![[セッションレポート] Build AI architectures with custom models on Cloud Run 発表まとめ #GoogleCloudNext](https://images.ctfassets.net/ct0aopd36mqt/4VZteia2tZFWoXPzZmZcuT/32265bac33524fc15a9254504b80ef85/260401_eyechatch_googlecloudnext26_w1200h630.png?w=3840&fm=webp)
[セッションレポート] Build AI architectures with custom models on Cloud Run 発表まとめ #GoogleCloudNext
はじめに
こんにちは、すらぼです。Google Cloud Next Las Vegas' 26 のセッション "Build AI architectures with custom models on Cloud Run" (Cloud Run 上で AI モデルのデプロイ・ファインチューニングを行う) のセッションレポートです。
ここよりセッション紹介
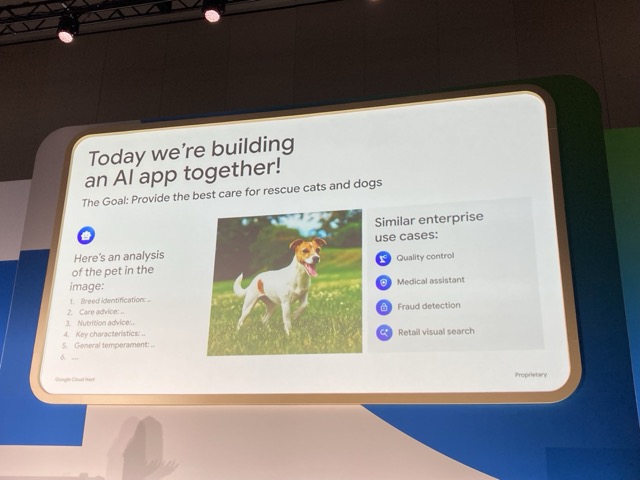
今回想定するケース
架空の企業「PetLife」の架空のサービス「Smart Pet Care」を題材に、社内Slackに投稿されるペット画像から品種を識別し、飼育アドバイスを提供するツールを構築します。
同社のメンバーは動物がすごく好きで、保護猫や保護犬をたくさん保護しています。
そんな中、「保護した猫の種類は?」「餌のあげ方は?」といった質問に対し、ペットに関する質問が溢れかえっている状態が発生しました。これを解決するために、写真をアップロードすることで回答してくれるチャットを作成することを目指します。
今回はペットを例にしていますが、同様のパターン(マルチモーダル分類+専門的推論)は、品質管理、医療支援、不正検知、小売のビジュアル検索にも応用可能です。
エンタープライズ基準の5つの要件
エンタープライズ環境で動作させるために重要な要件は次の5つです。
プロトタイプとは全く異なり、高いハードルを超える必要があります。
- 開発の容易さと精度
- セキュアで、アクセス制限ができること
- コンプライアンス
- コスト効率
- スケーラブル

システムアーキテクチャ
このポイントを押さえた上で、以下のようなアーキテクチャ構成で実装をします。
- フロントエンド: Next.js + IAP
- 推論: vLLM + Gemma 4(RTX PRO 6000)
- 学習: Cloud Run Jobs(L4 GPU)
- ストレージ: GCS

