Spark DataFrameで日付列の値をもとに曜日列を追加する
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部の若槻です。
Apache Sparkは、大規模なデータを処理するための統合分析エンジンです。
今回は、Spark DataFrameで日付列の値をもとに月、火、水…のような曜日列を追加してみました。
環境
% pyspark
Python 3.8.6 (default, Oct 8 2020, 14:06:32)
[Clang 12.0.0 (clang-1200.0.32.2)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/usr/local/Cellar/apache-spark/3.0.1/libexec/jars/spark-unsafe_2.12-3.0.1.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
21/01/04 06:37:24 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
21/01/04 06:37:25 WARN Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.0.1
/_/
Using Python version 3.8.6 (default, Oct 8 2020 14:06:32)
SparkSession available as 'spark'.
やってみる
下記のような日付(timestamp)列を持ったSpark DataFrame形式のデータがあります。
>>> df = spark.createDataFrame(
[
('3ff9c44a', 0, 1609348014),
('e36b7dfa', 1, 1609375822),
('7d4215d0', 0, 1609497057),
('e36b7dfa', 1, 1609565442),
('3ff9c44a', 1, 1609618552),
('7d4215d0', 0, 1609741678),
('dfa6932c', 0, 1609777371),
('dfa6932c', 0, 1609858800)
],
['device_id', 'state', 'timestamp']
)
まずdate_format()でtimestamp列をパースして英語の曜日テキスト列days_of_week_text_enを作成します。
>>> from pyspark.sql.functions import to_timestamp, date_format
>>> df = df.withColumn('day_of_week_text_en',
date_format(
to_timestamp(df.timestamp),
'E'
)
)
作成できました。ちゃんとtimestamp列の日付の値に応じた曜日となっています。
>>> df.show()
+---------+-----+----------+-------------------+
|device_id|state| timestamp|day_of_week_text_en|
+---------+-----+----------+-------------------+
| 3ff9c44a| 0|1609348014| Thu|
| e36b7dfa| 1|1609375822| Thu|
| 7d4215d0| 0|1609497057| Fri|
| e36b7dfa| 1|1609565442| Sat|
| 3ff9c44a| 1|1609618552| Sun|
| 7d4215d0| 0|1609741678| Mon|
| dfa6932c| 0|1609777371| Tue|
| dfa6932c| 0|1609858800| Wed|
+---------+-----+----------+-------------------+
次に下記のように曜日テーブルのDataFrameを作成します。
>>> days_of_week_df = spark.createDataFrame(
[
('Mon', 1, '月'),
('Tue', 2, '火'),
('Wed', 3, '水'),
('Thu', 4, '木'),
('Fri', 5, '金'),
('Sat', 6, '土'),
('Sun', 7, '日'),
],
['day_of_week_text_en', 'day_of_week_id', 'day_of_week_text']
)
データと曜日テーブルを結合します。join()の第二引数にカラム名を指定すると、そのカラムを元に両データの結合が行われます。
>>> df = df.join(days_of_week_df,
'day_of_week_text_en'
)
データに曜日ID列(day_of_week_id)と曜日テキスト列(day_of_week_text)を追加できました。
>>> df.show()
+-------------------+---------+-----+----------+--------------+----------------+
|day_of_week_text_en|device_id|state| timestamp|day_of_week_id|day_of_week_text|
+-------------------+---------+-----+----------+--------------+----------------+
| Sun| 3ff9c44a| 1|1609618552| 7| 日|
| Mon| 7d4215d0| 0|1609741678| 1| 月|
| Thu| 3ff9c44a| 0|1609348014| 4| 木|
| Thu| e36b7dfa| 1|1609375822| 4| 木|
| Sat| e36b7dfa| 1|1609565442| 6| 土|
