Google Cloud Translation APIでPDFを丸ごと翻訳してみた
こんにちは、けーまです。
ドキュメントを、レイアウトを保ったまま別の言語に翻訳したい場面はよくあります。
図表入りのマニュアルや提案書をそのまま英語にしたい、といった要件です。
ただ、PDF からテキストだけを抜いて翻訳すると、表や段組みが崩れて元の見た目が再現できません。
さらに、製品名やキャラクター名のような独自の固有名詞は、毎回決まった訳に揃えたいことも多いです。
そこで本記事では、Google Cloud の Cloud Translation API が持つ Document Translation 機能を取り上げました。
PDF をファイルのまま API に渡すと、レイアウトをどこまで保ったまま翻訳できるのか。
ネイティブ PDF とスキャン PDF で結果はどう変わるのか。
用語集を使って独自用語を固定できるのか。
この3点を中心に、実際に動かして確かめた結果をまとめました。
ドキュメント翻訳の自動化を検討するときの参考にしていただければと思います。
検証に使うサンプル文書は、実在の作品とは関係のない、完全オリジナルの架空アニメの設定資料をClaudeに作ってもらいました。
固有名詞の翻訳を試したいので、わざと造語をちりばめてあります。
先に結論だけ書いておきます。
- ネイティブ PDF なら、色・フォント・ハイパーリンク・表・グラフまで、ほぼそのまま保持して翻訳できた
- 用語集を使うと、バラついていた固有名詞の訳が狙いどおりに固定された
- スキャン PDF も翻訳でき、元画像の色はそのまま残る(ただし訳文は重ね描きで、ネイティブほど書式は忠実でない)
- 用語集などのリソースは
us-central1でしか作れず、東京リージョンには置けない
1. Cloud Translation API のドキュメント翻訳とは
Cloud Translation API には、テキストを翻訳する機能とは別に、ファイルをそのまま翻訳する Document Translation という機能があります。
PDF や DOCX をファイルごと渡すと、書式やレイアウトを保ったまま翻訳して返してくれます。
公式ドキュメントでは次のように説明されています。
Cloud Translation - Advanced provides a Document Translation API for directly translating formatted documents such as PDF and DOCX. Compared to plain text translations, Document Translation preserves the original formatting and layout in your translated documents, helping you retain much of the original context like paragraph breaks.
引用元: 公式ドキュメント: Translate documents | Google Cloud
ドキュメント翻訳を自前で組むと、ファイルの構造を解析してテキストだけを抜き出し、翻訳して、元の構造に書き戻す、という手順を自分で用意することになります。
Document Translation はこの構造解析と書き戻しをサービス側が担当するので、ファイルを丸ごと投げるだけでレイアウト保持をまかせられます。
対応している入力形式は次のとおりです。
PDF だけでなく、Word・PowerPoint・Excel の各形式(旧形式も含む)に対応しています。
| 入力形式 | MIME タイプ | 出力形式 |
|---|---|---|
application/pdf |
PDF または DOCX | |
| DOCX | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
DOCX |
| DOC | application/msword |
DOC または DOCX |
| PPTX | application/vnd.openxmlformats-officedocument.presentationml.presentation |
PPTX |
| PPT | application/vnd.ms-powerpoint |
PPT または PPTX |
| XLSX | application/vnd.openxmlformats-officedocument.spreadsheetml.sheet |
XLSX |
| XLS | application/vnd.ms-excel |
XLS または XLSX |
引用元: 公式ドキュメント: Translate documents | Google Cloud
Word(DOC / DOCX)には、テキストボックス内のテキストは翻訳されず原文のまま残る、という注意点があります。
Content inside text boxes aren't translated and remain in the source language.
引用元: 公式ドキュメント: Translate documents | Google Cloud
1.1 Basic(v2)と Advanced(v3)の2つのエディション
Cloud Translation には Basic(v2)と Advanced(v3)の2つのエディションがあります。
今回使う Document Translation は Advanced だけの機能で、用語集やバッチ翻訳も Advanced 側にしかありません。
Existing Cloud Translation - Basic (v2) users who want to use the latest Cloud Translation features, such as glossaries and AutoML models, must migrate their applications to use Cloud Translation - Advanced (v3).
引用元: 公式ドキュメント: Migrate to Advanced from Basic | Google Cloud
公式の記載をもとに主な違いを整理すると、次のようになります。
| 項目 | Basic(v2) | Advanced(v3) |
|---|---|---|
| テキスト翻訳・言語検出 | できる | できる |
| 翻訳モデル | NMT のみ | NMT / Translation LLM / カスタム(AutoML) |
| ドキュメント翻訳(対応形式は前掲の表) | × | ○ |
| 用語集(独自用語の固定) | × | ○ |
| バッチ翻訳(Cloud Storage) | × | ○ |
| 認証 | API キー または サービスアカウント | サービスアカウント(IAM)。API キーは不可 |
翻訳モデルと認証の違いは、公式に次のように記載されています。
When you request a translation by using Cloud Translation - Basic, Google uses a pre-trained Neural Machine Translation (NMT) model. For Cloud Translation - Advanced, you can use the pre-trained NMT model, the Translation LLM, or a custom AutoML Translation model.
Because of this, you cannot use API keys to authenticate to the service. Instead, you must use service accounts when authenticating to Cloud Translation - Advanced.
引用元: 公式ドキュメント: Migrate to Advanced from Basic | Google Cloud
エディションごとの全機能の一覧は、公式の比較ページ(Compare Basic and Advanced | Google Cloud)にまとまっています。
1.2 ファイルの渡し方(同期とバッチ)
Advanced の Document Translation では、ファイルを渡す方法が同期(オンライン)とバッチ(非同期)の2通りあります。
今回は手軽に試せる同期のほうを使います。
| 方式 | API | 入出力 | 主な上限 | 向いている場面 |
|---|---|---|---|---|
| 同期(オンライン) | translateDocument |
リクエストにバイト列を直接載せる | 1ファイル。20MB。ネイティブ PDF は 300 ページ、スキャン PDF は 20 ページ | 小〜中規模、手軽に試す |
| バッチ(非同期) | batchTranslateDocument |
入出力ともに Cloud Storage が必須 | 最大100ファイル、合計 1GB または 1億Unicodeコードポイント | 大量・大容量、PDF から DOCX への変換 |
それぞれの上限は、公式ドキュメントに次のように記載されています。
Online translation provides real-time processing (synchronous processing) of a single file. For PDFs, the file size can be up to 20 MB and up to 300 pages for native PDFs (requires the isTranslateNativePdfOnly field to be true). If you enable the enableShadowRemovalNativePdf field, the limit is 20 pages. For scanned PDFs, the limit is 20 pages. For other document types, the file sizes can be up to 20 MB with no page limits.
Batch translation allows you to translate multiple files into multiple languages in a single request. For each request, you can send up to 100 files with a total content size of up to 1 GB or 100 million Unicode codepoints, whichever limit is hit first.
引用元: 公式ドキュメント: Translate documents | Google Cloud
バッチが Cloud Storage を必須とする点も明記されています。
Batch translation input files are read from a Cloud Storage bucket and output files are written to a Cloud Storage bucket.
