
AgentCore GatewayのInference Targetを試してみた
はじめに
こんにちは、業務スーパーも好きなコンサル部の神野(じんの)です。
皆さん、AgentCore Gateway作成時のコンソール見ることありますか??最近色々変わってきていますよね!(ガンガン更新が入ってびっくりする毎日です・・・)
特にターゲット追加する時にnewがいっぱいあって気になりました。
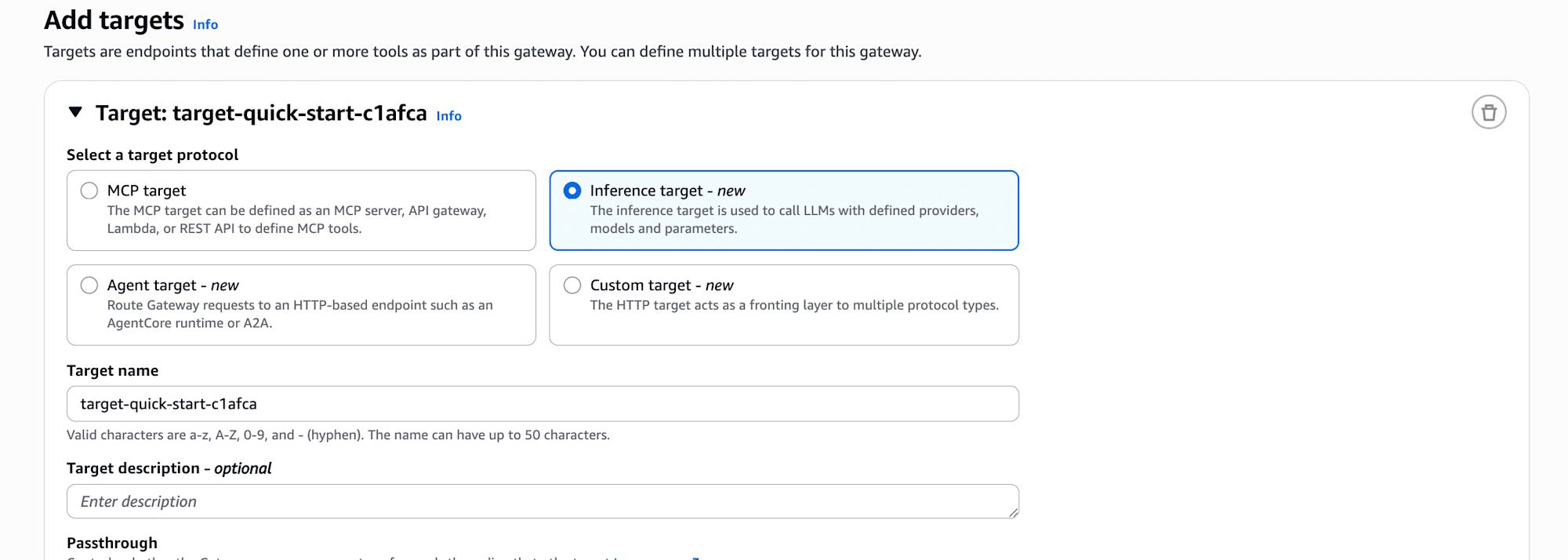
特に気になったのがInference Targetです・・・!
これまでGatewayといえば、Lambda関数やOpenAPIをMCPツールに変換するものというイメージでしたが、Inference Targetを使うとLLMプロバイダーそのものをGatewayの背後に置けるようになるみたいです。
例えばAzure側のAPIキーをAgentCore Identityに登録しておけば、クライアントはGatewayのエンドポイントだけを知っていればよく、プロバイダーのAPIキーを配布する必要がなくなります。LiteLLMのように、アプリから見た推論エンドポイントを抽象化するイメージですね。面白いですね・・・!!!
今回はAzure AI Foundry上のDeepSeek-V4-FlashをAPIキー登録で追加し、さらにBedrockも同じGatewayから使えるようにして、1つのエンドポイントで2つのプロバイダーを呼び分けるところまでコンソールから実際にやってみます!
Inference targetの挙動
まずInference targetがどういう作りなのかを整理しておきます。
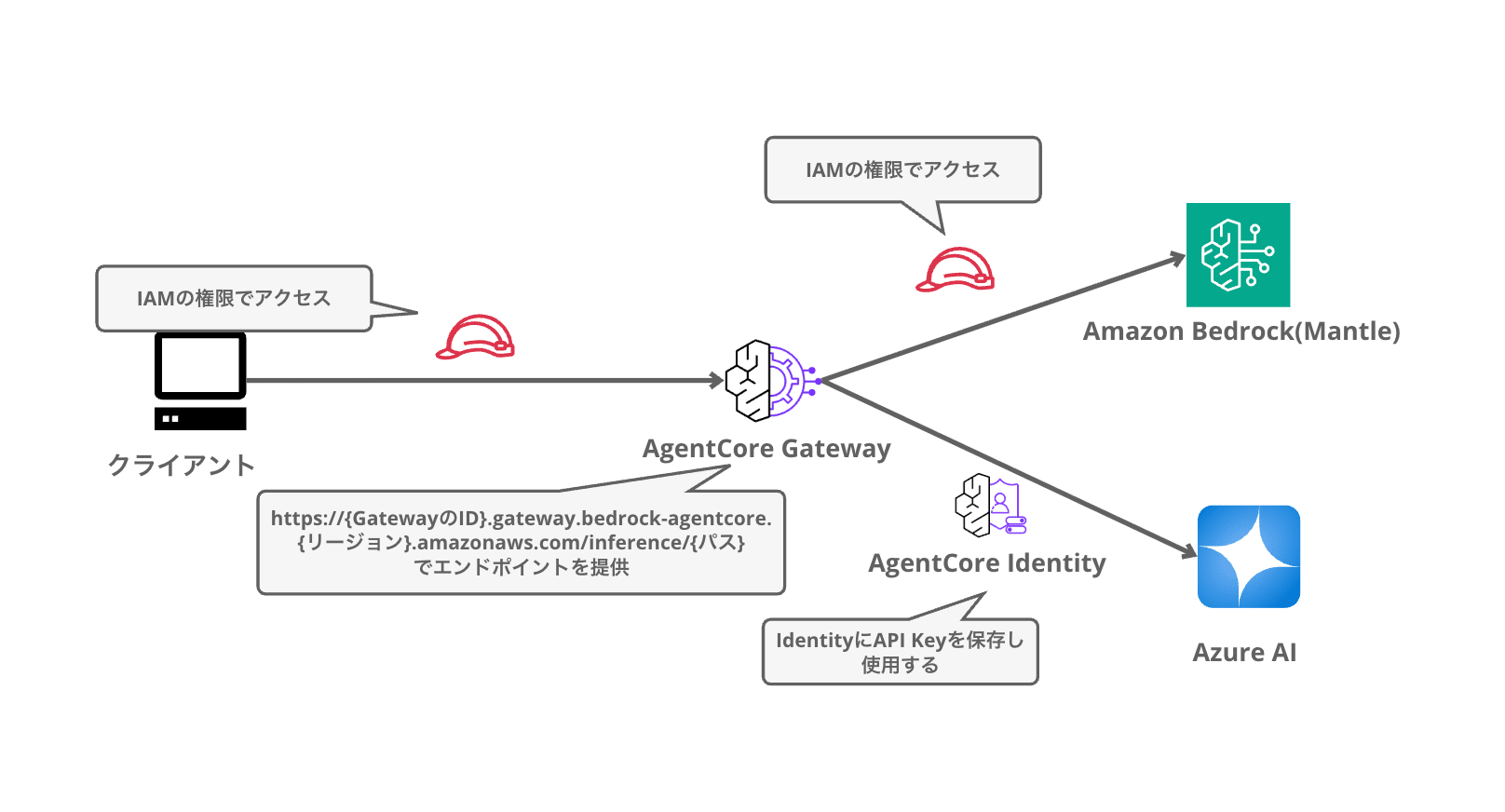
Inference targetを追加すると、Gateway自体がLLM APIとして振る舞うようになります。エンドポイントの構造は下記の通りで、パス部分にはOpenAI互換の/v1/chat/completionsや/v1/responsesのほか、Anthropicネイティブの/v1/messagesも用意されています。
https://{GatewayのID}.gateway.bedrock-agentcore.{リージョン}.amazonaws.com/inference/{パス}
どのプロバイダーに転送するかはパスではなくリクエストボディのmodelの値で決まります。判定ルールは次の3段階です。
- modelが「ターゲット名/モデルID」形式(例:bedrock/claude-opus-4-7)なら、そのターゲットに明示的にルーティング
