
AIエージェントを構築するワークショップをやってみた
はじめに
最近、生成AIやそれを活用したAgentic AIなどの最新動向をキャッチアップできていないと感じていたため、これを機にAWSのワークショップをやってみました。
ワークショップについて
今回取り組んだのは以下のワークショップです。
Building and Scaling Agentic AI Workflows
このワークショップでは、以下のことが学べるとされています。
- Agentic AIを実装するさまざまな方法
- ユースケースに応じた実装方法の比較検討
Agentic AIがどのようなものかは、インターネット上にさまざまな解説記事が存在します。既にご存知の方も多いと思いますが、ワークショップの最初のページに簡単な解説がまとめられています。
このワークショップは3つのLab、合計12のモジュールで構成されており、所要時間は2時間とされています。それぞれのLabの内容は以下の通りです。
- Lab1
- AIエージェントが複数のツールを使用してユーザに適切な応答を返す流れを学習
- Step Functionsを利用してワークフローとして実装する方法を学習
- Lab2
- Strands Agents SDKを利用したAIエージェントのステップバイステップの実装
- RAGやMCPサーバを活用するAIエージェントの実装
- API GatewayとCognitoによるAIエージェントの公開
- Lab3
- Amazon Bedrock AgentsでのAIエージェントの構築
- 複数のAIエージェントを連携させるソリューションの構築
各Labは独立しているため、気になったLabのみ実施できます。
事前準備
自分のAWSアカウントでこのワークショップを実行する場合、まずは以下のページに書かれた手順に従ってCloudFormationスタックをデプロイする必要があります。
Running workshop in your own AWS account
上記ページの「Launch Stack」と書かれたリンクをクリックすると、S3のURLが指定された状態でCloudFormationのスタック作成ページが開きます。そのまま「次へ」をクリックします。
スタック名を任意の値に設定します。ここでは、ワークショップのページに書かれていたagentic-ai-workshopという名前を指定します。その他のパラメータは変更せずに「次へ」をクリックします。
「スタックオプションの設定」画面では、以下のチェックボックスにチェックを入れて「次へ」をクリックします。
「確認して作成」画面で「送信」をクリックします。
スタックのデプロイが完了するまで少し待ちます。私の場合は、5分ほどで完了しました。
Lab 1: Building agentic workflows with AWS Step Functions
Lab 1 - Building agentic workflows with AWS Step Functions
このLabでやること
このLabでは、AWS Lambda、AWS Step Functions、Amazon Bedrockを活用したエージェントワークフローを構築します。
ここでは、以下のことを実行できるエージェントを構築します。
- ブログやホワイトペーパーなどの技術文書を処理し重要なポイントを抽出する(Content Summarizer)
- 技術用語をプラットフォームに応じた適切なトーンに変換する(Tone Adapter)
- プラットフォームの仕様に合わせてコンテンツを作成する(Post Writer)
Module 1: ツールについての理解
モジュール1では、アプリケーションとユーザとのやり取りにおいて、Amazon Bedrockとツールがどのように活用されているかが、以下の図とともに解説されています。
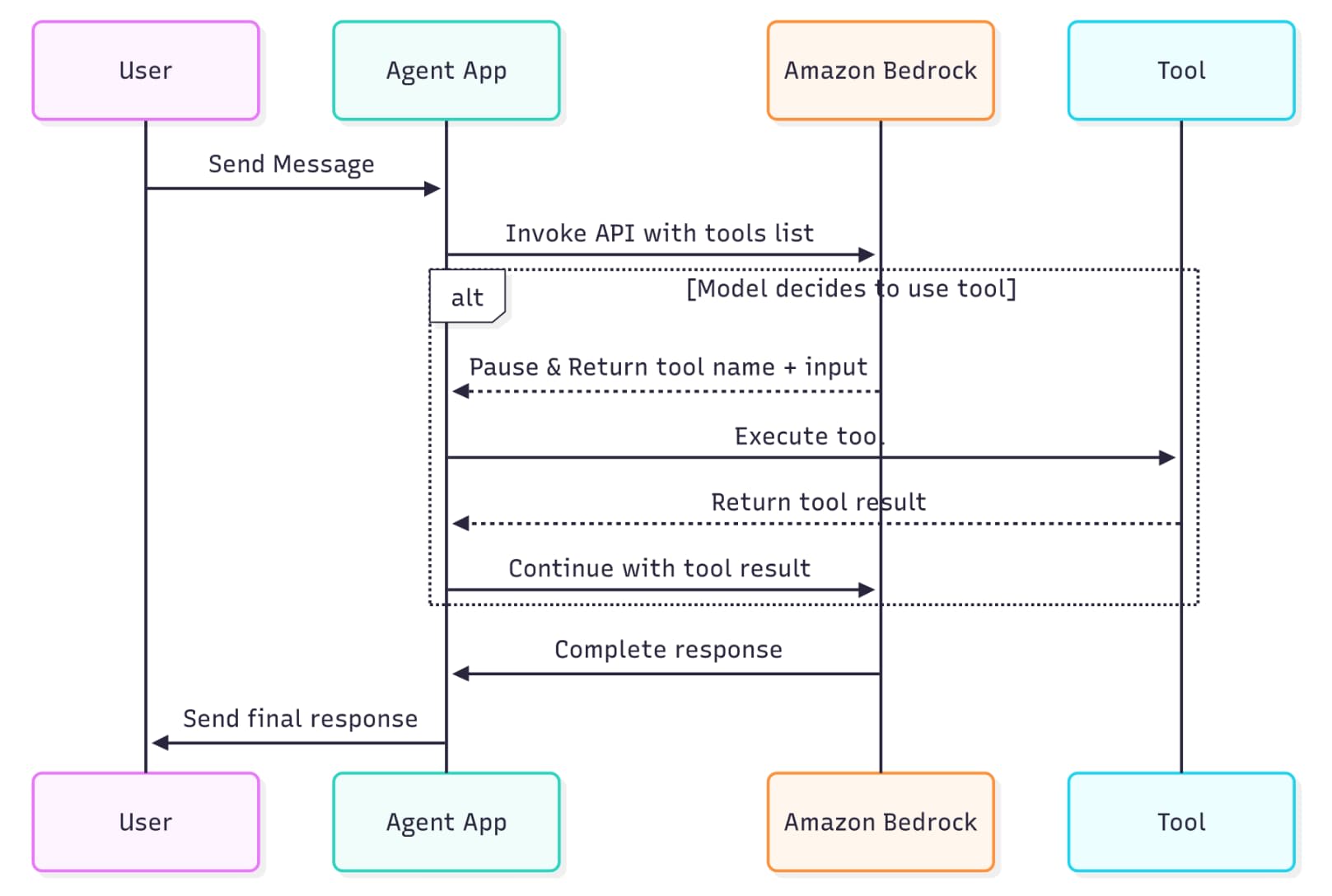
この図では、以下のような流れが表現されています。
- ユーザが自然言語で問い合わせする
- アプリケーションはツールの一覧とともに、Amazon BedrockのAPIを呼び出す
- Amazon Bedrockが適切なツールと入力パラメータをアプリケーションに返す
- アプリケーションは返ってきたツールを実行し応答を得る
- アプリケーションは得た応答をAmazon Bedrockに送信する
- Amazon Bedrockがユーザの問い合わせに対する応答を作成する
- アプリケーションがユーザに応答を返す
実際には、ステップ3~6はAmazon Bedrockの立てた計画に基づいて複数回繰り返される場合があります。