引用元: 公式ドキュメント: Batch translation | Google Cloud
同期翻訳のうち、用語集を使わない一番シンプルな構成なら、Cloud Storage も不要です。
PDF のバイト列をそのままリクエストに載せて、翻訳済みのバイト列を受け取るだけで完結します。
1.3 PDF はネイティブとスキャンで挙動が変わる
PDF には、文字データを持つ「ネイティブ PDF」と、画像だけの「スキャン PDF」があり、Document Translation での扱いが変わります。
| 項目 | ネイティブ PDF | スキャン PDF |
|---|---|---|
| 入力の中身 | 文字データを持つ | 画像のみ |
| 文字色・フォント・ハイパーリンクの構造的な保持 | 保持される | されない |
| 見た目の色(ページ画像の色) | 保持される | 残る(元の画像をそのまま保持) |
| 同期翻訳のページ上限 | 300 ページ | 20 ページ |
| PDF → DOCX 変換 | できる(バッチのみ) | できない |
| 注意点 | 訳文が原文に重なることがある(shadow text) | 整形が一部失われる。原稿は横書きである必要がある |
文字色・フォント・ハイパーリンクの保持と PDF → DOCX 変換が、いずれもネイティブ PDF に限られる点は公式に明記されています。
Support for PDF to DOCX conversions is available for batch document translations on native PDF files only. Also, Document Translation preserves hyperlinks, font size, and font color for native PDF files only (for both synchronous and batch translations).
引用元: 公式ドキュメント: Translate documents | Google Cloud
ここでいう保持は、構造化された「文字色・フォント」の話です。
スキャン PDF でも元のページ画像はそのまま残るので、カラー原稿であれば見た目の色は保たれます(実際の挙動は §4 で確認します)。
スキャン PDF は整形が一部失われることも明記されています。
複雑なレイアウト(表・多段組・凡例つきのグラフ)が崩れうるという点が、今回の検証対象です。
Translating scanned PDF files results in some formatting loss. Complex PDF layouts can also result in some formatting loss, which can include data tables, multi-column layouts, and graphs with labels or legends.
引用元: 公式ドキュメント: Translate documents | Google Cloud
2. 検証の準備
2.1 前提環境
本記事の検証は、次の環境で動かしました。
| 項目 | 今回の環境 |
|---|---|
| OS | macOS |
| Python | 3.12.13(この中に venv を作成) |
| Google Cloud SDK(gcloud) | 565.0.0 |
| google-cloud-translate | 3.26.0 |
| GCP プロジェクト | 個人プロジェクト(課金を有効化済み) |
加えて、次の準備ができている前提で進めます。
- 課金を有効にした Google Cloud プロジェクトがあること(Document Translation はページ単位の課金が発生します)
gcloudコマンドが使えること- 翻訳や用語集を操作できる IAM 権限があること(
roles/cloudtranslate.editor相当。用語集を使う場合は対象バケットへの書き込み権限も)
2.2 サンプル文書(オリジナルの架空アニメ)
検証用に、架空アニメ「星霊物語 ルミナ・クロニクル」の設定資料という体で、2ページの PDF を Claude に作ってもらいました。
実在の作品・人物・団体とは一切関係のない、完全オリジナルの内容です。
この資料に、崩れやすい要素と翻訳で確かめたい要素を意図的に詰め込んでいます。
- データ表、2段組、凡例つきの棒グラフ(崩れやすいレイアウトの確認用)
- ティール・紫・オレンジの色つき文字と、3種類のフォント、ハイパーリンク(書式保持の確認用)
- ページの境界で文が途中分割される箇所(改ページをまたいだ翻訳の確認用)
星霊、共鳴進化、雷狼ボルテのような造語(用語集の確認用)
同じ内容を、文字データを持つ「ネイティブ PDF」と、一度印刷してスキャンした体の「スキャン PDF(画像のみ)」の2種類で用意しました。
翻訳前のネイティブ PDF(1〜2ページ目)はこちらです。

翻訳前のネイティブPDF 1ページ目(日本語)
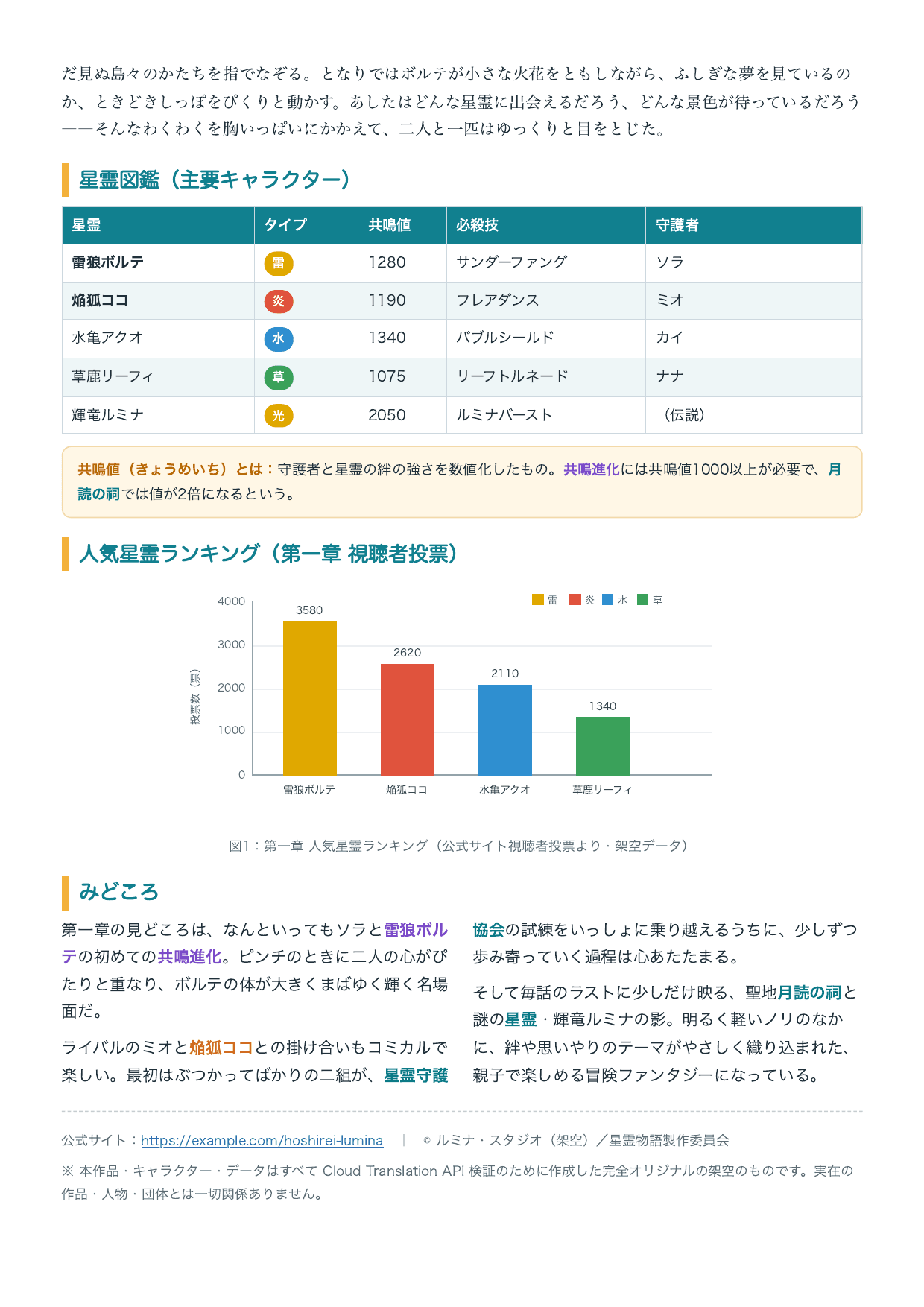
