生成AIでメンバー育成を『見える化』してみた -- コンテキストエンジニアリングとしてのデータ前処理とエージェント活用
はじめに
クラスメソッドオペレーションズの かねこ です。
テクニカルサポートにおいて、新卒・中途メンバーの初期配属先であるチームのリーダーを務めています。
お問い合わせ対応の OJT を通じて、育成担当者(トレーナー)と共にメンバーを育成し、各専門チームへ配属するまでを支援する役割です。
リモートワーク中心の環境では、メンバーの育成状況が見えにくいという課題がありました。この記事では、散在するデータを Amazon Bedrock で収集・構造化し、業務固有のコンテキストを添えて分析することで、育成状況の見える化に取り組んだ話をご紹介します。
「AI エージェント」と聞くと、チャットで対話する AI アシスタントを想像される方が多いかもしれません。
今回紹介するのも対話型のアシスタントは含みますが、それだけでなく AI アシスタントが参照するデータを体系的に整理・構造化する前処理工程も含めた、一連のソリューションとしての取り組みになります。
そして、記事を通じて特にお伝えしたいのは、生成 AI に渡す「コンテキスト」の整備が大切だということです。
ここでいうコンテキストとは、メンバーの在籍期間や成長段階、業務の性質、過去の育成経緯など、生データだけでは伝わらない「前提」を生成 AI のプロンプトに組み込むための情報を指します。この整備に手をかけたことで、実際の業務で活用できるレベルの分析が得られるようになりましたので、その試行錯誤を含めて共有できればと思います。
なお、大前提として、メンバーの成長に向き合い、対話し、伴走するのはリーダーやトレーナーの責務であり、そこを生成 AI に代替させるつもりはありません。今回の取り組みはあくまで「情報を集めて整理する」部分を自動化し、私たちが判断や対話に集中できる時間を作るためのものです。この前提は、今後も変わらないということを念頭に置いた上で、以下の内容を読み進めていただければ幸いです。
育成で感じた課題
私のチームではリモートワーク中心で業務を進めています。メンバーがお客様からのお問い合わせ(チケット)の対応を学び、トレーナーが Slack 上で回答案をレビューし、リーダーである私が週次の 1on1 で伴走する形で育成を進めています。
このリモートワーク環境下での育成において、以下の課題を感じていました。
| 課題 | 説明 |
|---|---|
| 成果物の散在 | メンバーの育成状況に関する情報は、Slack でのトレーナーとのやり取り、Google Docs や Sheets での議事録やパフォーマンスデータ、Meet の議事録等に分散していました。横断的に把握するには都度それぞれを開いて確認する必要があり、認知的な負荷が高い状態でした。 |
| 状況把握の属人化 | リーダーは週次 1on1 の準備にメンバー 1 人あたり 15〜30 分を要していました。トレーナーも自身が対応したレビュー以外のメンバー状況を把握しにくく、課題の検知が遅れたり、チーム内での共有の粒度にばらつきが生じていました。 |
| 増員に対するスケーラビリティ | メンバー・トレーナー双方の増員が見込まれる中、手作業ベースの情報収集・共有では対応が困難になりつつありました。今のやり方ではリーダーがボトルネックになってしまい、一人ひとりに十分な時間を確保できなくなる危機感がありました |
生成 AI パイプラインを作ることにした経緯
