Amazon S3 Vectorsはサーバーレスなベクトルデータベースだ #jawsugsaga #jawsug
2025年7月にリリースされた Amazon S3 Vectors について、8月11日開催の JAWS-UG佐賀「佐賀の中心でAWSを叫ぶ」 で登壇した内容を共有します。
登壇資料
お伝えしたかったこと
2025年7月にAmazon S3 Vectorsというサービスがリリースされました。
Amazon S3 Vectorsのサービスページでは大規模なベクトルの保存とクエリをネイティブサポートし、最大で90%コスト削減されるとあります。

Amazon OpenSearch ServiceとAmazon S3 Vectorsの連携紹介ブログでは、検索レイテンシーを犠牲にコスト最適化できるとあります。
OpenSearch Service マネージドクラスターは、マネージドサービスの S3 Vectors を使用してコスト最適化されたベクトル格納を行います。この統合により、レイテンシーの増加を許容してでもコストを抑えつつ、高度な OpenSearch の機能 (ハイブリッド検索、高度なフィルタリング、地理フィルタリングなど) を利用したい OpenSearch のワークロードをサポートします。
Amazon S3 Vectorsは以下の特徴をもっています
- Amazon S3 Vectorsはサーバーレスなベクトルデータベース
- 埋め込みベクトルの型(float32)や次元(1024など)により、運用コストが高くなりがちな大規模なベクトルデータに対して1秒程度の遅い検索レイテンシーをトレードオフに低コストで運用できる
- Amazon Bedrock Knowledge Bases(全⽂検索できないことに注意)やAmazon OpenSearch Service(個人的大本命)のバックエンドとしても使える
これを以下の流れで学びます。
- S3 Vectorsを直接使う
- S3 VectorsのAPI操作を学ぶ
- Amazon Bedrock Knowledge Basesと連携
- S3 Vectorsはベクトルデータベースであることを学ぶ
- Amazon OpenSearch Serviceと連携
- S3 Vectorsはなにを解決するのか学ぶ
S3 Vectorsの作り方
S3 Vectorsを使い始めるのは非常に簡単です。主に2つのリソースを作成します
- Vector Bucket:
Vector Indexを格納するための「箱」 - Vector Index : ベクトルデータを効率的に検索するためのインデックスそのもの
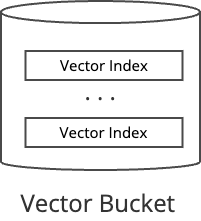
1. Vector Bucketの作成
AWSマネジメントコンソールのS3画面のサイドメニューに「Vector buckets」が追加されています。
ここから、バケット名を指定するだけで簡単に作成できます。
2. Vector Indexの作成