翻訳前のネイティブPDF 2ページ目(日本語・表とグラフ)
スキャン PDF は、同じ内容をカラーのままわずかに傾けて画像化した、実機のスキャンに近い見た目にしてあります(文字データを持たない、画像のみの PDF です)。

翻訳前のスキャンPDF 1ページ目(画像のみ)
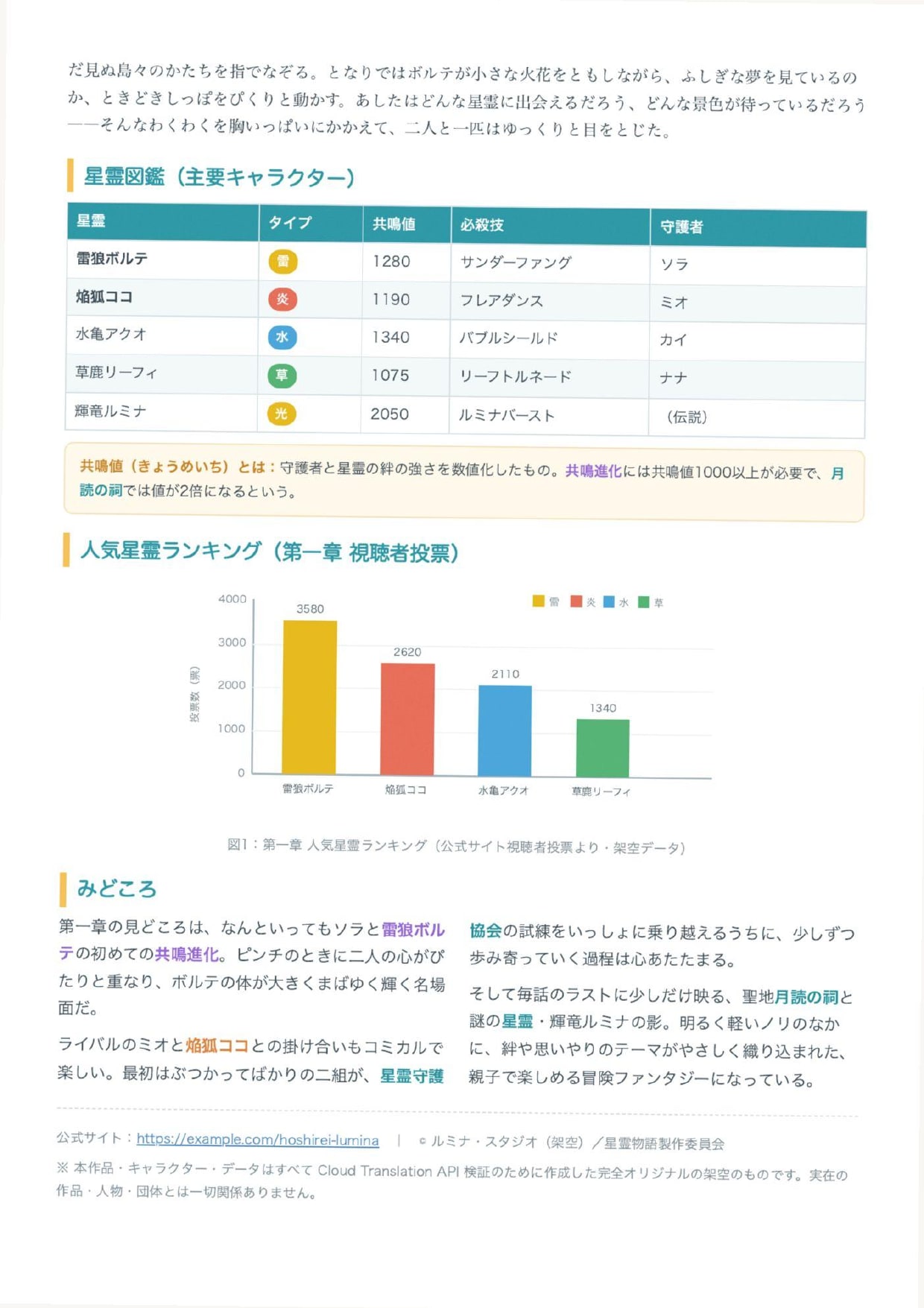
翻訳前のスキャンPDF 2ページ目(画像のみ・表とグラフ)
2.3 環境のセットアップ
準備は次の流れです。
まず、Cloud Translation API を有効化します。
対象のプロジェクトを --project で指定します。
すでに有効になっていれば、このコマンドは何もせずに完了します。
gcloud services enable translate.googleapis.com --project <YOUR_PROJECT_ID>
次に認証です。
Document Translation(v3 / Advanced)は API キーに対応していないため、ADC(Application Default Credentials)を使います。
この点は公式ドキュメントにも明記されています。
API keys can be used only with API methods that support API keys. Cloud Translation supports API keys for the following API methods:
- All methods for the Cloud Translation - Basic API (v2) support API keys, such as translate and detect. The Cloud Translation - Advanced API (v3) does not support API keys.
引用元: 公式ドキュメント: Authentication | Google Cloud
ローカルでは ADC が手軽です。
次のコマンドを実行すると、ブラウザが開いて Google アカウントの同意を求められます。
許可すると、ローカルに認証情報が保存され、クライアントライブラリがその情報を自動で使うようになります。
gcloud auth application-default login
gcloud auth application-default set-quota-project <YOUR_PROJECT_ID>
2行目の set-quota-project は、どのプロジェクトのクォータと請求で API を呼ぶかを指定するものです。
これを設定しておかないと、呼び出し時に請求先プロジェクトが定まらず、エラーになることがあります。
仮想環境(venv)を作って、その中にライブラリを入れます。
python3 -m venv .venv
source .venv/bin/activate
pip install google-cloud-translate
source .venv/bin/activate を実行すると、プロンプトの先頭に (.venv) が付き、このターミナルでは venv の Python が使われるようになります。
以降のコマンドは、この venv を有効にした状態で実行します。
正しく入ったかは、次の import が通れば確認できます。
python -c "import google.cloud.translate_v3; print('import OK')"
# 出力例
import OK
3. ネイティブPDFを翻訳してみる(最小構成)
まずは用語集を使わない、一番シンプルな構成で翻訳します。
PDF のバイト列をそのままリクエストに載せる、同期翻訳です。
翻訳に使ったコードを、translate_pdf.py という名前で、サンプル PDF(hoshirei_native_ja.pdf)と同じフォルダに保存します。
ネイティブ PDF として扱うため、is_translate_native_pdf_only を True にしています。
translate_pdf.py の全文(クリックすると展開します)
import time
from pathlib import Path
from google.cloud import translate_v3 as translate
PROJECT_ID = "<YOUR_PROJECT_ID>"
LOCATION = "us-central1"
INPUT = "hoshirei_native_ja.pdf"
OUTPUT = "hoshirei_native_en.pdf"
content = Path(INPUT).read_bytes()
print(f"入力: {INPUT}({len(content):,} bytes, ja→en)")
client = translate.TranslationServiceClient()
request = {
"parent": f"projects/{PROJECT_ID}/locations/{LOCATION}",
"source_language_code": "ja",