- 素のモデルID(例:gpt-5.5)なら全ターゲットの定義と照合し、一意に決まればそこへルーティング
- 複数ターゲットが同じモデルを持つ場合は、Bedrockターゲットがあればそちらを優先、なければラウンドロビンで分散
転送時にはGatewayが裏でいろいろ面倒を見てくれます。プロバイダー側のAPIパスへの書き換え、モデルIDの変換、そしてAgentCore Identityに登録したAPIキー(またはIAMロールのSigV4署名)の注入です。つまりクライアントはプロバイダー側の認証情報を一切持たず、Gateway側の認証だけを行えばよい、という作りになっています。
詳細な挙動は下記の公式ドキュメントにまとまっています。必要に応じてご参照ください。
Inference Targetの2つの型
そんなInference Targetには2種類の設定方法があります。コンソールだとModel sourceの選択肢に対応します。
| 型 | 説明 | 使いどころ |
|---|---|---|
| connector型 | 事前構成済みのコネクタを指定するだけ。モデル検出・ID変換・パス書き換えは自動 | Bedrock(Bedrock Mantle)/ OpenAI / Anthropicの3種 |
| provider型(Custom) | エンドポイントURL・モデルマッピング・操作パスを明示的に指定 | コネクタが無いプロバイダー(Azureなど)や細かく制御したい場合 |
Azure AI Foundryには組み込みコネクタがないため、今回はCustom(provider型)で設定します。BedrockはBedrock Mantleコネクタがあるのでconnector型でサクッと追加します。
イメージとしては下記のような構成です。
前提
Azure AI Foundryは事前のセットアップを前提としています。エンドポイントや、API Keyなどは事前に用意しておきましょう。
-
AWSアカウント(バージニア北部リージョンを使用)
-
AWS CLIの認証設定済み(動作確認でawscurlを使うため)
-
Azure AI Foundryのリソースとモデルデプロイメントが作成済み
- 今回はDeepSeek-V4-Flashを使用するためデプロイしておきましょう
-
uv
構築
AzureのAPIキーをAgentCore Identityに登録する
先にAzure AI FoundryのAPIキーをクレデンシャルプロバイダーとして登録しておきます。APIキーはAgentCore Identityのトークンボルトに保管され、Gatewayが送信時に自動で注入してくれます。
