![[レポート] Amazon Bedrock AgentCoreでマルチテナントSaaSエージェントを構築する #AWSreInvent #SAS407](https://images.ctfassets.net/ct0aopd36mqt/4pUQzSdez78aERI3ud3HNg/fe4c41ee45eccea110362c7c14f1edec/reinvent2025_devio_report_w1200h630.png?w=3840&fm=webp)
[レポート] Amazon Bedrock AgentCoreでマルチテナントSaaSエージェントを構築する #AWSreInvent #SAS407
はじめに
こんにちは、スーパーマーケットが好きなコンサルティング部の神野です。
AWS re:Invent 2025に元気よく参加しています!
今回は「Building multi-tenant SaaS agents with Amazon Bedrock AgentCore (SAS407)」というセッションに参加してきました!
私もよく触っている、10月にGAされたAmazon Bedrock AgentCoreですが、SaaSとしてエージェントを提供する場合、マルチテナンシーをどのように実現するか気になったのでこのセッションを受講しました。本セッションでは、Amazon Bedrock AgentCoreを使ってマルチテナントSaaSエージェントを構築するための具体的なパターンが紹介されていたのでセッションレポートを記載します。
セッション概要
- タイトル: Building multi-tenant SaaS agents with Amazon Bedrock AgentCore (SAS407)
- 日時: Mon, December 1, 1:00 PM - 2:00 PM PST
- 場所: Wynn | Upper Convention Promenade | Bollinger
- スピーカー: Bill Tarr (Principal Partner Solutions Architect)、Ujwal Bukka (Senior Partner Solutions Architect)
- レベル: 400 – Expert
公式Abstract:
