
【アップデート】Vertex AI Model GardenでClaude Opus 4.7が利用できるようになりました
はじめに
こんにちは。
クラウド事業本部コンサルティング部の渡邉です。
2026年4月16日、Vertex AI Model GardenでClaude Opus 4.7が GA(一般利用可能) になりました。
Claude Opus 4.7 は Anthropic の最新の最上位モデルシリーズです。1,000,000 トークンの入力コンテキスト、128,000 トークンの最大出力、そして Extended thinking(拡張思考) や Computer use をフルサポートする機能セットを備えています。
今回は、Claude Opus 4.7 の概要と前バージョン(Opus 4.6)からの主な変更点、そして Vertex AI 経由で実際に API を呼び出すハンズオンまでの流れを見ていきたいと思います。
Claude Opus 4.7 とは
Claude Opus 4.7 は、コーディング・エージェント・Computer use・エンタープライズワークフローに最適化された Anthropic の最上位モデルです。Vertex AI 経由で利用することで、Google Cloud の IAM・組織ポリシー・監査ログといったエンタープライズセキュリティ機能をそのまま適用できます。
Anthropic の発表によると、Opus 4.6 と比較して特にソフトウェアエンジニアリングの高度なタスクで著しい改善が見られ、「複雑で長時間実行されるタスクを厳密性と一貫性で処理する」モデルとして位置づけられています。
Vertex AIのModel GardenからもOpus 4.7が確認でき、モデルの詳細情報を確認することができます。
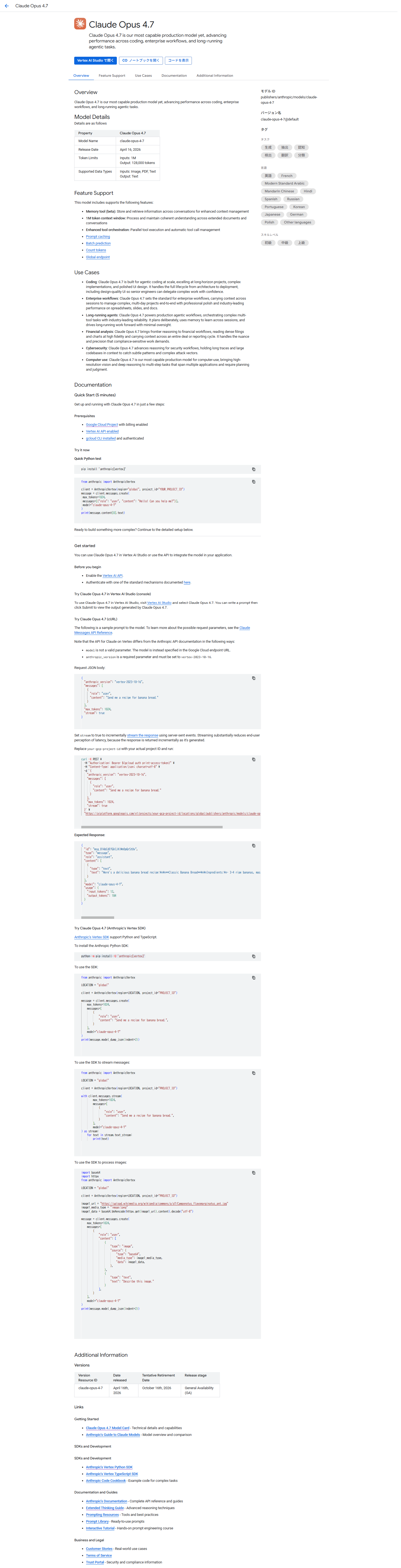
サポート機能
Claude Opus 4.7でサポートされている機能になります。
| 機能 | 対応 |
|---|---|
| Computer use | ✅ |
| Web search | ✅ |
| Extended thinking(拡張思考) | ✅ |
| Batch predictions | ✅ |
| Prompt caching | ✅ |
| Function calling | ✅ |
| Count tokens | ✅ |
| Provisioned Throughput | ✅ |
主なユースケース
Model Garden のモデルカードでは、Claude Opus 4.7 の代表的なユースケースとして以下の6つが挙げられています。
| ユースケース | 説明 |
|---|---|
| コーディング | 長期にわたるプロジェクト・複雑な実装・大規模なコードベースのリファクタリングなど、大規模なアジェンティックコーディングに最適 |
| エンタープライズワークフロー | スプレッドシート・スライド・ドキュメントなど業務ファイルの横断的な処理・分析・作成をエージェントとして実行 |
| 金融分析 | 財務ワークフローへの高度な推論の適用。規制対応や大規模なコンプライアンス業務の自動化 |
| サイバーセキュリティ | セーフティ強化トレーニングにより、セキュリティ関連の複合的タスクを安全かつ高精度に処理 |
| カスタマーサポート | 複雑な問い合わせへの対応・社内ドキュメントの参照・長い会話コンテキストの維持を組み合わせた高度なサポートエージェント |
| Computer use | 高精度な PC 操作の自動化。Web ブラウジング・GUI 操作・デスクトップアプリ連携など幅広いタスクに対応 |
スループットの大幅向上
Claude Opus 4.7 では、グローバルエンドポイントのクォータが Opus 4.6 から2倍に引き上げられています。
リージョン別クォータ
| リージョン | QPM | Input TPM | Output TPM | Context length |
|---|---|---|---|---|
| us(マルチリージョン) | 400 | 4,000,000 | 400,000 | 1,000,000 |
| eu(マルチリージョン) | 400 | 4,000,000 | 400,000 | 1,000,000 |
| global endpoint | 800 | 8,000,000 | 800,000 | 1,000,000 |
グローバルエンドポイント(global リージョン)を使うと、単一リージョンの2倍のスループットが得られます。高トラフィックなエージェントワークロードでは、グローバルエンドポイントの活用を検討するとよいでしょう。
対応リージョン
Claude Opus 4.7 は以下のリージョンで利用できます。
現状シングルリージョンでのサポートはなく、グローバルリージョンか、usとeuのマルチリージョンでのサポートになるようです。
