
Bedrock Converse APIで「10回目から応答しない」を追った — Extended Thinking × ツール使用時の落とし穴
TL;DR — Extended Thinking × ツール使用時の注意点
調査プロセスに興味がなく結論だけ知りたい方向けのまとめです。
問題: Bedrock Converse APIでExtended Thinking(reasoningContent)とツール使用を併用する場合、会話履歴の加工によって reasoningContent ブロックが連続すると ValidationException が発生する。
原因: reasoningContent ブロックには暗号署名(signature)が付与されている。この署名はブロックの真正性(Claudeが生成したものであること)を証明するもので、テキスト内容のハッシュではない。APIは署名の真正性に加えて、reasoningブロックの連続パターンがモデルの元の出力と一致するかを構造的に検証する。会話履歴から toolUse/toolResult ブロックを除外した結果、本来は非連続だった reasoningContent ブロックが隣接すると、元の出力に存在しない連続パターンが生まれ、構造検証に失敗する。
モデル出力: [reasoning_A, toolUse, reasoning_B, text]
↓ toolUse除外
フィルタ後: [reasoning_A, reasoning_B, text]
^^^^^^^^^^^^^^^^^^^^^^^^
モデル出力には存在しない連続パターン → ValidationException
対策:
- フィルタ後に
reasoningContentが連続する場合、テキストを結合して1ブロックにまとめる(署名はテキスト内容を検証しないため、いずれかの署名を保持すればよい) - フィルタ後に
contentが空になるメッセージは会話履歴から除外する(カスケード障害の防止)
参考: Anthropic公式ドキュメント — Extended thinking
the entire sequence of consecutive thinking blocks must match the outputs generated by the model during the original request
はじめに
「チャットアシスタントに10問ほど質問したら、11問目から応答しなくなりました。エラーは出ていません。」
この報告を受けたとき、最初に浮かんだ仮説は「コンテキストウィンドウの超過」でした。10回のやり取りでトークン上限に達し、入力が長すぎるエラーが出ているのだろう、と。
結論から言うと、この仮説は間違っていました。
実際の原因はBedrock Converse APIの メッセージ構造の制約違反 であり、そこにたどり着くまでに、CloudWatch、DynamoDB、Bedrock Model Invocation Logging、そして直接のAPI呼び出しと複数のデータソースを横断する調査が必要でした。この記事では、その調査プロセスを追体験する形で紹介します。
症状の整理
問題が発生したアプリケーションは、Bedrock Converse APIを使ったチャットアシスタントです。以下の構成で動作しています:
- モデル: Claude Sonnet 4(Extended Thinking有効)
- ツール使用: Function Callingによるデータベースクエリ等のツール
- 会話履歴: DynamoDBに保存し、毎回のリクエストで全履歴をAPIに送信
報告された症状:
- 10問程度までは正常に応答
- 11問目以降、エラー表示なし、即座に次の質問が送信可能な状態になる
- アプリケーションのクラッシュやエラー画面はなし
「エラーが出ない」という点が厄介でした。
第1章: サイレントエラーの発見
CloudWatchには何もない
まずCloudWatch Logsを確認しました。アプリケーションのロググループで該当時刻のログを検索しましたが、WARN(レベル40)以上のログは一切ありませんでした。
fields @timestamp, @message
| filter level >= 40
| sort @timestamp desc
| limit 100
結果: 0件。全ログがINFO(レベル30)のみ。
DynamoDBに手がかりがあった
