
Amazon Fraud Detector が新規受け入れを停止するので、代替案の AutoGluon を SageMaker AI Notebooks で検証してみた
こんにちは。
人生ハルシネーション
オペレーション部のかわいです。
最近ひやっこいですね。
先日、プロダクトライフサイクルのページで Amazon Fraud Detector の名前が上がっているのを見かけました。
内容としては「 2025/11/7でサービスの新規受け入れを停止する 」というもので、「終わっちゃうんだな~」という認識でした。
Fraud Detector はAWS試験でたまに見かけるなーというくらいでしたが、サービスページに以下のような記述を見かけ、
Amazon Fraud Detector will no longer be open to new customers starting November 7, 2025. If you would like to use Amazon Fraud Detector, sign up prior to that date. For capabilities similar to Amazon Fraud Detector, explore Amazon SageMaker, AutoGluon, and AWS WAF.
WAF は直接的にサービスやアプリケーションに関わる部分の防御なのでいいとして、
SageMaker AI や AutoGluon ってどう使うんだ?と思ったので、簡易的に SageMaker AI Notebooks でインスタンスを建てて検証してみました。
本記事では機械学習初学者の筆者が、クレジットカードのトランザクションデータセットから、SageMaker AI Notebooks で AutoGluon を使用して不正検知モデルを構築する までの記録を書いていきます。
下準備
まずはデータを準備します。
自前で用意するのは大変なので、Kaggle から「Credit Card Transactions Fraud Detection Dataset」をダウンロードしました。 ※ライセンスは「CC0: Public Domain」のものを使用
ファイルは2種類用意されており、「fraudTrain.csv」と「fraudTest.csv」があります。
Train が学習用で、Test は名前通りテスト用です。
中身はこんな感じ。
,trans_date_trans_time,cc_num,merchant,category,amt,first,last,gender,street,city,state,zip,lat,long,city_pop,job,dob,trans_num,unix_time,merch_lat,merch_long,is_fraud
