![[レポート] Amazon Redshift Serverless におけるAI駆動スケーリング #AWSreInvent #ANT420](https://images.ctfassets.net/ct0aopd36mqt/4pUQzSdez78aERI3ud3HNg/fe4c41ee45eccea110362c7c14f1edec/reinvent2025_devio_report_w1200h630.png?w=3840&fm=webp)
[レポート] Amazon Redshift Serverless におけるAI駆動スケーリング #AWSreInvent #ANT420
クラウド事業本部の石川です。データエンジニアやアーキテクトにとって、予測可能なワークロードと予測不可能なワークロードの両方を管理する際の最大の課題の一つが、適切なクラスタのサイジングです。リソースを過剰にプロビジョニングすればコストがかさみ、不足すればパフォーマンスの低下や小規模クエリへの影響が生じます。
この課題に対処するため、Amazon Redshift Serverlessは、手動でのチューニングを必要としないAI駆動スケーリングと最適化というインテリジェントな機能を提供します。実際の設定は、コスト重視とパフォーマンス重視をスライダーバーで簡単に指定するだけなのですが、それだけにどのような仕組みで実現しているのか気になるところです。
本セッションでは、この機能がどのようにして大規模なETLパイプライン、バースト的なダッシュボードトラフィック、変動するデータボリュームを自動的に処理し、パフォーマンスとコストの双方を最適化するのか、そのアーキテクチャと設計思想を深く掘り下げていきます。
概要
AI-driven scaling in Amazon Redshift Serverless(ANT420)
For data engineers and architects managing both predictable and unpredictable workloads, AI-driven scaling and optimization in Amazon Redshift Serverless brings intelligent scaling without manual tuning. This session covers how, AI-driven scaling and optimization handles large ETL pipelines, bursty dashboard traffic, and shifting data volumes—automatically. We’ll break down the architecture, design choices, and predictive models behind it, then whiteboard real-world scenarios showing how the AI-driven scaling and optimization optimizes for both performance and cost.
予測可能なワークロードと予測不可能なワークロードの両方を管理するデータエンジニアとアーキテクトにとって、Amazon Redshift Serverless の AI 駆動型スケーリングと最適化は、手動チューニングなしでインテリジェントなスケーリングを実現します。このセッションでは、AI 駆動型スケーリングと最適化が、大規模な ETL パイプライン、バースト的なダッシュボードトラフィック、そして変化するデータボリュームをどのように自動的に処理するかを説明します。アーキテクチャ、設計上の選択肢、そしてその背後にある予測モデルを詳しく説明した後、AI 駆動型スケーリングと最適化がパフォーマンスとコストの両方を最適化する様子をホワイトボード形式で実例とともに紹介します。