このワークショップにおいては、ツールは「Content Summarizer」「Tone Adapter」「Post Writer」を指します。
Module 2: ツール使用のためのコーディング
モジュール2では、CloudFormationによって作成されたアプリケーションおよび各ツールについて解説されています。
マネジメントコンソールでLambdaのページを開くと、Lab1に関連して5つのLambda関数が作成されています。

lab1-social-media-agentがアプリケーションです。ソースコードを確認すると、ユーザからの入力とツールの一覧と共に、Amazon BedrockのAPIを呼び出していることがわかります。
async function invokeConverseAPI(messages) {
return await bedrockClient.send(new ConverseCommand({
modelId: MODEL_ID,
system: SYSTEM_PROMPT,
toolConfig: { tools: TOOLS},
messages: messages
}));
}
また、Amazon Bedrockから返されたツール名を元に、適切なツールを呼び出していることも確認できます。
async function invokeTool(tool) {
console.log(`Invoking tool: ${tool.name} (ID: ${tool.toolUseId})`);
switch (tool.name) {
case CONTENT_SUMMARIZER_TOOL_NAME:
return await invokeLambda(CONTENT_SUMMARIZER_FUNCTION, tool.input);
case TONE_ADAPTER_TOOL_NAME:
return await invokeLambda(TONE_ADAPTER_FUNCTION, tool.input);
case POST_WRITER_TOOL_NAME:
return await invokeLambda(POST_WRITER_FUNCTION, tool.input);
default:
throw new Error(`Unknown tool: ${tool.name} (ID: ${tool.toolUseId})`);
}
}
ワークショップでは、このアプリケーションをテストする方法も記されています。
lab1-social-media-agent関数ページの「テスト」タブを開きます。「イベントJSON」にプロンプトを以下の形式で入力します。
{
"prompt": "プロンプト"
}
ワークショップでは、Amazon Bedrockのアナウンスブログの投稿から、mythicalなトーンでのソーシャルメディア投稿を生成するプロンプト例が掲載されています。しかしながら、英語で返されてもmythicalかどうか判別ができないので、日本語で返してもらうようにプロンプトを少し修正しました。
{
"prompt": "Please create a social media post in Japanese using a mythical tone: This April, ...(略)"
}
イベントJSONを入力したら、「テスト」をクリックします。30秒ほど待つと、成功の表示がされます。

{
"response": "Here is your social media post in Japanese:\n\n🌟 古代のデジタル魔法の世界で、Amazon Bedrockが革新の光として現れました! ✨ 賢者たちからの贈り物で、生成AIアプリケーションを簡単に生み出せる完全に管理された領域を提供します。🔮(中略)生成AIの旅を続ける者たちに、Amazon Bedrockが忠実な仲間となることを確信してください。🌐\n\n#AmazonBedrock #AI革命 #デジタル魔法 #AWS #GenerativeAI #データ保護 #革新の光\n\nFeel free to share this post on your social media platforms to announce the general availability of Amazon Bedrock in an engaging and mythical way!"
}
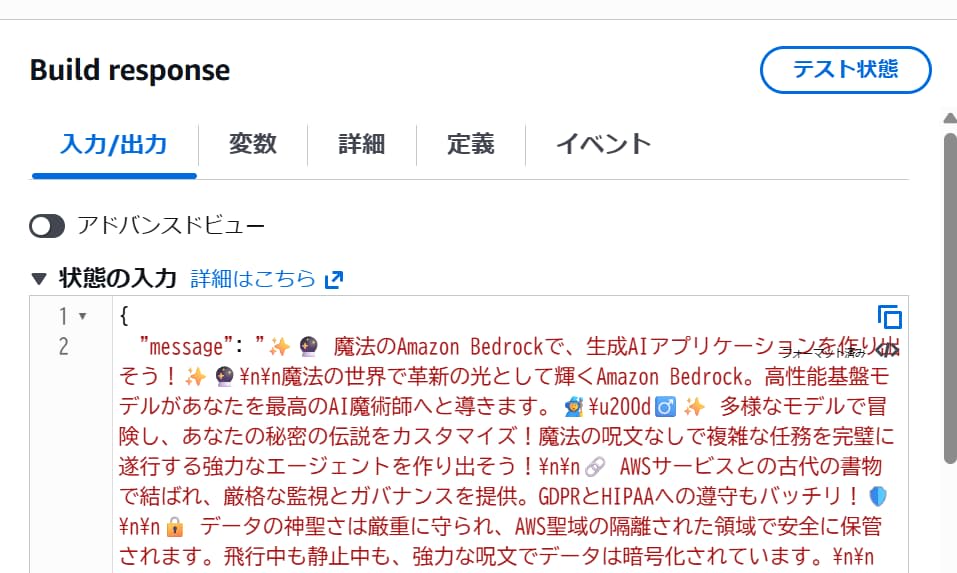