The introduction of Amazon Bedrock AgentCore equips builders with a range of new tools and technologies. These tools enable a range of new strategies and techniques that will directly impact how teams build multi-tenant AI solutions and agents. This session will dig into working examples how tenancy is leveraged and landed in an intelligence-as-a-service environment, highlighting the multi-tenant nuances and possibilities that can built with the latest AI-powered AWS services. This includes a deep dive AgentCore multi-tenant pattern, spanning the identity, memory, gateway, observability, and run-time elements of the AgentCore experience. The goal here is to understand how SaaS providers can introduce tenant-context into their agents to support core SaaS mechanisms and constructs (onboarding, isolation, data partitioning, identity, etc.).
結構広い会場ですが参加者がかなり集まっていて、AgentCoreへの関心の高さが伺えました。
具体的にどうやってSaaSにAgentCoreを実装するのかは皆、気になりますよね。
セッション内容
SaaSにおける5つのアーキテクチャ課題

セッションの冒頭で、スピーカーからSaaSを構築する際に直面する5つの主要な課題が紹介されました。
一度は聞いたことがある話もあるのではないでしょうか。私も過去にふわっと聞いたことがあるなと思いながら聞いていました。
Tenant Onboarding
テナントオンボーディングとは、顧客が製品を知ってから実際に価値を得られるまでの時間をいかに短縮するかという課題です。SaaSにおいて、オンボーディング体験が悪く、使い始めるまでに1週間もかかるようでは、顧客は離れてしまいます。
SaaS Identity
ユーザーの認証・認可をどのように行うか、そしてテナントIDやテナントコンテキストをどのようにソリューション全体に伝播させるかという課題です。
