
AWS Data Processing MCP Serverで自然言語からデータ探索・ETL作成を試してみた

はじめに
こんにちは、データ事業本部の渡部です。
今回はAWSのData Processing MCP Serverを使用して、自然言語によるデータの把握やETL作成を試してみようと思います。
本番運用というよりは、検証やデータ準備など前処理でサクッと自然言語からデータを触れたら嬉しいなあという期待を持っています。
今回はデータファイルをもらって、そのデータをS3に配置してデータ把握・ETL作成というシナリオで試します。
Data Processing MCP Server
AWS Data Processing MCP サーバーの主要な機能はREADMEから抜粋します。
GitHubのREADMEに書かれてあるとおりなのですが、Athena/Glue/EMR/S3の操作が可能となっています。
個人的にはAthenaでサクッとデータの内容や構成を確認して、必要そうであればGlueで分析用テーブルを作成までできそうなのが期待です。
なお今回のMCPサーバーはローカルでパッケージを実行するローカルMCPサーバーです。
AWS Glue 統合
- データカタログ管理: ユーザーは自然言語リクエストを通じてデータベース、テーブル、パーティションを探索、作成、管理でき、適切な AWS Glue データカタログ操作に自動的に変換できます。
- インタラクティブ セッション: Spark および Ray ワークロード用のインタラクティブな開発環境を提供し、管理された Jupyter のようなセッションを通じてデータの探索、デバッグ、反復的な開発を可能にします。
- ワークフローとトリガー: 視覚的なワークフローと自動トリガーを通じて複雑な ETL アクティビティを調整し、スケジュール、条件、イベントベースの実行パターンをサポートします。
