![[アップデート] Amazon OpenSearch Service のログ分析最適化エンジン「Optimized」が利用可能になったので試してみた](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-b383cfad7452c18278d4772c71cae640/70681da1d5cfd4b8d3a7edcc29830075/amazon-opensearch-service?w=3840&fm=webp)
[アップデート] Amazon OpenSearch Service のログ分析最適化エンジン「Optimized」が利用可能になったので試してみた
クラウド事業統括本部の石川です。Amazon OpenSearch Service にログ分析ワークロード専用に設計された新しいエンジンモード「Optimized」が登場しました。ログ分析に利用しているユーザーや企業にとっては、非常に大きなアップデートと言え、めっちゃ良さそうです。実際にドメインを作成してログの投入から PPL / SQL クエリまで試してみました。
ログ分析ワークロード専用 Optimized エンジンとは
Optimized エンジンは、Amazon OpenSearch Service のドメイン作成時に選択できる新しいエンジンモードです。従来のエンジンは General Purpose という位置付けになり、コンソール・API・セキュリティモデル・ネットワーク設定はそのまま共通で利用できます。
クラウドネイティブアーキテクチャや AI ワークロードの普及に伴いログ量が増え続ける中、日常的な運用では集計やトレンド分析が中心となる一方、インシデント調査では精密なテキスト検索が必要になります。今回発表された Optimized エンジンは、この両方を単一のマネージドサービスで提供するログ分析特化のエンジンモードです。
AWS の発表によると、内部ベンチマークで従来比最大 4 倍の価格性能を実現し、列指向ストレージによりストレージ使用量を最大 70% 削減(同一コストで最大 3 倍のデータ保持が可能)、同一ハードウェアで最大 2 倍のインジェストスループットと 2 倍高速な分析クエリを実現するとのことです。追加料金はありません。
Optimized エンジン の処理の流れ
公式ドキュメントによると、内部では操作ごとに最適なデータ構造を使い分けるアーキテクチャを採用しています。ログデータは Apache Parquet(列指向フォーマット)に保存され、検索可能なフィールドは Lucene 転置インデックスにも保存されます。クエリはコーディネーターノード上の Apache Calcite が解析・最適化し、集計などの分析処理は Rust ベースのベクトル化実行エンジンである DataFusion が、全文検索は Lucene が実行します。両者はクエリ実行中に連携できるため、ログ本文を全文検索して結果を集計するようなクエリも 1 つのステートメントで実行できます。
利用にあたっての主な前提条件は以下のとおりです。
- OpenSearch 3.5 以上の新規ドメインでのみ利用可能(既存ドメインへの後からの適用は不可、作成後のエンジンモード変更も不可)
- ホットティアのインスタンスは OpenSearch Optimized Instance(OR1、OR2、OM2)のみ
- 認証は IAM および IAM Identity Center のみ(Amazon Cognito は非対応)
- 可視化は OpenSearch UI のみ(OpenSearch Dashboards は非対応)
- クエリ言語は PPL(Piped Processing Language)と SQL(DSL クエリ API はリリース時点で非対応)
やってみた
前提条件
- リージョン: ap-northeast-1(東京)
