
Amazon Bedrock Knowledge Basesで同期したメタデータがAmazon OpenSearch Serviceにどう格納されるか確認してみた
はじめに
こんにちは、スーパーマーケットが大好きなコンサルティング部の神野です。
Bedrock Knowledge Basesでメタデータファイル(.metadata.json)を設定した際に、Amazon OpenSearch Serviceへメタデータも同期されますよね。
このメタデータを活用して、通常はRetriveやRetriveAndGenerateコマンドでメタデータフィルタリングを行いますが、以下のようなケースではOpenSearchに直接クエリを発行したいことがあります。少なくとも私はありました・・・!
- Bedrockへのリクエスト前に、独自ロジックでメタデータによる絞り込みを行って、後続で独自の処理を行いたい
- ドキュメントの集計やグルーピングなど、対応していない処理を行いたい
こういったケースの際に.metadata.jsonで定義した情報が、Knowledge BasesでOpenSearchに同期した場合、フィールドにどう表現されているのかわからないとOpenSearchのクエリをどう書いたらいいかわからないですよね。
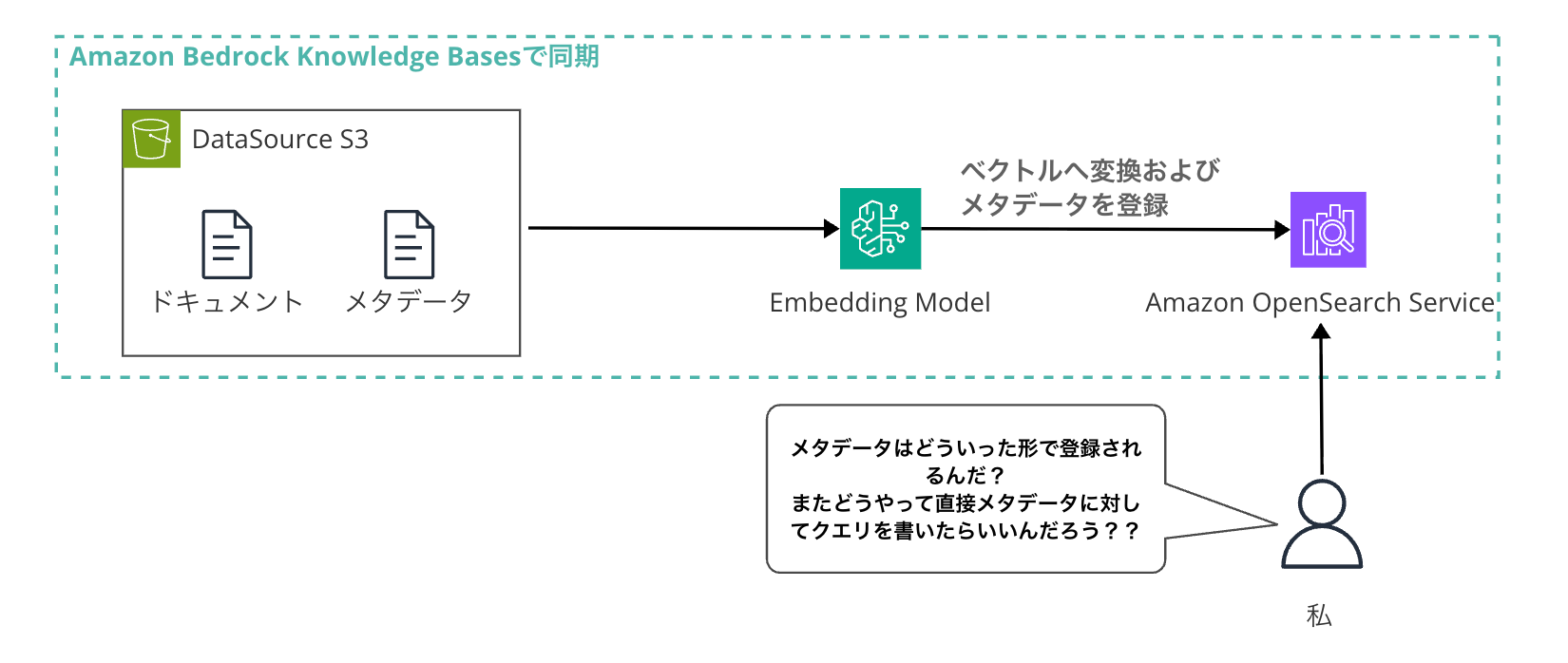
なので、今回は確認して実際に設定したメタデータに対してクエリを実行して挙動を確認することにしました。
今回やること
S3に配置したメタデータがOpenSearchにどう同期されるかを確認し、
OpenSearchのダッシュボードでDev Toolsから直接クエリを発行して挙動を確認してみます。
環境
- Amazon Bedrock Knowledge Bases(OpenSearch Serverlessをベクトルストアとして使用)
- AWS CDKで構築
CDKのサンプルコードは以下に配置しています。
CDKで作成されるリソース
今回のCDKスタックでは@cdklabs/generative-ai-cdk-constructsを使用して以下のリソースを作成しています。
| リソース | 説明 |
|---|---|
| S3バケット | ドキュメント格納用。サンプルドキュメントも自動でデプロイされます |
| Bedrock Knowledge Bases | OpenSearch Serverlessをベクトルストアとして自動作成 |
| S3データソース | Knowledge BaseとS3バケットを紐付け |
| OpenSearch Serverless Collection | Knowledge Base作成時に自動で構築されるベクトルストア |
Knowledge Baseの主な設定値は以下のとおりです。
| 設定項目 | 値 |
|---|---|
| Embedding Model | Amazon Titan Text Embeddings V2(1024次元) |
| Vector Store | OpenSearch Serverless |
| Chunking Strategy | Fixed Size |
| Max Tokens | 500 |
| Overlap Percentage | 20% |
generative-ai-cdk-constructsのVectorKnowledgeBaseを使って、OpenSearch Serverlessのコレクションやインデックス、データアクセスポリシーなどを作成します。
サンプルドキュメント
検証用に3種類のドキュメントとメタデータファイルを用意しています。
| ファイル | document_type | department | is_public | 備考 |
|---|---|---|---|---|
| annual-report-2024.txt | report | finance | false | 年次報告書。year属性あり |
| tech-blog-aws-bedrock.txt | blog | engineering | true | 技術ブログ。tags属性(STRING_LIST)あり |