作成したVector Bucketの中に、Vector Indexを作成します。
ここでは、従来のベクトルデータベースと同じく、利用する埋め込みモデルに合わせて、ベクトルの以下の情報を指定します。
- 次元(Dimension)
- 類似度を測る距離(Distance metric)
Amazon S3 Vectorsの作り方のまとめ
S3 Vectorsが提供するのはベクトル検索のインデックスであって、通常のS3バケットのようにオブジェクト(ファイル)を直接管理するわけではありません。
S3 Vectorsの3つの使い方
S3 Vectorsには大きく分けて3つの使い方があります。それぞれのユースケースから、このサービスへの理解を深めていきましょう。
1. S3 Vectorsを直接APIで使う
これは最も基本的な使い方で、S3 Vectorsを検索システムの純粋なベクトルデータベースとして利用するパターンです。
処理の流れ
- テキストや画像などのデータを、埋め込みモデル(Amazon Titanなど)を使ってベクトル化
put_vectorsAPIで、ベクトルデータと関連するメタデータをS3 Vectorsに登録query_vectorsAPIで、検索したいベクトルを投げ、類似するベクトルを検索。
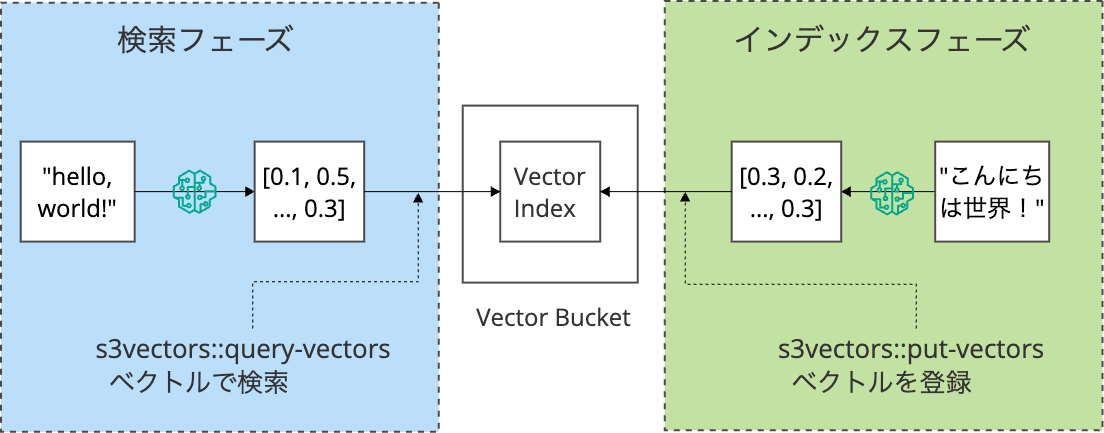
ベクトルデータの登録
Pythonを使ったサンプル(抜粋)
# 埋め込みモデルでテキストをベクトル変換
bedrock = boto3.client("bedrock-runtime")
response = bedrock.invoke_model(
modelId=MODEL_ID, # Amazon Titan 等
body=json.dumps(
{
"inputText": CHUNK,
"embeddingConfig": {"outputEmbeddingLength": DIMENSION},
}
),
)
response_body = json.loads(response["body"].read())
embedding = response_body["embedding"]
# ベクトルの登録 (抜粋)
s3vectors.put_vectors(
vectorBucketName=VECTOR_BUCKET_NAME,
indexName=VECTOR_INDEX_NAME,
vectors=[{
"key": "doc_001",
"data": {"float32": embedding},
"metadata": {"source_text": "これはテストドキュメントです。"}
}]
)
ベクトルデータの検索
Pythonを使ったサンプル(抜粋)
s3vectors = boto3.client("s3vectors")
response = s3vectors.query_vectors(
vectorBucketName=VECTOR_BUCKET_NAME,