mythicalらしきトーンで結果が返ってきました。ちゃんとハッシュタグもついてソーシャルメディアの投稿らしくなっています。
ログを見ると、モデルがどのツールを使用するべきかを計画し、アプリケーションがそれぞれのツールを呼び出していることがわかります。

Module 3: Step Functionsの理解
モジュール3では、AIエージェントをワークフローベースで構築する利点と、Step Functionsを使用してAmazon Bedrock APIを呼び出す方法が解説されています。
モジュール2で確認したアプリケーションでは、APIの呼び出しやツールの使用といったロジックを1つのLambda関数の中に記述していました。これは、ロジックが一ヶ所に集約されておりシンプルである反面、状態の追跡や監視を自分で構築する必要があったり、ツールからの応答待機時間に応じて料金がかかってしまったりするデメリットがあります。ワークフローベースのソリューションに移行することで、状態の可視化やメンテナンスコストの削減、実行時間の最適化といったメリットを享受できます。
それでは、ワークショップの内容に従って、Amazon Bedrock APIを呼び出すためのシンプルなStep Functionsワークフローを作成していきます。
ワークショップでは、シンプルなStep Functionsのワークフローを作成する手順が記載されていますが、ここでは割愛します。
Module 4: Step Functionsを使用したワークフロー構築
モジュール4では、モジュール2のアプリケーションで行っていた各処理が、Step Functionsのワークフローとして表現されています。
Step Functionsのコンソールにlab1-social-media-agent-sfnという名前のステートマシンが作成されています。
中を見てみると、以下のようにワークフローが構成されています。
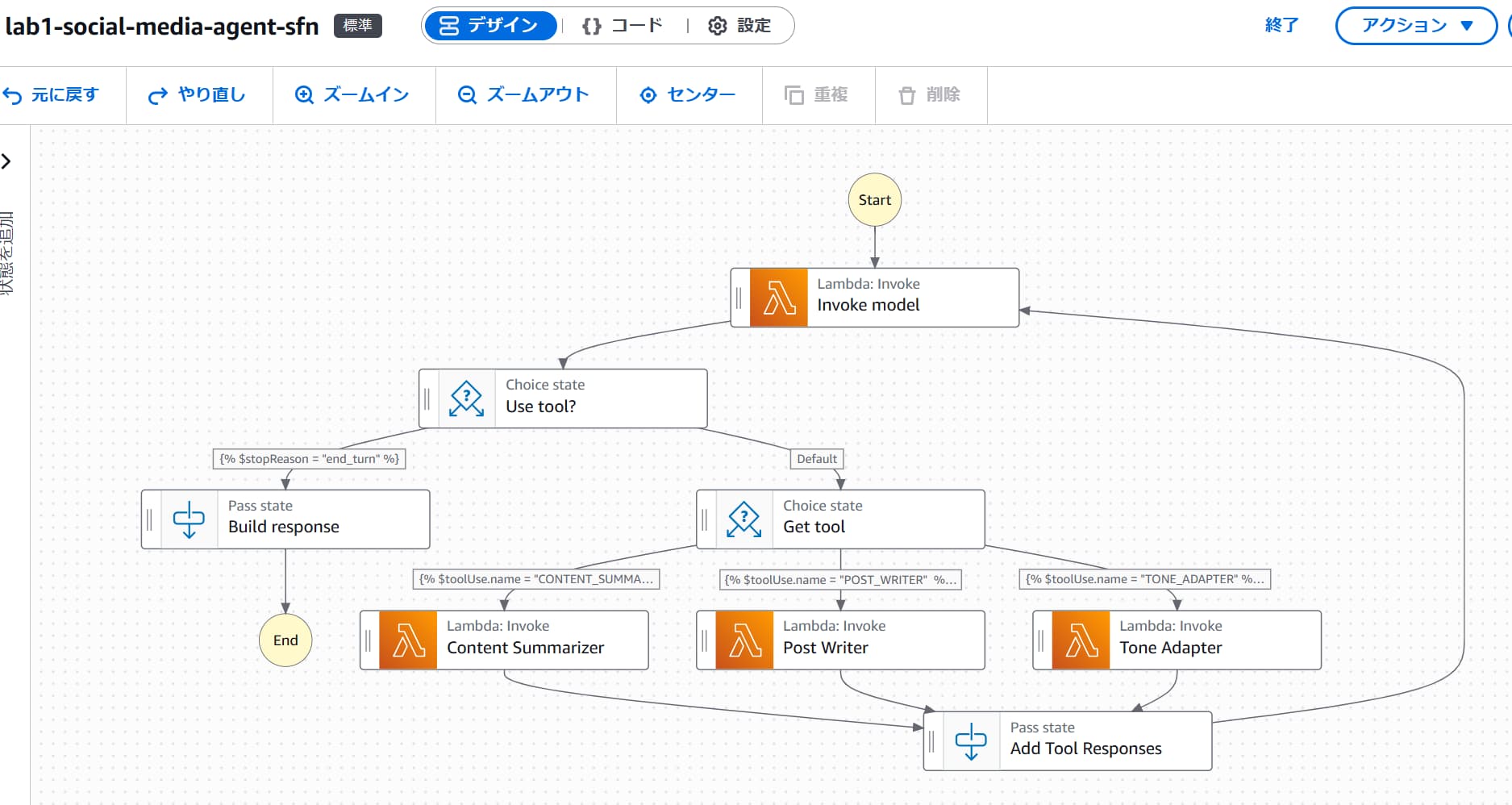
最初のステップであるInvoke modelでは、lab1-bedrock-integratonというLambda関数が実行されます。この関数は、モジュール2で確認したlab1-social-media-agentのうち、Amazon Bedrock APIを呼び出す部分のみを担当する関数です。つまり、APIの応答を元に適切なツールを呼び出す部分は、Step Functionsの独立したステップとして、アプリケーションから切り離されています。
詳細な動作はLambda関数のコードおよびStep Functionsの定義を確認していただければわかりますが、Invoke modelは実行後、messages、stopReason、toolUseの3つのステート変数を更新します。後続のUse toolやGet toolは、そのステート変数を参照し、条件分岐によって適切なステップを呼び出しています。
このStep Functionsをテストすることができます。ステートマシンのページで「実行を開始」をクリックします。

モーダルが表示されるので、モジュール2で使用したJSONと同じものを入力し、「実行を開始」をクリックします。
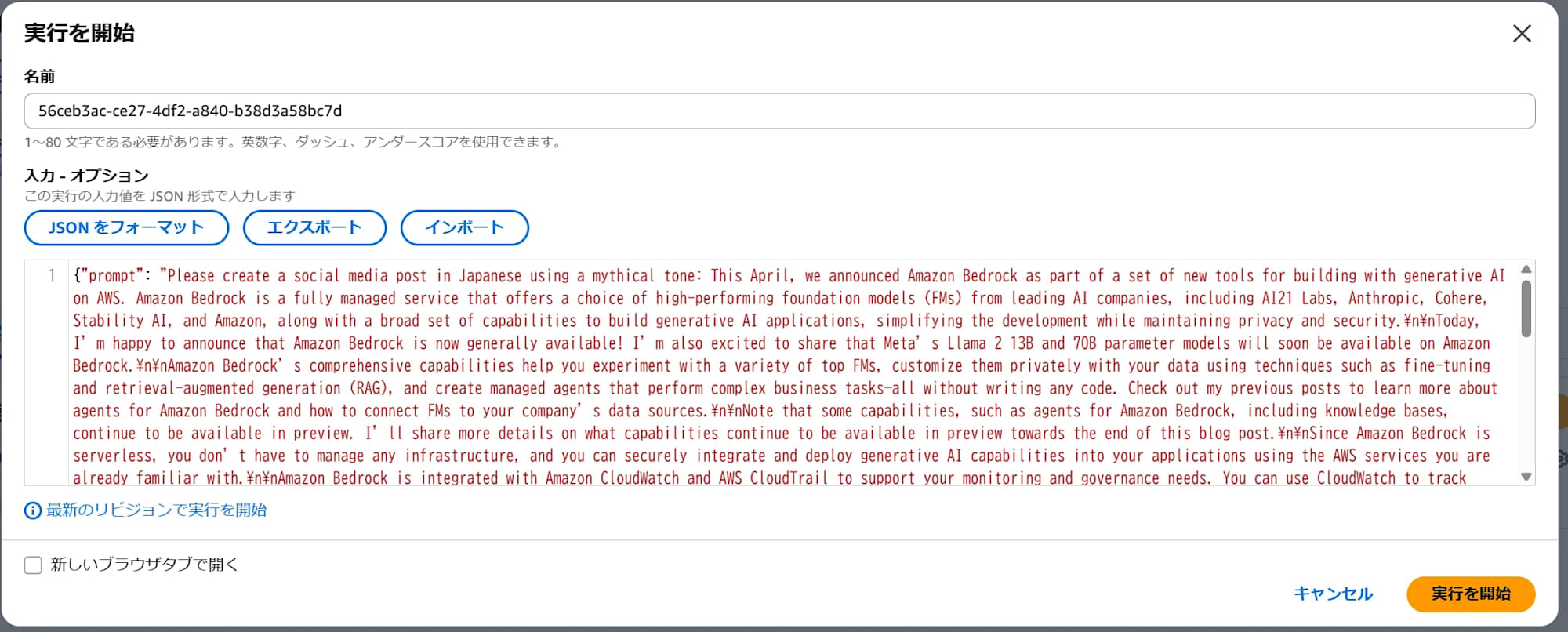
モジュール2と同じような結果が返ってきました。
Lab 2: Building agents with Strands Agents SDK
Lab 2 - Building agents with Strands Agents SDK
このLabでやること
このLabでは、Strands AgentsとAWSの各サービスを利用して、AWS上にAIエージェントを構築します。Strands Agentsとは、AWSが公開しているオープンソースのフレームワークで、AIエージェントを構築することができます。
ここでは、以下のことを実行できるエージェントを構築します。
- 旅行のフライトオプションを提案する
- 旅行先の天気予報を提供する
Module 1: Strandsを使用したAIエージェントの構築
モジュール1では、Strandsを使用したAIエージェントをLambda上にデプロイします。
マネジメントコンソールでLambdaの画面を開き、strands-travel-agentという関数を開きます。
ワークショップのページにコードが掲載されているので、コピーしてコードエディタにペーストします。ペーストしたら、「Deploy」をクリックします。
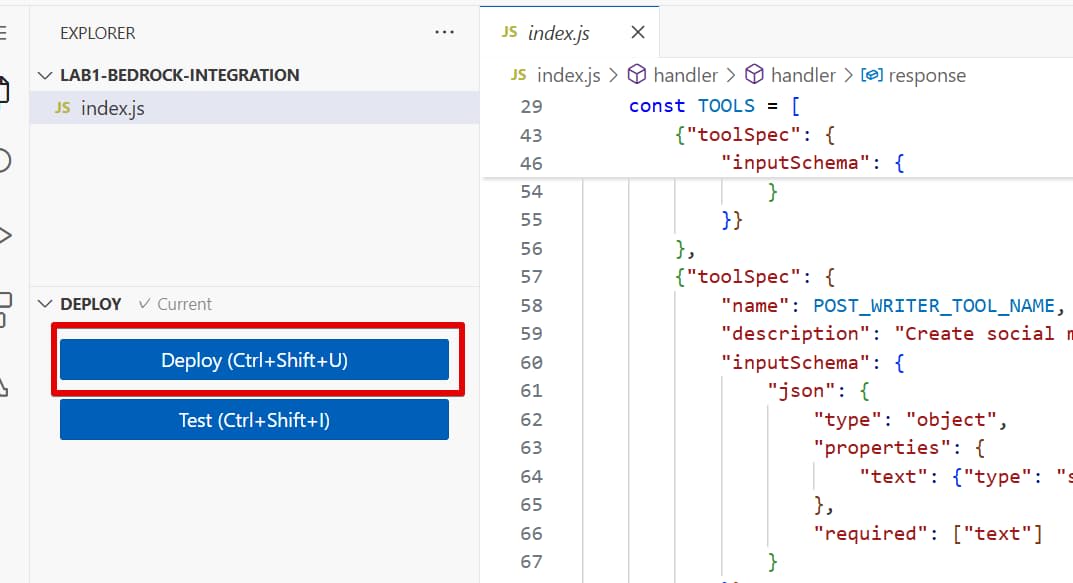