Data Partitioning
テナントデータを適切に管理する方法です。例えば論理的または物理的なバケットにテナントデータを分離し、他のテナントのデータから安全に保護する必要があります。
Tenant Isolation
テナントがアクセスできるリソースとできないリソースを定義するポリシーです。テナントリソースは明確かつ明示的に定義される必要があります。
SaaS Observability
テナントの健全性を監視する能力です。特にエージェントソリューションのように多くの可動部分がある場合、オブザーバビリティは誰が何をしているかは重要になります。
改めて考えてみるとどれも大事ですし、適切にクリアしようとすると難しい課題のように感じます。
Amazon Bedrock AgentCoreの紹介
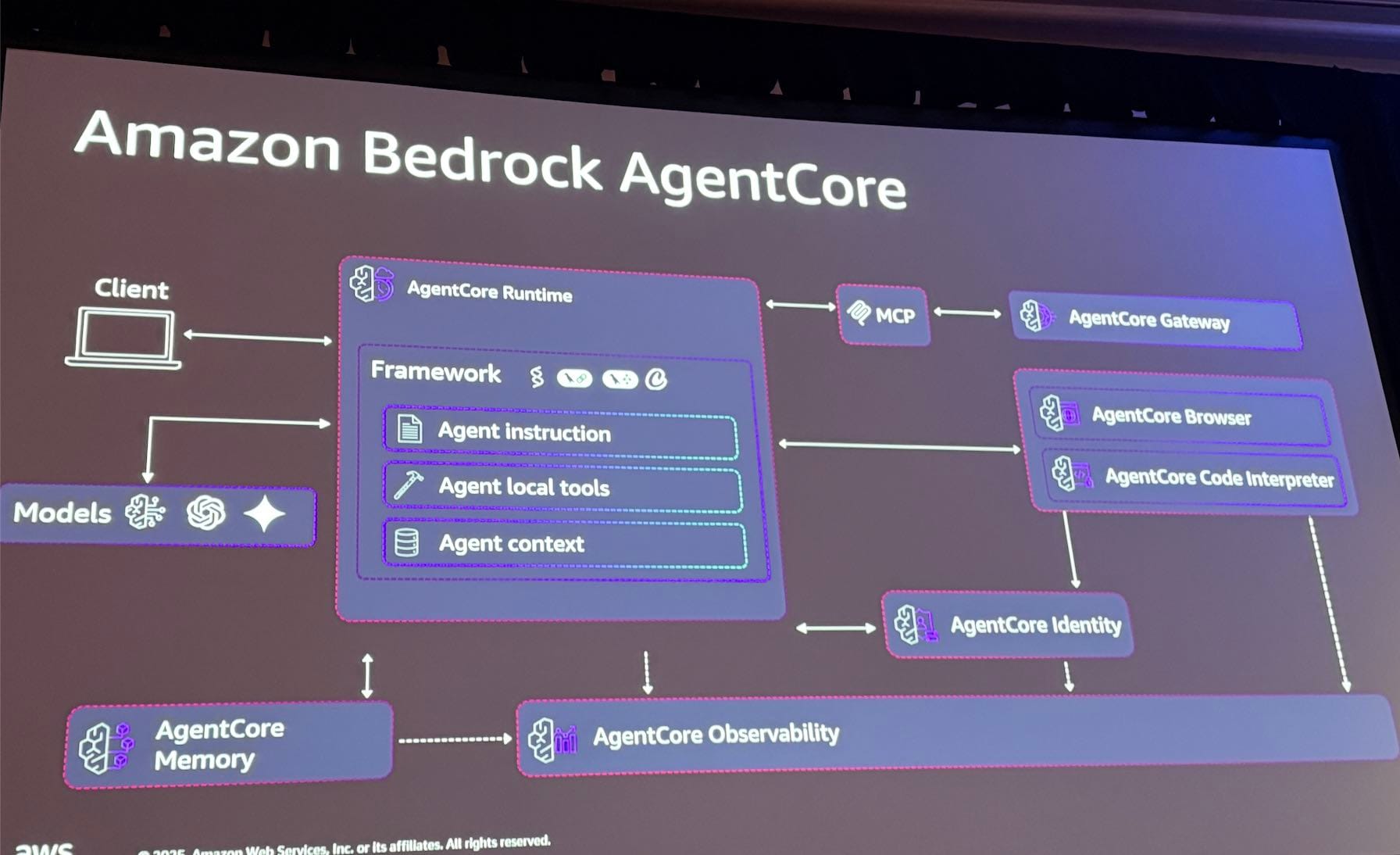
上記の課題に対応するAmazon Bedrock AgentCoreの下記機能が紹介されました。
より各機能詳細に知りたい場合は下記ブログをご参照ください。
今回はあくまでセッション内での紹介レベルで記載しています。
AgentCore Runtime
エージェントコードをデプロイし、安全にスケールさせるための実行環境です。マネージドサービスでAIエージェントをホストできるので、インフラの管理が最小限になり便利です。
AgentCore Gateway
ツールコードをデプロイするための機能です。「MCP as a Service」と考えるとわかりやすいとセッション内で紹介されていました。AgentCore Runtimeで動作するエージェントは、MCPを通じてGatewayにデプロイされたツールを呼び出すことができます。
ただこれだけではGatwayを理解するところは難しいところもあるので、気になる方は下記ブログもご参照ください。
Gatewayの利用イメージについて詳細に記載しています。
私としては既存アセット(Lambda関数など)をMCPツール化したい、利用するMCP Serverを中央集約したいケースなどに使用するイメージです。
AgentCore Identity
インバウンド呼び出し(ユーザーからエージェントへの呼び出し)とアウトバウンド呼び出し(エージェントから外部リソースへの呼び出し)の認証・認可を管理します。
AgentCore Memory
エージェントの会話メモリを保存し、タスクを解決するためのコンテキストを維持します。短期記憶と長期記憶の2種類があります。
AgentCore Observability
エージェントが何をしているのか監視機能を提供します。