こうした課題を解決するには、散在する情報を一箇所に集め、育成の文脈を踏まえて分析し、リーダーやトレーナーが素早く参照できる仕組みが必要でした。
しかし、ChatGPT や Claude 等の一般的なモデルに都度質問する方法では、複数ツールに散在するデータを横断的に蓄積・分析することはできません。仮に、同様のことを手動で実現しようと思うと、非常に凝ったプロンプトを都度手動で作成する必要があります。
都度必要なタイミングでそれを行うことは、生成 AI を利用して得られる以上の負担が掛かります。(それでも、このツールを作るまでは頑張ってコンテキストを手でまとめていました⋯)
そこで、散在する成果物を自動で収集し、業務ドメイン固有のコンテキストを整備して生成 AI に渡す多段データパイプラインを構築するアプローチを取りました。
システムは以下の 4 つの構成要素からなります。以降のセクションで、それぞれの詳細を順に説明していきます。
| 要素 | 説明 |
|---|---|
| 1. データ収集パイプライン | 各ツールからメンバーの成果物を日次で自動収集し、S3 データレイクに集約・蓄積 |
| 2. 分析パイプライン | Amazon Bedrock (Claude モデル) で非構造化データを構造化し、複数の観点から分析を実施(詳細は後述) |
| 3. ダッシュボード | Streamlit によるダッシュボードで分析結果を可視化 |
| 4. AI エージェント | Bedrock AgentCore 上の AI エージェントが対話形式でメンバー状況のブリーフィングや質問応答を提供 |
<データパイプライン構成図>
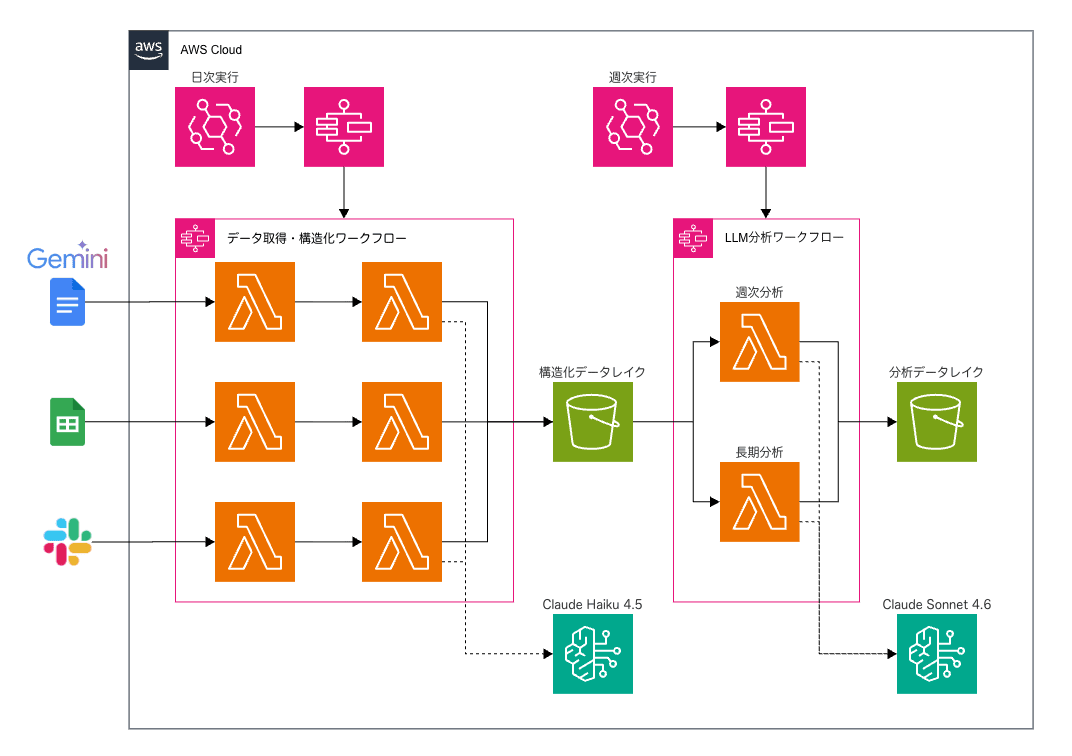
※ AI エージェント側の構成図は後述に添付しています。
データの収集と構造化
ここからは、4 つの構成要素のうち「データ収集パイプライン」と「分析パイプライン」の詳細を説明します。
データの集め方と前処理
以下のデータソースから日次バッチで差分取得し、S3 データレイクに集約しています。
- Slack: トレーナーとのやり取りに関するデータ
- Google Docs: 各種会議メモや振り返り資料 等
- Google Sheets: 対応実績や育成の進捗に関するデータ 等
集めたデータはそのままでは形式がバラバラなので、後続の分析に渡せるよう JSON 形式に変換(構造化)する必要があります。正規表現やスクレイピングですべてを処理しきるのは非効率的なので、LLM に任せると手軽にできます。
ただし、全てのデータを LLM で構造化するのではなく、Google Sheets 等の表形式で構造化できるデータや、計算・集約・突合等の機械的な処理が必要な箇所は、LLM を介さずに直接プログラムでパースしています。一方で、Google Docs に保存されているような自然言語のテキスト(振り返り資料、会議メモ等)は、構造が不定なので LLM の方が構造化に適しています。この使い分けが地味にコストと精度の両立に効いてきます。また、毎回全データを取り直すのではなく、SSM Parameter Store に保存した前回取得タイムスタンプを参照し、新規・更新分のみを取得しています。これを Step Functions でメンバーごとに並列処理を行い、日次でバッチ処理するようにしています。
パイプラインの段階分けとそのメリット
パイプラインは大きく 3 段階に分けました。
- データの取得: 各データソースから生データを差分取得し、S3 に保存(日次)
