
Amazon Connectで通話終了直後に、即文字起こし内容を要約してコンタクト詳細に表示する方法
はじめに
Amazon Connect Contact Lensによる音声の文字起こしには、以下の2種類のタイプがあります。
- 通話後の分析
- 文字起こしの精度を最大限に高めるために推奨されます。
- リアルタイムの分析
- 通話中にリアルタイムで文字起こしが行われます。
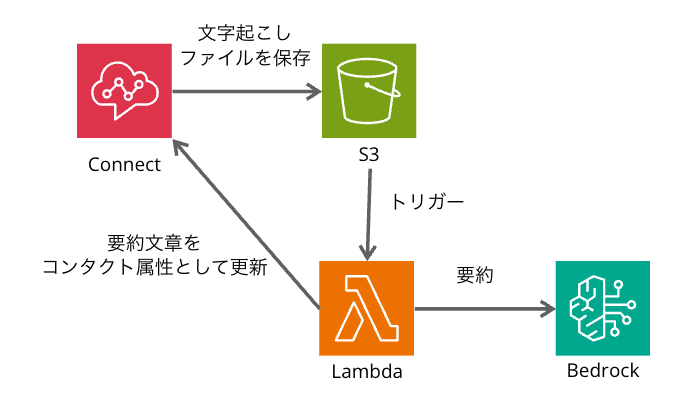
以前、「通話後の分析」を利用し、Amazon Connectでの会話内容を日本語で要約し、コンタクト詳細に表示する方法を紹介しました。
構成
しかし、この方法では要約が確認できるまでに5~10分程度かかるというデメリットがあります。これは、文字起こし内容がS3バケットにアップロードされるまでに時間がかかり、S3へのファイルアップロードをトリガーにLambda関数を実行して要約を生成するためです。
例えば、上記の記事では、2分程度会話した場合、S3バケットに保存されるまでに7分程度かかりました。
通話終了後、即座に要約内容をCRMに自動記載し、記載された内容を確認したい(一部を書き直したい場合もある)といったケースも多くあると思います。
そのため、今回は「リアルタイムの分析」を利用し、通話終了直後にコンタクト詳細へ要約を保存する方法を紹介します。
一部コードを修正すれば、コンタクト詳細に保存するだけでなく、CRMに保存する、といったことも可能です。
なお、「リアルタイムの分析」を利用するデメリットは、「通話後の分析」よりも文字起こし精度が低い点にありますので、十分な検証が必要です。
構成
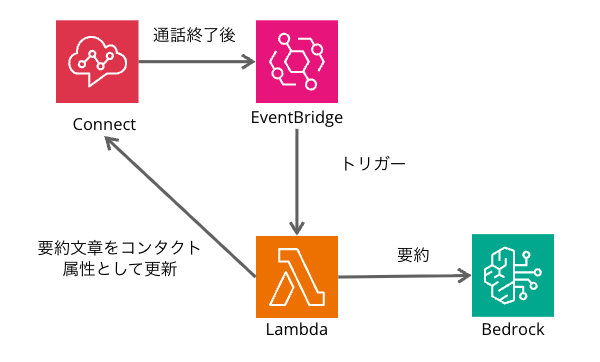
構成は以下の通りです。
構成は以下のとおりです。
- 通話終了後、EventBridgeルールが起動し、Lambda関数を実行
- Lambda関数が、EventBridgeルールから渡されたイベント情報をもとに、ListRealtimeContactAnalysisSegments APIでリアルタイム文字起こしを取得
- Lambda関数が、Bedrockで要約を生成
- Lambda関数が、connect:UpdateContactAttributes APIを使い、要約をコンタクト属性としてConnectに保存
Lambda
Lambda関数の設定内容は以下のとおりです。
- 名前:connect-realtime-summary
- ランタイム: Python 3.14
- タイムアウト:20秒
- メモリ:1024MB
- 要約をコンタクト属性に保存する処理速度を向上させるため、メモリを増やしています。効果の有無は文字起こしの量などによります。
- IAMロールに付与するポリシーは以下のとおりです(Connect インスタンスARNは環境に合わせて変更してください)。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "bedrock:InvokeModel",
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"connect:ListRealtimeContactAnalysisSegments",
"connect:UpdateContactAttributes"
],
"Resource": [
"arn:aws:connect:ap-northeast-1:111111111111:instance/3ff2093d-af96-43fd-b038-3c07cdd7609c",
"arn:aws:connect:ap-northeast-1:111111111111:instance/3ff2093d-af96-43fd-b038-3c07cdd7609c/contact/*"
]
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:*"
}
]
}
コードは以下です。
import boto3
import json
import time
# 定数定義
MODEL_ID = 'jp.anthropic.claude-sonnet-4-5-20250929-v1:0'
MAX_RESULTS = 100
SLEEP_SECONDS = 1
# AWSクライアント初期化
connect_lens = boto3.client('connect-contact-lens')
connect_client = boto3.client('connect')
bedrock_client = boto3.client('bedrock-runtime')
def validate_and_extract_ids(detail: dict) -> (str, str):
"""
event.detail から contactId と instanceId を検証して取得する。
instanceArn からインスタンスIDを抽出。
contactId または instanceArn がなければエラーを投げる。
"""
contact_id = detail.get('contactId')
instance_arn = detail.get('instanceArn')
if not contact_id:
raise ValueError("Missing contactId in event.detail")
if not instance_arn:
raise ValueError("Missing instanceArn in event.detail")
try:
instance_id = instance_arn.split(":")[-1].split("/")[-1]
except Exception:
raise ValueError(f"Invalid instanceArn format: {instance_arn}")
return contact_id, instance_id
def fetch_transcripts(instance_id: str, contact_id: str) -> list[dict]:
"""
Connect Lens を使ってすべてのリアルタイム文字起こしのセグメントを取得。
発言者と内容のリストを返す。
失敗時には例外を投げる。
"""
transcripts = []
next_token = None
while True:
params = {
'InstanceId': instance_id,
'ContactId': contact_id,
'MaxResults': MAX_RESULTS
}
if next_token:
params['NextToken'] = next_token
try:
resp = connect_lens.list_realtime_contact_analysis_segments(**params)
except Exception as e:
raise RuntimeError(f"Failed to list realtime segments: {e}")
segments = resp.get('Segments', [])