"target_language_code": "en",
"document_input_config": {"content": content, "mime_type": "application/pdf"},
# ネイティブPDFは True で 300 ページまで。False / 未指定はスキャン扱い(20 ページ)
"is_translate_native_pdf_only": True,
}
started = time.perf_counter()
response = client.translate_document(request=request)
elapsed = time.perf_counter() - started
# 翻訳済み PDF を書き出す
out = response.document_translation.byte_stream_outputs[0]
Path(OUTPUT).write_bytes(out)
print(f"処理時間: {elapsed:.2f} 秒")
print(f"出力: {OUTPUT}({len(out):,} bytes)")
コード内の PROJECT_ID を自分のプロジェクト ID に書き換えます。
あとは、§2.3 で有効にした venv のまま実行するだけです。
python translate_pdf.py
2ページの PDF が、3秒足らずで翻訳されました。
# 出力例
入力: hoshirei_native_ja.pdf(1,130,037 bytes, ja→en)
処理時間: 2.62 秒
出力: hoshirei_native_en.pdf(119,631 bytes)
hoshirei_native_en.pdf という翻訳済みの PDF が、同じフォルダにできあがります。
結果を翻訳前と並べてみます。

翻訳前後の比較(ネイティブPDF・1ページ目)
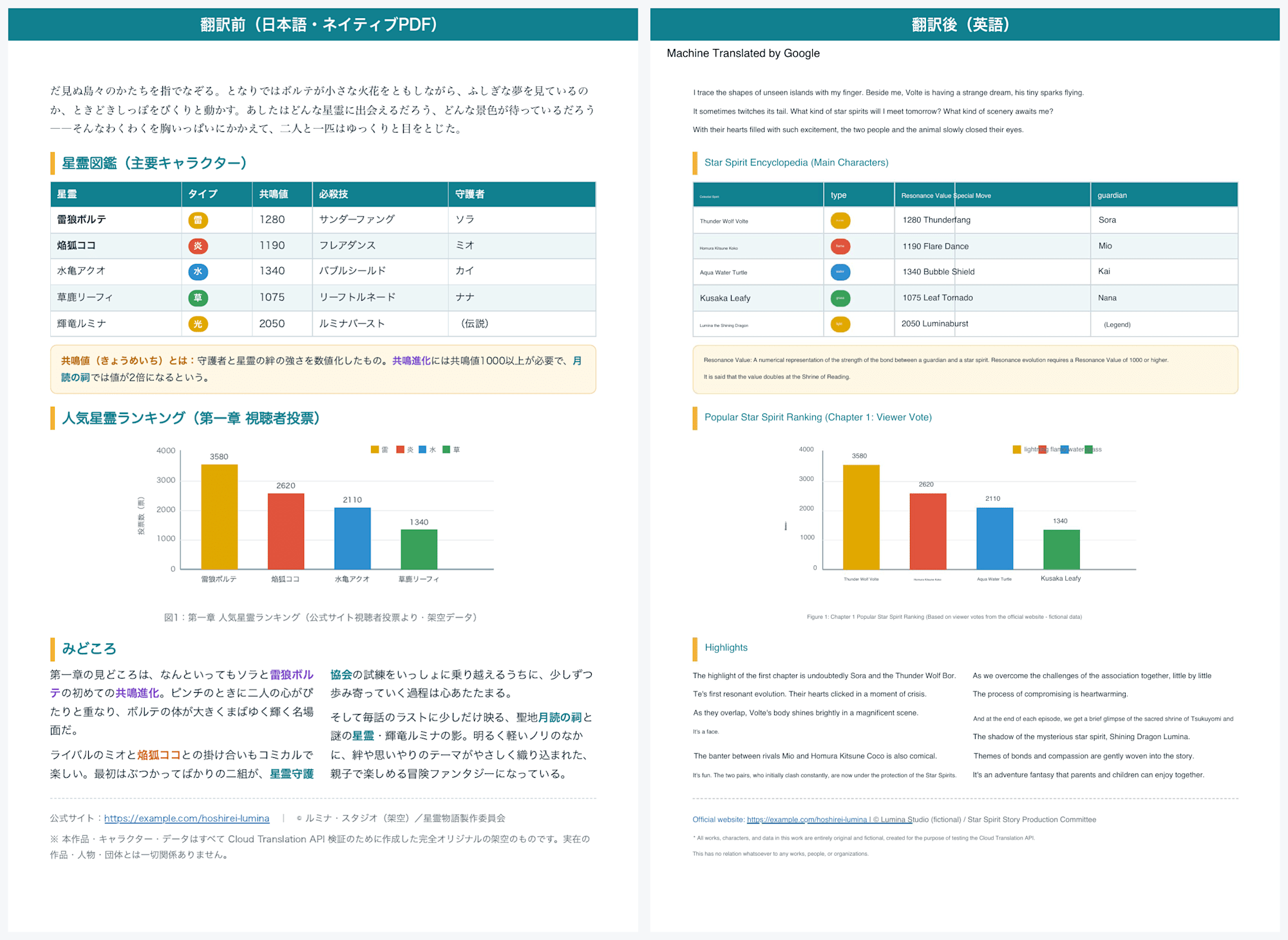
翻訳前後の比較(ネイティブPDF・2ページ目の表とグラフ)
正直、ここまで保つとは思っていませんでした。
バナーのグラデーション、2段組、イラスト、そしてハイパーリンクまで、見た目がほぼそのまま残っています。
2ページ目の表と棒グラフも、配置や色がきれいに維持されました。
また、日本語から英語に変換した際、英語は文字数が増えがちなため、フォントサイズを自動で縮小して収めていることも分かります。
2ページ目の表や棒グラフでレイアウトが一部重なったり崩れたりしている箇所もありますが、おおむね許容範囲だと思います。
一点気になったのは、3色ある色つき文字が翻訳後に正しく引き継がれていなかったことです。
色・フォント・ハイパーリンクの保持がネイティブ PDF に限られることは §1.3 で公式の記載を引用したとおりで、今回のサンプルでもそのまま保持されました。
改ページをまたいだ文も確認してみました。
サンプルでは、1ページ目の最後が「ま」で切れて、2ページ目の先頭が「だ見ぬ」から始まる、という単語の途中で分割された状態を作ってあります。
翻訳後はこの段落が自然な英文としてつながっていました。
段落をひとつのまとまりとして扱うため、見た目の改ページでは文脈が壊れないようです。
もう一点、翻訳後の PDF をよく見ると、左上に「Machine Translated by Google」という表示が入っています。
これは仕様で、リクエストで customizedAttribution を指定しなかったときのデフォルトの帰属表示です。
公式の API リファレンスに次のように記載があります。
customizedAttribution
stringOptional. This flag is to support user customized attribution. If not provided, the default is Machine Translated by Google. Customized attribution should follow rules in https://cloud.google.com/translate/attribution#attribution_and_logos
引用元: API リファレンス: Method: projects.locations.translateDocument | Google Cloud
customizedAttribution に文字列を渡せば、この表示の文言は差し替えられます。
ただし、Google Translate の翻訳結果を利用者に見せるときは、機械翻訳であることを明示することがブランドガイドラインで求められています。
Whenever you display translation results from Google Translate directly to users, you must make it clear to users that they are viewing automatic translations from Google Translate using the appropriate text or brand elements.