| product-manual-v2.txt | manual | product | true | 製品マニュアル。version属性あり |
それぞれのドキュメントに異なるメタデータ属性を設定して、型ごとの挙動を確認できるようにしています。
またサンプルのドキュメントメタデータもCDKのデプロイを実施するとアップロードされます。
S3メタデータファイルの形式
Bedrock Knowledge Basesでメタデータを設定するには、対象ドキュメントと同じS3パスにファイル名.拡張子.metadata.jsonという名前でメタデータファイルを配置します。
例えばannual-report-2024.txtに対してはannual-report-2024.txt.metadata.jsonを同じ場所に置く形ですね。
今回使用したメタデータファイルの例に見てみます。
{
"metadataAttributes": {
"document_type": {
"value": { "type": "STRING", "stringValue": "report" }
},
"priority": {
"value": { "type": "NUMBER", "numberValue": 95 }
},
"is_public": {
"value": { "type": "BOOLEAN", "booleanValue": false }
},
"department": {
"value": { "type": "STRING", "stringValue": "finance" }
},
"year": {
"value": { "type": "NUMBER", "numberValue": 2024 }
},
"tags": {
"value": {
"type": "STRING_LIST",
"stringListValue": ["aws", "bedrock", "generative-ai"]
}
}
}
}
typeにはSTRING、NUMBER、BOOLEAN、STRING_LISTの4種類が指定可能です。
なお、メタデータには制約があります。属性名は最大50個まで、文字列は最大2048文字まで、STRING_LISTの要素数は最大10個までとなっています。
デプロイ手順
前提・使ったバージョン
- Node.js v24.10.0
インストール
git clone https://github.com/yuu551/sample-knowledge.git
cd sample-knowledge
pnpm install
パラメータ設定
lib/parameter.tsでOpenSearch Serverlessダッシュボードへのアクセス権限を設定します。
自分のIAMユーザーまたはロールのARNを追加してください。
export const parameter = {
/**
* OpenSearch Serverlessダッシュボードにアクセスを許可するIAMプリンシパル
*/
opensearchAccessPrincipals: [
'arn:aws:iam::123456789012:user/your-username',
// 'arn:aws:iam::123456789012:role/Admin',
] as string[],
// ... その他の設定
};
デプロイ
初回の場合はBootstrapが必要です。
deployコマンドを実行してデプロイを実施します。
# 初回のみ
cdk bootstrap
# デプロイ
cdk deploy
デプロイ完了後、以下の出力が表示されます。
Outputs:
SampleKnowledgeStack.KnowledgeBaseId = XXXXXXXXXX
SampleKnowledgeStack.DataSourceId = XXXXXXXXXX
SampleKnowledgeStack.DocumentBucketName = sampleknowledgestack-docbucket...
