![[新機能] Amazon DynamoDB と Amazon Redshift の Zero-ETL 統合を試してみた](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-63f1274931b942e9a92e601c1127ad73/cfe87ec6d62fa2fc3c474ed4cb2f6c2e/amazon-redshift?w=3840&fm=webp)
[新機能] Amazon DynamoDB と Amazon Redshift の Zero-ETL 統合を試してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。Amazon DynamoDB と Amazon Redshift の Zero-ETL 統合の一般提供を開始しました。本日はこの新機能が動作する環境を構築し、データがニアリアルタイムで同期される事を検証しました。
Amazon DynamoDB と Amazon Redshift の Zero-ETL 統合とは
この新機能は、DynamoDB から Redshift への複雑なデータパイプラインの構築と維持することなくデータが連携され、ニアリアルタイムな分析に利用できるようになります。
- DynamoDB のデータが Redshift にシームレスに複製され、15-30分ごとに増分更新されます。
- DynamoDB のパフォーマンスや可用性にほとんど影響を与えず、読み取りキャパシティユニット(RCU)も消費しません。
- Redshift の高性能 SQL、機械学習、Spark 統合、マテリアライズドビューなどの機能を活用できます。
DynamoDB テーブルの作成
AWS CLI を使用して、以下のコマンドでテーブルを作成します。
aws dynamodb create-table \
--table-name devices \
--attribute-definitions AttributeName=id,AttributeType=S AttributeName=timestamp,AttributeType=S \
--key-schema AttributeName=id,KeyType=HASH AttributeName=timestamp,KeyType=RANGE \
--billing-mode PAY_PER_REQUEST
このコマンドは以下の設定でテーブルを作成します。
- テーブル名:
devices - パーティションキー:
id(文字列型) - ソートキー:
timestamp(文字列型) - 課金モード: オンデマンド (PAY_PER_REQUEST)
Point-in-Time リカバリ(PITR)を有効化の設定
AWS CLI を使用して、point-in-time-recoveryを有効化します。
aws dynamodb update-continuous-backups \
--table-name devices \
--point-in-time-recovery-specification PointInTimeRecoveryEnabled=true
Amazon Redshift の設定変更
この新機能は、Amazon Redshift Serverless と Amazon Redshift Provisioned 両方で利用可能ですが、今回はServerlessを用いて検証します。検証用に構築する場合は、以下のブログを参考にしてください。