引用元: ブランドガイドライン: Attribution requirements | Google Cloud
完全に消すというより、帰属表示が入る前提で配布方法を考えておくのがよさそうです。
4. スキャンPDFを翻訳してみる
次に、同じ内容のスキャン PDF を翻訳します。
スキャン PDF は文字データを持たない画像なので、ネイティブ PDF とは処理の経路が変わります。
ネイティブ PDF は文字データをそのまま翻訳できますが、スキャン PDF はまず画像から文字を読み取る必要があります。
スキャン PDF は画像から文字を読み取る都合上、原稿が横書きであることが前提になります。
この点は公式ドキュメントに記載があります。
For scanned PDF translations, the source text must be oriented horizontally. If, for example, a scanned document includes text that is sloping up or down, Cloud Translation might not correctly parse all the text, which results in incorrect or incomplete translations.
引用元: 公式ドキュメント: Translate documents | Google Cloud
色・フォント・ハイパーリンクの保持がネイティブ PDF に限られる点は §1.3 で引用したとおりで、スキャン PDF では整形が一部失われます。
コードは §3 の translate_pdf.py を、入力ファイルと PDF の扱いだけ変えて使います。
スキャン扱いにするため is_translate_native_pdf_only を False にし、今回のスキャン PDF は少し傾けてあるので傾き補正の enable_rotation_correction も加えました。
スキャン PDF 版の全文は次のとおりです。
import time
from pathlib import Path
from google.cloud import translate_v3 as translate
PROJECT_ID = "<YOUR_PROJECT_ID>"
LOCATION = "us-central1"
INPUT = "hoshirei_scanned_ja.pdf"
OUTPUT = "hoshirei_scanned_en.pdf"
content = Path(INPUT).read_bytes()
print(f"入力: {INPUT}({len(content):,} bytes, ja→en)")
client = translate.TranslationServiceClient()
request = {
"parent": f"projects/{PROJECT_ID}/locations/{LOCATION}",
"source_language_code": "ja",
"target_language_code": "en",
"document_input_config": {"content": content, "mime_type": "application/pdf"},
# スキャンPDFなので False(ページ上限は20)
"is_translate_native_pdf_only": False,
# 傾きを補正してから翻訳する
"enable_rotation_correction": True,
}
started = time.perf_counter()
response = client.translate_document(request=request)
elapsed = time.perf_counter() - started
out = response.document_translation.byte_stream_outputs[0]
Path(OUTPUT).write_bytes(out)
print(f"処理時間: {elapsed:.2f} 秒")
print(f"出力: {OUTPUT}({len(out):,} bytes)")
同じように python translate_pdf.py で実行すると、次の出力になりました。
# 出力例
入力: hoshirei_scanned_ja.pdf(549,573 bytes, ja→en)
処理時間: 7.45 秒
出力: hoshirei_scanned_en.pdf(520,800 bytes)
処理時間は、ネイティブの2〜3秒に対して7.45 秒でした。
画像から文字を読み取る工程が挟まるぶん、2〜3倍ほど時間がかかっています。
スキャン PDF の翻訳前後を並べてみます。
サンプルは、カラーのままスキャンした体(文字データを持たない画像のみ)の PDF です。

翻訳前後の比較(カラースキャンPDF・1ページ目)
2ページ目も同様です。
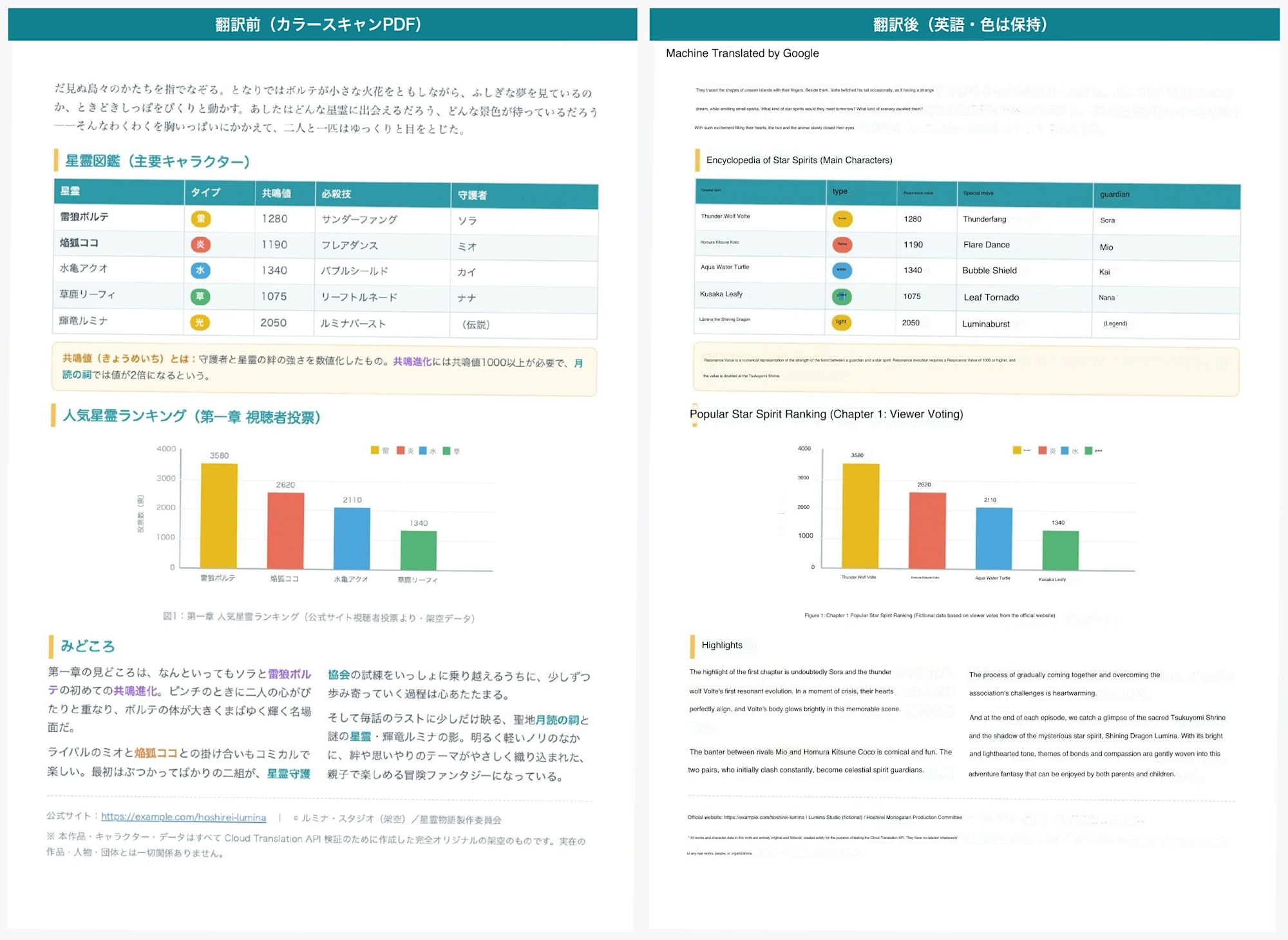
翻訳前後の比較(カラースキャンPDF・2ページ目の表とグラフ)
概ね翻訳できていて、画像からの文字の読み取り精度も高いと感じました。
表のタイトルや本文も正しく認識されています。
棒グラフのデータや表の色も、おおむね元の配置と一致していました。
訳文は画像ではなく文字として埋め込まれており、テキストとして選択やコピーもできました。
一点気になったのが、棒グラフの凡例ラベルです。
各バーが何を表すかを示す凡例の文字(元の文書では「雷・炎・水・草・光」)が、翻訳後も一部日本語のまま残っていました。
グラフ本文の軸ラベルや数値は英訳されているにもかかわらず、凡例部分だけ取りこぼされた形です。
意外だったのが背景色です。
当初は「スキャンだと色が落ちるだろう」と思っていたのですが、カラースキャンを翻訳しても、バナーのグラデーションや色つきの背景、イラストの色はそのまま残りました。
スキャン PDF の色は画像の一部なので、API は元のページ画像をそのまま背景として残し、その上に訳文を重ねます。