また、実装計画は以下のステップで進めていきます。
- Gemma 4 のデプロイ
- フロントエンドの構築とセキュリティ
- ファインチューニング
- カスタムモデルの適用
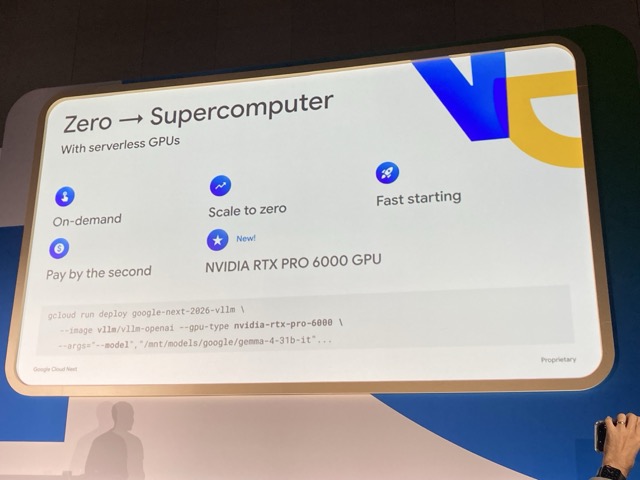
Cloud Run GPU について
構築の前に、Cloud Run GPU を紹介します。
今回デプロイするモデル Gemma4 は、Cloud Run GPU の最新版 "NVIDIA RTX PRO 6000 GPU" にぴったり収まります。必要なドライバーなどもプリインストールされており、デプロイがとても簡単にできます。
また、Cloud Runを選ぶ利点としては、オンデマンド・0台へのスケールイン・即時起動などが挙げられます。
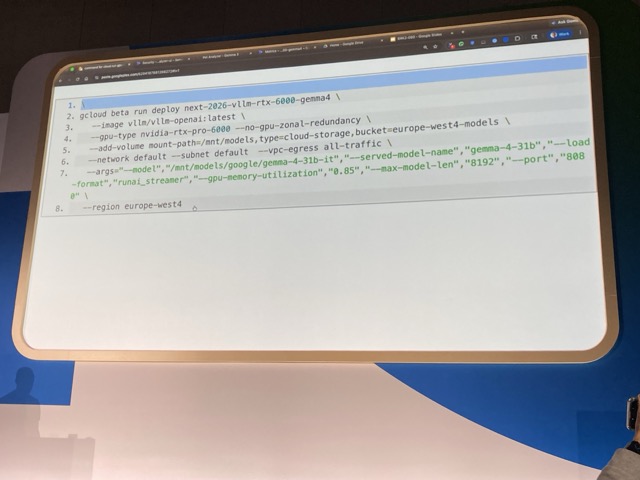
Phase 1: Gemma 4 のデプロイ
実際に Gemma4 をデプロイします。
用意したコマンドは、 vLLM にデプロイするためのコマンドです。モデルは GCS に事前にダウンロードしており、最新の vLLM イメージを使用しています。
また、高速なネットワーキングと迅速なコールドスタートのために Direct VPC Egress を有効化しています。
そのほか、LLM に必要なコマンドライン引数を追加し、デプロイします。
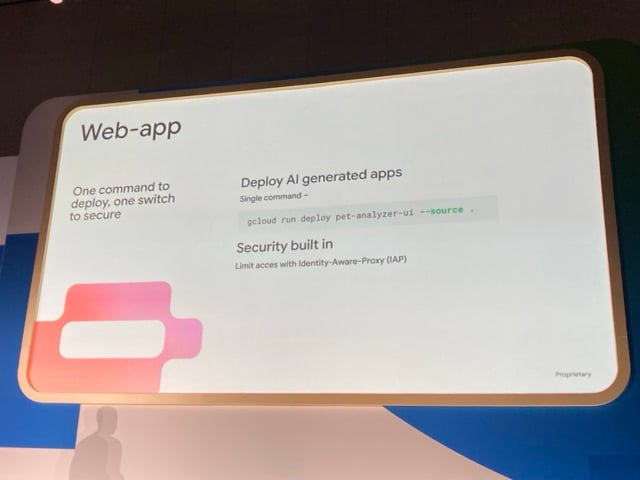
Phase 2: フロントエンドの構築とセキュリティ
次に、フロントエンドを構築します。今回は Next.js を使用し、こちらも Cloud Run にデプロイします。
セキュリティは標準機能である IAP を使用して、アクセス制限を行います。
デプロイが完了し、設定を行うと以下のようにチャットができるようになります。
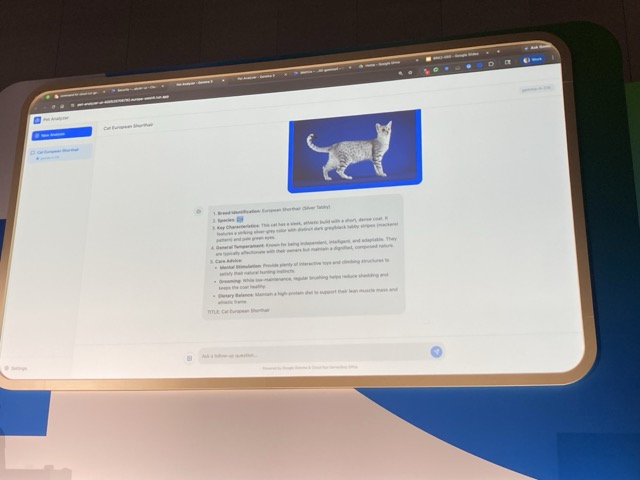
ベースモデルの限界
しかし、回答の精度に限界があることを感じました。具体的には猫の種類を誤って判定しており、 "エジプシャン・マウ" を "ヨーロピアン・ショートヘア" と誤判定しています。

(※画像の拡大及び編集は筆者によるもの)
なぜファインチューニングが必要か
Gemini のような強力なモデルがある中で、なぜファインチューニングが必要なのでしょうか?
それは、3つの理由があります。
- 高い専門性
- 汎用モデルからエキスパートモデルへの変換
- 今回のような、ペットに適切なおやつを与えるために、37種類の犬と猫の品種を非常に高い精度で識別する必要がある場合など
- セキュリティ・主権
- 外部APIにデータを送れない場合など。この場合はセルフホストが必要になる。
- コスト効率
- Gemma4 の場合、単一GPUで動作するモデルのうち最も有効なもの
- トークン課金制ではないこと
- Scale-to-Zero によって、未使用の場合は利用費がゼロになること。もちろんスケールアウトも可能。
NVIDIA 論文: Small Language Models are the Future of AI Agents

Cloud Run Jobs での Fine tuning 実行
目的・理由が整理できたところで、 Fine tuning を Cloud Run jobs GPU で実行する流れを確認します。
- Hugging Face → GCS にモデルを事前ダウンロード
- Cloud Run Jobs(L4 GPU)で実行
- LoRA で一部の重みのみ更新
- 学習済みモデルを GCS に保存
今回の学習データ: Oxford-IIIT Pet Dataset(37種の犬猫)