コンソールのAmazon Bedrock AgentCore → Identityを開き、Outbound Authセクションの「Add Outbound Auth」から「Add API key」を選択します。
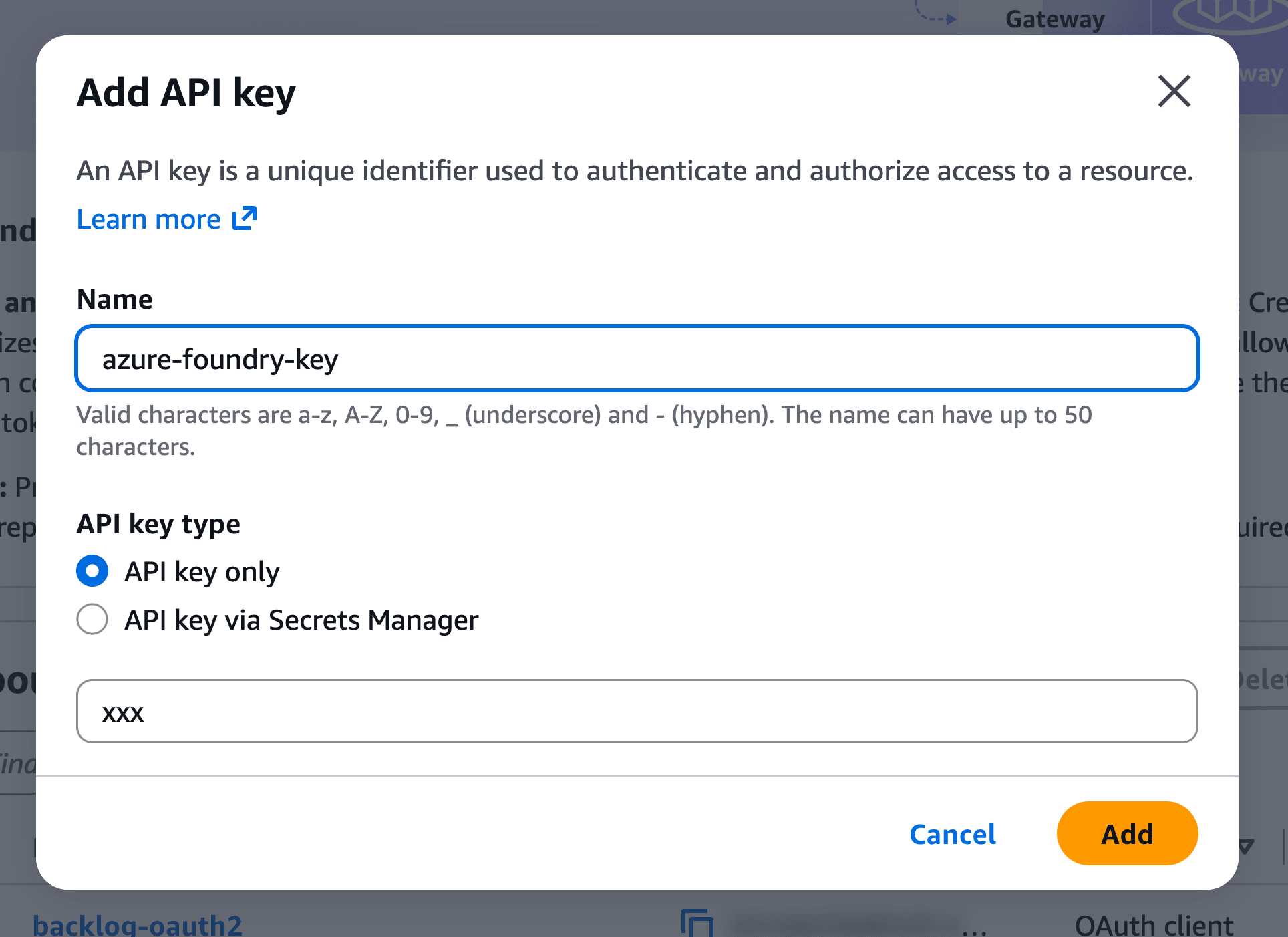
ダイアログで名前とAzureのAPIキーを入力して「Add」を押下します。今回はazure-foundry-keyという名前で登録しました。
Gatewayを作成する
コンソールのAmazon Bedrock AgentCore → Gatewaysを開き、「Create Gateway」を押下します。
ウィザードは4ステップ構成です。順に進めていきます。
Define gateway details
Gateway名は自動生成されたものをそのまま使います。IAMロール(サービスロール)もCreate default roleを選択して自動作成にお任せします。Policy・KMSキー・WAFもここで設定できますが、今回はスキップします。
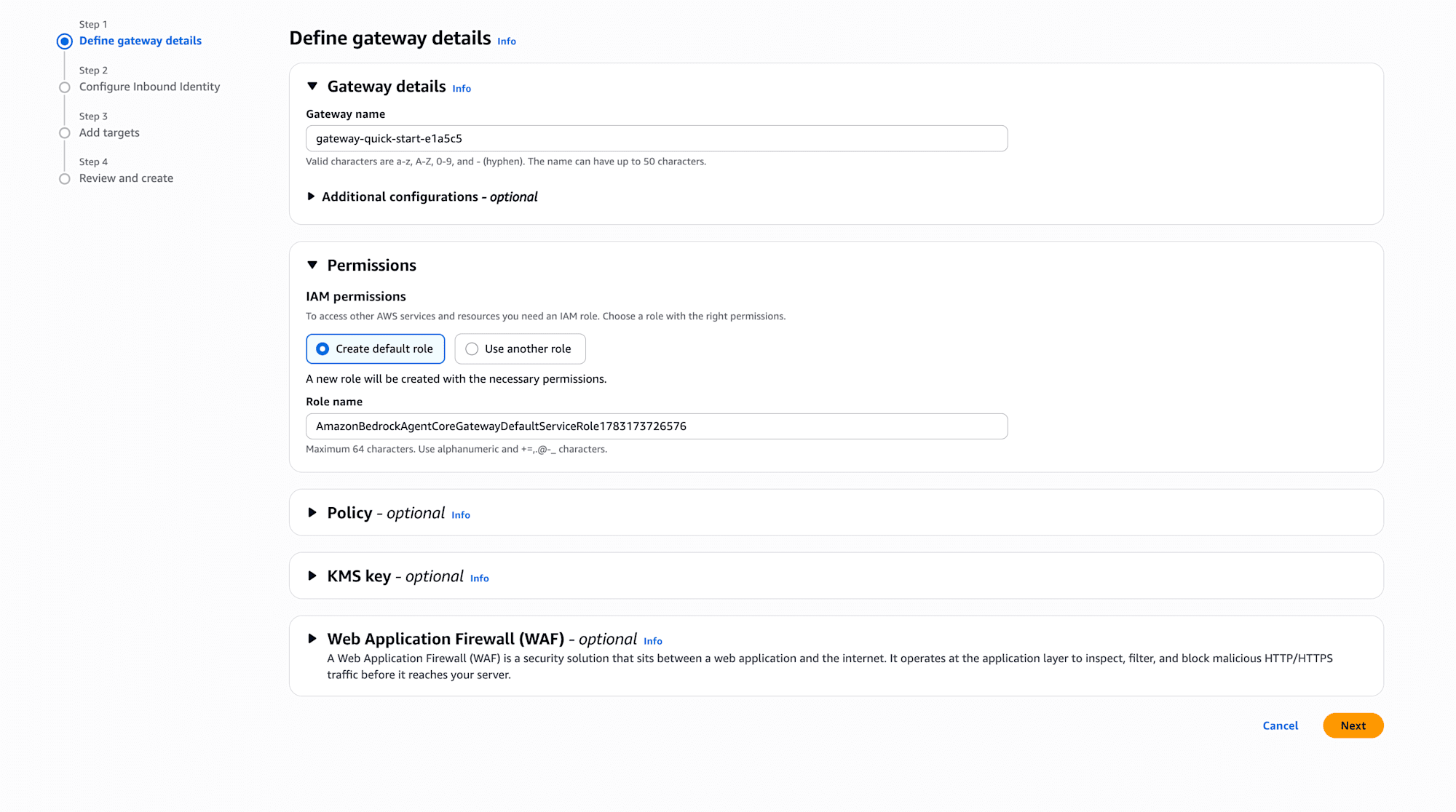
Configure Inbound Identity
Gatewayを呼び出す側の認証方式を選びます。IAM permissions(SigV4)、JWT、No authorizationの3択で、今回はUse IAM permissionsを選択しました。追加設定なしでAWSの認証情報がそのまま使えます。OAuthベースにしたい場合はJWTを選ぶことになります。
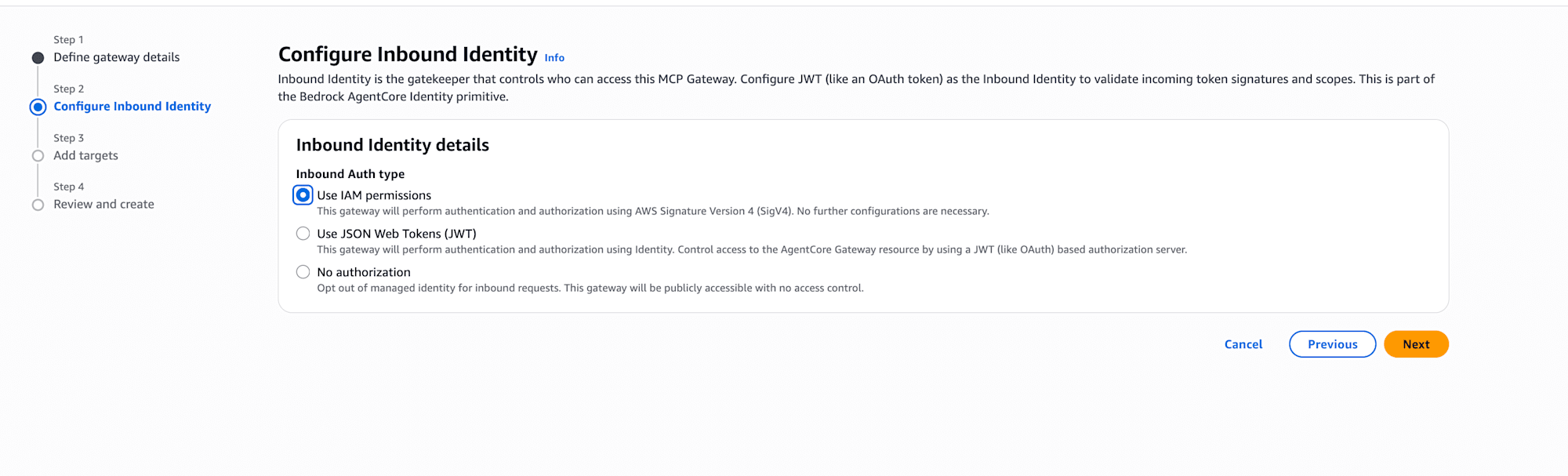
Add targets(1つ目:Bedrock)
1つ目のターゲットとしてBedrockを追加します。Inference targetを選択し、Model sourceのドロップダウンでBedrock Mantleコネクタを選ぶだけです。Outbound AuthはIAM Roleを選択します。
connector型はモデル検出やID変換をGatewayが自動でやってくれるので、設定はこれで終わりです。
Add targets(2つ目:Azure AI Foundry)
「Add another target」を押下して、Azure向けのターゲットを追加します。こちらはコネクタが無いのでModel sourceにCustomを選択し、エンドポイントや操作パスを自分で定義していきます。
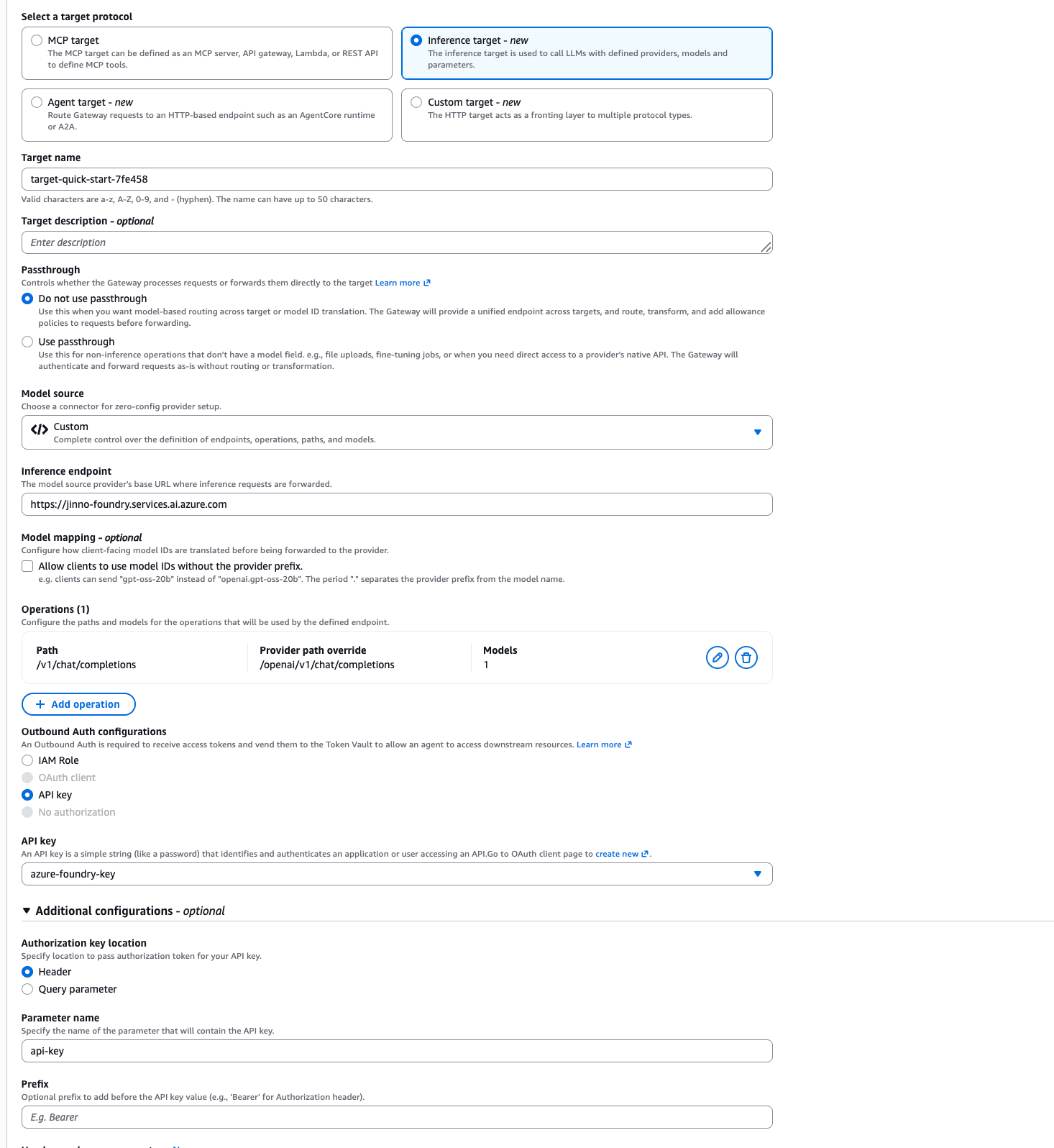
最終的に動いた設定値は下記の通りです。
| 設定項目 | 設定値 | 説明 |
|---|---|---|
| Target protocol | Inference target | LLMプロバイダーをフロントする |