- インスタンスタイプ: or2.medium.search ×1(東京リージョンのオンデマンド料金は執筆時点で $0.121/時間)
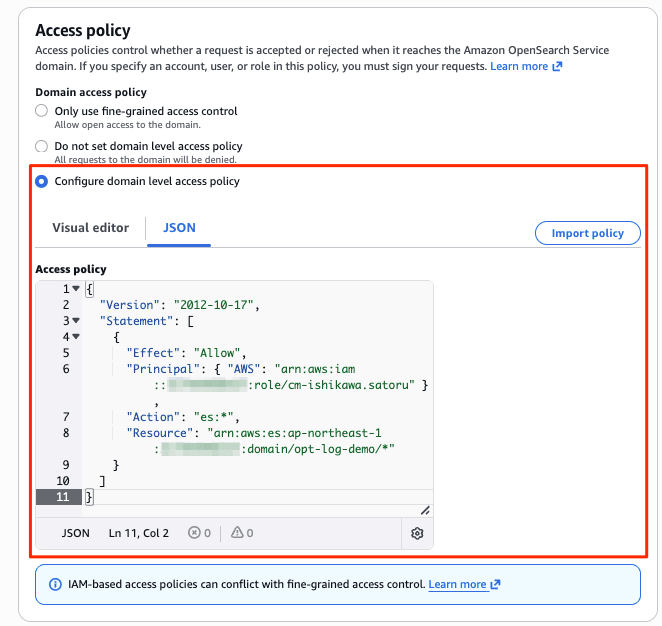
- 専用ロールの新規作成を省くため、AWS アカウントと、既存のログインロールをそのまま FGAC マスターに使いました。
システム構成
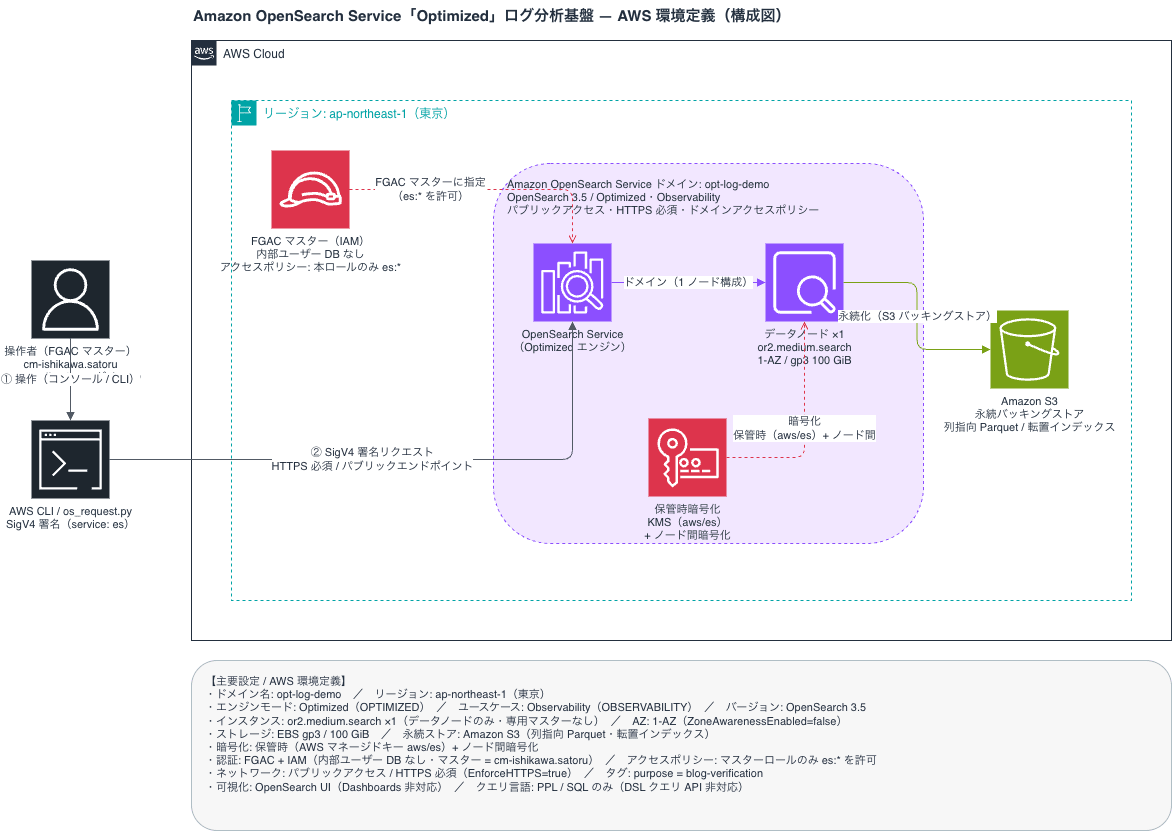
ドメインの作成
マネジメントコンソールのメニュー[Create Domain] から新たにドメインを作成しました。新しく追加されたObservabilityと Optimized を指定して、Optimized エンジンのドメインを作成します。認証は IAM のみのため、ファイングレインドアクセスコントロール(FGAC)のマスターユーザーに IAM ロールを指定しています。(ドメインの作成画面は非常に長いのでデフォルトの項目について割愛します。)
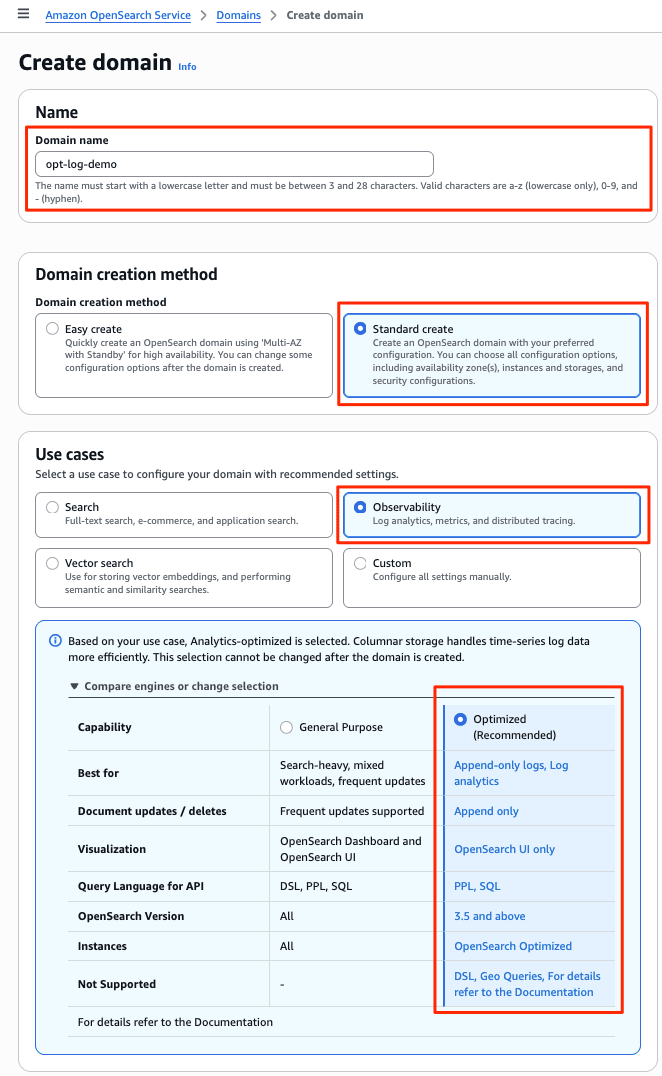
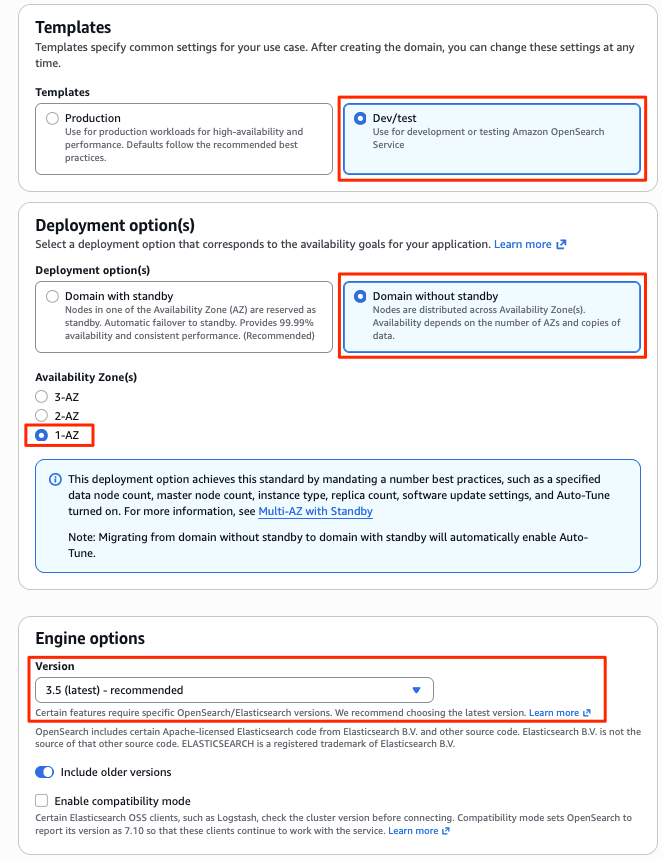
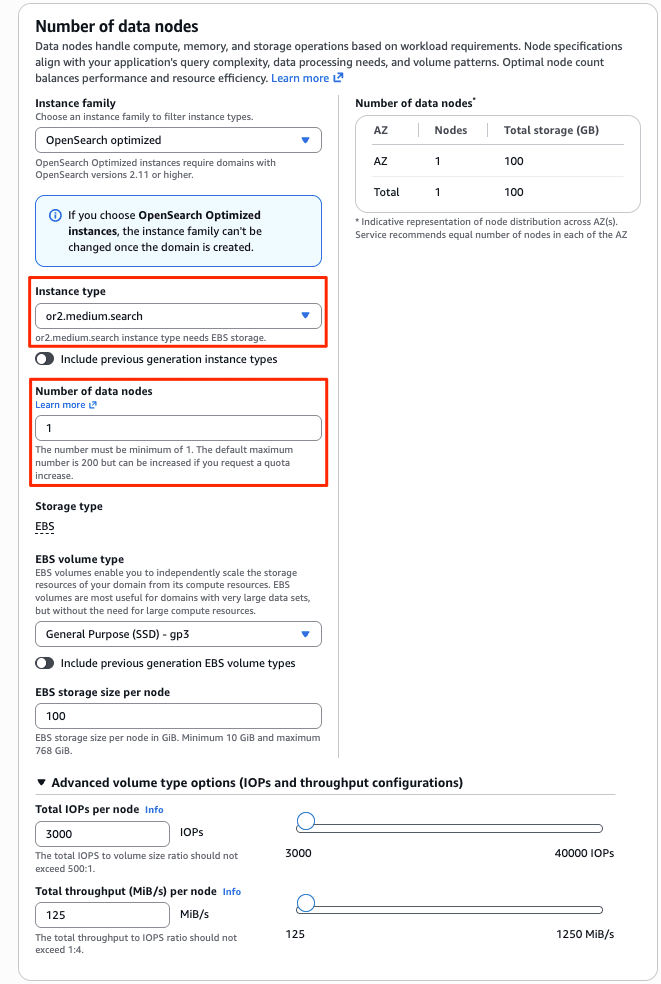

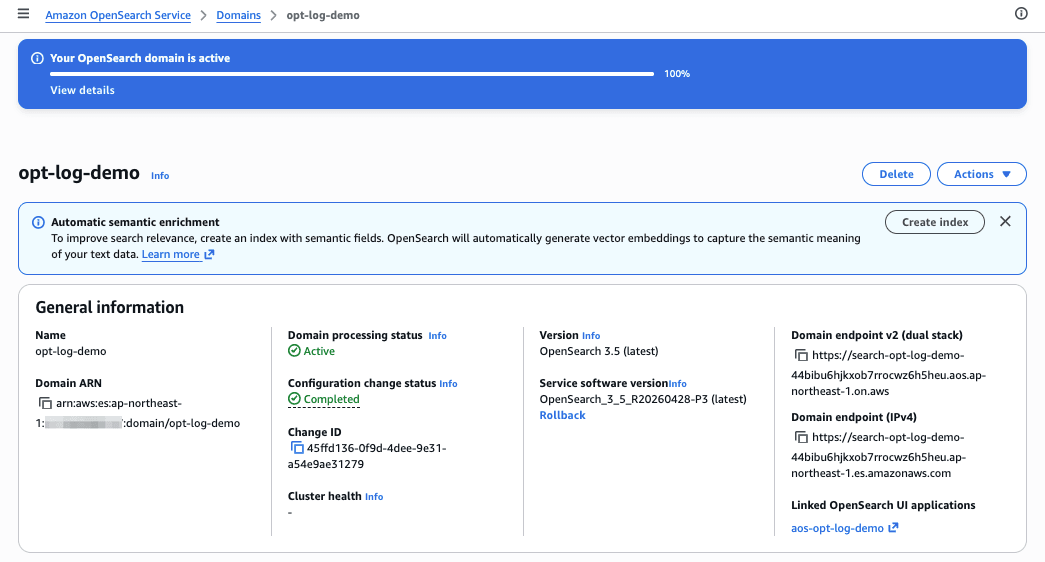
約15分ほどで、新しいOptimized エンジンのドメインopt-log-demoとOpenSearch UI (Dashboards)aos-opt-log-demoがデプロイされました。
動作確認用のヘルパーコマンド「os_request.py」
以降の動作確認をするための ヘルパーコマンドos_request.pyを用意しました。Amazon OpenSearch Service のドメインに、SigV4 署名付きで HTTP リクエストを送るための CLI ツールです。OpenSearch の REST API を、AWS の認証を通しつつ curl 感覚で叩けるようにする小さなラッパーになっています。
os_request.py
#!/usr/bin/env python3
"""SigV4 署名付きで Amazon OpenSearch Service ドメインに HTTP リクエストを送る。
usage: os_request.py <METHOD> <https://endpoint/path> [--data-file FILE | --data JSON] [--region REGION]
"""
import argparse
import json
import sys
import boto3
from botocore.awsrequest import AWSRequest
from botocore.auth import SigV4Auth
import urllib.request
import urllib.error
def main():
p = argparse.ArgumentParser()
p.add_argument("method")
p.add_argument("url")
p.add_argument("--data-file")
p.add_argument("--data")
p.add_argument("--region", default="ap-northeast-1")
p.add_argument("--content-type", default="application/json")
args = p.parse_args()
body = None
if args.data_file:
with open(args.data_file, "rb") as f:
body = f.read()
elif args.data:
body = args.data.encode("utf-8")
session = boto3.Session()