- データの構造化: 自然言語テキストを Claude Haiku 4.5 で JSON 形式に変換(日次)。表形式データは LLM を介さずに直接パース
- データの分析: 構造化済みデータにコンテキストを付与し、Claude Sonnet 4.6 でプロンプトに基づき定量的にスコアリング、定性的な分析を実施(週次)
生データの収集からスコアリングまでを一度に LLM に渡すこともできなくもないですが、コンテキストウィンドウを圧迫してプロンプトの指示に従いにくくなることで、生成される評価結果の品質が悪化する懸念があります。そのため、生成 AI アプリケーションのベストプラクティス[1]に従って、あえて構造化と分析を分離する構成としました。
- トークン効率: 構造化済みの JSON は、分析上不要な記号や単語を含まないので、生のテキストよりサイズが小さく、少ないサイズでより多くの情報を保存できる
- 横断的な評価: 日付や ID をキーに構造化データを蓄積することで、業務上の各種データを、メンバー×週で突き合わせて横断的に分析できる
- AI エージェントでの再利用: 構造化データが整理された形で残るため、ダッシュボード表示や AI エージェントのツールにそのまま活用可能
- モデルの使い分け: 構造化は軽量・高速な Haiku モデル、分析は推論力の高い Sonnet モデルと、処理の性質に応じてモデルを選択できる (実際は後者のインプットトークン量が大きいので、あまりコスト減にはなっていませんが⋯)
生成 AI に渡すコンテキストの整備と分析
コンテキストの整備
パイプラインの構成自体は前節で説明した通りですが、最初に組んだ時点のプロンプトでは分析内容の生成品質がとても低く、少なくとも業務でそのまま使えるものではありませんでした。例えば「メンバーの対応件数が少ないので、どうアドバイスすればよいか」と聞いても、返ってくるのは「ハンズオンを増やしましょう」「テンプレートを整備しましょう」といった、どの組織にも当てはまるような大味な提案ばかり。「うちのチームはそうじゃないんだよな⋯」というものでした。
そもそも同じ「今週の対応件数が少なかった」というデータでも、難易度の高いお問い合わせにじっくり取り組んでいた結果なのか、次に何を着手するか決めきれずに時間が過ぎてしまったのかでは、意味合いが全く異なります。しかし件数だけを渡しても、その背景までは読み取ってもらえません。組織の育成方針やチームの業務フロー、メンバーの現在地といったコンテキストを都度手で流し込まないと、業務で使えるレベルの生成品質にはならないということを痛感しました。
そこから、リーダーやトレーナーのフィードバックをプロンプトに織り込みながら、生成 AI に渡すコンテキストを丁寧に整備する、いわゆる「コンテキストエンジニアリング」[2]に注力するようになりました。分析プロンプトに組み込むコンテキストを、以下の 3 層に分けて整備しています。
メンバー情報のコンテキスト
- 在籍期間からのステージ判定: 在籍期間に応じていくつかのステージを設け、ステージごとに評価の目線を変えている
- メンバー種別: 新卒と中途で成長タイムラインを調整(中途メンバーは業務経験があるため、新卒に比べある程度短い期間で同等ステージへの到達を期待する 等)
- 配属目標日: 逆算で、一人ひとりに合わせた対応の判断に使用
業務のコンテキスト
次にあげるような、過去の育成状況からリーダーやトレーナーが感じた肌感覚をプロンプトとして落とし込みました。
- 問い合わせの定型/非定型分類: 手順書で対応可能な定型と、環境調査やログ等の調査や技術的判断が必要な非定型を LLM が分類