| Passthrough | Do not use passthrough | モデルベースルーティングを使うため |
| Model source | Custom | コネクタが無いのでprovider型 |
| Inference endpoint | https://<リソース名>.services.ai.azure.com | Azure AI Foundryリソースのエンドポイント |
| Operations - Path | /v1/chat/completions | クライアントがGatewayに投げるパス |
| Operations - Provider path override | /openai/v1/chat/completions | Azure側の実際のAPIパス。Gatewayが書き換えてくれる |
| Operations - Models | DeepSeek-V4-Flash | ルーティングするデプロイメント名 |
| Outbound Auth | API key → azure-foundry-key | 先ほど登録したクレデンシャルを選択 |
| Authorization key location | Header | api-keyはヘッダーで送る |
| Parameter name | api-key | Azureのapi-keyヘッダー認証に合わせる |
| Prefix | 空欄 | - |
Provider path overrideによるパス書き換えが可能で、クライアントは標準的なOpenAI互換パスで呼ぶだけで、Gateway側でAzure固有のパスに変換してくれます。Azure AI FoundryはOpenAI互換のv1エンドポイントを提供しているので、DeepSeekのようなOpenAI以外のモデルでもデプロイメント名をmodelとして渡せば呼び出せます。
Model Mappings
Custom(provider型)の設定画面にはModel Mappingsという項目もあります。今回は未設定のままにしましたが、これはクライアントが指定するモデルIDと、プロバイダー側が期待するモデルIDの変換を定義する設定です。
現時点で設定できるのはproviderPrefixで、strip(プレフィックスの省略を許可するか)とseparator(プレフィックスとモデル名の区切り文字)の2つを指定します。たとえばBedrockをprovider型で定義する場合に{"strip": true, "separator": "."}と設定しておくと、クライアントはanthropic.claude-opus-4-7の代わりにclaude-opus-4-7という短い名前で呼び出せるようになります。Gatewayが送信時にプレフィックス付きの正式なIDへ変換してくれるイメージですね。