スピーカー
- Ashish Agrawal, Principal Product Manager, AWS (写真の左の方)
- Davide Pagano, Software Development Manager, AWS(写真の右の方)

サイジングの課題
典型的なワークロードパターン
多くの組織が直面するサイジングに関連した課題として、以下のようなシナリオが挙げられます。
日中と夜間で異なるワークロード
日中はダッシュボードクエリが実行され、夜間にはETL処理が走るケース。ダッシュボードクエリは定常的なワークロードである一方、ETLはコンピュート集約型の処理となります。
スパイクワークロード
全体の90%は定常的なワークロードでも、残り10%が大規模でコンピュート集約型のスパイクワークロードとなるケースが存在する。
月次の大規模処理
月末の財務処理など、定期的に発生する大規模な処理がある。
従来のスケーリング手法の限界
-
ワークフローパターン
- 定常状態の小さなクエリ、夜間の大規模 ETL、月に一度発生する大規模な財務イベントなどのジャンボクエリといった、共通のワークフローパターンが示され、それぞれ異なるスケーリング要件を持つことが指摘されました。
-
従来のサイジングの問題点
- 小さなワークロードに合わせてサイジング(例:32RPU)すると、大規模で複雑なクエリがクラスター全体を遅くし、小さなクエリの実行も遅延させ、結果的により大きなコストが発生する可能性があります。
- ピークに合わせてサイジング(例:256 RPU)すると、それは垂直スケーリングに該当しますが、ほとんどの時間で容量が過剰にプロビジョニングされ、不要な容量に対してコストを支払うことになります。
-
水平スケーリングの検討
- 水平スケーリングは追加のコンピューティングを追加しますが、複雑なクエリが本当に250 CPU cores(CPUコア)を必要とする場合、水平にスケールしても個々のコンピューティング能力が不足しているため、パフォーマンスは向上しません。
-
従来の限界
- 水平スケーリングや垂直スケーリングだけでは、変動するワークロード、データ量の増加、およびヘビーヒッター(非常に大規模なクエリ)に対処できません。
-
解決策
- そこで、水平方向と垂直方向の両方にスケーリングできるダイアゴナル・スケール(斜めスケーリング)という概念が導入されました。これが K-advanced scaling の機能の基礎となります。
スケーリング戦略
3つのスケーリング戦略
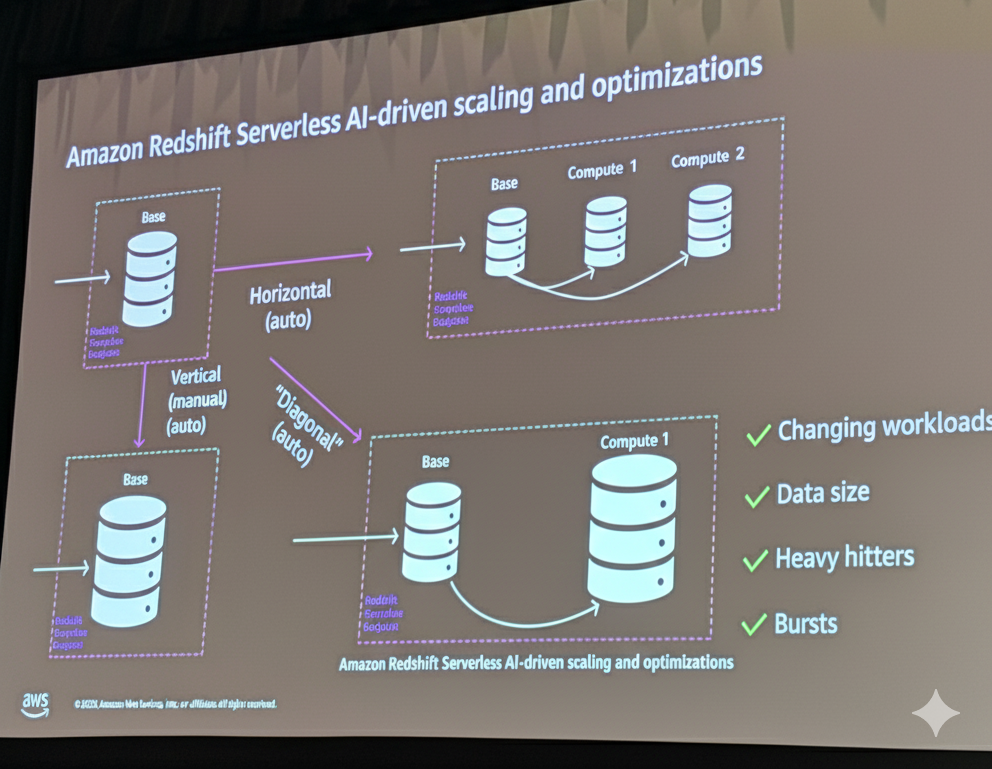
垂直スケーリング(Vertical Scaling)
最小限のワークロードに合わせてサイズを設定した場合(例:32 RPU)、大規模クエリが来た際にクラスター全体が遅くなり、小規模クエリにも影響が出ます。逆にピークに合わせてサイズを設定すると(例:256 RPU)、大半の時間でオーバープロビジョニングとなり、不要なコストが発生します。
水平スケーリング(Horizontal Scaling)
定常クエリ用に32 RPUのベースを設定し、負荷に応じて追加のコンピュートを配置する方式です。しかし、これらは分離されたワークグループであるため、256 RPUを本当に必要とする複雑なクエリは、どのコンピュートを選んでも十分なパフォーマンスが得られません。
対角スケーリング(Diagonal Scaling)