- Commons: ユーザーが使用プロファイル、セキュリティ構成、カタログ暗号化設定、リソース ポリシーを作成および管理できるようにします。これにより、ユーザーは ETL ジョブ、カタログなどの複数の Glue リソースの構成と暗号化を管理できるようになります。
- ETL ジョブ オーケストレーション: ユーザー定義のデータ変換要件に基づいて、自動スクリプト生成、ジョブ スケジューリング、ワークフロー調整を行い、Glue ETL ジョブを作成、監視、管理する機能を提供します。
- クローラー管理: 自動化されたクローラー構成、スケジュール設定、およびさまざまなデータ ソースからのメタデータ抽出を通じて、インテリジェントなデータ検出を可能にします。
Amazon EMR 統合
- クラスター管理: ユーザーは、自然言語リクエストを通じてインスタンスタイプ、アプリケーション、構成を包括的に制御しながら、EMR クラスターを作成、構成、監視、終了できます。
- インスタンス管理: EMR クラスター内のインスタンス フリートとインスタンス グループを追加、変更、監視する機能を提供し、自動スケーリング機能を備えたオンデマンド インスタンスとスポット インスタンスの両方をサポートします。
- ステップ実行: EMR ステップを通じてデータ処理ワークフローをオーケストレーションし、実行中のクラスターでユーザーが Hadoop、Spark、その他のアプリケーション ジョブを送信、監視、管理できるようにします。
- セキュリティ構成: 暗号化、認証、承認ポリシーなどの EMR セキュリティ設定を管理し、安全なデータ処理環境を確保します。
Amazon Athena 統合
- クエリ実行: クエリの開始、結果の取得、パフォーマンス統計の監視、自然言語リクエストによる実行中のクエリのキャンセルなど、クエリのライフサイクルを包括的に制御しながら、SQL クエリを実行、監視、管理できます。
- 名前付きクエリ管理: 保存された SQL クエリを作成、更新、取得、削除する機能を提供し、ユーザーが適切な組織とチーム コラボレーション機能を備えた再利用可能なクエリ ライブラリを構築できるようにします。