print(f"Fetched {len(segments)} segments")
for seg in segments:
t = seg.get('Transcript')
if t and 'Content' in t:
content = t['Content'].strip()
participant = t.get('ParticipantRole', 'UNKNOWN')
if content:
transcripts.append({'participant': participant, 'content': content})
next_token = resp.get('NextToken')
if not next_token:
break
time.sleep(SLEEP_SECONDS)
return transcripts
def create_summary_and_update(instance_id: str, contact_id: str, full_text: str) -> str:
"""
full_text をベースに要約を生成し、Connect の contact attributes に保存する。
成功時には要約文字列を返す。
"""
# 最小限スタイルのプロンプト
prompt = f"""
通話記録の要約をお願いします。
通話内容:
{full_text}
要約内容:
1. 顧客の問い合わせ内容
2. エージェントの対応内容
3. 結論(解決・今後の対応など)
制約:
- 通話内容に忠実であること
- 推測はしないこと
- 具体的な情報(日付、注文番号など)は明記すること
出力形式:
- 3~4 文
- 自然な文章
- 前置きなし、要約のみ
"""
try:
resp = bedrock_client.converse(
modelId=MODEL_ID,
messages=[{"role": "user", "content": [{"text": prompt}]}],
inferenceConfig={"maxTokens": 1000, "temperature": 0.1}
)
content_list = resp['output']['message']['content']
if not content_list or len(content_list) == 0:
raise RuntimeError("Bedrock response has no content")
summary = content_list[0].get('text', '').strip()
except Exception as e:
raise RuntimeError(f"Failed to generate summary: {e}")
try:
connect_client.update_contact_attributes(
InstanceId=instance_id,
InitialContactId=contact_id,
Attributes={'realtimesummary': summary}
)
except Exception as e:
raise RuntimeError(f"Failed to update contact attributes: {e}")
return summary
def lambda_handler(event, context):
print('Event Received: ' + json.dumps(event, ensure_ascii=False))
try:
detail = event.get('detail', {})
contact_id, instance_id = validate_and_extract_ids(detail)
print(f"ContactId={contact_id}, InstanceId={instance_id}")
transcripts = fetch_transcripts(instance_id, contact_id)
if not transcripts:
print("No transcript segments found.")
return {'statusCode': 200, 'body': 'No transcript to summarize'}
full_text = "\n".join(f"[{t['participant']}] {t['content']}" for t in transcripts)
print("Transcript:\n" + full_text)
summary = create_summary_and_update(instance_id, contact_id, full_text)
print("Generated and updated summary: " + summary)
return {
'statusCode': 200,
'body': {
'contact_id': contact_id,
'realtimesummary': summary
}
}
except ValueError as ve:
print(f"Input validation error: {ve}")
return {'statusCode': 400, 'body': str(ve)}
except RuntimeError as re:
print(f"Processing error: {re}")
return {'statusCode': 500, 'body': str(re)}
except Exception as e:
print(f"Unexpected error: {e}")
return {'statusCode': 500, 'body': f"Internal error: {e}"}
このコードは、以下の処理を行います。
- EventBridgeから通知されたイベント情報から、コンタクトIDとインスタンスIDを取得
- ListRealtimeContactAnalysisSegments APIを使用して、リアルタイム文字起こしデータを全て取得
- ページネーションに対応し、NextTokenがある限り繰り返し取得
- 取得した文字起こしデータを整形し、発言者と発言内容を結合
- Bedrockの Converse APIを使用して、通話内容の要約を生成
- 顧客の問い合わせ内容、エージェントの対応内容、結論を含む要約を3~4文で出力
- UpdateContactAttributes APIを使用して、生成した要約をコンタクト属性「realtimesummary」として保存
ListRealtimeContactAnalysisSegments APIは、チャネルが音声のみサポートしており、音声データは24時間以内に取得する必要があります。
ListRealtimeContactAnalysisSegments: 音声のコンタクトに使用します。
なお、「リアルタイムの分析」の文字起こしはAPIで取得できますが、「通話後の分析」の文字起こしはAPIで取得できません。
Voice data is retained for 24 hours. You must invoke this API during that time.
