
正しい証拠があってもRAGが誤答するのはなぜか 〜モデル内部を帰属グラフで分析した論文を読む〜
はじめに
RAG(Retrieval-Augmented Generation)は、LLMの回答生成を外部のドキュメント検索と組み合わせる手法です。GPTなどのLLMが登場してすぐに浮き上がった「学習データ以外の情報を参照できない」「社内ドキュメントに答えられない」という課題に対して、2020年前後から実用化が進んできました。現在では社内QA、カスタマーサポート、医療・法律など幅広い場面で使われています。
実運用に乗せていくうちに、精度を上げるためのノウハウも蓄積されてきました。チャンクの粒度の工夫、埋め込みモデルの選択、Rerankerの導入……改善の引き出しはたくさんあります。それでも「検索ログには正しいドキュメントが取得できているのに答えがおかしい」という誤答が残ることがあり、このタイプは原因を特定しにくく時間を浪費しがちです。
Kai Guo らは 「Why Retrieval-Augmented Generation Fails: A Graph Perspective」(2026年5月、arxiv: 2605.14192)にて、Circuit Tracingで帰属グラフを構築すると、モデルが正答を出すときと誤答を出すときで内部の情報経路が明確に異なることを報告しました。
arxivなので未査読プレプリントではありますが、読む価値があると感じましたので紹介します。
結論から先に
この論文が何を言っているか、先に整理しておくと
RAGが失敗するとき、モデルは質問を深く理解できていない。
ということです。
失敗ケースでは「質問の意味を十分に処理する前に、取得したドキュメントの表面的な一致に飛びついてしまう」という現象が起きていました。正答ケースでは逆に、質問の内容が最後まで推論を制約し続けていたようです。
この違いが、帰属グラフ(Attribution Graph)の構造として可視化できたというのが論文の結論になります。さらに、この構造的な差異を使って「これは間違えそうな回答だ」と事前検出したり、Attentionの重みを直接調整して精度を上げる手法も提案していました。
検索結果は正しくても誤答する、とはどういうことか
たとえばこういう状況です。
「Aという法律が成立した年に、Bという組織の代表を務めていた人物は誰か?」
RAGで検索すると、「Aという法律が成立した年」を説明するドキュメントと、「Bという組織の歴代代表」を列挙するドキュメントが両方取得できました。一見、正しい回答が生成されるように思われます。
しかし、RAGモデルは「Bという組織の代表」だけに反応して、年の条件を無視した人物を答えてしまうことがあります。取得した証拠は正しくても、複数の条件を組み合わせて推論するプロセスで崩れる。これが多段推論(Multi-hop QA)で起きがちな失敗パターンです。
論文ではHotpotQA、2WikiMultihopQA、MuSiQueという3つの多段推論データセットでこのパターンを分析していました。
前提知識:Transformerの層と情報処理
Circuit Tracingと帰属グラフの話に入る前に、Transformerの層の役割を簡単に整理しておきます。「低層・中間層」という言葉が後で出てくるので、何を指しているのか確認しておきます。