| Wed| dfa6932c| 0|1609858800| 3| 水|
| Fri| 7d4215d0| 0|1609497057| 5| 金|
| Tue| dfa6932c| 0|1609777371| 2| 火|
+-------------------+---------+-----+----------+--------------+----------------+
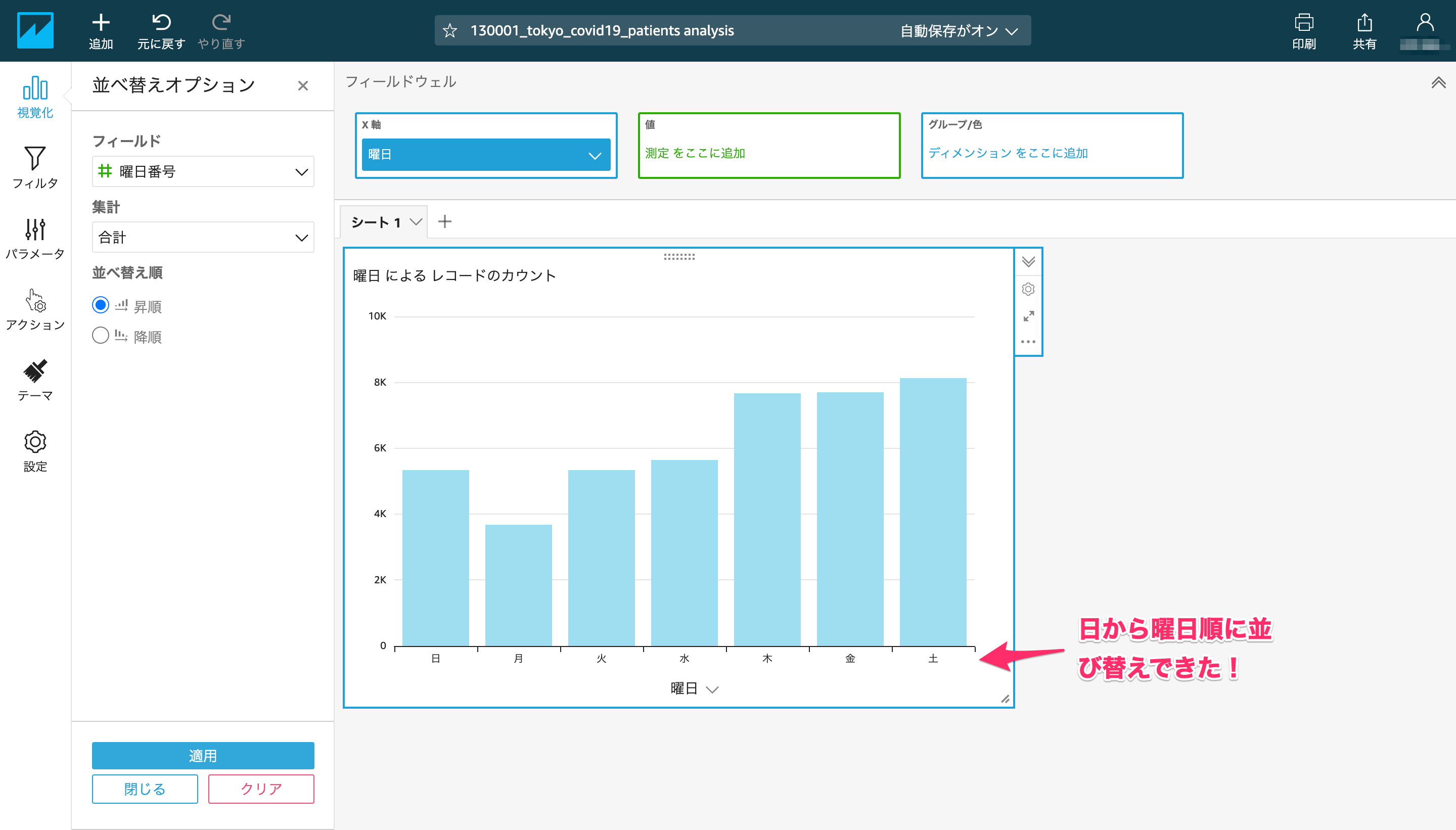
曜日ID列は、以下記事にあるようにBIツールでデータを曜日順に並び替えしたい時に役立ちます。
date_format()のuオプションについて
今回、データに曜日IDと曜日テキストを付与するためにわざわざday_of_week_text_en列を使用しましたが、date_format()のuオプションを使用すれば曜日IDを直接付与することができます。
ただし環境によってはuオプションの利用には一工夫いります。例えば今回の環境だと下記のようなエラーとなります。
>>> df = spark.createDataFrame(
[
('3ff9c44a', 0, 1609348014),
('e36b7dfa', 1, 1609375822),
('7d4215d0', 0, 1609497057),
('e36b7dfa', 1, 1609565442),
('3ff9c44a', 1, 1609618552),
('7d4215d0', 0, 1609741678),
('dfa6932c', 0, 1609777371),
('dfa6932c', 0, 1609858800)
],
['device_id', 'state', 'timestamp']
)
>>> df = df.withColumn('day_of_week_id',
date_format(
to_timestamp(df.timestamp),
'u'
)
)
>>> df.show()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/Cellar/apache-spark/3.0.1/libexec/python/pyspark/sql/dataframe.py", line 440, in show
print(self._jdf.showString(n, 20, vertical))
File "/usr/local/Cellar/apache-spark/3.0.1/libexec/python/lib/py4j-0.10.9-src.zip/py4j/java_gateway.py", line 1304, in __call__
File "/usr/local/Cellar/apache-spark/3.0.1/libexec/python/pyspark/sql/utils.py", line 128, in deco
return f(*a, **kw)
File "/usr/local/Cellar/apache-spark/3.0.1/libexec/python/lib/py4j-0.10.9-src.zip/py4j/protocol.py", line 326, in get_return_value
py4j.protocol.Py4JJavaError: An error occurred while calling o116.showString.
: org.apache.spark.SparkUpgradeException: You may get a different result due to the upgrading of Spark 3.0: Fail to recognize 'u' pattern in the DateTimeFormatter. 1) You can set spark.sql.legacy.timeParserPolicy to LEGACY to restore the behavior before Spark 3.0. 2) You can form a valid datetime pattern with the guide from https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html
at org.apache.spark.sql.catalyst.util.DateTimeFormatterHelper$$anonfun$checkLegacyFormatter$1.applyOrElse(DateTimeFormatterHelper.scala:196)
at org.apache.spark.sql.catalyst.util.DateTimeFormatterHelper$$anonfun$checkLegacyFormatter$1.applyOrElse(DateTimeFormatterHelper.scala:185)
at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:38)
at org.apache.spark.sql.catalyst.util.Iso8601TimestampFormatter.validatePatternString(TimestampFormatter.scala:109)
at org.apache.spark.sql.catalyst.util.TimestampFormatter$.getFormatter(TimestampFormatter.scala:278)
at org.apache.spark.sql.catalyst.util.TimestampFormatter$.apply(TimestampFormatter.scala:312)
at org.apache.spark.sql.catalyst.expressions.DateFormatClass.$anonfun$formatter$1(datetimeExpressions.scala:646)
at scala.Option.map(Option.scala:230)