OpenTelemetry形式のログからエージェント動きをダッシュボード上で可視化してくれる便利なサービスです。
処理ごとに経過時間もわかるので、処理スピードのボトルネックなども考察可能です。
マルチテナントモデル
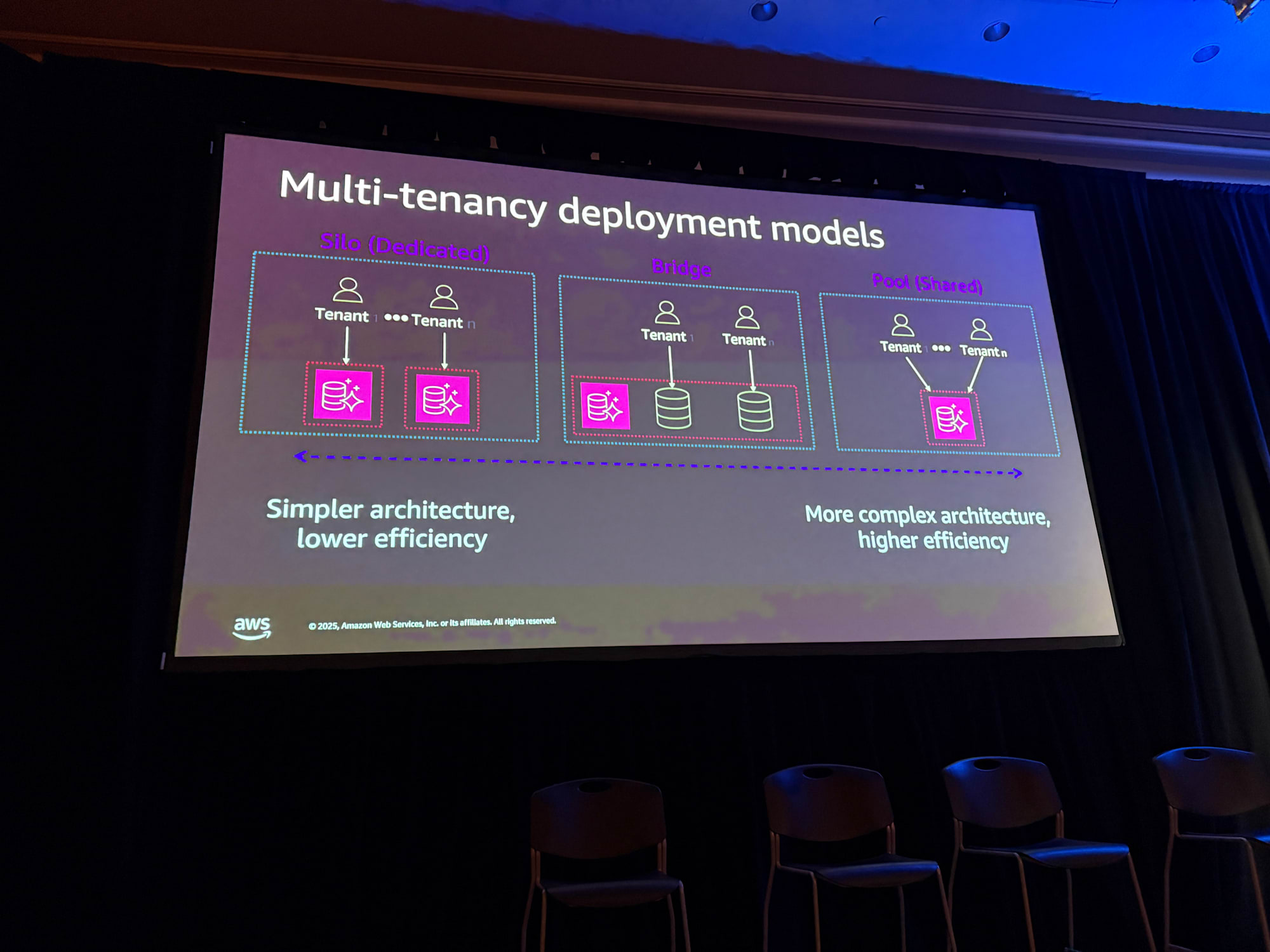
SaaSソリューションを構築する際、顧客のタイプに応じて異なるデプロイメントモデルを検討する必要があります。
Silo(サイロ)/ Dedicated(専用)モデル
各テナントが独自のスタックを持つモデルです。Webサーバー、コンピュート、すべてが独立したアーキテクチャになります。シンプルなアーキテクチャですが、テナント数が増えると運用・保守が困難になります。
AWSのリソースがそのまま独立して増える(例えばEC2がテナント毎に10台とか)と金額的なコストも嵩んでいくイメージなります。
Pooled(プール)/ Shared(共有)モデル
インフラストラクチャを複数のテナントで共有するモデルです。ランタイムで「あなたは誰か?」「何をしようとしているのか?」「その操作を行う権限があるか?」を判断する必要があります。複雑ですがリソースコスト的には効率的です。トレードオフですね。
Hybrid(ハイブリッド)/ Bridge(ブリッジ)モデル
上記2つの組み合わせです。一部のコンポーネントは共有し、他のコンポーネントは専用にするという柔軟な構成です。例えばEC2は共有だけど、RDSは独立しているなど。
実際のSaaSでは、Basic Tierはプールモデル、Premium Tierはサイロモデルといった形で提供するケースなどあるかと思います。どれが優れているというわけではなく、顧客の要件に応じて最適なモデルを考えていくことが大切ですね。
テナントオンボーディング
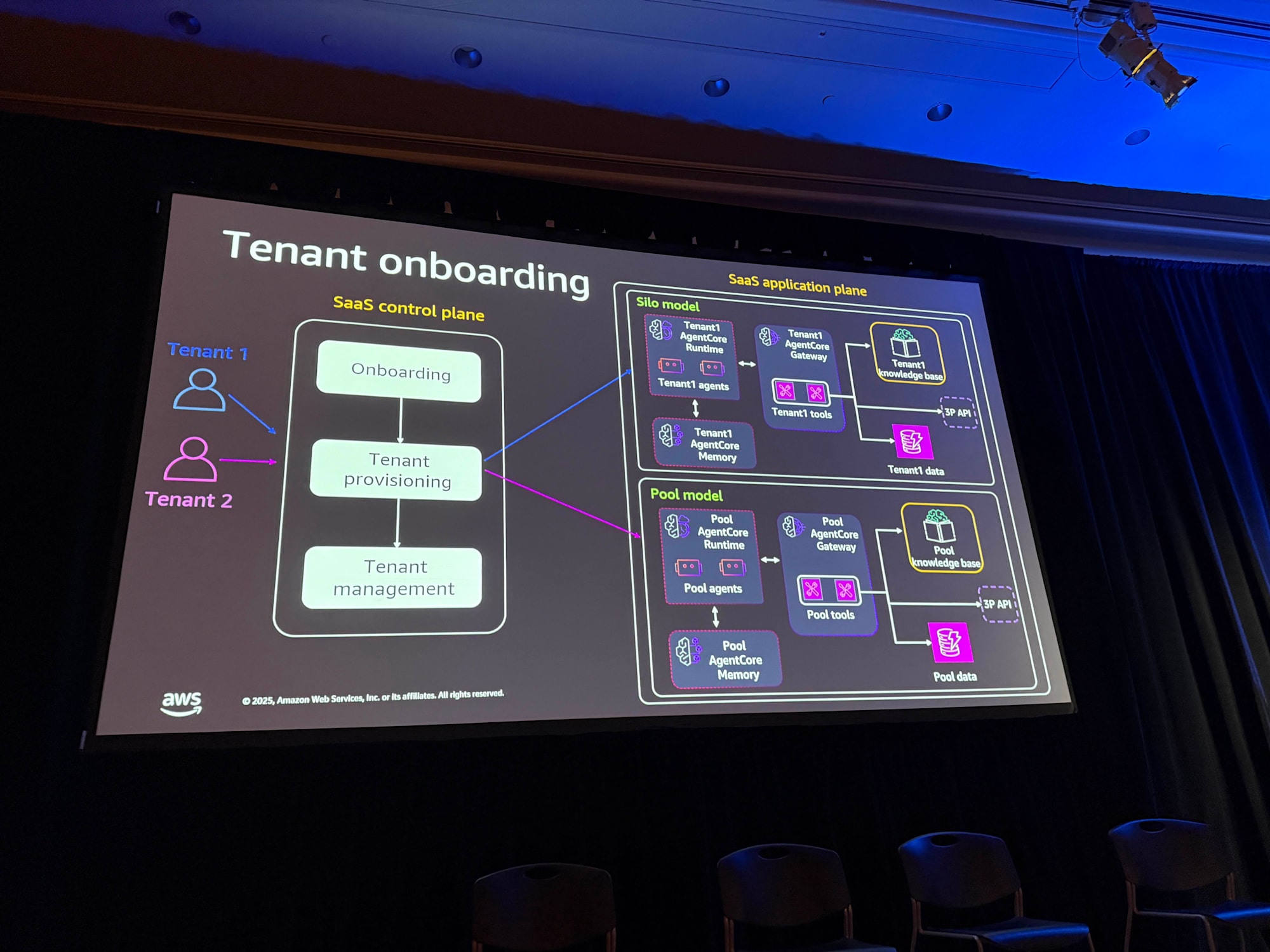
SaaSのベストプラクティスとして、コントロールプレーンを構築することが推奨されています。コントロールプレーンには、オンボーディングサービス、テナントプロビジョニングサービス、テナント管理サービスなどが含まれます。
テナントをオンボーディングする際、そのテナントがどのモデル(サイロまたはプール)にマッピングされるかに応じて、適切なインフラストラクチャがプロビジョニングされます。
サイロモデルの場合はテナントオンボーディング時に専用リソースをプロビジョニングし、プールモデルの場合は事前にプロビジョニングされた共有リソースに紐付けします。
SaaSアイデンティティとAgentCore Identity
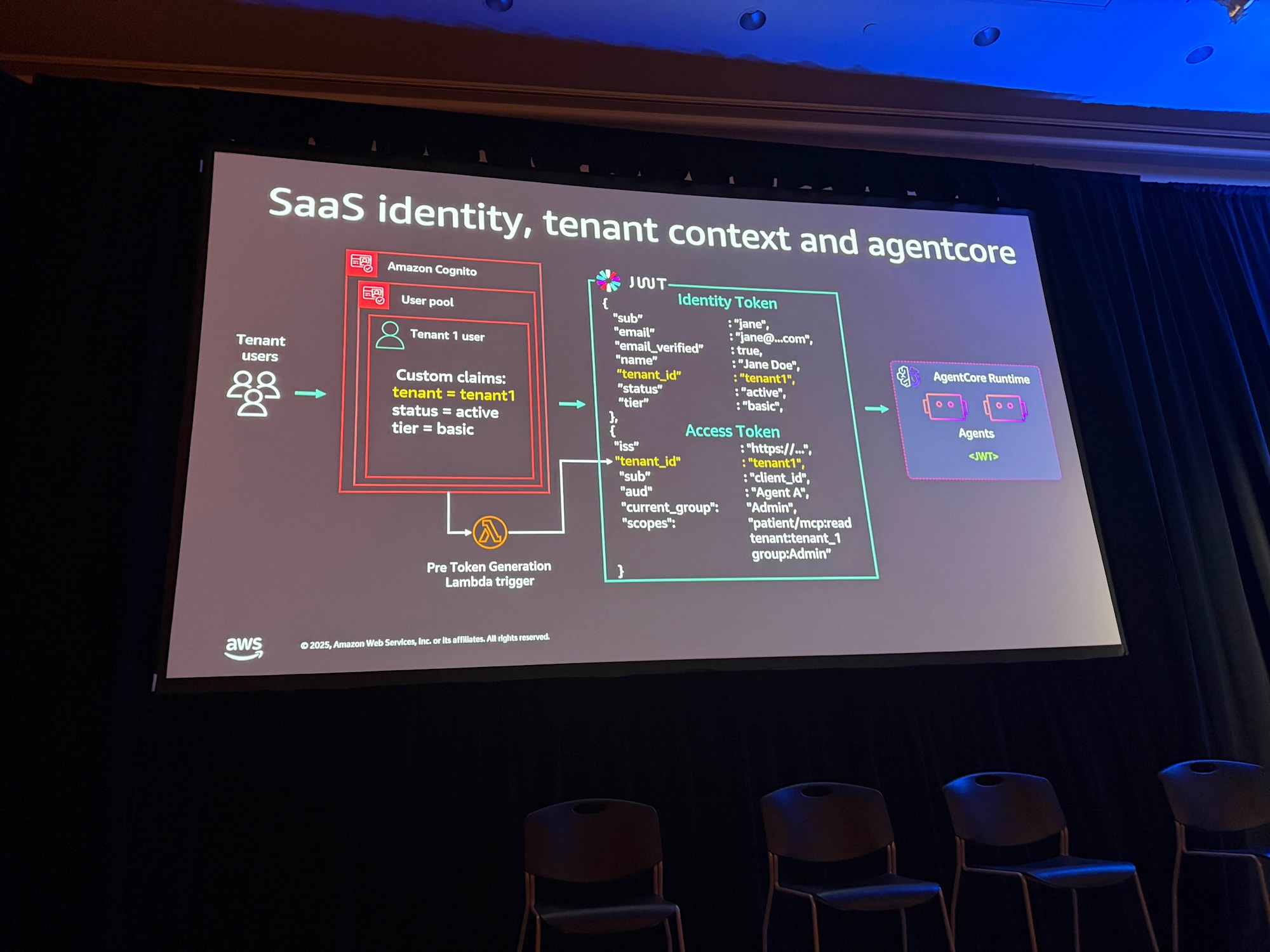