0,2019-01-01 00:00:18,2703186189652095,"fraud_Rippin, Kub and Mann",misc_net,4.97,Jennifer,Banks,F,561 Perry Cove,Moravian Falls,NC,28654,36.0788,-81.1781,3495,"Psychologist, counselling",1988-03-09,0b242abb623afc578575680df30655b9,1325376018,36.011293,-82.048315,0
上記からも、クレジットカード取引に関する情報が含まれているのがなんとなく分かります。
特に最後のカラムにある「is_fraud」という列が重要で、is_fraud 列は取引が「不正(1)」だったのか、「正常(0)」だったのかを示し、この値から正常/不正パターンを学習させます。
ダウンロードが完了したら、「fraudTrain.csv」と「fraudTest.csv」を S3 バケットにアップロードします。
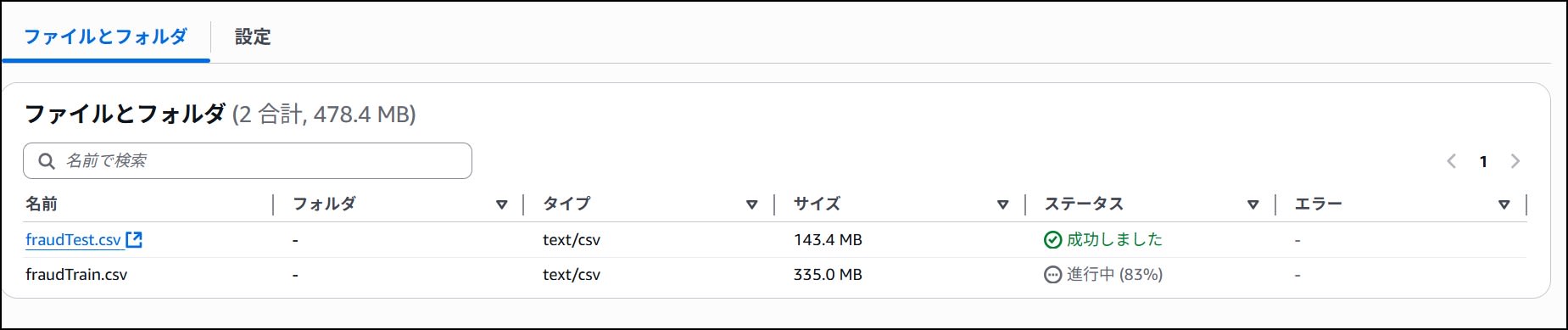
後で使うので、アップロード後にファイルの S3 パス(例えば s3://<バケット名>/fraudTrain.csv)を控えておきます。
これで下準備は完了です。
Amazon SageMaker AI Notebooks インスタンスの起動
ここからは、機械学習に必要なインスタンスを立ち上げます。
SageMaker AI Notebooks から【ノートブックインスタンスの作成】をクリックし、インスタンスを作成します。
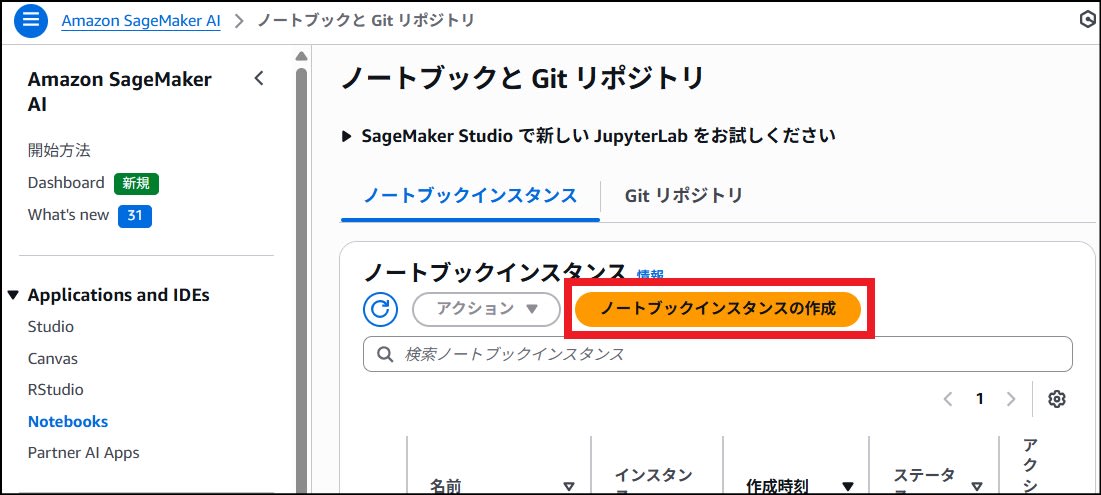
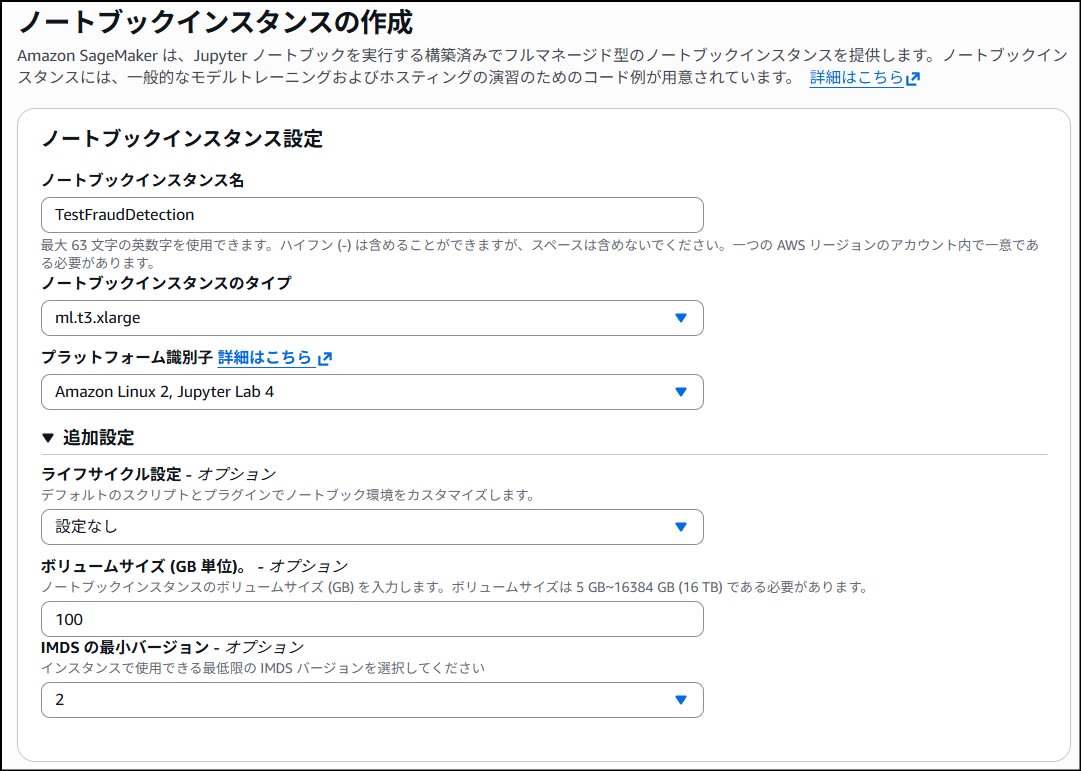
今回タイプには「ml.t3.xlarge」、ボリュームサイズを念のため 100GB にしました。
今回は検証用途なのでこれで足りましたが、それ以上の用途が見込まれる場合はもう少しスペックを上げるのが良いと思います。
また、IAM ロールは今回作成した S3 バケットに対するアクセスを許可する内容を作成、または付与します。
セキュリティグループでは、送信元からのみ接続を許可するか、インターネット側からの通信を許可しないようにします。
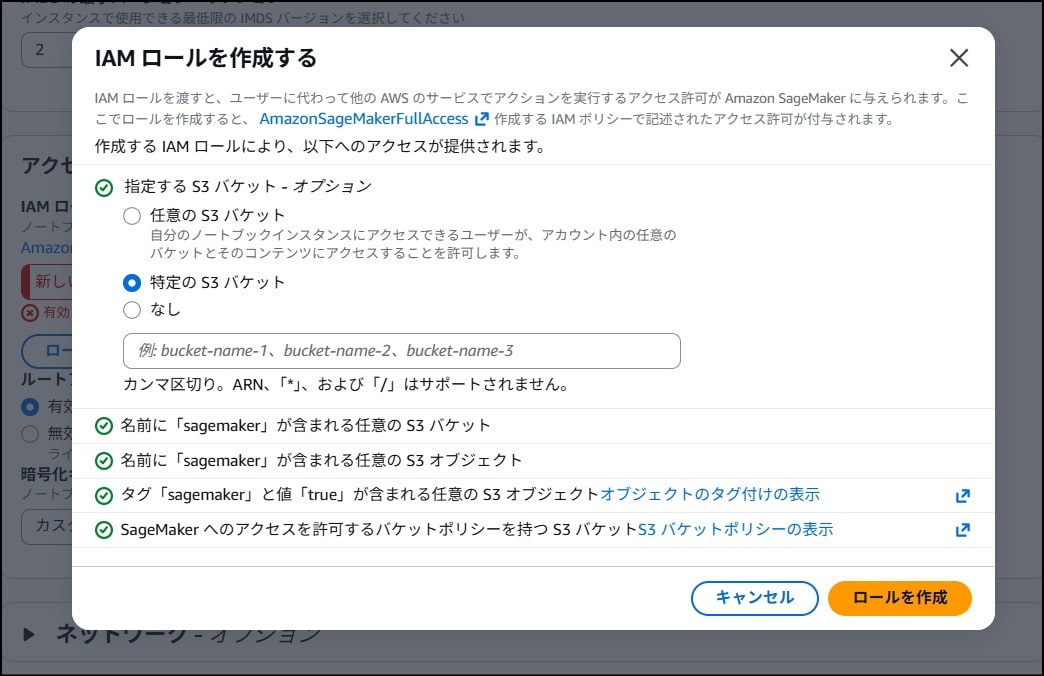
ここまで設定できれば【ノートブックインスタンスの作成】をクリックし、ステータスが「InService」になるまでお茶でも飲みながら待ちます。

必要ライブラリのインストール
インスタンスが起動したら、インスタンス詳細から JupyterLab を開きます。
このような画面に遷移するので、「conda_python3」を選びます。

JupyterLab の画面に遷移したら、以下を実行してライブラリのインポートと、既存ライブラリのアップグレードを実施します。
※筆者環境における依存関係エラーなどから、以下に落ち着きました(2025/10/31時点)
!pip install --upgrade mxnet
!pip install autogluon.tabular autogluon.core autogluon.features
