
Amazon Athena Partition Projectionで設定したHive形式の日付カラムをWHERE句で使う
2022.10.18
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部 IoT事業部の若槻です。
Amazon AthenaではS3 Bucket LocationのパーティションパスをHive形式または非Hive(Non-Hive)形式のいずれでも設定可能です。
// Hive
${S3BucketLocation}/year=${year}/month=${month}/day=${day}
// Non-Hive
S3BucketLocation/${year}/${month}/${day}
これらのパーティションパス形式はいずれもPartition Projectionでも設定できます。
今回、Hive形式の日付カラムをPartition Projectionで設定する機会があったので、そのカラムをWHERE句で使う方法を確認してみました。
やってみた
環境準備
必要なリソースをAWS CDKで作成します。
lib/aws-cdk-app-stack.ts
import {
aws_athena,
aws_glue,
aws_s3,
RemovalPolicy,
Stack,
StackProps,
} from 'aws-cdk-lib';
import { Construct } from 'constructs';
import * as aws_glue_alpha from '@aws-cdk/aws-glue-alpha';
export class AwsCdkAppStack extends Stack {
constructor(scope: Construct, id: string, props?: StackProps) {
super(scope, id, props);
new aws_athena.CfnWorkGroup(this, 'workGroupV3', {
name: 'workGroupVersionSpecified',
workGroupConfiguration: {
engineVersion: {
selectedEngineVersion: 'Athena engine version 3',
},
},
});
const sourceBucket = new aws_s3.Bucket(this, 'sourcebucket', {
bucketName: '20221017-sourcebucket',
removalPolicy: RemovalPolicy.DESTROY,
});
const glueDatabase = new aws_glue_alpha.Database(this, 'glueDatabase', {
databaseName: 'gluedatabase',
});
const sourceGlueTable = new aws_glue_alpha.Table(this, 'sourceGlueTable', {
tableName: 'source_glue_table',
database: glueDatabase,
bucket: sourceBucket,
s3Prefix: 'data/',
dataFormat: aws_glue_alpha.DataFormat.JSON,
partitionKeys: [
{
name: 'year',
