
ざっくり理解するAmazon Athenaの概要と使い方
最近AWS認定のCertified Data Engineer - Associate(DEA)を受験しました。
Data Engineerという名の通りデータエンジニアリングに関するサービスを中心に問題が構成されていますが、本試験で頻出、かつ今回解説するAmazon Athenaはデータエンジニアリング系の業務でなくとも触れる機会が多いというか、一般的なシステム開発でも効果的に使うことができる場面が多いのではないかと思い、概要を整理したくブログを書くことにしました。
もろもろの詳細な仕様については公式ドキュメントやAWS Black Beltを参照するのが良いと思いますので、今回はわかりやすさ重視で進めていきます。
本記事を読んでほしい人
- Amazon Athenaの概要をざっくり把握したい人
- AWS認定(特にData Engineer Associate)の勉強中で、Athenaの基本を押さえたい人
- 試験でよく出る単語などは 太文字で 記載しておきます
- 実際のAWSコンソール画面でAthenaがどう使われるのかをイメージしたい人
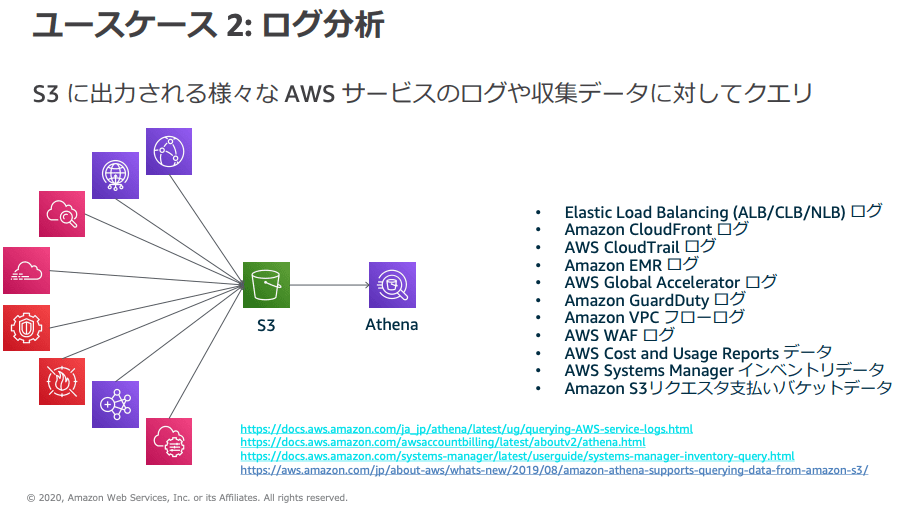
Amazon Athenaとは
公式ドキュメントによると、Amazon Athenaは標準的なSQLを利用してS3のデータを直接分析できるサーバーレスなサービスです。
ざっくり言うと「S3に置いたCSVやJSONなどのファイルに対して、SQLでクエリを実行できる」サービスになります。
フェデレーテッドクエリ
「S3のデータをクエリするサービス」という説明が多いですが、S3以外のデータソースにもクエリできます。大きく分けると2つの方式があります。
- S3直接クエリ: 最も一般的な使い方
- フェデレーテッドクエリ(Federated Query): S3以外のデータソースに対してもSQLでクエリできる機能
フェデレーテッドクエリとは、S3以外のデータソース(Amazon RDS、Amazon DynamoDB、Amazon Redshift、さらにはオンプレミスのDBなど)に対して、データをS3に移動させることなくAthenaから直接SQLでクエリできる機能です。仕組みとしてはAWS Lambda経由でデータソースに接続しており、複数のデータソースを1つのSQLで横断することも可能です。
対応しているデータソースは30以上あり、DynamoDB、Redshift、Timestreamなど主要なAWSサービスのほか、MySQL / PostgreSQL / SQL ServerなどのRDBや、CloudWatch / CloudWatch Metricsにも対応しています。
AWS認定でもたびたび出てくるキーワードなので、「フェデレーテッドクエリ = S3以外のあらゆるデータソースにAthenaからクエリできる機能」と覚えておくと良いと思います。
なお、CloudWatchに対してはCloudWatch Logs Insightsというログ検索機能がありますが、CloudWatch Logsの保持期間やコストの問題から長期保存分はS3にエクスポートしてAthenaで分析するという使い分けが実務では多いようです。日常的なリアルタイム調査はLogs Insights、長期間・横断的な分析はAthenaという棲み分けですね。
今回の記事では一般的なS3からのクエリに焦点を当てて進めていきます。
AthenaがS3からクエリするときの流れ
AthenaでS3のデータをクエリするまでの流れは以下のようになります。
- テーブル定義: クエリ先のS3の場所とデータの構造をAthenaに教える
- AWS Glue Data Catalogに保存: テーブル名、カラム名、データ型、S3パス、データ形式などのスキーマ情報がカタログに登録される
- AthenaからSQLを実行
- Athenaがデータを読み取り: Glue Data Catalogからスキーマ情報を参照し、S3上のデータを読み取って結果を返す
ここで重要なのがschema-on-read(読み取り時にスキーマを適用) という考え方です。従来のRDBはデータを入れるときにスキーマに合わせますが(schema-on-write)、Athenaはクエリを実行するタイミングでスキーマを被せてデータを解釈するという仕組みになっています。結果として、S3上の元データには一切手が加わらず読み取り専用で分析ができるというわけですね。
