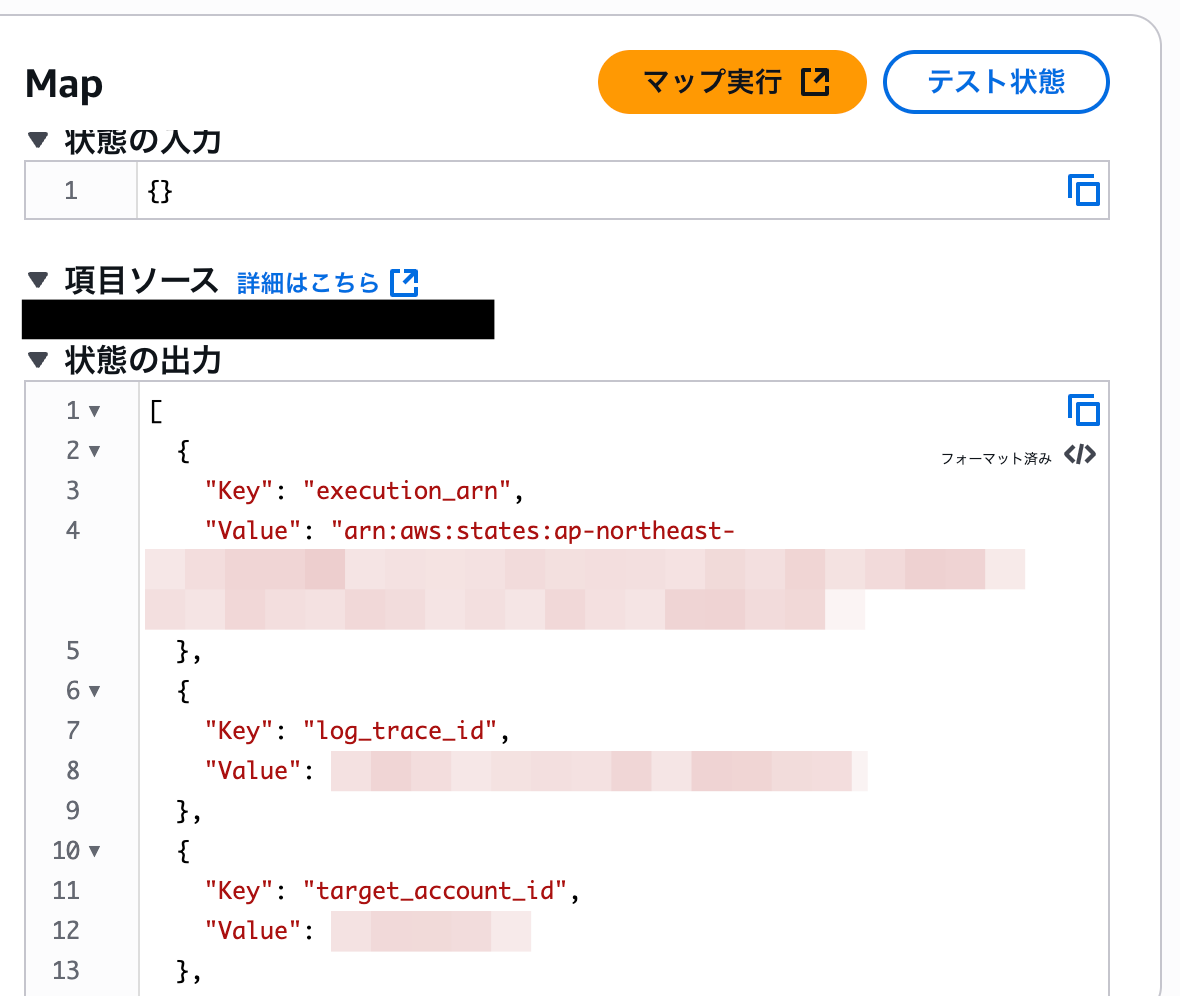
この挙動からも分かるように、指定したリストのオブジェクトの中身はすべて同じ形式である必要があるので、注意しましょう。
まとめ
AWS Step FunctionsのLOAD_AND_FLATTEN機能により、大規模データ処理ワークフローの構築が大幅に簡素化されました。従来は複雑な前処理やネストした構成が必要だった処理を、シンプルな設定で実現できるようになりました。
大規模なデータ処理やETLワークフローを構築している方は、ぜひこの新機能を試してみてください。







