
Alteryxの「PDFからテキスト抽出」ツールを使ってテキストと画像コンテンツを読み取ってみた
こんにちは、まつおかです。
Alteryx Designerのオンプレミス版には、機械学習やテキストマイニング、コンピュータービジョンなどの高度な分析機能を利用できる 「Intelligence Suite」 という有料のアドオン製品があります。
今回はその中のコンピュータービジョンにある 「PDFからテキスト抽出」 ツールを使用し、PDFファイルからテキストを抽出してみましたのでその手順をご紹介します。
前提
使用環境
- Windows 11 Pro
- Alteryx Designer 2025.1.2.79
- Alteryx Intelligence Suite 2025.1
PDFファイルのテキストについて
PDFファイルは、一見テキストに見える内容でも、実際には「テキストデータ」として扱える場合と「画像」として埋め込まれている場合があります。
見た目は同じでも画像の場合はOCR(光学文字認識)という技術を使って抽出しますので、本ツールを使用する際もテキストか画像かで扱いが変わる箇所があります。
やってみた
まずはテキストと画像コンテンツが混在しているPDFを読み込んでみます。

このようなごくシンプルなPDFファイルを使いますが、上半分のテキストコンテンツと書かれたブロックまでがテキストデータとなっており、下半分の画像コンテンツと書かれたブロックは画像となっています。
テキストと画像コンテンツの抽出
「PDFからテキスト抽出」ツールは、「コンピュータービジョン」パレットの中にあります。

なんと、このツールひとつ配置して読み込み対象のPDFファイルなどを設定するだけで、PDFからテキストを抽出することができます。
入力アンカーが2つもあるのに、何も繋げなくても動きます。
ということで、キャンバスにポツンと配置して設定していきます。
こちらが設定画面です。
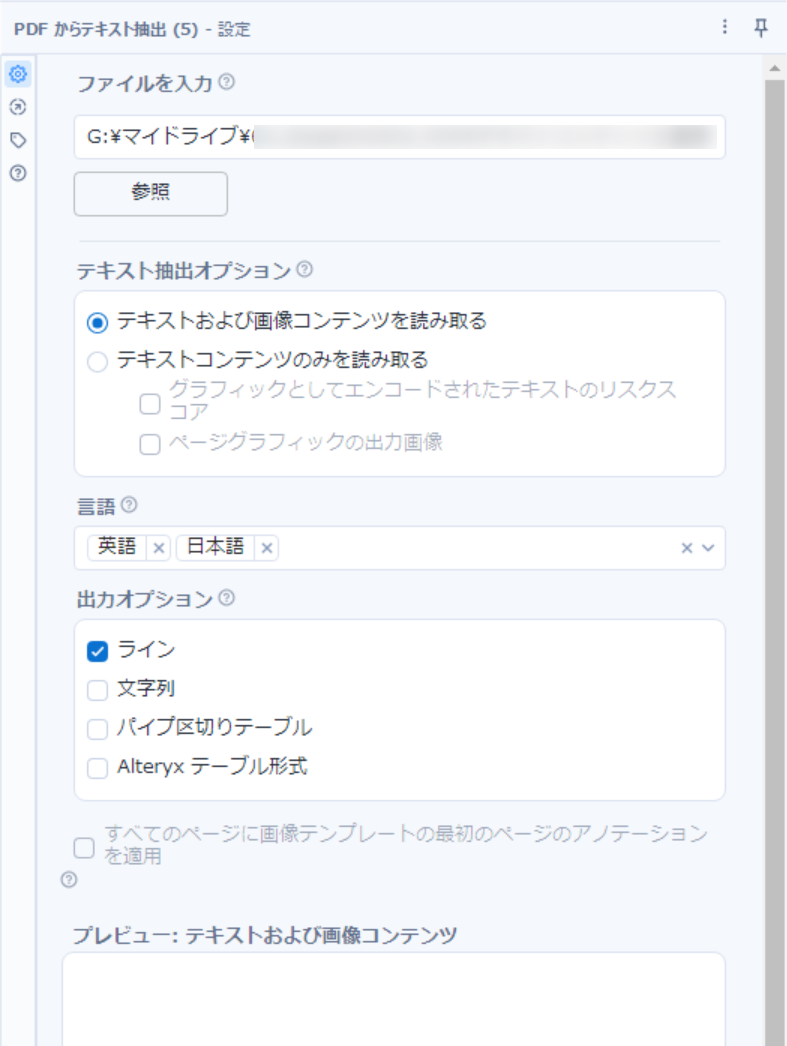
- ファイルを入力
- 読み込み対象のPDFファイルのパスを設定します。参照ボタンからファイル選択するか、テキストボックスに直接パスを入力することもできます。
- テキスト抽出オプション
- 今回はテキストも画像も読み取りたいので「テキストおよび画像コンテンツを読取る」を選択します。
- 言語
- 画像コンテンツに含まれる言語を指定します。
- アラビア語、英語、フランス語、ドイツ語、イタリア語、日本語、ポルトガル語、簡体字中国語、スペイン語がサポートされています。
- 出力オプション
- 今回は「ライン」のみを選択します。(他のオプションは後ほどご紹介します)
以上の設定でワークフローを実行した結果がこちら!
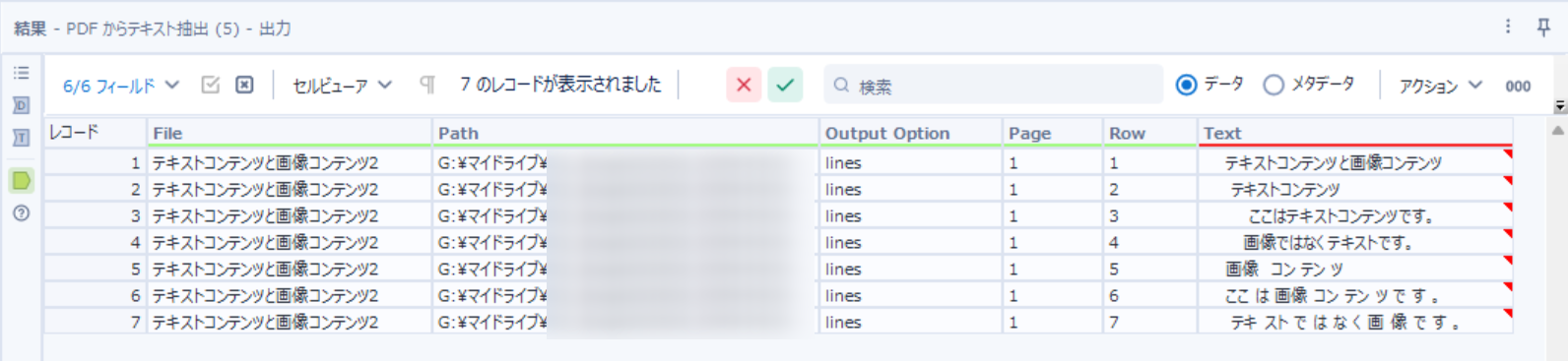
ファイルの情報と、出力オプション(今回はラインを指定したので”lines”)、ページ番号、行数と、読み取られたテキストが確認できます。
テキスト列は空白が含まれてしまっているので警告が表示されていますがこのあとクレンジングすればOKです。
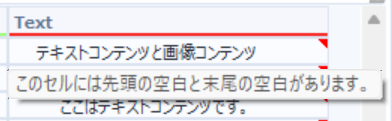
上半分のテキストコンテンツはテキストデータなので非常に綺麗に読み取れています。
下半分は画像コンテンツのため少し不自然に空白などが含まれていますが、これもクレンジングで簡単に解決できますし、何より画像からこんなに簡単にテキストが抽出できてありがたい!
出力オプションについて
先程は「ライン」のみを選択して試した出力オプションですが、4種類のオプションが用意されています。
以下ののPDFファイルを読み込んだ際に、出力オプションによってどのような出力がされるか見てみます。

