
Amazon S3 Vectors をベクトルストアにした Amazon Bedrock Knowledge Bases のノーコード RAG 構築をゼロから解説

コーヒーが好きな emi です。最近はカフェインを控えています。
2025/7/15 に Amazon S3 Vectors がパブリックプレビューとして発表されました。S3 がベースとなっているベクトルストアであるため、安価に RAG 構築できるのが魅力です。私も検証のために安く RAG を構築したくなり、触ってみることにしました。
前提として、私は「全文検索とベクトル検索の違い」や「Amazon S3 Vectors の利点」については、いくつかのブログを参考にして、なんとなくイメージは掴んでいます。
S3 Vectors の利点については以下を参照ください。
全文検索(テキストマッチング)はクエリと正確に一致するドキュメントを探すことに長けている検索方法で、ベクトル検索は類似度の高いアイテムを効率的に扱うことに長けている検索方法です。
しかし、私は普段インフラエンジニアとして働いていることが多いためコーディングなど開発にあまりなじみがなく、以下 S3 Vectors ドキュメントのチュートリアルを読んだのですが、ちんぷんかんぷんになってしまいました。
本記事ではコードを書かずに、Amazon S3 Vectors をベクトルストアとして接続した Bedrock Knowledge Bases で RAG を構築する手順を紹介します。
開発はあまり馴染みがない方やインフラエンジニア向けにも分かりやすいように、ハンズオン的に実施できる内容を目指しました。
イメージ図
Amazon S3 Vectors をベクトルストアにした Amazon Bedrock Knowledge Bases のノーコード RAG の構成を先に見ていきます。
まず S3 バケットは、元の生データを格納するデータソースとしての汎用バケットと、ベクトルストアとして利用するベクトルバケットの二つを作成します。本記事の手順では先にこれら二つのバケットを先に作成します。
その後、Bedrock Knowledge Bases の構築を行います。Knowledge Bases ではチャンキング戦略やベクトル化する際に利用する埋め込みモデル(Embedding Model)の設定などを行います。詳細は後述します。
Knowledge Bases の構築ができたら、データソースからデータの同期をおこないます。この同期作業により、Knowledge Bases 側でチャンキングやベクトル化を自動でいい感じに行ってくれ、ベクトルストアにベクトル化されたデータが格納されます。
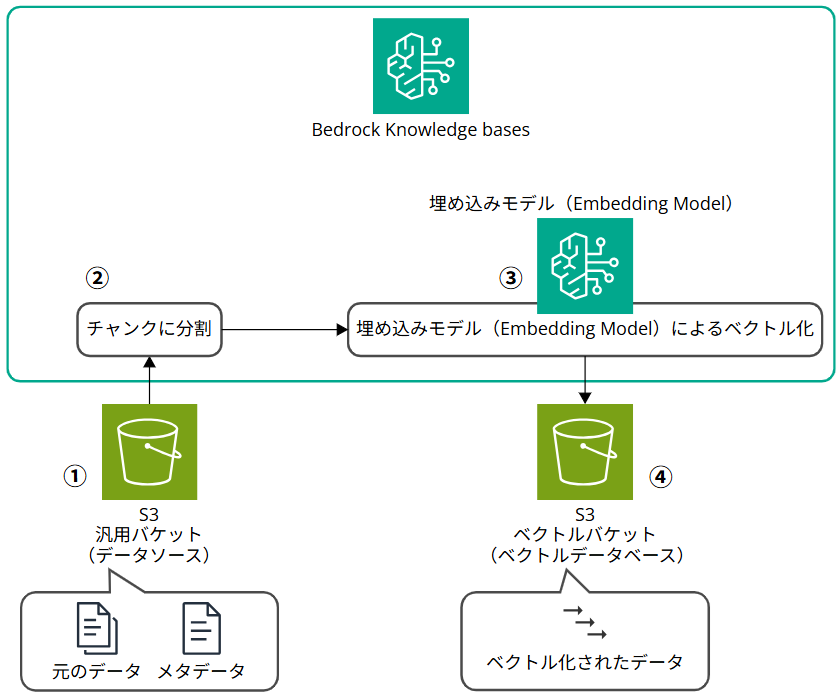
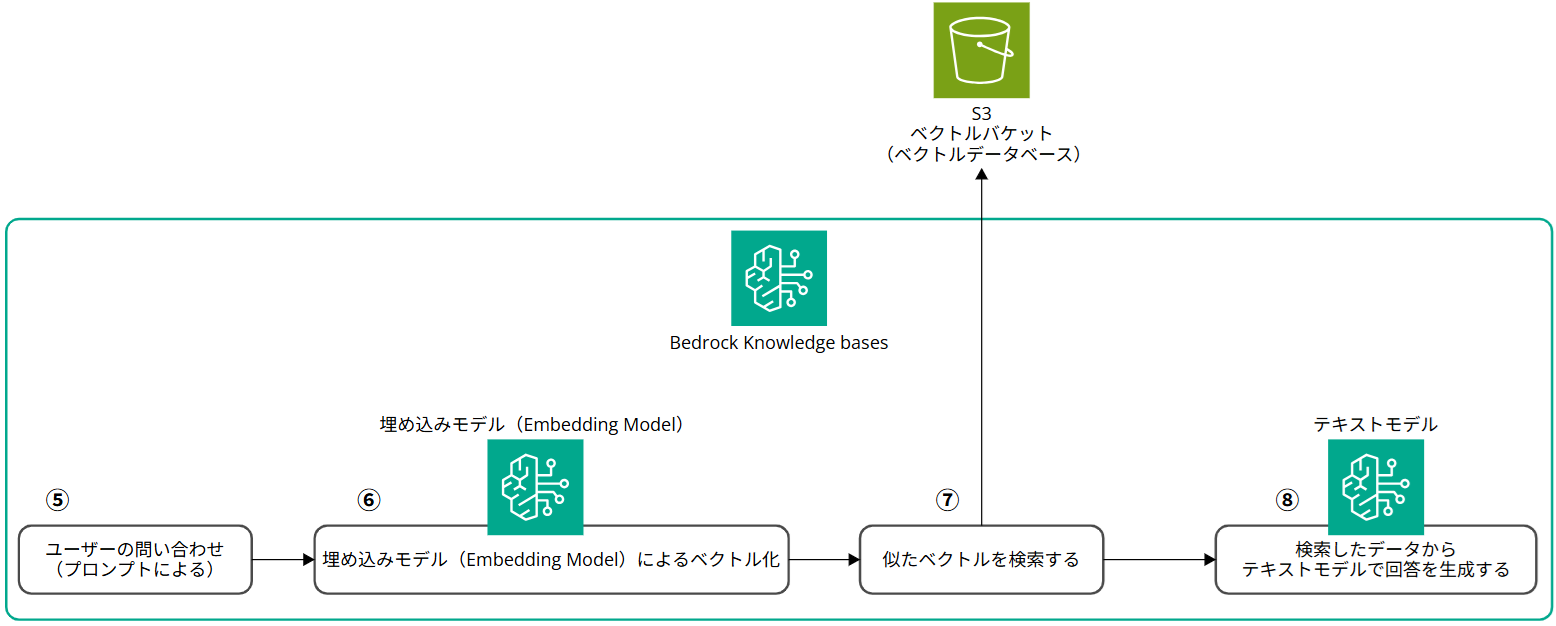
リソースの構築が終わったら、Bedrock Knowledge Bases 上でテストを行います。
ユーザーの問い合わせに対してベクトル化し、ベクトルバケット内のベクトルと照らし合わせて似たドキュメントを検索した上で、検索結果を加味してテキストモデルが回答生成し、ユーザーに回答します。
参考ブログ
手順
各種リソースの作成はバージニア北部リージョンでおこないます。S3 Vector は 2025/9/8 現在パブリックプレビュー中でまだ東京リージョンで使用できません。
使用する元データ
今回 RAG を構築するための元データは Step 3: Insert vectors into a vector index with the SDK for Python (Boto3) のサンプルコード内のデータを参考に、とっても簡単に作成しました。
映画のタイトルと説明、ジャンル、公開年を記載した簡単な CSV ファイル movie.csv です。
id,title,description,genre,year