AI駆動スケーリングの基盤となる概念で、水平方向と垂直方向の両方にスケールできる能力です。変化するワークロード、増大するデータサイズ、ヘビーヒッタークエリ、そして季節性に対応できます。
AI駆動スケーリングの設定
Redshift Serverlessのパフォーマンスタブには、コスト最適化とパフォーマンス最適化のバランスを調整するスライダーがあります。
- コスト最適化(0): コストを優先
- バランス(50): AI駆動スケーリングがワークロード情報に基づいて自動判断
- パフォーマンス最適化(100): パフォーマンスを優先
スライダーの位置に基づいて、AI駆動スケーリングが自動的にワークロードをスケールします。
AI駆動スケーリングの仕組みとアーキテクチャ
AI-driven scaling が実際にどのように機能するかに付いて解説します。
予測モデルへの入力
クエリが投入されると、システムは以下の情報を使用してコンピュート要件を判断します。
クエリプラン
パーサー、リライター、プランナーを経て生成される実行ツリー。どのステップ(テーブルスキャンなど)が実行されるかを示します。
特徴量(Features)
データボリューム、ジョイン数、データ特性(Spectrumクエリか、マテリアライズドビュークエリか、データ共有クエリかなど)。
予測器(Predictors)のアーキテクチャ
シミュレーションベースのアプローチは、すべてのスケールでクエリを実行する必要があり、特に複雑なクエリでは非常に高コストになります。そのため、AI/MLベースの予測器が採用されています。
グローバル予測器
Redshift全顧客のデータで訓練。コールドスタート問題を解決し、分布外クエリにも対応できます。
ローカル予測器
特定のクラスターで訓練。より小さく、高速に再訓練され、そのクラスター固有のクエリパターンに最適化されます。
K-Meansクラスタリング
過去の実行をキャッシュとして機能させます。例えば、100万行をスキャンするクエリが34 RPUで10分かかることを観測していた場合、翌日に100万1行をスキャンする同様のクエリが来ても、新しい予測は不要です。1行の差は全体に影響しないため、同じ実行時間を予測できます。
重要なのは、テーブルIDへの依存度が低いことです。クエリの形状やデータ特性に基づいて予測するため、テーブルが日々再作成されるようなケースでも予測精度が維持されます。
クエリのスケーラビリティプロファイル
予測器はクエリのスケーラビリティプロファイルを判断します。スケーリングパターンを3つに分類。サブリニアクエリをスケールするかどうかは、パフォーマンススライダーの設定に依存します。パフォーマンス最適化を選択していれば、ある程度のコスト増加を許容してスケールしますが、コスト最適化を選択していれば、スケールしない判断がなされます。
線形スケーリング
リソースを2倍にすると、パフォーマンスも2倍向上(1時間→30分)するパターン。
サブリニアスケーリング
リソースを2倍にしても、パフォーマンス向上は2倍未満(1時間→44分)するパターン。短いクエリやライトバウンドのロードで発生しやすい。
スーパースカラースケーリング
リソースを2倍にすると、パフォーマンスは2倍以上向上(1時間→10分)するパターン。リソース競合が激しいクエリで発生。スーパースカラークエリは、2倍のリソースコストを支払っても、実行時間が大幅に短縮されるため、結果的にコスト削減にもつながります。サーバーレスは従量課金なので、短時間で完了すれば総コストも下がります。
ポリシーオプティマイザー
クエリ単位の最適化だけでなく、ワークロード全体を見た最適化も行われます。