Connectフロー
Connectフローでは、フローブロック「記録と分析の動作を設定」で「リアルタイムおよび通話後の分析」を有効化します。その他の設定は、エージェントに接続されるConnectフローであれば問題ありません。
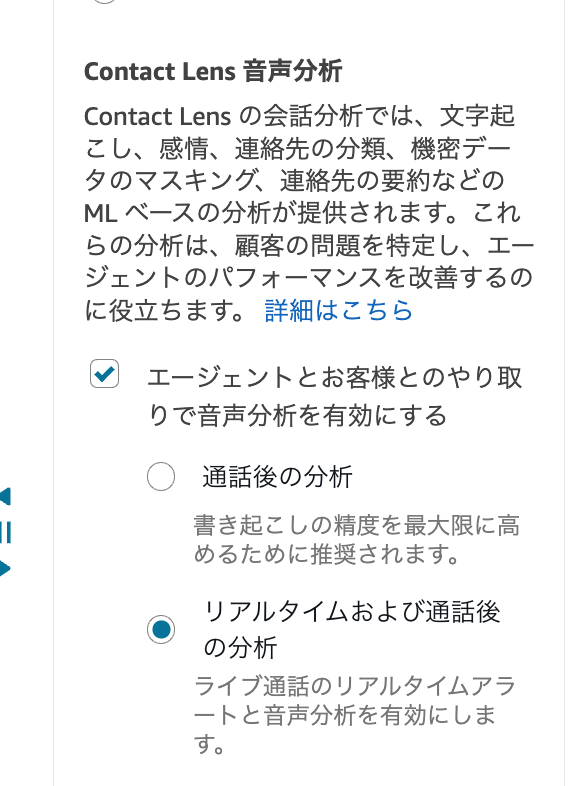
なお、「リアルタイムおよび通話後の分析」を設定した場合のトランスクリプトは、リアルタイム分析の精度のみが適用されます。通話後に精度の高いトランスクリプトへの更新は行われませんので、ご注意ください。詳細は以下の記事をご参照ください。
EventBridgeルールの作成
通話終了後にトリガーするため、以下のイベントパターンで作成します。Connectインスタンスで制限しています。
{
"source": ["aws.connect"],
"detail-type": ["Amazon Connect Contact Event"],
"detail": {
"eventType": ["DISCONNECTED"],
"channel": ["VOICE"],
"instanceArn": ["arn:aws:connect:ap-northeast-1:111111111111:instance/3ff2093d-af96-43fd-b038-3c07cdd7609c"]
}
}
さらに、Connectフロー上でコンタクト属性を設定することで、特定のConnectフローに制限することもできます。
ターゲットは、先ほど作成したLambda関数を指定します。
動作確認
会話内容は以下です。
会話内容は以下のとおりです。
Customer:実は、ウェブサイトにログインしようとしたんですが、パスワードを受け取ったメールのリンクをクリックしても、「リンクが無効です」というエラーが出るんです。
Agent:それはご不便をおかけして申し訳ありません。どのメールプロバイダーをご利用でしょうか?
Customer:Gmail です。
Agent:ありがとうございます。リンクを開く際に、ブラウザを変えてみたり、別のデバイスで試すことはされましたか?また、リンクが届いたメールが古い可能性もあります。
Customer:はい、スマホとパソコン両方で試しましたが、同じエラーが出ます。メールは15分前に届いたものです。
Agent:承知しました。それではこちらでパスワードリセットリンクを再発行いたします。新しいリンクをお送りしますので、届き次第クリックしていただけますか?
Customer:はい、お願いします。
Agent:新しいリンクを送りました。届いたメールのリンクをクリックしてみてください。
Customer:…わかりました、開いてみます。あ、今、ログインできました!ありがとうございます!
エージェントとの会話終了後、即、コンタクト詳細ページに要約が出力されました。

まとめ
Amazon ConnectのリアルタイムContact Lens分析機能を利用することで、通話終了直後に要約を表示する方法を紹介しました。
「通話後の分析」では要約表示まで5~10分かかりますが、今回の方法では通話終了と同時に要約が確認できます。
ただし、「リアルタイムの分析」は「通話後の分析」よりも文字起こし精度が低いため、本番導入前に十分な検証が必要です。
また、今回のコードを一部修正することで、CRMへの自動保存など、さまざまな用途に応用できます。