- 対応 AWS サービスの多様性: 特定分野のサービスに偏っていないかの指標
- レビューのやり取りの密度: トレーナーとのやり取りの密度を段階的に把握
- フィードバック内容の分類: 対応方針に関する指摘か、表現など形式面の指摘かを区分。前者の方が、考え方から認識合わせやアドバイスを行う必要のあるフィードバックである傾向にある
育成のコンテキスト
- 育成マイルストーン進捗: 前述の習熟度チェックリストのレベルごとの完了率
- 過去のフィードバック傾向: 繰り返し指摘されている項目のパターン
- 前週の分析結果: 直前週のスコアと変化の傾向を参照し、推移を把握
- ローリングサマリー: 過去の長期分析を 2-3 文に圧縮した要約。トークン効率を保ちながら長期コンテキストを継続する工夫
コンテキストなし vs ありの出力比較
ここでは、コンテキスト整備の効果をイメージしやすいように、複数のデータを組み合わせて作った架空のサンプルで比較します。私が生成 AI に対して、「あるメンバーのお問い合わせ対応に時間がかかっているので、アドバイスの例を提示してほしい」と指示を出したものとします。これに対して、コンテキストを共有していない生成 AI と本システムとで、回答にどのような差が出るかを示します。
コンテキストなしの場合 (素の LLM に質問):
「技術知識のギャップ?」「調査方法の問題?」「文章作成?」「優先度判断?」と汎用的な確認ポイントを並べ、アドバイスも「ハンズオンを実施」「テンプレートを整備」「タイムボックスを設ける」等の一般論にとどまります。
最後に「特定の状況があればさらに具体的なアドバイスもできます」
→ つまり、コンテキストが足りていないことを生成 AI 自身が示唆している
コンテキストありの場合 (本システムの AI エージェント):
対応実績データから「目標に対してペースが不足している」と定量的に現状を把握。振り返りデータから「調査に時間をかけすぎる傾向がある」という行動面の課題を特定。
さらに過去の好調だった週のデータと比較して「あの週と今で何が違ったか」を具体的な改善アプローチとして提案します。
→ 単にデータを並べるだけでなく、複数のデータソースを横断して課題の構造を読み解いた助言を提供できている
以上のように、十分な事実に基づくデータをコンテキストとして生成 AI に提供したことで、より具体性、実効性のあるアドバイスが生成できることを確認できました。
スコアリングとプロンプト設計
コンテキストを整備してデータの意味が伝わるようになっても、評価の軸がなければ生成の度に結果がブレてしまいます。とはいえ、育成の状況は多次元的で、どれか一つの指標で定量・定性的に評価することは困難です。
そこで、パイプラインの実装に入る前に、まず評価の枠組みづくりから始めました。Claude Code と「育成のゴールって何だろう」「これまで早く成長できたメンバーにはどんな共通点があったか」を壁打ちし、実際の育成データも読ませながら、リーダーやトレーナーが無意識に重視していた観点を言語化・分解していきました。
その結果たどり着いた 5 つの軸を、パイプラインの初期実装の時点からそのまま組み込んでいます。枠組み自体は今も変わっていませんが、各軸の 1〜5 点のスコアリング基準はその後の運用を通じてかなり手を入れました。
- 技術領域の広がり: 慣れた対応にとどまらず、未知の技術領域にも踏み出せているか
- 対応の安定性: ステージに見合ったペースで安定的に対応できているか
