
Alteryxの「PDFからテキスト抽出」ツールを使ってテキストコンテンツを読み取ってみた
こんにちは、まつおかです。
前回のブログでは「PDFからテキスト抽出」ツールを使用し、テキストと画像コンテンツを読み取った場合にどのような動きになるのかをご紹介しました。
今回はテキスト抽出オプションを 「テキストコンテンツのみを読み取る」 に設定した場合どのような結果になるのかを見ていきます。
「PDFからテキスト抽出」ツールは、機械学習やテキストマイニング、コンピュータービジョンなどの高度な分析機能を利用できる 「Intelligence Suite」 という有料のアドオン製品に含まれています。
前提
使用環境
- Windows 11 Pro
- Alteryx Designer 2025.1.2.79
- Alteryx Intelligence Suite 2025.1
PDFファイルのテキストについて
PDFファイルは、一見テキストに見える内容でも、実際には「テキストデータ」として扱える場合と「画像」として埋め込まれている場合があります。
見た目は同じでも画像の場合はOCR(光学文字認識)という技術を使って抽出しますので、本ツールを使用する際もテキストか画像かで扱いが変わってきます。
やってみた
使用するPDFファイルは、前回と同じものを使用します。
上半分のテキストコンテンツと書かれたブロックまでがテキストデータ、下半分の画像コンテンツと書かれたブロックは画像となっています。

テキストコンテンツのみを読み取る
「PDFからテキスト抽出」ツールは、「コンピュータービジョン」パレットの中にあります。

こちらが設定画面です。
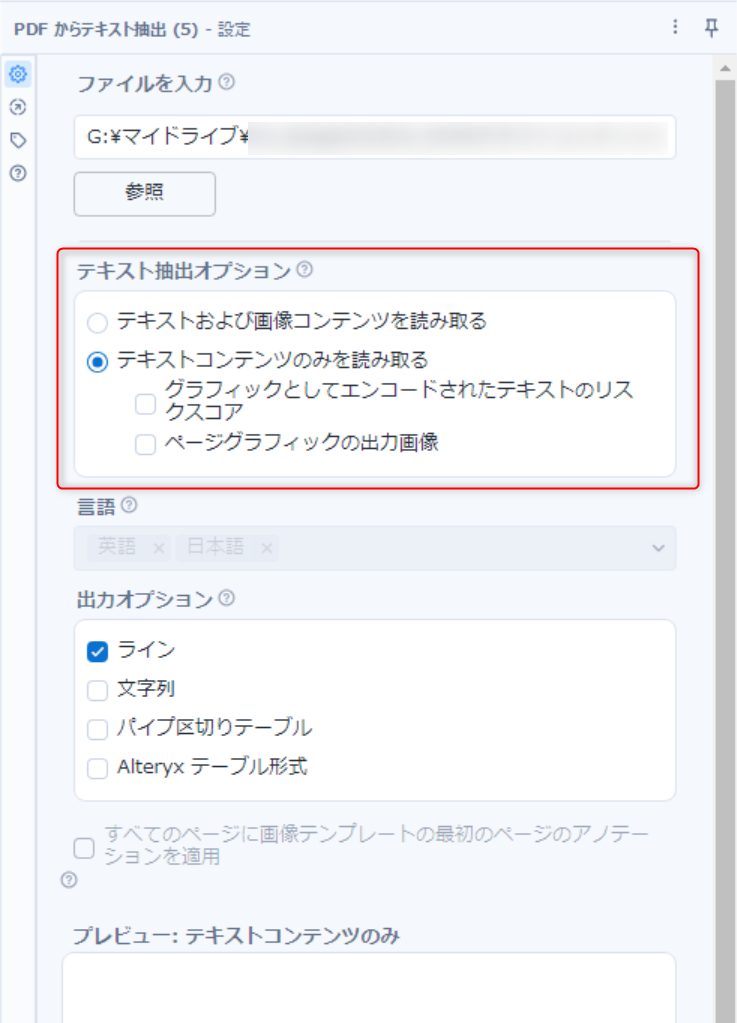
今回はテキスト抽出オプションで「テキストコンテンツのみを読み取る」を選択します。
抽出オプション以外の設定は前回と同じです。
- ファイルを入力
- 読み込み対象のPDFファイルのパスを設定します。参照ボタンからファイル選択するか、テキストボックスに直接パスを入力することもできます。
- 言語
- 画像コンテンツに含まれる言語を指定します。
- アラビア語、英語、フランス語、ドイツ語、イタリア語、日本語、ポルトガル語、簡体字中国語、スペイン語がサポートされています。
- 出力オプション
- 「ライン」のみを選択します。
- 他のオプションについてはこちらを参照してください。
以上の設定でワークフローを実行した結果がこちら。