このコードでは、ツールが一つ定義されています。都市名を受け取って、利用可能なフライトを返すツールです。ここではサンプルのため配列がハードコードされていますが、実際のツールはデータベースへアクセスして情報を取得します。
@tool
def flight_search(city: str) -> dict:
"""Get available flight options to a city.
Args:
city: The name of the city
"""
flights = {
"Atlanta": [
"Delta Airlines",
"Spirit Airlines"
],
"Seattle": [
"Alaska Airlines",
"Delta Airlines"
],
"New York": [
"United Airlines",
"JetBlue"
]
}
return flights[city]
関数をテストします。「テスト」タブへ移動し、イベントJSONに以下の値を入力します。
{
"prompt": "Can you tell me travel options to Seattle?"
}
実行すると、以下のように利用可能なフライトが返ってきました。
Hi there! I'm happy to assist you with your travel plans. Here are the available flight options to Seattle:
1. Alaska Airlines
2. Delta Airlines
Module 2: 外部API連携の追加
モジュール2では、フライトオプションの他、旅行先の天気予報を返す機能を組み込みます。
ワークショップの指示に従い、先ほどのコードを修正します。ここでは、エージェントへのシステムプロンプトが更新されています。weather.gov APIを使用して目的地の天気予報を取得すること、およびそのAPIの利用方法が新たに追加されています。
3. Provide weather information for locations in the United States
4. The Seattle zip code value is 98101 and the latitude and longitude coordinates are 47.6061° N, 122.3328° W
5. First get the coordinates or grid information using https://api.weather.gov/points/{latitude},{longitude} or https://api.weather.gov/points/{zipcode}
6. Then use the returned forecast URL to get the actual forecast
When displaying responses:
- Format weather data in a human-readable way
- Highlight important information like temperature, precipitation, and alerts
- Handle errors appropriately
- Convert technical terms to user-friendly language
また、モデルに渡すツールとして先ほどのflight_searchの他に、http_requestが追加されています。
travel_agent = Agent(
model="us.amazon.nova-lite-v1:0",
system_prompt=TRAVEL_AGENT_PROMPT,
tools=[flight_search, http_request]
)
先ほどと同じようにテストをすると、応答に天気予報が追加されています。(長いので省略しています)
Hi there! I'm happy to help you with your travel plans to Seattle. Here are the flight options available for you:
- Alaska Airlines
- Delta Airlines
As for the weather forecast for Seattle, here is a summary of the upcoming days:
- **Tonight:** Mostly cloudy with a low of 34°F. Northeast wind around 2 mph.