次にDynamoDBのチャット履歴テーブルを確認しました。このアプリケーションではチャットメッセージをgzip圧縮+Base64でエンコードして保存しています。復号すると:
[
{ "type": "note", "key": "InternalServerError" },
{ "type": "note", "key": "InternalServerError" },
{ "type": "note", "key": "InternalServerError" }
]
エラーはDynamoDBに保存されていたが、クライアントには送信されていなかった。
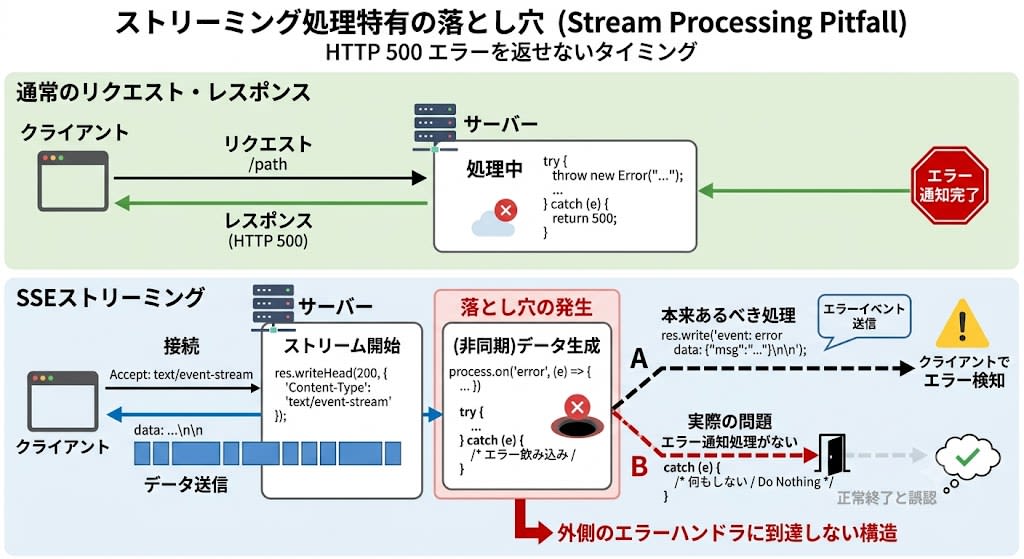
コードを確認すると、ストリーミング応答の処理中にエラーが発生した場合のエラーハンドリングに問題がありました。エラー情報はDBに保存されていたものの、クライアントへのSSE送信とログ出力が両方とも欠落していたのです。
これはストリーミング処理特有の落とし穴です。通常のリクエスト・レスポンスではエラーをHTTPステータスコードで返せば済みますが、SSEストリーミング中のエラーは「レスポンスを途中で返し始めた後」に発生するため、エラーを通知する専用の処理が必要です。この通知処理が抜け落ちていたため、catchブロックがエラーを飲み込み、外側のエラーハンドラにも到達しない構造になっていました。
この時点での学び
- エラーが見えない ≠ エラーが発生していない: 永続化層のデータを直接確認して初めてエラーの存在を確認できた
- サイレントなcatchブロックは危険: エラーをcatchするなら、ログ出力とユーザー通知の両方を必ず行うべき
第2章: ValidationExceptionの正体
DynamoDBで InternalServerError を見つけた時点では、まだ「コンテキストウィンドウ超過」を疑っていました。しかし保存メッセージのトークン数を概算すると、200Kトークンの上限に対して15%程度しか使っていないことが判明。別の原因を探る必要がありました。
| 項目 | サイズ |
|---|---|
| システムプロンプト | 約10,000文字 |
| テキストコンテンツ合計 | 約26,000文字 |
| 推論テキスト合計 | 約7,000文字 |
| 推論シグネチャ合計 | 約19,000文字 |
合計で約62,000文字(≒20,000〜30,000トークン)。使用モデルはClaude Sonnet 4.6(コンテキストウィンドウ200Kトークン)であり、上限の15%程度しか使っていないことが判明しました。
アプリケーションログにはエラー詳細が一切出力されず、DynamoDBにも InternalServerError というコードしか保存されていません。エラーの正体を確認するため、Bedrock Model Invocation Logging を有効にしました。
Bedrock Model Invocation Loggingの有効化
-
CloudWatch Logsのロググループ作成: 保持期間は1日(一時的なデバッグ用)
-
Bedrock設定で有効化: Amazon Bedrock → Settings → Model invocation logging
-
ログ記録先の選択: CloudWatch Logsのみ を選択
-
IAMロールの作成: Bedrockがログを書き込むためのサービスロール
-
CloudWatchで確認: CloudWatchで作成したロググループを選択しログを確認する
判明したエラー種別
ステージング環境で再現後、Invocation Logを確認すると:
{
"operation": "ConverseStream",
"modelId": "jp.anthropic.claude-sonnet-4-6",
"errorCode": "ValidationException"
}
InternalServerError ではなく ValidationException でした。InternalServerError はアプリケーション側のcatchブロックが割り当てたコードであり、Bedrock APIが返した本来のエラー種別はリクエスト構造の制約違反を示す ValidationException だったのです。