at org.apache.spark.sql.catalyst.expressions.DateFormatClass.formatter$lzycompute(datetimeExpressions.scala:641)
at org.apache.spark.sql.catalyst.expressions.DateFormatClass.formatter(datetimeExpressions.scala:639)
at org.apache.spark.sql.catalyst.expressions.DateFormatClass.doGenCode(datetimeExpressions.scala:665)
at org.apache.spark.sql.catalyst.expressions.Expression.$anonfun$genCode$3(Expression.scala:146)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.catalyst.expressions.Expression.genCode(Expression.scala:141)
at org.apache.spark.sql.catalyst.expressions.Alias.genCode(namedExpressions.scala:159)
at org.apache.spark.sql.execution.ProjectExec.$anonfun$doConsume$1(basicPhysicalOperators.scala:66)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238)
at scala.collection.immutable.List.foreach(List.scala:392)
at scala.collection.TraversableLike.map(TraversableLike.scala:238)
at scala.collection.TraversableLike.map$(TraversableLike.scala:231)
at scala.collection.immutable.List.map(List.scala:298)
at org.apache.spark.sql.execution.ProjectExec.doConsume(basicPhysicalOperators.scala:66)
at org.apache.spark.sql.execution.CodegenSupport.consume(WholeStageCodegenExec.scala:194)
at org.apache.spark.sql.execution.CodegenSupport.consume$(WholeStageCodegenExec.scala:149)
at org.apache.spark.sql.execution.RDDScanExec.consume(ExistingRDD.scala:132)
at org.apache.spark.sql.execution.InputRDDCodegen.doProduce(WholeStageCodegenExec.scala:483)
at org.apache.spark.sql.execution.InputRDDCodegen.doProduce$(WholeStageCodegenExec.scala:456)
at org.apache.spark.sql.execution.RDDScanExec.doProduce(ExistingRDD.scala:132)
at org.apache.spark.sql.execution.CodegenSupport.$anonfun$produce$1(WholeStageCodegenExec.scala:95)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:213)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:210)
at org.apache.spark.sql.execution.CodegenSupport.produce(WholeStageCodegenExec.scala:90)
at org.apache.spark.sql.execution.CodegenSupport.produce$(WholeStageCodegenExec.scala:90)
at org.apache.spark.sql.execution.RDDScanExec.produce(ExistingRDD.scala:132)
at org.apache.spark.sql.execution.ProjectExec.doProduce(basicPhysicalOperators.scala:51)
at org.apache.spark.sql.execution.CodegenSupport.$anonfun$produce$1(WholeStageCodegenExec.scala:95)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:213)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:210)
at org.apache.spark.sql.execution.CodegenSupport.produce(WholeStageCodegenExec.scala:90)
at org.apache.spark.sql.execution.CodegenSupport.produce$(WholeStageCodegenExec.scala:90)
at org.apache.spark.sql.execution.ProjectExec.produce(basicPhysicalOperators.scala:41)