未設定の場合は変換なしで、クライアントはプロバイダーの完全なモデルIDを指定する必要があります。connector型ではこのID変換が自動で行われるので、Model Mappingsを意識するのはprovider型でBedrockのようなプレフィックス付きモデルIDを扱うときです。
今回のAzureターゲットはデプロイメント名(DeepSeek-V4-Flash)をそのままmodelに使う構成でプレフィックスの概念が無いため、設定不要でした。
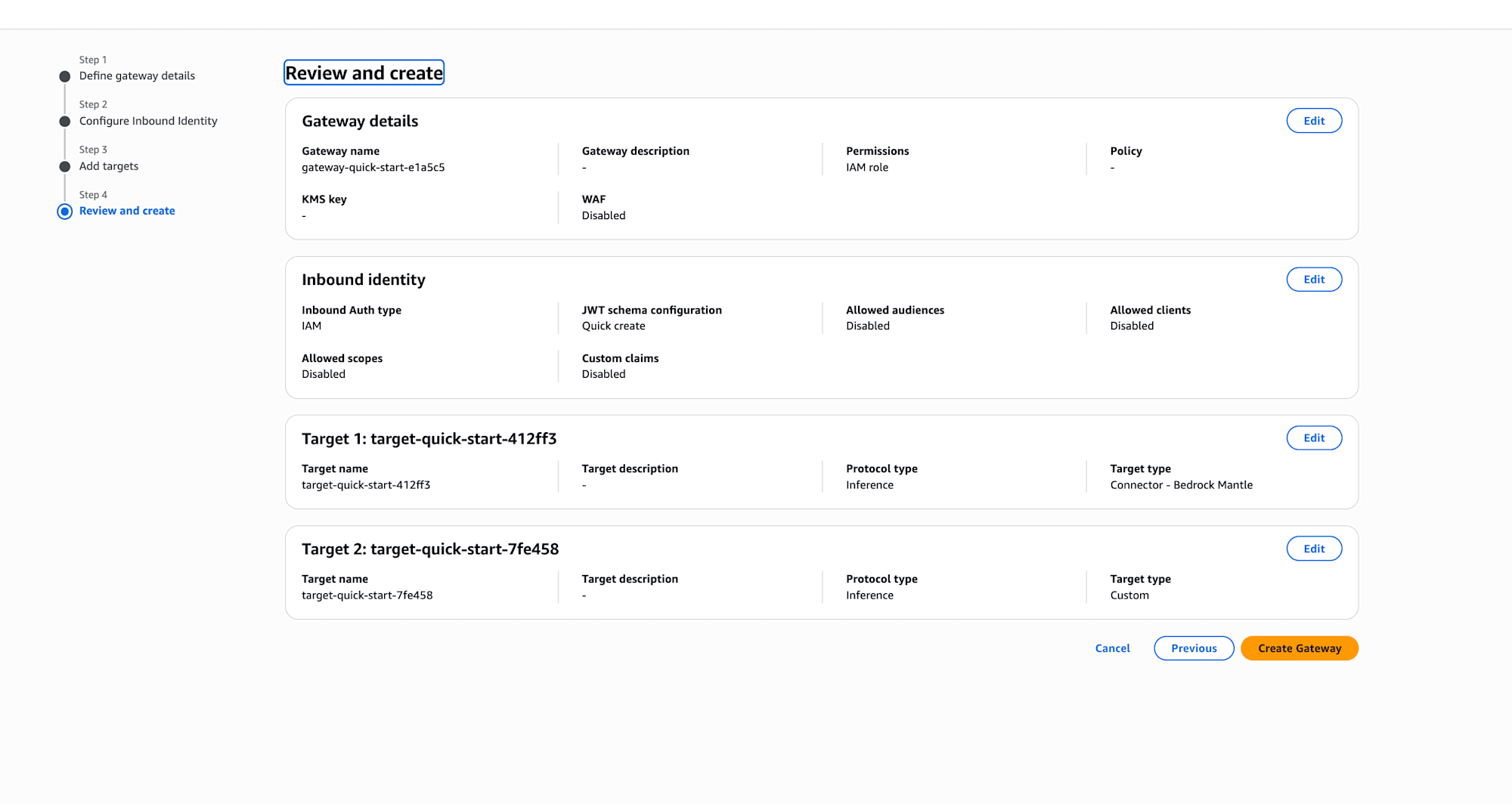
Review and create
設定内容を確認して「Create Gateway」を押下します。Inbound identityがIAM、ターゲットがConnector - Bedrock MantleとCustomの2つになっていることが確認できますね。
Bedrock Mantleの権限によるエラー
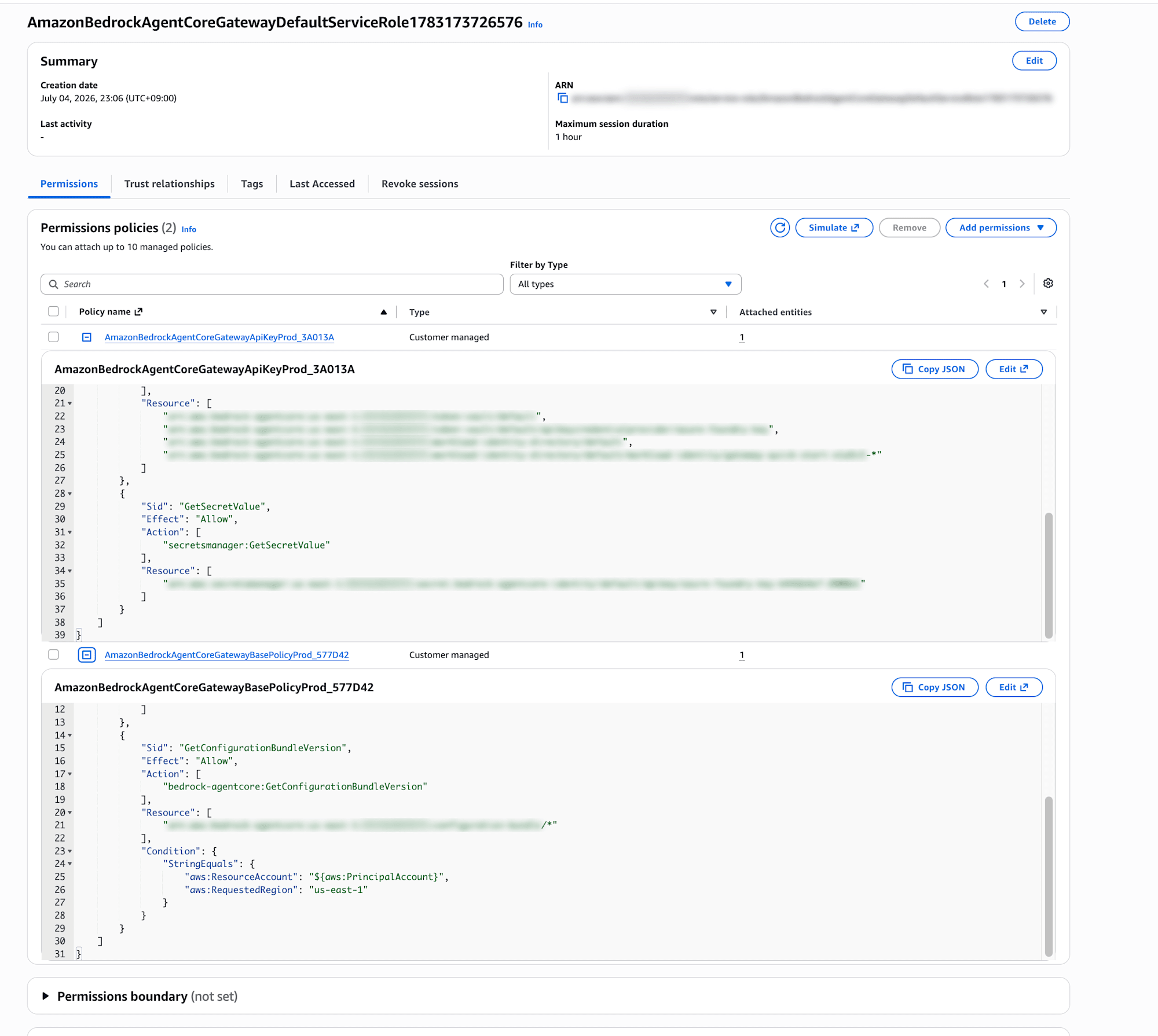
作成ボタンを押すと、Bedrock側のターゲットだけFAILEDになりました。

エラーを読むと、自動生成されたサービスロールにbedrock-mantle:ListModelsの権限が無いと言われています。Bedrock Mantleコネクタ経由では、少なくともモデル一覧取得にbedrock-mantleという専用のIAM名前空間の権限が必要なんです。
実際にIAMコンソールでデフォルトロールを見てみると、付いているのはAPIキー取得用とベース権限の2つだけで、bedrock-mantle系の権限がありません。なるほど・・・対応します。
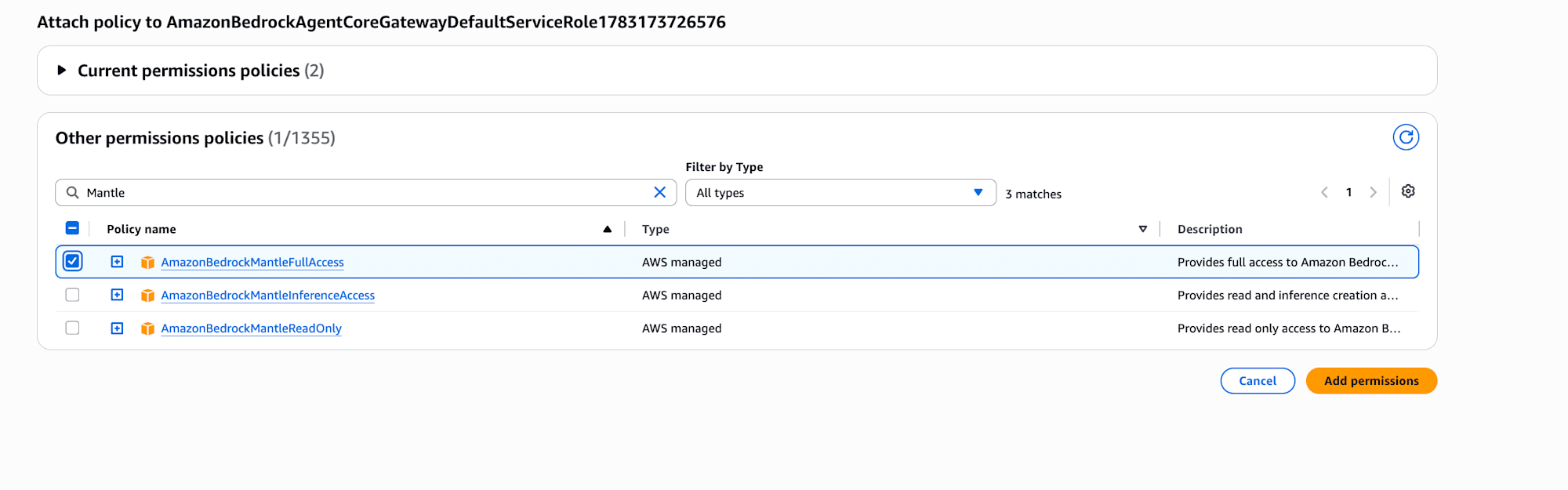
Add permissions → Attach policiesから、AWSマネージドポリシーのAmazonBedrockMantleFullAccessをアタッチします。
Gateway詳細に戻るとBedrock側のターゲットはまだFailedのままなので、選択して「Sync」を押下します。

しばらく待つと両方Readyになりました!

これで準備ができたので試してみます!
動作確認
利用可能なモデルの一覧を確認する
インバウンド認証がIAM permissions(SigV4)なので、SigV4署名できるawscurlを使ってGatewayの/inference/v1/modelsを叩きます。