また、AWS Glue Data Catalogは「どのS3パスに、どんな形式で、どんなカラム構造のデータがあるか」を管理するメタデータストアです。Athena専用ではなく、Amazon Redshift SpectrumやAmazon EMRなど他のサービスからも同じカタログを参照できます。これもAWS認定で頻出するサービスですね。
対応しているデータ形式
AthenaはCSVやJSONのほか、ビッグデータ処理でよく使われる以下のフォーマットにも対応しています。
- Parquet: ビッグデータ処理に最適化されたオープンソースの列指向(カラムナ)データ保存フォーマット
- ORC(Optimized Row Columnar): Apache Hiveなどのビッグデータ基盤で利用される列指向の高性能データ圧縮ファイル形式
- Avro: JSONで定義されたスキーマを用いてデータを高速・コンパクトにバイナリシリアライズするデータ形式
パーティションとパーティションプロジェクション
パーティションとは
パーティションとは、S3上のデータをフォルダで分割して整理する仕組みです。
例えば、パーティションなしで全データが1つのフォルダにある場合、クエリ時にすべてのファイルをスキャンすることになりますが
# /logs 以下に全ファイル保存
s3://my-bucket/logs/
├── log001.csv
├── log002.csv
├── ... (数万ファイル)
└── log99999.csv
日付でパーティションを切っておくと、WHERE year='2026' AND month='01' AND day='15' のように指定することで該当フォルダだけをスキャンできます。
# /logs 以下にさらに year/month/day でパーティションを切る
s3://my-bucket/logs/
├── year=2025/month=12/day=01/
│ └── data.csv
├── year=2025/month=12/day=02/
│ └── data.csv
└── year=2026/month=01/day=15/
└── data.csv
不要なデータを読み飛ばすことで、クエリが速くなり、スキャン量も減るのでコストも下がります。
パーティションプロジェクション
通常、パーティションを使うにはAWS Glue Data Catalogにパーティション情報の登録が必要です。新しいデータが増えるたびにMSCK REPAIR TABLEを実行したり、AWS Glue Crawlerを動かすなどの管理作業が発生します。
パーティションプロジェクションを使うと、テーブル作成時のDDLでパーティションの範囲(yearは2025〜2026、monthは1〜12など)を宣言しておくだけで、Athenaが自動でパーティションを算出してくれます。Glueへのパーティション登録が不要になるのが大きなメリットです。
時系列データに対しては、S3を日時ベースのパーティション構造にし、パーティションプロジェクションを使うのが王道パターンのようです。AWS公式ドキュメントでもCloudTrail、ALBアクセスログ、CloudFront、VPC Flow Logs、WAFなど主要サービスのログに対して、この構成でのテーブル作成手順が紹介されています。
料金とコスト最適化
Athenaはスキャンしたデータ量に対して課金される料金モデルです(1TBあたり約$5)。
コストを最適化するポイントは2つあります。
- パーティション: 日付などでパーティションを切ることで、必要な範囲だけスキャンして不要なデータの読み込みを避ける
- データ形式: 列指向フォーマット(Parquet、ORC)を使うと、必要なカラムだけを読み取るためCSV/JSONよりスキャン量を抑えられる
- データ形式をParquetに変更してクエリ効率UPは試験でよくでる
パーティションで行方向の読み取り範囲を絞り、列指向フォーマットで列方向の読み取り範囲を絞る、というのがAthenaのコスト最適化の基本的な考え方になります。
実際にやってみる
ここからは実際にS3にテストデータを配置して、Athenaでクエリを実行してみます。
Claude Codeにお願いしてそれっぽいデータを用意してもらいました。