残念ながら、Bedrock Model Invocation Loggingはエラー発生時のリクエストボディやエラーメッセージの詳細を記録しません。しかし、直前の成功リクエストのボディは完全に記録されているため、これを手がかりに調査を進めました。
第3章: 根本原因 — reasoningブロックの連続
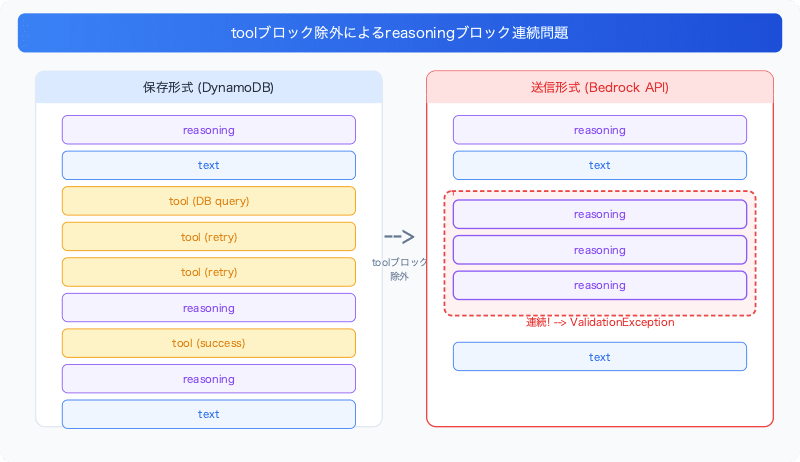
会話履歴のフィルタ処理
まず背景を説明します。このアプリケーションでは、会話履歴をBedrock APIに送信する際、APIに送る必要のあるコンテンツタイプ(text, image, attachment, reasoning)だけを許可リスト(allowlist)方式で選別していました。
この許可リストは、アプリケーションにまだツール使用機能がなかった時期に設計されたものです。当時は text と attachment しか存在せず、許可リストで十分でした。その後 reasoning(Extended Thinking)や image が追加された際にはリストに追加されましたが、後から導入された tool ブロックは許可リストに追加されないまま残りました。
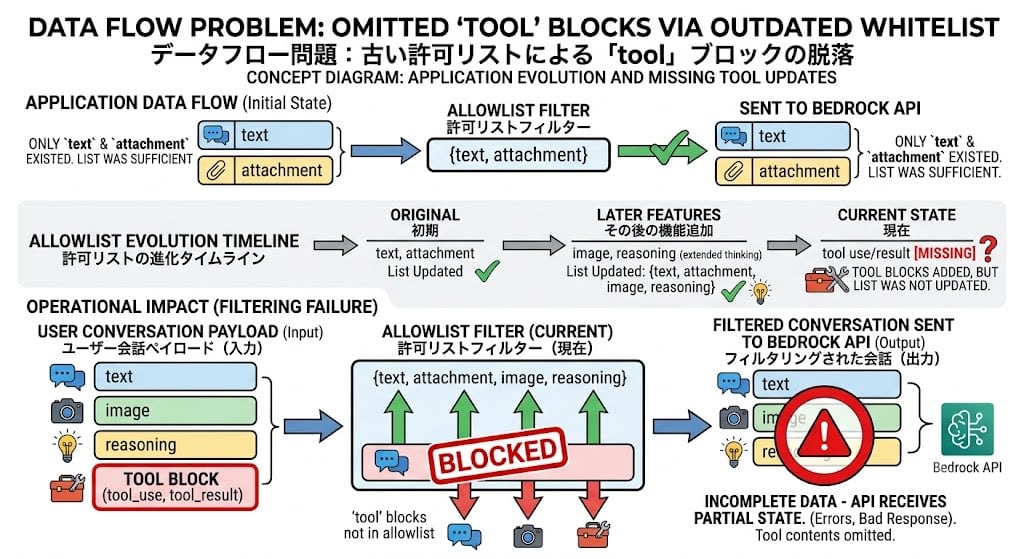
tool ブロックはアプリケーション内部でのツール実行状態(ツール名、パラメータ、結果)を保持するUI表示用のメタデータであり、Bedrock APIに送信する必要がないため、許可リストに含まれていなくても通常は問題ありません。
しかし、この設計には思わぬ副作用がありました。
成功リクエストと保存データの差分
成功リクエスト(Invocation Log)と保存メッセージ(DynamoDB)を突き合わせることで、決定的な発見がありました。
許可リストによるフィルタにより、ほとんどの場合これは問題なく動作します。しかし、モデルがツール呼び出し間で「再考」する場合 — たとえばツール実行結果を見て別のツールを呼ぶ前にreasoningを挟む場合 — ツールブロックがreasoningブロック間の唯一の区切りになることがあります:

AWS CLIによる仮説の検証
ここまでの分析で「reasoningブロックが連続するとエラーになる」という仮説が立ちました。しかしBedrock Model Invocation Loggingからはエラーの詳細メッセージが取得できません。仮説を確定させるため、AWS CLIでBedrock Converse APIに直接テストペイロードを送信して検証しました。
テストのベースには、Invocation Loggingから取得した最後の成功リクエストのペイロードを使用しました。このペイロードには実際の署名付きreasoningブロックが含まれているため、APIの制約を正確に検証できます。
aws bedrock-runtime converse \
--region ap-northeast-1 \
--model-id jp.anthropic.claude-sonnet-4-6 \
--cli-input-json file://test-payload.json
4つのテストを実施し、以下の結果を得ました:
| テスト | ペイロードの内容 | 結果 |
|---|---|---|
| ベースライン | 成功リクエストそのまま(toolブロック除外済み、reasoning非連続) | 成功 |
| テスト1 | reasoningブロックを連続させる(間のtextを削除) | ValidationException |
| テスト2 | 過去のassistantメッセージ(最新ではない)でreasoningを連続 | ValidationException |
| テスト3 | assistantメッセージの content を空配列にする |
ValidationException |
テスト1の結果:
An error occurred (ValidationException) when calling the Converse operation:
The model returned the following errors:
messages.1.content.1: `thinking` or `redacted_thinking` blocks in the
latest assistant message cannot be modified. These blocks must remain
as they were in the original response.