uvx awscurl --service bedrock-agentcore --region us-east-1 \
"https://<GatewayのID>.gateway.bedrock-agentcore.us-east-1.amazonaws.com/inference/v1/models"
{
"object": "list",
"data": [
{"id": "target-quick-start-412ff3/anthropic.claude-fable-5", "object": "model", "owned_by": "system"},
{"id": "target-quick-start-412ff3/anthropic.claude-haiku-4-5", "object": "model", "owned_by": "system"},
{"id": "target-quick-start-412ff3/anthropic.claude-opus-4-7", "object": "model", "owned_by": "system"},
{"id": "target-quick-start-412ff3/deepseek.v3.2", "object": "model", "owned_by": "system"}
]
}
Bedrock Mantleが自動検出した51モデルが、ターゲット名のプレフィックス付きでずらっと並びます。Claude、DeepSeek、Gemma、Mistralなどなど・・・
なお、Custom(provider型)で定義したAzure側のモデルは、今回の検証ではこの一覧に出てきませんでした(呼び出し自体は問題なくできます)。クライアントにモデルを発見させたい構成の場合は、一覧に出てくるか事前に確認しておくと安心ですね。
Azure側のDeepSeekを呼び出す
リクエストボディのmodelフィールドの値で、Gatewayがどのターゲットに送るかを自動で判定してくれます。まずはDeepSeek-V4-Flashを指定してAzureを呼んでみます。
uvx awscurl --service bedrock-agentcore --region us-east-1 -X POST \
"https://<GatewayのID>.gateway.bedrock-agentcore.us-east-1.amazonaws.com/inference/v1/chat/completions" \
-H "Content-Type: application/json" \