SaaSアイデンティティの管理には、Amazon Cognitoを使用する例が紹介されました。テナント境界として「User Pool per Tenant」、つまりテナントごとにCognitoのユーザープールを分ける方式を採用し、テナントAのユーザーはプールA、テナントBのユーザーはプールBというように明確に分離します。
ユーザーには以下のようなカスタム属性(JWTトークン内ではカスタムクレーム)を設定できます。
- Tenant ID
- Status
- Tier
JWTトークンにはIdentity TokenとAccess Tokenの2種類があります。Identity Tokenは自動的にカスタムクレームを継承しますが、Access Tokenは継承しません。AgentCore内ではAccess Tokenが使用されるため、pre-token generation Lambdaトリガーを使用してカスタムクレームをAccess Tokenにコピーするやり方が有効です。
ここにLambdaを挟むのはそうなんだと、改めて自分の勉強にもなりました。Access Tokenにカスタムクレームが継承されない点は注意したいですね。
インバウンド認証
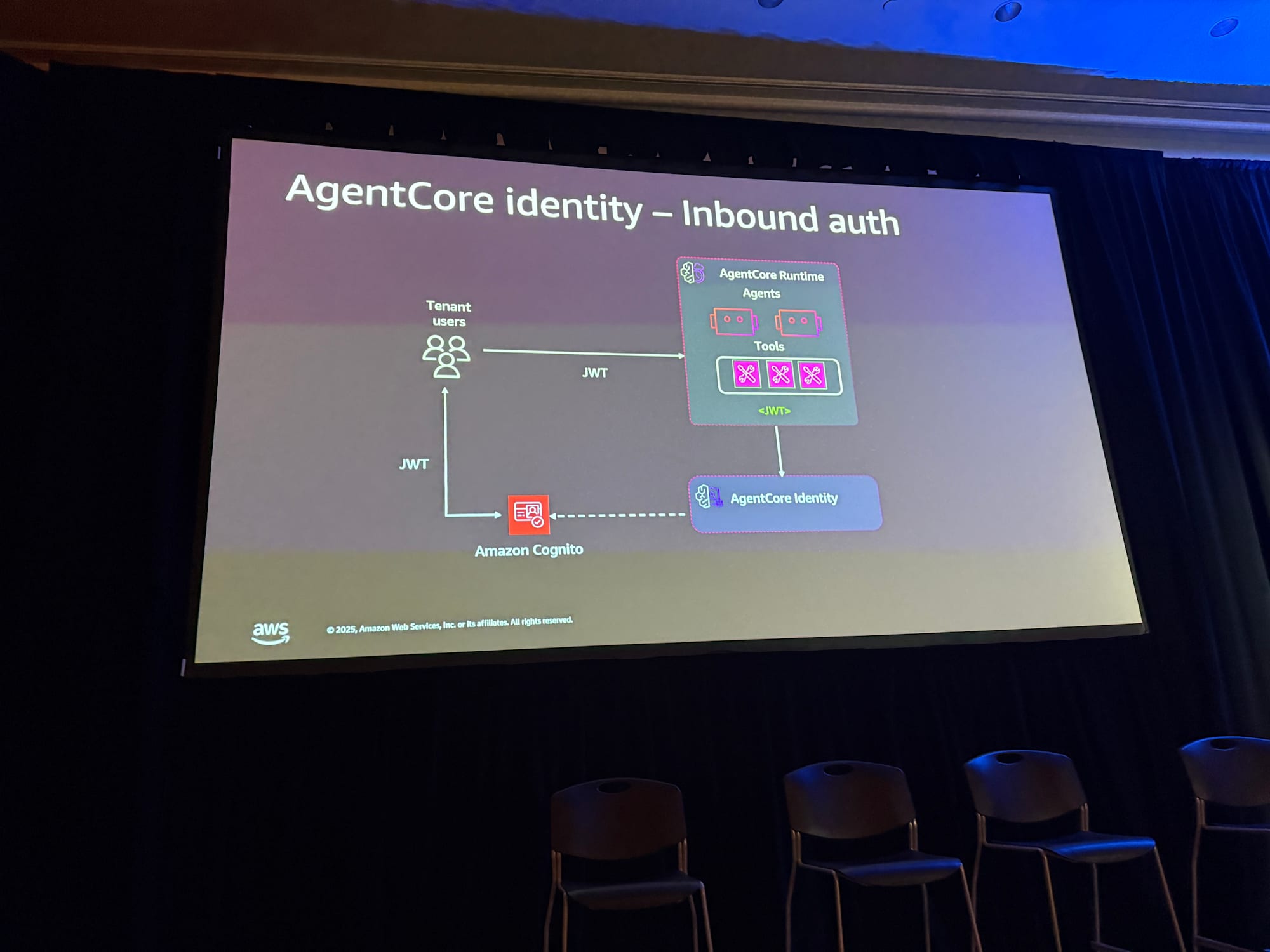
インバウンド認証は、ユーザーがエージェントを呼び出す際の認証です。
AgentCore Runtimeに対してIdP(ディスカバリーURL)を設定しておけば、あとは認証を行ってくれるため、開発者は認証ロジックを自前で実装する必要がないのは嬉しいですよね。
アウトバウンド認証
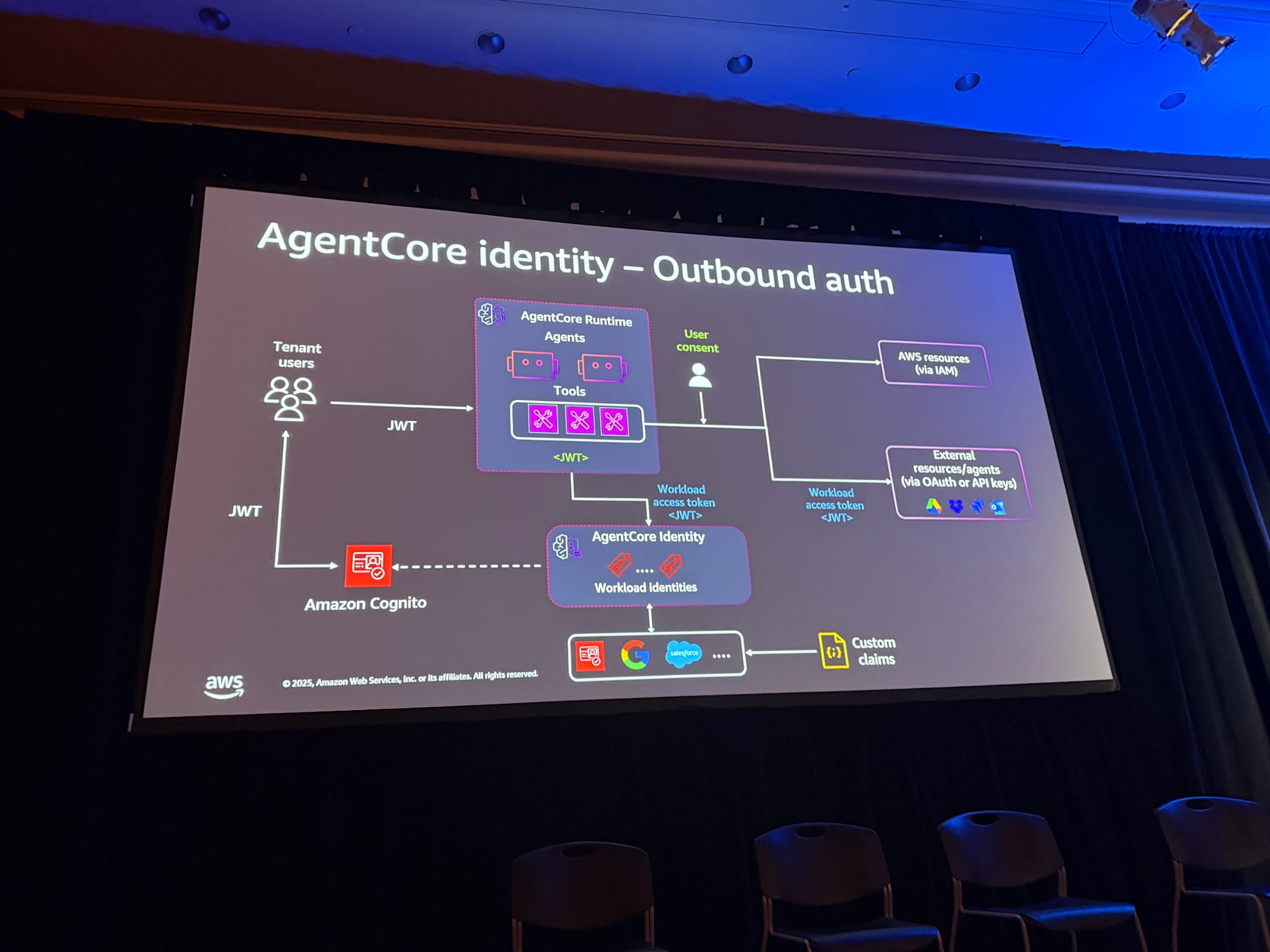
エージェントが外部リソースにアクセスする際の認証には、以下のパターンがあります。
AWSリソースへのアクセス
IAM実行ロールをAgentCore Runtimeにアタッチすることで認可します。
LambdaやECSなどと同じですね。
外部リソース(OAuth/APIキー)へのアクセス
各エージェントにOutbound Authを使ってAPIキーや、OAuthなどの権限を取得し、外部リソースへアクセス可能です。
外部リソースへのアクセストークンを取得する場合は、コード上で@requires_access_tokenアノテーションを使用するだけで、動的にアクセストークンを取得することが可能な便利な機能もあります。
AgentCore Gatewayの認証
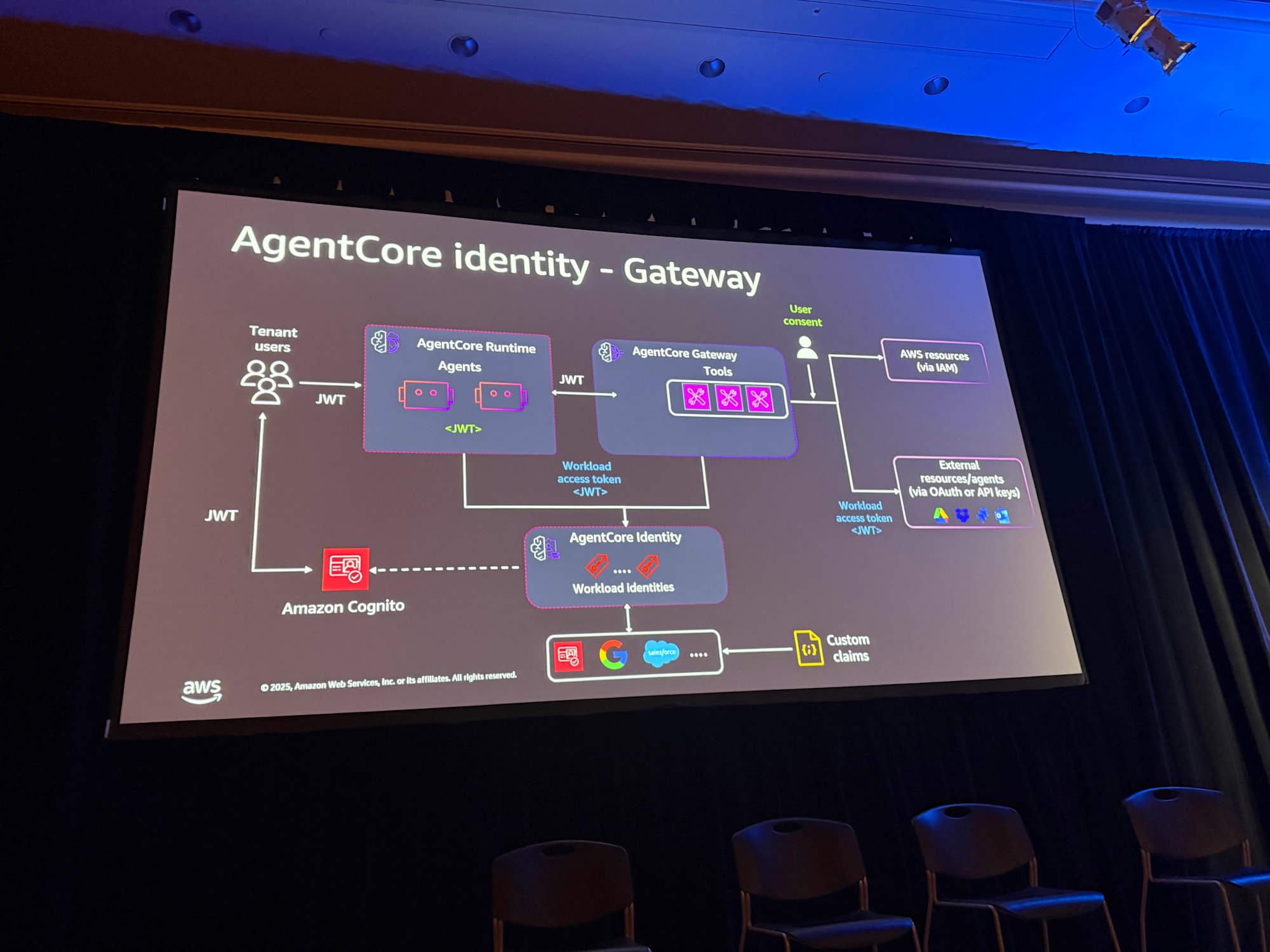