| リージョン種別 | リージョン |
|---|---|
| 米国 | us(マルチリージョン) |
| 欧州 | eu(マルチリージョン) |
| グローバル | global endpoint |
Multi-region endpoint(Preview)
Claude Opus 4.7 のリリースに合わせて、Multi-region endpointが Preview として追加されました。これは「米国」「EU」といったより広い地理的スコープでの高可用性アクセスとデータレジデンシー制御を実現する新しいエンドポイントです。
エンドポイント URL
| リージョン | エンドポイントホスト | locations パラメータ |
|---|---|---|
| 米国 | aiplatform.us.rep.googleapis.com |
us |
| EU | aiplatform.eu.rep.googleapis.com |
eu |
通常のシングルリージョンエンドポイント(us-east5-aiplatform.googleapis.com)とは異なり、locations に us や eu を指定します。
サポート状況
現時点でサポートされているモデルは Claude Opus 4.7 のみです。今後以下のモデルも順次対応予定とされています。
- Claude Haiku 4.5
- Claude Sonnet 4 / 4.5
- Claude Opus 4.5 / 4.6
Multi-region endpoint の制限事項
Provisioned Throughput は Multi-region endpoint では利用できません。
| 項目 | 対応状況 |
|---|---|
| Prompt caching | サポート |
| Provisioned Throughput | 非サポート |
| SLA | Preview のため対象外 |
試してみた
ここからは、実際に Claude Opus 4.7 を Vertex AI で使う手順を見ていきます。
前提条件
- Google Cloud プロジェクトが作成済みであること
gcloudCLI がインストール・認証済みであること- 以下の API が有効化されていること
- Vertex AI API(
aiplatform.googleapis.com)
- Vertex AI API(
- Vertex AI Model Garden で Claude Opus 4.7 が有効化されていること
- anthropic SDKのバージョンは
0.96.0であること
Model Garden で Claude Opus 4.7 を有効化する
Vertex AI コンソールの Model Garden で Claude Opus 4.7 のモデルカードを開き、Enable をクリックしてモデルを有効化します。初回は Anthropic の利用規約への同意が求められます。
有効化の手順は以前ブログで記載した Claude Sonnet 4.6の有効化手順と変わらないため、以下のブログを参照ください。
Cloud Shell上で以下の初期設定を行っていきます。
# プロジェクトを設定
export PROJECT_ID="your-project-id"
export REGION="global"
gcloud config set project $PROJECT_ID
Anthropic Vertex SDK を使って呼び出す
Python の anthropic ライブラリを使って Claude Opus 4.7 を呼び出します。
# Anthropic SDK のインストール
pip install anthropic[vertex]
Anthropic Vertex SDKを利用して、以下のPythonコードを実行してみます。
from anthropic import AnthropicVertex
client = AnthropicVertex(
region="global",
project_id="your-project-id",
)
message = client.messages.create(
model="claude-opus-4-7",
max_tokens=1024,
messages=[
{
"role": "user",
"content": "Vertex AIについて5行で説明してください。"
}
],
)
print(message.content[0].text)
以下の回答が得られました。