-d '{"model": "DeepSeek-V4-Flash", "messages": [{"role": "user", "content": "こんにちは!一言で自己紹介して"}], "max_tokens": 100}'
{
"id": "7c639bc3fe984e7a8a60ecb9d27ec002",
"model": "DeepSeek-V4-Flash",
"choices": [{
"index": 0,
"message": {"role": "assistant", "content": "こんにちは!私はDeepSeek、あなたの頼れるAIアシスタントです!😊"},
"finish_reason": "stop"
}],
"usage": {"prompt_tokens": 15, "completion_tokens": 25, "total_tokens": 40}
}
無事Azure AI Foundryから応答が返ってきました!!よかった!!DeepSeek-V4-Flashはazure側のターゲットにしか定義されていないため、プレフィックスなしでも一意にルーティングされます。
Bedrock側のモデルを呼び出す
次は同じエンドポイントに対して、modelだけ変えてBedrockを呼んでみます。ターゲット名/モデルIDの形式で明示的にルーティングします。
uvx awscurl --service bedrock-agentcore --region us-east-1 -X POST \
"https://<GatewayのID>.gateway.bedrock-agentcore.us-east-1.amazonaws.com/inference/v1/chat/completions" \
-H "Content-Type: application/json" \
-d '{"model": "target-quick-start-412ff3/deepseek.v3.2", "messages": [{"role": "user", "content": "こんにちは!一言で自己紹介して"}], "max_tokens": 100}'
{
"model": "deepseek.v3.2",
"choices": [{
"message": {"role": "assistant", "content": "プログラミングと知識の世界を駆けるAI、DeepSeekと申します!よろしくお願いします✨"},
"finish_reason": "stop"
}],
"usage": {"prompt_tokens": 15, "completion_tokens": 28, "total_tokens": 43}
}
こちらも問題なく応答が返ってきましたね!