AgentCore Gatewayの認証についても説明がありました。AgentCore Identityで説明した設計方針は、Gatewayにも同様に適用できます。
- AgentCore RuntimeのエージェントがJWTトークンを使ってAgentCore Gatewayを呼び出す
- AgentCore GatewayにAgentCore Identityを設定して、リクエストを認証
また、AgentCore GatewayにはGateway Interceptorという新機能があり、Gatewayへのリクエストをインターセプトしてヘッダー情報を取得できます。JWTトークンを取得してツールで利用可能にしたり、テナントコンテキストを抽出して活用することが可能です。
具体的には下記機能になります。私も検証して紹介したいと思います。
データパーティショニング
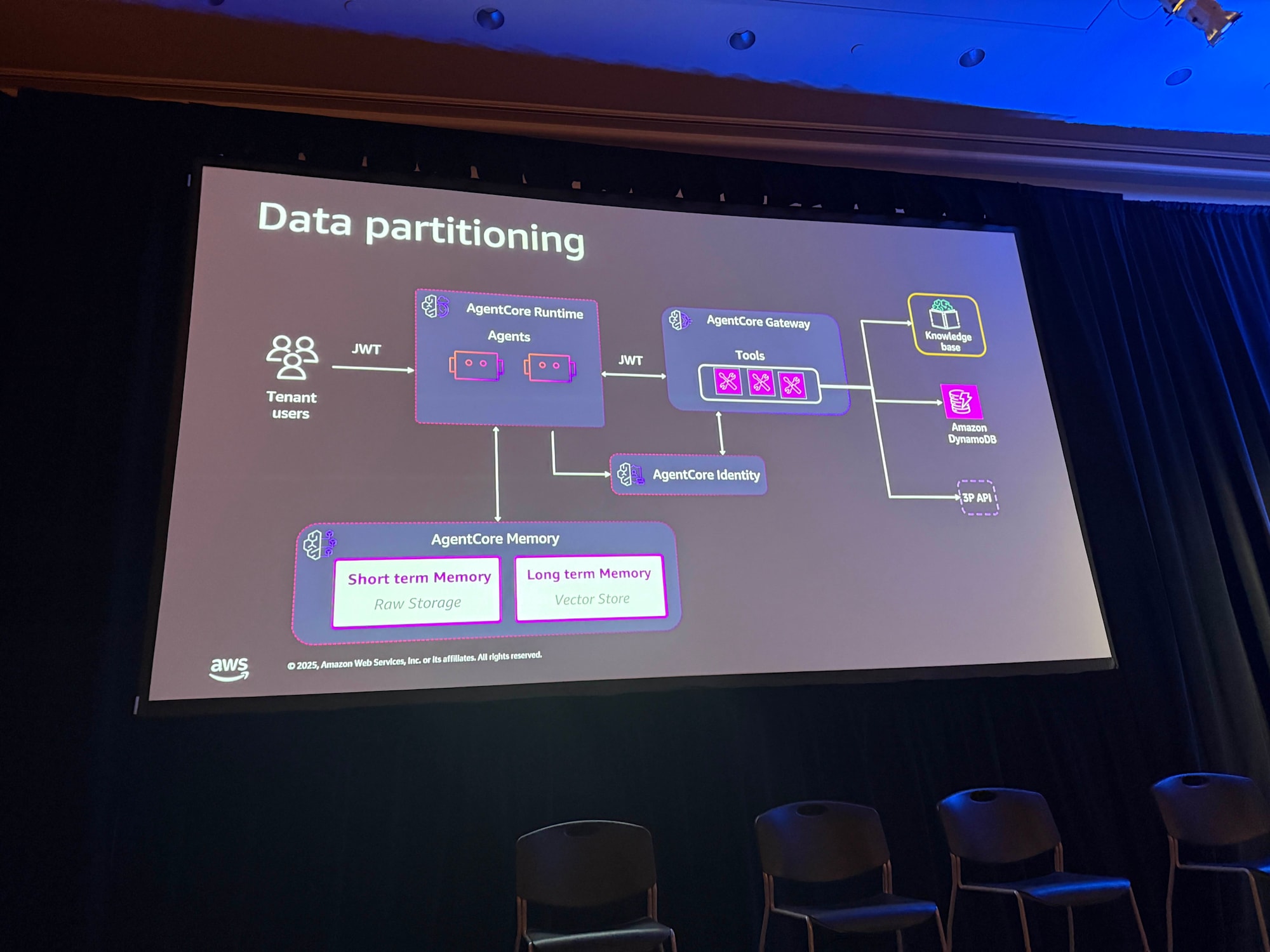
AgentCore MemoryやAWSリソースなどに対してどうデータアクセスを分離するかを説明されていました。
AgentCore Memory
セッションでは、サイロモデルとプールモデルそれぞれでのAgentCore Memoryのパーティショニング方法が説明されていました。
サイロモデルの場合

サイロモデルでは、テナントごとに専用のAgentCore Memoryを作成します。
短期記憶にイベントを作成する際には以下が必要です。
- Memory ID: AgentCore Memory作成時に生成される一意のID
- Session ID: セッションごとの一意のID
- Actor ID: ユーザーの一意のキー
Actor IDの規約として Tenant ID : Subject という形式が紹介されていました。
ただし、スピーカーからは「もしテナント単位でパーティショニングしたいだけなら、Actor IDはTenant IDだけでも良い。しかしその場合、サイロモデルではすでにテナントごとに専用のMemoryを作成しているため、この規約はあまり役に立たない。この規約はプールモデルに移行したときに役立つ」との説明がありました。
確かに図を見た時はサイロモデルならメモリー毎分離されるからactor_idにテナントID含めなくていいのではと思ったので、なるほどと納得しました。
プールモデルの場合
プールモデルでは、複数テナントで共有するAgentCore Memoryを使用します。この場合、Actor IDによるパーティショニングが重要になります。
Actor ID = Tenant ID : Subject
共有Memoryの中でテナントユーザーごとにデータを分離するため、この規則が活きてきます。