そのため、元が色付きなら翻訳後も色付きのままです(グレースケールでスキャンすれば、当然グレーのままになります)。
ただし、重ね描きされる訳文はすべて黒文字になりました。
元の文書で白文字だった箇所—たとえばカラーのバーの上の数値や、色付きの見出しテキストも、翻訳後は黒文字に置き換わります。
これはネイティブ PDF のように文字色を構造として引き継いでいるわけではなく、あくまで画像の上に重ね描きしているためです。
文字の色やフォントの忠実度はネイティブに劣ります。
| 観点 | ネイティブ PDF | スキャン PDF |
|---|---|---|
| 処理時間(2ページ) | 約 2〜3 秒 | 約 7 秒 |
| 見た目の色 | 保持 | 残る(元のページ画像をそのまま保持。カラー入力ならカラーのまま) |
| 文字色・フォント・ハイパーリンクの構造的な保持 | 保持 | されない |
| 文字の扱い | もとの文字データを翻訳して差し替え | 画像から読み取った文字を上に重ね描き |
| 書式の忠実度 | 高い | 落ちる(訳文は重ね描きのため) |
5. 用語集で独自用語を固定する
固有名詞や独自用語を、決まった訳に固定できるかを確かめます。
5.1 用語集を作る
用語集は、source と target を並べた TSV ファイルとして用意します。
今回は造語10語を、英語のローカライズ名に固定する形で用意しました。
星霊 Hoshirei
共鳴進化 Reso-Evolution
雷狼ボルテ Voltefang
輝光石 Lumina Shard
守護者 Warden
この内容を glossary_ja_en.tsv として保存し、Cloud Storage にアップロードします。
バケットは用語集と同じ us-central1 に作っておきます。
# バケットを作成(既にあれば不要)
gcloud storage buckets create gs://<YOUR_BUCKET> \
--project <YOUR_PROJECT_ID> --location us-central1
# TSV をアップロード
gcloud storage cp glossary_ja_en.tsv \
gs://<YOUR_BUCKET>/glossaries/glossary_ja_en.tsv
次に、アップロードした TSV から用語集リソースを作成します。
作成は長時間オペレーション(LRO)なので、クライアントライブラリから実行して完了を待ちます。
これも create_glossary.py として保存し、venv のまま実行します。
create_glossary.py の全文(クリックすると展開します)
from google.cloud import translate_v3 as translate
PROJECT_ID = "<YOUR_PROJECT_ID>"
LOCATION = "us-central1" # 用語集は us-central1 のみ
GLOSSARY_ID = "hoshirei-ja-en"
INPUT_URI = "gs://<YOUR_BUCKET>/glossaries/glossary_ja_en.tsv"
client = translate.TranslationServiceClient()
name = client.glossary_path(PROJECT_ID, LOCATION, GLOSSARY_ID)
glossary = translate.Glossary(
name=name,
# 単方向(ja→en)の用語集
language_pair=translate.Glossary.LanguageCodePair(
source_language_code="ja", target_language_code="en"
),
input_config=translate.GlossaryInputConfig(
gcs_source=translate.GcsSource(input_uri=INPUT_URI)
),
)
parent = f"projects/{PROJECT_ID}/locations/{LOCATION}"
operation = client.create_glossary(parent=parent, glossary=glossary)
result = operation.result(180) # 完了を最大180秒待つ
print(f"作成完了: {result.name}(エントリ数: {result.entry_count})")
python create_glossary.py
# 出力例
作成完了: projects/.../locations/us-central1/glossaries/hoshirei-ja-en(エントリ数: 10)
長時間オペレーションとはいえ、今回は数秒で完了しました。
ここで一点はまったのが、リソースを置けるリージョンです。
用語集は東京リージョンには作れませんでした。
公式ドキュメントにも、対応ロケーションは限られると書かれています。
Note: All of your resources in a single request to Cloud Translation - Advanced must have the same location. Currently, only global and us-central1 locations are supported. For all custom resources—AutoML models, glossaries, long-running-operations—you must use us-central1.
引用元: 公式ドキュメント: Migrate to Cloud Translation - Advanced (v3) | Google Cloud
用語集のようなカスタムリソースは us-central1 必須です。
データの所在地に要件がある場合は、設計の段階で考えておく必要があります。
5.2 用語集あり/なしを比べる
用語集を指定して translateDocument を呼ぶと、ひとつの応答に「用語集なし」と「用語集あり」の両方の翻訳結果が返ってきます。