例えば、小さなクエリに32 RPU、大きなクエリに256 RPUが最適だとしても、両方を考慮すると、中間の128 RPUを定常状態として設定した方が全体的に効率的な場合があります。大きなクエリには十分なリソースを提供しつつ、小さなクエリのコスト増加も抑えられます。
ポリシーオプティマイザーはバックグラウンドで実行され、十分なクエリデータが蓄積された後(場合によっては1日後など)に、ベースRPUのリサイズをトリガーします。これは単一クエリではなくワークロード全体に影響する重要な判断であるため、慎重に行われます。
導入事例
- コスト管理(ガバナンス)
- 予期せぬコストを防ぐために、ユーザーは最大容量 (max capacity) や、日次または月次の RPU 時間に基づく使用量制限 (usage limits) を設定できます。
- 顧客の成功事例
- ある大手自動車メーカーのベンチマーク結果が共有されました。
- 「パフォーマンスの最適化」を設定した結果、4倍のパフォーマンス向上を達成したにもかかわらず、コストも削減されました。これは、顧客のワークロードがリソースを追加するほど、そのリソース増加率以上にパフォーマンスが大幅に向上するクエリ(Super Scaler Query)が多かったことを示唆しています。
- 最終的に、ニーズに合致していたコスト最適化を選択しました。
- ある大手自動車メーカーのベンチマーク結果が共有されました。
デモ
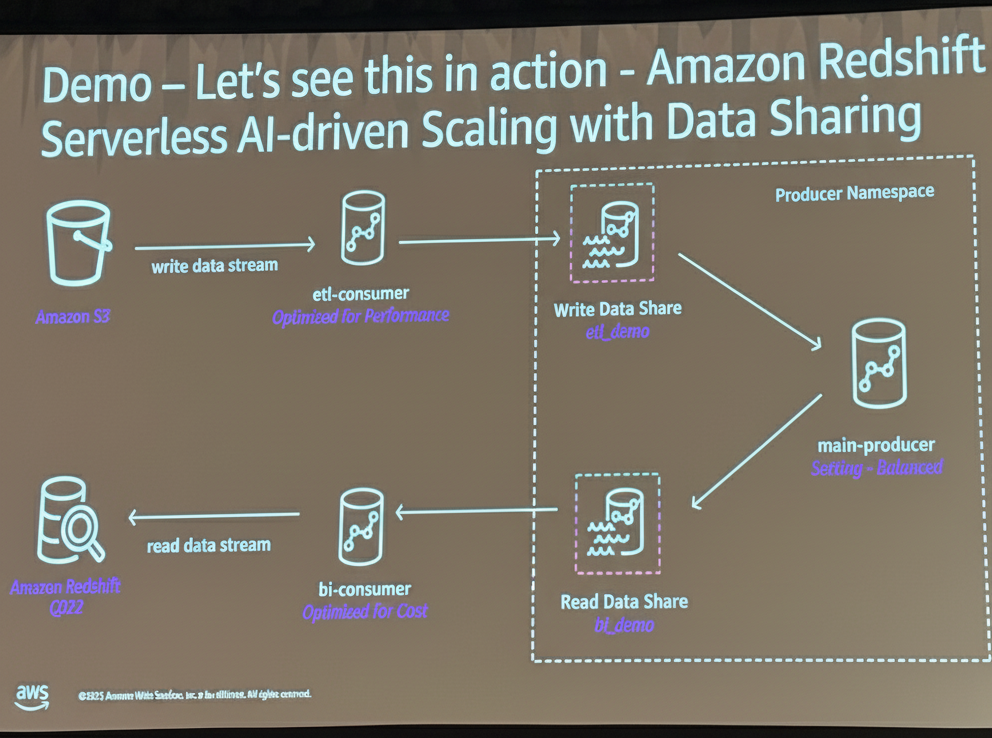
- メインプロデューサー、ETLコンシューマー(パフォーマンス最適化設定)、BIコンシューマー(コスト最適化設定)という3つのクラスターを用いたデモが紹介されました。
- ETLコンシューマーは、大規模ロード時に迅速に処理を完了するために、1.8 RPUまでスケールアップしました。
- 一方、BIコンシューマーは、コスト最適化が設定されていたため、高負荷な処理を実行しても、定常状態の 64 RPU を維持し、スケールアップしませんでした。
- 結論と推奨事項
- ユーザーは、まず目標、期待、目的を設定し、そこから逆算して作業を進めるべきであり、AI駆動スケーリングはそのプロセスを支援します。
補足: AI駆動スケーリングに関する質疑応答
1. ワークロードとサイジングの課題(問題提起)
Q. Sizing(サイジング)に関して、現在抱えている具体的なペインポイント(課題)は何ですか?
A. 聴衆から挙げられた課題には以下のようなものがあります。
- コールドスタートの問題
- 小さなサーバーで実行に20秒かかること。
- 巨大な負荷
- システムを停滞させるような巨大な(enormous)負荷(多くのデータサイエンス処理など)。
- データ共有の遅延(ラグ)
- データ共有において遅延が発生すること。
- 異なるコンピューティングエンジンの必要性
- Spectrum(データレイクのクエリ)と非Spectrumのワークロードに対して異なるコンピューティングエンジンが必要であること。
- 処理時間の問題
- 処理に15分かかってしまうこと。
Q. 変動するワークロードや、データ量の増加、大規模クエリ(ヘビーヒッター)への対処において、垂直スケーリングや水平スケーリングの限界は何ですか?
A. 従来の垂直スケーリング(ピークに合わせてサイジングする)では、ほとんどの時間で容量が過剰にプロビジョニングされ、不要なコストが発生します。一方、水平スケーリング(追加のコンピュートを追加する)では、複雑なクエリが個々のコンピュートの能力を超えている場合、パフォーマンスが向上しないという問題があります。また、変動するワークロード、データ量の増加、そしてヘビーヒッター(非常に大規模なクエリ)は、水平または垂直スケーリングだけでは適切に対処できません。