- 自律性: トレーナーの指導なしに、方針を立案・実行できているか
- 課題認識: 自身の課題を認識し、改善行動に移せているか
- レビュー依頼の質: トレーナーへのレビュー依頼時の情報整理度・顧客課題の理解度
最も抽象的な指標である「自律性」を例に紹介します。レビューのやり取りの密度と、フィードバック内容が方針に関する指摘か形式面の指摘かを組み合わせて評価しています。特定の条件が複数週にわたって継続した場合に、対応の方向性を検討するきっかけになるようにしています。
なお、これらのスコアはあくまでリーダー・トレーナーの判断材料であり、メンバーの人事評価に直結するものではありません。
このスコアリングの精度を保つために、プロンプト側でもいくつか工夫しています[3]。
- 評価基準表の埋め込み: 各スコア軸について 1〜5 点の判定基準をプロンプト内に明記し、LLM が生成の都度判定がぶれることを抑制
- エビデンス必須化: 全スコアに対してデータ根拠と信頼度 (0〜1) の明記を要求し、根拠のないスコアリングを抑止する。Bedrock モデル呼び出しログから、事後的に根拠を追跡できるように実装
- ステージに応じた期待値の調整: 在籍期間や成長段階に応じて評価の目線を変え、同じ物差しで一律に評価しないようにする仕組み
- 構造化出力 (JSON Schema)[4]: LLM の出力を JSON Schema で厳密に定義し、後続処理の安定性を確保
ダッシュボードと AI エージェント
ダッシュボード
パイプラインの分析結果を、Streamlit ベースの Web ダッシュボードで可視化しています。現時点ではリーダーとトレーナーが閲覧する管理画面として運用しています。スコアの安定性や見せ方の工夫がまだ途上のため、メンバー本人への公開は段階的に進めていく予定です。
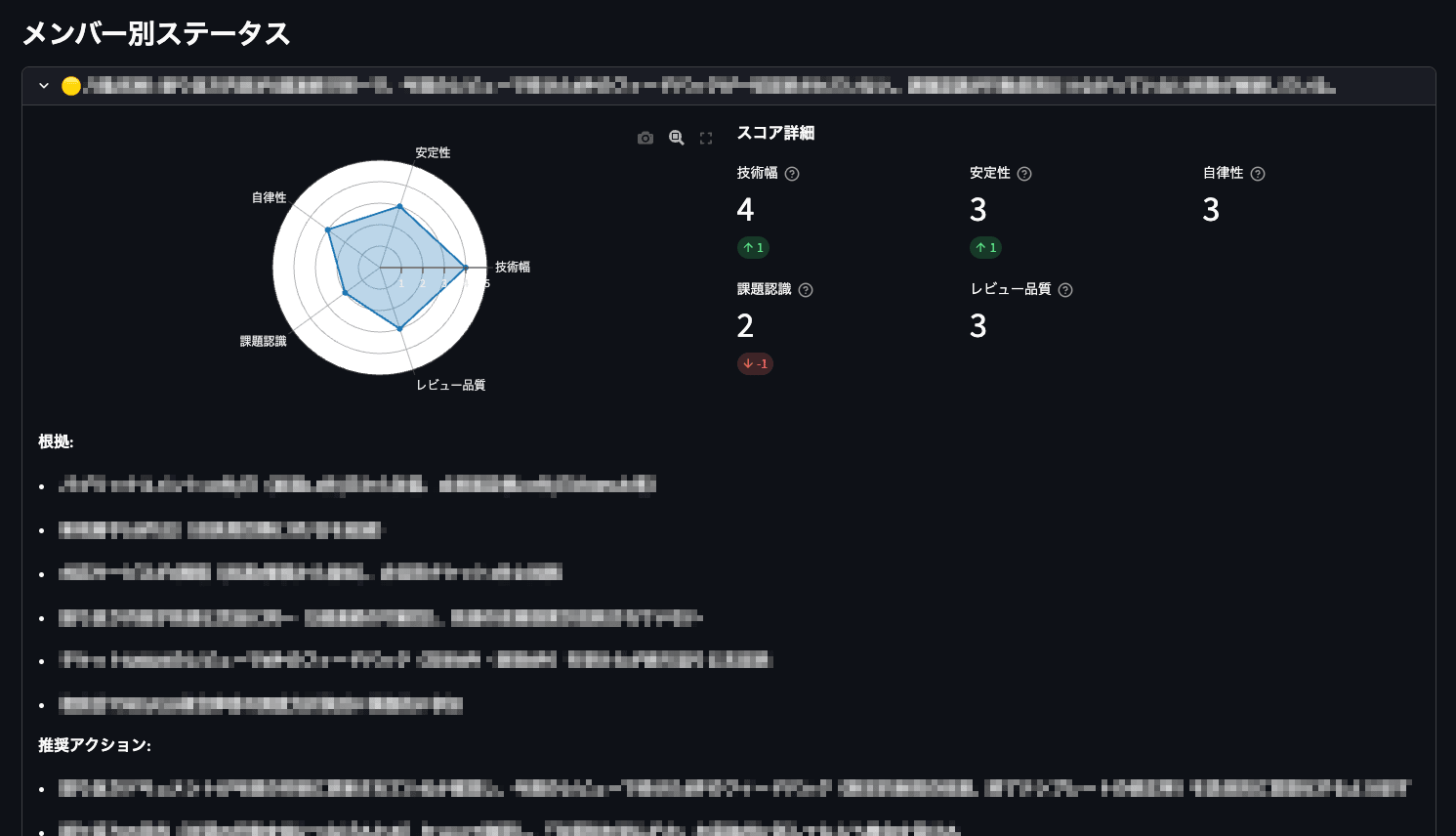
ダッシュボードは大きく「AI 分析ページ群」と「元データページ群」の 2 層で構成しています。
AI 分析ページには、全メンバーの状況サマリー(トップページ)、レーダーチャートやエビデンス付きスコア(メンバー詳細)、スコアの折れ線グラフ(推移分析)、マイルストーンの進捗率と配属目標日に対する進捗(配属までの進捗)を配置しています。
一方で、AI 分析結果だけでなく、分析の元になった各データソースの内容をそのまま確認できるページも用意しています。
AI の分析結果に疑問を感じたときに、ダッシュボードの元データページからワンクリックで根拠となる資料に遡れるようにしています。
また、問い合わせ対応のライフサイクル分析では、対応の各フェーズにかかる時間をフェーズ別に分離して可視化しており、育成プロセス全体のボトルネック特定にも活用しています。
AI エージェント
パイプラインが裏側で自動分析した結果を、対話形式で引き出せる AI エージェントも構築しました。Bedrock AgentCore Runtime 上で Strands Agent として動作し、Bedrock AgentCore Memory でセッションを永続化しています。
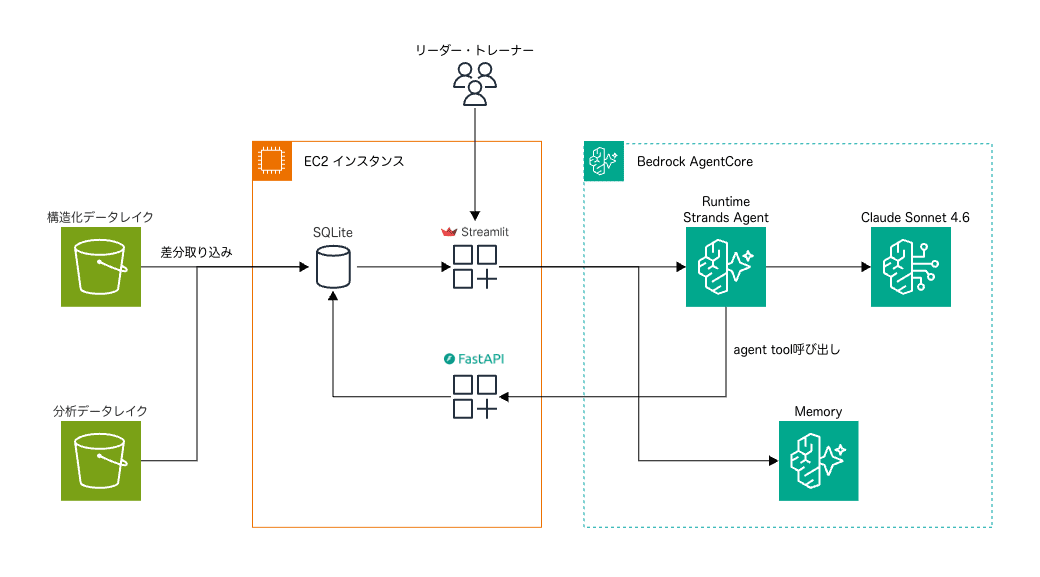
エージェントは FastAPI 経由で以下の 8 つのツールを呼び出し、データを取得して回答を生成します。
| ツール名 | 役割 |
|---|---|
get_member_list |
メンバー一覧の取得 |
get_member_analysis |
最新の短期/長期分析結果 |