Redshift Serverlessの大文字小文字の区別を有効化
このコマンドはRedshift Serverlessのワークグループの「大文字小文字の区別」(enable_case_sensitive_identifier)を有効に設定します。
aws redshift-serverless update-workgroup \
--workgroup-name default-workgroup \
--config-parameters parameterKey=enable_case_sensitive_identifier,parameterValue=true
※ マネジメントコンソールでZero-ETL 統合を設定する過程で、[Fix it for me]オプションに従い自動設定できることを後で知りました。
その他の設定
今回は、「その他の設定」が不要です。
今回の検証環境は、Amazon DynamoDB と Amazon Redshift ともに同一アカウントのリソースなので、設定せずにマネジメントコンソールでZero-ETL 統合を設定する過程で、[Fix it for me]オプションに従い自動設定に頼ることにします。なお、[Fix it for me]オプションで設定されるポリシーは、DynamoDBに対するリソースベースのポリシー設定 です。
Amazon DynamoDB と Amazon Redshift 間でデータを連携するためには、権限の設定が必要です。方法は2つあり、1つはリソースベースのポリシー設定、もう1つはIDベースのポリシー設定する方式です。
詳細は、以下をご覧ください。
Zero-ETL 統合の作成
準備が整いましたので、早速作成します。ナビゲーションペインで[ゼロETL統合]を選択し、 [Create zero-ETL integration]を選択します。