1,Star Wars,A farm boy joins rebels to fight an evil empire in space,scifi,1977
2,Jurassic Park,Scientists create dinosaurs in a theme park that goes wrong,scifi,1993
3,Finding Nemo,A father fish searches the ocean to find his lost son,family,2003
4,The Matrix,A hacker discovers reality is a computer simulation,scifi,1999
5,Toy Story,Toys come to life when humans aren't around,family,1995
また、Openserach Serverless をベクトルストアとして利用する際はメタデータを付与しメタデータフィルタリングをおこなうことができました。
S3 Vector でも同様にメタデータファイルを作成して設定しておくことにします。movie.csv.metadata.json というメタデータファイルを作成してみました。
{
"metadataAttributes": {
"type": "movie_database",
"category": "entertainment"
}
}
メタデータの形式についてドキュメントを探したのですが、どうもうまく見つからず… Knowledge bases for Amazon Bedrock でメタデータフィルタリングを試してみる | DevelopersIO のブログや他の方の設定例などを見て自己流で設定してみました。今回は RAG の元になる CSV ファイルが movie.csv 一つだけなのでフィルタリングすることもないくらい小規模なのですが、一応格納しておきます。
S3 バケットの作成
汎用バケットの作成
バージニア北部リージョンの S3 コンソールで、まずは元のデータを格納する汎用バケットを作成します。これが、Bedrock Knowledge Bases のデータソースになります。
バケット名を指定し、後はデフォルトのままとします。
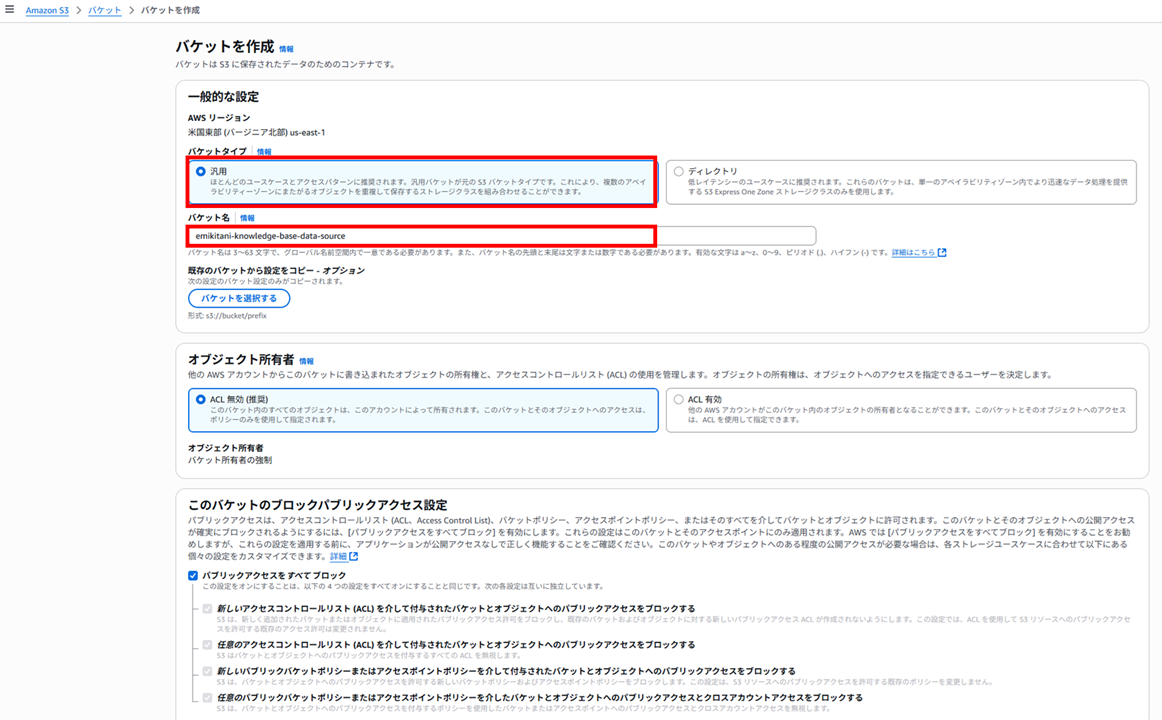
バケットを作成します。
作成した汎用バケットに、「使用する元データ」で作成した movie.csv と movie.csv.metadata.json を格納しておきます。
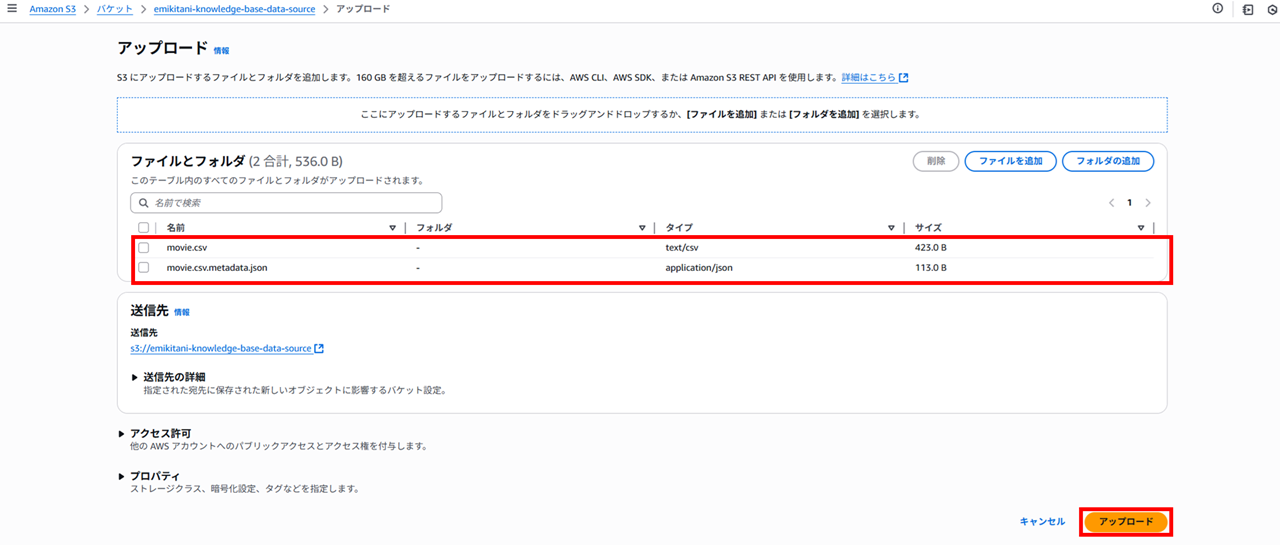
ベクトルバケットの作成
以下ドキュメントに、Bedrock Knowledge Bases 用のベクトルストアとして S3 Vector を使用するための前提条件が書かれています。こちらもあわせて参照ください。
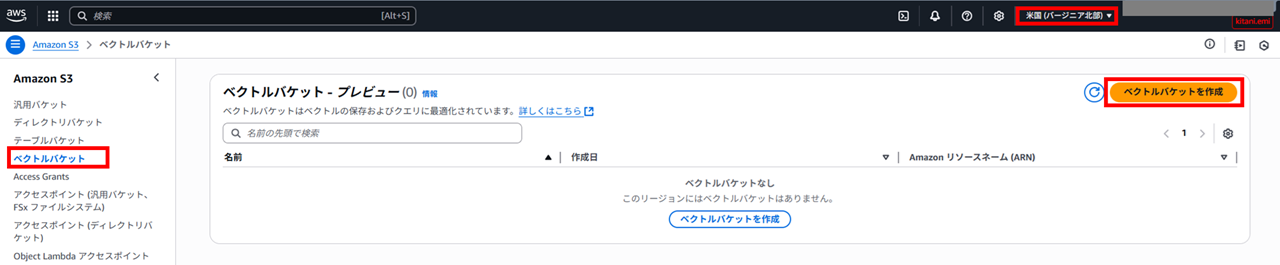
S3 コンソールでベクトルバケットの作成をおこないます。
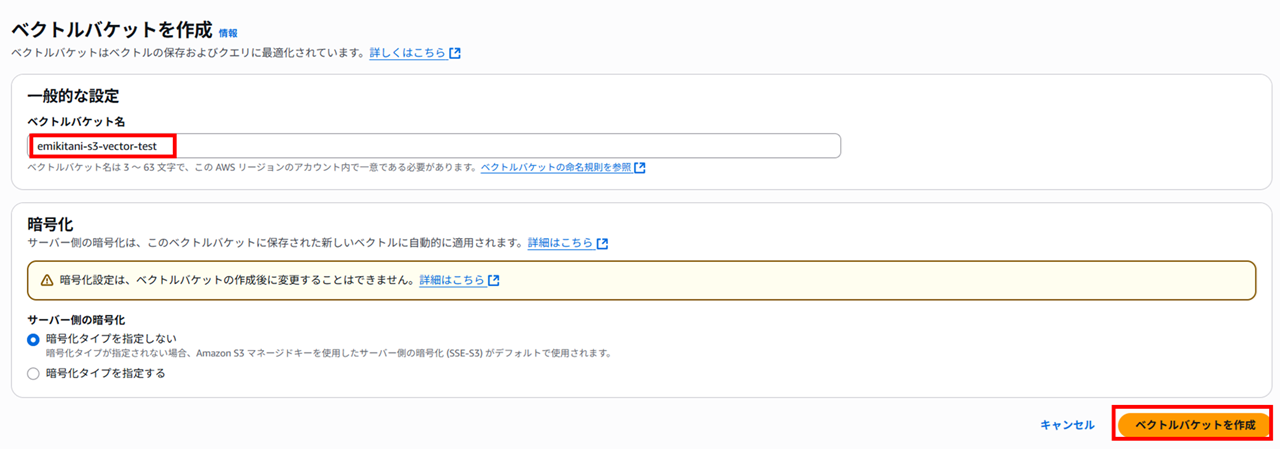
ベクトルバケット名を指定して作成しました。暗号化はデフォルトのままにしています。
続いてベクトルバケットの中にベクトルインデックスを作成します。
ベクトルインデックスは、効率的な類似検索のためにベクトルデータを保存するものです。
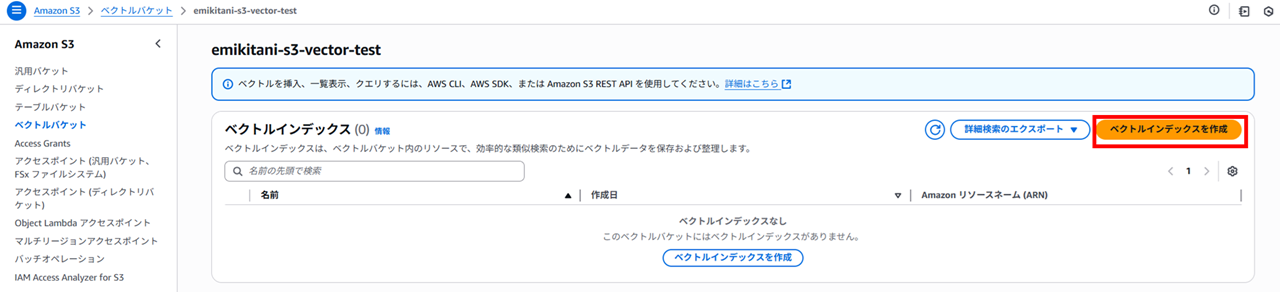
ベクトルインデックス名、ベクトルのディメンション(次元数)、距離メトリック(CosineまたはEuclidean)を指定します。
今回は設定しませんが、オプションで、類似検索クエリのフィルタリングから除外するメタデータフィールドのリストを指定できます。
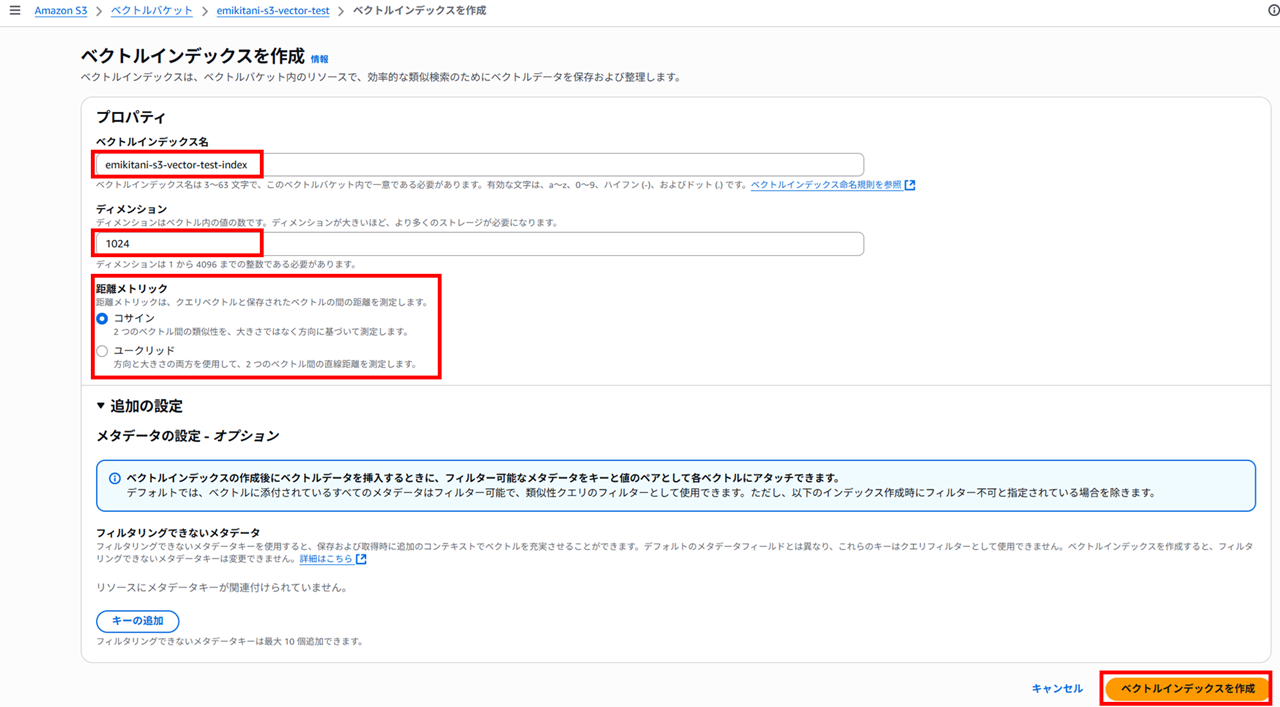