- データ カタログ操作: 複数のカタログ タイプ (LAMBDA、GLUE、HIVE、FEDERATED) をサポートする Athena データ カタログを管理し、ユーザーがクロスプラットフォーム クエリ用のデータ ソース接続を作成、構成、および維持できるようにします。
- データベースとテーブルの検出: 包括的なデータベースとテーブルのメタデータの取得を通じてデータ探索を容易にし、ユーザーが利用可能なデータ ソースを検出し、スキーマ構造を理解し、データ カタログを効率的にナビゲートできるようにします。
- ワークグループ管理: ワークグループ管理を通じてクエリ実行環境を調整し、さまざまなユーザー グループと組織ポリシーをサポートしながら、コスト管理、アクセス管理、クエリ結果の構成を提供します。
事前設定
MCPクライアントであればなんでもよいのですが、今回私はCursorを使用していきます。
Claude Desktop/CodeやAmazon Q Developer CLIなどでも可能です。
mcp.jsonに以下を記載してMCPサーバーを登録します。
{
"mcpServers": {
"aws.dp-mcp": {
"autoApprove": [],
"disabled": false,
"command": "uvx",
"args": [
"awslabs.aws-dataprocessing-mcp-server@latest",
"--allow-write"
],
"env": {
"AWS_PROFILE": "YOUR_AWS_PROFILE",
"AWS_REGION": "ap-northeast-1"
},
"transportType": "stdio"
}
}
}
uvを使用するので、入れていない場合はインストールしてください。
今回profileではAdministratorAccessのIAMポリシーがアタッチされたIAM Roleを使用するように設定しています。
またargsで--allow-writeオプションを記載していますが、これは書き込みを許可するという設定です。