!pip install "ray[default,tune]>=2.10.0,<2.45.0"
モデルの学習
まずは以下のコードを実行し、モデル学習と性能評価を行います。
# 必要なライブラリのインポート
import pandas as pd
from sklearn.model_selection import train_test_split
from autogluon.tabular import TabularPredictor
# データ読み込み用
s3_path = 's3://<バケット名>/fraudTrain.csv'
print(f"S3からデータセットを読み込み中: {s3_path}")
df = pd.read_csv(s3_path)
# 最初の5行を表示
print("データセットの最初の5行:")
print(df.head())
# データセットの基本情報
print("\nデータセットの基本情報です")
df.info()
# 不正取引の割合を確認 (is_fraud=1 の割合)
fraud_count = df['is_fraud'].sum()
total_count = len(df)
fraud_percentage = (fraud_count / total_count) * 100
print(f"\n合計取引数: {total_count}")
print(f"不正取引数 (is_fraud=1): {fraud_count}")
print(f"不正取引の割合: {fraud_percentage:.2f}%")
# ラベル)の設定とデータ分割
# 予測したいラベル
label = 'is_fraud'
# データセットをトレーニング用と評価用に分割
train_data, test_data = train_test_split(df, test_size=0.2, random_state=42, stratify=df[label])
print(f"\nトレーニングデータの行数: {len(train_data)}")
print(f"テストデータの行数: {len(test_data)}")
print(f"トレーニングデータ内の不正取引の割合: {(train_data[label].sum() / len(train_data)) * 100:.2f}%")
print(f"テストデータ内の不正取引の割合: {(test_data[label].sum() / len(test_data)) * 100:.2f}%")
# AutoGluonでモデル学習
print("\nAutoGluon でモデル学習を開始します")
predictor = TabularPredictor(label=label, path='AutogluonModels').fit(train_data, presets='good_quality')
print("\nモデル学習が完了しました!")
# モデルの性能を評価
print("\nテストデータでモデルの性能を評価します...")