Vertex AIは、Google Cloudが提供する統合型の機械学習・AI開発プラットフォームです。データ準備からモデルの学習、デプロイ、運用までのMLライフサイクル全体を一元的に管理できます。AutoMLによるノーコード開発と、カスタムモデル開発の両方に対応しており、幅広いユーザーが利用可能です。GeminiをはじめとするGoogleの基盤モデルやサードパーティモデルをAPI経由で活用できる生成AI機能も備えています。MLOps機能も充実しており、エンタープライズ規模でのAI活用を効率的に実現します。
Extended thinking(拡張思考)を使う
Claude Opus 4.7 では Adaptive thinking がサポートされています。
from anthropic import AnthropicVertex
client = AnthropicVertex(
region="global",
project_id="your-project-id",
)
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=16000,
thinking={"type": "adaptive"},
output_config={"effort": "high"}, # 思考の深さを制御(後述)
messages=[
{
"role": "user",
"content": "大規模なマイクロサービスアーキテクチャを設計する際の主要な考慮事項を、トレードオフも含めて詳しく分析してください。"
}
],
)
print(response.content[0].text)
以下の回答が得られました。
# 大規模マイクロサービスアーキテクチャ設計の主要考慮事項
## 1. サービス分割の粒度(Service Granularity)
### 考慮事項
- **境界づけられたコンテキスト(Bounded Context)** に基づく分割(DDD)
- ビジネスケイパビリティ単位での切り出し
- データ所有権の明確化(各サービスが自身のDBを持つ)
### トレードオフ
| 細かすぎる分割 | 粗すぎる分割 |
|---|---|
| 運用複雑性の爆発、ネットワークオーバーヘッド増 | モノリスに逆戻り、デプロイの独立性が損なわれる |
| 分散トランザクションの困難化 | スケーリングの柔軟性低下 |
**実践的指針**: 「2ピザチーム」が責任を持てる単位、変更頻度・スケール要件が同じものをまとめる。
---
## 2. サービス間通信
### 同期通信(REST/gRPC)
- **メリット**: シンプル、低レイテンシ(gRPC)、リクエスト-レスポンスが明確
- **デメリット**: 時間的結合、カスケード障害のリスク
### 非同期通信(Kafka, RabbitMQ, EventBridge)
- **メリット**: 疎結合、耐障害性、バッファリング効果
- **デメリット**: 結果整合性、デバッグ困難、メッセージ順序保証の難しさ
### トレードオフの本質
> **整合性 vs 可用性 vs 結合度** のトリレンマ。即時整合性を求めれば結合度が上がり、疎結合を求めれば結果整合性を受け入れる必要がある。
---
## 3. データ管理
### Database per Service パターン
- **利点**: サービス独立性、技術選択の自由(Polyglot Persistence)
- **課題**:
- クロスサービスJOINが不可能 → **CQRS / API Composition**で対応
- 分散トランザクション → **Sagaパターン**(Choreography or Orchestration)
### Sagaパターンのトレードオフ
| Choreography(イベント駆動) | Orchestration(中央調整) |
|---|---|
| 疎結合だがフロー全体が見えない | 可視性高いがオーケストレータが単一障害点になりうる |
### Event Sourcing / CQRS
- 監査性・時系列分析に強いが、**学習コストと運用負荷が極めて高い**
---
## 4. サービスディスカバリとAPI Gateway
- **クライアントサイド**(Eureka): 柔軟だがクライアント実装が複雑
- **サーバーサイド**(K8s Service, Envoy): インフラに依存するがクライアントが単純
- **API Gateway**(Kong, AWS API Gateway): 認証・流量制御の集約点だが、**ボトルネックや単一障害点**になり得る
**BFF(Backend for Frontend)** パターンでクライアント別Gatewayを設けることで凝集度を上げる手法も有効。
---
## 5. 耐障害性とレジリエンス
### 必須パターン
- **Circuit Breaker**(Hystrix, Resilience4j): 障害伝播防止
- **Retry with Exponential Backoff + Jitter**: リトライストーム回避
