![[プレビュー] S3ベースの低コストなベクトルストレージ「Amazon S3 Vectors」が発表されました (Bedrock Knowledge Basesのベクトルストアとしても使える!)](https://devio2024-media.developers.io/image/upload/f_auto,q_auto,w_3840/v1752646521/user-gen-eyecatch/bplz6zc01wohslamj8yk.png)
[プレビュー] S3ベースの低コストなベクトルストレージ「Amazon S3 Vectors」が発表されました (Bedrock Knowledge Basesのベクトルストアとしても使える!)
みなさん、こんにちは!
福岡オフィスの青柳です。
S3ベースの低コストなベクトルストレージ「Amazon S3 Vectors」がプレビューとして発表されました。
個人的に期待大なサービスが登場した!って感じです。
軽く触ってみましたので、紹介していきます。
どんなサービス?
端的に言うと、以下のように利用できるサービスです。
- 「Amazon OpenSearch Service」などと同じようにベクトルストレージとしてアプリケーションプログラムから利用できる
- Amazon Bedrock Knowledge Basesと組み合わせて安価なRAGを実現できる
他のベクトルストレージサービスと比較して、S3 Vectorsには以下のような特徴があります。
ベクトルストアを低コストで利用可能
S3をベースとしているため、実際に保存したデータ容量のみに対して費用が発生します。(※ 加えてAPIリクエストやクエリ実行に対する費用も発生します)
つまり、「リソースを作成した時点で維持費が発生する」「データを保存する領域を確保した分だけ費用が発生する」といったことがありません。
これに対して他のサービス、例えばRAGでよく使われる「Amazon Kendra」の場合は、リソース (Kendraインデックス) を作成した瞬間から「1時間あたり1.125〜1.4ドル」(月に換算すると810〜1,008ドル) の維持費が発生します。