- **Tuesday:** Partly sunny with a high of 45°F. East wind around 2 mph.
Module 3: 会話履歴保存機能の追加
モジュール3では、会話履歴の保存機能を追加します。
AIエージェントとやり取りする際、一意のセッションIDが付与されます。同一IDを利用してやり取りをすることで、会話履歴を維持できます。
StrandsではS3SessionManagerという機能を使用して、これを実現できます。
ワークショップの指示に従い、コードを更新します。システムプロンプトは変更せず、S3SessionManagerを利用するように修正します。
session_manager = S3SessionManager(
session_id=event["user"]["session_id"],
bucket=os.environ['SESSIONS_BUCKET'],
prefix="agent-sessions"
)
travel_agent = Agent(
model="us.amazon.nova-lite-v1:0",
system_prompt=TRAVEL_AGENT_PROMPT,
tools=[flight_search, http_request],
session_manager=session_manager
)
デプロイしたら、まず以下のJSONでテストを実行します。
{
"prompt": "Can you tell me travel options to Seattle?",
"user": {
"session_id": "123"
}
}
先ほどと同様の回答が返ってきます。(突然日本語ですが、システムプロンプトに日本語で応答するように付け加えたためです)
こんにちは!シアトルへの旅行オプションを提供します。
**利用可能な航空会社:**
1. アラスカ航空
2. デルタ航空
**シアトルの天気予報:**
**今日の夜:**
- 気温:34°F
- 予報:主に曇り
- 降水確率:5%
続いて以下のJSONでテストします。
{
"prompt": "Can you tell me some local things to do?",
"user": {
"session_id": "123"
}
}
以下のような応答が返ってきます。
こんにちは!シアトルで楽しめるアクティビティをご紹介します。
1. **スペースニードルの訪問:** シアトルのシンボルであるスペースニードルは、展望デッキから美しい眺めを楽しめます。
2. **パイク・プレイス・マーケット:** 地元の農産物や手作り品を販売する市場です。ここでは、新鮮な魚やフルーツなどを購入できます。
3. **ピケ・マーケット・フード・ツアー:** 地元のレストランやカフェを巡るフード・ツアーに参加し、シアトルの味を体験しましょう。
2つ目のテストではシアトルという単語を指定していないにも関わらず、過去の会話履歴からシアトルに関する質問であると理解し、適切な応答を返していることがわかります。
Module 4: RAGの追加
モジュール4では、Amazon Bedrockのナレッジベースを利用して、AIエージェントにRAGを実装します。
まず、Amazon Bedrock上にナレッジベースを作成します。ワークショップのページに書かれているコマンドを、CloudShellで実行します。
※注意※
ワークショップに書かれているコマンドはlab2-strands-travelagents3bucketragから始まるバケット名を検索しています。しかし実際に作成されていたバケット名はagentic-ai-workshop-lab2str-travelagents3bucketragのように先頭の文字列が異なっていました。そのため、コマンドを以下のように修正しています。
BUCKET=$(aws s3api list-buckets --query "Buckets[?starts_with(Name, 'agentic-ai-workshop-lab2str-travelagents3bucketrag')].Name" --output text)
aws s3 cp s3://ws-assets-prod-iad-r-pdx-f3b3f9f1a7d6a3d0/eb18d538-bf1f-49b9-9747-c474953deee1/seattletouroperators.txt .
cat seattletouroperators.txt
実行が完了すると、ナレッジベースのソースとなるドキュメントの内容が表示されます。
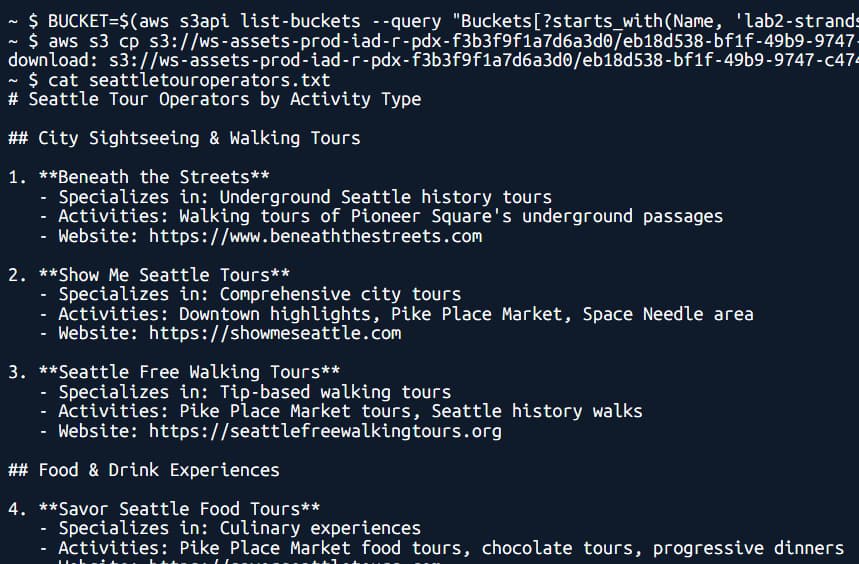
ワークショップの指示に従い、このテキストファイルをS3バケットにアップロードします。
aws s3 cp seattletouroperators.txt s3://$BUCKET/
続いて、Amazon Bedrockのナレッジベースを作成します。作成手順はここでは割愛しますが、ワークショップの指示通りに操作すれば問題なく作成できました。
※先ほども説明しましたが、バケット名のプレフィックスが指示と異なる部分があります。
ナレッジベースを作成したら、データソースを同期します。

ナレッジベースのIDが必要なので、コピーしておきます。

Lambda関数strands-travel-agentに戻ります。
まず、コピーしたナレッジベースIDを、環境変数KNOWLEDGE_BASE_IDに登録します。続いて、ワークショップのページにある通り、コードを更新します。
今回は、ツールとして新たにretrieveが追加されています。
travel_agent = Agent(
model="us.amazon.nova-lite-v1:0",
system_prompt=TRAVEL_AGENT_PROMPT,
tools=[flight_search, http_request, retrieve],
session_manager=session_manager
)
デプロイが完了したら、以下のJSONでテストをします。
{
"prompt": "What are some tour operators with water activities?",
"user": {
"session_id": "123"
}
}
以下のような応答が返ってきます。ナレッジベースに記載されている内容に基づいて応答していることがわかります。
こんにちは!シアトルで楽しめる水上アクティビティを提供するツアーオペレーターをご紹介します。
1. **Argosy Cruises**
- 専門分野:港湾観光とディナークルーズ
- アクティビティ:港湾クルーズ、Tillicum Excursion、閘門クルーズ
- ウェブサイト:[Argosy Cruises](https://www.argosycruises.com)
2. **Let's Go Sailing Seattle**
- 専門分野:プライベートセーリング体験
- アクティビティ:サンセットセール、デイセーリング、セーリングレッスン
- ウェブサイト:[Let's Go Sailing Seattle](https://letsgosailingseattle.com)
Module 5: MCPサーバ呼び出しの追加
モジュール5では、Amazon Bedrock AgentCore Gatewayを使用して、既存のLambda関数をMCPサーバに変換します。そして、strands-travel-agent関数はMCPクライアントとして、MCPサーバを呼び出します。
Amazon Bedrock AgentCore Gatewayは、既存のAPIやLambda関数をMCP互換ツールに変換できるサービスです。詳しくは、以下の記事をご覧ください。
[Amazon Bedrock AgentCore] Gateway経由でLambda関数をAIエージェントのツールにしてみた | DevelopersIO
まず、Amazon Bedrock AgentCore Gatewayを作成します。手順は割愛しますが、ワークショップの指示通りに操作すれば問題ありません。
ここでは、attractionsというLambda関数をMCPサーバに変換しています。この関数の中を見てみると、以下のツールが定義されています。
list_attractions- アトラクションの時間と料金を返す
reserve_ticket- アトラクション名と日時を受け取り、予約する
cancel_ticket- 予約コードを受け取り、キャンセルする
ゲートウェイが作成できたら、strands-travel-agent関数を指示に従って更新します。また、指示に従って環境変数を更新します。
全て完了したら、以下のJSONでテストをします。
{
"prompt": "Reserve a ticket for Space needle for 9:00 AM tomorrow",
"user": {
"session_id": "123"
}
}
以下の応答が返ってきます。MCPサーバのreserve_ticketが使用されていることがわかります。
スペースニードルのチケットが予約されました。予約コードはFVZD4Oです。明日の9:00 AMをお楽しみください!