SampleKnowledgeStack.OpenSearchCollectionArn = arn:aws:aoss:...
これでインフラ環境一式は作成できました!Knowledge Bases の画面から同期を行います。
データの同期
デプロイ後、コンソールからデータソースの同期を実行してください。
実行することでデータがOpenSearchへベクトル化されてデータが保存されます。
- Bedrockコンソール → Knowledge bases → 作成されたKnowledge Baseを選択
- Data source → 同期(Sync)を実行
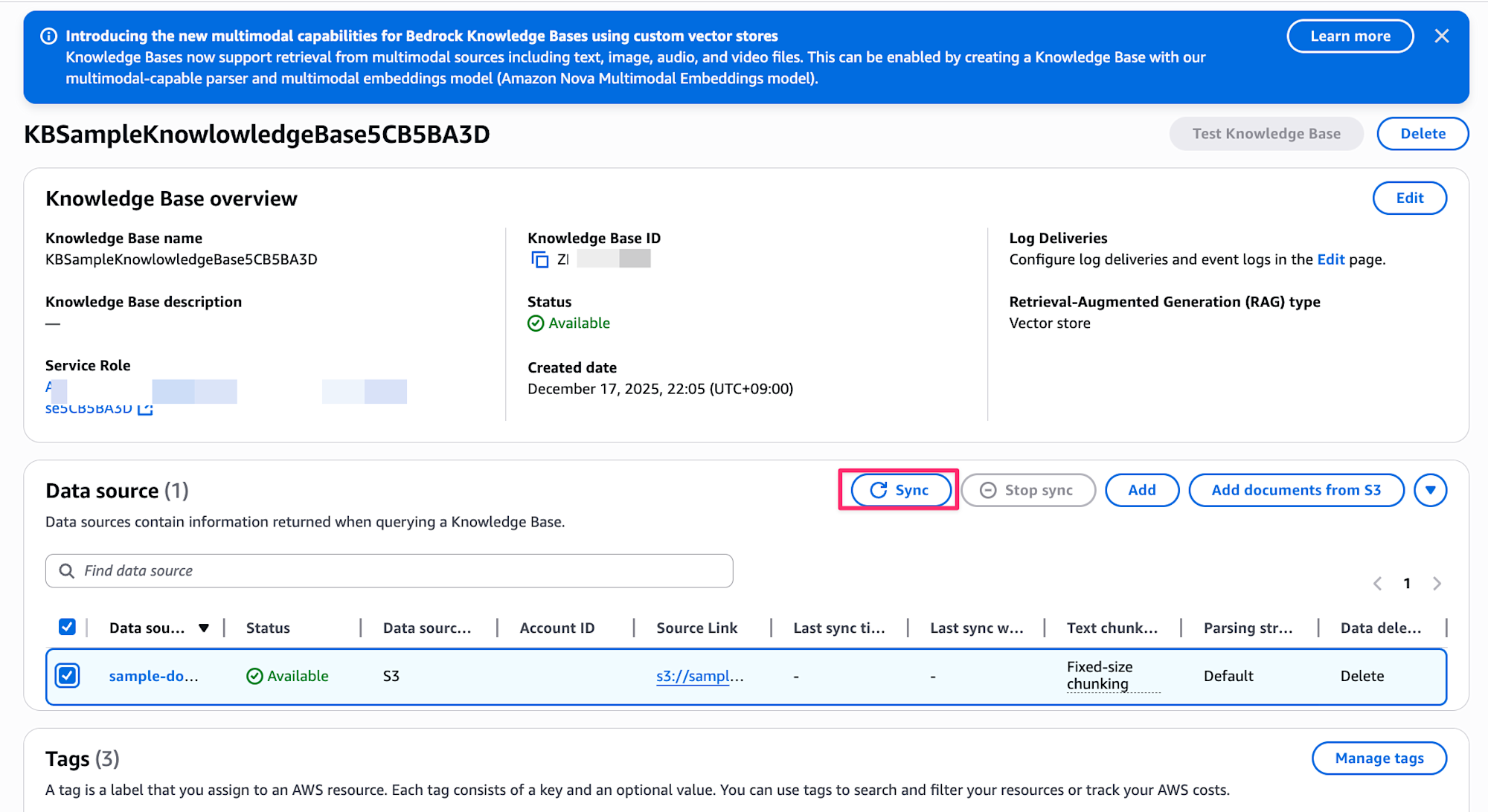
OpenSearchダッシュボードにアクセスする
データソースの同期が完了したら、OpenSearch Serverlessのダッシュボードからメタデータがどう格納されているか確認してみます。
AWSコンソールでOpenSearch Serviceを開き、左メニューから Serverless > Collectionsを選択します。CDKで作成したコレクションがあるので、それを選択してDashBoardをクリックします。

ダッシュボードにアクセスできたら、左メニューからDev Toolsを開きます。
ここでOpenSearchに対して直接クエリを発行できます。
左側のエディタにクエリを入力して、再生ボタンを押すと右側に結果が表示されます。
ダッシュボードにアクセスできない場合は、データアクセスポリシーに自分のIAMロールが追加されているか確認してください。
今回のCDKではparameter.tsで指定したロールに対してアクセス権限を付与しています。
OpenSearchへの格納形式を確認
それでは実際にメタデータがどのような形式でOpenSearchに格納されているか見ていきましょう。
マッピングを確認する