creds = session.get_credentials().get_frozen_credentials()
req = AWSRequest(method=args.method, url=args.url, data=body,
headers={"Content-Type": args.content_type})
SigV4Auth(creds, "es", args.region).add_auth(req)
http_req = urllib.request.Request(args.url, data=body, method=args.method,
headers=dict(req.headers))
try:
with urllib.request.urlopen(http_req, timeout=120) as resp:
print(f"HTTP {resp.status}", file=sys.stderr)
out = resp.read().decode("utf-8")
except urllib.error.HTTPError as e:
print(f"HTTP {e.code}", file=sys.stderr)
out = e.read().decode("utf-8")
print(out)
sys.exit(1)
try:
print(json.dumps(json.loads(out), indent=2, ensure_ascii=False))
except json.JSONDecodeError:
print(out)
if __name__ == "__main__":
main()
クラスタへの疎通確認
クラスタ名やバージョン情報("number": "3.5.x")が返り、署名・アクセスポリシー・FGAC がすべて正しく通っています。
% cd verification
% export ENDPOINT="https://search-opt-log-demo-44bibu6hjkxob7rrocwz6h5heu.ap-northeast-1.es.amazonaws.com"
% python os_request.py GET "$ENDPOINT/"
HTTP 200
{
"name": "4a0bb206066b32cc1b4ebcdc001ca4c6",
"cluster_name": "123456789012:opt-log-demo",
"cluster_uuid": "OXTdUVltREy4zfMkcqP8kg",
"version": {
"distribution": "opensearch",
"number": "3.5.0",
"build_type": "tar",
"build_hash": "unknown",
"build_date": "2026-06-26T11:38:38.041493137Z",
"build_snapshot": false,
"lucene_version": "10.3.2",
"minimum_wire_compatibility_version": "2.19.0",
"minimum_index_compatibility_version": "2.0.0"
},
"tagline": "The OpenSearch Project: https://opensearch.org/"
}
インデックスの作成
Optimized エンジンがサポートするフィールド型(date / keyword / integer / text 等)で、アプリケーションログ向けの明示マッピングを作成します(verification/mapping.json をそのまま使用)。
% python os_request.py PUT "$ENDPOINT/app-logs" --data-file mapping.json