さて、「ベクトルのディメンション(次元数)」、「距離メトリック」とは何でしょうか。
ベクトルのディメンション(次元数)
ディメンションとは、埋め込みモデルが出力するベクトルの要素数(次元数)です。
2 次元だと (x, y)
3 次元だと (x, y, z)
:
1024 次元だと (v1, v2, …, v1024)
のようなイメージです。
ディメンションが大きいほど計算量が多くなり、多くのストレージが必要になります。
S3 Vector で設定するベクトルのディメンションは、Bedrock Knowledge Bases でベクトル化をする際に指定する埋め込みモデル(Embedding Model)の出力次元と一致させる必要があります。埋め込みモデル(Embedding Model)の出力次元はモデルによって決まっています。
現在 Bedrock Knowledge Bases で使える埋め込みモデル(Embedding Model)は、 Amazon 社と Cohere 社と TwelveLabs 社が提供しているのが確認できました。
以下は Bedrock のモデルカタログ画面のキャプチャです。モダリティで Embedding でフィルタすると、すべての埋め込みモデル(Embedding Model)が表示できます。
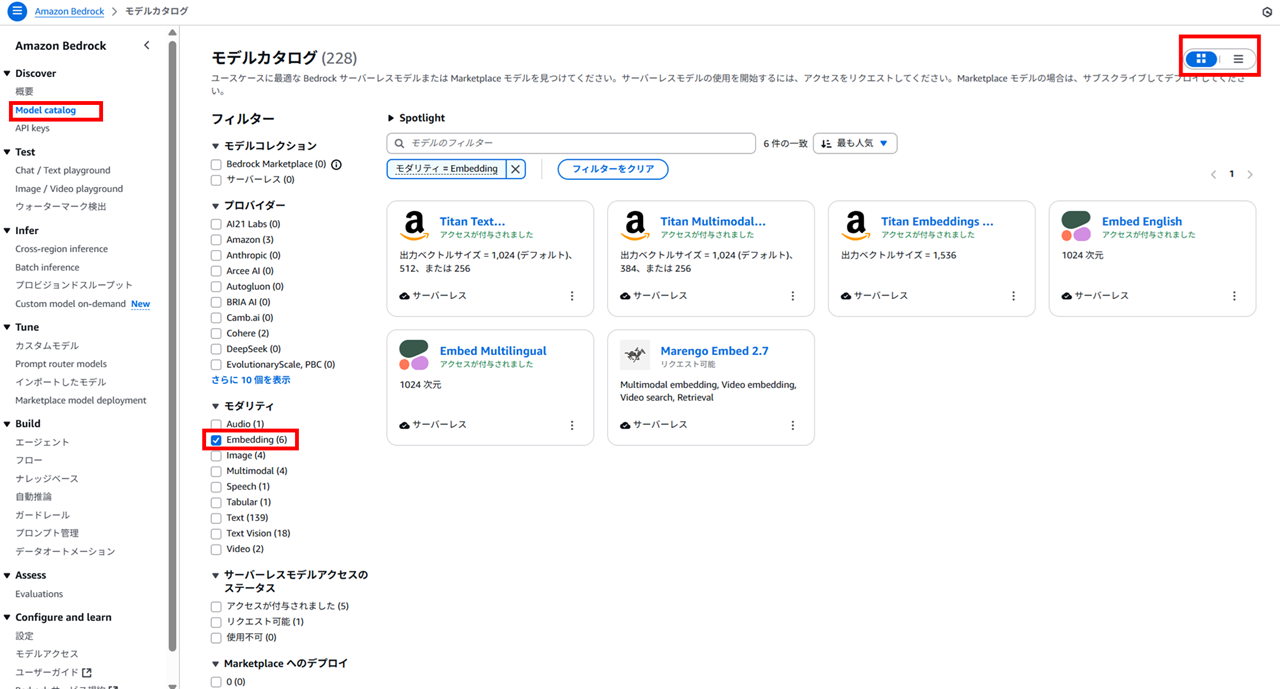
表形式にすると、ベクトル出力次元も分かりますね。出力ベクトルサイズと次元は同じです。
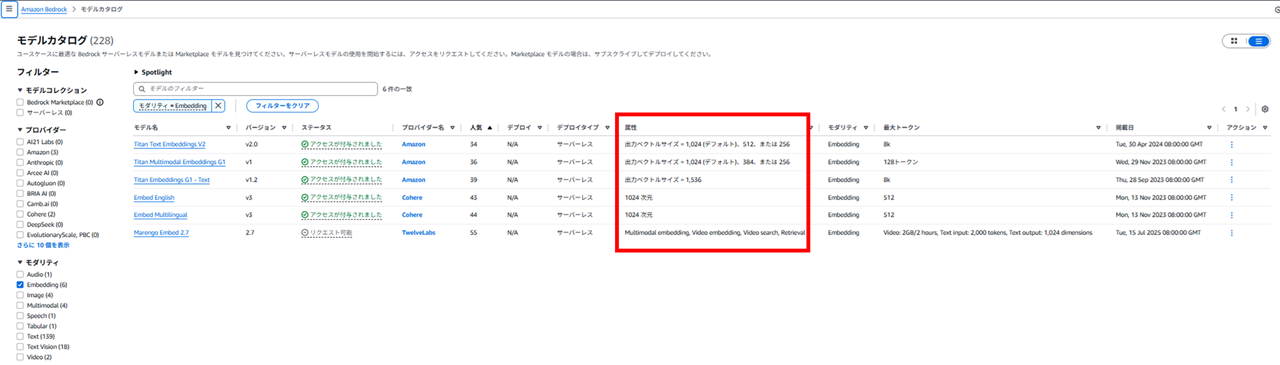
Prerequisites for using a vector store you created for a knowledge base - Amazon Bedrock の S3 Vector 部分を見ると、代表的な埋め込みモデル(Embedding Model)のディメンション(次元)も記載されています。これらのドキュメントを参照し、適切なディメンション(次元)を指定します。
ちなみに Prerequisites for using a vector store you created for a knowledge base - Amazon Bedrock の S3 Vector 部分に記載のディメンションを引用しますと以下のようになっています。Bedrock 側のカタログモデルからも確認できます。
| 埋め込みモデル | ディメンション数 | 用途 |
|---|---|---|
| Amazon Titan Text Embeddings V2 | 1024 (デフォルト), 256, 512 | 軽量で効率的なモデル、さまざまなディメンションが指定可能 |
| Amazon Titan Embeddings G1 - Text | 1536 | 高精度が必要な場合 |
| Cohere Embed (English) | 1024 | 英語テキスト専用 |
| Cohere Embed (Multilingual) | 1024 | 多言語対応 |
今回は RAG の元となるデータも少ないので軽量な Amazon Titan Text Embeddings V2 を使うことにします。よって、ディメンションは Amazon Titan Text Embeddings V2 のデフォルト値である 1024 を設定します。埋め込みモデル(Embedding Model)の設定は Bedrock Knowledge Bases 作成の際に後で指定します。
距離メトリック(Distance metric)
距離メトリック(Distance metric)は類似度を測る距離のことで、2 つのものの「離れ具合」を数で表すルールです。近いほど小さく(0に近い)、遠いほど大きくなります。
ベクトル検索では「距離が小さい=似ている」とみなして、一番距離が小さいものを返します。