まずはインデックスのマッピングを確認します。Dev Toolsで以下のクエリを実行してどういったマッピングでデータが登録されるのかを確認してみます!
GET /bedrock-knowledge-base-default-index/_mapping
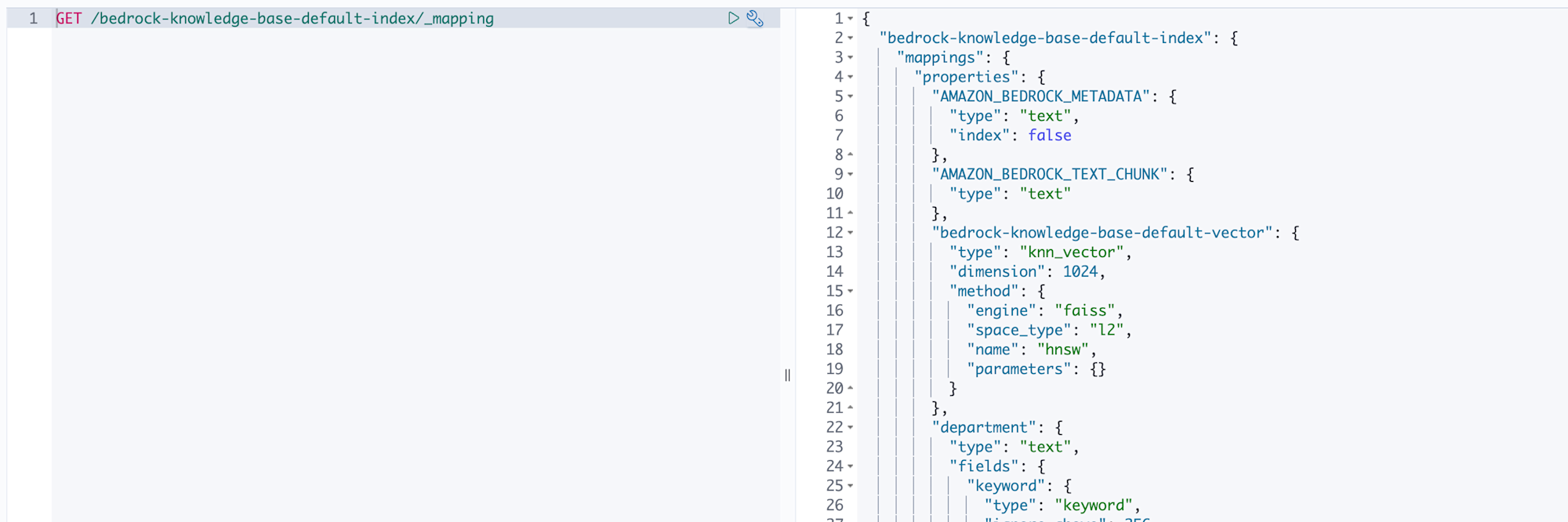
結果を見ると、Bedrockが自動で作成するフィールドに加えて、メタデータで定義した属性がフィールドとして追加されていることがわかります。
{
"bedrock-knowledge-base-default-index": {
"mappings": {
"properties": {
"AMAZON_BEDROCK_METADATA": {
"type": "text",
"index": false
},
"AMAZON_BEDROCK_TEXT_CHUNK": {
"type": "text"
},
"bedrock-knowledge-base-default-vector": {
"type": "knn_vector",
"dimension": 1024,
"method": {
"engine": "faiss",
"space_type": "l2",
"name": "hnsw",
"parameters": {}
}
},
"document_type": {
"type": "text",
"fields": {
"keyword": { "type": "keyword", "ignore_above": 256 }
}
},
"department": {
"type": "text",
"fields": {
"keyword": { "type": "keyword", "ignore_above": 256 }
}
},
"priority": { "type": "float" },