-
ライン(Output Option:line)
-
PDF内の1行につき1レコードで出力されます
-
各行のテキストが1つの文字列として出力されます

-
-
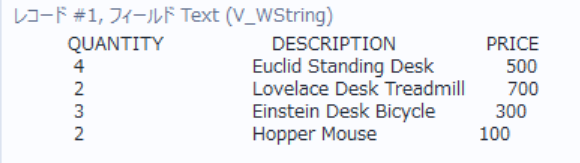
文字列(Output Option:String)
-
PDF1ページにつき1レコードで出力されます
-
ページ内の全てのテキストが1つの文字列として出力されます

-
Textフィールドの中に全テキストが入っています
-
-
パイプ区切りテーブル(Output Option:pipe-delimited table)
-
PDF1ページにつき1レコードで出力されます
-
視覚的に表形式となっているデータを、構造化されたテーブル形式に変換しパイプで区切り出力します

-
Textフィールドの中に全テキストが入っています

-
-
Alteryxテーブル形式(Output Option:Alteryx table)
-
PDF内の1行につき1レコードで出力されます
-
視覚的に表形式となっているデータを、構造化されたテーブル形式に変換し列に分割し出力します

-
オプションはチェックボックスになっており、複数選択が可能です。
選択したオプション分、レコードが出力されます。

さいごに
以上、PDFファイルからテキスト抽出の手順でした。
「PDFからテキスト抽出」ツールひとつで、非常に簡単にテキストを抽出することができました。
今後抽出オプションの「テキストコンテンツのみを読み取る」を選択した場合の動きも試してみたいと思います。
<2025/9/11 追記>
「テキストコンテンツのみを読み取る」を選択した場合の動きはこちら。