同じ条件で前後を比べられるので、検証にはちょうど良い仕様です。
| 出力フィールド | 内容 |
|---|---|
document_translation |
用語集を使わない翻訳結果 |
glossary_document_translation |
用語集を適用した翻訳結果 |
やることは、§3 の translate_pdf.py に用語集の指定(glossary_config)を1つ足すだけです。
用語集を使うときは原文言語(source_language_code)の指定が必須ですが、§3 でも ja を指定しているのでそのままで大丈夫です。
用語集あり版の全文は次のとおりです。
import time
from pathlib import Path
from google.cloud import translate_v3 as translate
PROJECT_ID = "<YOUR_PROJECT_ID>"
LOCATION = "us-central1"
GLOSSARY_ID = "hoshirei-ja-en" # 5.1 で作ったもの
INPUT = "hoshirei_native_ja.pdf"
OUTPUT = "hoshirei_native_en.pdf" # 用語集なし
OUTPUT_GLOSSARY = "hoshirei_native_en_glossary.pdf" # 用語集あり
content = Path(INPUT).read_bytes()
print(f"入力: {INPUT}({len(content):,} bytes, ja→en)")
client = translate.TranslationServiceClient()
request = {
"parent": f"projects/{PROJECT_ID}/locations/{LOCATION}",
"source_language_code": "ja",
"target_language_code": "en",
"document_input_config": {"content": content, "mime_type": "application/pdf"},
"is_translate_native_pdf_only": True,
# 用語集を指定する
"glossary_config": translate.TranslateTextGlossaryConfig(
glossary=f"projects/{PROJECT_ID}/locations/{LOCATION}/glossaries/{GLOSSARY_ID}"
),
}
started = time.perf_counter()
response = client.translate_document(request=request)
elapsed = time.perf_counter() - started
# 応答には用語集なし・ありの2つの結果が入る
no_glossary = response.document_translation.byte_stream_outputs[0]
with_glossary = response.glossary_document_translation.byte_stream_outputs[0]
Path(OUTPUT).write_bytes(no_glossary)
Path(OUTPUT_GLOSSARY).write_bytes(with_glossary)
print(f"処理時間: {elapsed:.2f} 秒")
print(f"出力(用語集なし): {OUTPUT}({len(no_glossary):,} bytes)")
print(f"出力(用語集あり): {OUTPUT_GLOSSARY}({len(with_glossary):,} bytes)")
実行すると、用語集なしと用語集ありの2つの PDF が一度に書き出されます。
# 出力例
入力: hoshirei_native_ja.pdf(1,130,037 bytes, ja→en)
処理時間: 2.79 秒
出力(用語集なし): hoshirei_native_en.pdf(119,631 bytes)
出力(用語集あり): hoshirei_native_en_glossary.pdf(119,155 bytes)
処理時間は 2.79 秒で、用語集なしのとき(§3 の 2〜3 秒)とほとんど変わりませんでした。
1 回のリクエストで用語集なし・ありの両方が返るので、用語集を付けても待ち時間がほとんど増えないのは扱いやすい点です。
まず用語集なしの結果を見ると、肝心の固有名詞の訳がかなりバラついていました(Claude調べ)。
たとえば 星霊 という1語が、文脈ごとに次のように揺れています。
星霊 の訳(用語集なし) |
出現回数 |
|---|---|
| Star Spirit | 10 |
| star spirit | 9 |
| Spirit | 3 |
| Hoshirei | 1 |
| その他の表記 | 数件 |
同じ単語なのに、大文字小文字も含めて7通りほどに分かれてしまいました。
機械翻訳は文脈ごとに最適な訳を選ぶので、固有名詞をそろえる仕組みがないとこうなります。
用語集ありに切り替えると、これがきれいに統一されました。
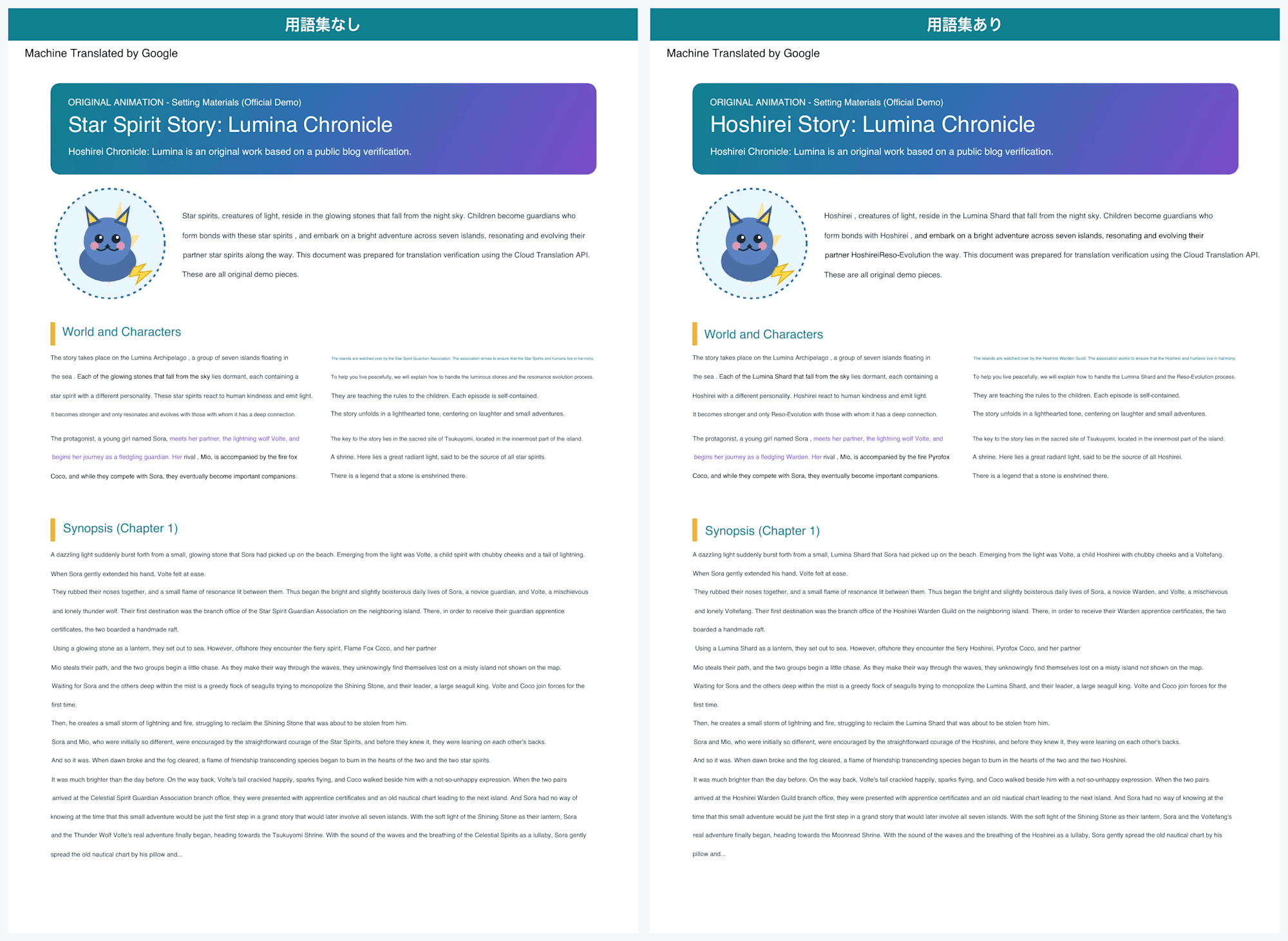
用語集なしと用語集ありの比較(1ページ目)
タイトルが「Star Spirit Story」から「Hoshirei Story」に変わっているのが分かります。
用語集なしでは7通りに割れていた 星霊 も、Hoshirei に統一されました。ハイパーリンクの箇所は、Hoshireiに変更させないあたり、優秀さを感じます。
他の造語も、雷狼ボルテ は Voltefang、輝光石 は Lumina Shard、守護者 は Warden と、登録したとおりの訳に固定されています。
2ページ目の表でも、造語が並ぶ箇所がきれいに置き換わりました。
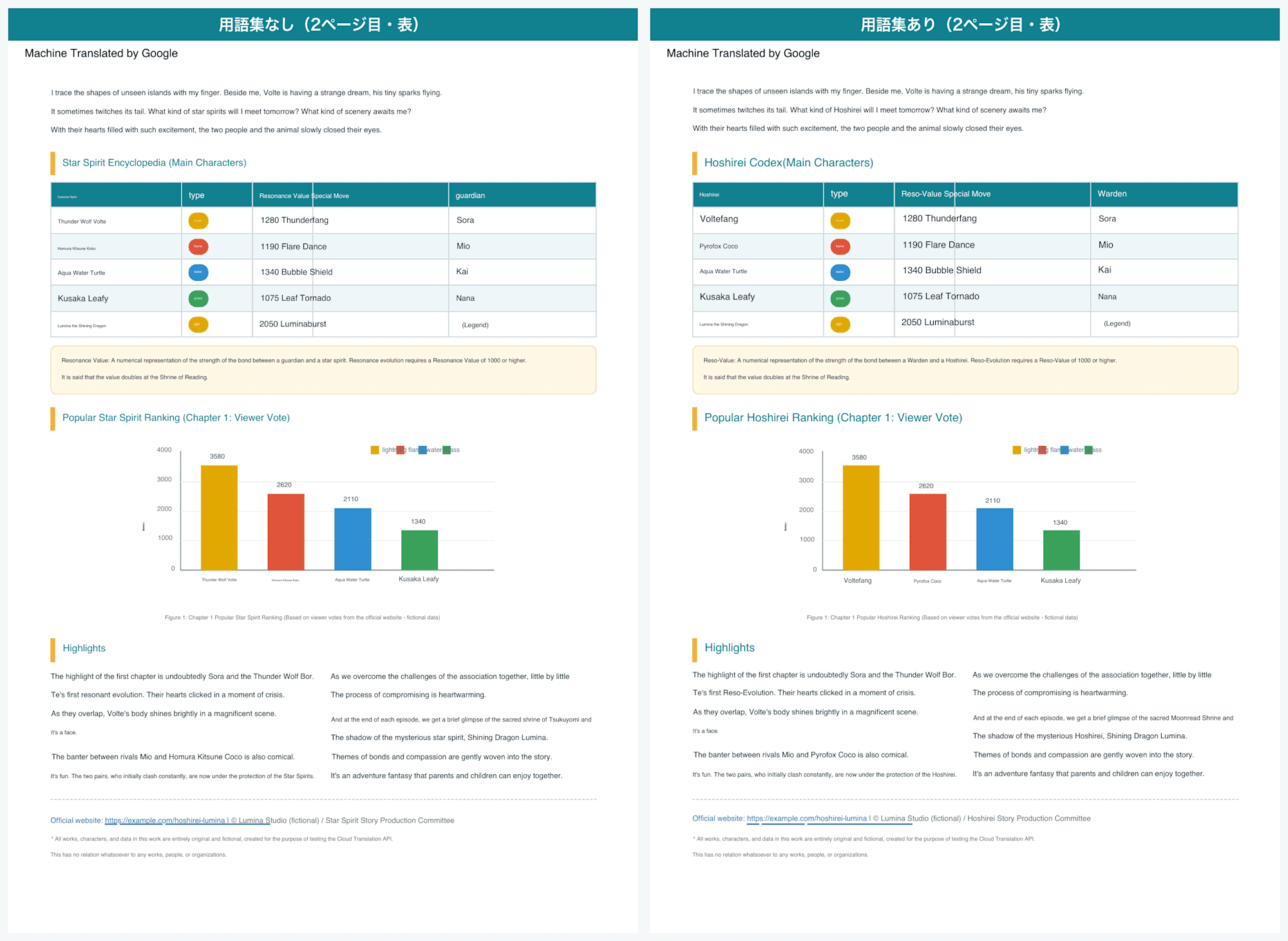
用語集なしと用語集ありの比較(2ページ目・表)