"is_public": { "type": "boolean" },
"year": { "type": "float" },
"tags": {
"type": "text",
"fields": {
"keyword": { "type": "keyword", "ignore_above": 256 }
}
}
}
}
}
}
なるほどこんな形で登録されるんですね。
AMAZON_BEDROCK_TEXT_CHUNKがチャンク分割されたドキュメント本文、bedrock-knowledge-base-default-vectorがそのベクトル表現です。そしてdocument_typeやpriorityといった、メタデータで定義した属性が個別のフィールドとして展開されています。
Bedrockがデータソースの同期時に.metadata.jsonを読み取って、自動でフィールドを作成してくれる仕組みになっていることがこれでわかりますね。
実データを確認する
次に実際のドキュメントがどう格納されているか見てみます。
GET /bedrock-knowledge-base-default-index/_search
_sourceフィールドにメタデータが個別の属性として格納されていることが確認できます。
{
"_source": {
"document_type": "report",
"department": "finance",
"priority": 95,
"is_public": false,
"year": 2024,
"AMAZON_BEDROCK_TEXT_CHUNK": "ドキュメント本文...",
"bedrock-knowledge-base-default-vector": [...],
"tags": ["aws", "bedrock", "generative-ai", "rag"]
}
}
メタデータの値がそのままフィールド値として入っていました!
