
Aurora カスタムエンドポイントはフェイルオーバーでどう変化する?Serverless v2 で 6 パターン(+派生 2)を検証してみた
はじめに
LINE/アプリ DevOps チームの及川です。
Aurora の reader インスタンスを用途別に分離したい、というケースは多いのではないでしょうか。例えば「サービス本体の読み取りクエリ」と「分析・外部連携系の重いクエリ」を別々の reader に固定し、お互いに影響を与えないようにしたい、といったケースです。
Aurora には reader エンドポイント(AWS ドキュメントの表記では「リーダーエンドポイント」。本記事ではインスタンスの役割を writer / reader と表記するため、こちらに揃えます)がありますが、これは全 reader に接続を分散させるため、特定のワークロードを特定の reader に固定できません。そこで登場するのがカスタムエンドポイントですが、いざ採用を検討すると、こんな疑問が出てきます。
- そもそも読み取り負荷への対処として、reader を増やすのと ACU を上げるのと比べて、カスタムエンドポイントを選ぶ理由は何か?
- フェイルオーバーが起きたとき、カスタムエンドポイントのメンバはどう変化するのか?
- カスタムエンドポイント配下の reader が予期せぬ障害で落ちたら、接続はどうなるのか?復旧するのか?本番で使って大丈夫なのか?
この疑問については 2019 年に同様の検証をされた記事があり、本検証でも大変参考にさせていただきました。ただ約 7 年前の検証で、当時はプロビジョンドの 2 台構成でした。その間に仕様が変わっている可能性もあるため、今回は Aurora PostgreSQL Serverless v2 + 3 インスタンス構成で、6 パターンに、その派生パターン 2 つを加えて改めて検証してみました。
この記事で紹介すること
- 読み取り負荷への対処として「ACU を上げる」「reader を増やす」「カスタムエンドポイントで分離する」をどう使い分けるか
- カスタムエンドポイント 6 パターン(TYPE × メンバ指定方式)それぞれのフェイルオーバー時の挙動
- フェイルオーバーの昇格先が「メンバ内」か「メンバ外」かで結果が変わること(3 台構成ならではの観点です)
- reader 単体障害(再起動)時のカスタムエンドポイントの挙動
- フェイルオーバー時の接続断時間の実測値(毎回つなぎ直す接続と、つなぎっぱなしの接続の違い)
- カスタムエンドポイント経由の負荷分離と ACU スケーリングの実測
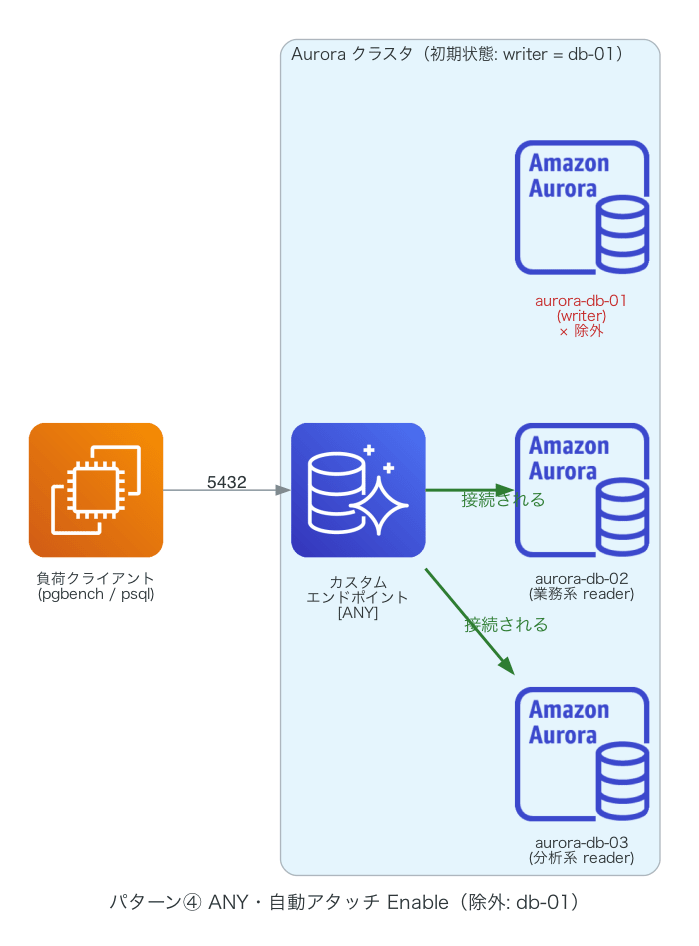
なお、Aurora Serverless v2 や CDK 自体の基本的な説明は割愛しますが、前提だけ少し補足します。Aurora クラスタは書き込みできる writer 1 台と読み取り専用の reader 複数台で構成され、アプリは個々のインスタンスではなくエンドポイント(DNS 名)に接続します。カスタムエンドポイントは、その接続先の集合を自分で決められる追加のエンドポイントで、対象とする役割(READER / ANY)と、メンバの指定方式(名指しの静的リスト、または「これ以外すべて」の除外リスト = 自動アタッチ)を設定できます。
Aurora クラスターのカスタムエンドポイントは、選択した DB インスタンスのセットを表します。カスタムエンドポイントに接続すると、Aurora は接続バランシングを行い、グループ内のいずれかのインスタンスを選択して接続を処理します。ユーザーは、このエンドポイントで参照するインスタンスを定義し、エンドポイントの用途を決めます。