LLaMA-3 8Bなどのモデルは数十の「Transformer層(layer)」を持っています。入力トークンはこの層を順番に通過しながら、内部表現(ベクトル)を変化させていきます。
| 層の深さ | LLaMA-3 8Bでの目安 | 主な役割 |
|---|---|---|
| 低層(early layers) | 0〜7層 | トークンの基本的な特徴抽出、表面的なパターン認識 |
| 中間層(mid layers) | 8〜18層 | 複数トークン間の意味統合、推論の中核 |
| 高層(later layers) | 19〜31層 | 回答の精緻化と流暢な文生成 |
低層での質問理解と中間層まで処理が深く続くかどうか、がこの論文の核心的な問いです。
提案手法:Circuit Tracingを用いた情報経路の可視化
Circuit Tracingとは
Circuit Tracingは、Transformerが特定の出力を生成するまでに、どのトークンがどの層を通じてどう影響し合ったかを因果的に追跡する手法です。Anthropicがモデルの解釈可能性研究の一環として開発したもので、2025年に公開された Attribution Graph の方法論(Ameisen et al., 2025)に基づいています。
処理の流れを簡潔に説明します。
入力:Transformerの推論時に生成される内部表現(residual stream)
処理:各層・各トークン位置の残差ストリームを、Transcoder(sparse autoencoder型のモジュール)で疎な活性化ユニットの集合に分解します。次に、ネットワークを局所線形化した置換モデルを使い、「あるトークンの状態が別のトークンの状態に与える貢献度」をユニット単位で計算。これをトークンペアに集約して、有向のattribution scoreを得ます。
出力:有向グラフ G = (V, E)。ノードはトークン×層の組み合わせで、エッジは情報の流れとその強度を表します。これが帰属グラフ(Attribution Graph)です。
他の解釈手法との違い
似た目的の手法としてAttention分析(どのトークンに注目しているか可視化)、Probing(中間層のベクトルに線形分類器をあてがう)、Sparse Autoencoder(SAE)などがあります。これらとCircuit Tracingの違いは、全層にわたる動的な因果関係を捉える点です。
Attention分析はどこを注視しているのかを可視化しますが、それがなぜ最終出力につながったかまでは分かりません。Probingは単一層のスナップショットです。
Circuit Tracingは複数層を横断する情報経路を因果グラフとして構造化することで、「質問の理解がどの深さまで到達したか」「いつ証拠への依存に切り替わったか」を層単位で見られます。
帰属グラフの読み方
RAGの文脈では、グラフに登場するノードは大きく3種類に分類されます。
-
Q:入力された質問のトークン
-
Ex(Ans_EXT):取得した証拠から生成される回答トークン(証拠と直接対応)
-
In(Ans_INT):モデルが内部的に生成する回答トークン(証拠対応なし)