通常のOpenSearchクエリでフィルタリングや集計ができますね。
型のマッピングについて
メタデータの型がOpenSearchでどのようにマッピングされるか整理しておきます。
| メタデータの型 | OpenSearchのマッピング |
|---|---|
| STRING | text型(keywordサブフィールド付き) |
| NUMBER | float型 |
| BOOLEAN | boolean型 |
| STRING_LIST | text型(keywordサブフィールド付き) |
ポイントは文字列系の型はtext型になるという点です。
OpenSearchのtext型は全文検索用にトークン分割されるため、完全一致で検索したい場合は.keywordサブフィールドを使う必要があります。例えばdocument_typeがreportのドキュメントを検索したい場合は、document_type.keywordに対してクエリを発行します。
また、date型への直接マッピングはサポートされていません。日付を扱いたい場合はNUMBER型でUNIXタイムスタンプやYYYYMMDD形式の数値として格納する形になります。今回のサンプルではyearを数値として定義しています。
Dev Toolsでクエリを試す
それでは実際にクエリを発行して、メタデータでフィルタリングできるか試してみます。
完全一致検索
まずはdocument_typeがreportで、かつis_publicがfalseのドキュメントを検索してみます。
GET /bedrock-knowledge-base-default-index/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "document_type.keyword": "report" } },
{ "term": { "is_public": false } }
]
}
}
}
ここで注意が必要なのが、文字列フィールドには.keywordを付ける必要があるという点です。先ほどのマッピングで見たとおり、文字列はtext型で格納されているため、完全一致で検索したい場合はkeywordサブフィールドを使います。これを忘れると意図した結果が返ってこないので気をつけたいですね。
実行結果を見ると、期待どおり年次報告書のドキュメントが1件ヒットしました。
{
"hits": {
"total": { "value": 1, "relation": "eq" },
"hits": [
{
"_source": {
"x-amz-bedrock-kb-source-uri": "s3://sampleknowledgestack-docbucket.../annual-report-2024.txt",
"year": 2024,
"is_public": false,
"priority": 95,
"department": "finance",