上半分のテキストデータ部分だけが出力されました。まさに「テキストコンテンツのみを読み取る」の結果です。
では次は、「グラフィックとしてエンコードされたテキストのリスクスコア」 にチェックを入れて実行してみます。
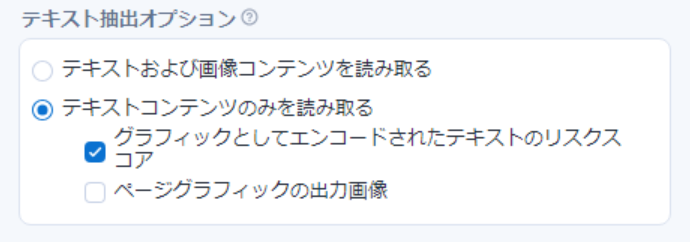
結果はこちら。

右に 「Graphic Text Risk」と「Graphic Text Word Count」の2列が追加 されて出てきました。
- 「Graphic Text Risk」
- 読み込んだページの中にあるテキストを抽出するにあたりOCRが必要かどうかをアドバイスします。つまり、画像となっていることで読み込めていないテキストがどのくらいあるかを知らせてくれるのです。
- 「Graphic Text Risk」が”medium”や”high”となっている場合は、テキスト抽出オプションで「テキスト及び画像コンテンツを読取る」を選択したほうが良いという判断になります。
- 「Graphic Text Word Count」
- 画像内のテキストをOCRで読み取った結果、単語として認識された数を表示しています。
- 日本語を単語で正確に分割するのは難しいのであまり参考にならないですが、英語の場合は単語を認識しやすいので有効な情報となりそうです。
そして画像となっているのがどの部分なのかを確認できるオプションが 「ページグラフィックの出力画像」 です。
チェックを入れて実行してみます。
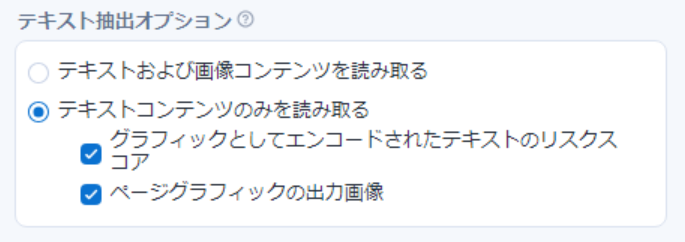
結果はこちら。