ちなみに再度実行すると、予約済みであると言われます。
すみませんが、スペースニードルの9:00 AMのチケットはすでに予約されています。他の時間や日付をご希望でしたら、お知らせください。
Module 6: API Gatewayを使用したエージェントの公開
モジュール6では、API Gateway経由でAIエージェントを公開します。Amazon Cognitoによる認証機能も追加します。
ワークショップの指示に従い、以下の操作を実施します。基本的に指示通りの操作で問題ありませんが、指示通りの操作ではうまくいかない部分を補足しています。
- API Gatewayの作成
- Security Policyの指定が必須となっていますが、ワークショップには値が指定されていません。ここでは
SecurityPolicy_TLS13_1_3_2025_09を選択しました。
- Security Policyの指定が必須となっていますが、ワークショップには値が指定されていません。ここでは
- リソースの作成
- POSTメソッドの作成
- Cognito Authorizerの作成
- POSTメソッドに認証の追加
- APIのデプロイ
- 「APIをデプロイ」ボタンが有効化されない場合、少し待ちます。
strands-travel-agent関数の更新- テストユーザの作成とトークンの取得
ここまでの手順で、APIが実行できるようになっています。ワークショップではCloudShellからAPIをテストする手順が紹介されているので、手順通りに実施します。
curl -X POST $API_URL \
-H "Authorization: $ID_TOKEN" \
-H "Content-Type: application/json" \
-d '{"prompt": "Can you tell me travel options to Seattle?"}' | jq
以下のように応答が返ってきます。
{
"response": "<response>\nこんにちは!シアトルへの旅行オプションと天気予報を提供します。\n\n**利用可能なフライト:**\n- アラスカ航空\n- デルタ航空\n\n**天気予報:**\n- **今日(2025年12月29日):** 夜間は曇り。最 低気温は34°F。北東の風は2マイル。\n- **明日(2025年12月30日):** 日中は晴れ。最高気温は45°F。東の風は2マイル。\n- **明後日(2025年12月31日):** 夜間は部分的に曇り。最低気温は34°F。南東の風は2マイル。\n- **2026 年1月1日(新年):** 日中は部分的に晴れ。最高気温は47°F。降雨の可能性は30%。\n- **2026年1月2日(金曜日):** 日中は雨。最高気温は50°F。降雨の可能性は78%。\n\n以上です。他にお手伝いできることはありますか?\n</response>"
}
CloudShell以外の任意のHTTPクライアントでAPIを実行できますが、日本語の応答が文字化けすることがあります。その場合、Lambda関数の戻り値を以下のように修正します。
return {
'statusCode': 200,
'body': json.dumps({
'response': re.sub(THINKING_PATTERN, '', str(response), flags=re.DOTALL).strip()
}, ensure_ascii=False),
'headers': {
'Content-Type': 'application/json; charset=utf-8'
}
}
Lab 3: Building agents on Amazon Bedrock Agents
Lab 3 - Building agents on Amazon Bedrock Agents
このLabでやること
このLabでは、Amazon Bedrockを使用してAIエージェントを構築します。
ここでは、以下の3つのAIエージェントを作成し、これらが相互に接続できるようにします。
- フライト関連の問い合わせに対応するエージェント
- 天気予報と推奨事項を提供するエージェント
- 他のエージェントからの情報を元に、最終的な推奨事項を作成するエージェント
Module 1: Amazon Bedrock Agentの構築
モジュール1では、まずフライトの検索、予約、キャンセルを行うフライトエージェントを作成します。
手順に従って以下の操作を実施します。指示通りに問題なく操作できると思いますので、詳細はここでは割愛します。
- エージェントの作成
- エージェントのカスタマイズ
- アクショングループの構成
- エージェントの準備
ここで構成した「アクショングループ」とは、ツールのインタフェース定義群です。
アクショングループごとにLambda関数を指定できます。この関数の中に複数のツールが実装されます。しかし、エージェントはどのツールをどんなパラメータで呼び出したら良いのかわかりません。そこで、アクショングループでツールのインタフェースを定義することで、エージェントが関数を呼び出せるようにします。
例えば、Lambda関数にはFlightSearchというツールが定義されています。このツールを実行するには、「origin(出発する空港コード)」、「destination(目的の空港コード)」、「departureDate(出発日)」、「returnDate(帰宅日)」の4つのパラメータが必要です。アクショングループにこれらのパラメータ定義を記述しておくことで、エージェントがユーザの入力を解析し、必要な形式にしてLambda関数に渡してくれます。
では、このエージェントをテストします。
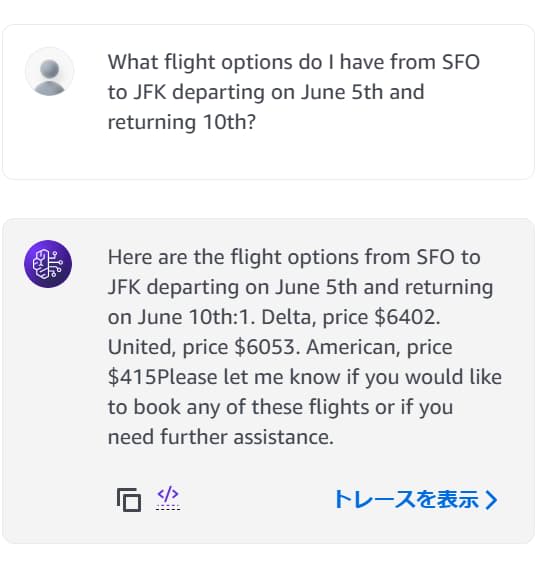
右側に表示されているテスト用のチャット欄に、以下の文章を入力します。
What flight options do I have from SFO to JFK departing on June 5th and returning 10th?