これらの間で情報がどの層でどの強さで流れたかが、グラフ構造として可視化されます。
正答と誤答でグラフの形が違う
Circuit Tracingで帰属グラフを構築し、正答ケースと誤答ケースで比較すると明確な差があったと報告されていました。
| 指標 | 正答 | 誤答 |
|---|---|---|
| 推論パスの深さ(DAG-L) | 長い(多段の経路) | 短い(浅い経路) |
| 証拠の分散具合(最大PageRank) | 低い(分散) | 高い(少数ノードに集中) |
| エッジ密度 | 高い(密な連結) | 低い(疎・断片化) |
| 中間層(8〜18層)の活性 | 高い | 低い |
正答のときはモデル内では情報が多くのトークン間で分散・統合されながら深く処理されており、誤答のときは特定のハブノードに情報が集中し、低層でほぼ処理が完結していたとのことです。
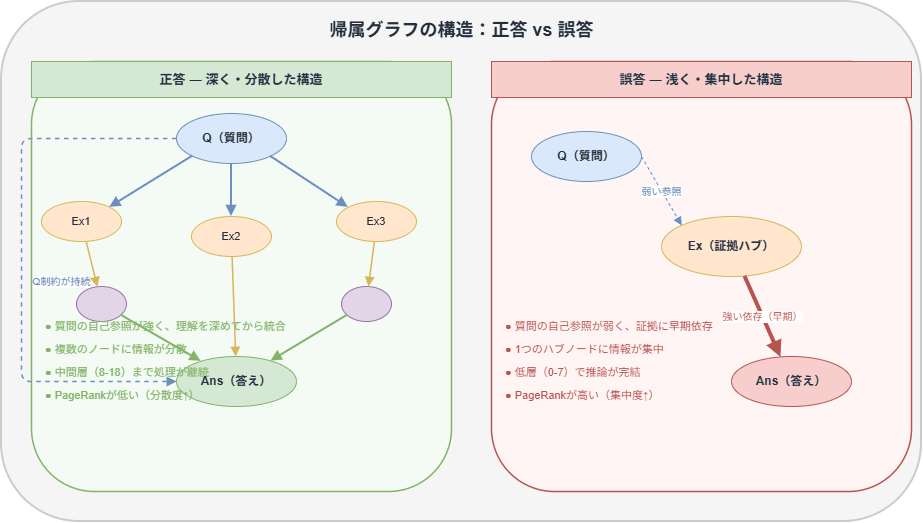
この傾向は3つのデータセット全体で一貫していたと報告されていました。
失敗パターンの分類:QCEGとSAEG
論文では正答パターンと誤答パターンにそれぞれ名前をつけていました。
QCEG(Question-Constrained Evidence Grounding)
正答に多く観察されるパターンです。低層(0〜7層)で「Q→Q」ルーティング、つまり質問トークンが自分自身を参照して意味を深める動きがしっかり確立されます。この段階で質問の意味表現が安定することで、その後の証拠との統合でも質問の制約が持続します。8層以降(中間層・高層)でも「Q→In」ルーティングが誤答時よりわずかに高く維持されており、回答生成まで質問の制約が続きやすい傾向があります。
SAEG(Surface-Aligned Evidence Grounding)
Surface-Alignedは「表面的な一致」という意味です。質問を深く理解する前に、取得した証拠トークンの表面的なパターンに飛びつく状態を指します。
低層で「Q→Q」ルーティングが弱く、代わりに「Q→Ans_EXT」、すぐ証拠から答えを取ろうとする動きが早期に強くなっていました。この早期のずれが後の層で増幅され、誤答につながります。
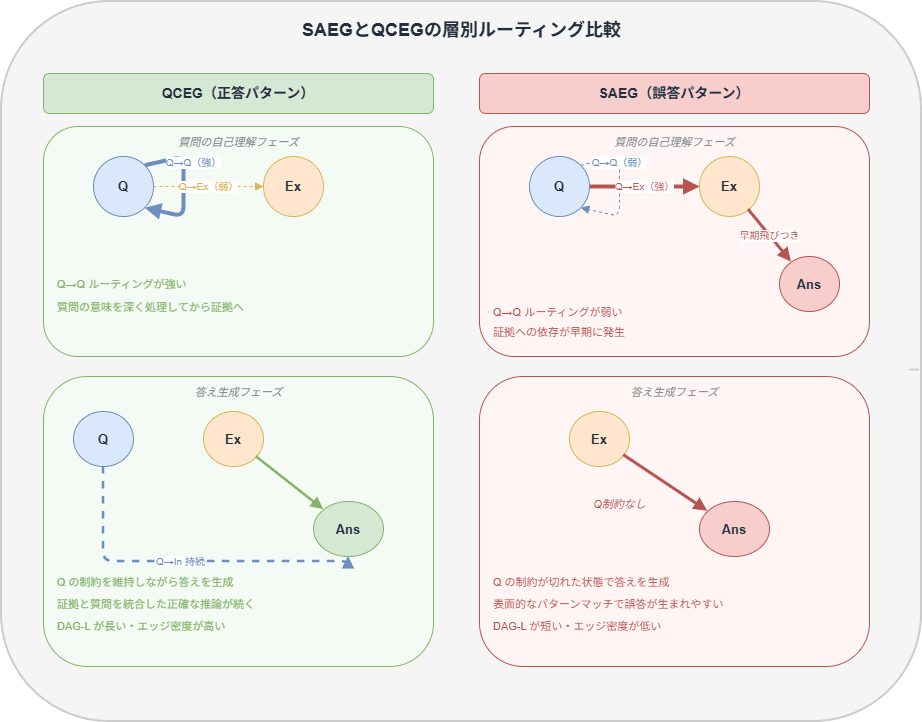
なお、「Q→Qが長い・短い」「集中度が高い・低い」といった指標は、正答群と誤答群の統計的な差として示されているものです。個別のクエリに対して「この値を超えたらSAEG」と判定できる固定閾値は、論文中で定義はされていませんでした。
この分析をどう活かすか:誤答の検出と注意の制御
論文では上記の分析をもとに、2つの具体的な活用方法を提案していました。
1. 帰属グラフの構造で誤答を事前検出する
論文では、帰属グラフの構造的な特徴(最長経路長、平均次数、三角形比率、PageRankなど)をGraph Transformer Encoderに入力し、この回答は正しいか誤りかを分類するフレームワークを用いて事前検出する手法を評価していました。