- コサイン(cosine)
- 角度の違いを見る。長さ(大きさ)は無視
- テキスト・画像などの埋め込み(Embedding)検索でよく使う
- ユークリッド(Euclidean)
- 直線距離を見る。向きと大きさの差の両方に効く。
- 量の差そのものが意味を持つ数値特徴や座標データで使いやすい。
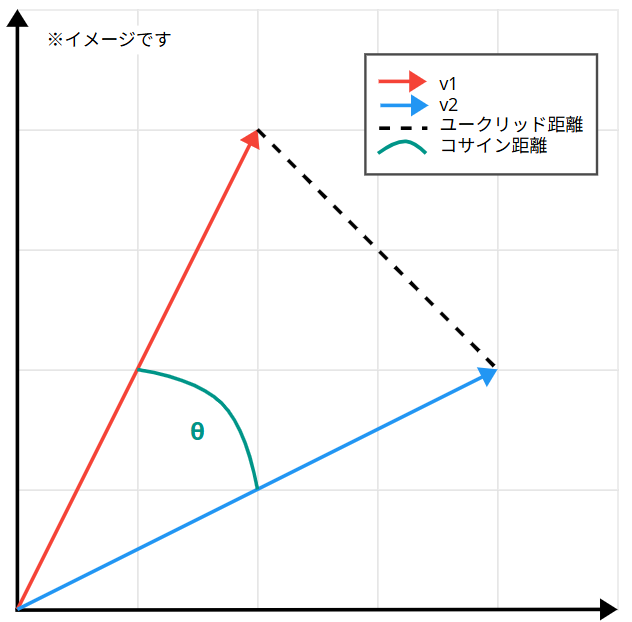
今回は少量テキストのみのベクトルストアとして使用するため「コサイン」を選択して、ベクトルインデックスを作成します。
ナレッジベースの作成
S3 Vector の作成が終わったら、Bedrock コンソールに移動して Knowledge Bases を作成していきます。
「ナレッジベース」から「作成」をクリックし「ベクトルストアを含むナレッジベース」を選択します。
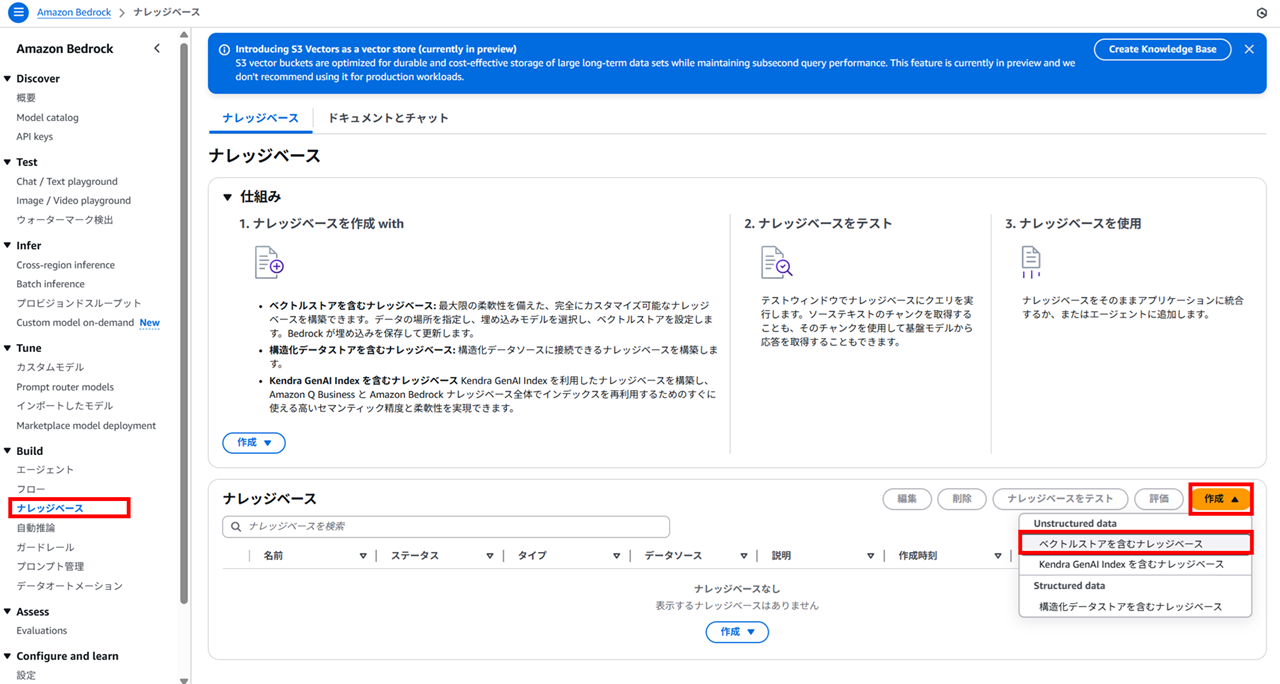
ナレッジベース名、説明を入力します。
IAM ロールは今回新規作成しました。
IAM ロール knowledge-base-quick-start-s3-vector
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "BedrockInvokeModelStatement",
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel"
],
"Resource": [
"arn:aws:bedrock:us-east-1::foundation-model/amazon.titan-embed-text-v2:0"
]
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "S3ListBucketStatement",
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::emikitani-knowledge-base-data-source"
],
"Condition": {
"StringEquals": {
"aws:ResourceAccount": [
"<この AWS アカウントのアカウント ID>"
]
}
}
},
{
"Sid": "S3GetObjectStatement",
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::emikitani-knowledge-base-data-source/*"
],
"Condition": {
"StringEquals": {
"aws:ResourceAccount": [
"<この AWS アカウントのアカウント ID>"
]
}
}
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "S3VectorsPermissions",
"Effect": "Allow",
"Action": [
"s3vectors:GetIndex",
"s3vectors:QueryVectors",
"s3vectors:PutVectors",
"s3vectors:GetVectors",
"s3vectors:DeleteVectors"
],
"Resource": "arn:aws:s3vectors:us-east-1:<この AWS アカウントのアカウント ID>:bucket/emikitani-s3-vector-test/index/emikitani-s3-vector-test-index",
"Condition": {
"StringEquals": {
"aws:ResourceAccount": "<この AWS アカウントのアカウント ID>"
}
}