Claudeを呼び出す
ClaudeはAnthropicネイティブの/v1/messagesパスに対応しています。anthropic_versionフィールドを付けて呼び出します。
uvx awscurl --service bedrock-agentcore --region us-east-1 -X POST \
"https://<GatewayのID>.gateway.bedrock-agentcore.us-east-1.amazonaws.com/inference/v1/messages" \
-H "Content-Type: application/json" \
-d '{"model": "target-quick-start-412ff3/anthropic.claude-haiku-4-5", "anthropic_version": "bedrock-2023-05-31", "max_tokens": 100, "messages": [{"role": "user", "content": "こんにちは!一言で自己紹介して"}]}'
{
"type": "message",
"role": "assistant",
"content": [{"type": "text", "text": "こんにちは!私はClaudeです。質問への回答、文章作成、クリエイティブな作業など、様々なタスクでお手伝いできます。何かお力になれることがあれば、お気軽にお聞きください!"}],
"stop_reason": "end_turn"
}
ちゃんとAnthropic API形式のレスポンスで返ってきましたね!GatewayはOpenAI互換のchat/completionsとAnthropicのmessagesの両方のパスを提供していて、モデルごとに対応するAPIが異なるという構造です。OpenAI SDKならchat/completions、Anthropic SDKならmessagesと、既存アプリケーションのSDKに合わせて使用できます。
Strands Agentsから使う
curlだけでなく、エージェントフレームワークからも使ってみます。GatewayはOpenAI互換なので、StrandsのOpenAIModelでbase_urlを差し替えるだけ・・・と言いたいところですが、今回のGatewayはインバウンド認証がIAM認証なので、OpenAI SDKが付けるBearerヘッダーの代わりにSigV4署名を付与する必要があります。
ここで便利なのがmcp-proxy-for-awsに同梱されているSigV4HTTPXAuthです。名前の通り本来はMCP用のプロキシツールなのですが、中身は汎用のhttpx.Auth実装なので、OpenAI SDKのhttp_clientにそのまま渡せます。自前で署名処理を書かなくていいのは嬉しいですね!
import boto3
import httpx
from mcp_proxy_for_aws.sigv4_helper import SigV4HTTPXAuth
from strands import Agent
from strands.models.openai import OpenAIModel
auth = SigV4HTTPXAuth(
credentials=boto3.Session().get_credentials(),
service="bedrock-agentcore",
region="us-east-1",
)
model = OpenAIModel(
client_args={
"base_url": "https://<GatewayのID>.gateway.bedrock-agentcore.us-east-1.amazonaws.com/inference/v1",
"api_key": "unused", # SigV4で上書きされるためダミー
"http_client": httpx.AsyncClient(auth=auth),
},
model_id="DeepSeek-V4-Flash",
)
agent = Agent(model=model)
agent("こんにちは!得意なことを一言で教えて")
uv run --with 'strands-agents[openai]' --with mcp-proxy-for-aws strands_gateway.py
こんにちは!私の得意なことは、**幅広い分野の知識を基に、質問や課題に対して的確で丁寧な回答を提供すること**です😊
StrandsのエージェントがGateway経由でAzureのDeepSeekと会話できました!先ほどawscurlで確認した通りルーティングはmodelの値で決まるので、model_idをtarget-quick-start-412ff3/deepseek.v3.2に差し替えれば、同じコードのままBedrock側に切り替えられます。
おわりに
マルチプロバイダーのルーティングができるようになっていたとは・・・!これから統制を意識していく際に活用の余地がありそうです。特に複数LLMプロバイダーのアクセスを一元提供する共通基盤のような場面では有用になっていくかもしれませんね。
そんなAgentCore Gatewayに次回はAgentCore PolicyとCedarでGuardrailsを組み込む方法についてもご紹介していきたいと思います!
本記事が少しでも参考になりましたら幸いです。最後までご覧いただきありがとうございました!
補足:各SDKから直接呼ぶ
Strands以外に、素のSDKからの呼び出しも試したので記載します。いずれも認証はSigV4HTTPXAuthに任せる構成としています。
OpenAI SDK
base_urlをGatewayの/inference/v1に向け、http_clientにSigV4HTTPXAuthを設定します。api_keyは省略できません(SDKの必須チェックでエラーになります)が、値はリクエスト送信前にSigV4署名で置き換わってサーバーには届かないため、任意の文字列でOKです。
import boto3
import httpx
from mcp_proxy_for_aws.sigv4_helper import SigV4HTTPXAuth
from openai import OpenAI
auth = SigV4HTTPXAuth(
credentials=boto3.Session().get_credentials(),
service="bedrock-agentcore",
region="us-east-1",
)
client = OpenAI(
base_url="https://<GatewayのID>.gateway.bedrock-agentcore.us-east-1.amazonaws.com/inference/v1",
api_key="unused",
http_client=httpx.Client(auth=auth),
)
response = client.chat.completions.create(
model="DeepSeek-V4-Flash",
messages=[{"role": "user", "content": "こんにちは!一言で自己紹介して"}],
max_tokens=100,
)
print(response.choices[0].message.content)
こんにちは!私はDeepSeek、あなたの知識欲を無限にサポートするAIアシスタントです!
Anthropic SDK
messagesパスはAnthropic API互換なので、Anthropic SDKも使えます。base_urlは/inferenceまでで、/v1/messagesはSDKが付けてくれます。
import boto3
import httpx
from anthropic import Anthropic
from mcp_proxy_for_aws.sigv4_helper import SigV4HTTPXAuth
auth = SigV4HTTPXAuth(
credentials=boto3.Session().get_credentials(),
service="bedrock-agentcore",
region="us-east-1",
)
client = Anthropic(
base_url="https://<GatewayのID>.gateway.bedrock-agentcore.us-east-1.amazonaws.com/inference",
auth_token="unused",
http_client=httpx.Client(auth=auth),
)
response = client.messages.create(
model="target-quick-start-412ff3/anthropic.claude-haiku-4-5",
max_tokens=100,
messages=[{"role": "user", "content": "こんにちは!一言で自己紹介して"}],
)
print(response.content[0].text)
こんにちは!私はClaudeという、Anthropic社が開発したAIアシスタントです。質問への回答や会話、文章作成など、様々なことでお手伝いできます。何かお力になれることはありますか?
Anthropic SDKでは2点注意があります。
- ダミーの認証情報はapi_keyではなくauth_tokenに渡します。認証情報なしだとリクエスト時に「Could not resolve authentication method」エラーになるため省略はできず、かつapi_keyだとSDKがx-api-keyヘッダーを送り、SigV4のAuthorizationヘッダーと共存できず「request must not include both 'authorization' and 'x-api-key' headers」という401になります。auth_tokenならAuthorizationヘッダーに記載されるため、SigV4署名でそのまま上書きされます
- curlで必要だったanthropic_versionフィールドは不要です。SDKがanthropic-versionヘッダーを自動付与し、Gatewayはヘッダーでも受け付けてくれます
ストリーミングについて
GatewayはプロバイダーのSSEをそのまま素通しする作りなので、既存のストリーミング実装を変える必要はなく、設定も意識する必要がありません。