結果、「ロジットベースの自己判定(モデル自身が自分の確信度を評価する方法)」と比べて平均11.53%精度が改善したと報告していました。ロジットベースが見ているのは出力の確信度だけで、推論がどう組織化されたかは読めません。グラフ構造はそこを直接評価できます。FVRAGパイプラインに信頼度スコアとして組み込めば、Verifier的な役割を持たせられます。
2. 推論時のAttentionの重みを制御する
モデルパラメータを変えずに、推論時のforward hookでAttentionの重みを調整する手法です。3つの制御を組み合わせます。
- 低層で「Q→Q」ルーティングを強化する(αQQ = 1.5)
- 低層で証拠への早期依存を抑制する(αctx = 0.5)
- 8層以降で「Q→In」ルーティングを維持する(αQIn = 1.5)
Mix-MuSiQue(支持的な証拠と非支持的な証拠が混在する設定)での実験では、介入前56.5%→介入後61.6%で+9.0%の改善が確認されました。パラメータ変更なし、計算オーバーヘッドもほぼなしで実現できていました。
なお、この手法を実際の推論パイプラインに組み込む場合の大まかな流れを示すと、まず入力クエリが多段推論かどうかを判定し(この判定手法は論文の範囲外のため割愛)、該当するクエリに対してLLMが回答を生成したタイミングでCircuit Tracingを走らせて帰属グラフを構築します。その後、グラフの構造に基づいて「誤答を検出する」か「Attentionの重みを調整して回答品質を上げる」かを選ぶという流れです。LLMの内部パラメータにアクセスできる環境が前提になるため、現時点では研究・実験的な文脈での利用が主になります。
AWSで同じ問題に対処するには
論文の手法はTransformerの内部に直接触る必要があるため、BedrockのAPIモデルのようなブラックボックス環境では再現できません。ただ、SAEGの根本である「質問を深く処理する前に証拠に飛びつく」という問題への解答は、プロンプト設計とアーキテクチャで近似できます。
Extended Thinkingとの対応
最も直接的なアプローチはExtended Thinkingです。
論文がAttentionの制御でやっていたのは、低層で「Q→Q」ルーティングを先に確立してから証拠との統合に進ませることでした。Extended Thinkingを有効にすると、モデルは最終回答の前にthinkingトークンで推論を展開します。このthinkingフェーズが、「Q→Q」ルーティングが完了してから証拠統合に入るプロセスと構造的に対応しています。
Bedrock + ClaudeではExtended Thinkingを利用できるので、多段推論が絡むRAGクエリにthinkingを有効にするだけで、SAEGが起きやすい状況を緩和できる可能性があります。「難しい問題に使う機能」と捉えられがちですが、論文の知見から見ると多段推論RAGこそ使いどころです。
プロンプトで強制する
Extended Thinkingを使えない場合や、コストを抑えたい場合はプロンプトで同じ構造を作れます。
<step1>
以下の証拠を読む前に、この質問に正しく答えるために
満たされなければならない条件を全て書き出せ。
</step1>
<evidence>
{{retrieved_docs}}
</evidence>
<step2>