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AmazonBedrockKnowledgeBaseTrustPolicy",
"Effect": "Allow",
"Principal": {
"Service": "bedrock.amazonaws.com"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "<この AWS アカウントのアカウント ID>"
},
"ArnLike": {
"aws:SourceArn": "arn:aws:bedrock:us-east-1:<この AWS アカウントのアカウント ID>:knowledge-base/*"
}
}
}
]
}
データソースはあらかじめ作成済みの汎用バケットを使用するため、S3 を選択します。
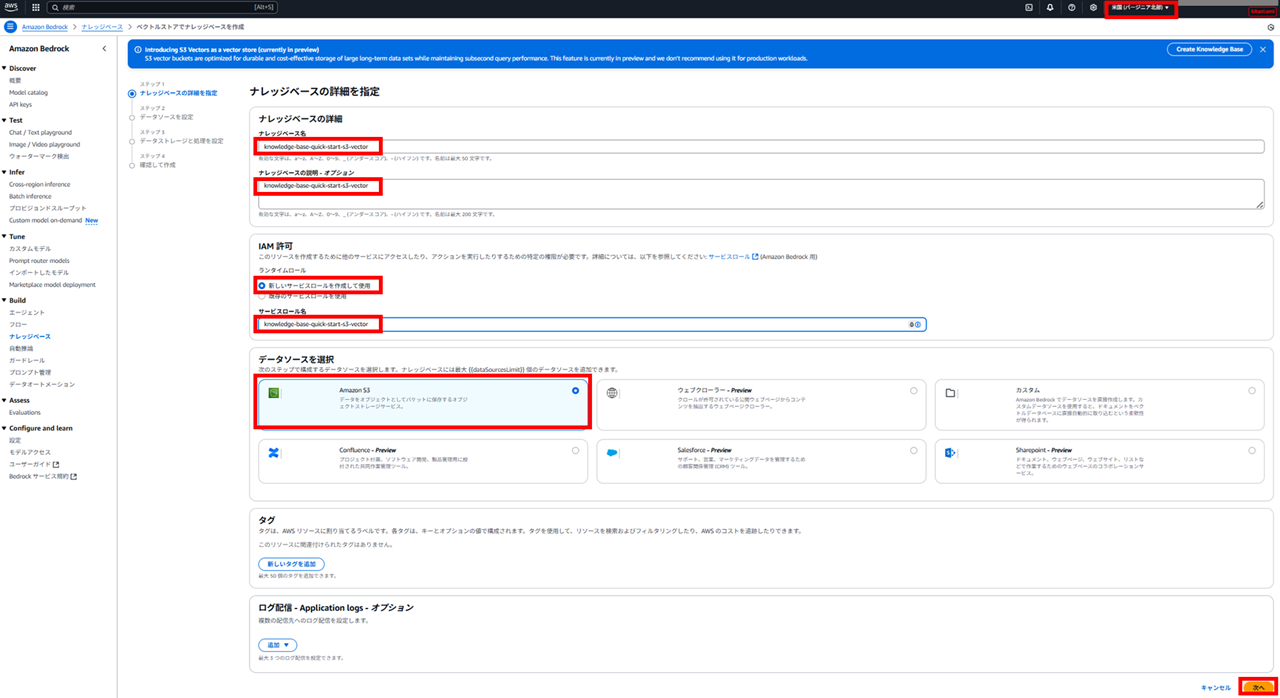
データソース名と、データソースとして作成した汎用バケットの情報を入力します。
その他の設定は今回はデフォルトとしました。チャンキング戦略については AWS 入門ブログリレー 2024 〜Amazon Bedrock Knowledge bases編〜 | DevelopersIO - チャンキング戦略 が分かりやすいので参照ください。
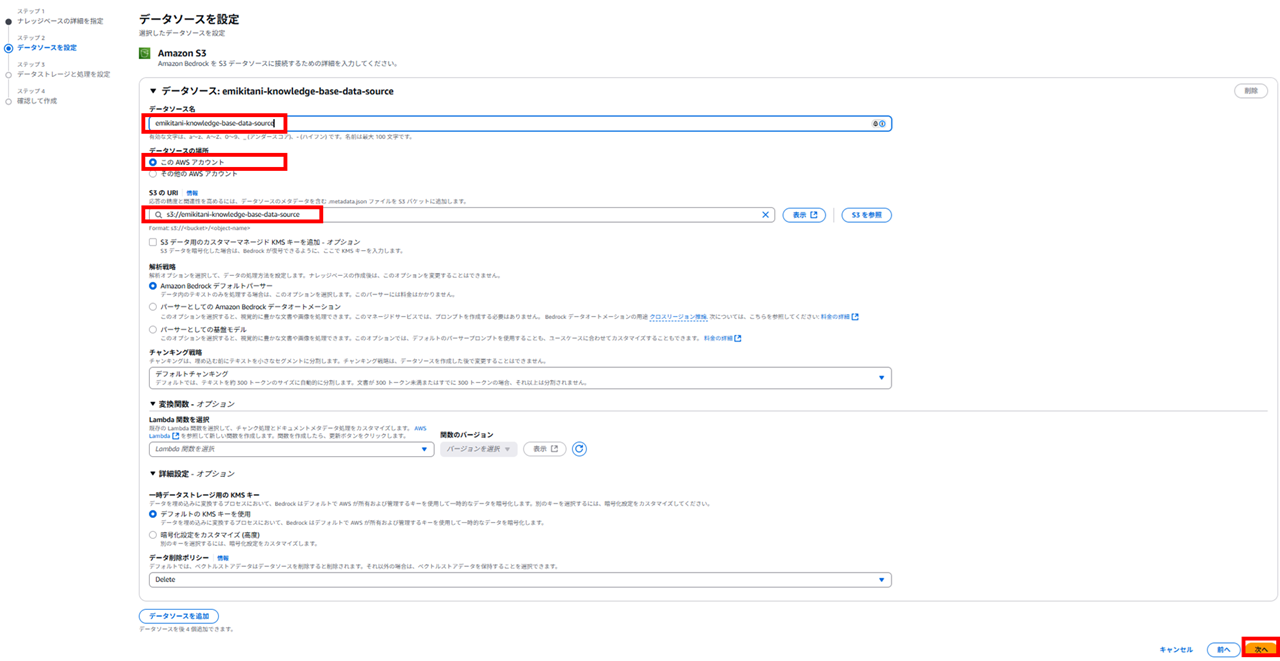
続いてベクトルストアの埋め込みモデル(Embedding Model)を選択します。S3 Vector の設定の際に Amazon Titan Text Embeddings V2 を使用すると決めてディメンションを設定しましたので、Amazon Titan Text Embeddings V2 を選択します。
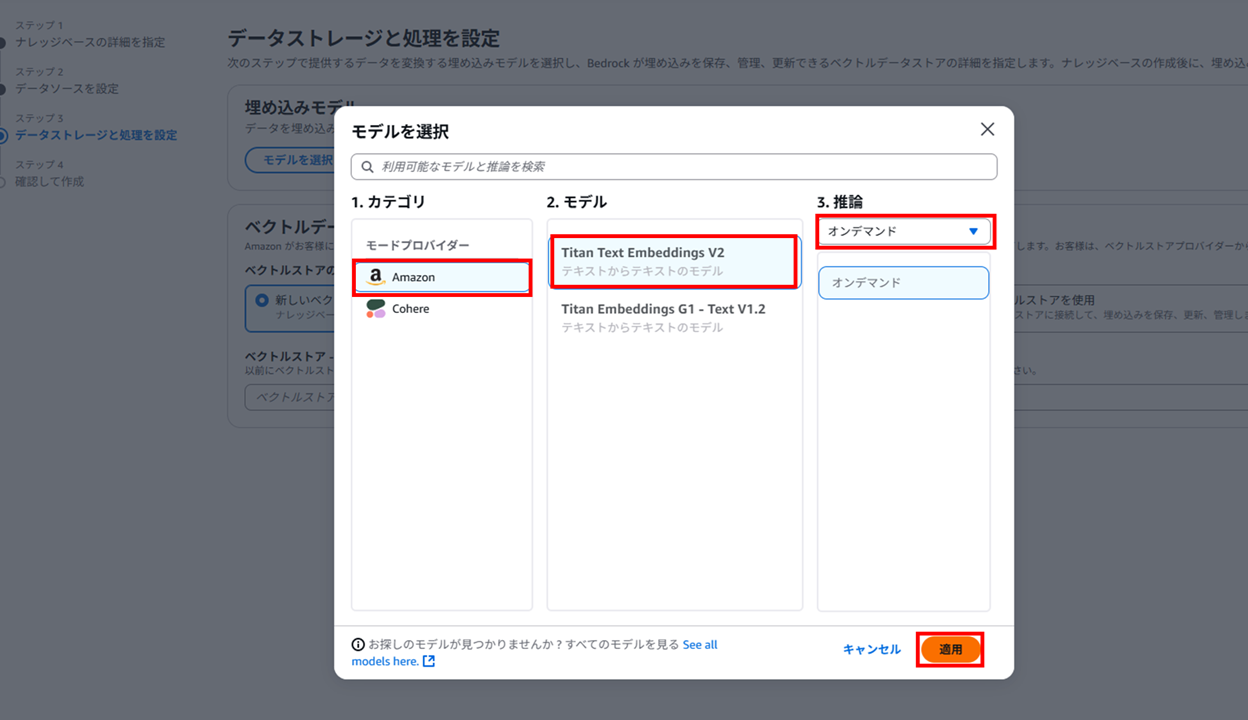
埋め込みモデルの設定で「追加設定」を展開すると「埋め込みタイプ」の選択肢が表示されます。ここでは「浮動小数点ベクトル埋め込み」を選択します。
(S3 Vectorsは「バイナリベクトル埋め込み」をサポートしていないため:参考情報)
既存のベクトルストアを選択し、作成済みのベクトルバケット情報を入力します。
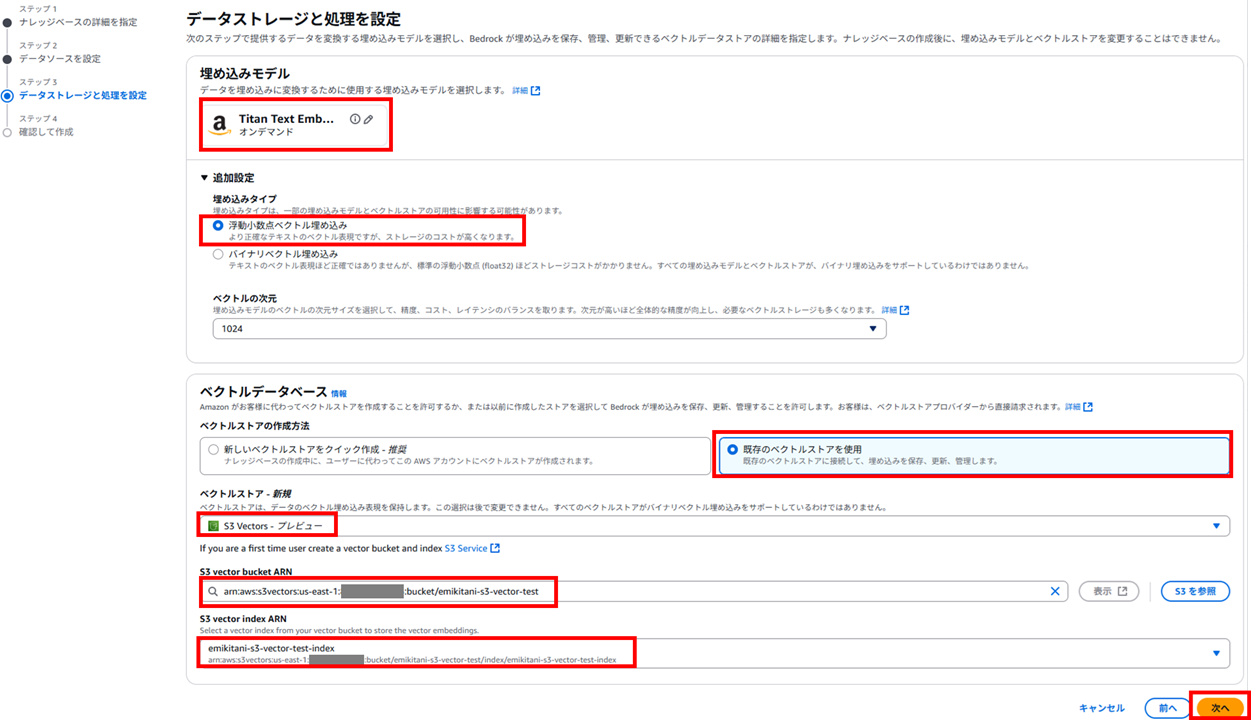
確認して作成します。
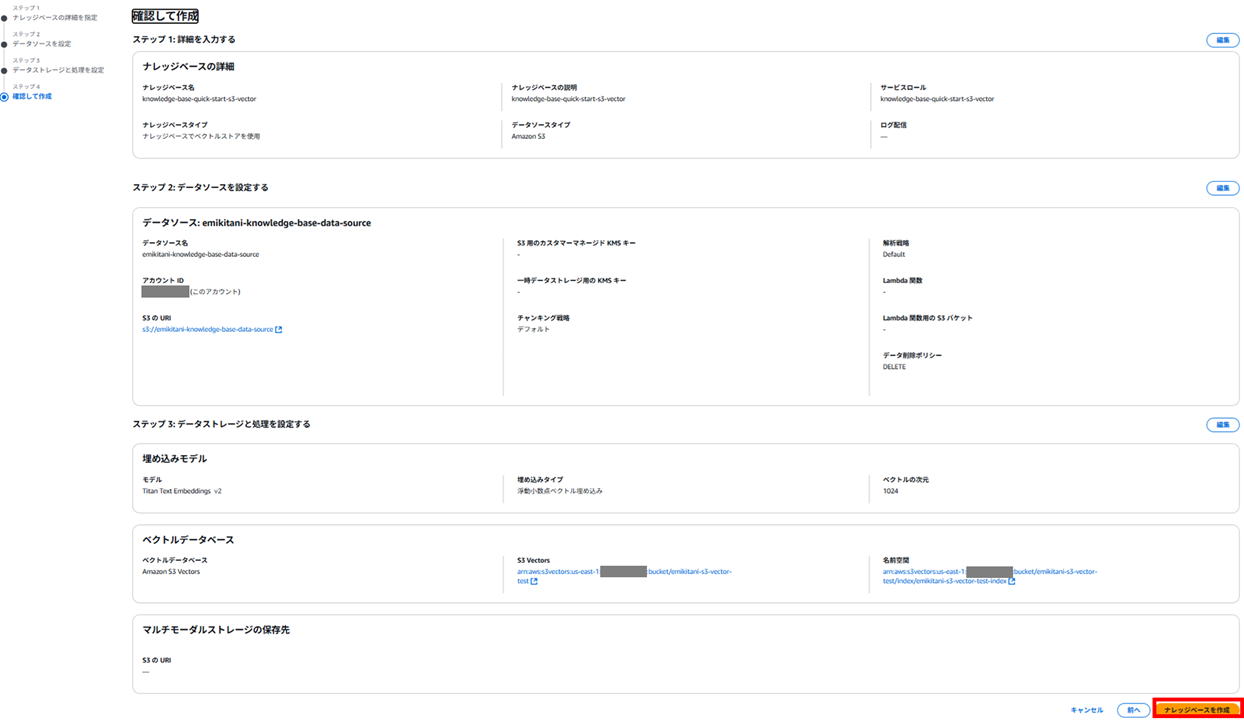
ナレッジベースができました。
このままだとデータソースとして作成した汎用バケットの内容がまだベクトル化(埋め込み・Embedding)されておらず、ベクトルバケットにベクトルが入っていません。
データソースを選択して、「同期」を行います。
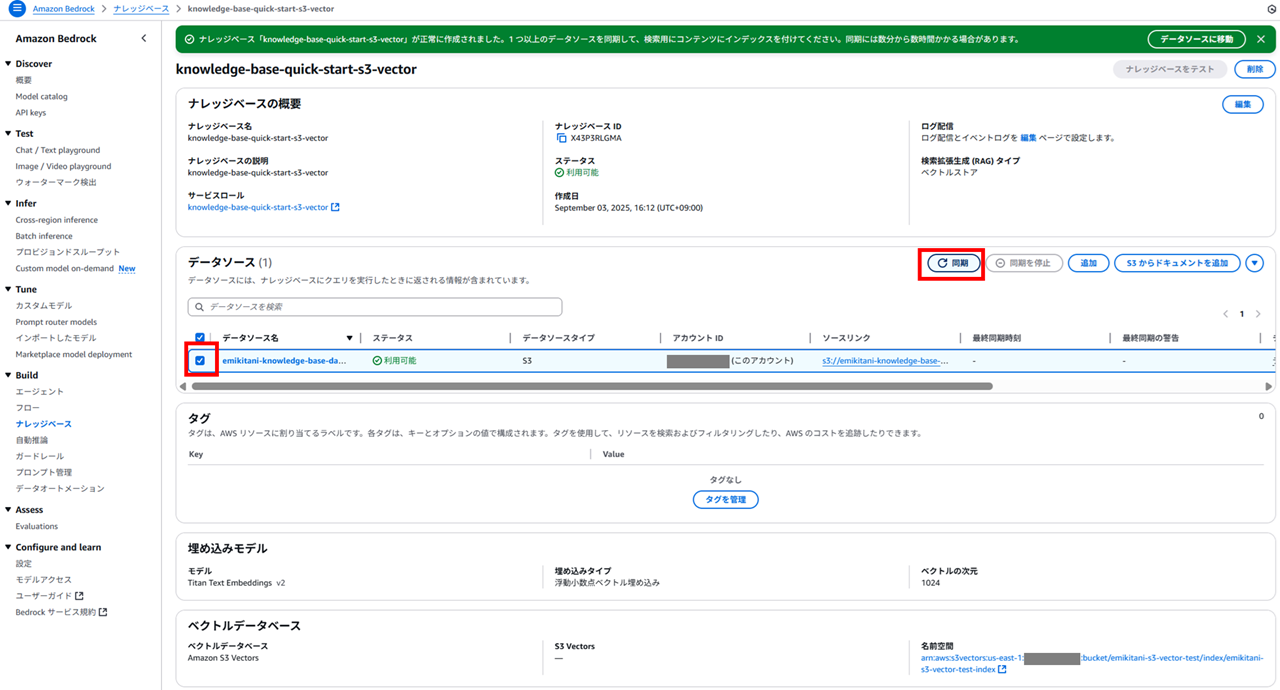
今回はデータ量が少ないためすぐに同期が終わりました。これで Embedding が行われ、S3 Vector にベクトル情報が格納された状態になります。
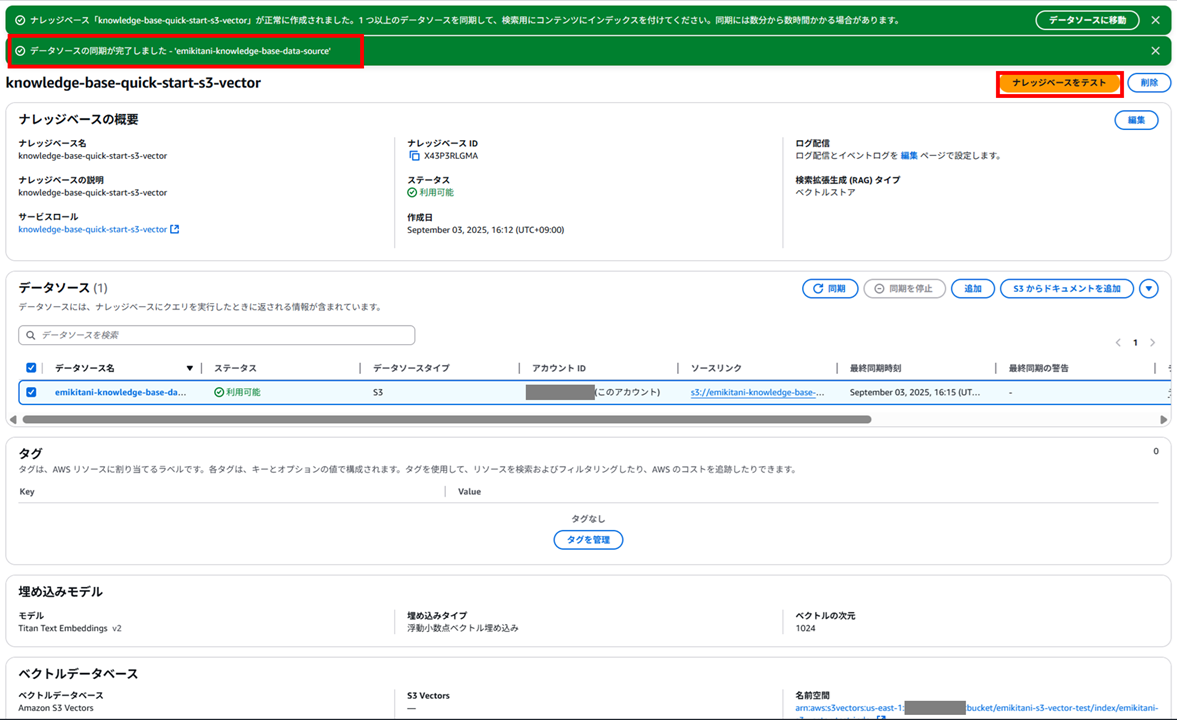
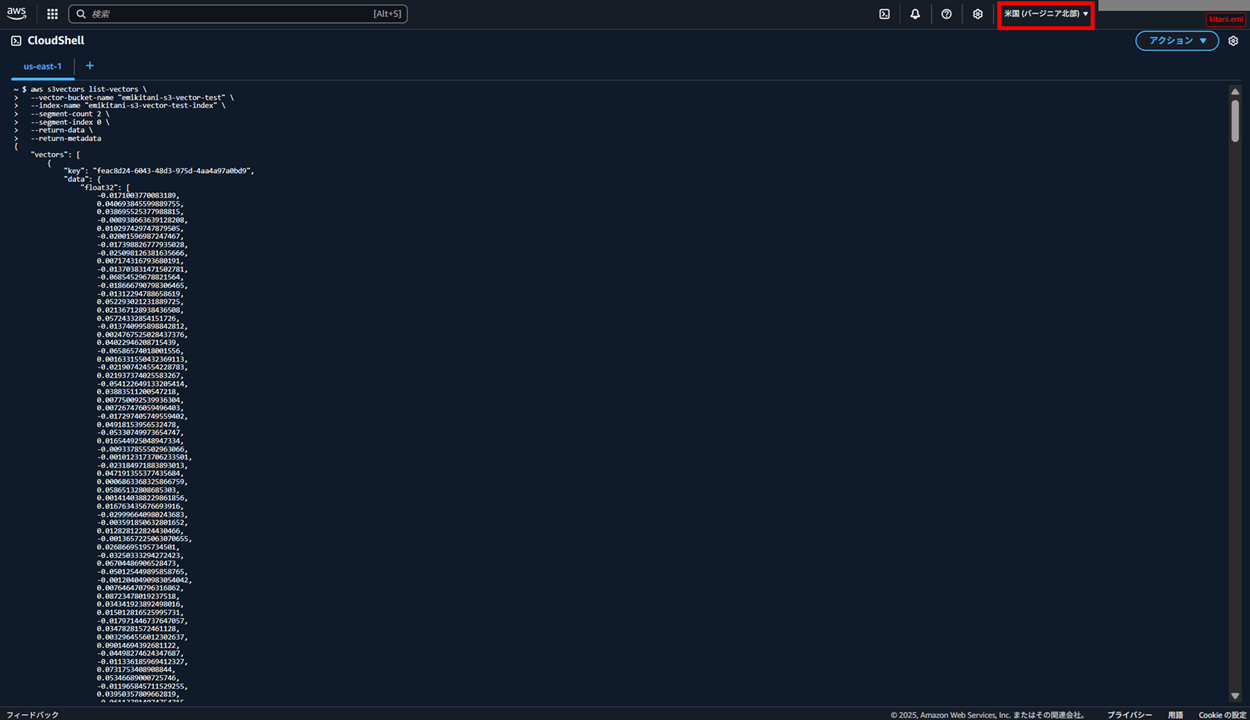
S3 Vector の中のベクトル情報は list-vectors コマンドで確認できます。
CloudShell で試してみます。
aws s3vectors list-vectors \
--vector-bucket-name "emikitani-s3-vector-test" \
--index-name "emikitani-s3-vector-test-index" \
--segment-count 2 \
--segment-index 0 \
--return-data \
--return-metadata