テストデータの準備
今回は、工場に設置された機械センサーが1時間ごとにデータを送信してくるシナリオを想定します。
デバイス構成:
| device_id | location | device_type | 説明 |
|---|---|---|---|
| sensor-001 | factory-A | temperature-humidity | 工場Aの温湿度センサー |
| sensor-002 | factory-A | pressure | 工場Aの気圧センサー |
| sensor-003 | factory-B | temperature-humidity | 工場Bの温湿度センサー |
データ項目:
| フィールド | 型 | 説明 |
|---|---|---|
| device_id | string | デバイスID |
| location | string | 設置場所 |
| device_type | string | センサー種別 |
| timestamp | string | 記録日時(ISO 8601) |
| temperature | double | 温度 |
| humidity | double | 湿度 |
| pressure | double | 気圧 |
| status | string | normal / warning / error |
statusはtemperatureの値に応じて自動判定される想定です。temperature > 88なら「error」、> 82なら「warning」、それ以外は「normal」としています。あとでこのstatusを使ってクエリしてみます。
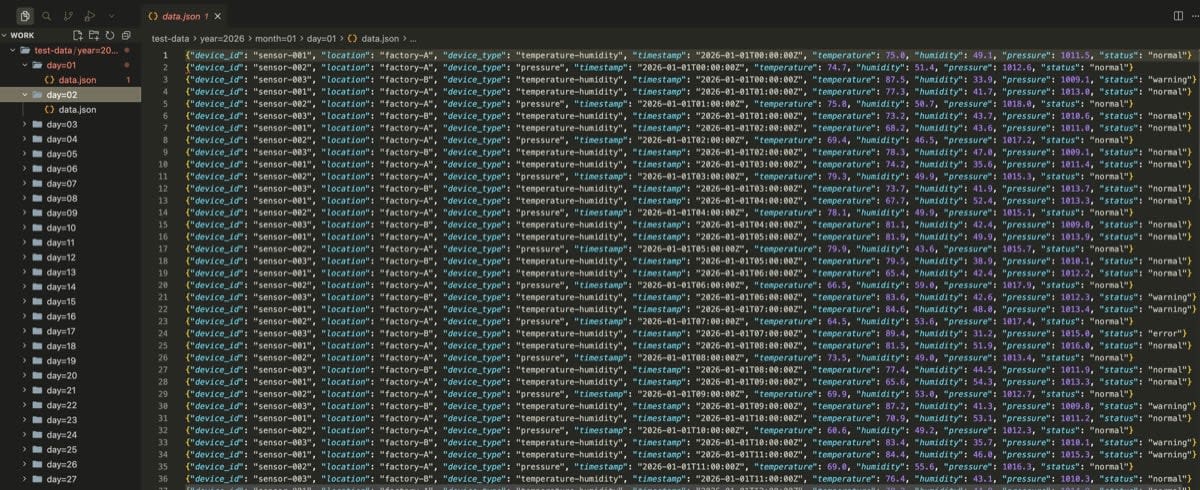
データはせっかくなのでParquet等を試そうかと思いましたが、馴染み深いJSON Lines形式(1行に1つのJSONオブジェクト)で作成しました。Athenaは1行 = 1レコードとして読み取るので、通常の配列で囲むJSON形式ではなく、このJSON Lines形式が適しています。
jsonファイルの中身はこんな感じ
1hごとに3つの機器がデータを送信 = 1日で72jsonレコード
72jsonオブジェクトを1日分のデータとして1つのjsonにまとめて、S3の各フォルダに配置する
を1月分
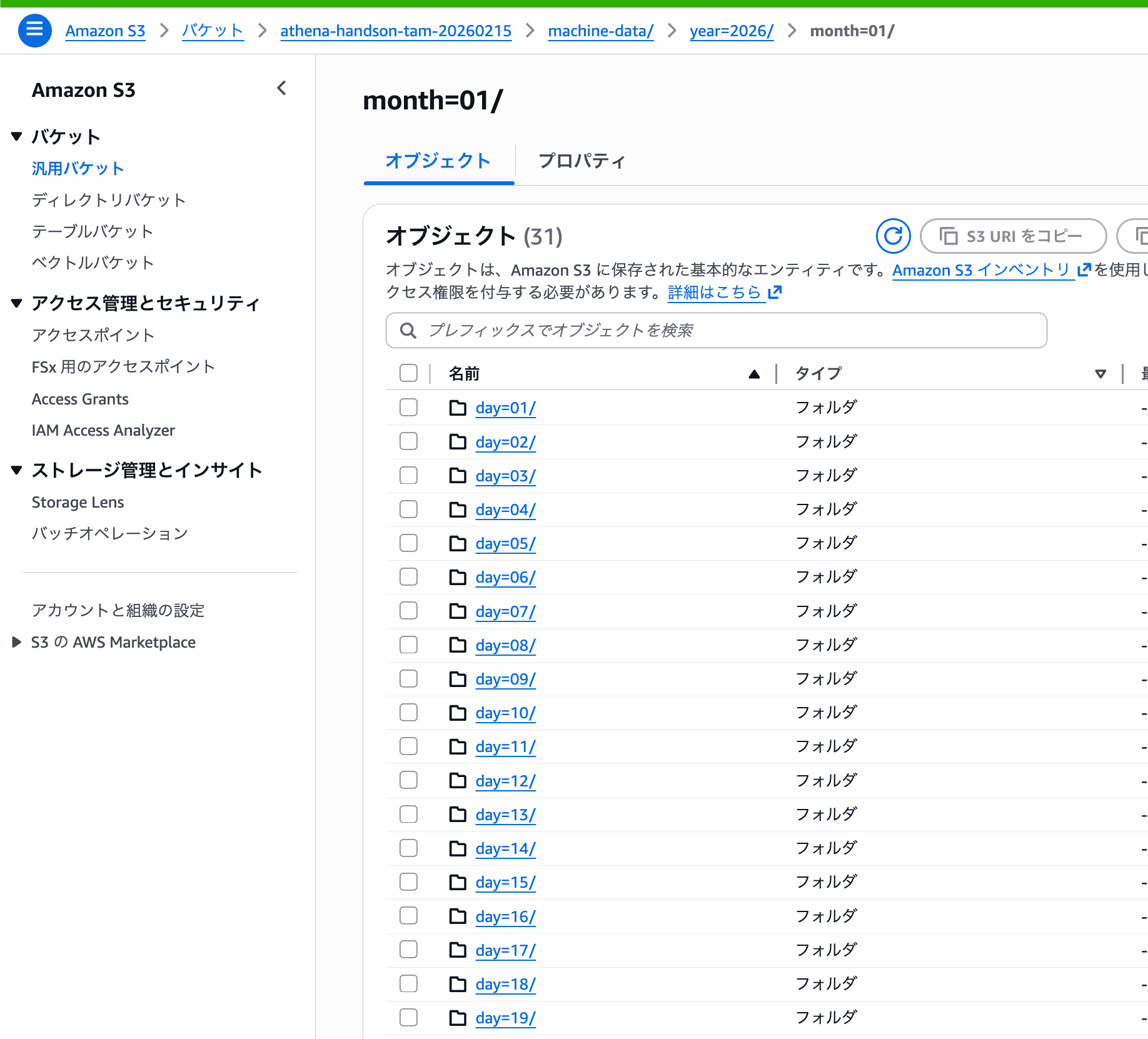
S3のフォルダ構造
S3のフォルダ構成ですが、ClaudeにHive形式(key=valueのフォルダ名)を勧められたのでそれでパーティションを構成しました。
s3://athena-handson-tam-20260215/machine-data/
└── year=2026/
└── month=01/
├── day=01/
│ └── data.json
├── day=02/
│ └── data.json
└── ...(31日分)
Hive形式にする理由としては、パーティションプロジェクションとの相性が良いためとのことです。自分でフォルダ構造を設計できる場合はHive形式が推奨されているみたいです。
# Hive形式(key=value)
year=2026/month=01/day=01/data.json
# 非Hive形式(値だけ)
2026/01/01/data.json
非Hive形式はCloudTrailなどAWSサービスが自動出力するログでよく見られるパターンです。この場合はパーティションプロジェクションのstorage.location.templateで対応できます。
Athenaの初期設定:クエリ結果の保存先
Athenaを初めて使うとき、クエリ結果の保存先S3バケットを設定する必要があります。
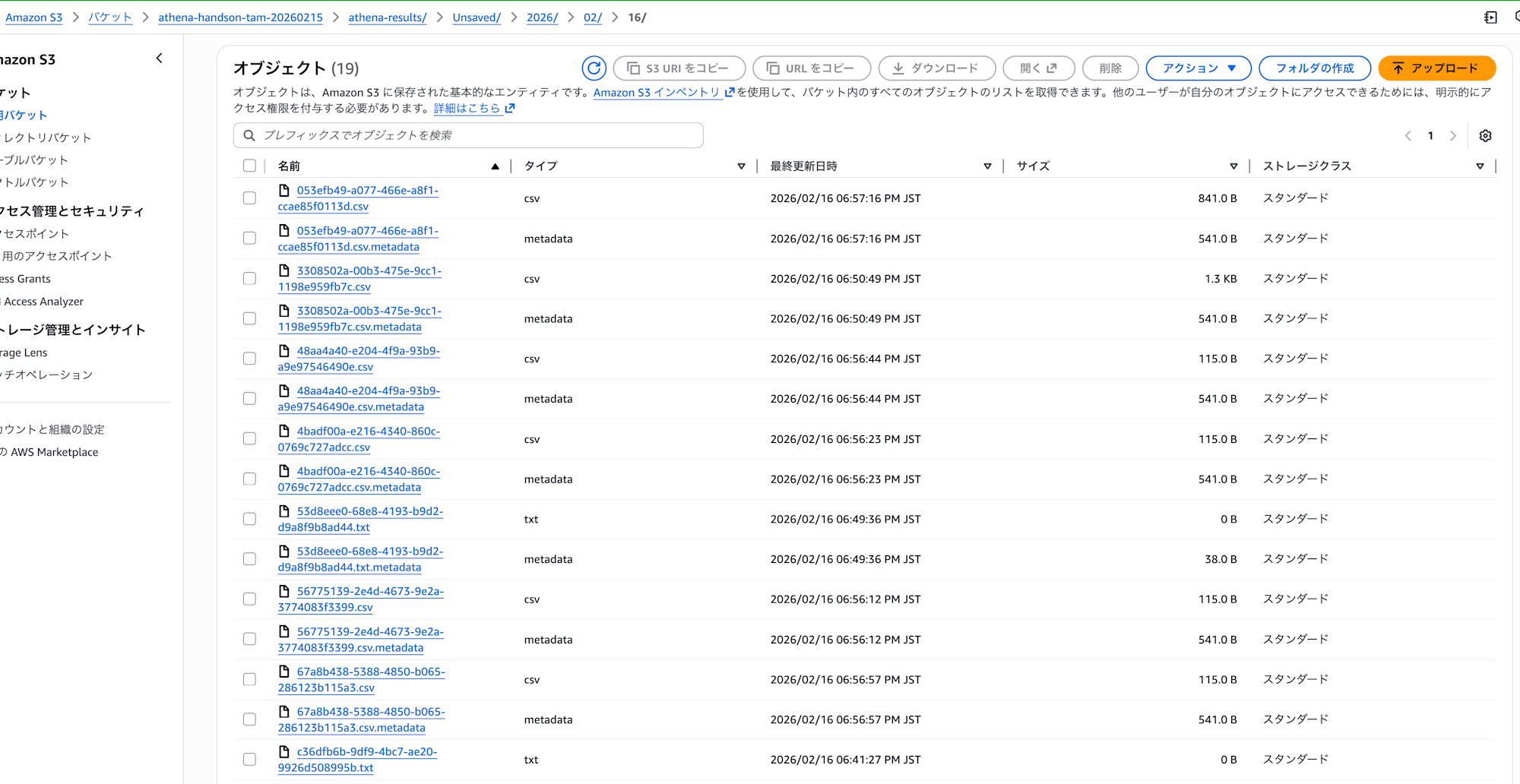
クエリ結果保存先バケットには下記のファイルが保存されます
QueryID.csv `CSV`: SELECTなどのDMLクエリの実行結果
QueryID.txt `テキスト`: CREATE TABLEなどのDDLクエリの結果
QueryID.csv.metadata `バイナリ`: クエリのメタデータ(人間が読む用ではない)
実際に見てみるとこんな感じです
基本的にこのクエリ結果ファイルを参照することはあまりなさそう?