また、OpenSearch Serverlessは「サーバーレス」と付いていますが、インデックス作成とクエリ実行に必要なコンピューティングリソース (OCU) のために最低でも「1時間あたり0.24ドル」(月に換算すると172.8ドル) が必要です。
S3ベースの高い伸縮性・信頼性
S3 Vectorsで扱えるベクトルデータに関する「数」の制限は、次のようになっています。
- 1つのAWSアカウントに作成できるベクトルバケットの数: 10,000個
- 1つのベクトルバケットに作成できるベクトルインデックスの数: 10,000個
- 1つのベクトルインデックスに保存できるベクトルの数: 5,000万個
また、データ容量に関する制限はありません。
(明確に「データ容量の制限は無い」という記述は見つけることができていませんが、S3ベースであるため制限は無いものと想像しています)
耐久性については、ドキュメントページに「99.999999999% (イレブンナイン) の耐久性」と明記されています。(S3のStandardクラスの耐久性と同じ)
暗号化についても同様に、S3に備わる「SSE-S3暗号化」または「SSE-KMS暗号化」が利用可能です。
リリースノートに「S3 Vectorsは、ペタバイト規模のビデオアーカイブで類似シーンを見つけたり、関連するビジネスドキュメントのコレクションを識別したり、何百万もの医療画像を含む診断コレクションでまれなパターンを検出したりするなどの操作のためのシンプルで柔軟なAPIを提供します」とあるように、大容量のデータを使った検索ソリューションやRAGを構築する場面で、S3 Vectorsは適しているのではないかと思います。
他のベクトルストレージサービスと比べて劣る点
S3 Vectorsはベクトルストレージサービスとして基本的な「ベクトルの保存 (追加)」「ベクトルデータのクエリ」「メタデータによるフィルタリング」といった機能のみを備えています。
OpenSearch Serviceのような「ハイブリッド検索」「高度なフィルタリング」「ファセット検索」といった機能は持っていません。
