![[レポート]世界記録となった2,500万の同時アクセスを捌いたHotstar.comとその方法 #reinvent [CMY302]](https://devio2023-media.developers.io/wp-content/uploads/2019/12/reinvent2019_report_eyecatch.jpg)
[レポート]世界記録となった2,500万の同時アクセスを捌いたHotstar.comとその方法 #reinvent [CMY302]
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは。DA事業本部の春田です。
本記事は、AWS re:Invent2019の CMY302: Scaling Hotstar.com for 25 million concurrent viewers のセッションレポートです。
The English version is here.
概要
This session focuses on why traditional autoscaling doesn't work for Hotstar (Disney's OTT streaming service), who recently created a global record for live streaming to 25.3 million concurrent viewers. We talk about challenges in scaling infrastructure for millions and how to overcome them, how Hotstar runs gamedays before facing live games, how it uses a load-testing monster called Hulk to prepare its platform for 50M peak. We also learn how the company uses chaos engineering to overcome real-world problems and achieve this scale.
本セッションでは、2530万人の視聴者にライブストリーミングを配信するためのグローバルレコードを作成したHotstar (Disney's OTT streaming service)で、なぜ従来のAutoScalingが機能しなかったかを掘り下げていきます。数100万人に対応するインフラにおけるスケーリングの課題と、それらをどう乗り越えたか、どうHotstarはGamedaysを運営していったか、50Mのピークに対応するプラットフォームを準備するために負荷テストの"怪物"、Hulkを使用したかを紹介していきます。また、会社が現実世界の問題やスケールを達成するために、どうchaos engineeringを使用したかご紹介します。
Speaker
- Gaurav Kamboj
- Cloud Architect, Hotstar
Hotstar.comはインドのOTT(Over-The-Top)プラットフォームで、9言語100,000時間以上のTVコンテンツや映画を提供しています。特に主要なコンテンツは、様々なスポーツのライブ中継であり、2019年7月10日のニュージランド対インドのクリケットの試合では、同時視聴者数が2530万人に到達し、自身が持つ世界記録1860万人を大きく塗り替えました。Hotstarのエンジニアは、この大規模な同時アクセストラフィックをどう捌いたのでしょうか?
Hotstarの戦略は取捨選択が非常に上手く、現実に徹したものという印象を受けました。ちょっとインド訛りがキツめの人で聞き取りづらかったのですが、かなりアーキテクトの参考になる内容だと思います!

内容
Hotstarについて
- ディズニーが所有するインドの No.1 OTTプラットフォーム
- 3.5億以上のダウンロード
- ある週末に行われたインド vs ニュージーランドの試合では、1億以上のUUを記録
- 15以上の言語に対応
- バラエティに富むコンテンツ
- ライブ、オンデマンド
- スポーツ、ニュース、TVプログラム、映画
- 地域ごとのカタログ
同時トラフィックのパターン
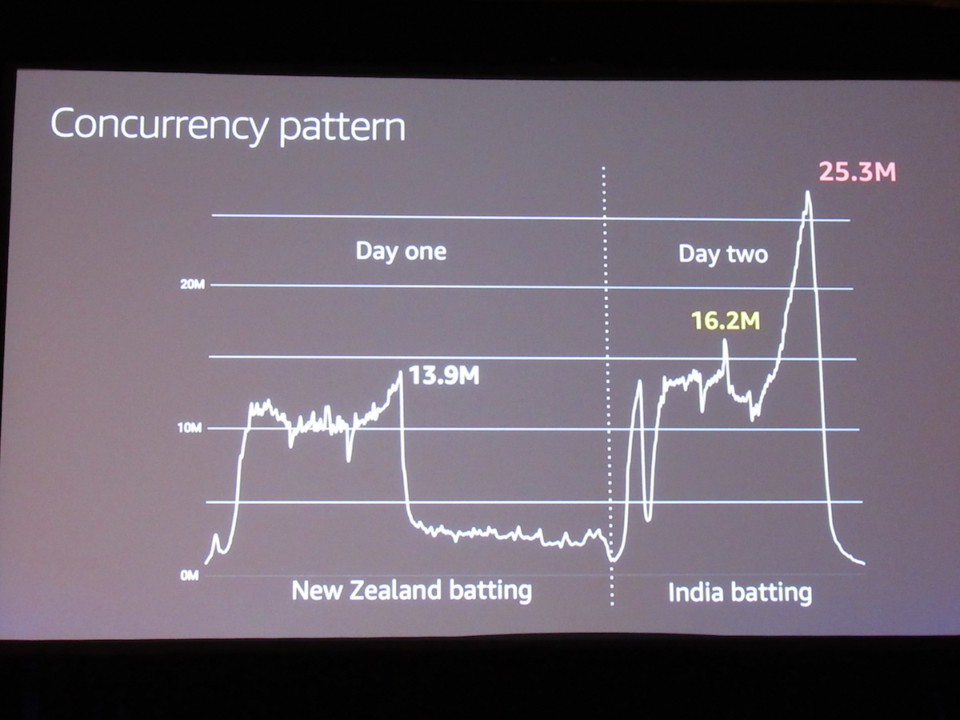
- インド vs ニュージーランド
- トラフィックの平均は1000万ユーザー
- 途中で雨が振り試合が中断となる前の、1,390万が最初のピーク
- 試合の翌日延期が決まって、ハイライト等を流している間も400~500万のユーザーが待機
- 試合が再開すると一気にトラフォックが上昇
- 戦略的タイムアウト時に急降下
- 最終的には2530万の視聴者数に到達し、世界新記録に
スケールについて
- ピーク時に、2500万以上の同時視聴者数、ワールドカップ2019 インド vs ニュージーランド
- 1秒間に100万リクエスト
- ピーク時に、10Tbps以上の帯域幅を消費
- インドのインターネットの70%〜75%、世界全体のインターネットの70%を消費
- 100億以上のクリックストリーム・メッセージ
なぜこの数字が膨大と言えるのか?