results = predictor.evaluate(test_data, silent=True)
print("\nモデル評価結果:")
print(results)
# 新しい取引データに対する予測結果の例を表示
print("\nテストデータに対する予測結果の例 (最初の10件):")
predictions = predictor.predict(test_data.drop(columns=[label]))
print(predictions.head(10))
# 不正確率の予測の例
print("\nテストデータに対する、不正である確率の予測結果の例 (最初の10件):")
# ここで得られる pred_proba は、モデルが各取引が不正であると予測した「確信度(スコア)」です。
# Amazon Fraud Detector が提供していた「不正スコア」と似たものと考えて良いでしょう。
pred_proba = predictor.predict_proba(test_data.drop(columns=[label]))
print(pred_proba.head(10))
# どのモデルの性能が良かったかをチェック
print("\nAutoGluon が選択した最適なモデル:")
print(predictor.leaderboard(test_data, silent=True))
コードを実行するとデータセットが S3 から読み込まれ、以下のように AutoGluon によるモデル学習が始まります。
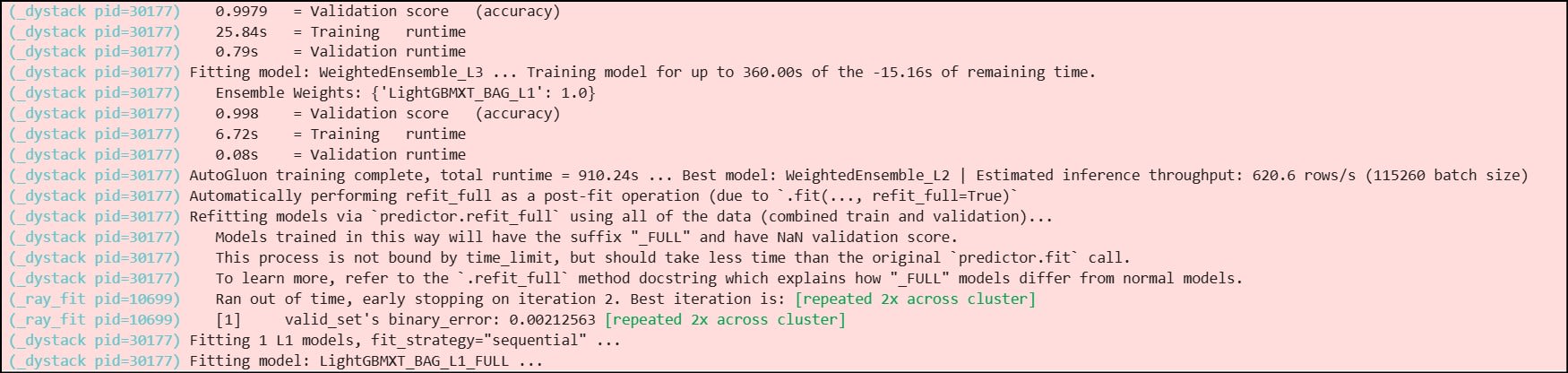
完了まで気長に待ちます。
データ量にもよりますが、筆者環境では30分~1時間程度かかったと思います。
130万行くらいあるので、確認のため最初の5行だけ出力させてます。
「is_fraud」列をチェックして、不正件数が出ました。

↓やっと終わりました。

学習が終わると、JupyterLab の左ペインにモデルの格納先フォルダ「AutogluonModels」が作成されます。

不正取引予測の実行と結果の評価
次は、いよいよ学習済みモデルを使って、S3 に保存されている「fraudTest.csv」のデータに対して不正チェックを行います。
JupyterLab で以下コードを実行します。
このコードでは、事前に「is_fraud」列を除去したデータを不正チェックさせ、最終的に 何件の不正予測ができたか?と、「is_fraud=1」の数を照らし合わせてモデルを評価 しています。
import pandas as pd
from autogluon.tabular import TabularPredictor
# 学習済みモデルの読み込み
# 今回作成したモデルが保存されているパスを指定します
predictor = TabularPredictor.load("/home/ec2-user/SageMaker/AutogluonModels/AutogluonModels")