2. AI駆動スケーリング(予測器)の仕組み
Q. クエリの実行に必要なコンピューティング量を予測するために、どのような情報(入力)が必要ですか?
A. クエリをカテゴリ化し、必要なコンピューティング量を理解するために、以下の要素が入力として使用されます。
- クエリの形状(Query Shape)/ クエリプラン
- Redshiftのプランナー層で解析・書き換えられた結果得られるクエリツリーや実行ツリー(どの操作が実行されるか)。
- 特徴量(Features)
- データ量 (Volume of data)、結合数 (Number of joins)、データの特性(Spectrumクエリか、マテリアライズドクエリか、データ共有クエリかなど)。
Q. コンピューティング量を予測するための主要な技術は何ですか?シミュレーションの問題点は何ですか?
A. 主要な技術は予測器(Predictors)であり、AI/ML指向のモデルが採用されています。シミュレーションを使用すると、クエリをすべての可能なスケールで実行する必要があるため、特に複雑なクエリの場合、非常に高価になりすぎるという欠点があります。
Q. 予測器にはどのような種類があり、それぞれの利点は何ですか?
A. 予測器には、グローバル予測器とローカル予測器の2種類があります。
| 種類 | 訓練データ | 利点 |
|---|---|---|
| グローバル予測器 | Redshiftの全顧客のデータ | コールドスタート問題やアウト・オブ・ディストリビューションのクエリに対処できる。AI駆動スケーリングを使い始めたばかりでもすぐに利用開始できる。 |
| ローカル予測器 | 特定のクラスター(ユーザーのクラスター)のデータ | 訓練が速く、頻繁に再訓練され、特定のクラスター固有のクエリのセットに合わせてファインチューニングされる。 |
Q. テーブルが毎日書き換えられる場合、予測器のデータは失われますか?
A. いいえ、データは失われません。予測器にはKNM(クラスタリングアルゴリズム)と呼ばれるレイヤーが組み込まれており、これはキャッシュのように機能し、過去の実行を保存します。システムはテーブルIDに過度に依存せず、たとえば100万行をスキャンするクエリが翌日100万1行をスキャンしても、新しい予測は必要とせず、過去の実行データから学習します。
Q. クエリのタイプ(線形、サブ線形、スーパー・スケーラー)はどのように定義されますか?
A. クエリは、リソース増加に対するパフォーマンス向上の度合いに基づいて分類されます。
-
線形スケーリング
- リソースを2倍(例: 32 RPUから64 RPU)にすると、パフォーマンスも2倍(例: 1時間から30分)に向上するクエリ。
-
サブ線形スケーリング
- リソースを増やしても、パフォーマンスの向上が少ないクエリ。非常に短いクエリや書き込み負荷の高い(write-bound)ロードが例として挙げられます。
-
スーパー・スケーラー(超線形)
- リソース競合が多く、リソースを増やすことでパフォーマンスが大幅に向上するクエリ。大規模な財務クエリなど、リソース競合が激しいクエリが該当します。
Q. サブ線形クエリ(Sub-linear queries)は、どのような場合にスケーリングされますか?
A. サブ線形クエリは、リソース増加に対するコスト増加が大きいため、常にスケーリングされるわけではありません。スケーリングするかどうかは、ユーザーが設定したパフォーマンススライダー(コスト最適化 vs. パフォーマンス最適化)の設定に依存します。パフォーマンス最適化を選択している場合は、わずかなパフォーマンス向上でもスケーリングが行われる可能性がありますが、コスト最適化を選択している場合は、コストが増加する動作はスケールされない可能性があります。
Q. 予測器は、個々のクエリごとにスケーリングの判断を行っているのですか?
A. はい、予測器とコンピュートマネージャーは、クエリのクリティカルパス上で、クエリごとに最適化とリソース決定を行います。このプロセスは非常に高速で、追加のオーバーヘッドは無視できる程度です。
Q. クエリごとの最適化ではなく、ワークロード全体を最適化する仕組みはありますか?
A. はい。ポリシーオプティマイザー(Policy Optimizer)がバックグラウンドで実行され、ワークロード全体を ホリスティックに最適化します。
-
機能
- 個々のクエリの実行トレースを集め、より広範な計算を実行して、ワークロード全体に基づいてクラスターの最適な定常状態のサイジングを計算します。
-
効果
- これにより、以前は手動で行う必要があった垂直スケーリング(定常状態のRPUサイズの調整)が自動化されます。
-
トリガー頻度
- ポリシーオプティマイザーはより複雑な計算を行うため、クエリが十分に収集された後(例:実行されるクエリの量に応じて1日後など)にトリガーされる可能性があります。