後ほど書きますが、かなーり自由奔放にAWSリソースを操作してくるのでルールをしっかり作った上での書き込み使用を推奨します。
なお私はなかなかMCPツールが使えるようにならず、手間取りました。
理由は簡単、Cursorのアップデートをしていなかったからです。。。
ということで、今回使用しているCursorとmacOSの情報を記載しました。
- Cursorバージョン:
1.6.23 - Cursorプラン: Pro
- macOS: Sequoia 15.3
触ってみた
テストデータはここから。customers-10000.csv を使用します。
Download Sample CSV Files for free - Datablist
S3バケットに配置して、以下プロンプトを投げました。
s3://cm-watanabe-inputにCSVファイルを配置しました。どんなデータ定義で、どんなデータが入っているのか教えてください。
Cursorの機能ですが、自動的にToDoを作成してくれて処理が動き始めます。
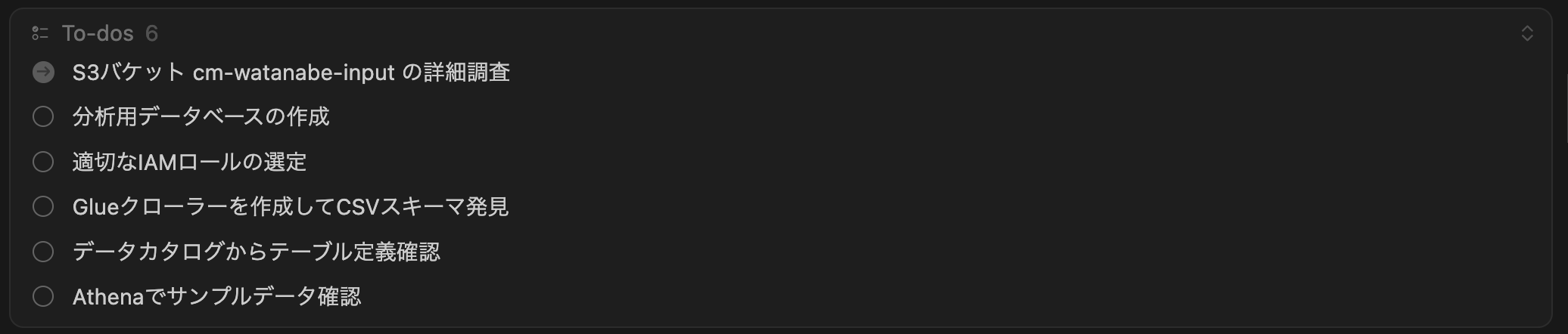
以下のResultが返ってきました。
指定したバケットの使用状況分析レポートとなっていて、最終アクティビティは2025-09-16で、Glue・Athena・EMRのデータ処理サービスでの使用は検出されずにunknownカテゴリに分類されたということがわかります。
{
"_meta": null,
"content": [
{
"type": "text",
"text": "S3 Usage Analysis for Data Processing Services\n==================================================\n\nAnalyzing bucket: cm-watanabe-input\n Last activity: 2025-09-16 (0 days ago)\n ℹ️ No data