type: aws_glue_alpha.Schema.INTEGER,
},
{
name: 'month',
type: aws_glue_alpha.Schema.INTEGER,
},
{
name: 'day',
type: aws_glue_alpha.Schema.INTEGER,
},
],
columns: [
{
name: 'deviceId',
type: aws_glue_alpha.Schema.STRING,
},
{
name: 'maxTemperature',
type: aws_glue_alpha.Schema.FLOAT,
},
],
});
const cfnSourceGlueTable = sourceGlueTable.node
.defaultChild as aws_glue.CfnTable;
cfnSourceGlueTable.addPropertyOverride('TableInput.Parameters', {
'projection.enabled': true,
'projection.year.digits': 4,
'projection.year.interval': 1,
'projection.year.range': '2022,2030',
'projection.year.type': 'integer',
'projection.month.digits': 2,
'projection.month.interval': 1,
'projection.month.range': '1,12',
'projection.month.type': 'integer',
'projection.day.digits': 2,
'projection.day.interval': 1,
'projection.day.range': '1,31',
'projection.day.type': 'integer',
'storage.location.template':
`s3://${sourceBucket.bucketName}/data/` +
'year=${year}/month=${month}/day=${day}',
});
}
}
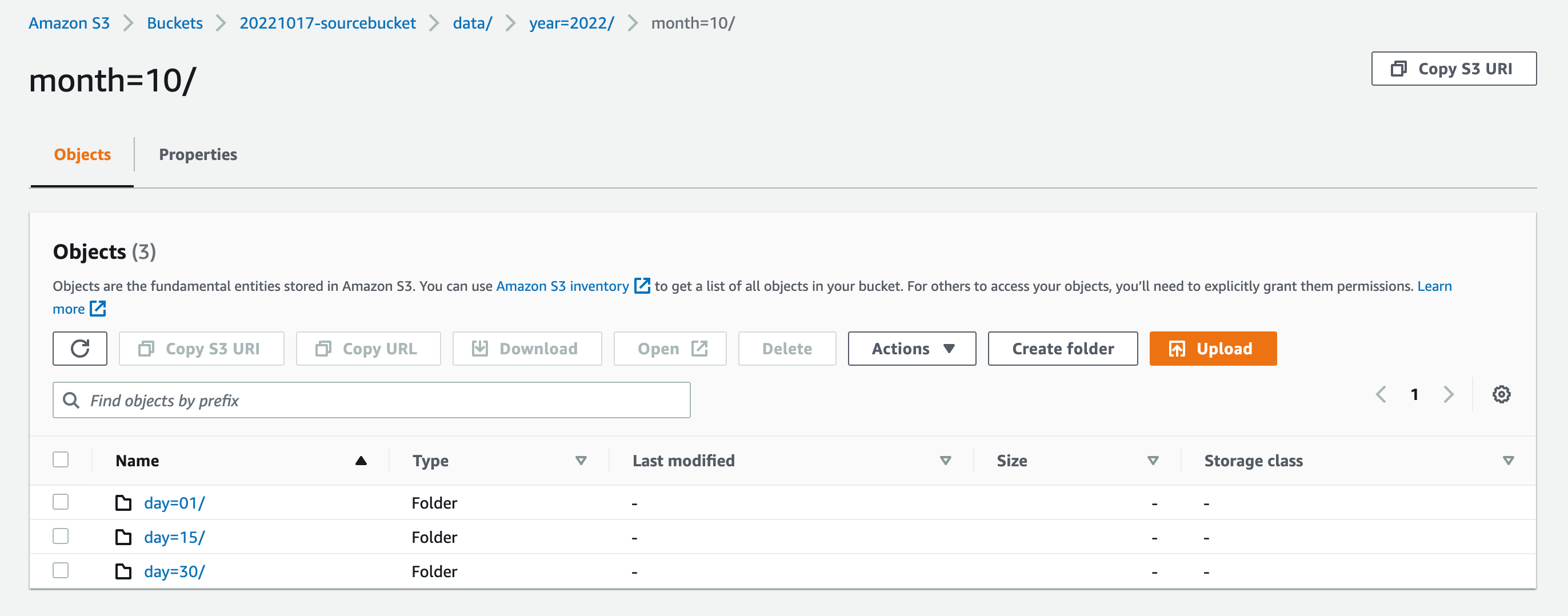
year=${year}/month=${month}/day=${day}という形式のパーティションをPartition Projection(パーティション射影)で設定しています。
バケットにデータをアップロードします。
$ cat data1.json
{"deviceId":"d001","maxTemperature":19.1}
{"deviceId":"d002","maxTemperature":22.9}
$ cat data2.json
{"deviceId":"d001","maxTemperature":22.7}
{"deviceId":"d002","maxTemperature":20.5}
$ cat data3.json
{"deviceId":"d001","maxTemperature":19.8}
{"deviceId":"d002","maxTemperature":21.0}
$ cat data4.json
{"deviceId":"d001","maxTemperature":20.1}
{"deviceId":"d002","maxTemperature":22.0}