3. 設定とコストに関する質問
Q. パフォーマンスとコストの最適化スライダーは、どのレベルで設定できますか?
A. このスライダーはクラスターごと(per cluster)に設定されます。ユーザーは、パフォーマンスを最大化する「100」からコストを最適化する「0」までの間で選択できます。
Q. スケーリングによる予期せぬコスト増加を避けるためのガバナンス設定はありますか?
A. 予期せぬコストを避けるために、ユーザーは以下の制限を設定できます。
-
最大容量(Max capacity)
- 上限を設定します。
-
使用量制限(Usage limits)
- 日次または月次ベースで RPU 時間(RPU hours)の最大制限を設定できます。
Q. スライダーを動かした際、コストがどのように変化するかを事前に推定する方法はありますか?
A. 現時点では、スライダーの変更に基づいたコストの変化を事前に推定する方法はありません。講演者は「我々はそれに取り組んでいる(We're working on that)」と述べています。最も確実な方法は、実際に使用してみて、ステータスがどうなるかを確認することです。
Q. 非常に短い(10秒未満の)クエリをミリ秒単位の応答時間(例:0.5秒)に短縮するために、AI駆動スケーリングは役立ちますか?
A. そのパフォーマンスレベル(ミリ秒単位)の目標は、AI駆動スケーリングの現在のバランス設定では十分ではないかもしれません。講演者は、この種の質問への対応は、現在開発中の別の機能で解決される可能性があると示唆しています。
4. 顧客事例とデモに関する質問
Q. 大手自動車メーカーの事例では、パフォーマンス最適化設定時にコストが削減されたのはなぜですか?
A. この顧客は「パフォーマンスの最適化」を設定したにもかかわらず、パフォーマンスが4倍に向上しただけでなく、結果的にコストも削減されました。これは、顧客らのワークロードにスーパー・スケーラー(超線形)なクエリが多かったことを示唆しています。スーパー・スケーラーなクエリは、リソースを増やして実行時間を短縮することで、トータルコストを削減できる性質があります。この企業は最終的に「コストの最適化」を選択しました。
Q. Serverlessに移行すれば、常にコストとパフォーマンスの両面でメリットがあると言って安全ですか?
A. いいえ、必ずしもそうとは限りません。AI駆動スケーリングは、自動化を通じてメリットをもたらしますが、ユーザーのワークロードに大きく依存します。もし顧客が自身のワークロードを深く理解し、24時間365日Redshiftの運用に専念できる専門チームを持っている場合、手動での最適化が潜在的により良い結果をもたらす可能性もあります。しかし、専任チームを持たない顧客にとっては、特にスーパー・スケーラーなワークロードがある場合、AI駆動スケーリングがコストとパフォーマンスの両方を節約する可能性があります。
Q. デモで示されたETLコンシューマーは、大規模ロード時にどのようにスケールしましたか?
A. パフォーマンス最適化(Optimized for performance)に設定されていたETLコンシューマーは、大規模なロード(COPYステートメント)を実行した際に、ワークロードを迅速に完了するために1.8 RPUまでスケールアップしました。
Q. デモで示されたBIコンシューマーは、高負荷時にどのように動作しましたか?
A. コスト最適化(Optimized for cost)に設定されていたBIコンシューマーは、高負荷な処理を実行しても、定常状態の 64 RPU を維持し、スケールアップしませんでした。
次のステップ
AI駆動スケーリングにおける予測器の数学的アルゴリズムや計算の詳細について、Davide Paganoさんも共同執筆者に名前を連ねている、下記の論文をご紹介されました。
最後に
本セッションは、チョークトークと言って、簡単な資料とホワイトボードを使って解説、随時聴衆からの質問を受けて進める形式のため、本当に知りたいことが聞ける有意義なセッションでもあります。
Amazon Redshift ServerlessのAI駆動スケーリングは、グローバル予測器とローカル予測器を組み合わせ、クエリごとに最適なリソース量を自動判断します。水平・垂直の両方向にスケールできる「対角スケーリング」により、従来のサイジング課題を根本的に解決します。コスト最適化からパフォーマンス最適化まで、スライダーひとつでワークロード特性に応じた調整が可能です。専任の運用チームを持たない組織でも、機械学習による自動最適化の恩恵を受けられる点が大きなメリットです。
とても画期的なAI駆動スケーリングでしたが、その詳細がブロックボックスなところがありましたが、本セッションを通じてイメージできるようになりました。改めて、上記の論文も読みブログ化したいところです。