get_analysis_history |
スコア推移(過去 4 週) |
get_slack_reviews |
レビュー関連データ |
get_ticket_performance |
対応実績データ |
get_milestone_progress |
育成進捗データ |
get_weekly_reflection |
振り返りデータ |
get_alert_history |
状況変化の履歴 |
「メンバー A との 1on1 が予定されています。今週話すべきことをブリーフィングしてください」と依頼すると、チケット実績・レビュー状況・スコア推移・検出された課題を統合した報告を生成します。メンバーごとの状況に応じて、具体的なデータに基づいた改善アドバイスの優先順位まで提示してくれます。
効果
定量効果
| 指標 | Before | After | 効果 |
|---|---|---|---|
| 1on1 準備時間(リーダー・サブリーダー計 2 名) | 平均約 20 分/人 × 2 名 | 平均約 8 分/人 × 2 名 | 約 60%短縮(週あたり計約 120 分削減) |
| メンバー状況把握のタイミング | 週次 1on1 時点 | 日次〜週次で随時 | リアルタイム化 |
| 情報参照の導線 | Slack ・ Docs ・ Sheets 等を個別に確認 | ダッシュボード 1 画面で一元参照 | 認知負荷の大幅軽減 |
| トレーナー間の情報共有 | 週次定例での口頭共有 | ダッシュボードで随時参照 | 属人化解消 |
定性効果(育成の質の改善)
- 複数ツールに散在していた情報がダッシュボードに集約され、概要(状況サマリー)から詳細(エビデンス付きスコア・各種履歴データ)まで、一画面で過不足なく把握できる状態になったこと。
- これまでチケット件数のような定量データでしか確認できなかったところを、対応内容の質や挑戦の幅まで追跡できるようになったこと。
- 実際に、新しい領域へのチャレンジのペースが変わっているメンバーに早期に気づき、トレーナーと相談して取り組み方のサポートに動けたケースがありました
- 育成の「量」だけでなく質的な変化が見えるようになった点が、個人的には一番大きな収穫だと感じています
- リーダー・トレーナー間の情報共有が、各自の感覚ベースから実際のデータを見ながらの議論に変わったこと。
- これまではリーダー定例の場で口頭で状況を聞くしかなかったメンバーの状況を、ダッシュボードでいつでも早期に確認できるようになったことも大きいです
- 分析結果とデータソースへのリンクがセットで表示されるので、「根拠がある」という安心感を持って分析を参照できるという声もトレーナーからもらっています
開発の振り返りと今後
開発体験
仕組みを作る以前に、組織情報・育成モデル・業務フローといったコンテキストの素材を整理し、生成 AI と壁打ちしながら要件定義やプロンプト設計を行う工程に相応の時間をかけました。振り返ると、この設計段階での整理が結果的にシステム全体の精度を左右していたように思います。
実装には Claude Code(Max プラン / Opus モデル)を活用し、パイプライン部分が約 2 週間、ダッシュボードとエージェントがそれぞれ約 1 週間で構築できました。開発に割ける時間が限られている中でも、Claude Code のおかげでこの規模のシステムを約 1 ヶ月で形にできました。
精度を保つための工夫