HTTP 200
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "app-logs"
}
mapping.json
{
"mappings": {
"properties": {
"@timestamp": { "type": "date" },
"level": { "type": "keyword" },
"service": { "type": "keyword" },
"host": { "type": "keyword" },
"status_code": { "type": "integer" },
"latency_ms": { "type": "integer" },
"message": { "type": "text" }
}
}
}
サンプルログの投入(Bulk API)
gen_logs.pyを用いてサンプルデータを生成し、既存の Bulk API(_bulk)で投入します。
gen_logs.py
#!/usr/bin/env python3
"""アプリケーションログ風のサンプルデータを OpenSearch Bulk API 形式で生成する。"""
import json
import random
import sys
from datetime import datetime, timedelta, timezone
random.seed(42)
SERVICES = ["checkout-api", "payment-api", "inventory-api", "auth-api", "search-api"]
HOSTS = [f"ip-10-0-{i}-{j}" for i in (1, 2, 3) for j in (11, 12, 13)]
LEVELS = ["INFO"] * 80 + ["WARN"] * 12 + ["ERROR"] * 7 + ["DEBUG"] * 1
INFO_MSG = [
"request completed successfully",
"user session refreshed",
"cache hit for product catalog",
"healthcheck ok",
"order accepted and queued",
]
WARN_MSG = [
"slow query detected on orders table",
"retrying upstream call after transient failure",
"connection pool utilization above 80 percent",
"response latency above threshold",
]
ERROR_MSG = [
"connection timeout to payment gateway",
"java.lang.OutOfMemoryError: Java heap space",
"failed to acquire database connection",
"upstream service returned 503 Service Unavailable",
"deadline exceeded while calling inventory service",
]
def main(count: int, index: str):
now = datetime(2026, 7, 3, 12, 0, 0, tzinfo=timezone.utc)
lines = []
for i in range(count):
level = random.choice(LEVELS)
if level == "ERROR":
msg = random.choice(ERROR_MSG)
status = random.choice([500, 502, 503, 504])