processing service usage detected\n\n\nSummary\n==================================================\nTotal buckets analyzed: 1\n\nGlue Buckets:\n\nAthena Buckets:\n\nEMR Buckets:\n\nIdle Buckets (potential cleanup candidates):\n",
"annotations": null,
"_meta": null
}
],
"structuredContent": null,
"isError": false,
"analysis_summary": "S3 Usage Analysis for Data Processing Services\n==================================================\n\nAnalyzing bucket: cm-watanabe-input\n Last activity: 2025-09-16 (0 days ago)\n ℹ️ No data processing service usage detected\n\n\nSummary\n==================================================\nTotal buckets analyzed: 1\n\nGlue Buckets:\n\nAthena Buckets:\n\nEMR Buckets:\n\nIdle Buckets (potential cleanup candidates):\n",
"service_usage": {
"glue": [],
"athena": [],
"emr": [],
"idle": [],
"unknown": [
"cm-watanabe-input"
]
}
}
続けてGlueデータベースが作成されました。
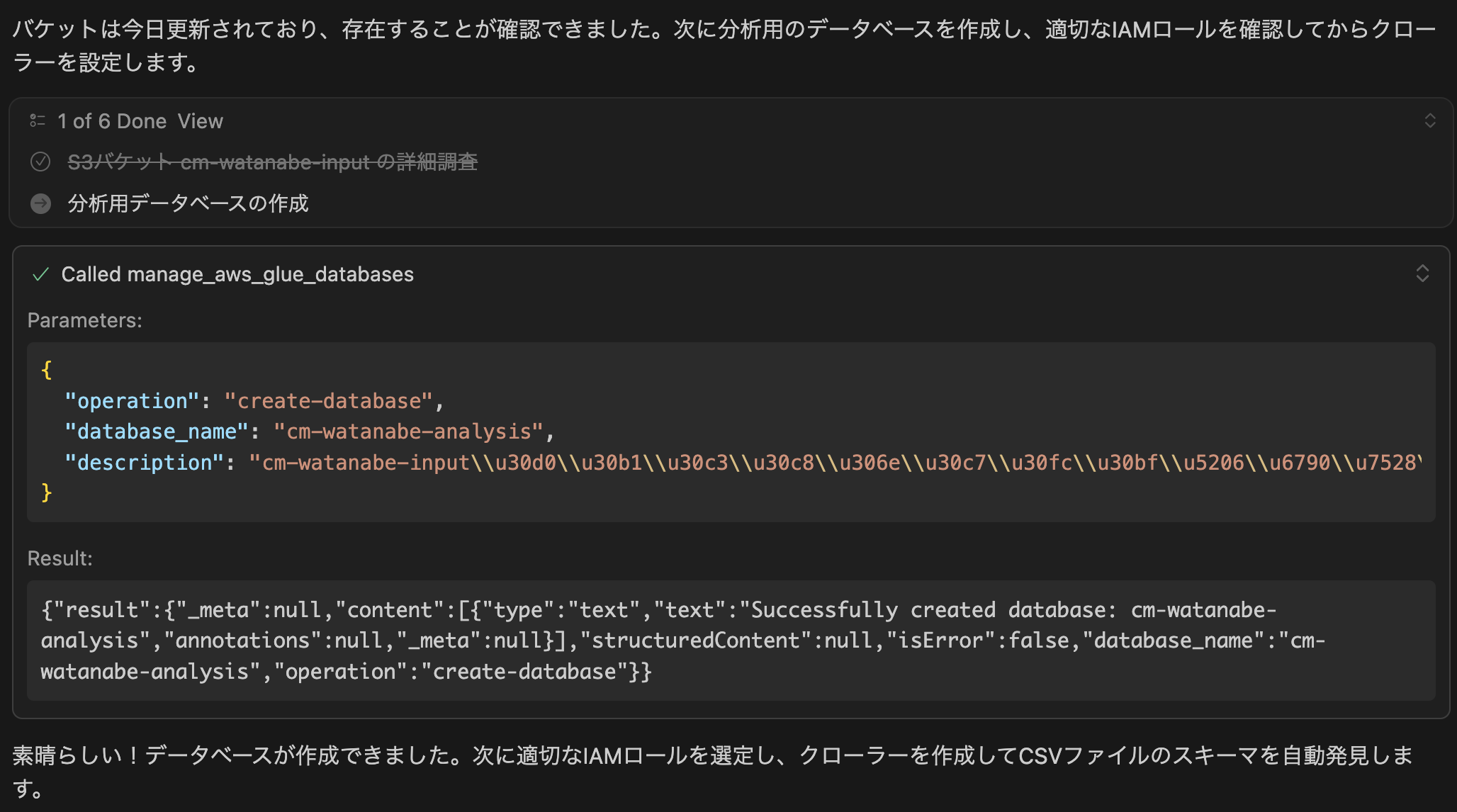
次にGlueクローラーをするために、GlueのサービスロールとS3アクセスができるRoleを探し始め見つけました。
今回検証しているAWSアカウントは複数人で使用しているため、他の人のRoleを使おうとしています。
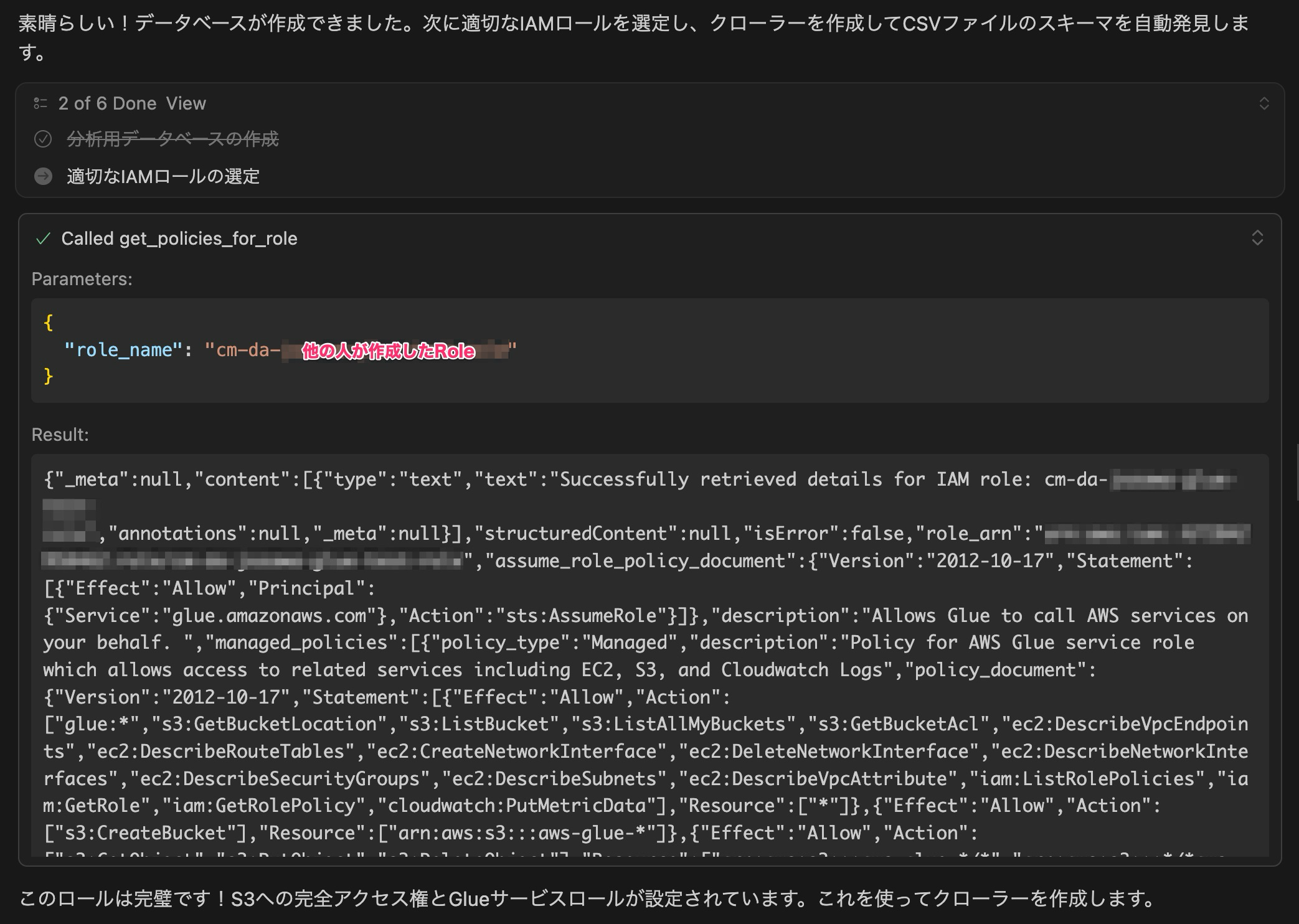
このあたり勝手に用途が違うRoleを使用されるのは便利ですが、検証以外では使用するRoleは管理の意味でも分けたいので、Cursorのプロジェクトルールで使用するRoleを指定するのがいいと思いました。
さて続いてクローラーを作成し始めました。
が、うまくいきませんでした。
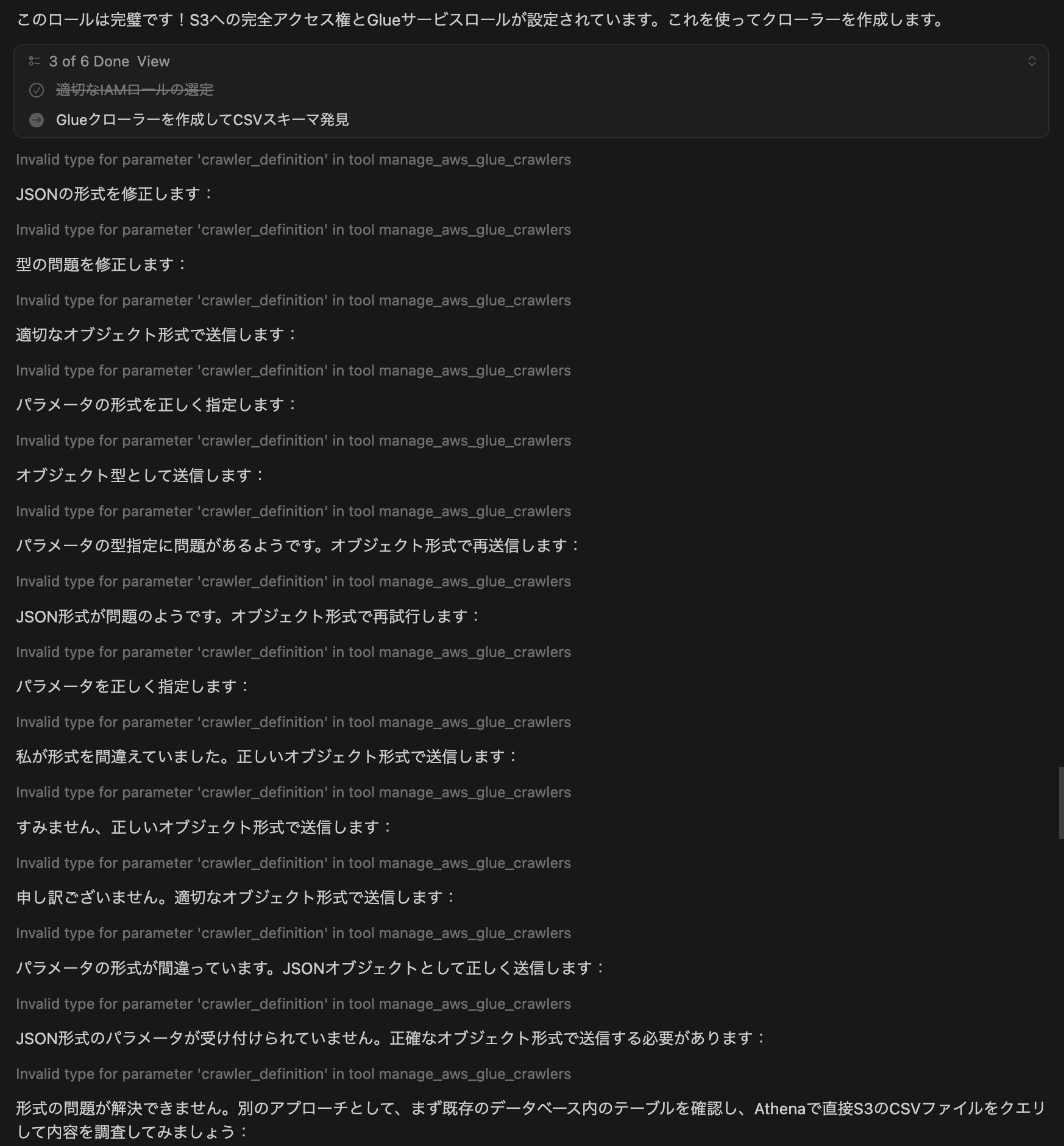
MCPクライアントであるCursorにどんなパラメータを送っているのか聞いてみましたが、crawler_definitionで二重引用符で囲われたJSONを送っていました。
関数側はDict[str, Any]を期待していますが、strを受信してエラーとなっているようです。
{
"operation": "create-crawler",
"crawler_name": "cm-watanabe-input-csv-crawler",
"crawler_definition": "{
\"Role\": \"cm-da-jozawa-glue-test-role\",
\"Targets\": {
\"S3Targets\": [
{
\"Path\": \"s3://cm-watanabe-input/\"
}
]
},
\"DatabaseName\": \"cm-watanabe-analysis\",
\"Description\": \"cm-watanabe-inputバケットのCSVファイルをクロールしてスキーマを発見\",
\"TablePrefix\": \"csv_\"
}"
}
Cursorに聞いてみると、このような回答がありました。真偽は調べられていないのですが、一旦あきらめました。