"AMAZON_BEDROCK_TEXT_CHUNK": "2024年度 年次報告書 概要 本報告書は、2024年度における当社の事業活動、財務状況、および今後の展望についてまとめたものです。...",
"document_type": "report"
}
}
]
}
}


数値フィールドでの絞り込み
次はyearフィールドで2024年のドキュメントを検索してみます。
GET /bedrock-knowledge-base-default-index/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "year": 2024 } }
]
}
}
}
数値フィールドの場合は.keywordは不要です。NUMBER型で定義したメタデータはfloat型としてマッピングされているので、そのまま数値で検索できます。
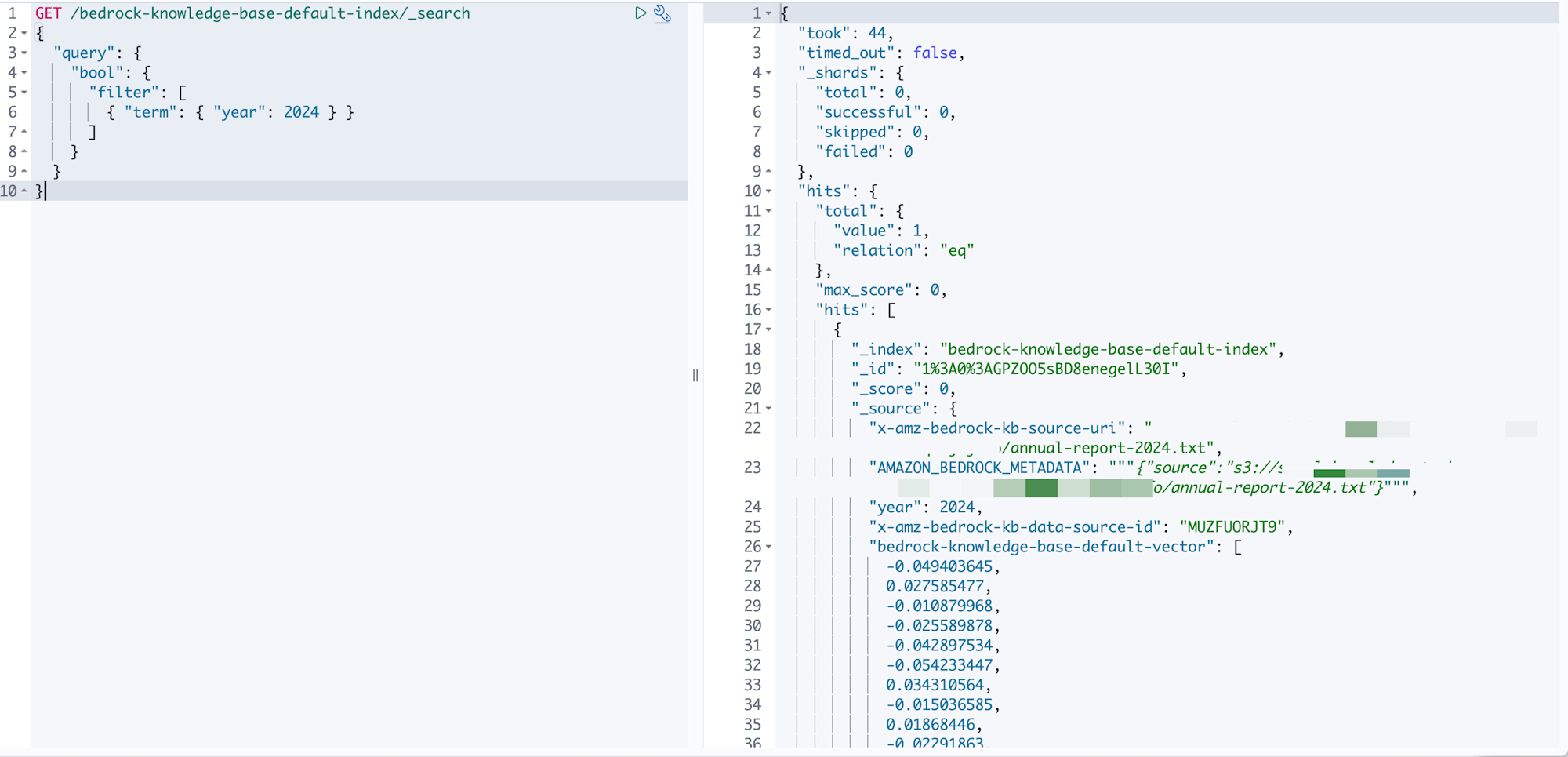

しっかりとメタデータが2024年度のデータが取得できましたね。
STRING_LISTの検索
tagsのようなSTRING_LIST型のフィールドも試してみましょう。departmentがengineeringで、tagsにawsを含むドキュメントを検索します。
GET /bedrock-knowledge-base-default-index/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "department.keyword": "engineering" } },
{ "term": { "tags.keyword": "aws" } }
]
}
}
}
STRING_LISTも内部的にはtext型の配列として格納されているので、完全一致検索には.keywordが必要です。
配列の中のいずれかの要素にマッチすればヒットするので、「awsタグを含むドキュメント」という検索が実施できます。
{
"hits": {
"total": { "value": 1, "relation": "eq" },
"hits": [
{
"_source": {
"x-amz-bedrock-kb-source-uri": "s3://sampleknowledgestack-docbucket.../tech-blog-aws-bedrock.txt",
"is_public": true,
"priority": 70,
"department": "engineering",
"AMAZON_BEDROCK_TEXT_CHUNK": "技術ブログ: Amazon Bedrockで始める生成AI はじめに Amazon Bedrockは、AWSが提供するフルマネージドの生成AIサービスです。...",
"document_type": "blog",
"tags": ["aws", "bedrock", "generative-ai", "rag"]
}
}
]
}
}