ベースラインとテスト1の比較から、ブロックの位置(インデックス)がずれること自体は問題なく、reasoningブロックが隣接する場合にのみエラーになることが確認されました。
テスト2の結果から、APIは最新のassistantメッセージだけでなく、会話履歴内のすべてのassistantメッセージを検証していることがわかりました。つまり、一度でもreasoningブロックが連続するメッセージが履歴に存在すると、それ以降のリクエストはすべて失敗します。
署名(signature)の正体 — API検証の仕組みを実験で解明
エラーメッセージの These blocks must remain as they were in the original response から、署名による検証が関与していることはわかります。しかし、署名が具体的に何を検証しているのかはドキュメントだけでは明確ではありません。
Anthropicの公式ドキュメントには以下の記述があります:
the entire sequence of consecutive thinking blocks must match the outputs generated by the model during the original request; you cannot rearrange or modify the sequence of these blocks
この「sequence」が何を指すのか — テキスト内容なのか、ブロックの構造なのか — を確かめるため、署名の検証対象を特定する追加実験を行いました。
署名は何を検証しているのか
先ほどのテストペイロード(2つの連続reasoningブロック [reasoning_A, reasoning_B, text])を使い、署名に関する4つの追加テストを実施しました:
| テスト | 操作内容 | 結果 |
|---|---|---|
| テスト4 | reasoning_Aのテキストを全く別の文章に書き換え、署名はそのまま | 成功 |
| テスト5 | reasoning_Aとreasoning_Bの署名を入れ替え(テキストはそのまま) | 成功 |
| テスト6 | 2つのreasoningのテキストを結合して1ブロックにし、いずれかの署名を使用 | 成功 |
| テスト7 | 完全に偽造した署名文字列を使用 | ValidationException |
テスト7のエラーメッセージ:
messages.1.content.0: Invalid `signature` in `thinking` block
この結果から、署名の役割が明確になりました:
1. 署名はテキスト内容のハッシュではない
テスト4でテキストを完全に書き換えても成功し、テスト5で署名を入れ替えても成功しました。署名は reasoningText の内容と紐づいていません。
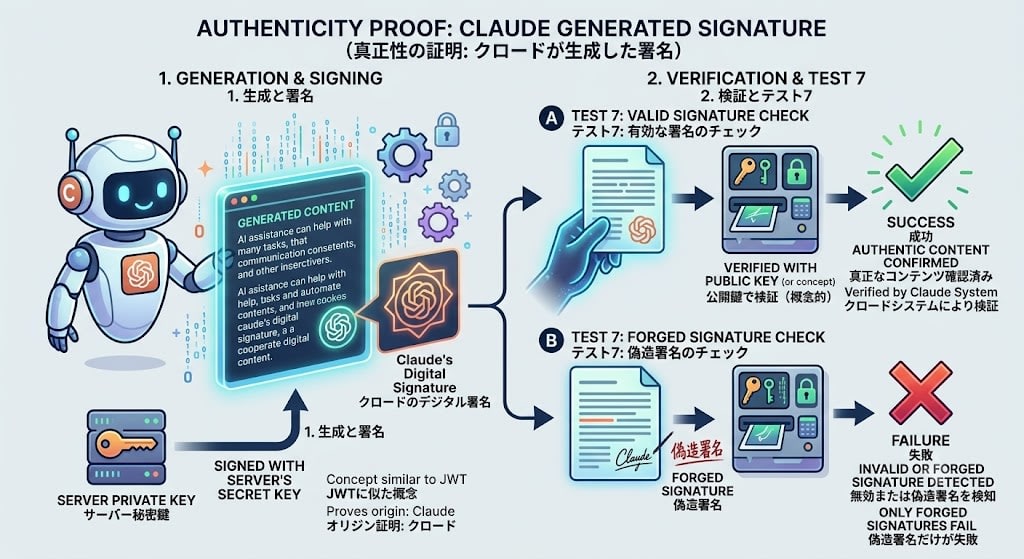
2. 署名は「Claudeが生成した」という真正性の証明
テスト7で偽造署名だけが失敗しました。署名の役割は、そのブロックがClaude APIによって生成されたものであることの証明(authenticity proof)です。概念としてはJWT(JSON Web Token)に近く、サーバーの秘密鍵で署名され、同じ鍵で検証されます。
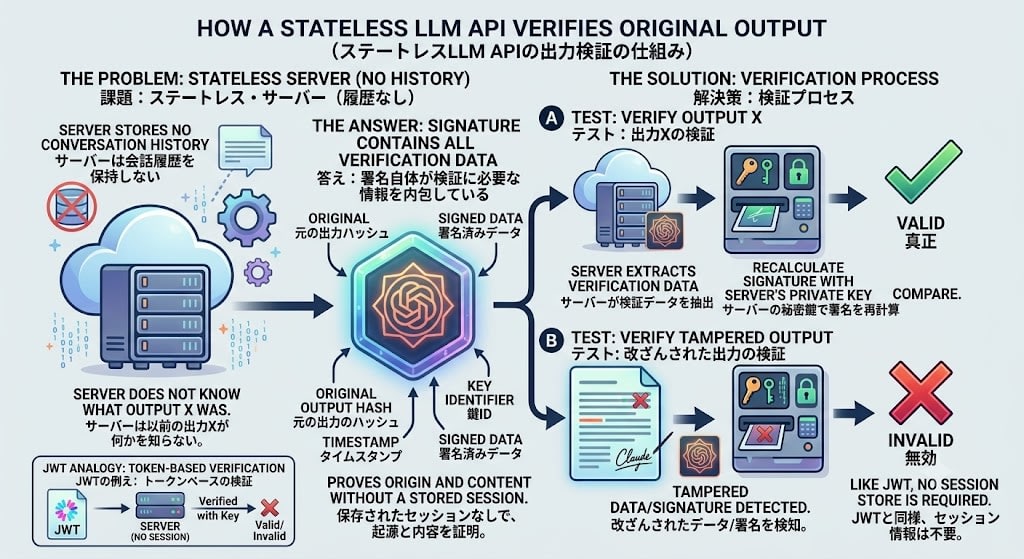
3. APIはステートレス — 署名が「状態」を内包している
LLM APIは本来ステートレスです。サーバー側に会話履歴を保持していないのに、どうやって「元の出力と一致するか」を検証できるのか? 答えは、署名自体が検証に必要な情報を内包しているからです。JWTがサーバー側のセッションストアなしにトークンの真正性を検証できるのと同じ仕組みです。
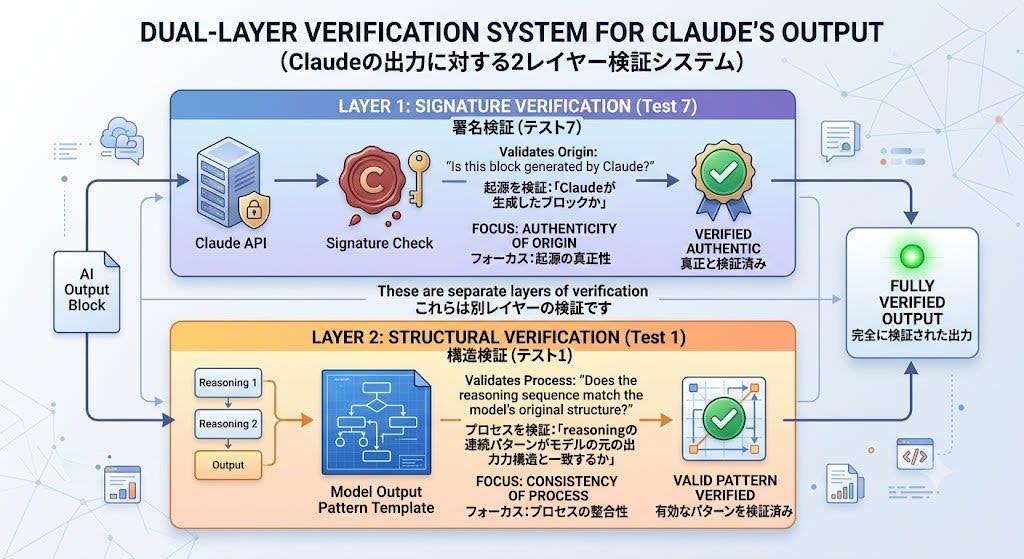
4. 連続パターンの検証は署名とは別の構造チェック
署名は「Claudeが生成したブロックか」を検証し、連続パターンの検証は「モデルの元の出力構造と一致するか」を検証します。この2つは別レイヤーの検証です:
- 署名検証(テスト7で確認): ブロックがClaude APIによって生成されたものか
- 構造検証(テスト1で確認): reasoningブロックの連続パターンがモデルの出力と一致するか
テスト結果が意味すること
この発見は対策に直接影響します。署名がテキスト内容を検証していないため、連続するreasoningブロックのテキストを結合して1ブロックにまとめることが可能です(テスト6で確認済み)。モデルの思考コンテキストを失わずに連続を解消できるため、単純にブロックを削除するよりも優れた対策になります。
なお、同ドキュメントでは前のターンのthinkingブロックを丸ごと省略することは許可されています(ツール使用時を除く)。問題になるのは「元の出力に存在しない連続パターンを作り出す」ことです。
テスト3の結果:
An error occurred (ValidationException) when calling the Converse operation:
The content field in the Message object at messages.1 is empty.