- **Bulkhead**: リソース隔離
- **Timeout**: 必須(無制限待機の禁止)
### トレードオフ
過剰な防御は**複雑性**を招く。SLAに基づいた費用対効果評価が必要。
---
## 6. 可観測性(Observability)
3本柱:
1. **Metrics**(Prometheus, Datadog)
2. **Logs**(構造化ログ + ELK/Loki)
3. **Distributed Tracing**(Jaeger, OpenTelemetry)
### トレードオフ
- **計測オーバーヘッド** vs **デバッグ可能性**
- ログ・トレースのサンプリング戦略が必須(全件保存はコスト爆発)
---
## 7. デプロイメントとインフラ
### コンテナオーケストレーション
- **Kubernetes**: デファクトだが運用複雑性高
- **サーバーレス**(Lambda, Cloud Run): 運用負荷低いがベンダーロックインとコールドスタート
### デプロイ戦略
- **Blue-Green**: 安全だがリソース2倍
- **Canary**: リスク最小だが監視基盤が前提
- **Feature Flag**: デプロイとリリースの分離が可能
---
## 8. セキュリティ
- **Zero Trust**: サービス間でも認証必須(mTLS, Service Mesh)
- **OAuth 2.0 / OIDC + JWT**: トークン伝播設計
- **Service Mesh**(Istio, Linkerd): セキュリティ・通信制御を統一できるが、**追加レイヤーの運用負荷とレイテンシ増**
---
## 9. 組織とコンウェイの法則
> 「システム設計は組織のコミュニケーション構造を反映する」
- マイクロサービスは**自律分散チーム**を前提とする
- **Platform Engineering**(共通基盤チーム)の整備がスケールの鍵
- **DevOps文化**(You build it, you run it)が不可欠
### トレードオフ
組織変革なしの技術導入は**分散モノリス**を生む典型的失敗パターン。
---
## 10. コストの全体像
| コスト項目 | モノリス | マイクロサービス |
|---|---|---|
| 開発初期 | 低 | 高 |
| 運用・インフラ | 中 | 高 |
| 機能追加(成熟後) | 高(変更困難) | 低(独立変更可) |
| 障害対応 | 中 | 高(分散デバッグ) |
---
## まとめ:導入判断の本質
マイクロサービスは**銀の弾丸ではなく、複雑性のトレードオフ**である。
### 採用が正当化されるケース
- 組織規模が大きく、独立デプロイの価値が高い
- スケール要件がサービス間で大きく異なる
- 技術スタックの多様性が必要
### モノリスを選ぶべきケース
- 初期スタートアップ、ドメイン理解が未成熟
- 小規模チーム
- → **モジュラーモノリス** からの段階的移行(Strangler Fig パターン)が推奨される
最終的な設計判断は、**ビジネス要件・組織能力・技術的成熟度**の3軸で評価し、「技術的に可能か」ではなく「組織として持続可能か」を問うべきです。
output_config の effort パラメータで思考の深さを制御できます。
| effort | 動作 | 備考 |
|---|---|---|
max |
思考深度の制限なし | |
xhigh |
常に深く思考 | Opus 4.7 のみ |
high |
常に思考(デフォルト) | |
medium |
中程度の思考。単純なクエリはスキップ | |
low |
思考を最小化。速度優先 |
effort を省略すると high が適用されます。
curl を使った呼び出し(確認用)
モデルが正しく有効化されているかを確認するシンプルな方法として、curl でも呼び出せます。
TOKEN=$(gcloud auth print-access-token)
curl -s -X POST \
-H "Authorization: Bearer $TOKEN" \
-H "Content-Type: application/json" \
"https://aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/global/publishers/anthropic/models/claude-opus-4-7:rawPredict" \
-d '{
"anthropic_version": "vertex-2023-10-16",
"max_tokens": 256,
"messages": [
{
"role": "user",
"content": "Hello from Vertex AI!"