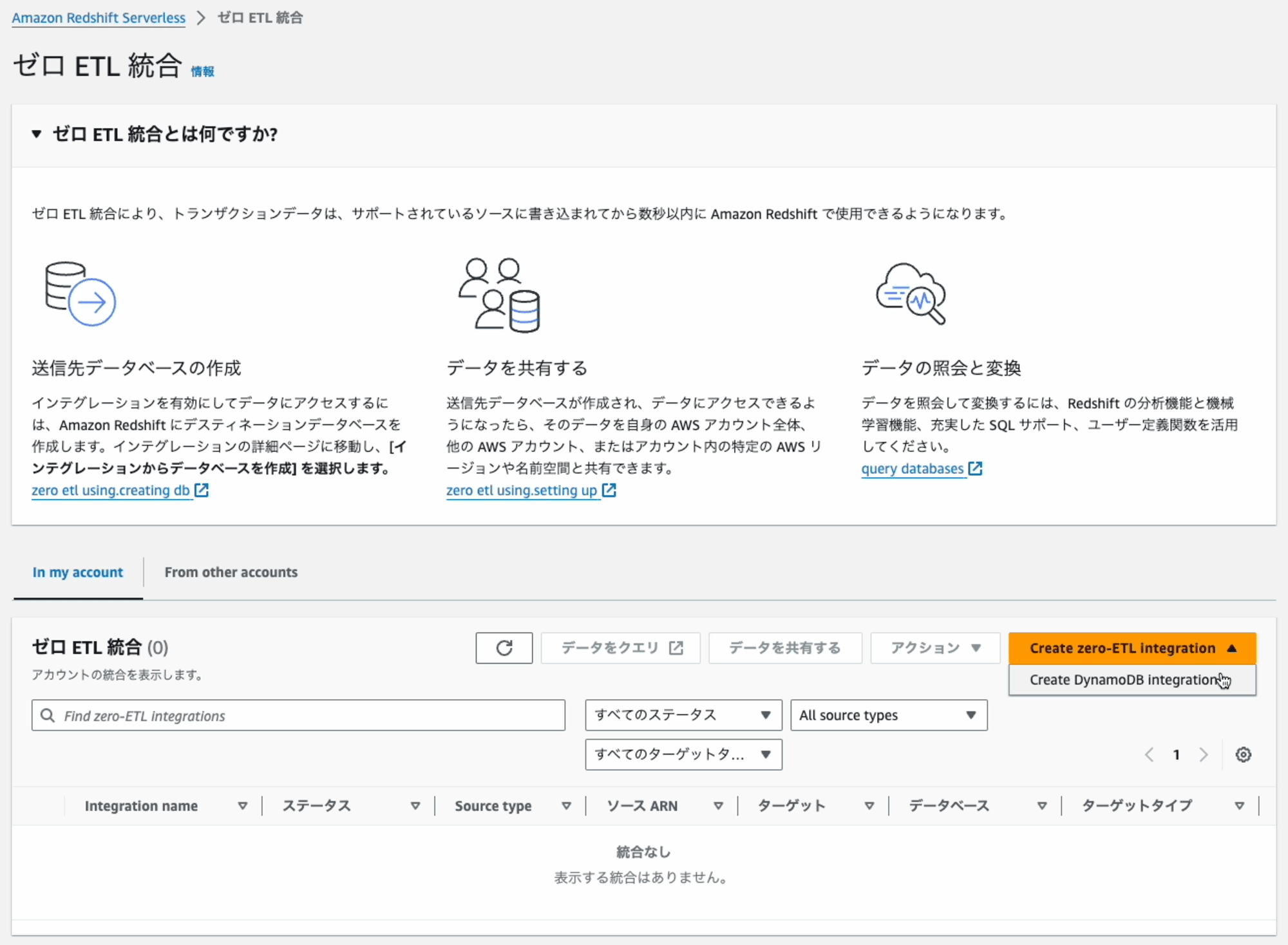
Step1: Enter Name and description
Integration nameを入力します。
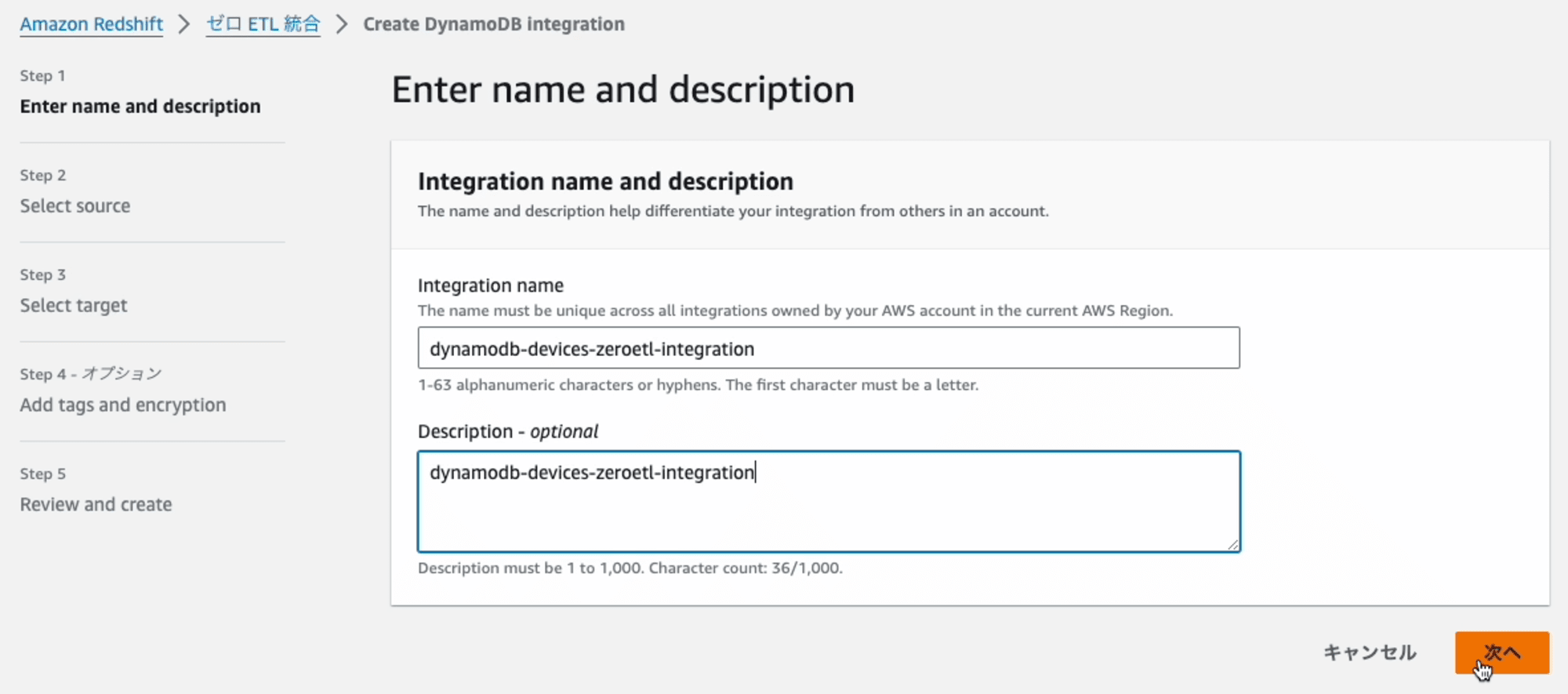
Step2: Select source
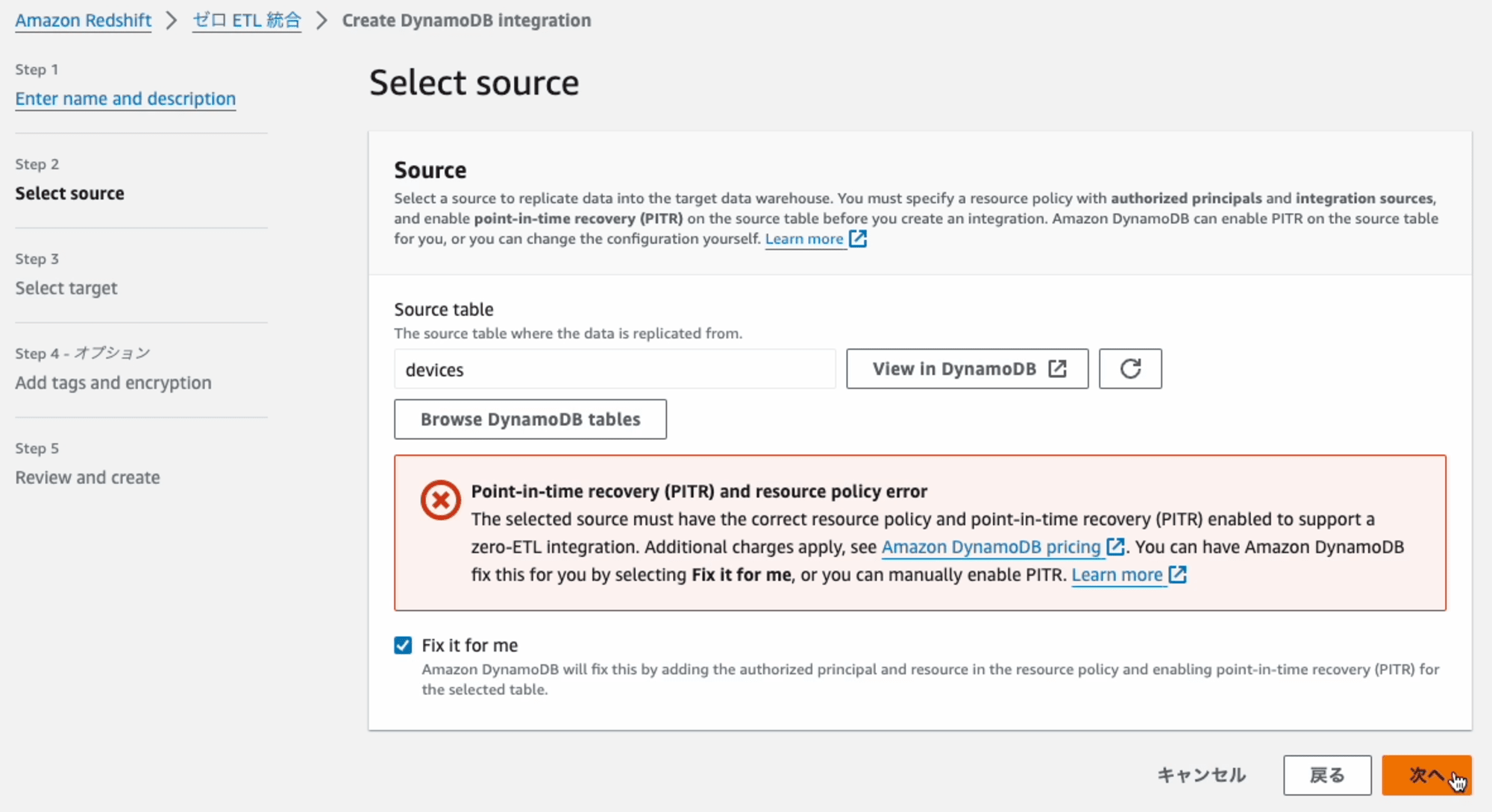
連携元となるDynamoDBのテーブルを指定します。[Browse DynamoDB tables]を押します。
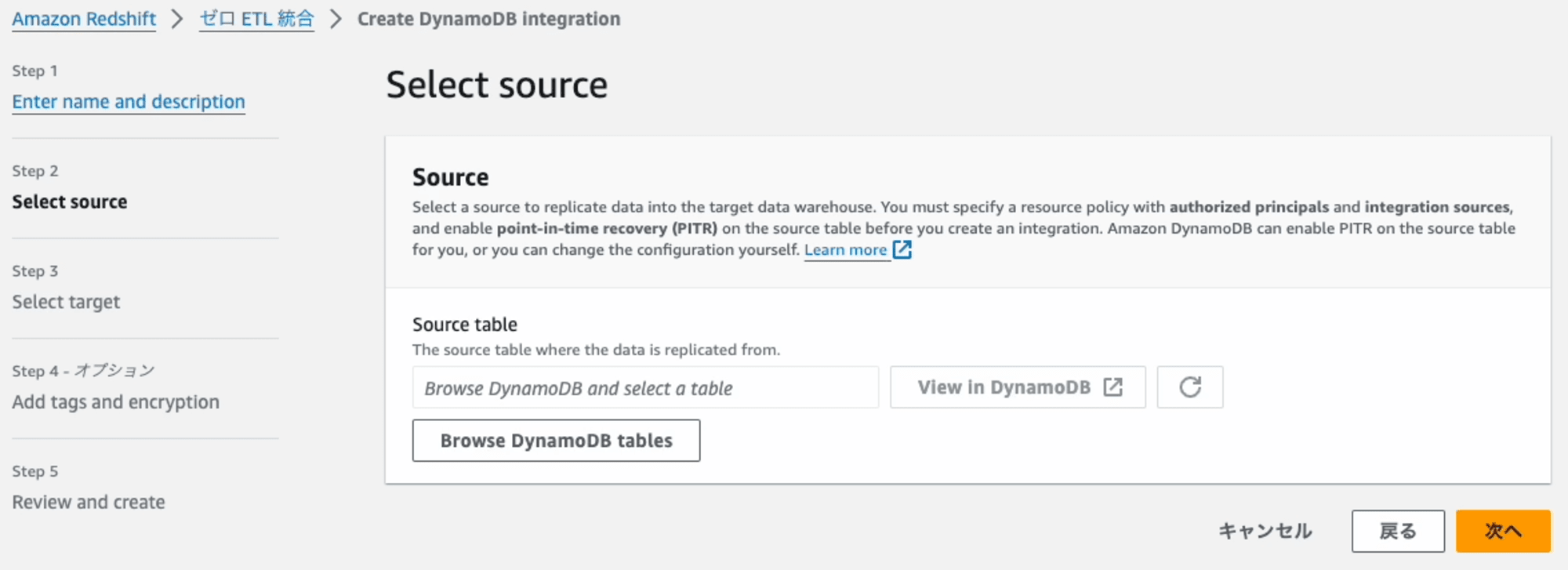
ダイアログに表示されたDynamoDBのテーブル名の一覧の中から**テーブル名(devices)**を選択します。
元の画面に戻ると、エラーメッセージ(Point-in-time recovery (PITR) and resource policy error)と[Fix it for me]オプションが表示されます。このオプションには、チェックを入れます。
その理由は、Zero-ETL 統合を設定するには、選択したDynamoDBのテーブル名に適切なリソースポリシーとPoint-in-time recovery (PITR) が有効になっている必要があります。[Fix it for me] オプションを選択すると、自動的に設定してくれます。
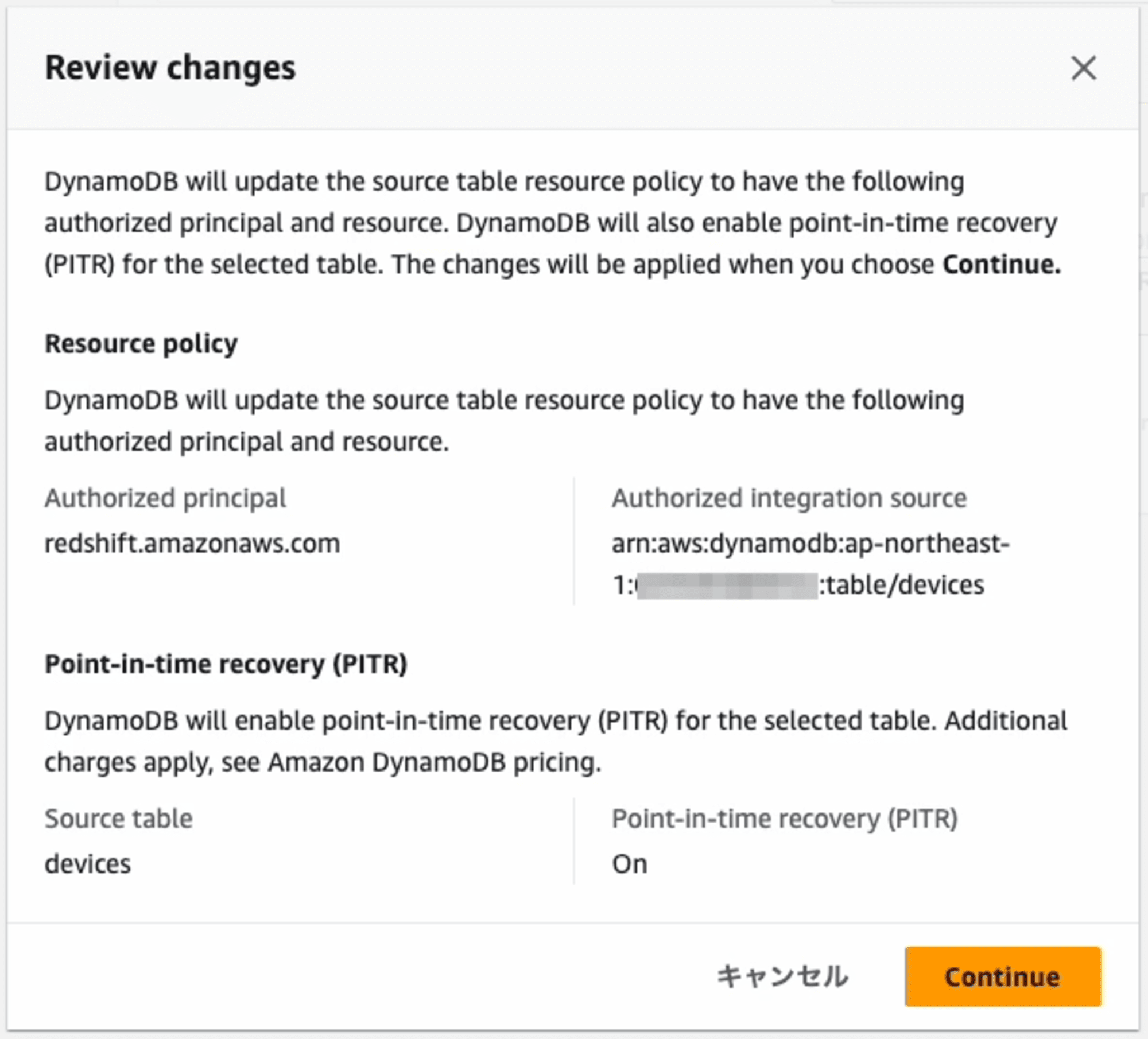
次に進むとどのような変更を加えるのかの解説が表示されます。
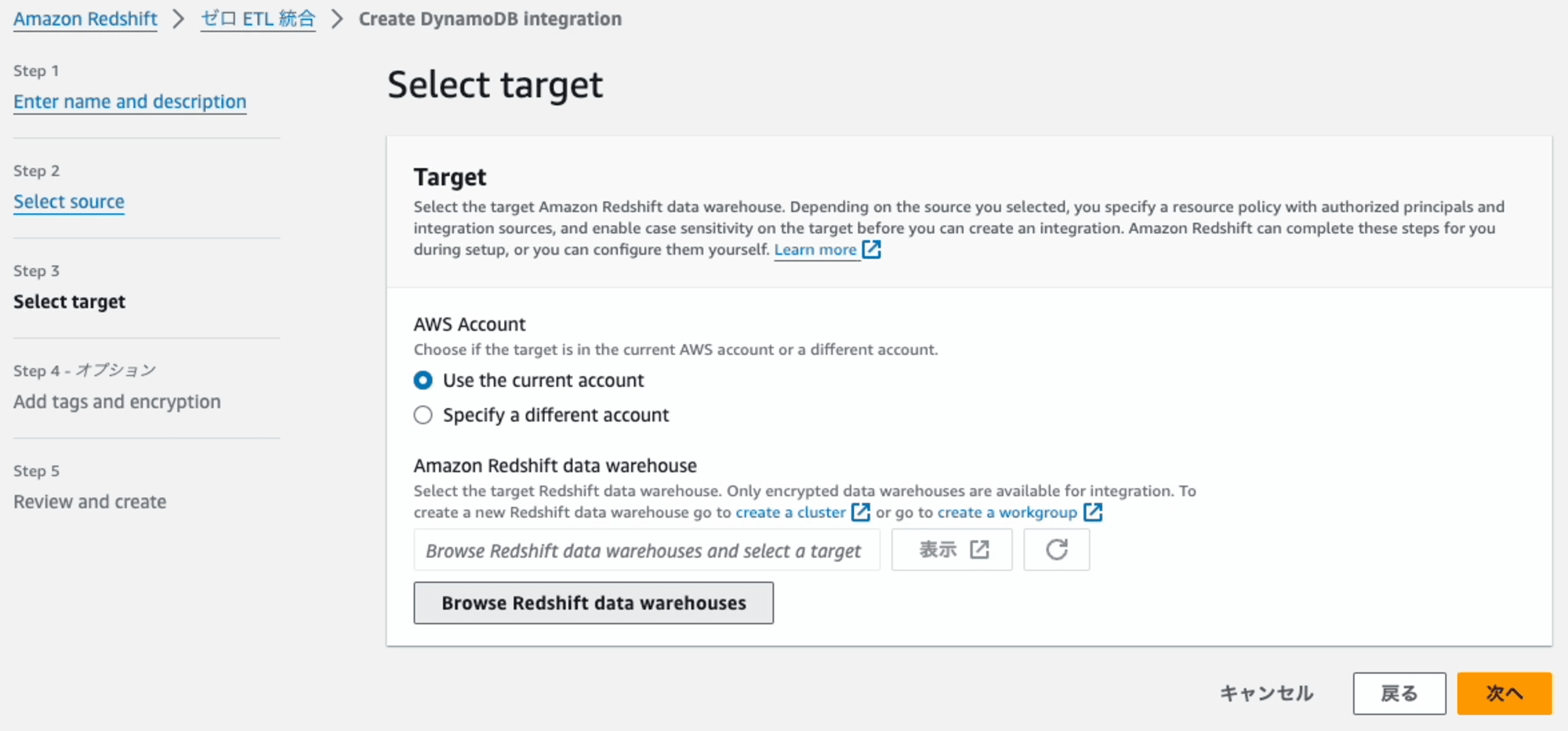
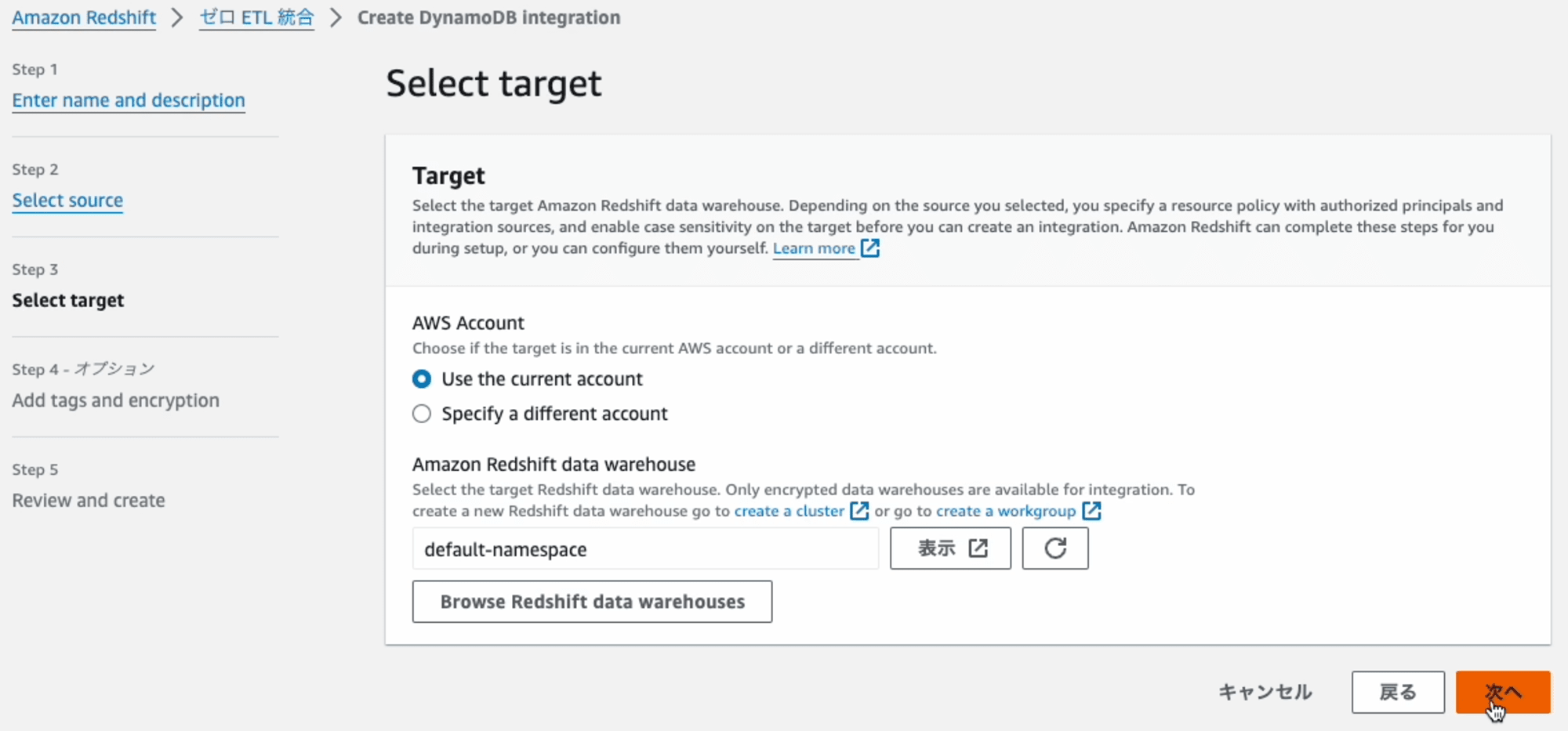