また、ベクトルデータに特化したデータベースを備え、処理能力のスケールアップも可能なOpenSearch Serviceなどと違って、オブジェクトストレージがベースとなっているS3 Vectorsは、ベクトルデータのクエリ性能 (応答速度) の面で不利である可能性があります。
これに関してはクエリ性能について明示的に言及はされていませんが、リリースノートには「1秒未満のクエリパフォーマンスでデータを保存および検索できます」とあるため、100ミリ秒 (以下) オーダーの処理速度を要求する用途には不向きなのではないかと想像します。
利用可能なリージョン
プレビュー公開時点 (2025-07-15) では以下のリージョンのみ利用可能となっています。
- バージニア北部 (us-east-1)
- オハイオ (us-east-2)
- オレゴン (us-west-2)
- シドニー (ap-southeast-2)
- フランクフルト (eu-central-1)
利用料金
利用料金の体系は以下のようになっています。(バージニア北部リージョンの場合)
ストレージ保管に対して発生する料金
| 料金 (単価) | 単位 |
|---|---|
| 0.06 USD | 1GB・1ヶ月あたり (データサイズと期間) |
APIリクエストに対して発生する料金
| リクエストの種類 | 料金 (単価) | 単位 |
|---|---|---|
| PUTリクエスト | 0.20 USD | 1GBあたり (データサイズ) |
| GET、LIST、その他すべてのリクエスト | 0.055 USD | 1,000リクエストあたり (回数) |
クエリリクエストに対して発生する料金
| 料金 (単価) | 単位 |
|---|---|
| 0.0025 USD | 1,000リクエストあたり (回数) |
クエリで処理されたデータ量に対して発生する料金
| 区分 | 料金 (単価) | 単位 |
|---|---|---|
| 最初の10万個のベクトル | 0.0040 USD | 1TBあたり (データサイズ) |