ただ、辞書ありの出力を全文で調べてみると、完全に100%ではありませんでした(Claude調べ)。
登録した語のうち4か所だけ、固定訳にならず字義どおりの訳が残っていました。
守護者:8か所はWardenに固定されたが、1か所だけguardiansのまま輝光石:7か所はLumina Shardに固定されたが、1か所だけShining Stoneのまま雷狼ボルテ:5か所はVoltefangに固定されたが、1か所だけThunder Wolfのまま月読の祠:Moonread Shrineに固定されたが、1か所だけTsukuyomi(字義訳)のまま
たとえば本文の「Children become guardians who form bonds with Hoshirei」では、同じ文の中で 星霊 は Hoshirei に固定されているのに、守護者 だけ guardians のまま残っていました。
用語集は出現箇所ごとに一致を見て適用するため、活用や前後の文脈によって、同じ語でもまれに取りこぼすことがあるようです。
とはいえ大半は固定できているので、「ほぼ統一されるが、取りこぼしがゼロではない」というのが実際のところでした。
6. 料金と処理時間
料金は、ドキュメント翻訳の場合は基本的にページ単位で、使う翻訳モデルによって単価が変わります。
表に出てくる2つのモデルは、それぞれ次のものです。
- NMT(ニューラル機械翻訳):Google が用意した標準の事前学習モデルです。学習は不要で、リクエストでモデルを指定しなければこれが使われます。
- カスタムモデル(AutoML):自分の対訳データを使って AutoML Translation で学習させた専用モデルです。ドメイン固有の言い回しに寄せられるぶん、単価は高くなります。
When you request a translation by using Cloud Translation - Basic, Google uses a pre-trained Neural Machine Translation (NMT) model. For Cloud Translation - Advanced, you can use the pre-trained NMT model, the Translation LLM, or a custom AutoML Translation model.
引用元: 公式ドキュメント: Migrate to Advanced from Basic | Google Cloud
| 項目 | 単価 |
|---|---|
| NMT ドキュメント翻訳 | 0.08 ドル / ページ |
| カスタムモデル(AutoML)ドキュメント翻訳 | 0.25 ドル / ページ |
引用元: 料金ページ: Pricing | Google Cloud
今回の検証は、すべて標準の NMT(0.08 ドル / ページ)で実行しました。
スクリプトで model を指定していないため、自動的にデフォルトの NMT が使われます。
カスタムモデルを使う場合は、別途 AutoML でモデルを学習し、リクエストの model にそのモデルを指定する必要があります。
If not provided, the default Google model (NMT) will be used for translation.
引用元: API リファレンス: Method: projects.locations.translateDocument | Google Cloud
今回の検証では、ネイティブ2ページ、スキャン2ページ、用語集あり(なし・ありの2系統が返る)を実行しました。
合計でおおよそ8ページ分で、1 ドル未満でした。
処理時間は公式に固定値の記載がないため、実測した値を載せておきます。
実行のたびに少し変わりますが、目安として次のくらいでした。
| 文書 | ページ数 | 処理時間 |
|---|---|---|
| ネイティブ PDF | 2 | 約 2〜3 秒 |
| スキャン PDF | 2 | 約 7 秒 |
7. 検証してわかったこと
実際に試して確認できたことは、次の3つです。
| 試したこと | 結果 | 補足 |
|---|---|---|
| ネイティブ PDF をレイアウトを保ったまま翻訳 | できた | 色・フォント・ハイパーリンク・表・グラフを維持 |
| 用語集で独自用語(固有名詞)を固定 | できた | バラついた訳を統一。ただし取りこぼしはゼロではない |
| スキャン PDF を翻訳 | できた | 画像から文字を読み取って翻訳。元画像の色は残るが、訳文は重ね描きで書式の忠実度は落ちる |
そのうえで、できる/できないというより「仕様としてそうなっている」ため、先に知っておきたい点が2つあります。
| 仕様・制約 | 内容 |
|---|---|
| 用語集を作れるリージョン | us-central1 のみ(翻訳そのものは global か us-central1) |
| 帰属表示 | 「Machine Translated by Google」が既定で付く。customizedAttribution で文言は変えられるが、表示自体は必須 |
このうち運用で効いてくるのが用語集のリージョンです。
データを日本国内に置きたいといった要件があると、用語集が us-central1 固定なのでそのままでは満たせません。
本格導入の前に確認しておきたいところです。
8. まとめ
Cloud Translation API の Document Translation は、PDF をファイルのまま渡すだけでレイアウトを保って翻訳でき、用語集を使えば独自用語の翻訳も固定できました。
最小構成なら Cloud Storage も認証キーも不要で、最初の一歩はかなり手軽です。
独自用語の多い社内文書や、製品名を統一したいマニュアルの翻訳では、用語集が効いてくると思います。
一方で、スキャン PDF は元画像をそのまま使う分書式の忠実度がネイティブに多少劣ります。用語集を置けるリージョンなどの制約もあります。
扱う文書がネイティブかスキャンか、データ所在地の要件があるか、といった点と照らし合わせて選ぶことになりそうです。
本記事が、PDF 翻訳の自動化を考えている方の参考になればうれしいです。