latency = random.randint(800, 30000)
elif level == "WARN":
msg = random.choice(WARN_MSG)
status = random.choice([200, 200, 429])
latency = random.randint(300, 5000)
else:
msg = random.choice(INFO_MSG)
status = 200
latency = random.randint(5, 300)
ts = now - timedelta(seconds=random.randint(0, 6 * 3600))
doc = {
"@timestamp": ts.strftime("%Y-%m-%dT%H:%M:%S.000Z"),
"level": level,
"service": random.choice(SERVICES),
"host": random.choice(HOSTS),
"status_code": status,
"latency_ms": latency,
"message": msg,
}
lines.append(json.dumps({"index": {"_index": index}}))
lines.append(json.dumps(doc, ensure_ascii=False))
sys.stdout.write("\n".join(lines) + "\n")
if __name__ == "__main__":
count = int(sys.argv[1]) if len(sys.argv) > 1 else 5000
index = sys.argv[2] if len(sys.argv) > 2 else "app-logs"
main(count, index)
# サンプル 5,000 件を生成
% python gen_logs.py 5000 app-logs > bulk_logs.ndjson
# Bulk 投入(NDJSON は Content-Type を x-ndjson にする)
% python os_request.py POST "$ENDPOINT/_bulk?refresh=true" \
--data-file bulk_logs.ndjson \
--content-type application/x-ndjson
{
[
{
"index": {
"_index": "app-logs",
"_id": "MmVPMp8BthanSRu9Q92G",
"_version": 1,
"result": "created",
"forced_refresh": true,
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 980,
"_primary_term": 1,
"status": 201
}
},
:
:
{
"index": {
"_index": "app-logs",
"_id": "M2VPMp8BthanSRu9Q92G",
"_version": 1,
"result": "created",
"forced_refresh": true,
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 981,
"_primary_term": 1,
"status": 201
}
}
]
}
PPL(Piped Processing Language) でクエリ
_plugins/_ppl エンドポイントに PPL を投げます。
件数確認
最初はレコード件数を確認します。
% python os_request.py POST "$ENDPOINT/_plugins/_ppl" \
--data '{"query": "source=app-logs | stats count()"}'