Add a ContentBlock object to the content field and try again.
これにより、カスケード障害のメカニズムも確認されました(詳細は第4章)。
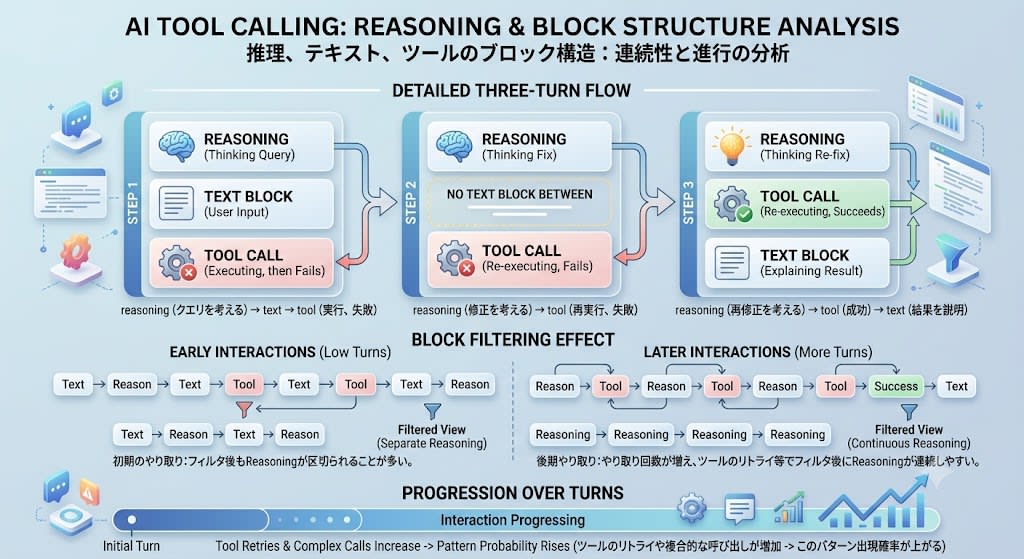
なぜ特定の回数で発生するのか
この問題はすべてのやり取りで発生するわけではありません。トリガーは「ツール呼び出しの間にreasoningブロックだけが挿入される」パターンです。
たとえば、ツール呼び出しが失敗してモデルがリトライする場合:
- reasoning(クエリを考える)→ text → tool(実行、失敗)
- reasoning(修正を考える)→ tool(再実行、失敗)
- reasoning(再修正を考える)→ tool(成功)→ text(結果を説明)
ステップ2でreasoningとtoolの間にtextブロックがないため、toolを除外するとreasoningが連続します。
初期のやり取りではtoolブロックの前後にtextブロックが存在することが多く、フィルタ後もreasoningが連続しません。やり取り回数が増えるほどツールのリトライや複合的な呼び出しが発生し、このパターンが出現する確率が上がります。「10回目くらいから」という再現性はこれが理由です。
第4章: カスケード障害 — 1度失敗すると永続的に壊れる
根本原因に加えて、一度失敗すると以降のすべてのリクエストが永続的に失敗するカスケード障害が発生します。これが問題をさらに深刻にしていました。
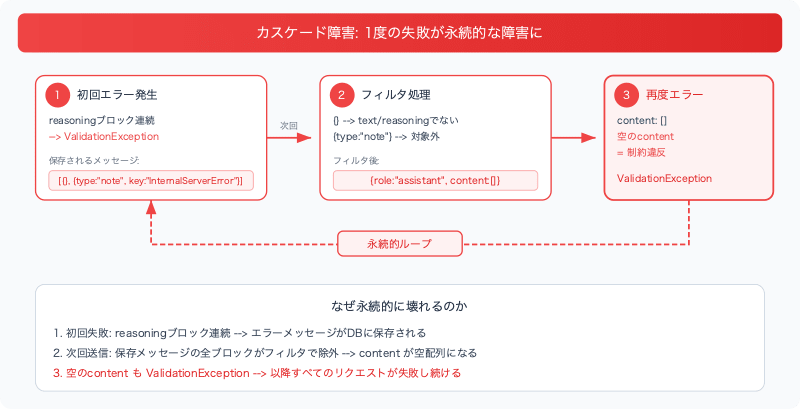
この障害パターンは今回のケースに限らず、会話履歴を永続化して毎回再送するチャットアプリケーション全般で起こりうるものです。エラー時に不完全なassistantメッセージが保存されると、その壊れたメッセージが以降のすべてのリクエストに含まれ続けます。
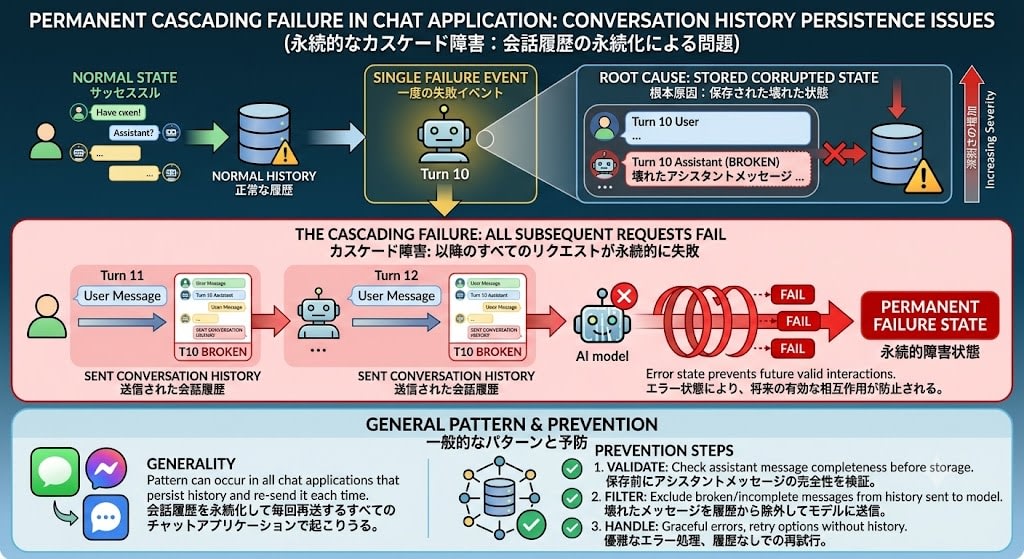
今回のメカニズム:
- 初回失敗時、assistantメッセージが不完全な状態(有効なcontentブロックを持たない形)で保存される
- 次回リクエスト時、このメッセージのすべてのブロックがフィルタで除外され、空のcontentを持つassistantメッセージがBedrockに送信される
- 空のcontentも
ValidationException→ 永続的な失敗ループ
// フィルタ後、contentが空になる
{
"role": "assistant",
"content": [] // Bedrock APIの制約違反
}
前章のテスト3で確認したとおり、空のcontent配列も ValidationException を返します。