クエリ結果保存先の設定に戻ります
Athenaコンソールのクエリエディタを開くと、以下のような通知が表示されます。
「設定を編集」からクエリ結果の保存先を設定します。
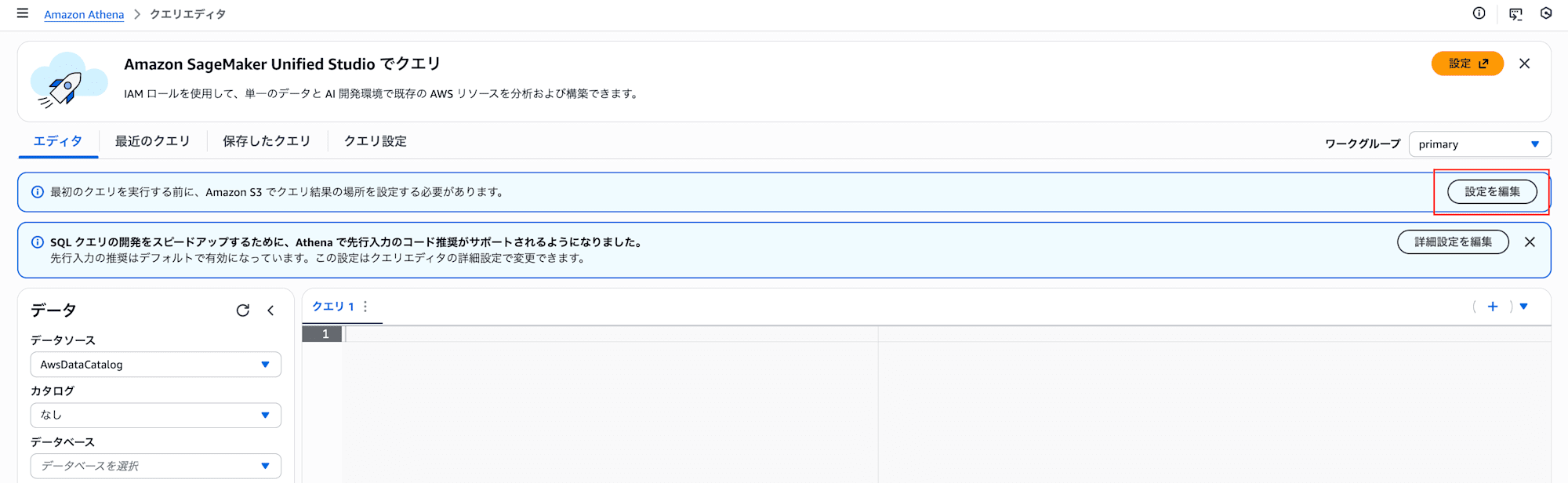
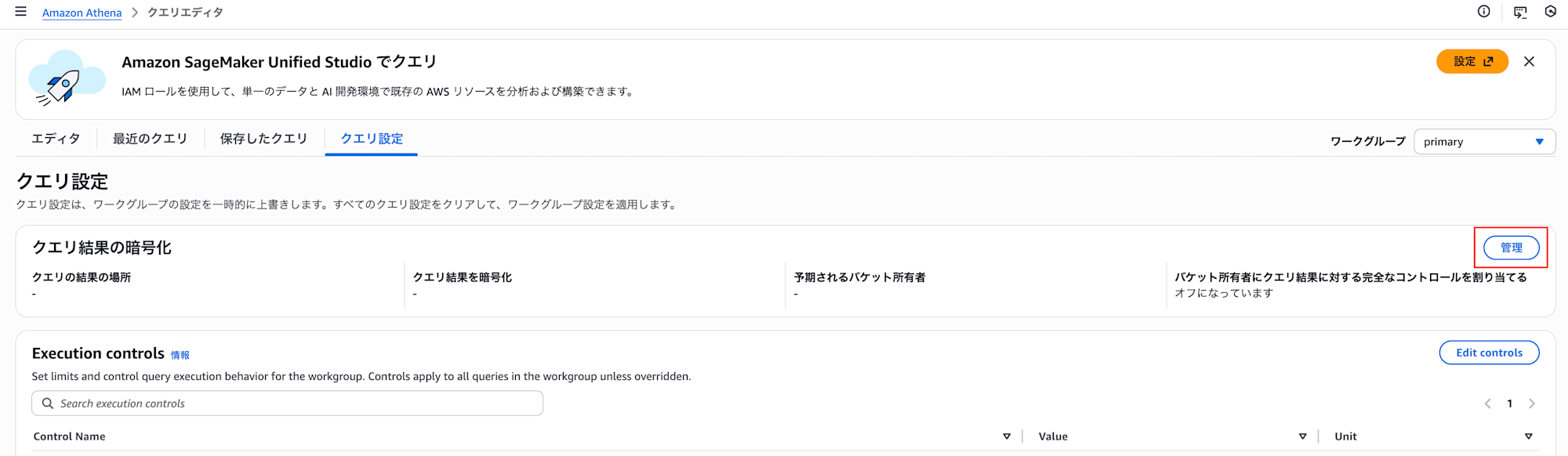
「クエリ設定」より「管理」
こちらはS3の画面ですが、今回はテストデータを保存しているバケット内に athena-results/ というプレフィックスを作成し、そこを保存先に指定することにします。
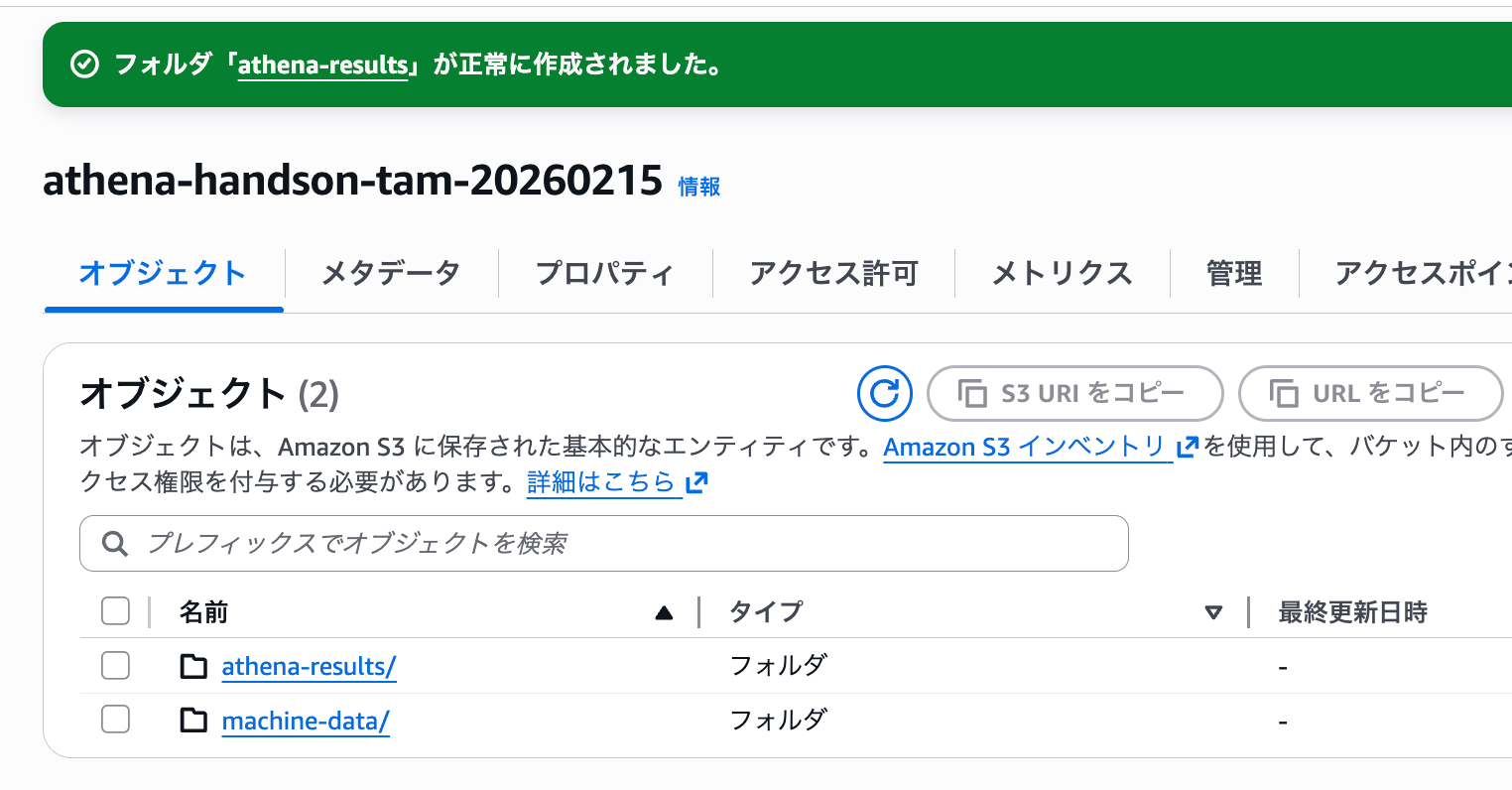
「Browse S3」からさっき作成したathena-results/ をクエリ結果保存先として設定します
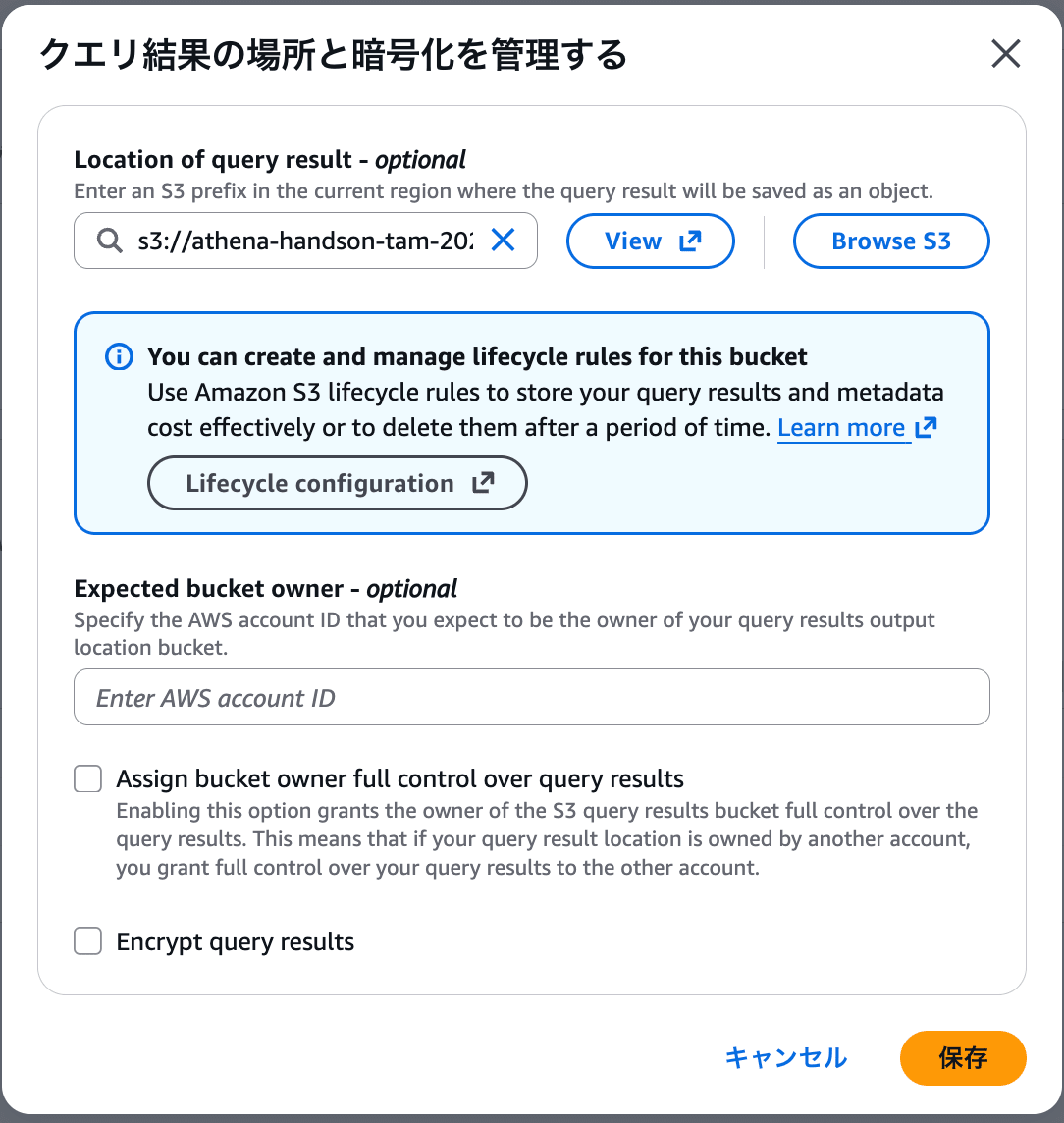
ちなみにAthenaはクエリを実行するたびに結果ファイル(CSV等)をこの保存先に出力するので、クエリを繰り返すとファイルが溜まっていきます。設定画面に注記として表示されている「Lifecycle configuration」からライフサイクルルールを設定すれば一定期間後に自動削除することもできます。
データベース作成
ここからはAthenaの画面にて、データベースとテーブルを作成していきます。
まずはクエリエディタで以下のDDLを実行し、handsonという名前でデータベースを作成します。
CREATE DATABASE IF NOT EXISTS handson;
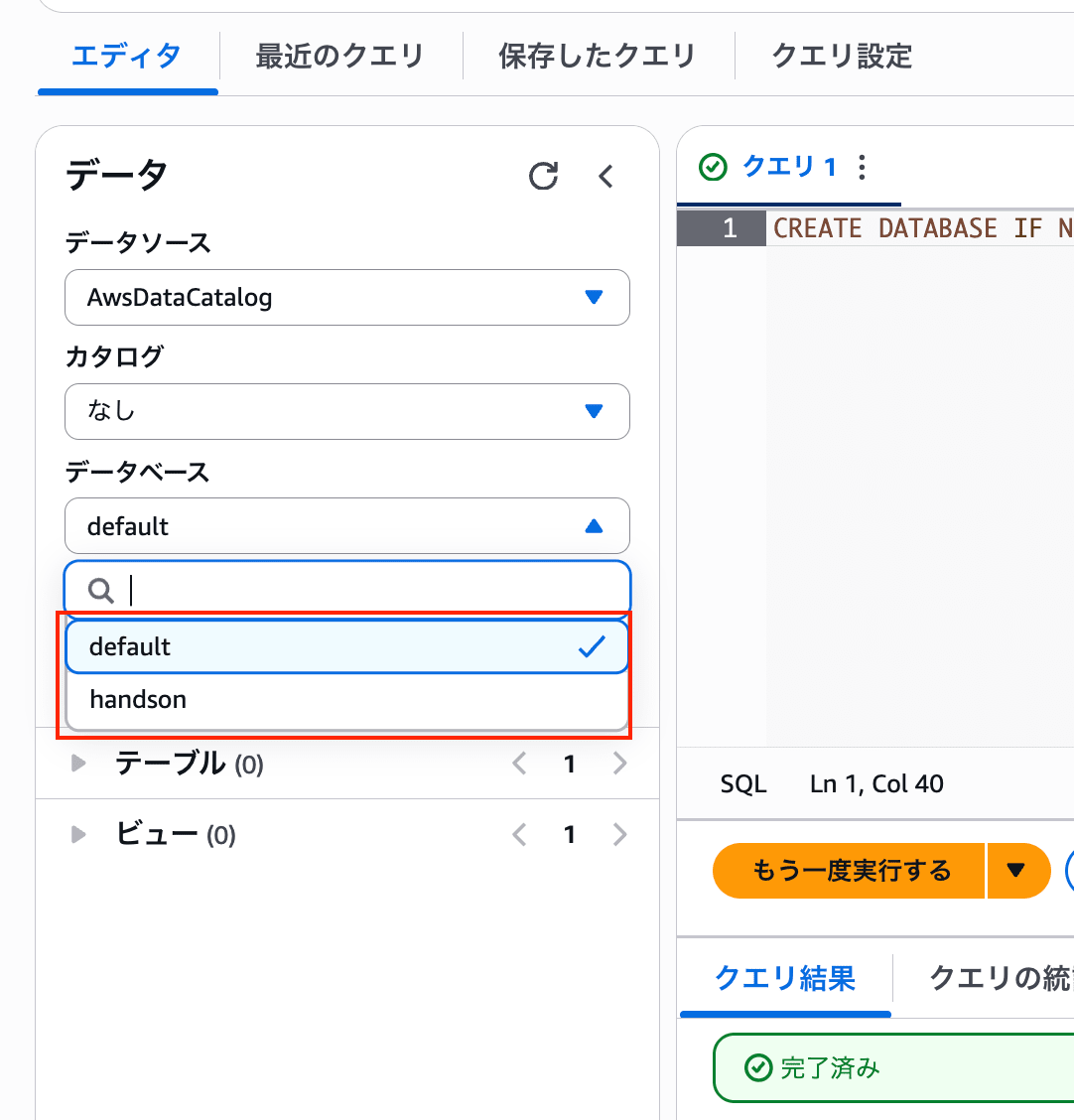
作成後、左側パネルのデータベース選択で handson を選択します。
テーブル作成(パーティションプロジェクション)
続いて、パーティションプロジェクションを使ったテーブルを作成します。
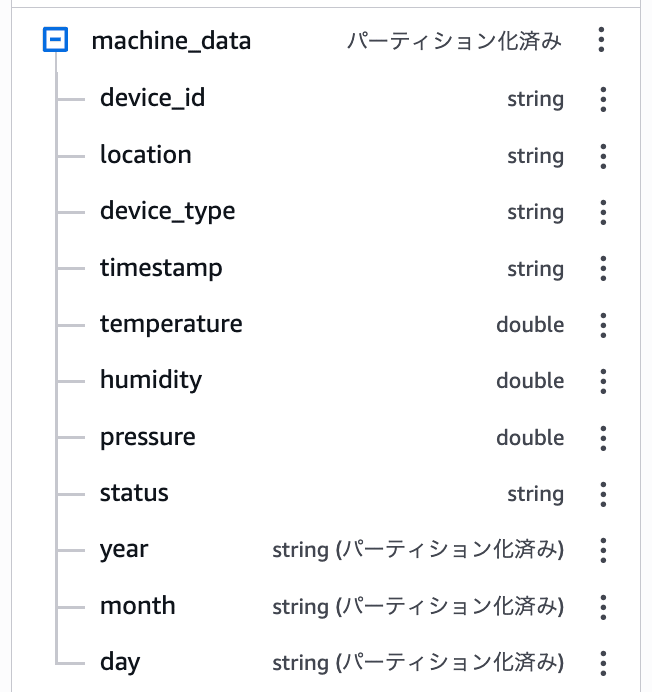