aws s3 cp data1.json s3://${BUCKET_NAME}/data/year=2022/month=10/day=01/data1.json
aws s3 cp data2.json s3://${BUCKET_NAME}/data/year=2022/month=10/day=15/data2.json
aws s3 cp data3.json s3://${BUCKET_NAME}/data/year=2022/month=10/day=30/data3.json
aws s3 cp data3.json s3://${BUCKET_NAME}/data/year=2022/month=11/day=01/data4.json
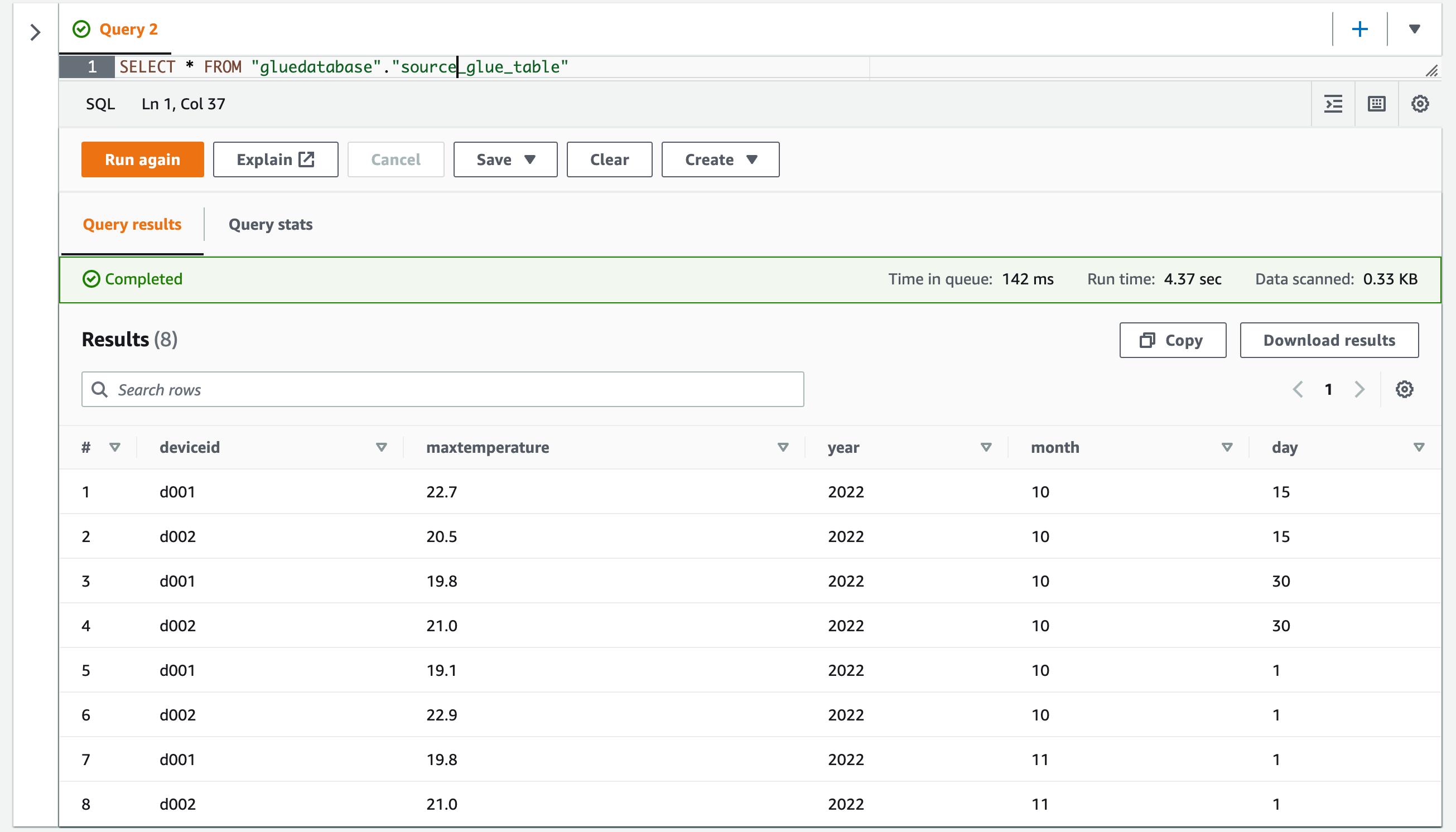
SELECTクエリを打つと問題なくデータが取得できています。
SELECT * FROM "gluedatabase"."source_glue_table"
WHERE句でフィルターしてみる
次の要領で日付形式のパーティションパスをWHERE句で使用できました。
- monthおよびdayを0埋めする
- year、monthおよびdayを文字列連結し、数値型にキャストする
- この値をWHERE句で使用する
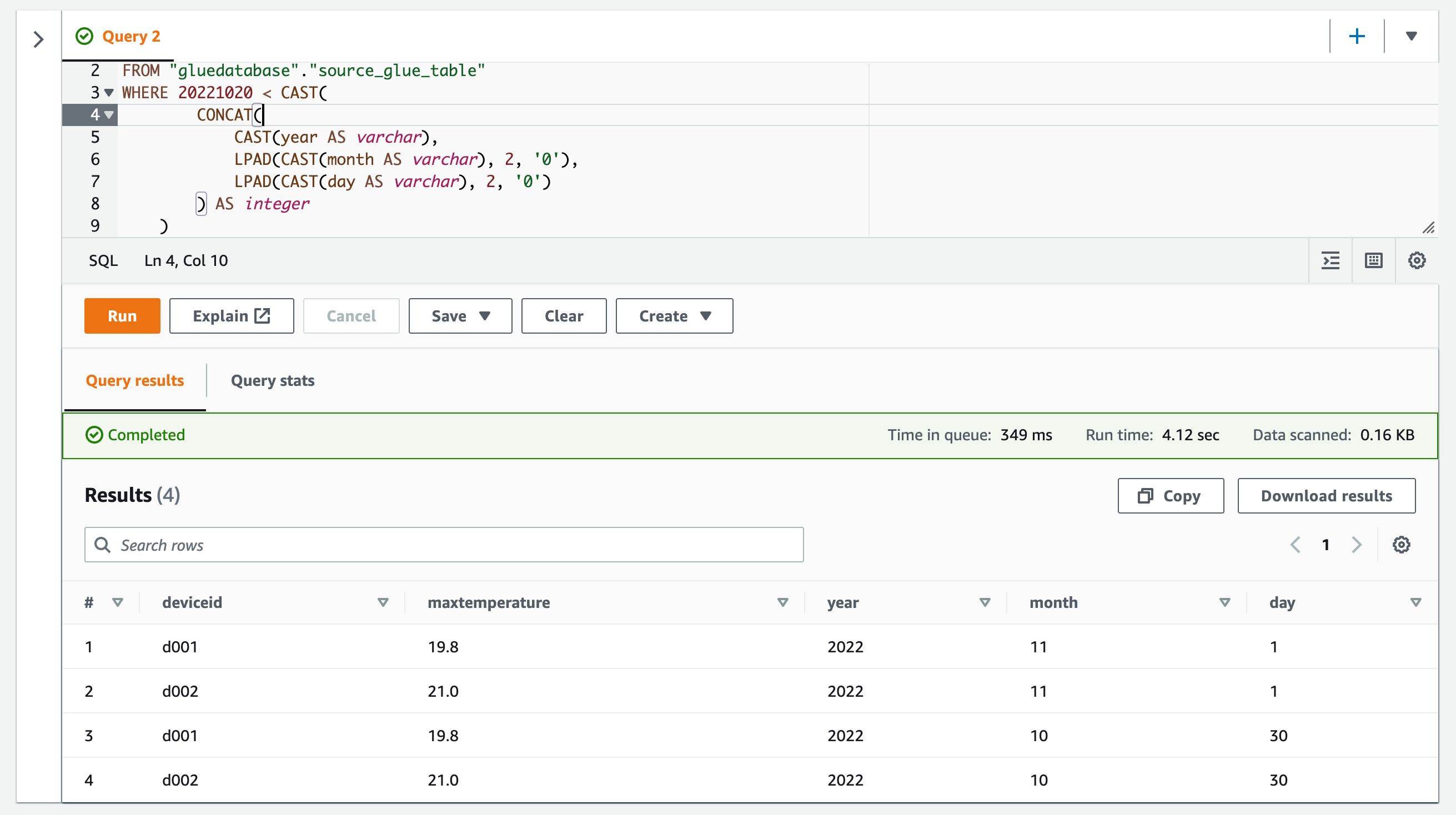
year,month,dayでフィルターする
不等号(<)でフィルターする。
SELECT *
FROM "gluedatabase"."source_glue_table"
WHERE 20221020 < CAST(
CONCAT(
CAST(year AS varchar),