step1で書いた条件を全て満たす答えを、証拠から導け。
</step2>
「証拠を見る前の思考フェーズ」をXMLタグで強制的に挟み、「Q→Q」ルーティングに相当する処理を先に完了させます。1回の呼び出しで済みます。
呼び出しを分割してアーキテクチャで保証する
プロンプトではなく設計として落としたい場合は、Bedrockの呼び出し自体を分割します。
- 呼び出し①(証拠なし):質問だけ渡して「この質問が要求する条件を全て挙げて」→ 条件リストを取得
- 検索:条件リストを使ってOpenSearch / Kendraでチャンク取得
- 呼び出し②(条件リスト+証拠):「あなたが整理した条件を全て満たす答えを証拠から導いて」→ 回答生成
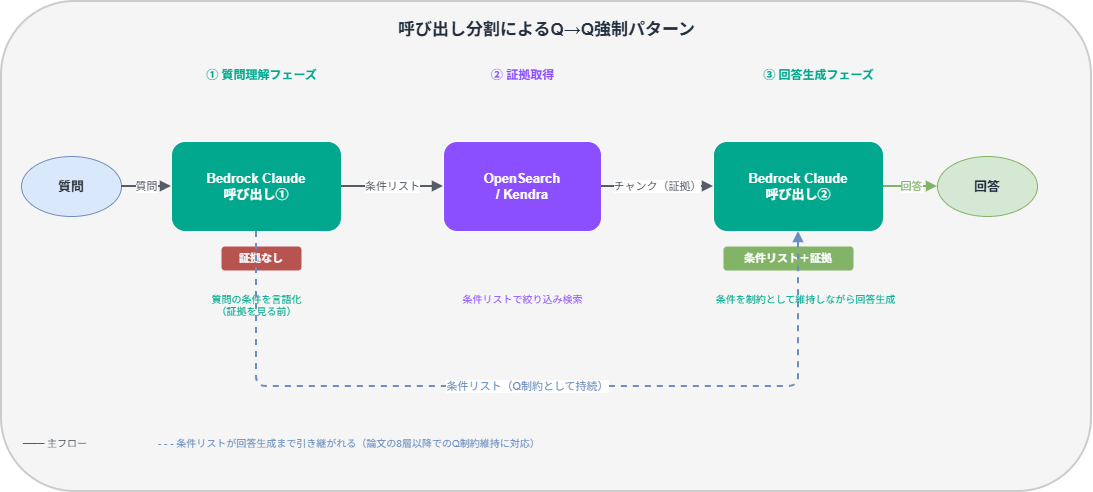
呼び出し①で証拠を見せないことで、モデルが表面的なパターンに引っ張られる前に質問の構造を言語化させます。呼び出し②で「あなたが整理した条件」と参照させることで、Q制約を回答生成まで持続させます(論文の高層での制御に対応)。
既存のクエリ分解パターンと外見は似ていますが、論文のSAEGメカニズムから設計根拠を説明できる点が違います。「なぜ多段推論RAGにこの構造が必要か」という問いに、経験則ではなくメカニズムで答えられます。
まとめ
「RAGは正しい証拠を取得できていれば答えられる」という前提が、実はそう単純ではないと気づかせてくれる論文でした。モデルの内部で「質問を深く理解してから証拠と統合する」プロセスが機能しているかどうかで、同じ入力に対する出力が変わるというトコロが面白いと感じます。
査読前のプレプリントなので今後修正が入る可能性はありますが、Circuit Tracingというモデル内部の解釈ツールをRAG失敗の原因分析に持ち込む発想は目新しく、「なぜ失敗するか」を出力の観察ではなく情報経路の構造から説明しようとしているところも読んでいて面白かったです。
読んでいて気になった制限もいくつかあります。
-
対象は多段推論QAに限定されている:この論文の実験は複数のドキュメントを組み合わせて推論する質問に絞られており、一般的なRAGシステムに入力される単純な1ホップ質問や要約・情報抽出タスクへの一般化は明示されていません。実運用でこの知見を活かすには、入力クエリが多段推論かどうかを事前に分類するステップが別途必要になります。
-
判定閾値は未定義:正答と誤答の差は統計的な傾向として示されており、個別ケースへの適用に使える固定閾値は現時点では存在しません。
Agentic RAGやマルチエージェント構成でRAGを使う場合、Verifier的なノードにこういった視点を組み込む余地があるかもしれません。
おわり!
参考
-
Why Retrieval-Augmented Generation Fails: A Graph Perspective(Kai Guo et al., arxiv 2605.14192, 2026)
-
Circuit Tracing: Revealing Computational Graphs in Language Models(Ameisen et al., 2025, Transformer Circuits Thread)