以下トグルにコマンド実行結果をしまっています。実際には 1052 行の出力結果があったのですが、ブログの文字数制限のためベクトルの数字部分は一部省略しています。ディメンションで 1024 次元と設定したので、数字列の行は 1024 行ありました。
実行結果
~ $ aws s3vectors list-vectors \
> --vector-bucket-name "emikitani-s3-vector-test" \
> --index-name "emikitani-s3-vector-test-index" \
> --segment-count 2 \
> --segment-index 0 \
> --return-data \
> --return-metadata
{
"vectors": [
{
"key": "feac8d24-6043-48d3-975d-4aa4a97a0bd9",
"data": {
"float32": [
-0.0171003770083189,
0.040693845599889755,
0.038695525377988815,
-0.008938663639128208,
0.010297429747879505,
-0.02001596987247467,
-0.017398826777935028,
-0.025098126381635666,
0.007174316793680191,
-0.013703831471502781,
-0.06854529678821564,
-0.018666790798306465,
-0.01312294788658619,
0.052293021231889725,
0.021367128938436508,
0.05724332854151726,
-0.013740995898842812,
0.0024767525028437376,
0.04022946208715439,
-0.06586574018001556,
0.0016331550432369113,
:
:
:
:
:
:
:
:
:
:
:
0.03170903027057648,
-0.02898329310119152,
-0.04021698236465454,
-0.012773502618074417,
0.05329957231879234,
0.024228045716881752,
-0.02399330399930477,
-0.013985470868647099,
0.011700217612087727,
0.043683383613824844,
0.026831770315766335,
0.04798451066017151,
0.028628908097743988,
0.023121396079659462,
-0.005929522216320038,
0.022038765251636505,
0.01917368173599243,
0.009823676198720932,
-0.0025868816301226616,
-0.018725600093603134,
0.07329335063695908,
0.056998737156391144,
-0.01217437069863081,
0.03196348994970322,
-0.032896194607019424,
0.03864175081253052,
0.023942578583955765,
-0.021422656252980232,
0.0098624462261796,
0.009755621664226055,
0.014366071671247482,
0.023753410205245018,
-0.023320479318499565,
-0.026944775134325027,
0.0018950486555695534,
-0.010709753260016441,
0.015508473850786686,