Step3: Select target
連携先となるRedshiftを指定します。[Browse Redshift data house]を押します。
ダイアログに表示されたRedshiftの一覧の中からRedshiftを選択します。
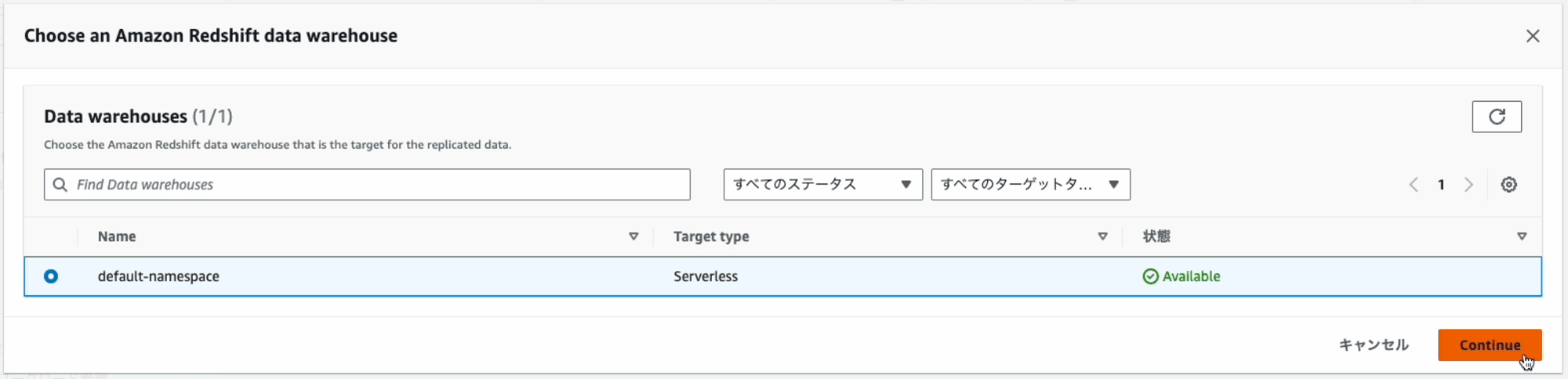
今回は、DynamoDBもRedshiftも、同じAWSアカウントにあるため、そのままで構いません。
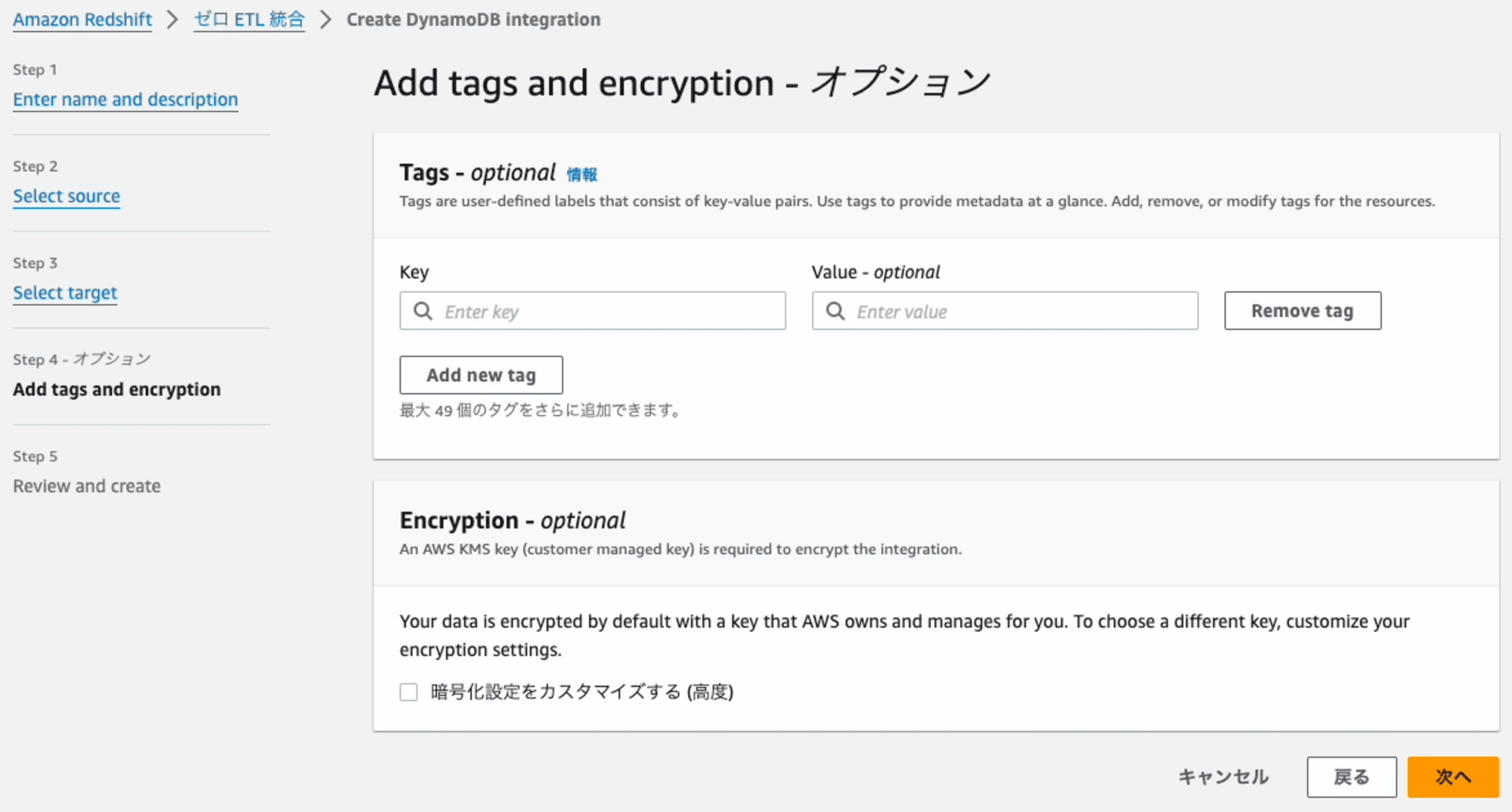
Step4: Add tags and encryption
そのままで構いません。
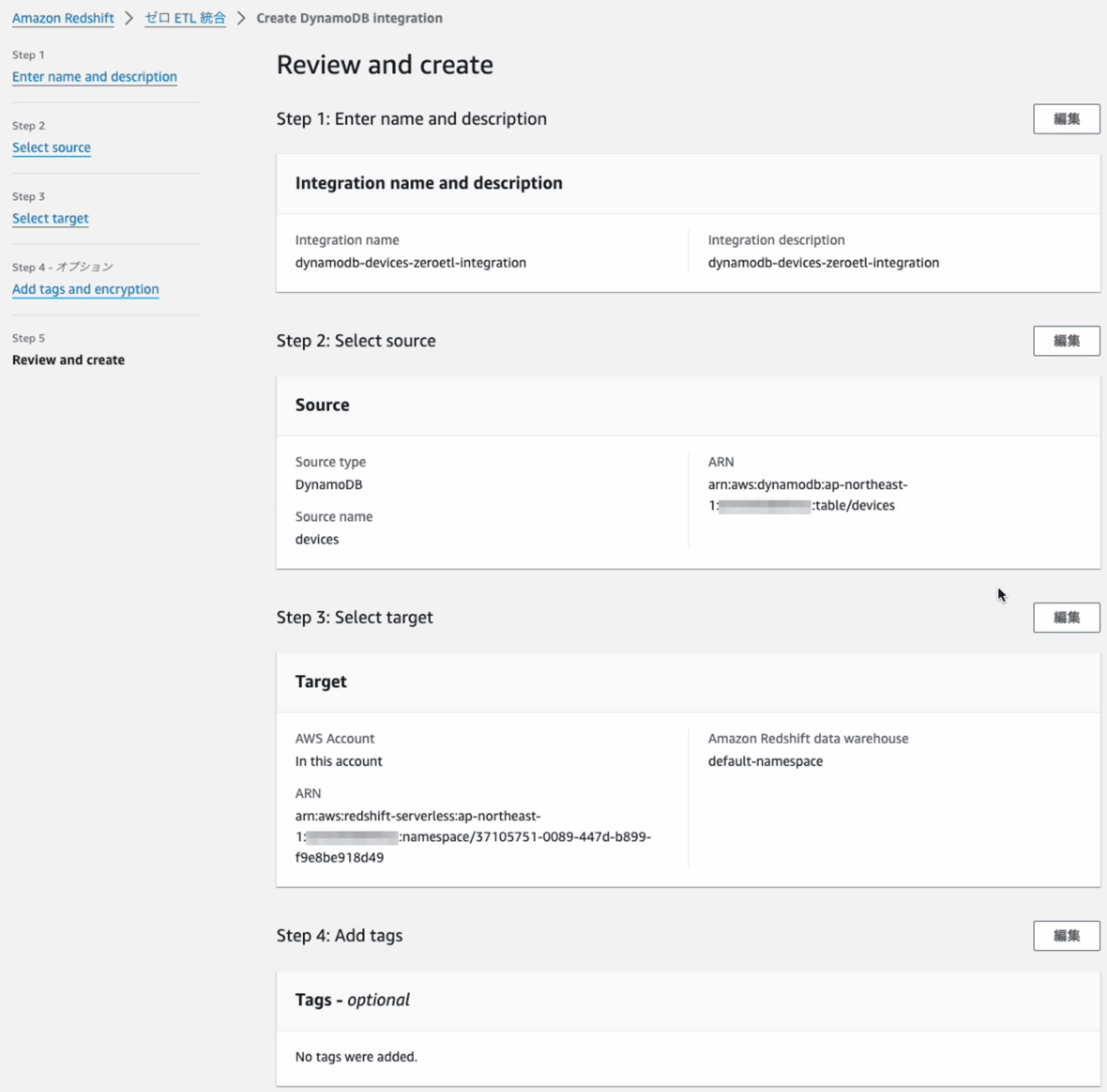
Step5: Review and create
内容を確認して、進むとZero-ETL 統合の作成します。
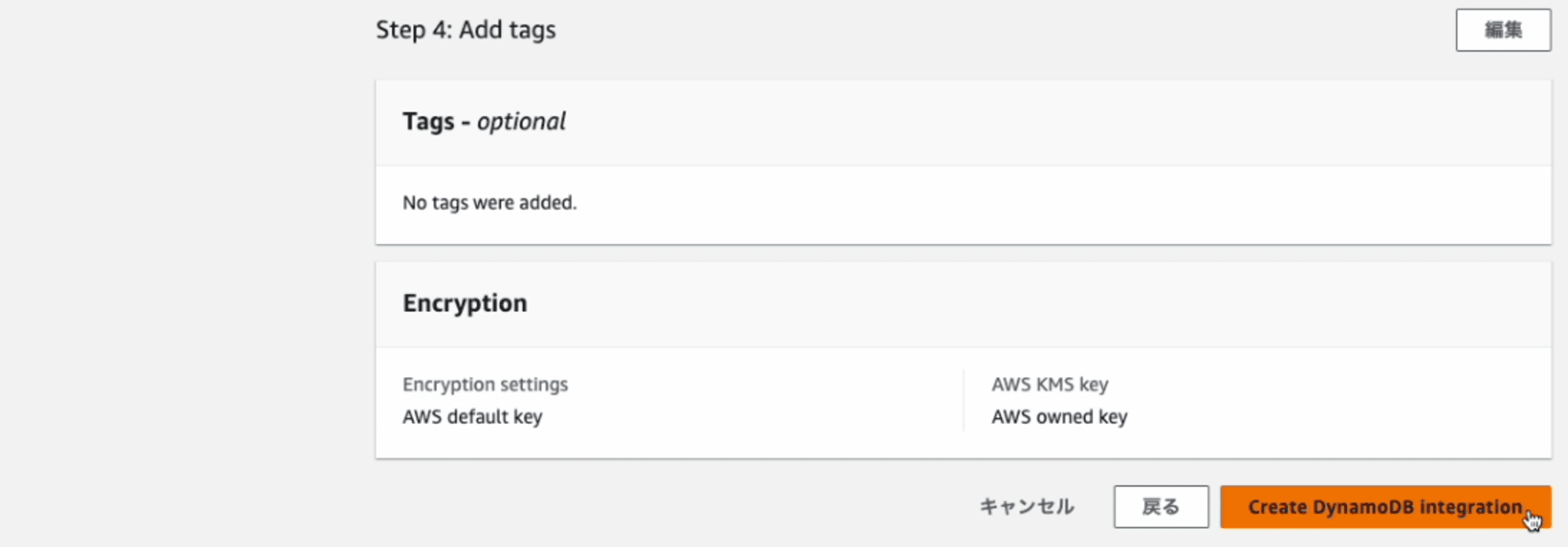
ステータスが「作成中」 となりました。
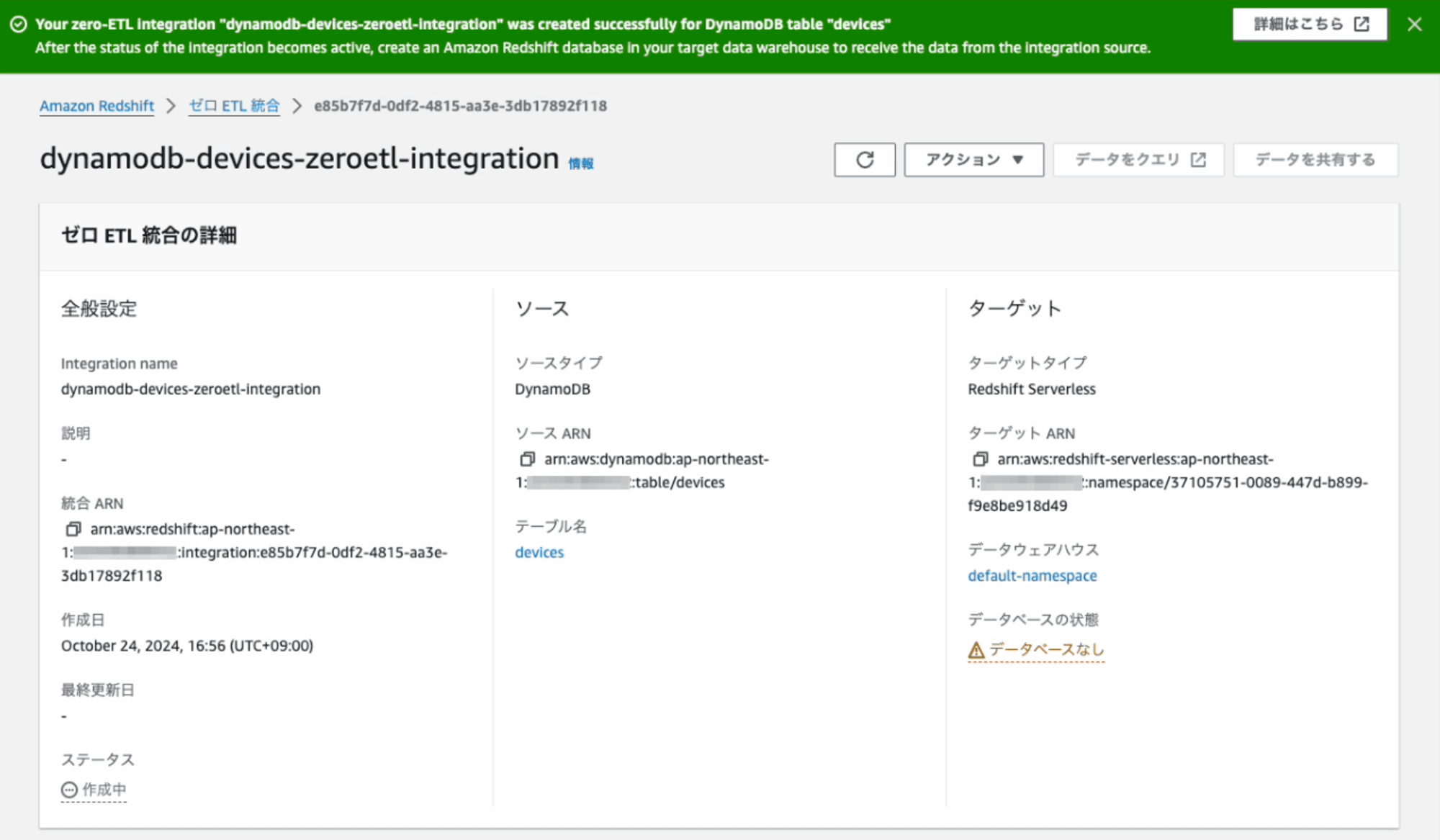
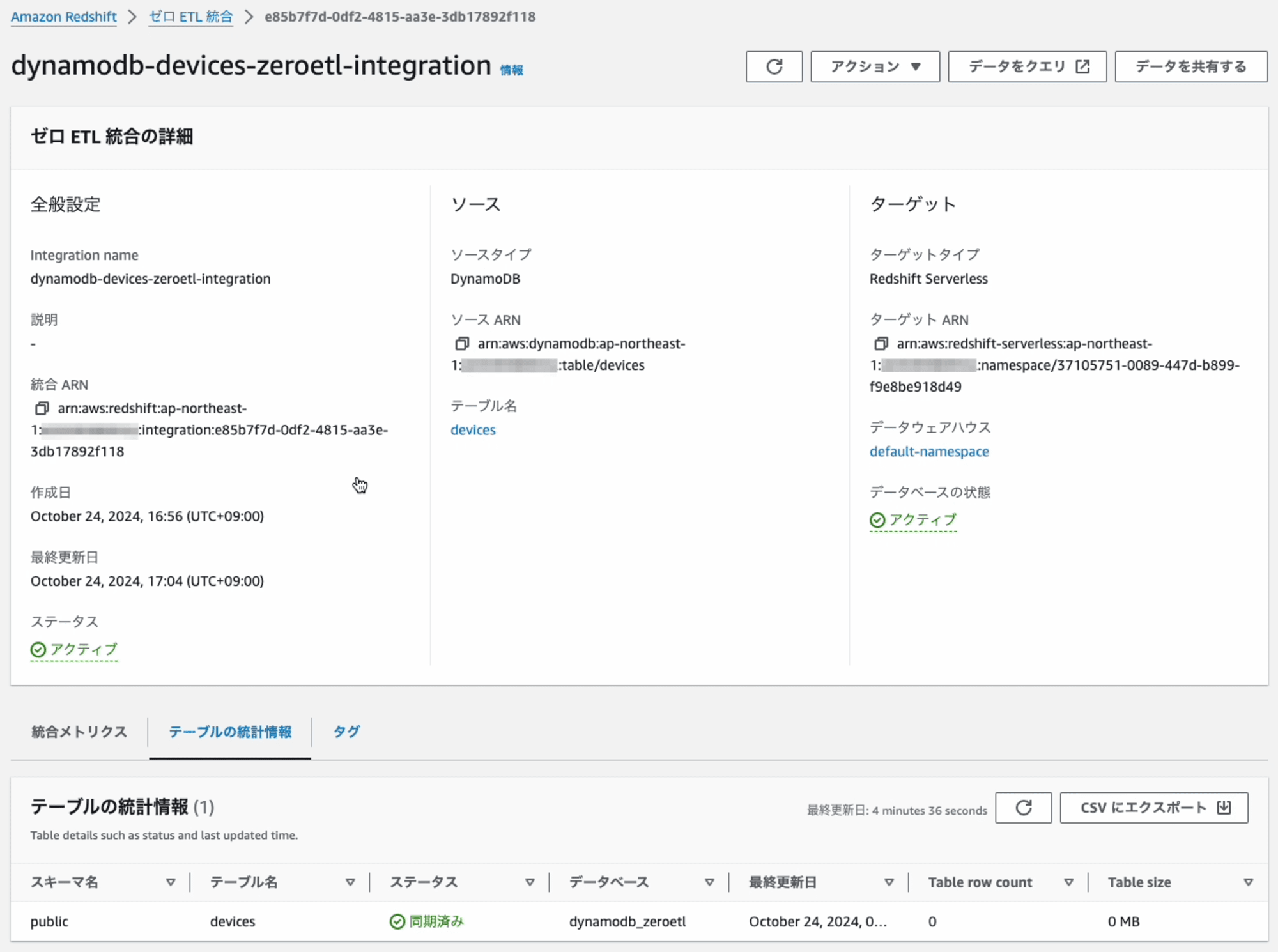
Zero-ETL 統合の作成が完了すると、ステータスが「アクティブ」 になります。
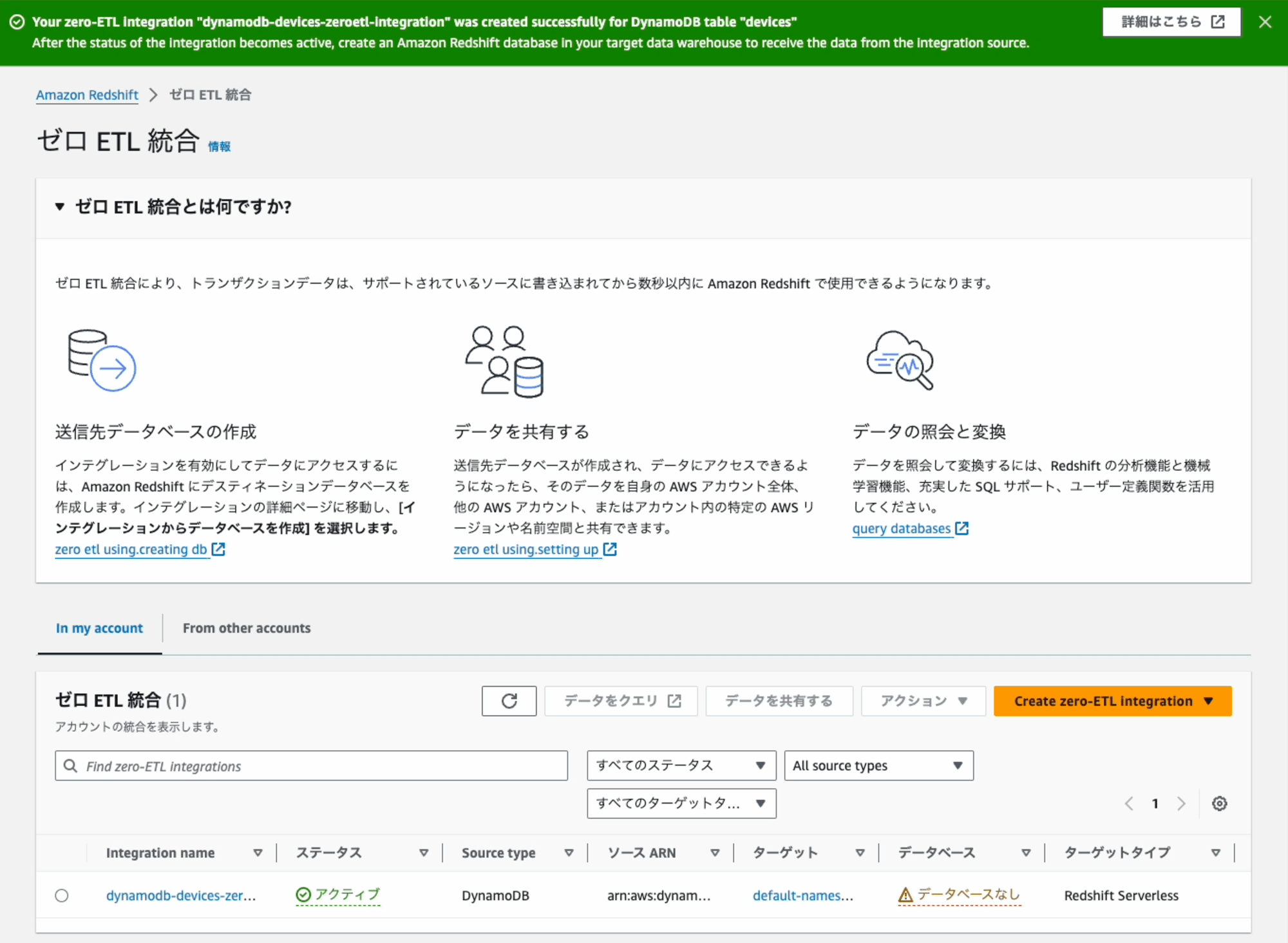
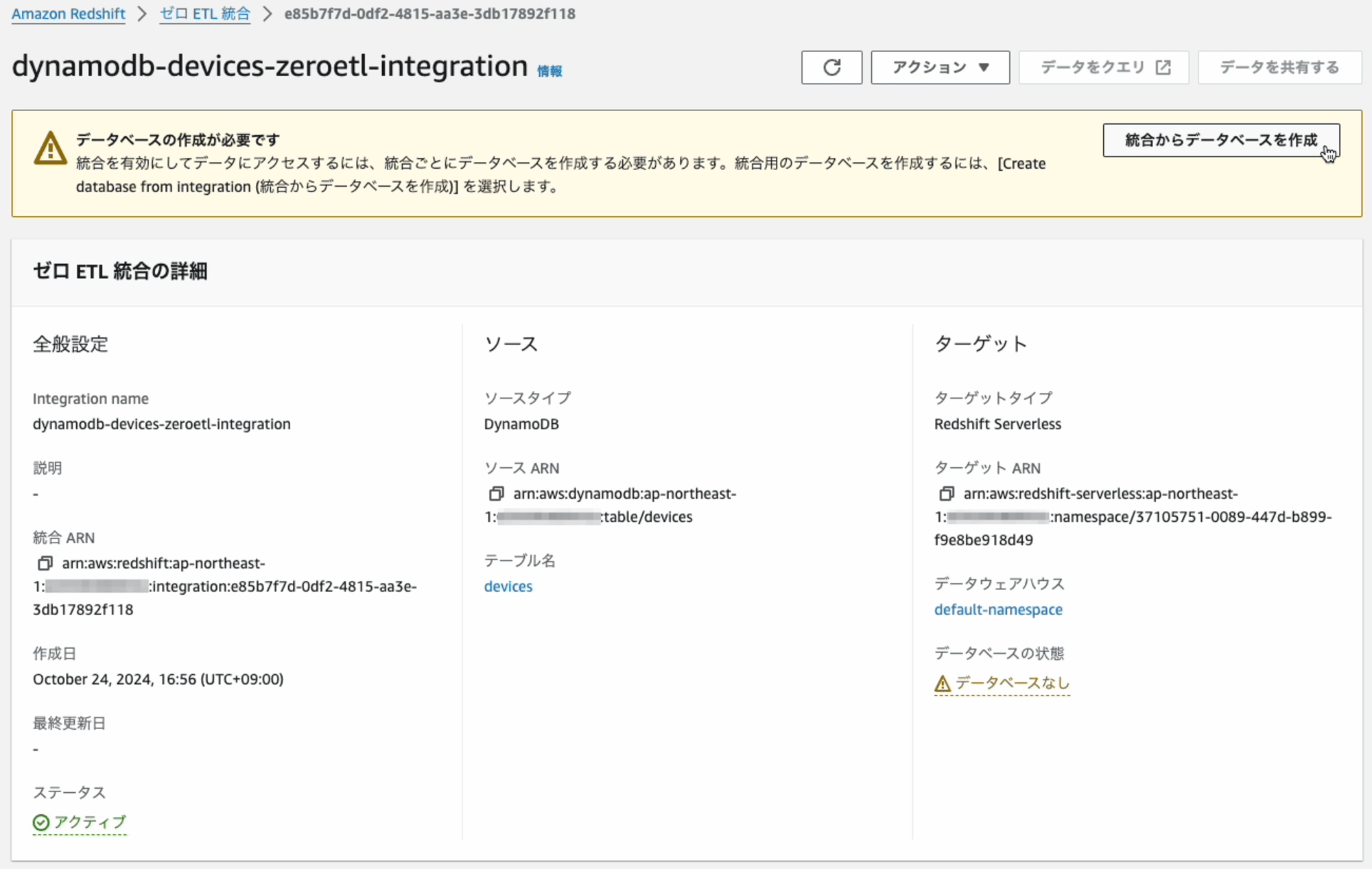
Zero-ETL 統合からデータベースの作成
Zero-ETL 統合が作成できたら、次はZero-ETL 統合からRedshiftのデータベースを作成します。データベースを作成するとその中にpublicスキーマがあり更にその下に連携したテーブルが作成され、そのテーブルにデータが連携されます。