CREATE EXTERNAL TABLE handson.machine_data (
device_id STRING,
location STRING,
device_type STRING,
timestamp STRING,
temperature DOUBLE,
humidity DOUBLE,
pressure DOUBLE,
status STRING
)
PARTITIONED BY (year STRING, month STRING, day STRING)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
LOCATION 's3://athena-handson-tam-20260215/machine-data/'
TBLPROPERTIES (
'projection.enabled' = 'true',
'projection.year.type' = 'integer',
'projection.year.range' = '2026,2026',
'projection.month.type' = 'integer',
'projection.month.range' = '1,12',
'projection.month.digits' = '2',
'projection.day.type' = 'integer',
'projection.day.range' = '1,31',
'projection.day.digits' = '2',
'storage.location.template' = 's3://athena-handson-tam-20260215/machine-data/year=${year}/month=${month}/day=${day}'
);
DDLがちょっとややこしいので各部分を順番に解説します。
テーブル定義:
CREATE EXTERNAL TABLE handson.machine_data (
device_id STRING,
location STRING,
device_type STRING,
timestamp STRING,
temperature DOUBLE,
humidity DOUBLE,
pressure DOUBLE,
status STRING
)
CREATE EXTERNAL TABLE でS3上のデータを参照する外部テーブルを作成します。EXTERNALを指定しているためテーブルを削除してもS3のデータは消えません。カラム定義はJSONの各フィールドに対応する名前と型を宣言しています。
パーティション定義:
PARTITIONED BY (year STRING, month STRING, day STRING)
パーティションに使うカラムを指定します。これらはS3のフォルダ構造(year=2026/month=01/day=01)から値が決まるためJSONデータ内のフィールドとは別です。
データ形式の指定:
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
S3上のファイルをJSON Lines形式として読み取るためのSerDe(Serializer/Deserializer)を指定しています。CSVやParquetの場合は別のSerDeを指定します。
テーブルプロパティ(パーティションプロジェクション):
TBLPROPERTIES (
'projection.enabled' = 'true', -- パーティションプロジェクションを有効化
'projection.year.type' = 'integer', -- yearは整数型
'projection.year.range' = '2026,2026', -- yearの範囲
'projection.month.range' = '1,12', -- monthの範囲(1〜12)
'projection.month.digits' = '2', -- monthは2桁(01, 02, ...)