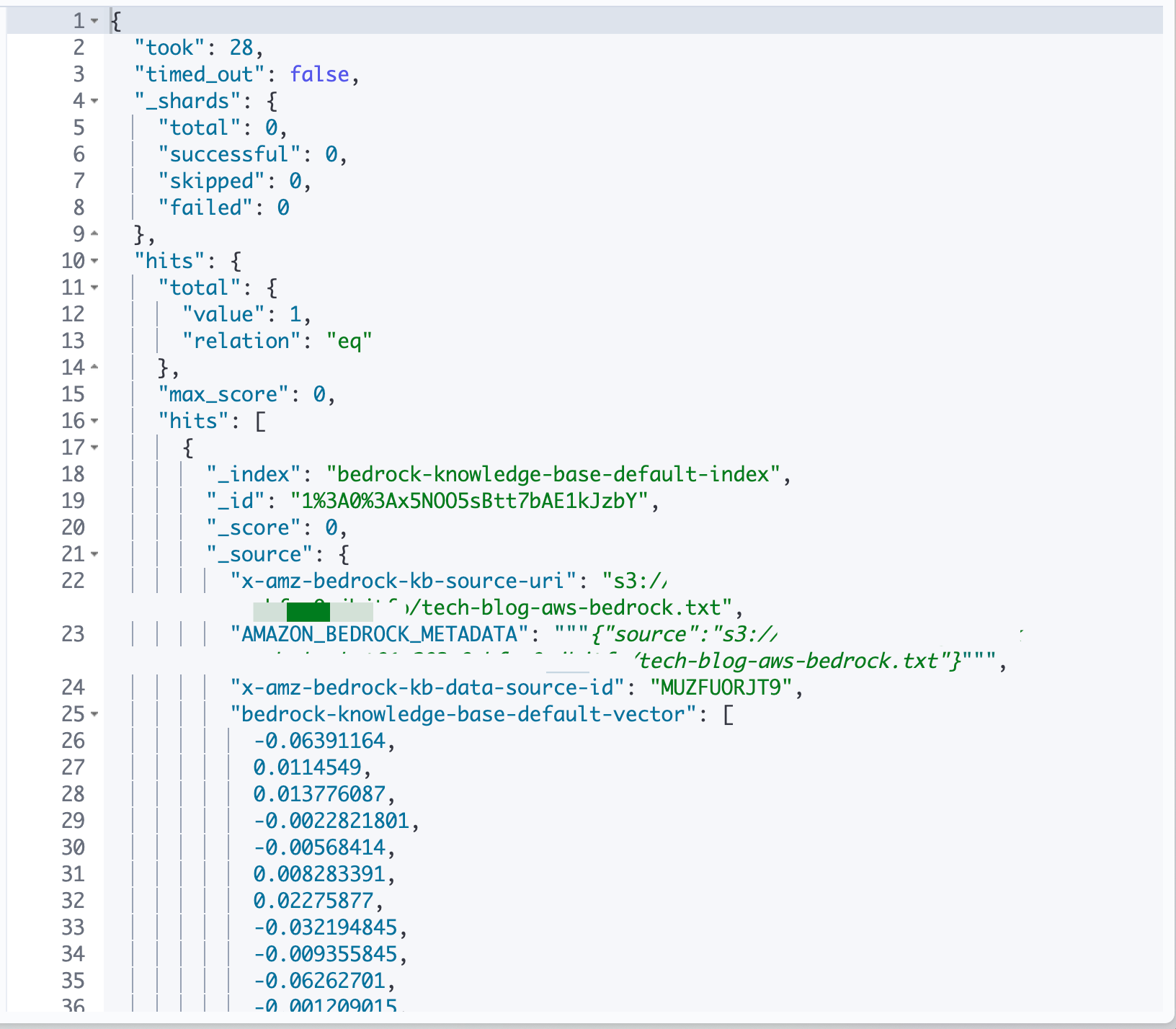

集計クエリ
OpenSearchは集計クエリも活用できます。
ドキュメントのグルーピングや統計情報の取得ができます。
GET /bedrock-knowledge-base-default-index/_search
{
"size": 0,
"aggs": {
"by_type": {
"terms": { "field": "document_type.keyword" }
},
"by_department": {
"terms": { "field": "department.keyword" }
},
"avg_priority": {
"avg": { "field": "priority" }
}
}
}
size: 0を指定すると検索結果のドキュメント自体は返さず、集計結果だけを取得できます。
ドキュメントの種類別・部署別の件数や、優先度の平均値といった情報を取得するのにも活用できますね。
下記のように取得できます。
{
"took": 80,
"timed_out": false,
"_shards": {
"total": 0,
"successful": 0,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"avg_priority": {
"value": 81.66666666666667
},
"by_department": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "engineering",
"doc_count": 1
},
{
"key": "finance",
"doc_count": 1
},
{
"key": "product",
"doc_count": 1
}
]
},
"by_type": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "blog",
"doc_count": 1
},
{
"key": "manual",
"doc_count": 1
},
{
"key": "report",
"doc_count": 1
}
]
}
}
}
おわりに
今回はBedrock Knowledge BasesのメタデータがOpenSearch Serverlessにどう格納されるかを確認してみました!
Knowledge Basesが.metadata.jsonの内容を読み取って、自動でOpenSearchのフィールドに展開してくれる仕組みになっています。文字列の完全一致検索には.keywordサブフィールドを使う必要があるのには注意したいですね。
OpenSearchに直接クエリを発行するケースなどではどういった構造でデータが格納されているか押さえておく必要があったので、勉強になりました!
本記事が少しでも参考になりましたら幸いです!最後までご覧いただきありがとうございましたー!!