Redshiftに作成したいデータベース名を指定します。
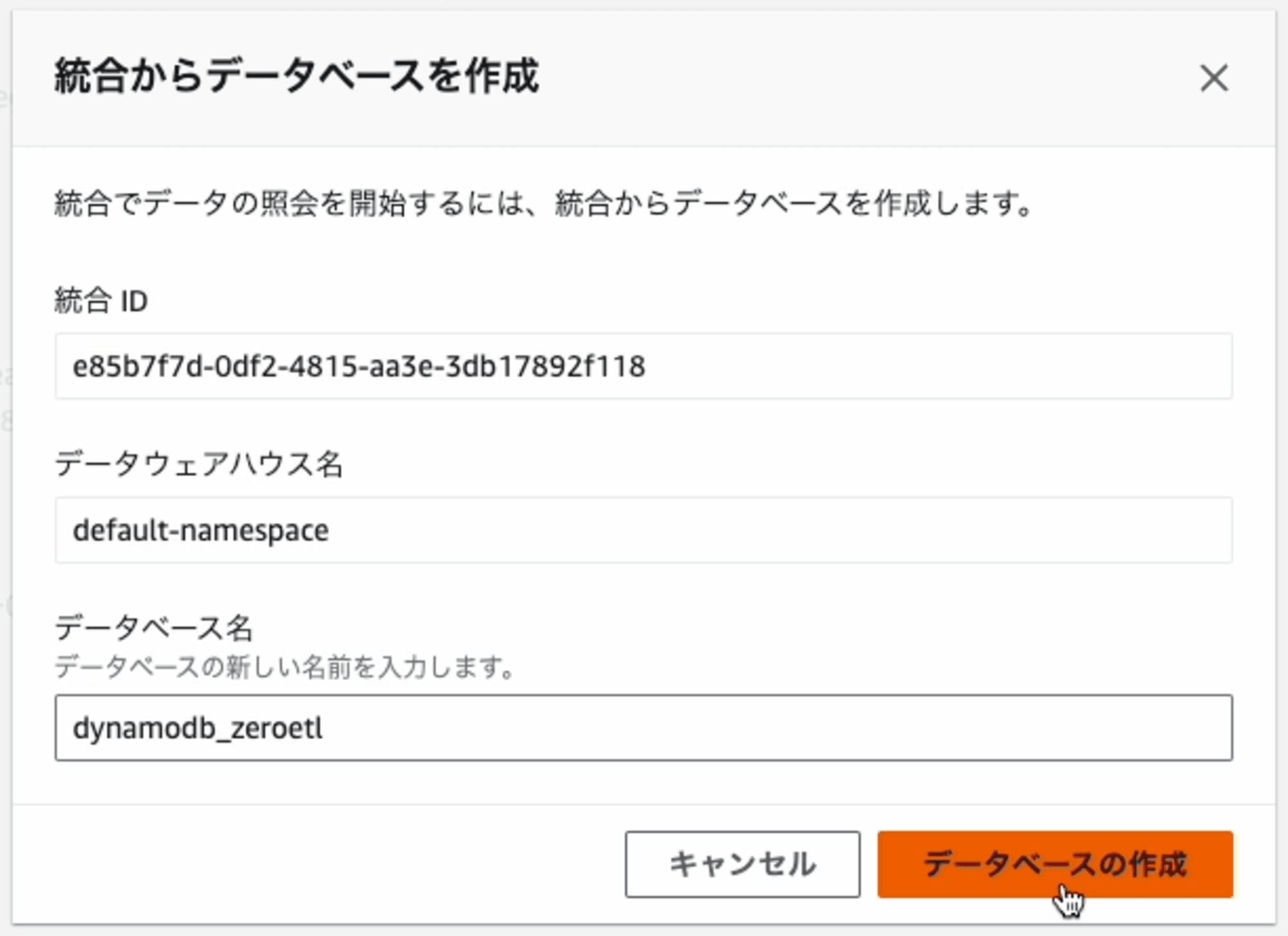
データベースを作成した直後から、データの連携が開始します。初期状態ですので、Table row countは、0件です。これで設定は完了です。
動作検証
最初は、AWSCLIコマンドで、DynamoDBのテーブル(devices)にレコードをPUTします。
$ aws dynamodb put-item \
> --table-name devices \
> --item '{
> "id": {"S": "CM1001"},
> "timestamp": {"S": "2024-10-24 00:00:00"}
> }'
しかし、1分毎に正確にコマンドを打ち続けるのは苦痛なので、簡単なツールを作成しました。(ツール(sim-iot-client.py)のソースコードは、最後のAppendex Ⅰをご覧ください。)
$ python sim-iot-client.py
Record added at 2024-10-24T08:15:20.253190
Record added at 2024-10-24T08:16:20.387938
:
初回は5〜6分程度で同期が開始されました。

Redshift Query Editor v2で確認しました。
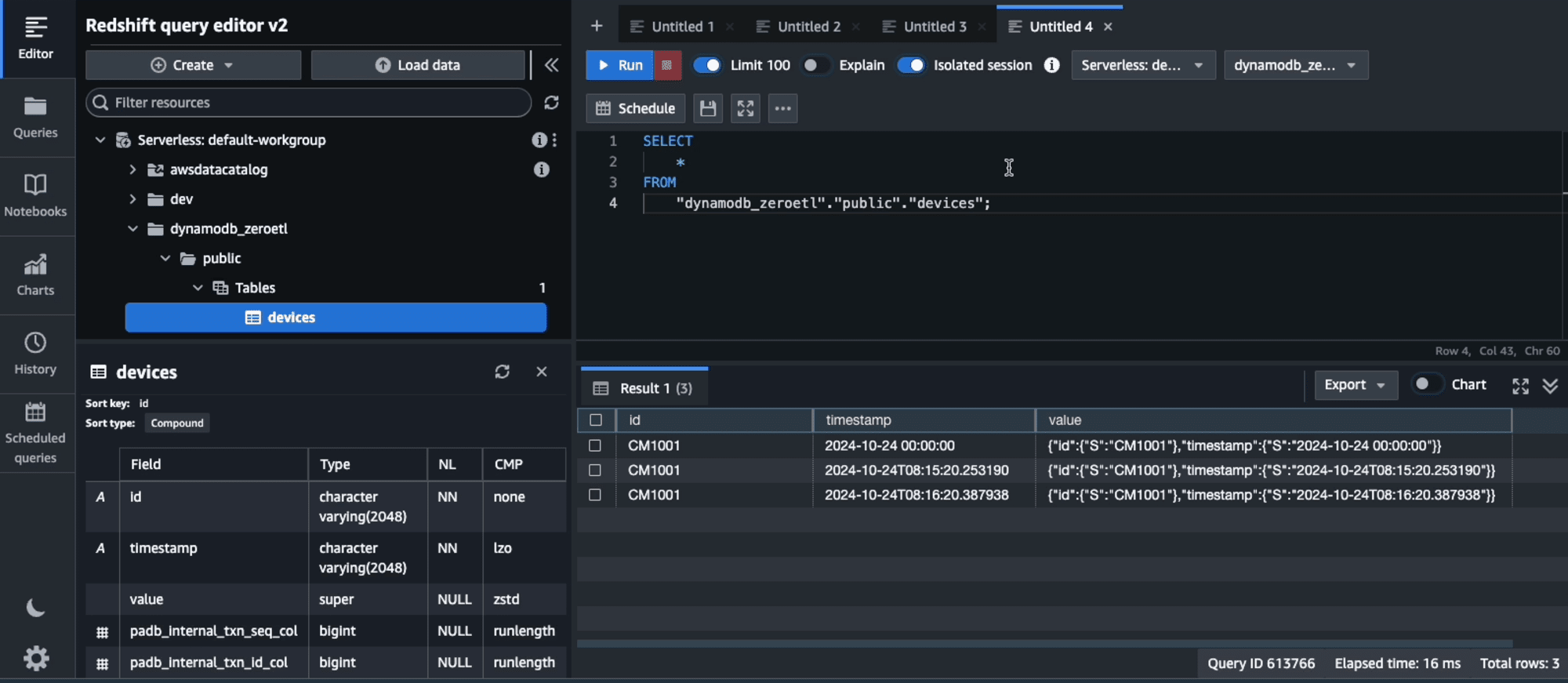
テーブルにつくても自動作成され、データの内容を確認できました。テーブル定義は、以下のとおりです。DynamoDBのレコードがJSONのため、RedshiftではSUPER型にも格納されているようです。