同一入力でも LLM の判定にはある程度のブレが存在します。温度パラメータを 0.0 に設定したり、プロンプトになるべく具体例を含む詳細な評価基準表を組み込んだり、生成時に参照したエビデンスを記載することを必須化とするようにして、このブレをある程度は抑制していますが、生成 AI の仕組み上、完全な再現性は保証できません。
そのため、LLM の呼び出し元プログラムで Pydantic による検証を挟み、スコア範囲や必須フィールドの存在といった構造的な不変条件をガードレールとして設けることとしました。また、週のチケット対応件数が少ない場合等、判定に十分なデータが揃わないケースではスコアの確度が下がるため、判定を控えめにする処理を入れています。
もともと私の「勘所」を 5 軸に分解したものなので、毎週の分析結果を自分で確認して「この評価はズレている」と感じたらプロンプトにフィードバックするサイクルで改善を続けています。Bedrock Prompt Management により、プロンプトの更新に Lambda の再デプロイが不要な点が、この改善サイクルの速度に貢献しています。
技術スタックとコスト
主要な技術選定とその理由をまとめます。
- AWS CDK (Python): インフラのコード管理(IaC)。環境の再現・横展開を容易にするために採用
- Bedrock Prompt Management: プロンプトのバージョン管理。Lambda の再デプロイなしにプロンプトの更新・調整が可能で、評価基準の改善サイクルを高速に回せる
- EC2 + Streamlit / FastAPI / SQLite: ダッシュボード。社内利用ツールなので、維持コストは極限まで安くおさえたかったので最小構成で構築
ランニングコストは、Bedrock 推論トークン料金が月 $40 程度(構造化の Haiku は数ドル、大部分は Sonnet による分析処理)、インフラ維持費が月 $5 以下(EC2 + S3 + Lambda 等その他もろもろ)です。
数名規模のチームであれば、運用コストとしては十分に許容範囲になっているかなと思います。
(蛇足ですが、開発中に使っている Claude Max プランが月 $100 でダントツに一番重たい運用コストになっています)
今後の展望
- 配属見通しの予測: 運用を継続するほど分析データが蓄積されるため、過去の育成データに基づいた配属時期の見通し精緻化に活用したいと考えています (もちろん外的環境の変化も取り入れて考える必要がありますが)
- ケーススタディ抽出: 類似の課題を抱えたメンバーの成功事例を蓄積データから抽出し、育成アドバイスの質を高めていきたいと考えています
- フィードバックループの仕組み化: リーダーやトレーナーが生成 AI の分析結果に対してフィードバックし、それを推論に再帰的に取り込む仕組みの構築を検討しています
おわりに
長文をお読みいただきありがとうございます。
フルリモート環境では対面に比べてメンバーの状況が見えにくくなりがちですが、散在するデータを集めてコンテキストを整備し、生成 AI に渡すことで、育成の状況を一定の解像度で見える化できるようになりました。
今回の取り組みを通じて実感したことを 2 つお伝えします。
1 つ目は、AI は育成を代替しない、育成を支援するということです。
AI がデータの収集・整理・分析を担い、人間(リーダー・トレーナー)は判断・対話・関係構築に集中する、この役割分担が機能したことで、育成の質を落とさずに効率化を実現できたと感じています。重要なことなので繰り返しますが、このシステムはあくまで私たちの判断を支援する補助ツールであり、スコアがメンバーの評価に直結するものではありません。チーム内でも「最終的な判断は人間が行う」という方針を共有しています。「はじめに」でも触れましたが、生成 AI が人を評価するのではなく、人が人を理解するための材料を整理する。この線引きは今後も意識的に保っていきます。