indexName=VECTOR_INDEX_NAME,
queryVector={"float32": query_embedding},
topK=3
)
)
print(json.dumps(response["vectors"], indent=2))
以下の様な形式のレスポンスが得られます
[
{
"key": "img/dog-whitepomeranian.jpg",
"metadata": {
"source_path": "img/dog-whitepomeranian.jpg"
},
"distance": 0.5091206431388855
},
…
]
まとめ
以上から、S3 Vectorsはベクトルに特化した ベクトルデータベース であり、データをベクトルに変換して登録・検索できるとわかります。
2. Amazon Bedrock Knowledge Basesと連携
Amazon Bedrock Knowledge Bases(以下、Bedrock KB)は、RAGアプリケーションを簡単に構築できるマネージドサービスです。
このBedrock KBが利用するベクトルストアとして、OpenSearch ServerlessやAurora PostgreSQL Serverless等とともにS3 Vectorsを選択できるようになりました。
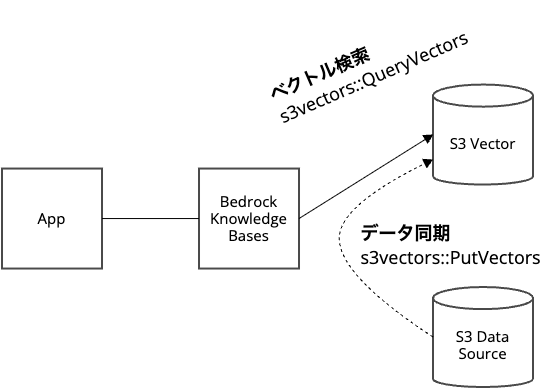
Bedrock KBの データベース として S3 Vectors を選択できるようになったのであり、 データソース としてのS3が無くなるわけではありません。
S3 VectorsとOpenSearch Serverlessの比較
OpenSearch Serverless との主な差異は以下の通りです。
| 機能 | OpenSearch Serverless | S3 Vectors |
|---|---|---|
| 検索方法 | 全文・ベクトルのハイブリッド検索に対応 | ベクトル検索のみ |
| 検索レイテンシー | 小さい(10ms) | 大きい(1秒) |
| 最低コスト | インスタンス費用が発生 ($150/月~) | インスタンス費用は $0、ストレージ費用のみ |
OpenSearch Serverlessの代わりにS3を採用すると、運用コストが下がる一方で、ベクトル検索しか行えず、検索レイテンシーが大きくなることにご注意ください。
なお、Bedrock KB は2025年3月から OpenSearch Service にも対応しています。
3. Amazon OpenSearch Serviceと連携
AWSからはS3 VectorsとOpenSearch連携が2種類紹介されています。
- (今回紹介)OpenSearch ServiceのベクトルデータをS3 Vectorsで管理
- S3 VectorsをOpenSearch Serverlessに移行
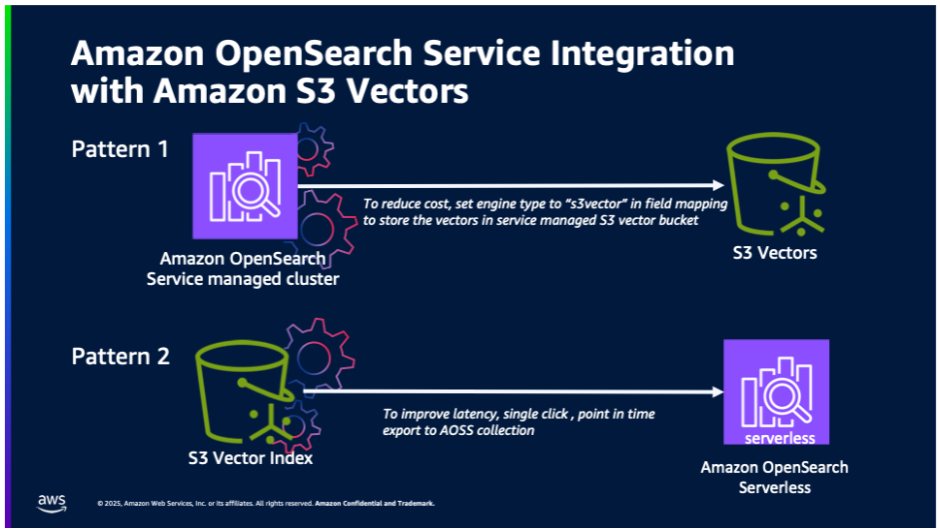