0.01057769637554884,
-0.006836803164333105,
-0.014828840270638466,
-0.017583955079317093
]
},
"metadata": {
"x-amz-bedrock-kb-data-source-id": "UUWV6YXCRU",
"category": "entertainment",
"type": "movie_database",
"AMAZON_BEDROCK_TEXT": "id,title,description,genre,year 1,Star Wars,A farm boy joins rebels to fight an evil empire in space,scifi,1977 2,Jurassic Park,Scientists create dinosaurs in a theme park that goes wrong,scifi,1993 3,Finding Nemo,A father fish searches the ocean to find his lost son,family,2003 4,The Matrix,A hacker discovers reality is a computer simulation,scifi,1999 5,Toy Story,Toys come to life when humans aren't around,family,1995",
"AMAZON_BEDROCK_METADATA": "{\"text\":null,\"author\":null,\"createDate\":\"2025-09-03T07:00:32Z\",\"modifiedDate\":\"2025-09-03T07:00:32Z\",\"source\":{\"sourceLocation\":\"s3://emikitani-knowledge-base-data-source/movie.csv\",\"sourceType\":null},\"descriptionText\":null,\"pageNumber\":null,\"pageSizes\":null,\"graphDocument\":{\"entities\":[]},\"parentText\":null,\"relatedContents\":null,\"sourceDocumentId\":\"ttLe2tsuS1FFEZv1/5NVAXVYgVmEFI5IzHIamTKOcNAmEAgKMHc+zmYMouC2BrTi\",\"additionalMetadata\":null}",
"x-amz-bedrock-kb-source-uri": "s3://emikitani-knowledge-base-data-source/movie.csv"
}
}
]
}
~ $
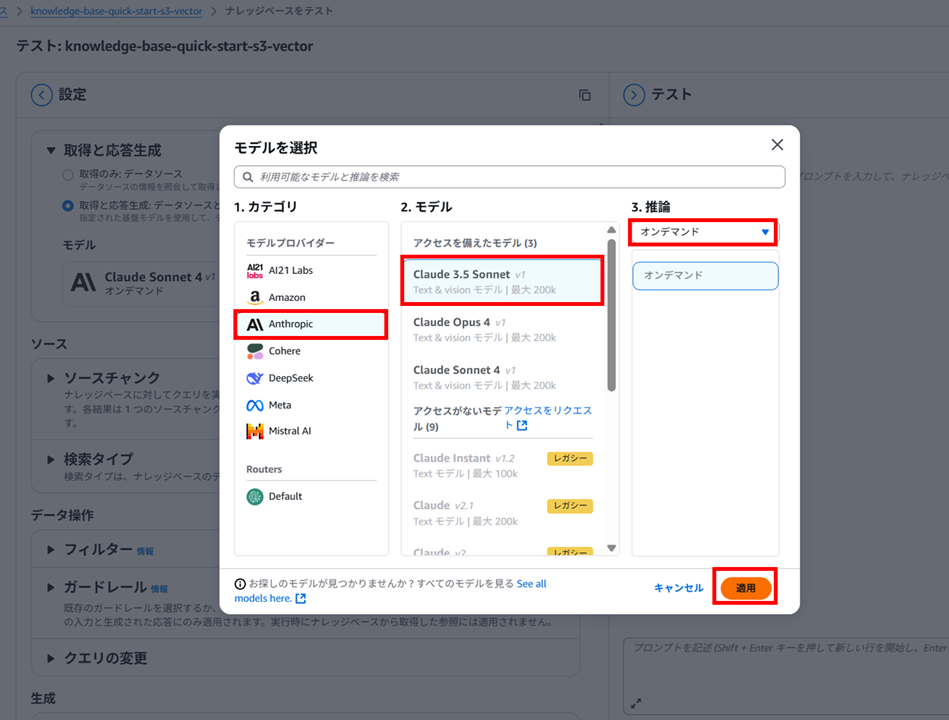
ナレッジベースのテスト
では、ナレッジベースのテストをおこなっていきます。
回答を生成させるテキストモデルを選択します。ここでは Claude 3.5 Sonnet を選択しました。
プロンプトを入力します。
宇宙を舞台にした冒険映画を教えて
以下のように回答を得られました。
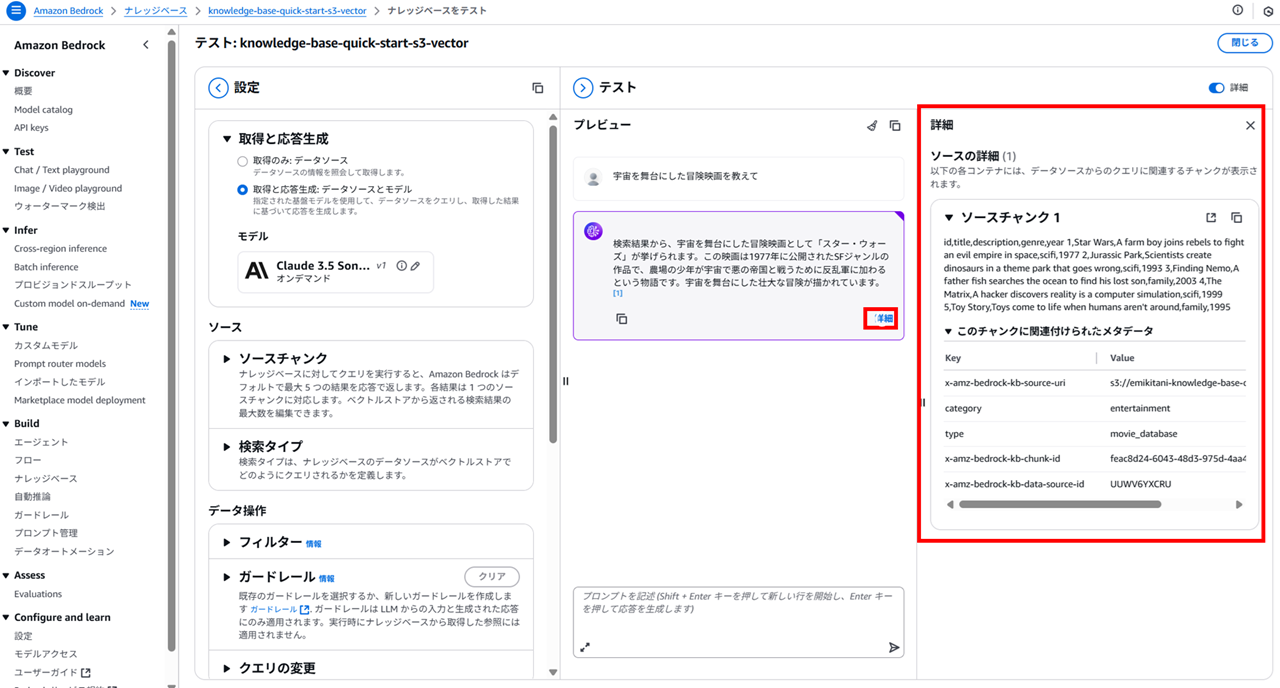
検索結果から、宇宙を舞台にした冒険映画として「スター・ウォーズ」が挙げられます。
この映画は1977年に公開されたSFジャンルの作品で、農場の少年が宇宙で悪の帝国と戦うために反乱軍に加わるという物語です。
宇宙を舞台にした壮大な冒険が描かれています。
「詳細」をクリックすると、データソースからのクエリに関連するチャンクを表示できます。
チャンクと言いつつ元のデータがわずかだったためか、movie.csv が全文表示されてますね。