at org.apache.spark.sql.execution.WholeStageCodegenExec.doCodeGen(WholeStageCodegenExec.scala:632)
at org.apache.spark.sql.execution.WholeStageCodegenExec.doExecute(WholeStageCodegenExec.scala:692)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$execute$1(SparkPlan.scala:175)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:213)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:210)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:171)
at org.apache.spark.sql.execution.SparkPlan.getByteArrayRdd(SparkPlan.scala:316)
at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:434)
at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:420)
at org.apache.spark.sql.execution.CollectLimitExec.executeCollect(limit.scala:47)
at org.apache.spark.sql.Dataset.collectFromPlan(Dataset.scala:3627)
at org.apache.spark.sql.Dataset.$anonfun$head$1(Dataset.scala:2697)
at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3618)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:100)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:160)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:87)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:764)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3616)
at org.apache.spark.sql.Dataset.head(Dataset.scala:2697)
at org.apache.spark.sql.Dataset.take(Dataset.scala:2904)
at org.apache.spark.sql.Dataset.getRows(Dataset.scala:300)
at org.apache.spark.sql.Dataset.showString(Dataset.scala:337)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:566)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.base/java.lang.Thread.run(Thread.java:834)
Caused by: java.lang.IllegalArgumentException: All week-based patterns are unsupported since Spark 3.0, detected: u, Please use the SQL function EXTRACT instead
at org.apache.spark.sql.catalyst.util.DateTimeFormatterHelper$.$anonfun$convertIncompatiblePattern$4(DateTimeFormatterHelper.scala:323)
at org.apache.spark.sql.catalyst.util.DateTimeFormatterHelper$.$anonfun$convertIncompatiblePattern$4$adapted(DateTimeFormatterHelper.scala:321)
at scala.collection.TraversableLike$WithFilter.$anonfun$foreach$1(TraversableLike.scala:877)
at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36)
at scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33)
at scala.collection.immutable.StringOps.foreach(StringOps.scala:33)
at scala.collection.TraversableLike$WithFilter.foreach(TraversableLike.scala:876)
at org.apache.spark.sql.catalyst.util.DateTimeFormatterHelper$.$anonfun$convertIncompatiblePattern$2(DateTimeFormatterHelper.scala:321)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238)
at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36)
at scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:198)