print("学習済みモデルをロードしました。")
# fraudTest.csvの読み込み
s3_test_path = 's3://<バケット名>/fraudTest.csv'
print(f"S3からテストデータセットを読み込み中: {s3_test_path}")
test_df = pd.read_csv(s3_test_path)
# 最初の5行を表示してデータを確認
print("テストデータセットの最初の5行:")
print(test_df.head())
# テストデータからラベル列(is_fraud)を削除
# ※実際の不正チェックでは、is_fraud列は存在しないため
if 'is_fraud' in test_df.columns:
test_data_nolabel = test_df.drop(columns=['is_fraud'])
else:
test_data_nolabel = test_df.copy() # is_fraud列がない場合はそのまま使用
print("\nテストデータに対して不正予測を実行します...")
# 不正取引の予測
# predict() で不正/正常の分類結果を取得 (0または1)。
predictions = predictor.predict(test_data_nolabel)
# predict_proba() で、不正である確率(不正スコア)を取得
pred_proba = predictor.predict_proba(test_data_nolabel)
print("\n不正予測が完了しました。")
# 予測結果の確認
print("\n予測結果 (最初の10件):")
print(predictions.head(10))
print("\n不正である確率 (最初の10件):")
print(pred_proba.head(10))
# 実際のラベルと比較(fraudTest.csvにis_fraud列がある場合)
if 'is_fraud' in test_df.columns:
print("\n実際の不正ラベル (最初の10件):")
print(test_df['is_fraud'].head(10))
# 予測結果と実際のラベルを結合して確認
comparison_df = test_df[['is_fraud']].copy()
comparison_df['predicted_fraud'] = predictions
comparison_df['fraud_probability'] = pred_proba[1] # 不正である確率
print("\n予測と実際のラベルの比較 (最初の10件):")
print(comparison_df.head(10))
# 誤検知や見逃しの数と例をチェック
# 1)実際には不正ではないのに不正と予測したケース
false_positives = comparison_df[(comparison_df['is_fraud'] == 0) & (comparison_df['predicted_fraud'] == 1)]