- 800万: Youtube → Felix Baumgartner’s Supersonic Jump
- 310万: NBC Sports App → Super Bowl(アメフト)
- 1030万: Hotstar → IPL決勝 2018(クリケット)
- 1860万: Hotstar → IPL決勝 2019
- 2530万: Hotstar → Worldcup インド vs ニュージーランド(クリケット)
Game Day
- 実際の試合の前に、GameDayを多くこなしてきた
- プロジェクト"HULK"
- 負荷を発生
- パフォーマンステスト・ツナミテスト
- Chaos Engineering
- 機械学習を使ったトラフィックパターン
- 108,000 CPU、216TB RAM、200Gbps Network out
- 8リージョンに地理的に分散
- Python製
- パブリッククラウドなので、共有してしているネットワークの負荷のかけすぎに注意
負荷発生のアーキテクチャ
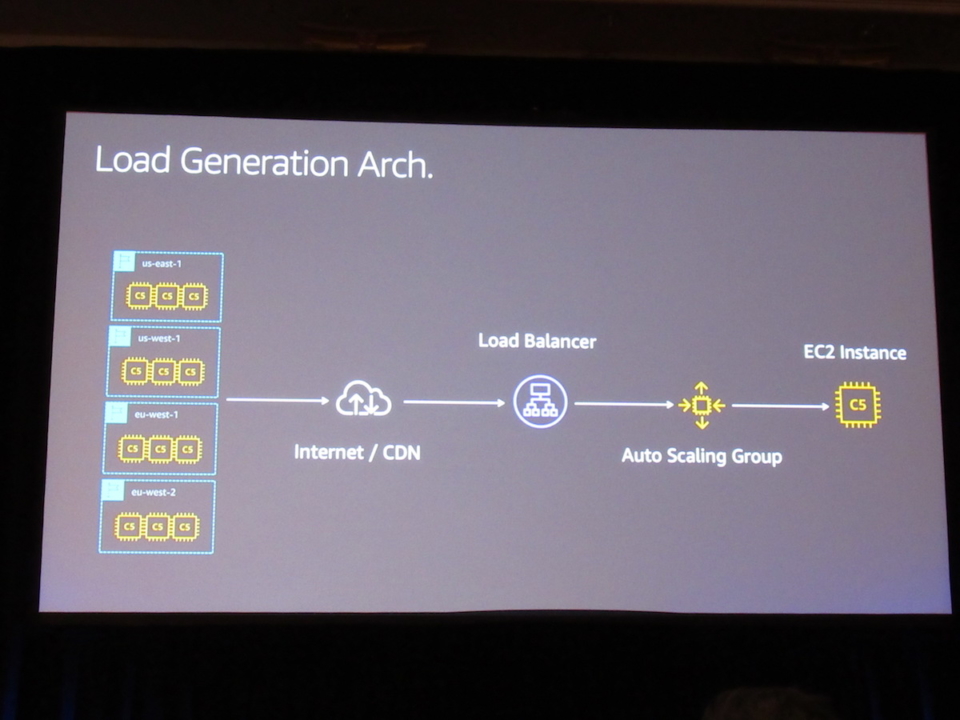
- かなりシンプル
- トラフィックを捌き切るために、複数のロードバランサ
- アクセスが集中しやすいホームページを負荷テスト
時間との闘い
- 全ての状況は同時に発生させる必要がある
- 1分ごとに100万以上のユーザー増加率
- 1分以内にアプリケーションを起動
- 90秒の反応時間
- プッシュ通知
- AMIをフルで作成
- 設定している暇がない
なぜAutoScalingを使わなかったのか?
- AWSが提供しているAuto Scalingを使わなかった
- キャパシティのエラーに対する機能が不十分
- 1つのAuto Scaling Groupにつき、一つのインスタンスタイプしか設定できない
- Auto Scaling Groupのステップサイズが遅い、増やした分だけAPIの数も増え複雑に
- リトライとExponential Backoff
戦闘でテストされたスケーリング戦略
- 試合開始前までにインフラをウォーミングアップさせておく
- リクエスト数とプラットフォーム上の同時実行数に基づいてスケールアップ
- 同時実行数に基づいて、プロアクティブに自動スケーリング
- EC2スポットフリートを、様々なインスタンスタイプで使用
実際の"Chaos"の中身
- プッシュ通知
- ツナミ・トラフィック
- スケールアップの遅延
- 帯域幅の制限
- レイテンシの増加
- ネットワーク障害(CDN)
何が知りたかったのか?
- それぞれのシステムの故障点
- 急激なスパイク(Death wave)
- ボトルネックや難所
- 未確認の問題や隠されたパターン
- ネットワークやアプリケーションなどの障害
パニックモード

- 実際、試合中は問題解決するための時間が15分20分もない
- クリティカルなコンポーネント(ビデオストリーミングや決済関連)は止めないために、レコメンデーション機能やパーソナライゼーション機能はOFFにしておく
重要なポイント
- あらゆる方法を駆使して障害に備える
- ユーザーの動き・流れを理解する
- 徐々に機能が低下していくことに関しては許容する
Q&A
- AWSのオートスケーリングの変わりに、どんなフレームワークを使ったのか?
- 自社製のPythonスクリプト
- スケーリングの監視に何のツールを使ったのか?
- 原始的な方法だが、コンテナのメトリクスを監視