この結果が以下の通りです。
- かかった時間: 4時間以下
- 精度: 89% → 94%
※参考: Google 社内の検証では、Gemma 3 でもファインチューニングによって 76% → 94% に向上。
Phase 4: カスタムモデルの適用
このモデルを、先ほどのコマンドと同様に再デプロイします。
そして、実際にモデルの回答が「エジプシャン・マウ」になったことが確認できました。
(筆者注:肝心なこの場面の写真がありません。すみません。)
Elastic社の本番運用事例
Elastic 社の事例として、月間約1兆トークンを処理するエンベディング・リランキングモデルのホスティング事例を紹介します。
共有GPUプールの課題
Elastic 社では、他社の買収などにより、17以上のモデルを Cloud Run で本番運用しています。
その数のモデルをホストする中で、初めは「共有GPUプール」を作り、全部のモデルで共有する方式をとっていました。しかし、スケールするに従って以下の課題が見えてきました。
1. 軽量化が困難、運用コストが高い
これらのモデルはすべて、要件、メモリのニーズ、トラフィックがスパイクするパターンが信じられないほど異なります。割り当てを常に調整し続けなければなりません。
2. アイドルコスト
ごく稀にしか使用されないものの、使用される時は非常に集中的に使用される特化型モデルがあります。そのマシンプールを管理するために専用のGPUプールを待機させておくのは好ましくありません。

GPUプールの解決策
転換点となったアーキテクチャ上の大きな解決策は、GPUを代替可能な計算リソースとして扱うことでした。
GPUを単一の箱として扱うのをやめ、「GPUは他のものと同様に計算プールである」と考えることで、「1つのモデルに対して1つのGPUプールを割り当て、理想的にはゼロにスケールダウンする」という形に変換されました。

Cloud Run でのアーキテクチャ
構成
- API Gateway: 標準 Cloud Run(GPUなし)で Redis によるレート制限・認証・ルーティング
- 各モデルサービス: 各バリアントが独立した Cloud Run サービス
- 設定値:L4 GPU、min_instances: 0
コールドスタート最適化
- CUDA のメモリロードが4〜25分 → enforce_eager=True で数秒(エンベディングモデルでは軽微なレベル)に短縮

得られた成果
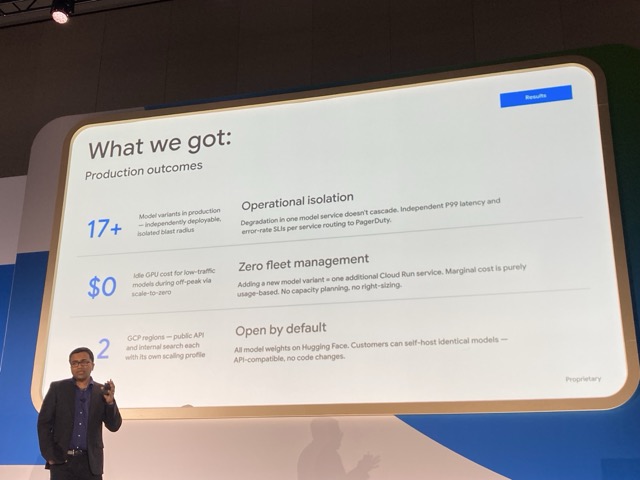
最終的に以下の成果が得られました。
17以上のモデルを独立稼働(運用の分離)
17種類以上のモデルを本番環境にデプロイしています。各サービスが独立しているため、1つのモデルでパフォーマンス低下などの障害が起きても他へ波及しません。アラートもサービスごとに独立してPagerDutyへ通知されます。
アイドル時のGPUコスト$0(インフラ管理ゼロ)
Cloud Runの「Scale to Zero」により、オフピーク時やアクセスの少ないモデルのGPU待機コストを完全にゼロに抑えています。面倒なキャパシティ計算やサイジング調整が不要になり、新しいモデルを追加する際もCloud Runサービスを1つ増やすだけの完全従量課金で済みます。
2つのGCPリージョン展開(デフォルトでオープン)
パブリックAPI用と社内検索用で、それぞれ独立したスケーリング設定を持たせて2リージョンで展開しています。また、使用しているモデルの重みはすべてHugging Face上で公開されており、顧客側でもAPIの互換性を保ったまま、コード変更なしでセルフホストが可能になっています。
セッション紹介ここまで
終わりに
gcloud コマンド1つで Gemma 4 をデプロイでき、ファインチューニングも Cloud Run Jobs で完結する一貫性や手軽さが印象的でした。
大規模モデルの発展速度が著しい中でファインチューニングが求められるシーンは、筆者としてはまだ判断がつきません。ただ、もし必要になった瞬間には、Cloud Run が強力な選択肢になるということを強く感じるセッションでした。
この記事が皆さんのお役に立てば幸いです。以上、すらぼでした。