print(f"\n誤検知 (False Positives) の数: {len(false_positives)}")
if not false_positives.empty:
print("誤検知の例 (最初の5件):")
print(test_df.loc[false_positives.index].head())
# 2)実際には不正なのに正常と予測したケース (見逃し)
false_negatives = comparison_df[(comparison_df['is_fraud'] == 1) & (comparison_df['predicted_fraud'] == 0)]
print(f"\n見逃し (False Negatives) の数: {len(false_negatives)}")
if not false_negatives.empty:
print("見逃しの例 (最初の5件):")
print(test_df.loc[false_negatives.index].head())
else:
print("\nテストデータに`is_fraud`列がないため、実際のラベルとの比較はできません。")
print("予測結果と不正確率のみを表示します。")
# モデルが不正と予測した取引だけをすべて抽出して表示
# 'predicted_fraud'列が「1」のものだけをフィルタリング
predicted_fraudulent_transactions = comparison_df[comparison_df['predicted_fraud'] == 1]
print("\n--- モデルが不正であると予測したすべての取引 ---")
if not predicted_fraudulent_transactions.empty:
print(f"合計 {len(predicted_fraudulent_transactions)} 件の取引が不正と予測されました。")
# 不正と予測された取引の元のデータと予測結果、不正確率を表示
# test_dfインデックスを使って元の取引情報を取得
print(test_df.loc[predicted_fraudulent_transactions.index])
else:
print("不正と予測された取引はありませんでした。")
# 実際の不正取引
actual_fraudulent_transactions = comparison_df[comparison_df['is_fraud'] == 1]
print(f"\n--- 実際に不正だった取引の合計: {len(actual_fraudulent_transactions)} 件 ---")
if not actual_fraudulent_transactions.empty:
print("実際に不正だった取引の最初の10件:")
print(test_df.loc[actual_fraudulent_transactions.index].head(10))