今回は、前者の連携を対象としており、個人的にはこれが大規模かつ低コストにベクトル検索を実現するS3 Vectorsの真価が発揮されるど真ん中のユースケースと思っています。
ブログから引用します。
OpenSearch Service マネージドクラスターは、マネージドサービスの S3 Vectors を使用してコスト最適化されたベクトル格納を行います。
この統合により、レイテンシーの増加を許容してでもコストを抑えつつ、高度な OpenSearch の機能 (ハイブリッド検索、高度なフィルタリング、地理フィルタリングなど) を利用したい OpenSearch のワークロードをサポートします。
OpenSearchでのベクトル検索の設定
ベクトル検索はベクトルが近い=似ているとみなす、類似検索(近似最近傍探索)です。
OpenSearchは検索方法をmethod(アルゴリズム)とengine(methodを実装したライブラリ)で指定します。
ベクトル検索では、以下の通りです。
- method例
- Hierarchical Navigable Small World (HNSW):グラフ探索
- Inverted File Index (IVF) : クラスタリング探索
- engine例
- Lucene : 全文検索エンジンで有名
- Faiss: Facebook AI Similarity Searchの略でOpenSearchの推奨
今回のアップデートは、OpenSearch Serviceのインデックスマッピングで、ベクトルフィールドのengineにs3vectorと指定するだけで、ベクトルデータの管理をS3 Vectorsにオフロードできるというものです。
マッピング例
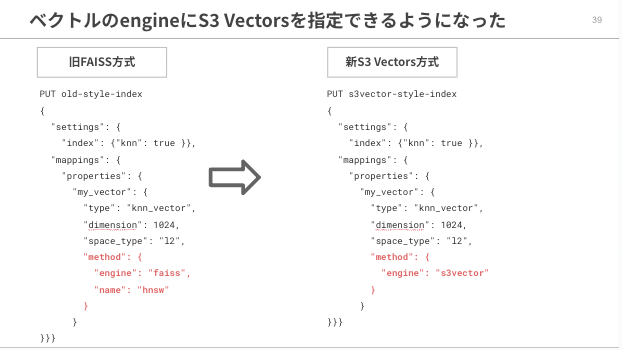
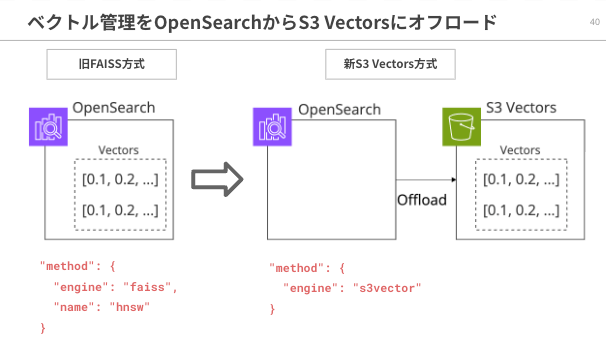
インフラ観点
インデックスのマッピングでは engine が faiss から s3vector に変わっただけですが、インフラ観点では、ベクトルの管理をOpenSearch本体から S3 Vectors にオフロードすることを意味します。
OpenSearchで大規模なベクトル検索は高コスト
OpenSearchのベクトルデータをS3 Vectorsにオフロードできると何が嬉しいかというと、OpenSearchの運用コストを大幅に下げられるからです。
ベクトルデータは多くのストレージを消費します。
仮に埋め込みモデルがfp32(4バイト)で1024次元の場合、ベクトルの実データだけで4KB、100万レコードあると4GBです。
より大量のデータ、レコード内のベクトル以外のデータ、インデックスのストレージなども考慮すると、これだけの容量を求められるOpenSearchは必然的にスペックが高くなり、運用コストも高騰します。
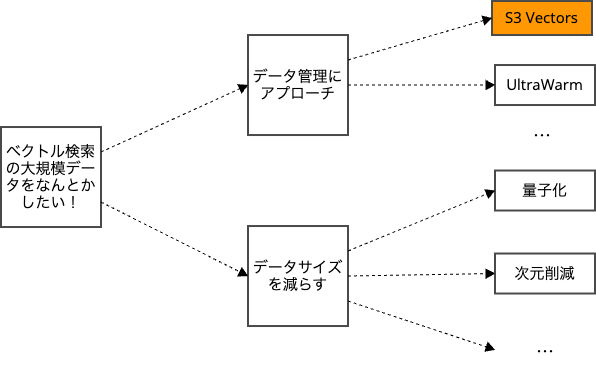
データサイズの大きい高次元ベクトルをなんとかしたい!