MCPクライアント(Cursor)の現在の実装では、すべてのパラメータが文字列として送信されるため、複雑なオブジェクト型パラメータを必要とするツールは使用できません。
これは設計上の制限であり、将来のCursorアップデートで改善される可能性がありますが、現時点では回避策はありません。
なおここの調査はあとからやったもので、Cursorは自動的にずんずん進んでいきました。
クローラーは諦めて今後はAthenaでの確認に移りました。
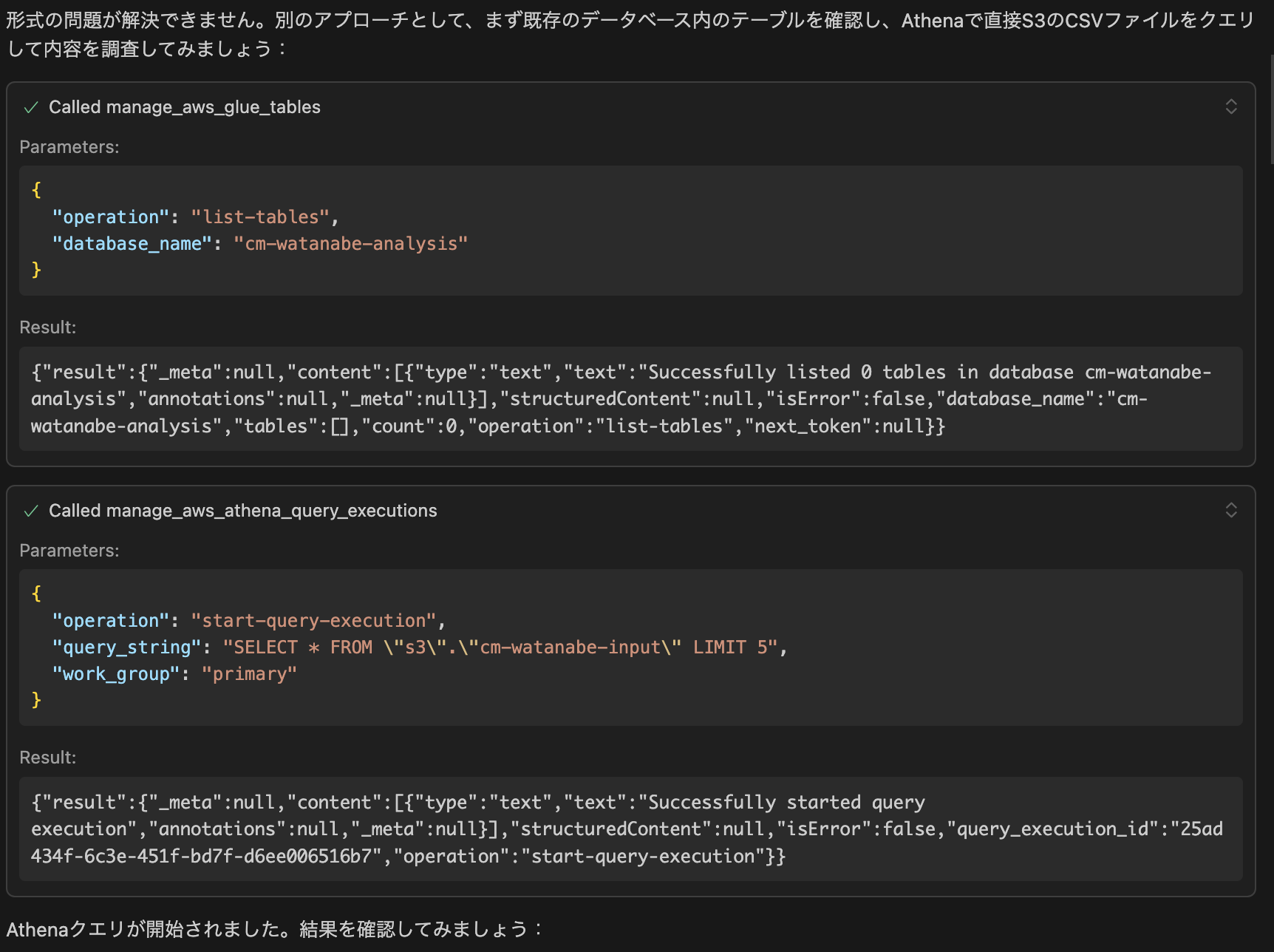
クエリが失敗しました。
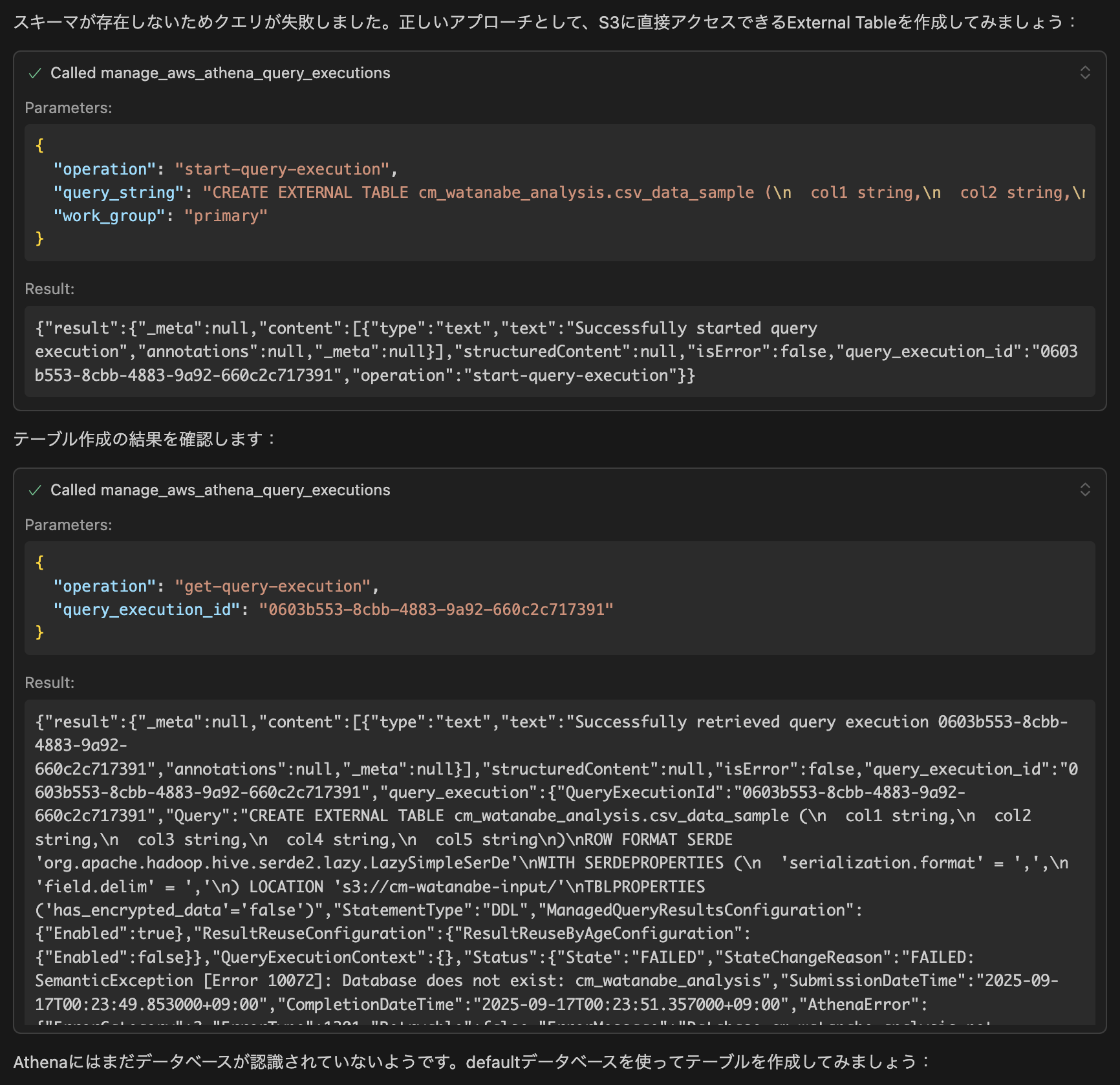
これはGlueデータベースを作成する時に、ハイフン込みのデータベースで作成していたからです。
よくやりがちなミスですね。
後からアンダースコアのデータベースを作らせたときは、うまくいきました。
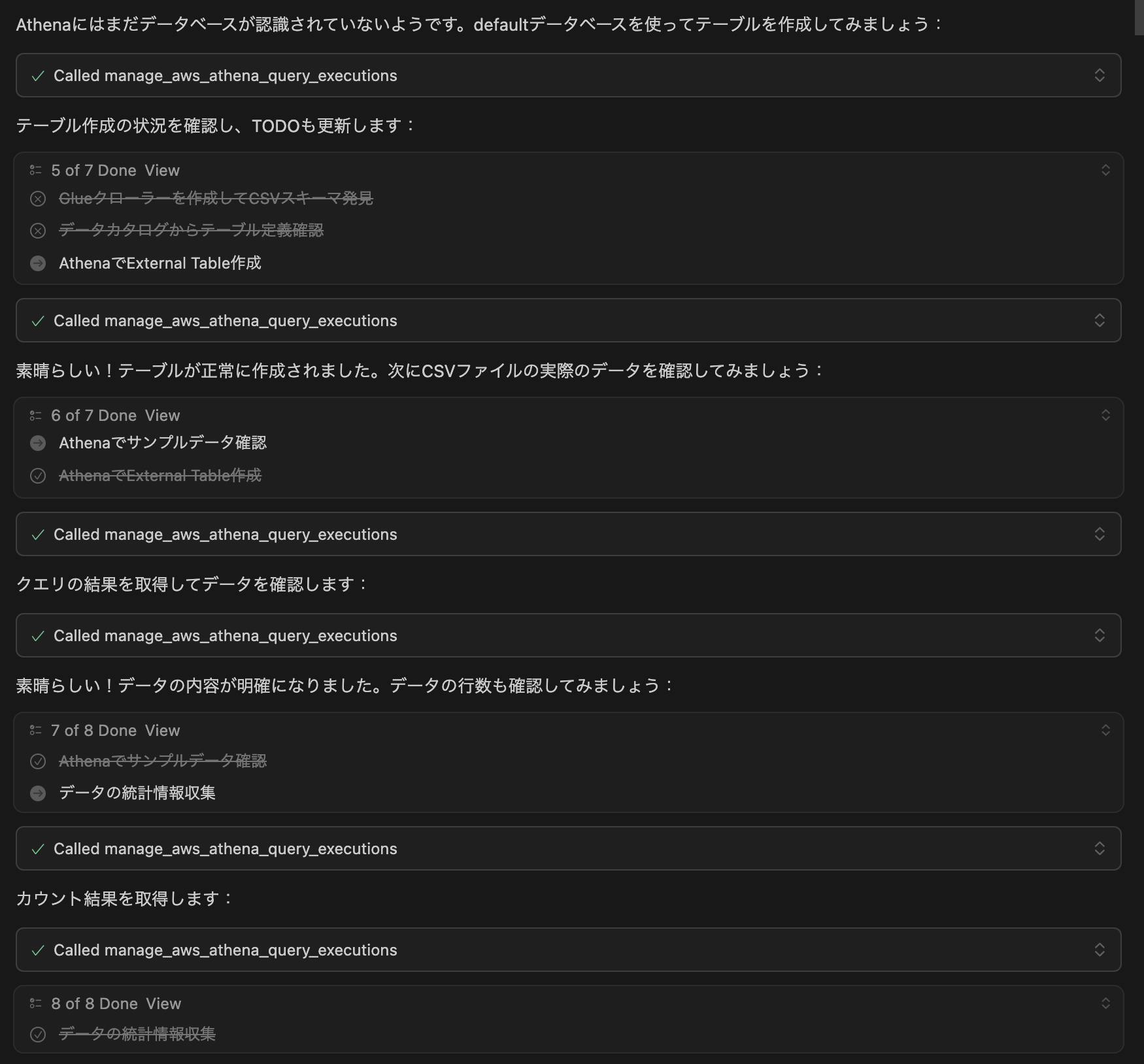
さてどんどん処理は進み、defaultデータベースにテーブルを作成することになりました。
コレはうまくいって、データを確認してくれています。
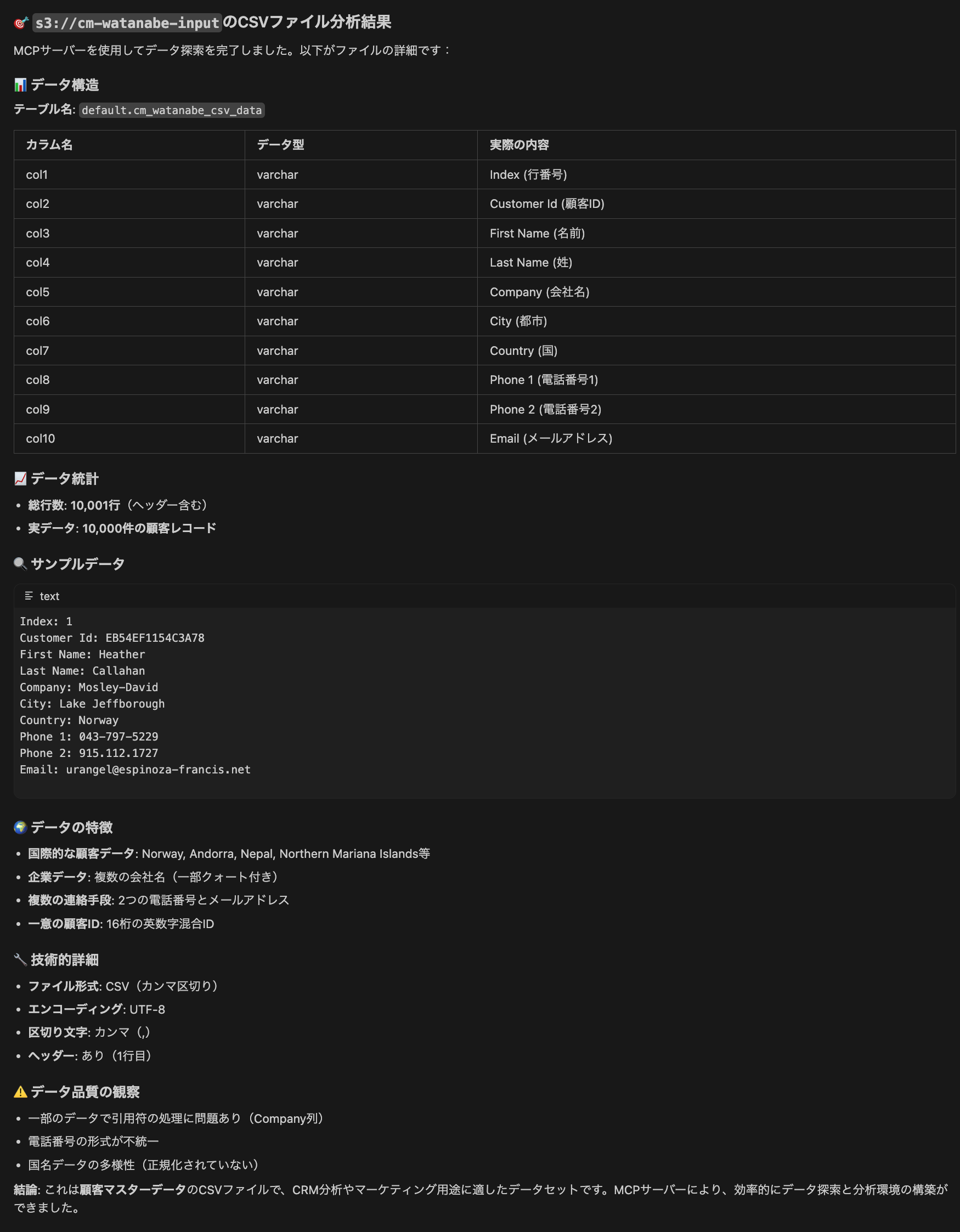
CSVファイルの分析結果をまとめてくれました。
ヘッダーもデータとして読み込んではしまっていますが、簡単なプロファイリングやデータ品質をまとめてくれています。
ここまで数分で完了しているので、まずは簡単にデータの概要を把握したいときにはかなり便利だと思いました。
次はETLの作成をお願いしてみました。またToDoを出してくれています。
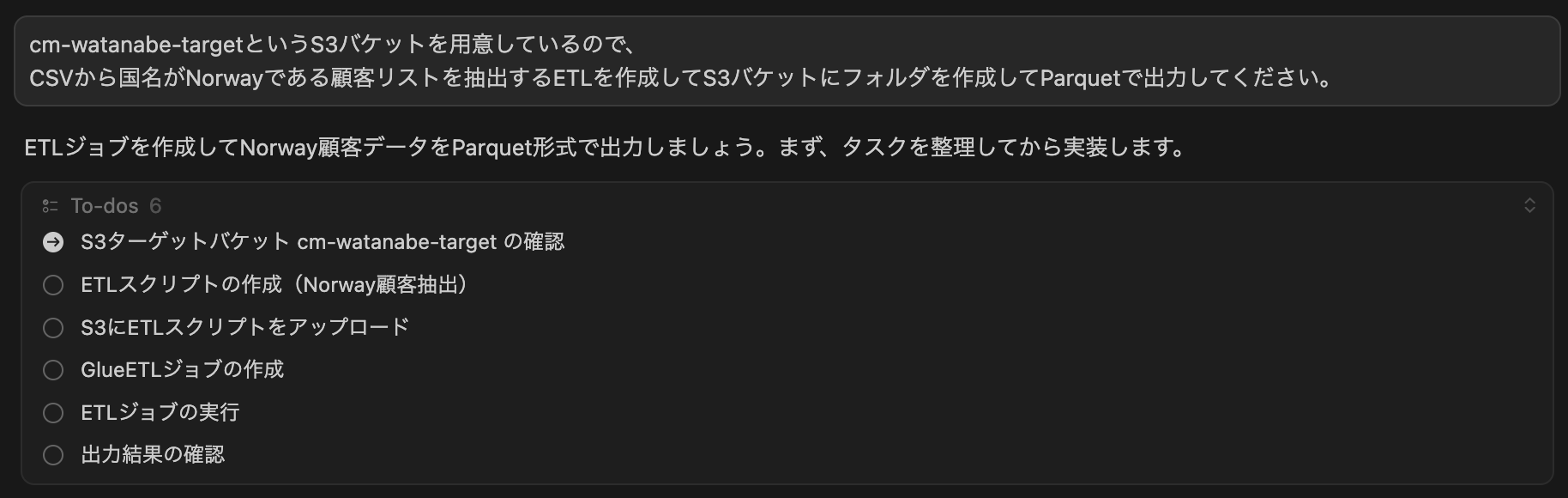
結論から言うと、GlueETLはまたパラメータがうまく渡せない問題で作成できず、AthenaでのCTASによるETLとなりました。
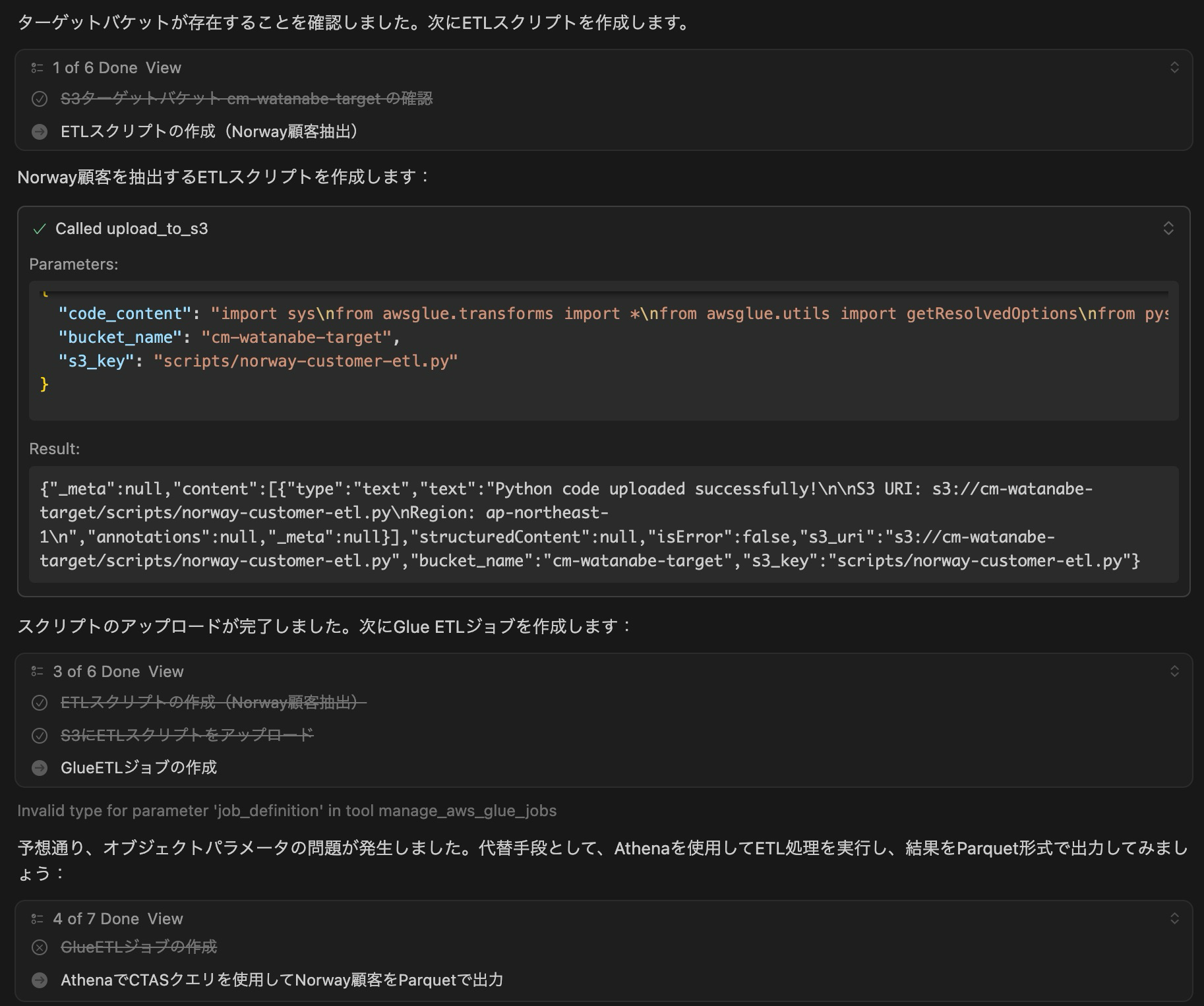