つまり、たとえ根本原因(reasoningブロック連続)を修正しても、過去に失敗したチャットは永続的に壊れたままです。空contentメッセージのスキップ処理も併せて対応しなければ、既存の障害チャットは回復しません。
修正と対策
修正①: サイレントエラーの解消
ストリーミング処理中のエラーハンドリングに、ログ出力とクライアントへの通知を追加しました。SSEストリーミング中のエラーは通常のHTTPエラーレスポンスとは異なる経路で通知する必要があるため、見落としやすいポイントです。
修正②: 根本原因の解消
会話履歴をBedrock APIに送信する際のフィルタ処理で、以下の2点を対応する必要があります。
1. reasoningブロック連続の解消
toolブロック除外後にreasoningブロックが連続する場合、連続するreasoningブロックを1つに結合します。前述のとおり、署名はテキスト内容を検証していないため、テキストを結合していずれかの署名を保持すれば検証に通ります。これにより、モデルの思考コンテキストを保持したまま連続パターンを解消できます。
// toolブロック除外後にreasoningの連続を解消する例
function sanitizeContentBlocks(blocks: ContentBlock[]): ContentBlock[] {
const filtered = blocks.filter(b => b.type !== 'toolUse' && b.type !== 'toolResult');
// 連続するreasoningブロックのテキストを結合して1ブロックにまとめる
const result: ContentBlock[] = [];
for (const block of filtered) {
const prev = result[result.length - 1];
if (prev?.type === 'reasoning' && block.type === 'reasoning') {
prev.reasoningText += '\n\n' + block.reasoningText;
// 署名はテキスト内容と紐づかないため、先頭ブロックの署名をそのまま保持
} else {
result.push({ ...block });
}
}
return result;
}
2. 空contentメッセージのスキップ
フィルタ後にcontentが空になるメッセージは、会話履歴から除外します。これにより、過去に失敗したチャットのカスケード障害を防止できます。
// 空contentのメッセージをスキップする例
const messages = history
.map(msg => ({ ...msg, content: sanitizeContentBlocks(msg.content) }))