HTTP 200
{
"schema": [
{
"name": "count()",
"type": "bigint"
}
],
"datarows": [
[
5000
]
],
"total": 1,
"size": 1
}
ログレベル別集計
ログレベル毎の件数が取得できます。
% python os_request.py POST "$ENDPOINT/_plugins/_ppl" \
--data '{"query": "source=app-logs | stats count() by level"}'
HTTP 200
{
"schema": [
{
"name": "count()",
"type": "bigint"
},
{
"name": "level",
"type": "string"
}
],
"datarows": [
[
597,
"WARN"
],
[
3959,
"INFO"
],
[
51,
"DEBUG"
],
[
393,
"ERROR"
]
],
"total": 4,
"size": 4
}
全文検索
match() と集計の組み合わせて、message に timeout を含むログをサービス別集計しました。
% python os_request.py POST "$ENDPOINT/_plugins/_ppl" \
--data "{\"query\": \"source=app-logs | where match(message, 'timeout') | stats count() by service\"}"
HTTP 200
{
"schema": [
{
"name": "count()",
"type": "bigint"
},
{
"name": "service",
"type": "string"
}
],
"datarows": [
[
12,
"payment-api"
],
[
13,
"auth-api"
],
[
13,
"inventory-api"
],
[
15,
"search-api"
],
[
19,
"checkout-api"
]
],
"total": 5,
"size": 5
}
SQL でクエリ
_plugins/_sql エンドポイントでは SQL が使えます。全文検索述語 match() と GROUP BY 集計を 1 クエリで組み合わせました。status_code >= 500 のステータス別件数・最大レイテンシが返れば、分析クエリが機能しています。
% python os_request.py POST "$ENDPOINT/_plugins/_sql" \
--data '{"query": "SELECT status_code, count(*) AS cnt, max(latency_ms) AS max_latency FROM `app-logs` WHERE status_code >= 500 GROUP BY status_code ORDER BY cnt DESC"}'
HTTP 200
{
"schema": [
{
"name": "status_code",
"type": "integer"
},
{
"name": "cnt",
"type": "long"
},
{
"name": "max_latency",
"type": "integer"
}
],
"datarows": [
[
502,
105,
29784
],
[
504,
99,
29639
],
[
503,
98,
29646
],
[
500,
91,
29745
]
],
"total": 4,
"size": 4
}
補足: 非対応 API の挙動についても確認する
DSL(Domain Specific Language) の _search API がどうなるかも確認しておきます。ドキュメントの記載どおり、DSL クエリは利用できません。