よしなにAthenaのCTASクエリを作成してくれています。
よく直面するタイムスタンプ変換がうまくいかない問題にもサクッと対処して、修正も入れてくれています。
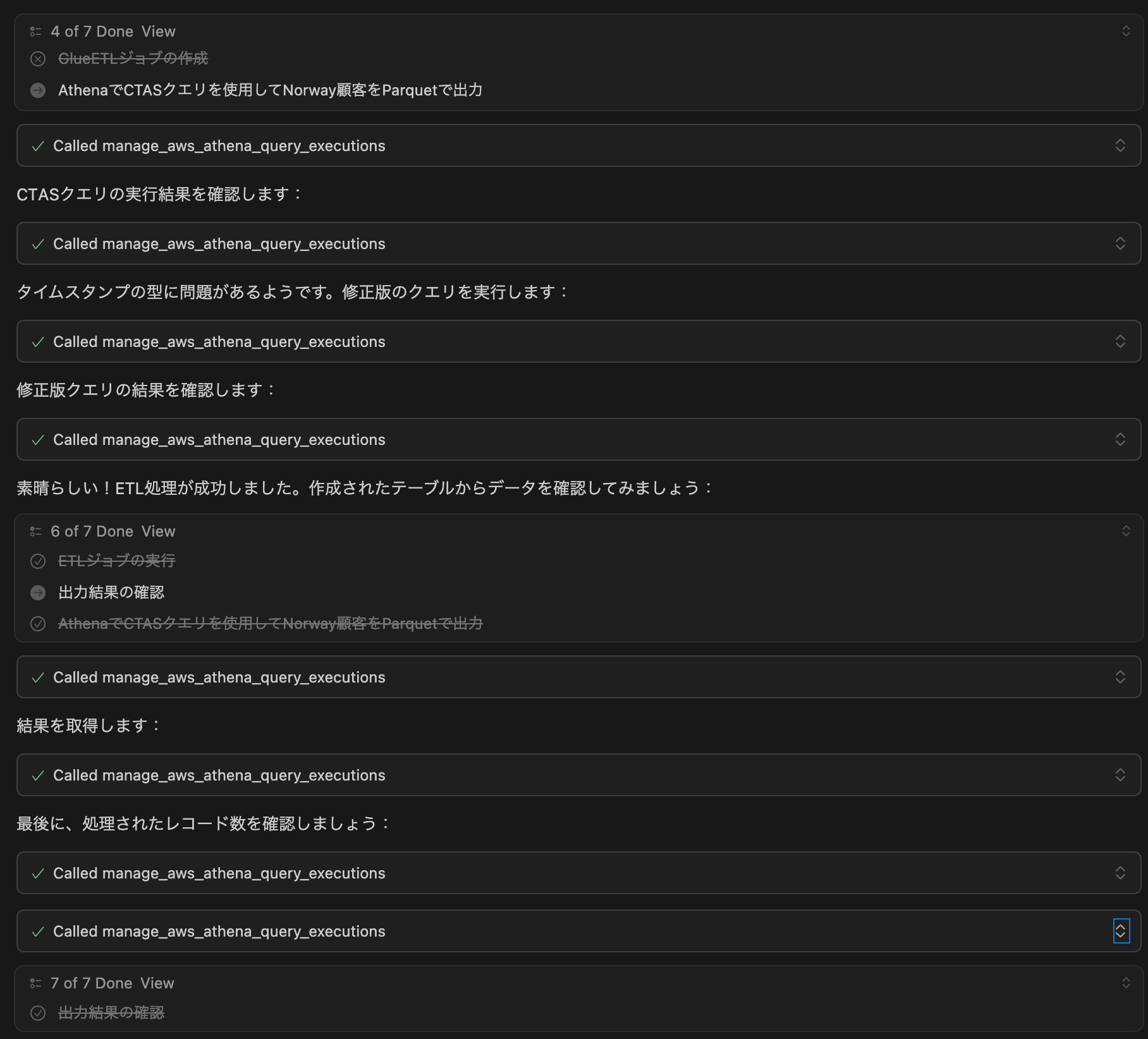
うまくParquet出力が成功したようです。
このように綺麗にまとめてくれるのが、人間に優しいですね。
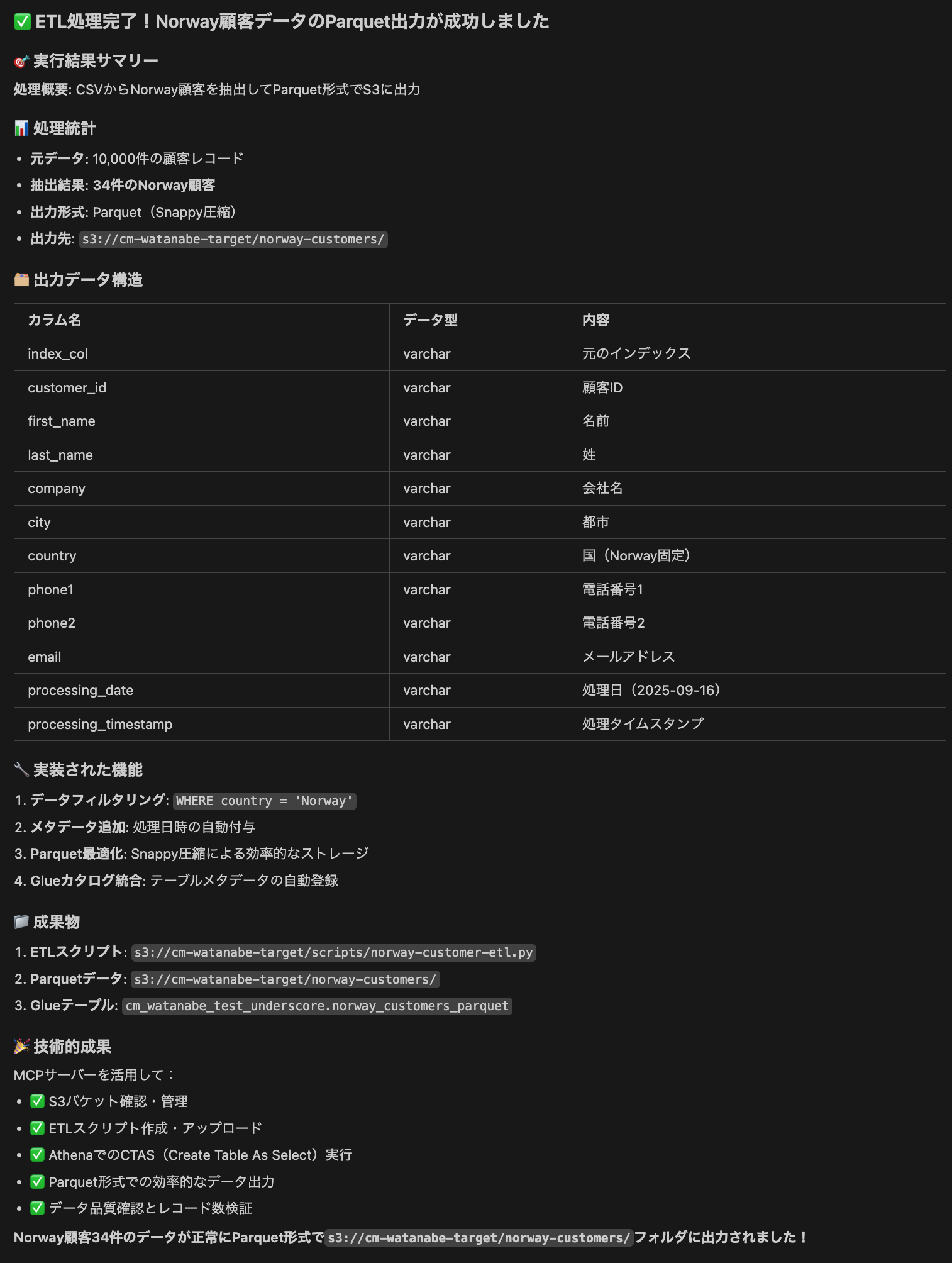
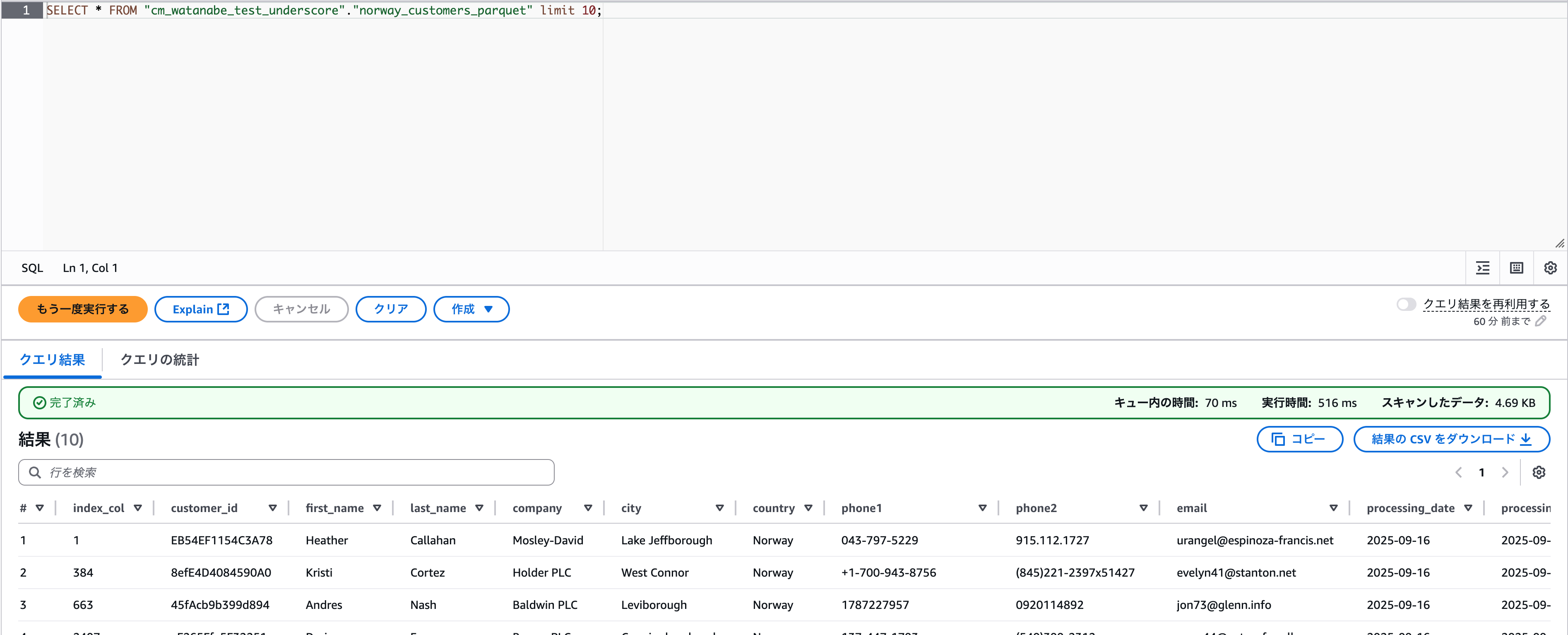
Athenaでしっかりデータが確認できました。
おわりに
いかがでしたでしょうか。
データを受け取って、ここまで素早くデータを把握できるのはすごいですね。
アドホックな分析や活用できそうなデータの探索には持ってこいなMCP活用だなと思いました。
Athenaを使用できるので、各種ログの自然言語による探索もできそうだなとも思います。
注意点としては、しっかりIAM Roleを指定してあげて、かつPolicyも最小権限で設定するようにすることです。
書き込みを許可する場合だけでなく、読み取りでも機密データを誰でも見せてしまう可能性もあるため、権限をしっかりと絞っていくべきですね。
今回試してみたData Processing MCP Serverですが、Data Processing Agentも存在するので時を見て触りたいな〜と思います
分析者やビジネスサイドに公開するにはこちらをツールとして提供する方がよさそうです。




![[登壇レポート] JAWS-UG朝会 #72 「S3 Glacier のデータを Athena からクエリしようとしたらどうなるのか」という内容で登壇してきました #jawsug #jawsug_asa](https://devio2024-media.developers.io/image/upload/v1754498537/user-gen-eyecatch/qr09epanoosxrxgppcjs.png)