...
'storage.location.template' = 's3://.../${year}/...' -- S3パスとの対応
)
本来はAWS Glue Data Catalogにパーティション情報を登録する作業が必要ですが、パーティションプロジェクションを使うことでその手間をなくすことができています。
テーブル作成が成功すると、以下のようにテーブルが確認できます。
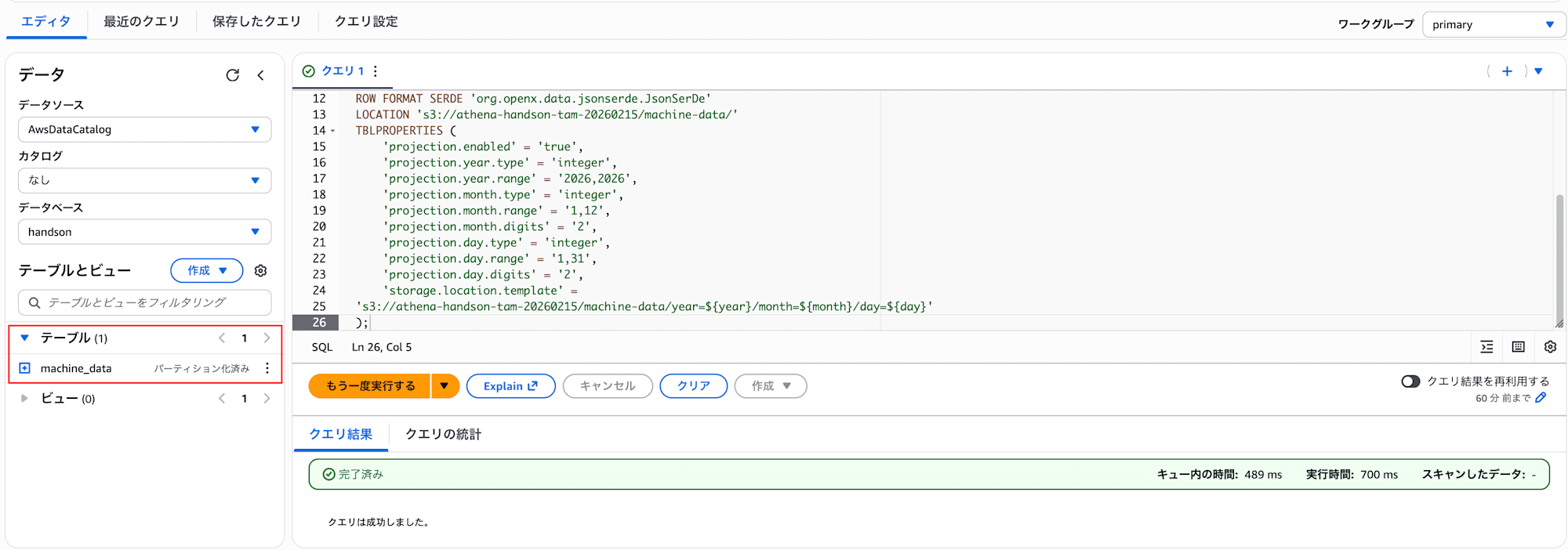
クエリを実行してみる
テーブルが作成できたので、実際にクエリを実行してみます。
1月1日のデータを10件取得:
SELECT *
FROM handson.machine_data
WHERE year = '2026' AND month = '01' AND day = '01'
ORDER BY timestamp ASC
LIMIT 10;
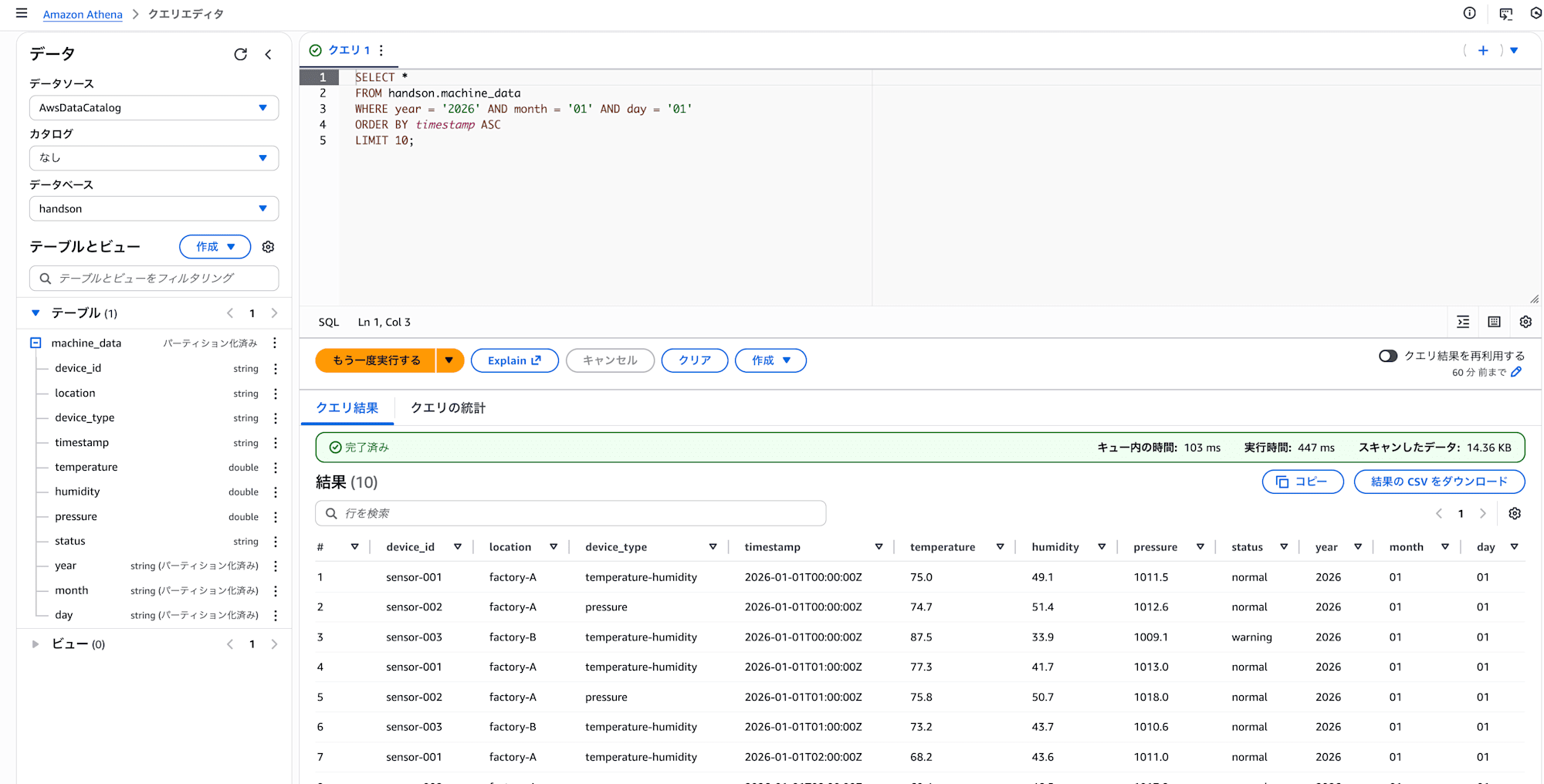
クエリが成功すると、結果が下のタブに表示されます
お馴染みのSQLでS3に置いたJSONの内容がちゃんと検索できていますね。
特定のケースを調べる:
次に、もう少し実践的なケースをやってみます。「2026/01/04でsensor-003のstatusがwarningになったとき」を調べてみましょう。