% python os_request.py POST "$ENDPOINT/app-logs/_search"
HTTP 404
{"message":"This API is not supported with Optimized Engine."}
一方、_cat/indices は動作しました。
% python os_request.py GET "$ENDPOINT/_cat/indices?v"
HTTP 200
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open app-logs 110100rNGWnLdVRIeFNNYByYbhaQ 5 1 5000 0 248.5kb 248.5kb
投入前の NDJSON ファイルが約 1.1MB だったのに対し、store.size は 246KB でした。今回は 5,000 件の小規模データのため公式の「最大 70% 削減」とは条件が異なりますが、列指向フォーマットによる圧縮の効果がうかがえます。
ブラウザからOpenSearch UI でドメインを確認
OpenSearch UIも作成しました。Optimized ドメインの可視化は OpenSearch UIで行います。なお、従来の OpenSearch Dashboards は非対応です。EndpointのURLからアクセスします。
OpenSearch UI アプリケーションは既定で私の AWS コンソールのログイン ID(IAM)で認証され、アクセスできます。
考察
実際に試して確認できたこと、注意が必要と感じたことを整理します。
確認できたこと
- データ投入は既存の Bulk API がそのまま使えました。取り込みパイプラインの変更は不要です
- PPL / SQL とも、全文検索述語(
match())と集計(GROUP BY、avg() 等)を同一クエリで組み合わせられることを確認できました
注意が必要なこと
_search(DSL)だけでなく_countなどの周辺 API も「This API is not supported with Optimized Engine.」となります。既存のツールや SDK がこれらの API に依存している場合、General Purpose エンジンからの移行では動作しません。クエリ経路を PPL / SQL に寄せられるかが移行判断のポイントになりそうですmatch()による全文検索は Lucene のトークナイズ規則に従います。「java.lang.OutOfMemoryError」のようなピリオド連結の文字列は 1 トークン扱いとなり、部分文字列ではヒットしないため、検索語の選び方には従来同様の注意が必要です- エンジンモードはドメイン作成時のみ指定でき、後から変更できません。既存ドメインの移行には新規ドメインの作成と取り込み先の切り替えが必要です
- ベクトル検索、ネストフィールド、Painless スクリプト、ドキュメント削除、地理空間クエリ、手動スナップショットなどは非対応です。全文検索の関連度ランキングに依存するワークロードには General Purpose エンジンが引き続き推奨されています
最後に
Amazon OpenSearch Service のログ分析最適化エンジン「Optimized」を、ドメイン作成からログ投入・PPL / SQL クエリまで一通り試しました。追加料金なしで利用でき、既存の取り込み経路を維持したまま、集計・トレンド分析と全文検索を 1 つのドメインで実行できることを確認できました。
一方で、クエリは PPL / SQL 前提となり DSL 系 API は利用できないため、導入時は既存のクエリ資産やツールとの互換性確認が重要です。ログ量の増加で OpenSearch のコストにお悩みの方は、新規ドメインでの検証から始めてみてはいかがでしょうか。