| 10万個を超えるベクトル | 0.0020 USD | 1TBあたり (データサイズ) |
詳細は下記ページも併せて参照ください。
Amazon S3 pricing (現在のところ英語ページのみ記載あり)
Bedrock Knowledge Basesで「S3 Vectors」を使ってみた
S3 Vectorsは単体でベクトルストレージとして使うこともできるのですが、やはりここは気になる「Amazon Bedrock Knowledge Bases」のベクトルストアとして使うのを試してみました。
今回は「バージニア北部」リージョンを使用しました。(東京リージョンではまだ使えないのでご注意!)
「S3 Vectors」の利用を選択してナレッジベースを作成
ナレッジベースの画面で「作成」をクリックして、「ベクトルストアを含むナレッジベース」を選択します。
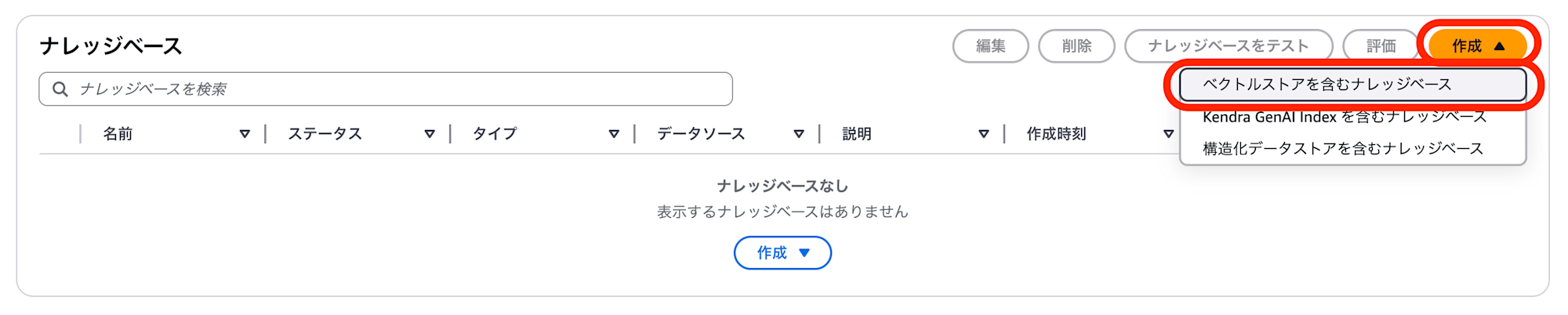
ウィザードの「ステップ1:ナレッジベースの詳細を指定」「ステップ2:データソースを設定」は、通常通り (OpenSearch Serverless等を使う場合と同様に) パラメーターを指定します。
「ステップ3:データストレージと処理を設定」で、次のように設定を行います。
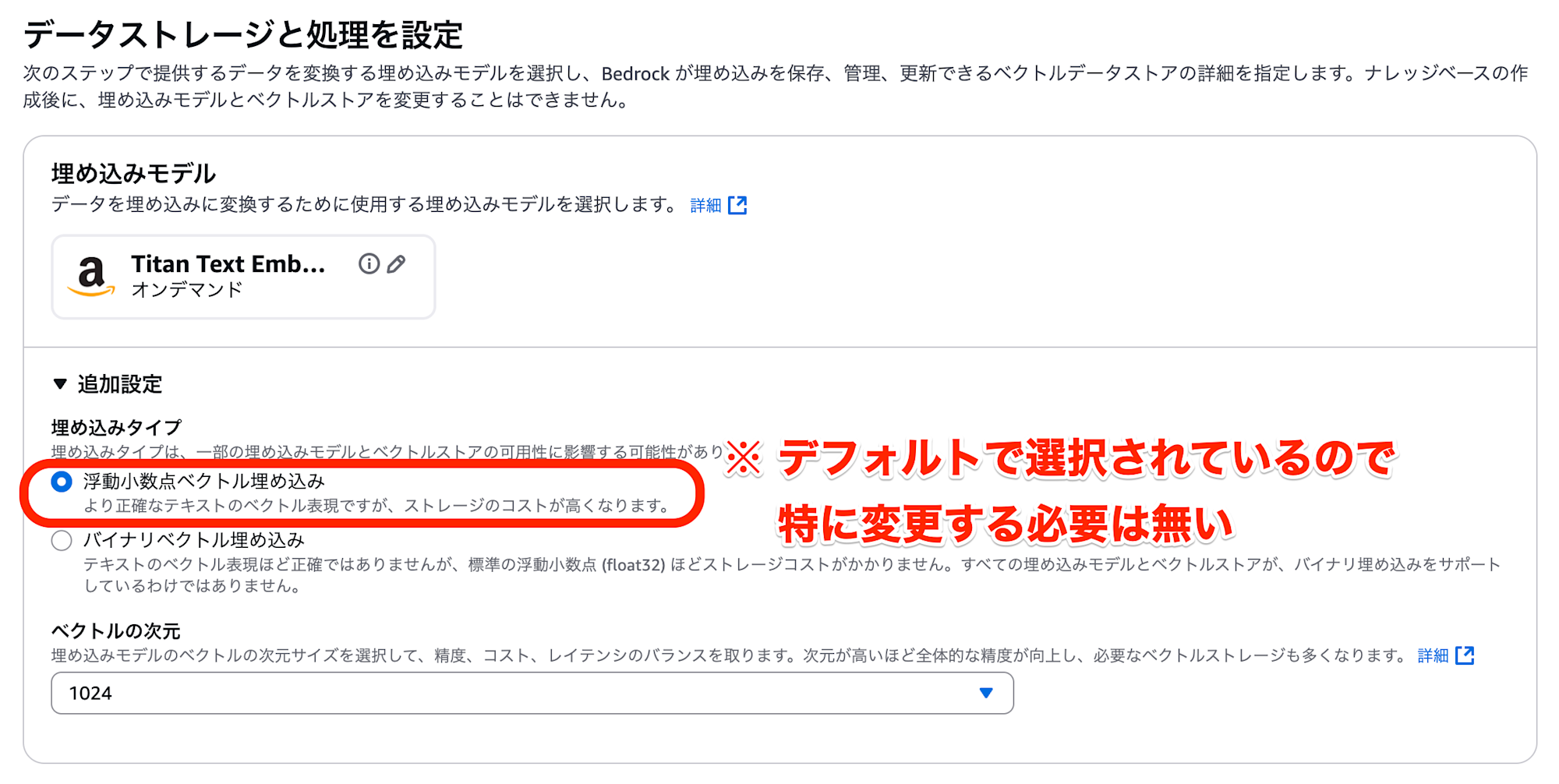
まず、埋め込みモデルの設定で「追加設定」を展開すると「埋め込みタイプ」の選択肢が表示されます。
ここでは「浮動小数点ベクトル埋め込み」を選択するようにします。
(S3 Vectorsは「バイナリベクトル埋め込み」をサポートしていないため:参考情報)
ただし、デフォルトで「浮動小数点ベクトル埋め込み」が選択されていますので、特に変更する必要もないと思います。
次に、ベクトルデータベースの設定で「新しいベクトルストアをクイック作成」を選択した上で、ベクトルストアの種類として「Amazon S3 Vectors」を選択します。
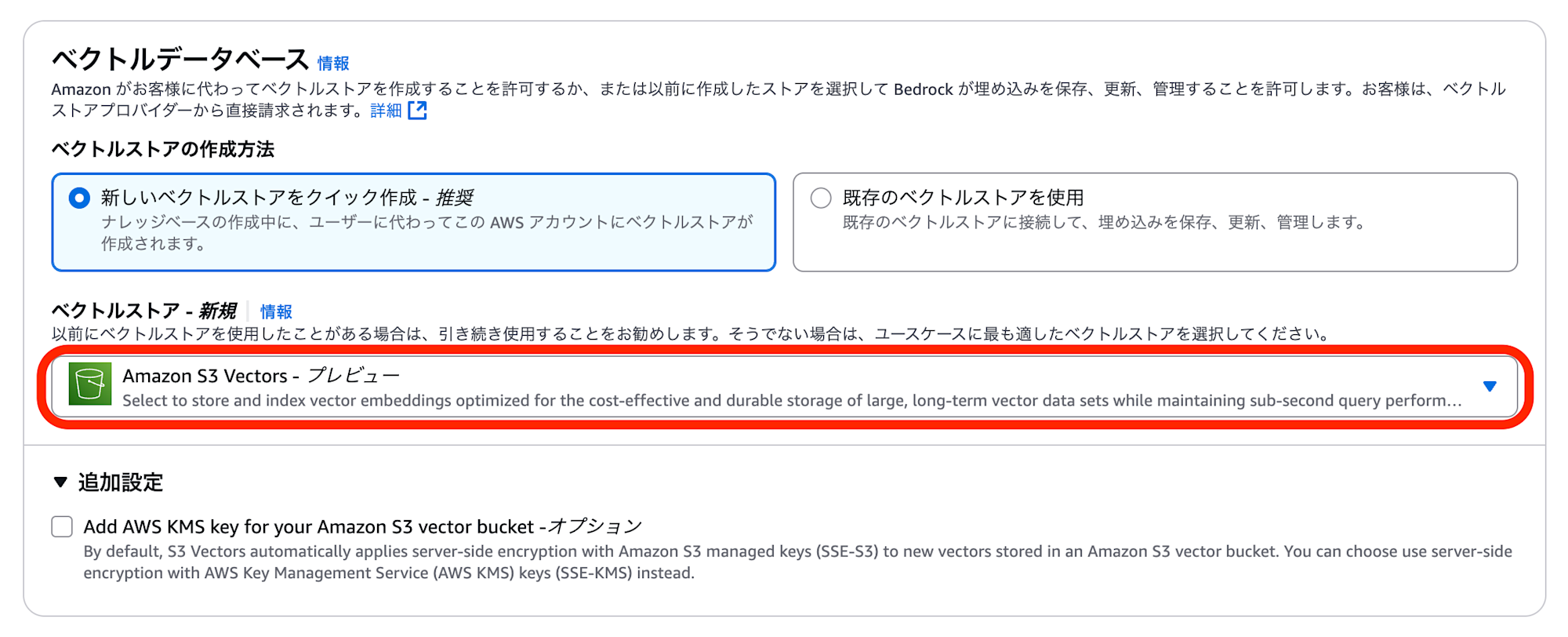
(※ なお、「既存のベクトルストアを使用」を選択して、予め作成したS3 Vectorsのベクトルインデックスを指定することも可能です)