at scala.collection.TraversableLike.map(TraversableLike.scala:238)
at scala.collection.TraversableLike.map$(TraversableLike.scala:231)
at scala.collection.mutable.ArrayOps$ofRef.map(ArrayOps.scala:198)
at org.apache.spark.sql.catalyst.util.DateTimeFormatterHelper$.convertIncompatiblePattern(DateTimeFormatterHelper.scala:318)
at org.apache.spark.sql.catalyst.util.DateTimeFormatterHelper.getOrCreateFormatter(DateTimeFormatterHelper.scala:121)
at org.apache.spark.sql.catalyst.util.DateTimeFormatterHelper.getOrCreateFormatter$(DateTimeFormatterHelper.scala:117)
at org.apache.spark.sql.catalyst.util.Iso8601TimestampFormatter.getOrCreateFormatter(TimestampFormatter.scala:59)
at org.apache.spark.sql.catalyst.util.Iso8601TimestampFormatter.formatter$lzycompute(TimestampFormatter.scala:68)
at org.apache.spark.sql.catalyst.util.Iso8601TimestampFormatter.formatter(TimestampFormatter.scala:67)
at org.apache.spark.sql.catalyst.util.Iso8601TimestampFormatter.validatePatternString(TimestampFormatter.scala:108)
... 74 more
エラー中の以下の記載によると、Spark 3.0以降のDateTimeFormatterでは使えないパターンのようです。今回の記事では2)の方法をとりEオプションを使用したことになります。
You may get a different result due to the upgrading of Spark 3.0: Fail to recognize 'u' pattern in the DateTimeFormatter. 1) You can set spark.sql.legacy.timeParserPolicy to LEGACY to restore the behavior before Spark 3.0. 2) You can form a valid datetime pattern with the guide from https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html
1)の方法ですと下記が参考になりました。
spark.sql("set spark.sql.legacy.timeParserPolicy=LEGACY")を実行してtimeParserPolicyをLEGACYとすることにより、date_format()のuオプションでday_of_week_idを直接取得できました。
>>> spark.sql("set spark.sql.legacy.timeParserPolicy=LEGACY")
DataFrame[key: string, value: string]
>>> df = spark.createDataFrame(
[
('3ff9c44a', 0, 1609348014),
('e36b7dfa', 1, 1609375822),
('7d4215d0', 0, 1609497057),
('e36b7dfa', 1, 1609565442),
('3ff9c44a', 1, 1609618552),
('7d4215d0', 0, 1609741678),
('dfa6932c', 0, 1609777371),
('dfa6932c', 0, 1609858800)
],
['device_id', 'state', 'timestamp']
)
>>> df = df.withColumn('day_of_week_id',
date_format(
to_timestamp(df.timestamp),
'u'
)
)
>>> df.show()
+---------+-----+----------+--------------+
|device_id|state| timestamp|day_of_week_id|
+---------+-----+----------+--------------+
| 3ff9c44a| 0|1609348014| 4|
| e36b7dfa| 1|1609375822| 4|
| 7d4215d0| 0|1609497057| 5|
| e36b7dfa| 1|1609565442| 6|
| 3ff9c44a| 1|1609618552| 7|
| 7d4215d0| 0|1609741678| 1|
| dfa6932c| 0|1609777371| 2|
| dfa6932c| 0|1609858800| 3|
+---------+-----+----------+--------------+
しかし特に理由がなければPySpark3環境なら今回最初に紹介した2)の方法を使う方が良いかと思います。
おわりに
Spark DataFrameで日付列の値をもとに月、火、水…のような曜日列を追加してみました。
データのETLの実装においてはよくある処理だと思うので確認できて良かったです。
参考
以上