大規模なベクトルデータに立ち向かうアプローチはいくつかあります。
ベクトルデータを小さくするアプローチ として、量子化や次元削減などがあります。
S3 Vectorsは ベクトル管理にアプローチし、 検索レイテンシーを犠牲に低コストでデータを運用できます。
S3 Vectors対応しているOpenSearch
Amazon OpenSearchは ServerlessとServiceの2種類があります。
S3 Vectorsが対応しているのは Service 型の OpenSearch Optimizedインスタンスファミリー(OR2/OM2など) でのみ利用可能です。

利用費
最大で 90% 安くなると紹介されている、利用費を計算してみましょう。
利用費は北部バージニアで計算します。
S3 Vectors の利用費
S3 Vectorsの費用は以下の2種類が発生します
- Storage / Month : $0.06/GB
- Requests :
- Put : $0.20/GB
- GET, LIST, その他 : $0.055/1,000 リクエスト
参考 : https://aws.amazon.com/s3/pricing/
料金ページの Pricing example 1 を例にすると
- 1000万ベクトルデータ
- 1ベクトルあたり 6.17KB
- ベクトルそのものは 4 KB : (fp32 x 1024 次元)
- フィルタ可能なメタデータ : 1 KB
- フィルタできないメタデータ : 1 KB
- キー : 0.17 KB
ベクトルの実データを求めると、 6.17 KB/vector * 1000万 = 59 GB です。
1ヶ月のストレージコストは 59 GB * $0.06/GB = $3.54 です。
これに、(細かい計算は端折って)ベクトル登録のPUTリクエストコスト($1.97)や100万/月の検索コスト($5.87)を追加すると、 合計で $11.38/月 となります。
OpenSearch Service の利用費
このデータをOpenSearchでホストすることを考えてみましょう。
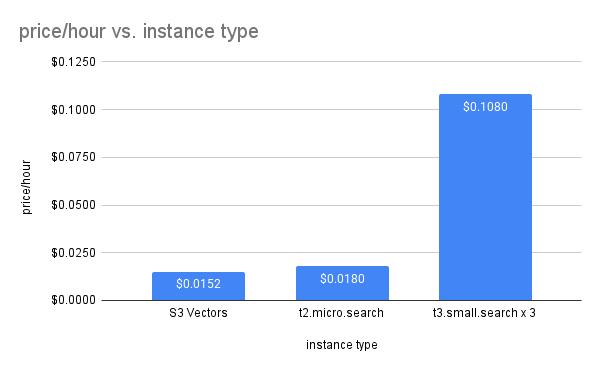
S3 Vectorsの月額を時間単価に直すと $11.38/750 = $0.01517 となります。
この単価は、OpenSearch Serviceの最小スペックの t2.micro.search の時間単価($0.018/hour)よりも さらに安いです。
OpenSearch Serviceのサイジングページにあるように、 split brain を含めた問題を回避するために推奨の3台構成を採用し、スペックが十分かは一旦忘れて t3.small.search でクラスターを組むと、時間単価は $0.036 * 3 = $0.108/hour 。1ヶ月の利用費は $0.108 * 750 = $81 です。
S3 Vectors 時間単価 / OpenSearch 3台構成時間単価 = 0.01517 / 0.108 = 0.14。つまり時間単価が 86%も減っています。
実運用に向けて、マネージドクラスターの採用やインスタンスタイプのスケールアップ、レプリカ追加などを考慮すると、金額差はより顕著になります。
OpenSearch ServiceからS3 Vectorsを呼び出すコスト
OpenSearch ServiceからS3 Vectorsを呼び出す場合の料金体系は現時点では公開されていません。

OpenSearch Serviceには S3やCloudWatch Logs等のデータを検索する Direct Query という機能があり、この機能と同じような利用費が発生するものと思われます。
まとめ
Amazon S3 Vectors はサーバーレスなベクトルデータベースです。特に、大規模ベクトル検索におけるコストという大きな課題に対して、検索レイテンシーを妥協して解決することが期待できます。
手軽に試すなら、 Bedrock Knowledge Bases と組み合わせてRAGを構築するのがおすすめです。ただし、S3 Vectors は全文検索には対応していない点に注意してください。
OpenSearch Service 上でベクトル検索を実現している場合、s3vector エンジンを用いることで、容量の大きなベクトルデータを S3 Vectorsにオフロードできます。これにより、OpenSearchクラスターの規模を大幅に縮小でき、運用コスト削減が期待できます。
一方で、ベクトル検索のレイテンシーは10msのオーダーから1秒程度まで可能性があります。
個人的には、このOpenSearch Service連携がS3 Vectorsの大本命なユースケースと思っています。
最後に
勉強会にあわせて初めて佐賀を訪れる予定だったのですが、当日は西鉄バスが運行を見合わせるほどの悪天候のため、急遽オンライン開催となりました。
フレキシブルに対応してくださった、主催の シバオ(@midnight480)さん 、ありがとうございました!