改行がなく若干見づらいのと、ワークショップのページに書かれた値段とは異なりますが、3つのオプションを提示されました。
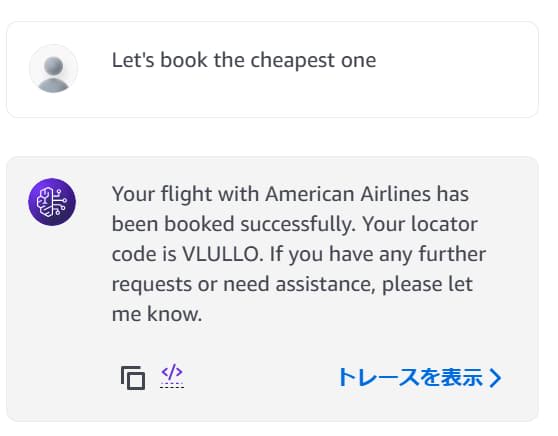
最も安いオプションを予約するよう依頼します。
Let's book the cheapest one
最も安い、アメリカン航空のフライト予約が取れました。
Module 2: IaCを使用したエージェント構築
モジュール2では、残り2つのエージェントを構築し、相互に連携できるようにします。まずは、天気予報を提供するエージェントをCloudFormationを使用して構築します。
構築自体は、あらかじめ用意されたCloudFormationテンプレートをデプロイするだけなので簡単に終わります。ワークショップのページには、IaCを活用する利点や、CloudFormationテンプレートの解説もありますので、気になる方は一読して頂ければと思います。
Module 2: エージェント間連携
続いて、他のエージェントと連携し最終的な推奨事項を作成するエージェントを構築します。詳細な手順については割愛します。
他のエージェントと連携するエージェントを作成するには、作成時に「マルチエージェントコラボレーション」にチェックを入れます。
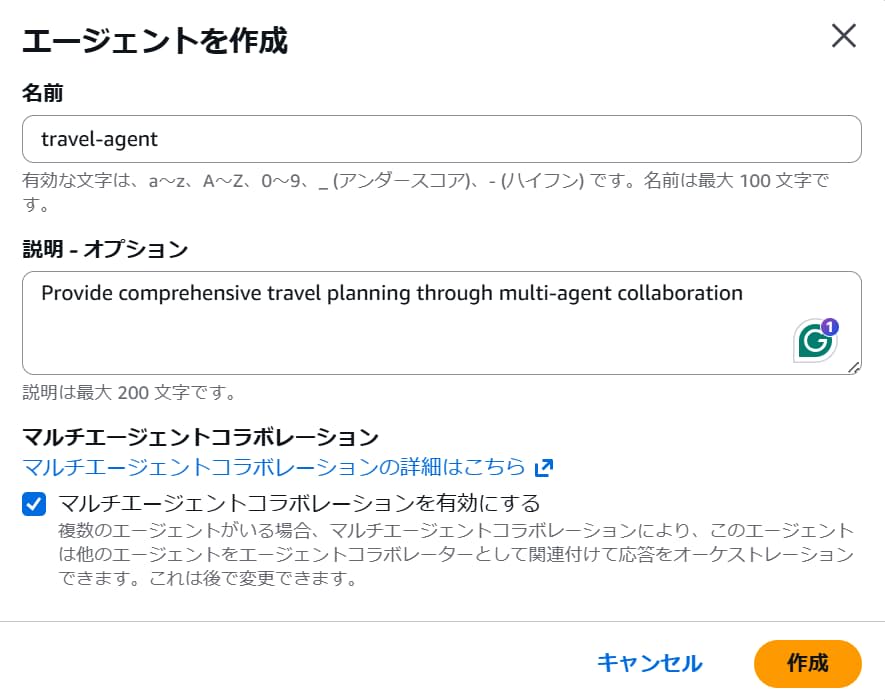
また、ワークショップの指示に「Anthropic - Claude 3.5 Haiku」モデルを選択するようありますが、有効化していない場合、以下のダイアログが表示される可能性があります。
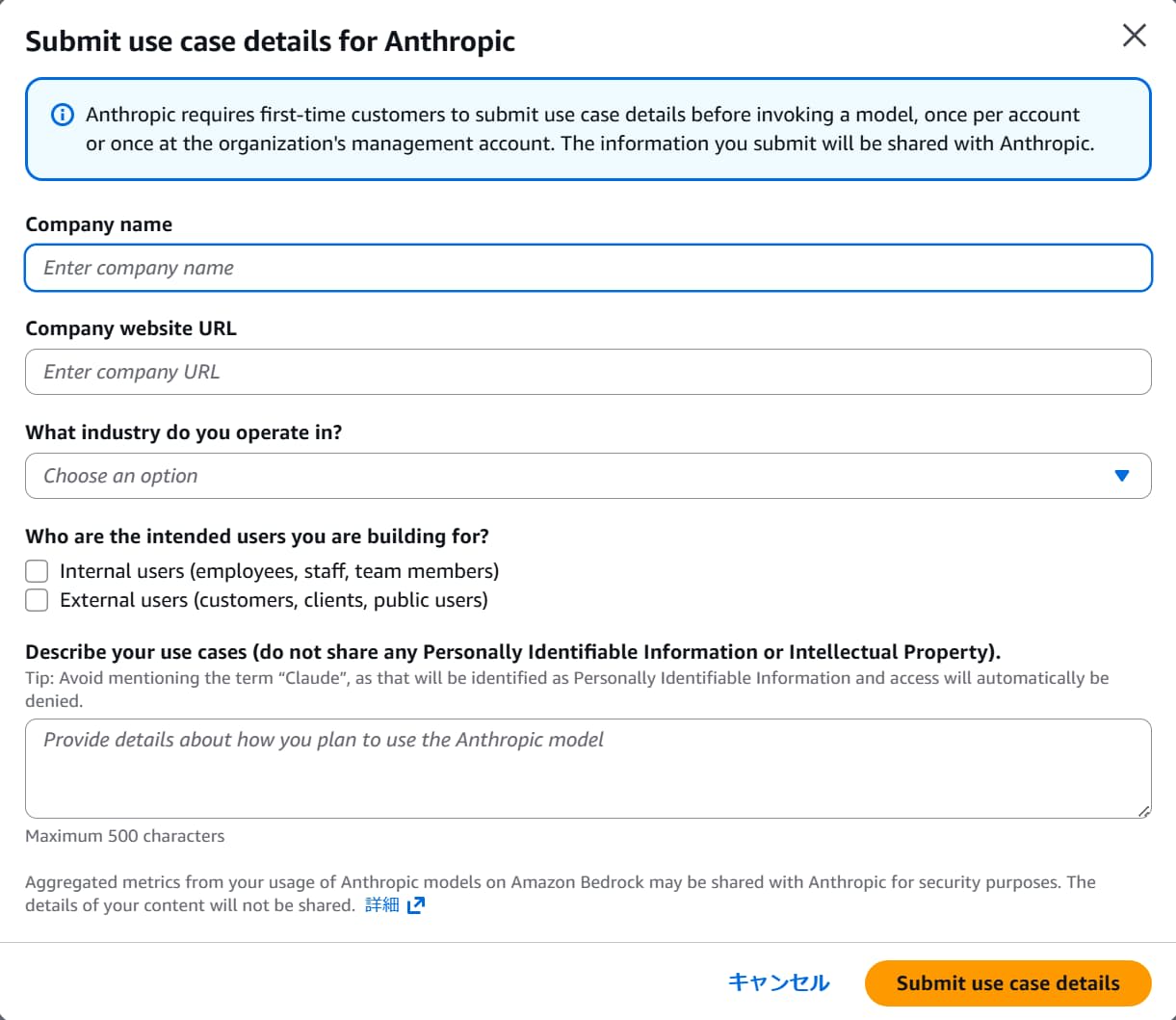
個人利用の場合は以下の手順を参考にしてください。
Amazon Bedrock で Claude を個人利用する
エージェントの動作をテストするためのフロントエンドアプリケーションのURLは、agentic-ai-workshopスタックの「出力」タブで確認できます。
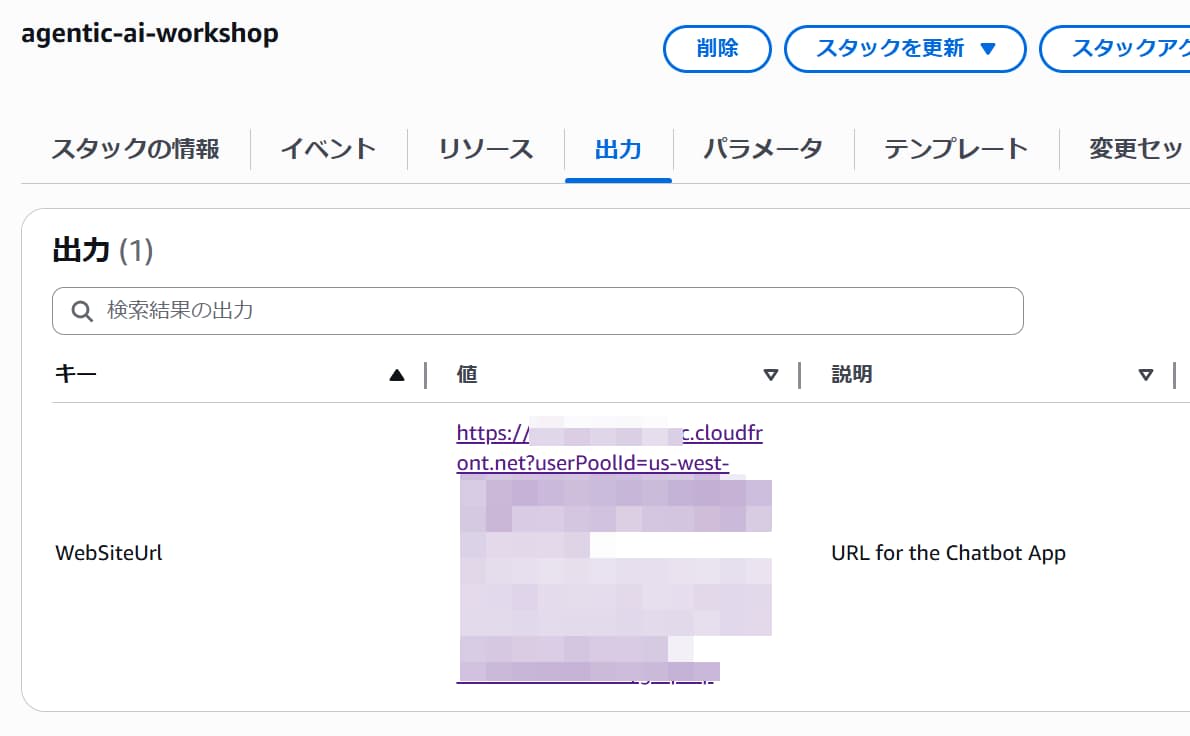