SELECT *
FROM handson.machine_data
WHERE year = '2026' AND month = '01' AND day = '04'
AND device_id = 'sensor-003'
AND status = 'warning'
ORDER BY timestamp ASC;
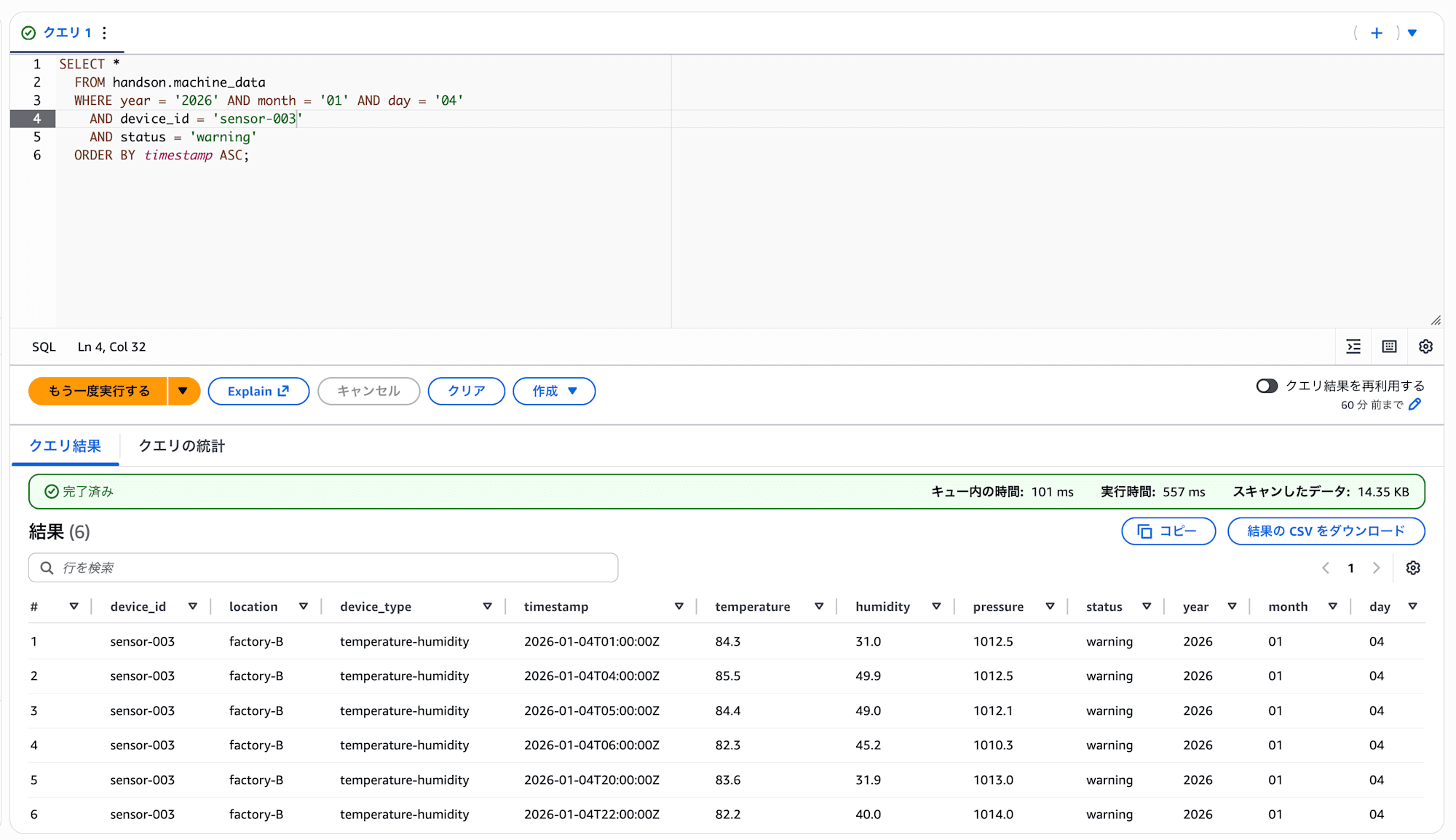
WHERE句でパーティション(year/month/day)を指定してスキャン範囲を絞りつつ、device_idやstatusでさらに絞り込んでいます。
こんな感じで、S3上のデータに対していろいろなクエリが実行できます。愚直にやるとS3からファイルをローカルにダウンロードして検索をかけて...となるところを、Athenaならクエリひとつで済むのでかなり楽ですね。しかも読み取り専用なので元のS3のデータを汚す心配もありません。
以上、Amazon Athenaの概要と簡単な使い方の解説でした。
S3からデータを検索するためにAthenaを使う、というケースは結構発生しがちだと思いますが、保存先S3の設定やGlue Data Catalogへパーティション情報を登録したりDDLを書いたりと、Athenaの初期設定は意外と手間があるので参考になれば幸いです。