2 つ目は、今回のアプローチが育成以外の場面でも参考になるかもしれない、ということです。「業務の中に散在している情報を集めて、そのドメイン固有のコンテキストを添えて生成 AI に渡す」という進め方自体は、育成に限った話ではないと考えています。手作業で追いきれないけれど横断的に分析できたら価値が出そうなデータがあれば、コンテキストをどう整備するかに注力することで、似たようなアプローチが取れるのではないかと思います。
もし同じような課題を感じている方がいらっしゃいましたら、まずは「構造化」だけでも始めてみることをおすすめします。Slack のスレッドや Google Drive 上の議事録を JSON 形式に変換するだけでも、後からデータ基盤として活用できるようになります。
今後は、トレーナーや各メンバーのフィードバックを取り入れながら、より育成を支援してくれるシステムに育てていきたいと思います。
参考ドキュメント
Data architecture - Generative AI Lens | AWS Well-Architected Framework (英語)
冒頭の "Strategic imperatives" にある "Data quality as a foundation" セクションで、"High quality, well-structured data is the bedrock of effective generative AI" と述べられており、非構造化データを構造化・品質管理した上で AI に渡すことの重要性が整理されています。 ↩︎Effective context engineering for AI agents | Anthropic (英語)
"The anatomy of effective context" セクションで、"good context engineering means finding the smallest possible set of high-signal tokens that maximize the likelihood of some desired outcome" と、渡すコンテキストを最小限かつ高品質に絞り込むことの重要性が述べられています。本記事でのコンテキスト 3 層設計はこの考え方に基づいています。 ↩︎Prompting best practices | Claude Docs (英語)
"Add context to improve performance" セクションで、指示の背景や動機をプロンプトに含めると精度が向上することが述べられています。また "Migrating away from prefilled responses" 内で Structured Outputs(構造化出力)による出力制御にも言及があり、本記事での評価基準表の埋め込みや JSON Schema による出力定義はこれらの考え方を取り入れています。 ↩︎Get validated JSON results from models - Amazon Bedrock (英語)
Amazon Bedrock の Structured Outputs 機能のドキュメントです。 ↩︎