また、ここではS3 Vectorsの「ベクトルバケットの暗号化方式」を選択することが可能です。
デフォルトではチェックボックスにチェックが入っておらず「SSE-S3」が選択されていますが、チェックを入れると「SSE-KMS」を選択することができます。
暗号化方式はベクトルバケット作成後に変更できませんので、SSE-KMSにしたい場合は必ずここで設定してください。
あとは、このままウィザードを進めて、ナレッジベースの作成を完了します。
データソース同期〜RAGのテスト
ここは、他のベクトルデータベースの種類を選択した場合と、手順は変わりません。
データソース (S3バケットなど) にRAGで使用するデータを保存して、ナレッジベースの「データソース」画面で「同期」を実行します。
準備ができましたら、ナレッジベースの「テスト」を実行します。
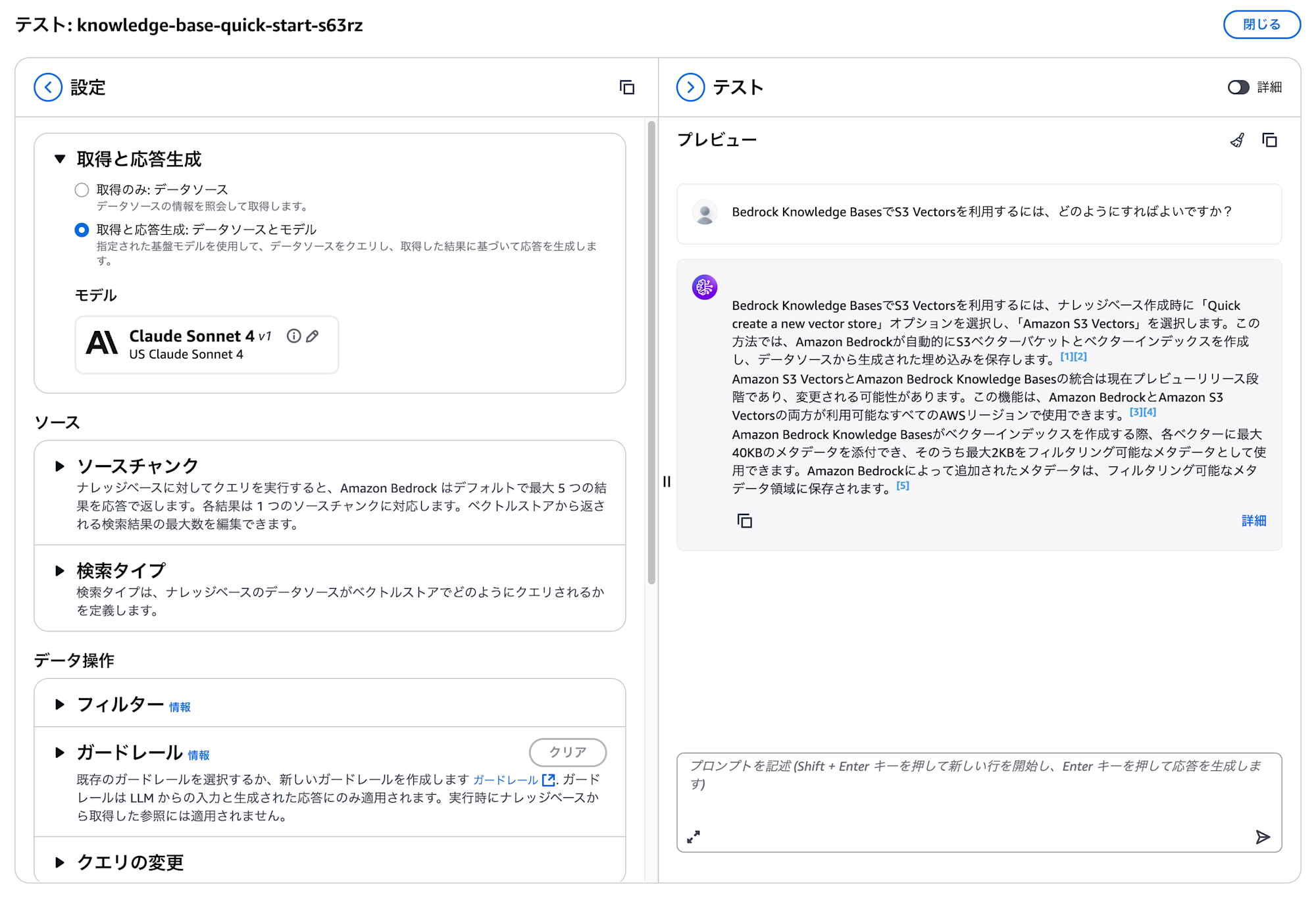
最新のAmazon BedrockドキュメントのPDFをデータソースに投入してS3 Vectorsに関する質問をしてみましたが、ちゃんと回答してくれました。(まあ当然ですね)
プレビュー段階ですのでベンチマーク等を行うつもりはないですが、回答までの時間も特に長いという感じはしませんでした。
(RAGの処理時間の大部分はGenerationのはずですので、そもそもRetrieveの処理時間の違いは分かり辛いですね)
参考1: S3 Vectorsを単体で使用する場合
冒頭でも書きましたように、S3 Vectorsは単体でベクトルストレージとして使うことができます。
現時点では、マネジメントコンソール上で行えるのは「ベクトルバケットの作成」「ベクトルインデックスの作成」のみとなっており、次のような操作は「AWS CLI」「AWS REST API」「AWS SDK」を使用する必要があります。
- ベクトルバケットのプロパティの確認 (暗号化方式など)
- ベクトルバケットのバケットポリシー (リソースベースポリシー) の設定・確認
- ベクトルインデックスへのベクトルデータの追加・削除・表示