LPAD(CAST(month AS varchar), 2, '0'),
LPAD(CAST(day AS varchar), 2, '0')
) AS integer
)
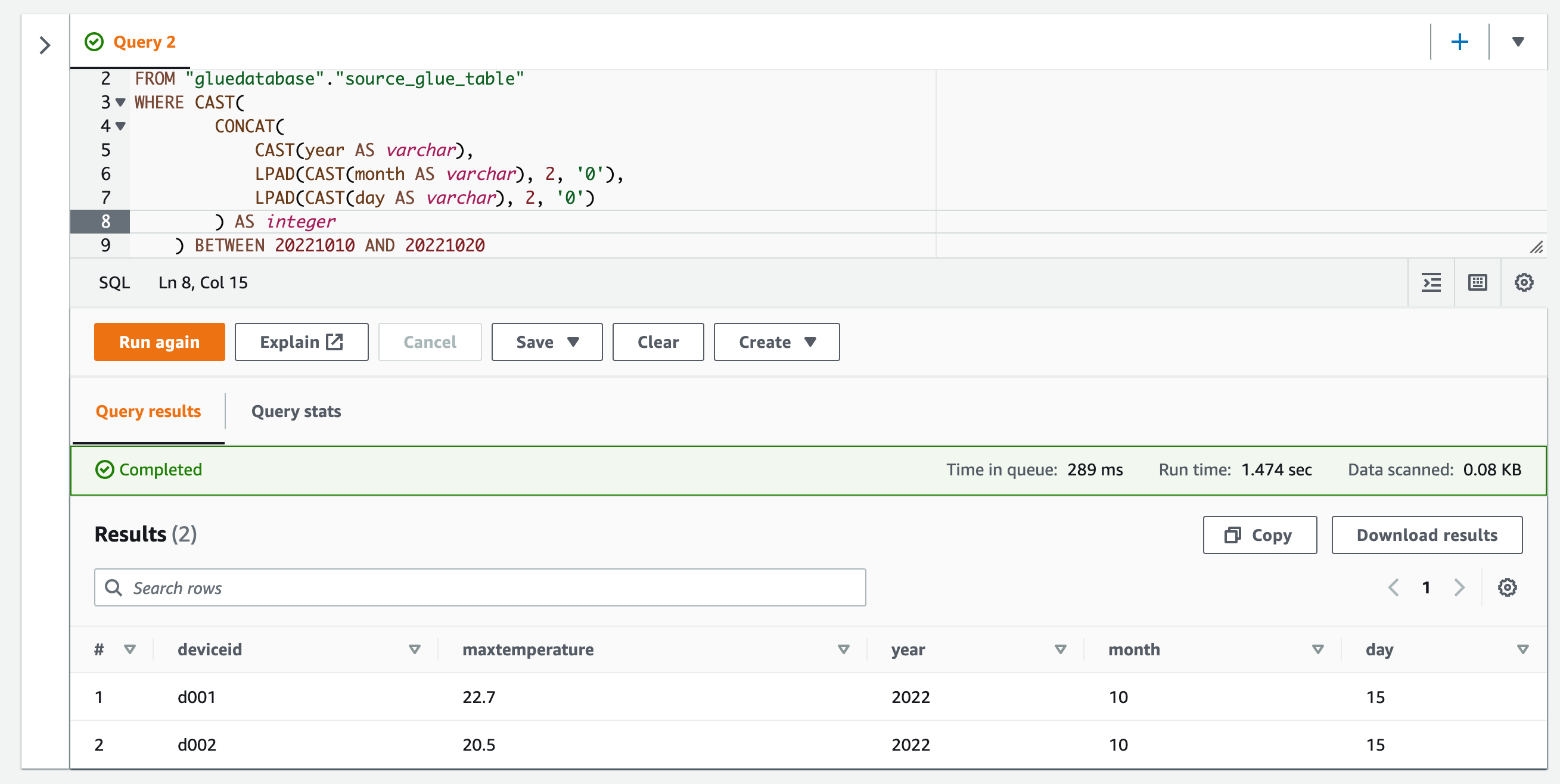
BETWEEN句を組み合わせてフィルターする。
SELECT *
FROM "gluedatabase"."source_glue_table"
WHERE CAST(
CONCAT(
CAST(year AS varchar),
LPAD(CAST(month AS varchar), 2, '0'),
LPAD(CAST(day AS varchar), 2, '0')
) AS integer
) BETWEEN 20221010 AND 20221020
yearおよびmonthでフィルターする
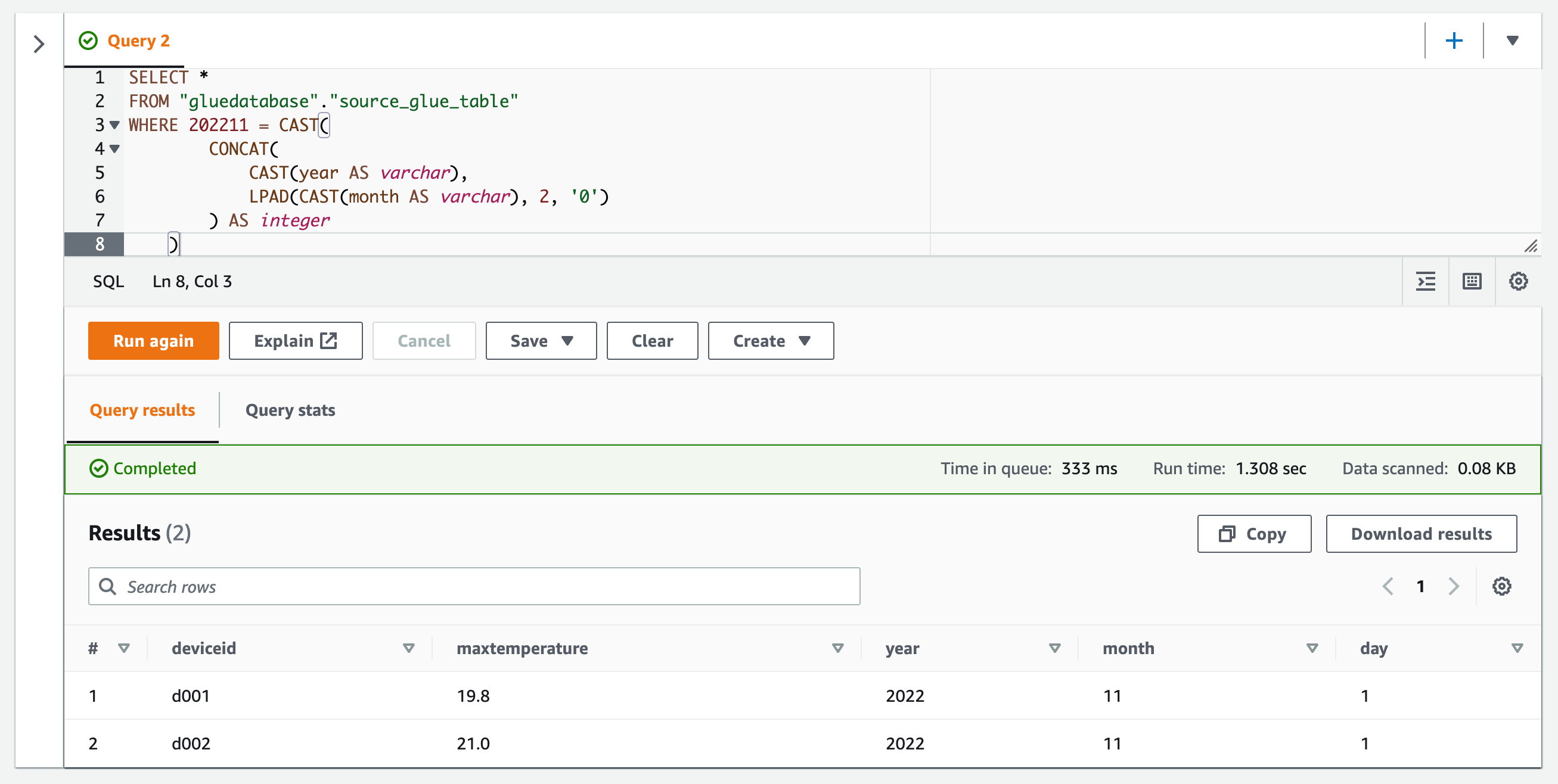
等号(=)でフィルターする。
SELECT *
FROM "gluedatabase"."source_glue_table"
WHERE 202211 = CAST(
CONCAT(
CAST(year AS varchar),
LPAD(CAST(month AS varchar), 2, '0')
) AS integer
)
おわりに
Amazon Athena Partition Projectionで設定したHive形式の日付カラムをWHERE句で使ってみました。
今までHive標準な形式の実装はほとんどしてこなかったのですが、同じデータソースにGlue Jobによるアクセスがある構成の場合はHive標準とする必要があるケースがあるため、今回方法を確認できて良かったです。
参考
以上