# モデルが正しく不正と予測できた取引
true_positives = actual_fraudulent_transactions[actual_fraudulent_transactions['predicted_fraud'] == 1]
print(f"\nモデルが正しく不正と予測できた取引 (True Positives) の数: {len(true_positives)}")
if not true_positives.empty:
print("True Positives の例 (最初の5件):")
print(test_df.loc[true_positives.index].head())
# モデルが見逃した不正取引
false_negatives_recheck = actual_fraudulent_transactions[actual_fraudulent_transactions['predicted_fraud'] == 0]
print(f"\nモデルが見逃した不正取引 (False Negatives) の数: {len(false_negatives_recheck)}")
if not false_negatives_recheck.empty:
print("False Negatives の例 (最初の5件):")
print(test_df.loc[false_negatives_recheck.index].head())
else:
print("テストデータには実際の不正取引が含まれていませんでした。")
まず、「実際に不正だった件数(is_fraud=1)」の件数です。
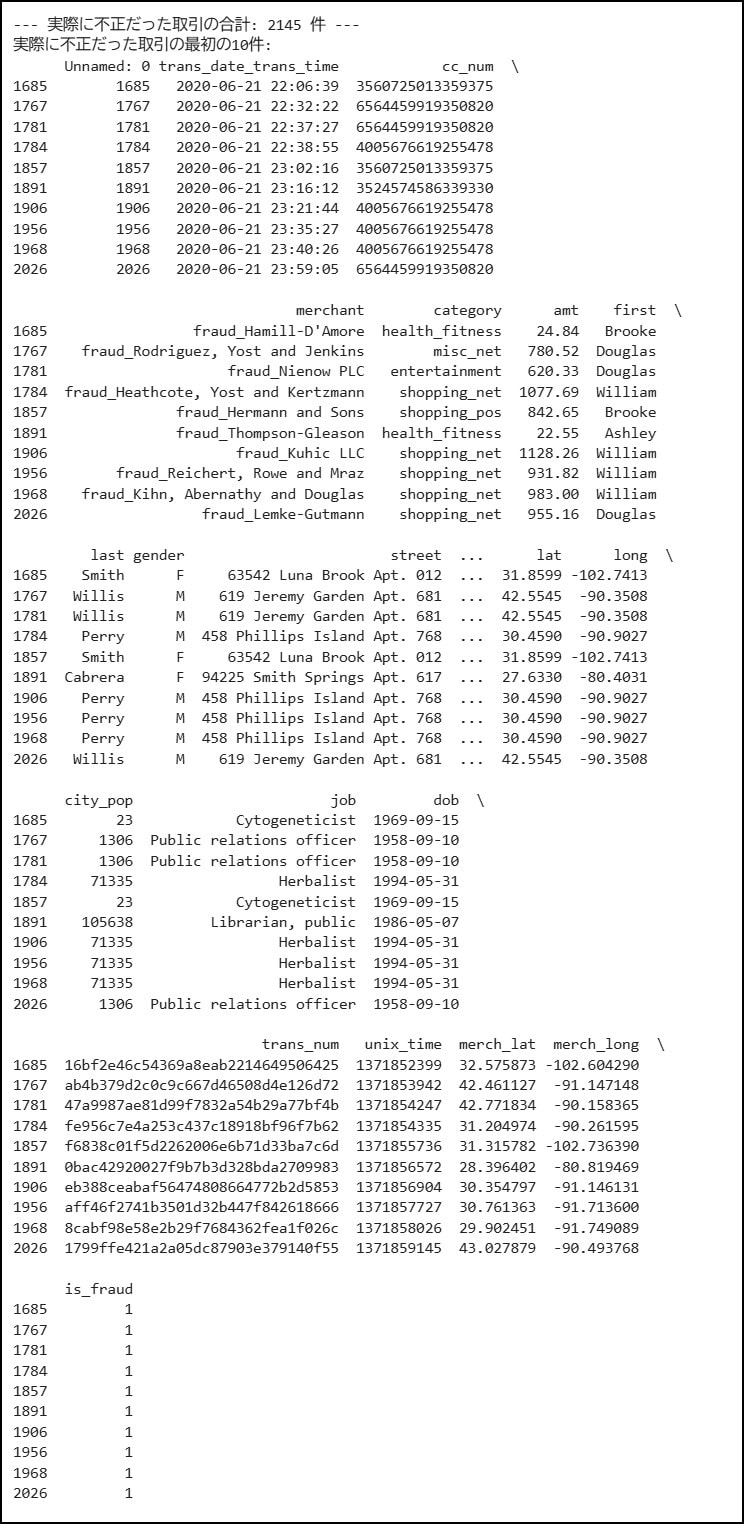
そんでもってこっちが不正と予測した件数です。
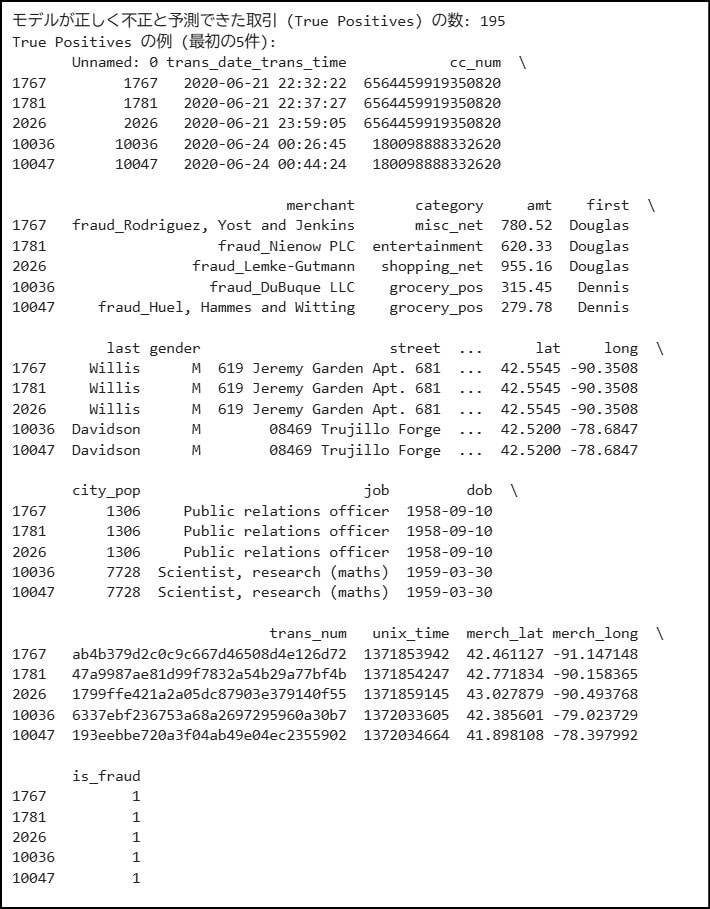
実際に不正だった取引が2145件、不正と予測したのが195件 なので、精度はまだまだですね。
おそらく要因として、今回のデータセット(fraudTrain.csv)内の約130万件の取引のうち、不正取引は7506件(約0.58%)だったことに起因しているんじゃないかと思います。
正常パターンは100万件以上学習できましたが、不正取引パターンを十分に学習しきれていない可能性が高いです。無念。
まとめ的なもの
結論:Amazon Fraud Detector とできること一緒(なのでライフサイクル入りは納得)
今回のブログでは、SageMaker AI Notebooks インスタンス上で、AutoGluon を使った不正検知モデルの構築と、その評価を簡易的に行いました。
十分な学習さえ実施できれば、Fraud Detector の代替として機能できそうです。
実運用に用いる場合ですが、新しい取引データを取り込んでモデルをアップデートさせたり、取引データとの連携がリアルタイムで必要になるため、他サービスとの連携も必須になりそうですね。
モデルの出力は以下記事が参考になりそう
完