チャットアプリでテストする際、私の環境ではLambdaがAccessDeniedExceptionでエラーになってしまいました。Lambdaの実行ロールにBedrockへのフルアクセスをつけてもダメでした。モデルをClaudeからNova Proに変更したら正常に動きました。モデルアクセスの問題かもしれませんが、正確な理由はわかりません。
クリーンアップ
ワークショップで最も大事なことは作成したリソースをクリーンアップすることです。
以下のページにクリーンアップの手順が記載されています。
ページ内のスタック名が実際に作成されたものと異なるためわかりづらいですが、以下のリソース削除を実施します。
- Amazon Bedrockの3つのエージェント
- Amazon Bedrockナレッジベース
- 作成された3つのS3バケット(中身を空にしてから削除)
lab3-weather-agentスタックLab3BedrockAgentsStackという名前が含まれているスタックagentic-ai-workshopスタック- API Gatewayの
strands-travel-agent - Amazon Bedrock AgentCore Gateway
- Cognitoの2つのユーザプール
- S3ベクトルバケット
- CloudWatchログ
ナレッジベースの削除でエラーが発生した場合、以下を参考にしてデータソースの削除ポリシーをRetainにすると解決するかもしれません。
Amazon Bedrock で発生する「Failed to delete knowledge base」エラーを解決する
おわりに
今回はAgentic AIのキャッチアップもかねてワークショップをやってみました。
AIエージェントが複数のツールを使用してどのようにユーザからの問い合わせに対処するかといった基本的なところから、StrandsやAmazon Bedrockを使用したエージェントの構築といった実践的な内容まで含まれており、概要を把握するのに最適なワークショップだと感じました。
ブログを書きながらだったので、2時間よりもかなり長くかかってしまいましたが、各ステップを理解しながら進めることで実装パターンを体系的に学ぶことができました。
この記事がどなたかの参考になれば幸いです。