- ベクトルインデックスに対するクエリ実行
このあたりは、GAまでにマネジメントコンソールでも操作可能になるんじゃないかと期待しています。
参考2: OpenSearch Serviceとの連係
S3 Vectorsには、以下のOpenSearch Serviceとの連係の機能が用意されています。
S3 VectorsからOpenSearch Serverlessへのエクスポート
S3 Vectorsのベクトルインデックス上のベクトルデータを、OpenSearch Serverlessへエクスポートすることが可能です。
これは、S3 Vectorsを運用していて、性能面・機能面を向上したくなった場合に、OpenSearch Serverlessへの移行を容易に行うために用意された機能かと思います。
S3 Vectors エンジンを使用した OpenSearch
OpenSearchマネージドクラスタで、従来のElasticSearch互換エンジンを使う代わりに、S3 Vectorsを検索エンジン&データストレージとして使うことができます。(これは、OpenSearch Serviceのマネジメントコンソール画面で設定を行います)
ElasticSearch互換エンジンに比べて性能面では劣ると想像されますが、コストを削減することが可能です。
おわりに
Bedrock Knowledge Basesを利用する上で、恐らく多くの方がネックと感じていた「コスト」に対して、解決策となるであろうサービスが (プレビューとして) 登場しました。
機能面や性能面でのトレードオフもあるため、あらゆる場面において「S3 Vectorsがベスト」とは言えませんが、次のような場面ではS3 Vectorsが有力な選択肢になるのではないでしょうか。
- PoCや検証など、小規模なRAGシステムをコストを抑えて利用したい
- 大容量のデータを使ってRAGやベクトル検索のシステムを構築するにあたって、性能面よりもコストを重視したい
GAが楽しみなサービスですね!
今回紹介できなかった機能についても、機会があれば試して紹介したいと思います。