長期記憶
長期記憶はNamespaceを使用してデータをパーティショニングします。こちらもActor IDを活用します。
Namespace = {actor_id}/...
感想ですがプールモデルでMemoryを共有するべきなのかそもそも悩ましいなと私は感じました。設計を間違えると他者の記憶にアクセスできたり、別テナントの長期記憶が抽出できたりと難しいところもあるので、テナント毎にメモリーを分割したい気持ちになります。もちろん、要件にもよりますし前提として権限分離の設定も慎重になる必要があると思います。
AWSリソース
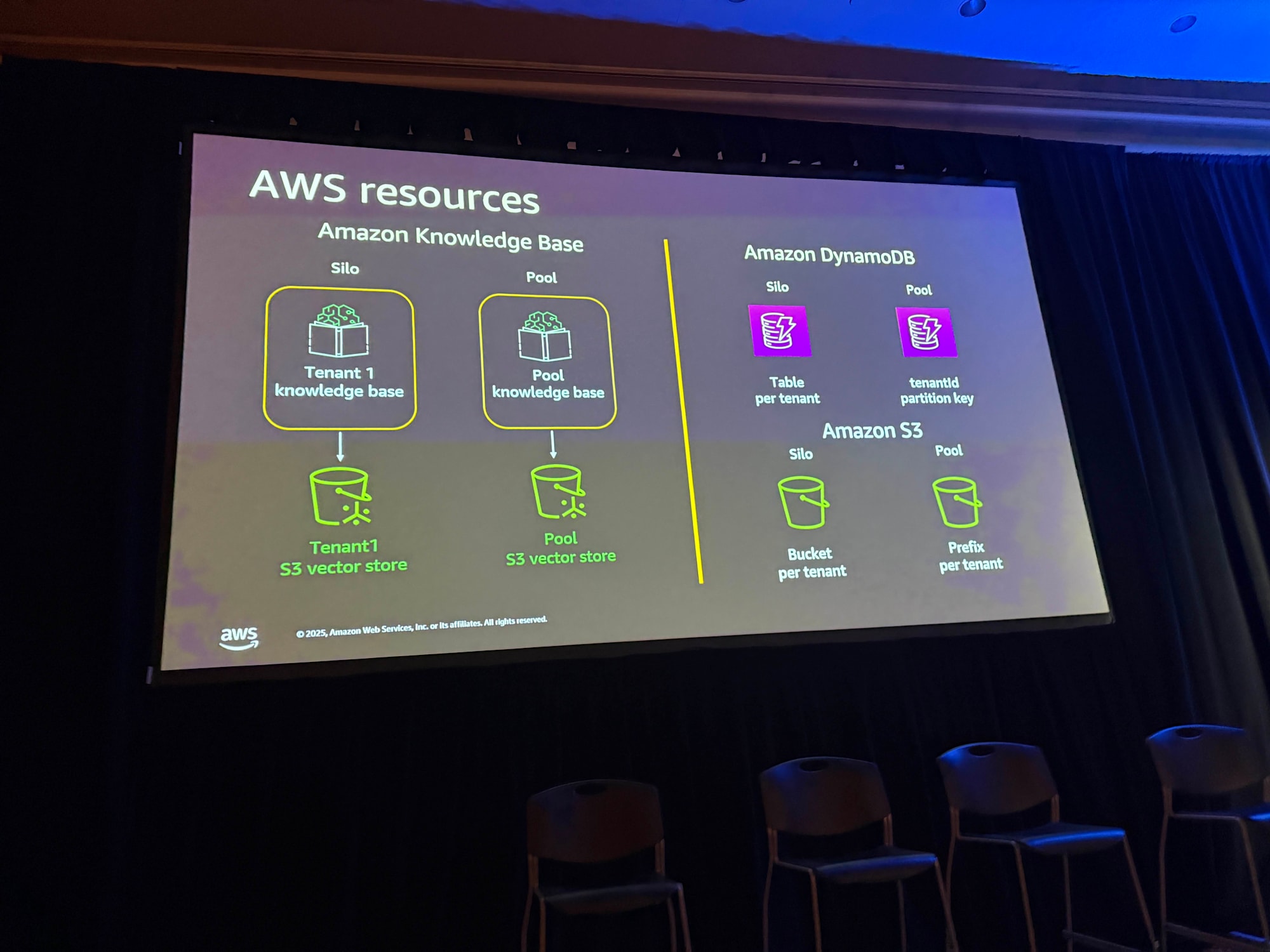
Amazon Bedrock Knowledge Base
サイロモデルでは、テナントごとに専用のKnowledge Baseとベクターデータベースを作成します。プールモデルでは、共有のKnowledge Baseにテナント固有のデータを取り込む際に、Tenant IDをメタデータとして付与します。
Amazon DynamoDB
サイロモデルではテナントごとにテーブルを作成します。プールモデルでは単一テーブルを共有し、Tenant IDをパーティションキーとして使用します。
Amazon S3
サイロモデルではテナントごとにバケットを作成します。プールモデルでは単一バケット内でテナントIDをプレフィックスとして使用します。
ここもやり方は納得したのですが、無理に共有のKnowledge Base、S3、DynamoDBを使わずと顧客毎にリソースを分割するようなブリッジモデルもいいのかなと感想までに思った次第です。
テナント分離
データをパーティショニングするだけでは不十分です。テナントが自分のリソースにのみアクセスできることを保証する必要があります。
サイロモデル
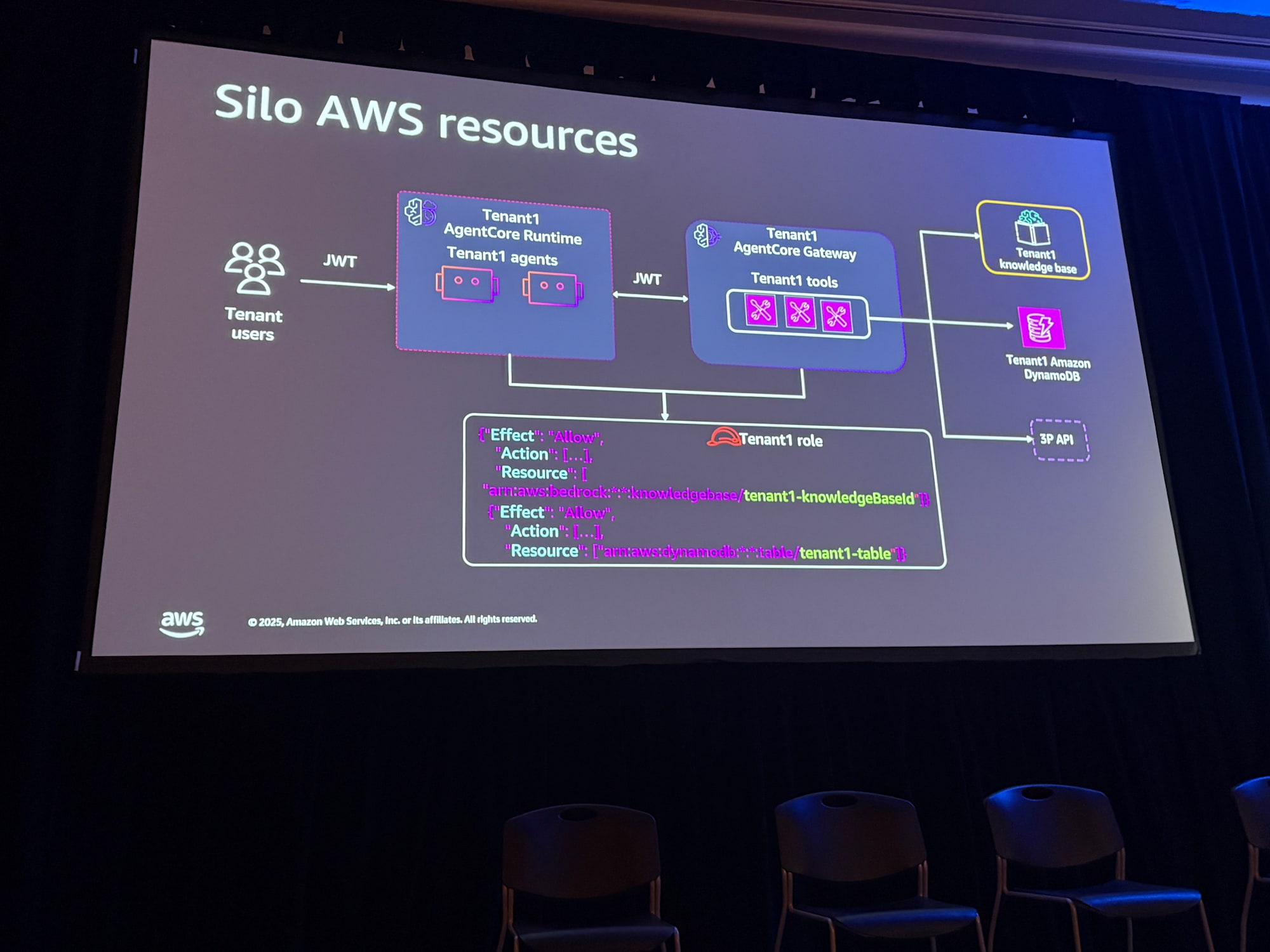
専用リソースの場合、IAM実行ロールをAgentCore Runtimeにアタッチし、テナント固有のリソースへのアクセスのみを許可します。
プールモデル
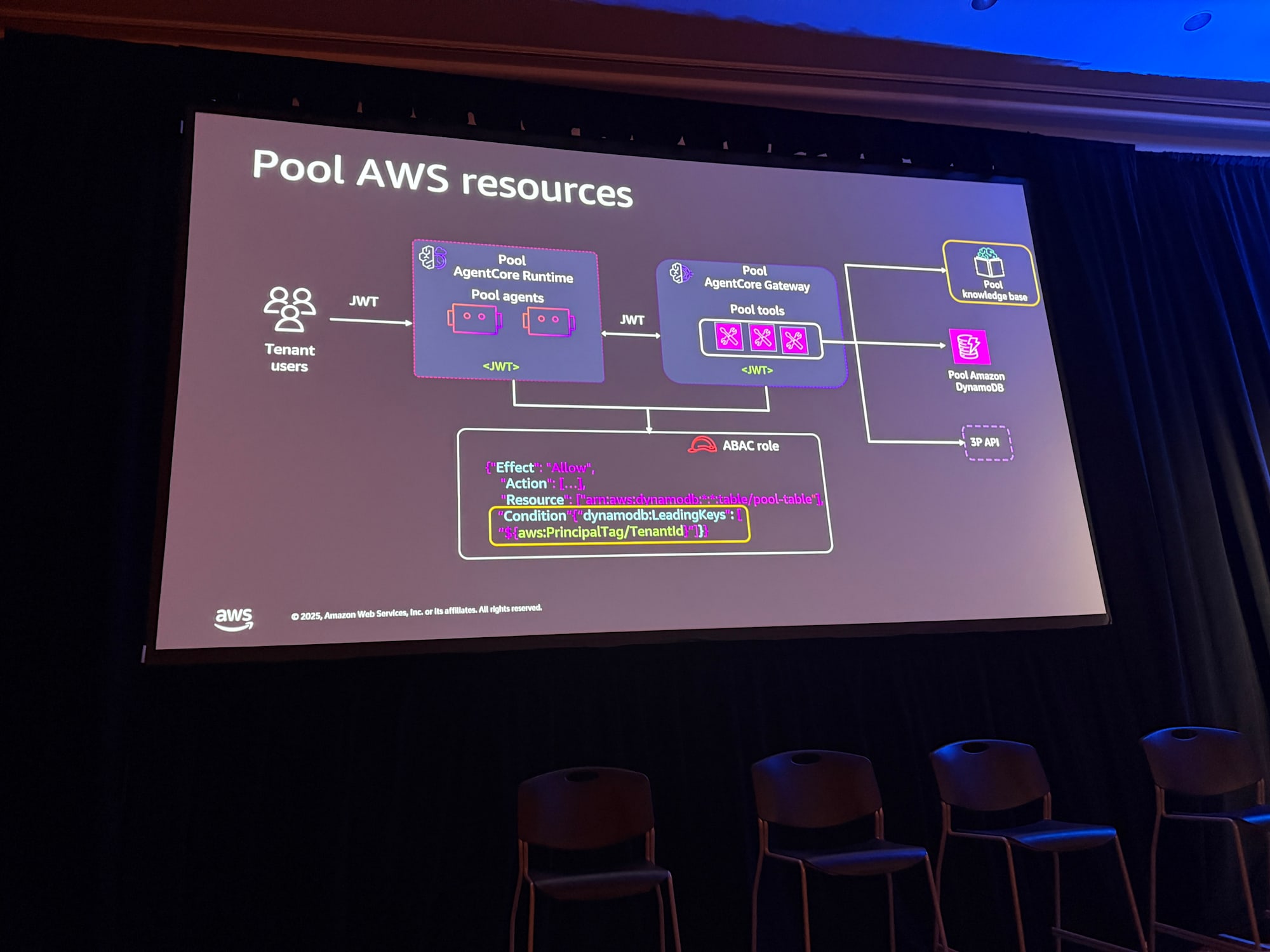
共有リソースの場合、ABAC(Attribute Based Access Control)ロールを使用します。
IAMの権限分離イメージ
{
"Condition": {
"StringEquals": {
"dynamodb:LeadingKey": "${aws:PrincipalTag/TenantId}"
}
}
}