CREATE TABLE public.devices (
id character varying(2048) NOT NULL ENCODE raw distkey,
timestamp character varying(2048) NOT NULL ENCODE lzo,
value super,
padb_internal_txn_seq_col bigint ENCODE runlength,
padb_internal_txn_id_col bigint ENCODE runlength,
PRIMARY KEY (id, "timestamp")
)
DISTSTYLE KEY
SORTKEY ( id );
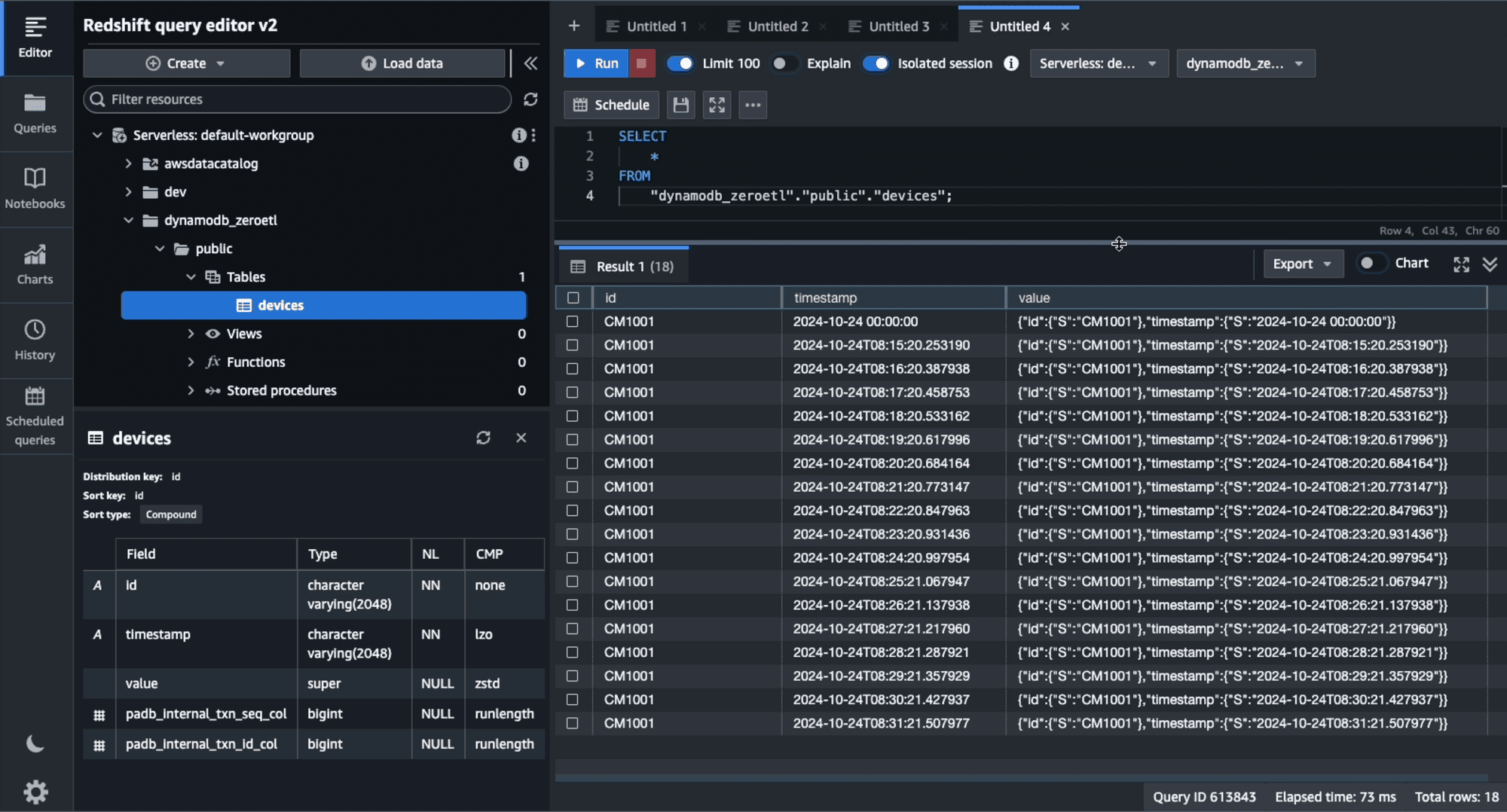
初回以降のデータ同期は、今回は15分程度のようです。
最後に
検証の準備段階では、マニュアルを読み込んで大変でしたが、実際の構築では、[Fix it for me]オプションに従い自動設定に頼る事ができたので、トラブルもなく進めることができました。そのため、Zero-ETL統合を体験したい場合は、[Fix it for me]オプションを頼るのがおすすめです。しかし、AWSの複数のアカウント間でのZero-ETL統合や、複数のテーブルのZero-ETL統合を効率的に管理するなど、本番運用においては、マニュアルの読み込みが必要になりますので、「急がば回れ」なのかもしれません。
従来、DynamoDBからRedshiftへデータを連携するにはする場合は、DynamoDBの読み取りキャパシティユニット(RCU)を使ってレコードを読み、S3に出力した後、Redshiftに読み込むといった手順を取る必要や、そのデータパイプラインの構築が不可欠でした。Amazon DynamoDB と Amazon Redshift の Zero-ETL 統合によって、簡単に、しかもDynamoDB のパフォーマンスや可用性にほとんど影響を与えず、読み取りキャパシティユニット(RCU)も消費しません。 これはクラウドベンダーの活かした唯一無二のデータ統合といえます。
この新機能により、DynamoDB のトランザクションデータを Redshift で簡単に分析できるようになり、データサイロの解消や組織全体のインサイト獲得が容易になるでしょう。
合わせて読みたい
Appendex Ⅰ
DynamoDBのテーブルに60秒毎にレコードを追加するPythonプログラムです。
sim-iot-client.py
import boto3
import time
from datetime import datetime
# DynamoDBクライアントの設定
dynamodb = boto3.resource('dynamodb', region_name='ap-northeast-1')
table = dynamodb.Table('devices')
def add_record():
timestamp = datetime.now().isoformat()
item = {
'id': 'CM1001',
'timestamp': f'{timestamp}'
}
table.put_item(Item=item)
print(f"Record added at {timestamp}")
def main():
while True:
add_record()
time.sleep(60)
if __name__ == "__main__":
main()
参考文献