[1] のリンクをクリックしても、データソースとしてどこが参照されているのか確認できます。
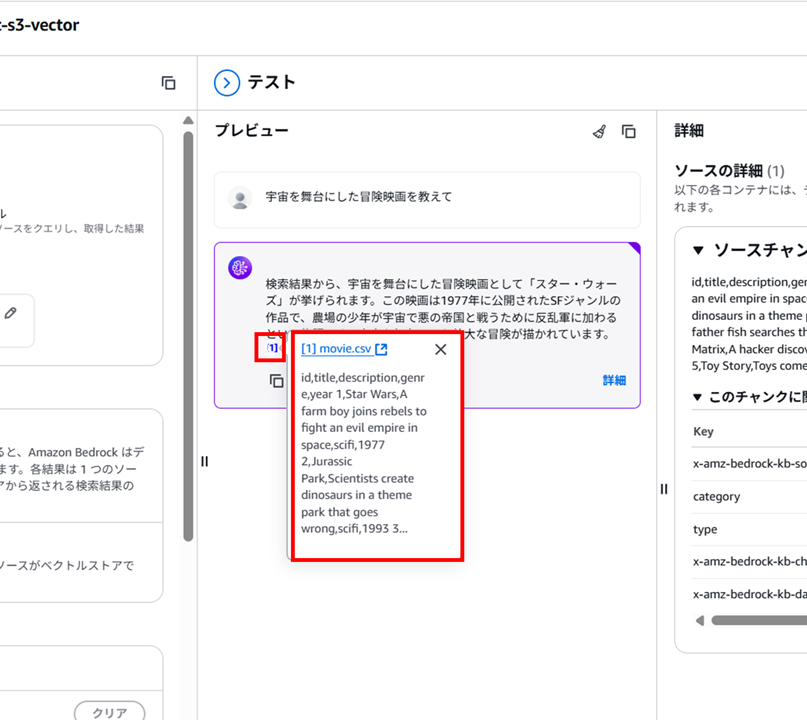
クロスリージョン推論を行うテキストモデルを選択してうまくいかなかった例
さて、私は最初、テキストモデルとして Claude Sonnet 4 を選択しました。このモデルは「cross-region inference(クロスリージョン推論)」のモデルです。
推論の選択では「オンデマンド」ではなく「推論プロファイル」と表示されます。
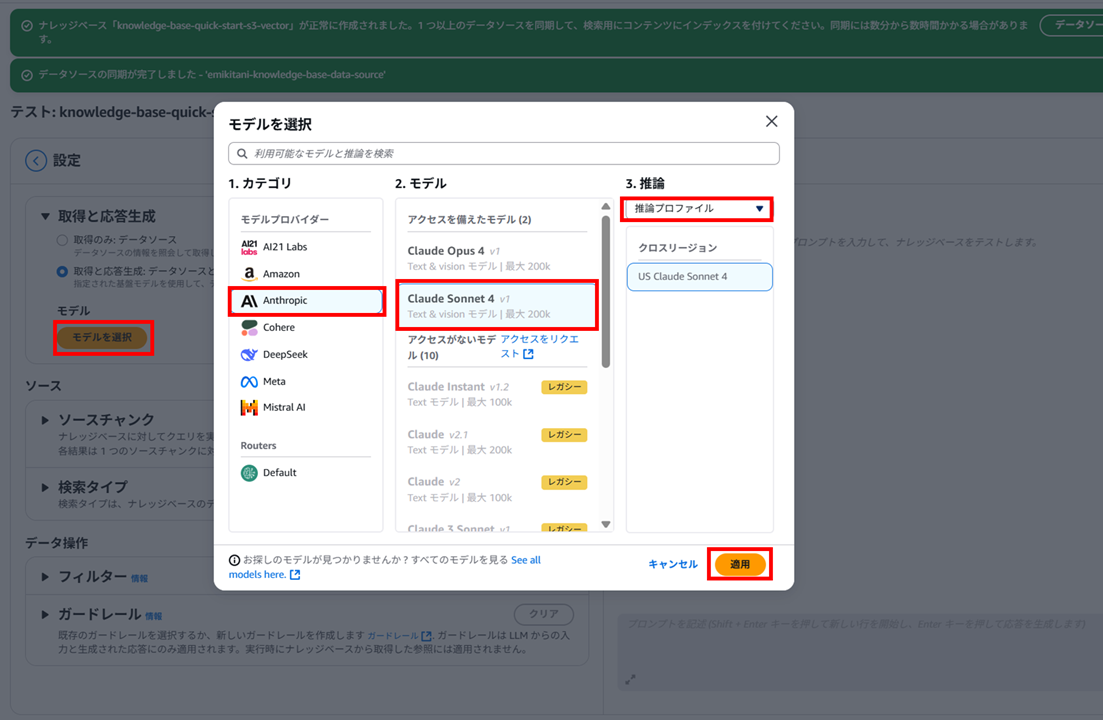
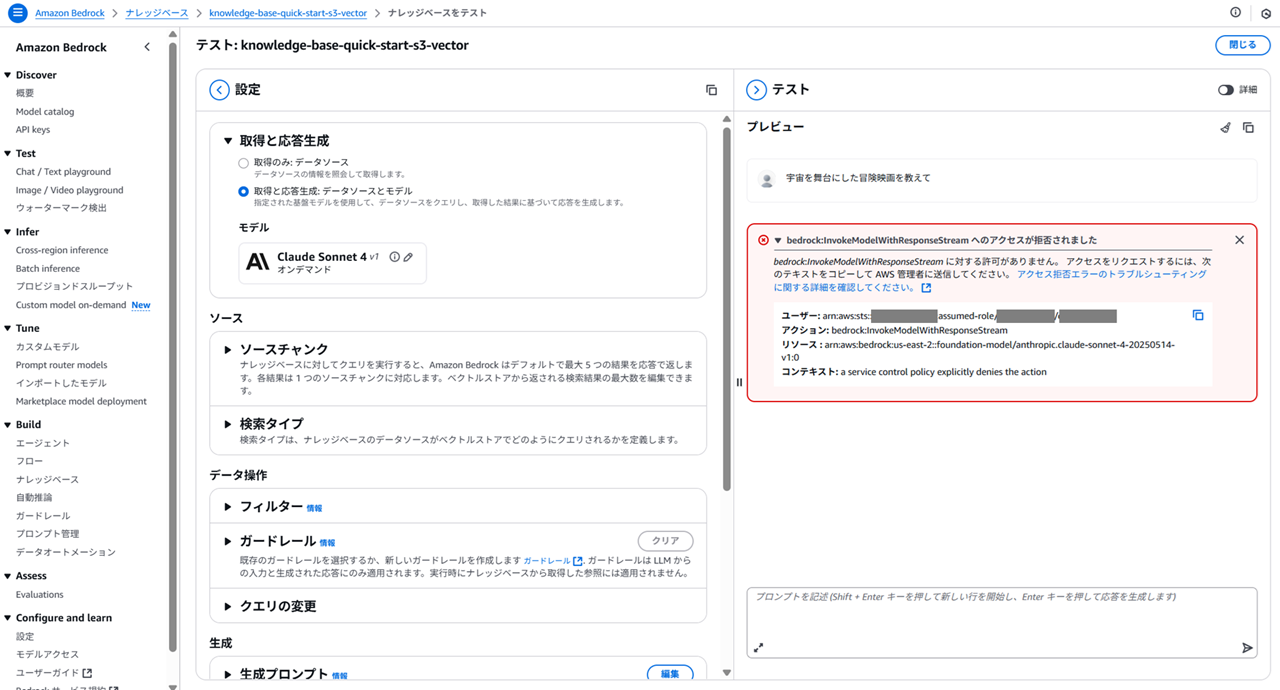
以下のようにエラーになりました。
ユーザー: arn:aws:sts::<この AWS アカウントのアカウント ID>:assumed-role/<ユーザー名>/<ユーザー名>
アクション: bedrock:InvokeModelWithResponseStream
リソース : arn:aws:bedrock:us-east-2::foundation-model/anthropic.claude-sonnet-4-20250514-v1:0
コンテキスト: a service control policy explicitly denies the action
これは、私がクラスメソッドメンバーズの セキュアアカウント リージョン制限 という機能を利用して AWS アカウント自体にリージョン制限をかけているために発生しました。
仕組みとしては Organizations の SCP により、利用可能リージョンを東京・大阪・バージニア北部に制限している形です。
推論プロファイルでは以下のクロスリージョンが使われるとモデル選択時に表示されました。
- US Claude Sonnet 4
この推論プロファイルではどこのリージョンに推論がトラフィックされるのか、以下のドキュメントで確認します。
今回の送信先リージョンはバージニア北部ですので us-east-1 です。
送信先は以下 3 リージョンとなっていました。
- us-east-1(バージニア北部)
- us-east-2(オハイオ)
- us-west-2(オレゴン)
エラーでは リソース : arn:aws:bedrock:us-east-2::foundation-model/anthropic.claude-sonnet-4-20250514-v1:0 となっていましたので、リージョン制限で使用できなくなっているオハイオリージョンへのトラフィックが走ろうとして、エラーになったものと読み取れました。
よって、暫定対応としてクロスリージョン推論を使わない Claude Sonnet 3.5 をテキストモデルとして選択することによりナレッジベースのテストを行いました。

クロスリージョン推論については以下ブログも参照ください。
おわりに
「理屈、仕組み、メリットはなんとなく理解できたが、実際のやり方が分からなず腹落ちできない」 な状態だったのですが、自分で手を動かしたり図を書いたり結果を見たりしてなんとか理解できました。
ベクトル検索についても今回しっかり理解できたと思います。
ベクトルインデックスにベクトルを挿入する際にコーディング開発をせずに検証できたのは手軽でとてもありがたかったです。Knowledge Bases 様様でした。
この RAG 環境は作りっぱなしで置いてあるのですが、S3 Vector が安価であるおかげでコストはかさまずに済んでいます。検証にはありがたいです。
引き続き検証を続けて参ります。
本記事への質問やご要望については画面下部のお問い合わせ 「DevelopersIO について」 からご連絡ください。記事に関してお問い合わせいただけます。
参考