.filter(msg => msg.content.length > 0);
調査プロセスの振り返り
今回の調査で使った手法と、それぞれの効果をまとめます。
| 手法 | 確認できたこと | 限界 |
|---|---|---|
| CloudWatch Logs | ログが出力されていないこと自体が手がかり | エラーがcatchされログ未出力のため直接の情報なし |
| DynamoDB | エラーコード、メッセージ構造の全体像 | エラーの詳細メッセージは保存されていない |
| Bedrock Model Invocation Logging | 実際のエラー種別(ValidationException)、成功リクエストのペイロード |
失敗時のリクエストボディ・エラーメッセージは記録されない |
| DynamoDB × コード × Invocation Logの突き合わせ | 根本原因の特定 | — |
| AWS CLIでの直接API呼び出し(7パターン) | エラーメッセージの正確な文言、仮説の確定、全メッセージが検証対象であること、署名の検証対象の特定 | — |
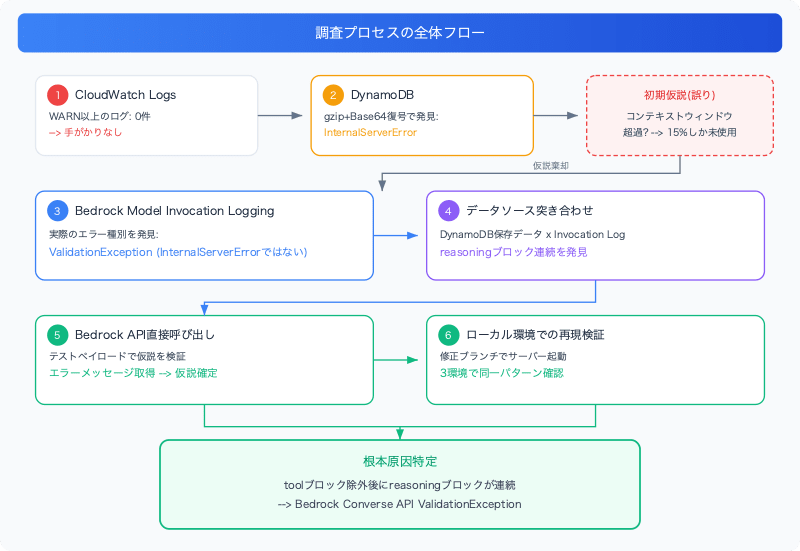
最も有効だったのは「複数のデータソースを突き合わせる」アプローチでした。 単一のログソースでは全体像が見えず、DynamoDBの保存データ × Invocation Logの成功ペイロード × コードの静的解析を組み合わせて初めて原因を特定できました。
まとめ
Bedrock Converse API利用者へ
- Extended Thinkingとツール使用を組み合わせる場合、会話履歴の再構築時にreasoningContentブロックが連続しないよう注意が必要です
- 会話履歴から特定のコンテンツタイプをフィルタする場合、フィルタ後のブロック順序がAPIの制約を満たすか確認してください
- reasoningブロックの
signatureはテキスト内容のハッシュではなく、Claudeが生成したことの真正性証明です。テキストの結合や書き換えは許容されますが、偽造署名や元の出力に存在しない連続パターンは拒否されます
デバッグ手法として
- サイレントエラーを疑う: ユーザーにエラーが見えない場合でも、永続化層にエラー情報が残っている可能性がある
- 仮説を早く棄却する: 「コンテキストウィンドウ超過」という思い込みにとらわれず、トークン数を実測して早期に棄却すべきだった
- Bedrock Model Invocation Loggingを活用する: API呼び出しの実態を確認する最も直接的な手段。一時的に有効化してすぐ無効化できるため、デバッグ時には積極的に使うべき
- 複数のデータソースを突き合わせる: 1つのログソースで完結しない場合、保存データ・アプリログ・サービスログを横断して分析する