出力オプションの列に ”pdf graphics” が出現し、Image列が追加 されています。
ここにはページの中で画像として認識された部分の情報が出力されていますので、レポーティングパレットの中にある「画像ツール」を使って確認が可能です。(「画像ツール」についての詳細はこちらをご参照ください)
フィルターツールを使って出力オプションが ”pdf graphics” の行に絞り、画像ツールと閲覧ツールを使いImage列を可視化します。
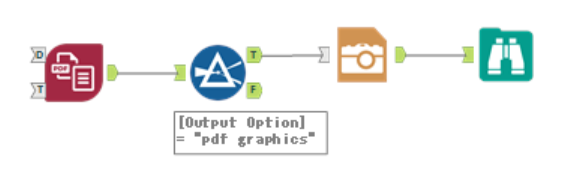
閲覧ツールを確認すると、画像コンテンツ部分が出ていました。
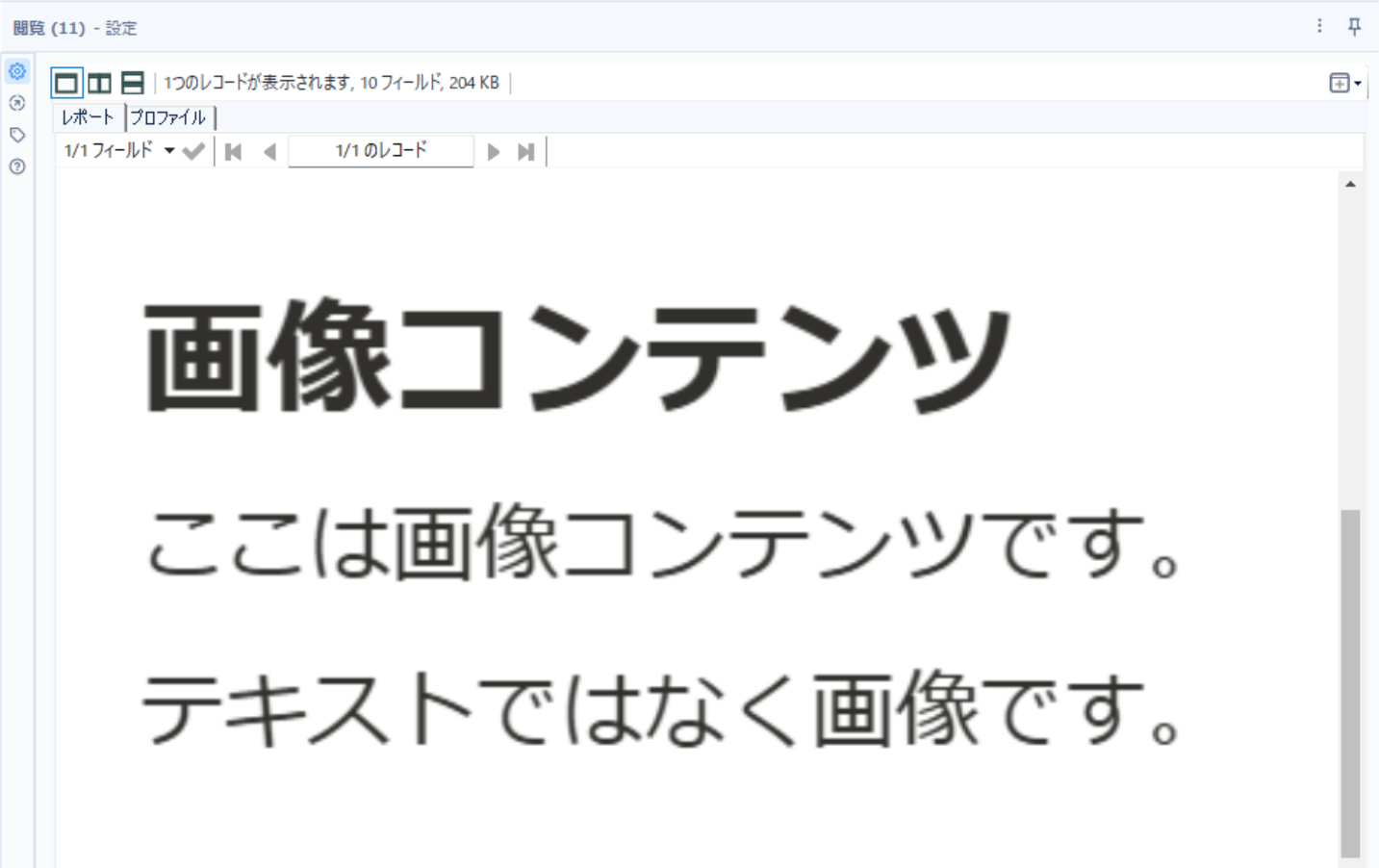
これでどの部分が画像となっているのかが確認できましたので、テキスト抽出オプションをテキストのみにするのか、画像コンテンツも読み取るのか判断します。
テキストコンテンツのみの抽出はOCRを使うより高速に処理ができる ため、画像コンテンツを読み込まないのであればテキストのみにするほうが処理が早くなります。
さいごに
今回は「PDFからテキスト抽出」ツールで抽出オプションに「テキストコンテンツのみを読み取る」を選択した場合の動きをご紹介しました。
テキストコンテンツだけを読むのではなく、さらにオプションとして画像に含まれるテキストの情報を出してくれることで、本当にテキストの読み込みだけでいいのか正確に判断できる点は非常に便利だと思いました。
ぜひご活用ください。