}
]
}'
正常に動作している場合、以下のような JSON レスポンスが返ります。
{
"model": "claude-opus-4-7",
"id": "msg_vrtx_012Q6Z4h8RTpNJdRKsYbybiU",
"type": "message",
"role": "assistant",
"content": [
{
"type": "text",
"text": "Hello! 👋 Welcome! It's great to hear from you via Vertex AI. \n\nHow can I help you today? Whether you have questions, need help with a task, or just want to chat, I'm here to assist!"
}
],
"stop_reason": "end_turn",
"stop_sequence": null,
"stop_details": null,
"usage": {
"input_tokens": 22,
"cache_creation_input_tokens": 0,
"cache_read_input_tokens": 0,
"cache_creation": {
"ephemeral_5m_input_tokens": 0,
"ephemeral_1h_input_tokens": 0
},
"output_tokens": 71
}
}
Multi-region endpoint を使う(Preview)
Multi-region endpoint を使うと、US または EU 全体に分散した高可用性なアクセスが得られます。エンドポイントのホスト名と locations パラメータが通常と異なる点に注意してください。
# US の Multi-region endpoint を使う例
export ENDPOINT="aiplatform.us.rep.googleapis.com"
export LOCATION="us"
export MODEL_ID="claude-opus-4-7"
curl -s -X POST \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \
-H "Content-Type: application/json" \
"https://${ENDPOINT}/v1/projects/${PROJECT_ID}/locations/${LOCATION}/publishers/anthropic/models/${MODEL_ID}:rawPredict" \
-d '{
"anthropic_version": "vertex-2023-10-16",
"max_tokens": 256,
"messages": [
{
"role": "user",
"content": "Hello from Multi-region endpoint!"
}
]
}'
正常に動作している場合、以下のような JSON レスポンスが返ります。
{
"model": "claude-opus-4-7",
"id": "msg_vrtx_019patLHQXe83hTZYGXBR8dQ",
"type": "message",
"role": "assistant",
"content": [
{
"type": "text",
"text": "Hello! 👋 Welcome! It looks like you're testing a multi-region endpoint setup. Everything seems to be working on my end — I received your message clearly.\n\nHow can I help you today?"
}
],
"stop_reason": "end_turn",
"stop_sequence": null,
"stop_details": null,
"usage": {
"input_tokens": 25,
"cache_creation_input_tokens": 0,
"cache_read_input_tokens": 0,
"cache_creation": {
"ephemeral_5m_input_tokens": 0,
"ephemeral_1h_input_tokens": 0
},
"output_tokens": 65
}
}
注意点・制限事項
- asia-northeast1は非対応: 公式ドキュメント公開時点では、Claude Opus 4.7 の利用可能リージョンとして asia-northeast1(東京)の記載がありません。また、opus4.6で利用できていたasia-southeast1(シンガポール)のサポートもされていないようです。
- Multi-region endpoint は Preview: SLA の対象外であり、本番環境での使用は推奨されません。また、Multi-region endpoint では Provisioned Throughput が利用できない点に注意してください。
まとめ
2026年4月16日に Vertex AI Model Garden で Claude Opus 4.7 が GA となりました。1M トークンのコンテキストウィンドウ・128K トークンの出力・Extended thinking をフルサポートしながら、グローバルエンドポイントのスループットが Opus 4.6 の2倍に引き上げられています。
特に注目すべきポイントは以下の3点です。
- グローバルエンドポイント(QPM 800 / Input TPM 8M)により、単一リージョンの2倍のスループットを確保でき、高トラフィックなエージェントワークロードにも対応しやすくなった
- Extended thinking + 1M コンテキストの組み合わせで、長大なコードベース解析や複数ドキュメントにまたがる複雑な推論タスクを単一リクエストで処理できる
- Vertex AI のエンタープライズセキュリティ(IAM・組織ポリシー・VPC Service Controls)がそのまま適用できるため、機密情報を扱うユースケースでも安心して導入できる
現状、本番ワークロードでClaude Opus 4.7を利用する場合は、Globalエンドポイントの利用が現実的な選択肢になりそうです。Multi-region endpointはPreviewであり、SLAの対象外となるためです。
早めの東京リージョンやアジア太平洋リージョンのサポートが期待されます。
この記事が誰かの助けになれば幸いです。
以上、クラウド事業本部コンサルティング部の渡邉でした!