JWTトークンからテナントコンテキストを取得し、STS(Security Token Service)を使用してこのロールを引き受け、テナント固有のデータにのみアクセスできる権限を取得します。
オブザーバビリティ
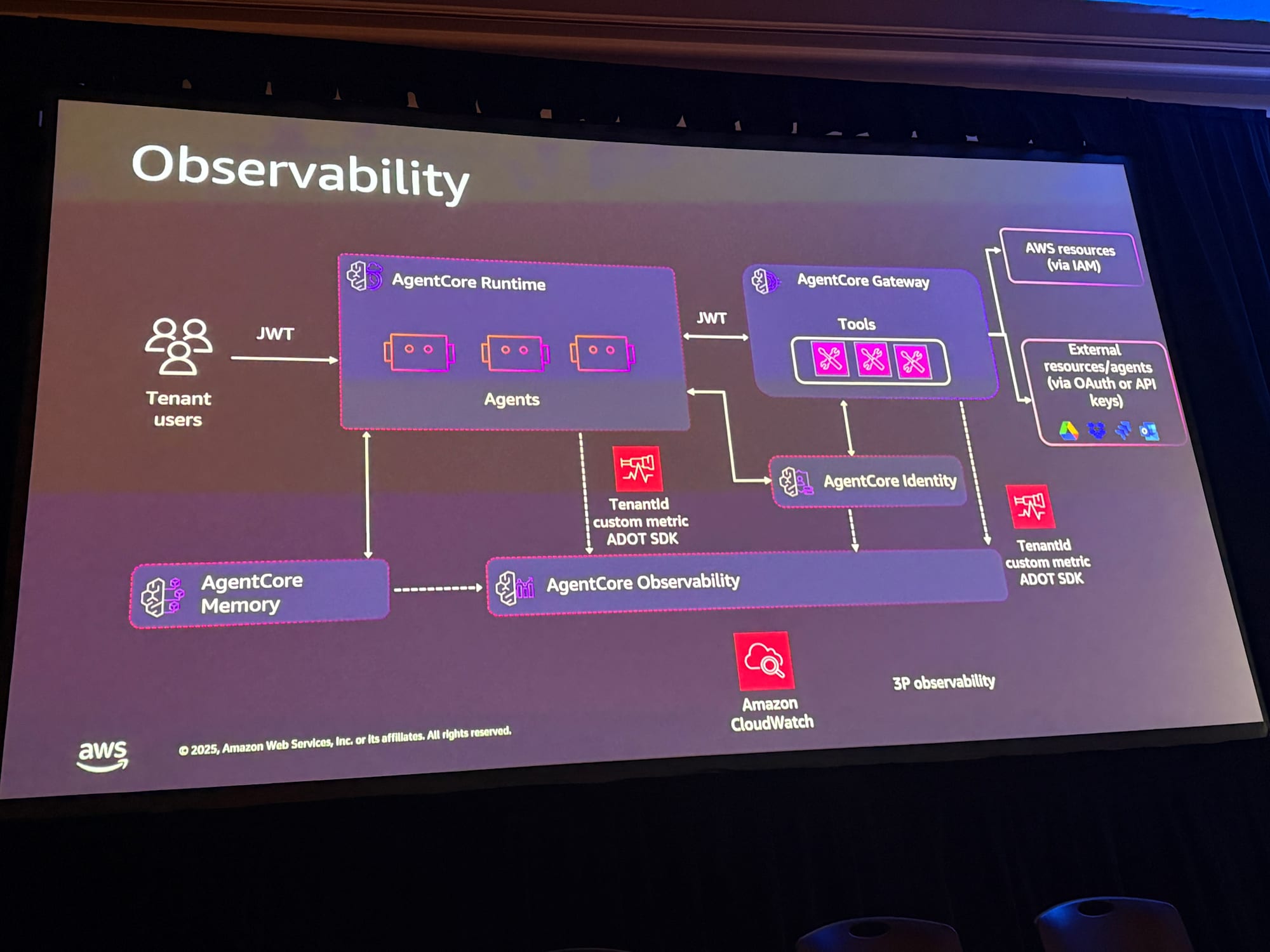
スピーカーはオブザーバビリティなしにSaaSの話はできないと強調していました。
Tenant IDは第一に優先される概念ではない
重要な点として、Tenant IDはCloudWatchやサードパーティのオブザーバビリティソリューションでファーストクラスの概念ではありません。すべてのソリューションがSaaSではないからです。
そのため、マルチテナントソリューションを構築する際は、SaaSに特化したカスタムメトリクスとカスタムダッシュボードを用意する必要があります。
個々のテナントの運用コストを把握
SaaSにおいて重要なのは、個々のテナントの運用コストを把握することです。特にAIエージェントのアプリケーションでは、推論コストが主要な費用となります。
入力・出力トークン数を計測する下記のようなカスタムメトリクスを実装します。

収集したログはCloudWatch Logs Insightsを使用して、テナント別のメトリクスを集計できます。
コスト可視化
収集したデータをDynamoDBに保存し、QuickSightなどのBIツールで可視化することで、以下のようなダッシュボードを作成可能とします。

- Cost per Tenant: テナントごとのコスト
- Feature Cost per Tier: ティアごとのコスト
これにより、ビジネスユーザーがテナントの運用コストを理解し、適切な価格設定を行うことができます。
補足:実際にどういった実装をするのか確認してみたい方へ
セッションで紹介された内容は、実際に動作するワークショップとしても提供されていります。GitHubでサンプルコードも公開されているので、どういった構成になっているのか確認してみると学びになるかもしれません。明日私も理解を深めるためにワークショップを受けてみたいと思いました。
まとめ
本セッションでは、Amazon Bedrock AgentCoreを使用してマルチテナントSaaSエージェントを構築するための包括的なパターンをレクチャーいただきました。
SaaSの課題から具体的にAgentCoreの実装にどう落とし込むのかといった箇所は改めて自分の理解の整理や、この辺りを気をつけないといけないんだなと観点の整理にも役立ったように感じました!
本記事が少しでも参考になれば幸いです。最後までご覧いただきありがとうございましたー!!