メンバの指定方式(静的リスト / 除外リスト)については、次のページで説明されています。
カスタムエンドポイントに含めたり、カスタムエンドポイントから除外したりする DB インスタンスのリストを定義できます。これらのリストは、それぞれ静的リストおよび除外リストと呼ばれます。
検証の結果はすべて実測ログと CloudWatch メトリクスに基づいています。掲載するログは読みやすさのため、IP アドレスをインスタンス名に、環境固有の文字列を xxxx に置換し、注釈(←)と中略を加えていますが、値そのものには手を加えていません。グラフも CloudWatch の値(1 分粒度)をそのまま描画したものです。
結論
先に、調査結果からの結論をまとめます。
- 読み取り負荷への対処は「ACU を上げる」「reader を増やす」「カスタムエンドポイントで分離する」の 3 つがあり、それぞれ解決する問題が違う
- カスタムエンドポイントは性能を伸ばすための手段ではなく、重いワークロードを隔離するための手段
それぞれが解決する問題を、今回の実測結果と合わせて整理すると次のようになります(ACU は Aurora Capacity Unit。Serverless v2 のスケールと課金の単位です)。
| 選択肢 | 解決すること | 解決しないこと・注意点 |
|---|---|---|
| ACU の上限を上げる | 1 台あたりの処理能力。設定変更のみで済み、実測では負荷開始 1 分以内に 0.5 → 4.0 ACU へ自動追従 | 重いクエリと軽いクエリの同居は解消されない。max ACU を上げるほどコストの上限も上がる |
| reader を増やす | 読み取りの総量。標準 reader エンドポイントが自動で分散する(実測で db-02 : db-03 = 107 : 123、ほぼ半々) | 接続先は選べないため、重い分析クエリの影響が全 reader に及びうる |
| カスタムエンドポイントで分離する | 特定ワークロードの接続先固定と、相互影響の遮断(実測で完全分離) | 障害時の挙動の理解が必須(本記事の主題)。構成を誤ると全断するパターンもある |
補足すると、性能を上げたいだけなら ACU の引き上げや reader 追加で足りることも多く、分離が必要になって初めてカスタムエンドポイントの出番になります。
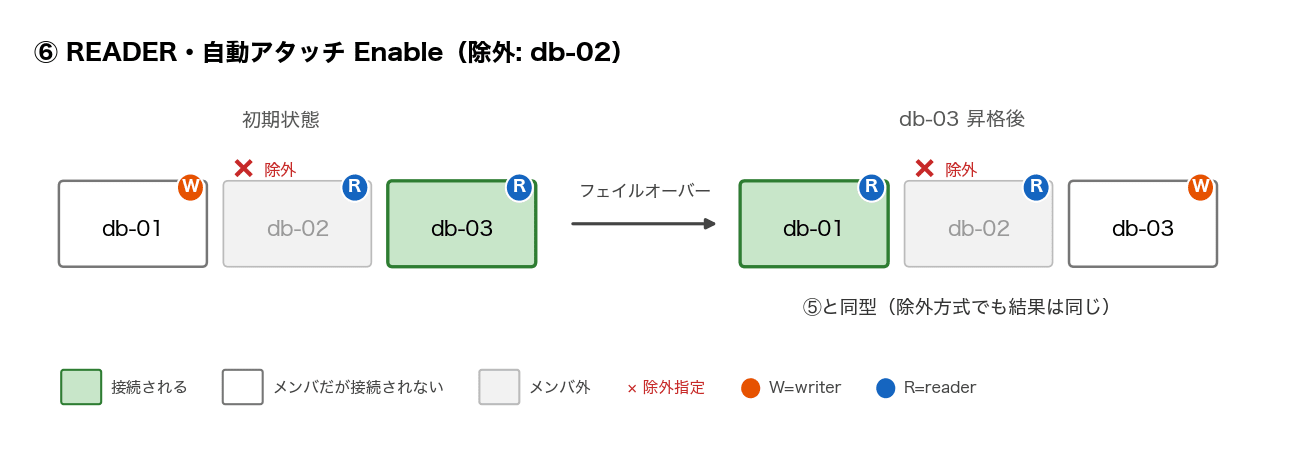
そのうえで、カスタムエンドポイントを採用する場合のパターン別早見表がこちらです。3 台構成(writer: db-01、reader: db-02 / db-03)で、各パターンのカスタムエンドポイントに接続し続けながらフェイルオーバーを実行した結果です。表中の ①′ と ②′ は、それぞれ ① と ② から派生させたパターンです。①′ は ① のメンバを 1 台に絞ったもの、②′ は ② の除外指定をなくしたもので、挙動の仕組みを切り分けるために追加しました。
表の読み方を補足します。
- TYPE … エンドポイントを繋ぐ相手の役割。
READERは reader だけ、ANYは writer / reader のどちらにも繋ぐ - 自動アタッチ … メンバの決め方。
Disable(静的リスト)はメンバを名指しで固定する方式(あとから増えたインスタンスは自動で加わらない)、Enable(除外リスト)は「除外した ID 以外すべて」をメンバにする方式(あとから増えたインスタンスも自動で加わる) - db-03 / db-02 昇格後 … そのインスタンスが writer に昇格するフェイルオーバーの後、エンドポイントが実際に繋いだ先
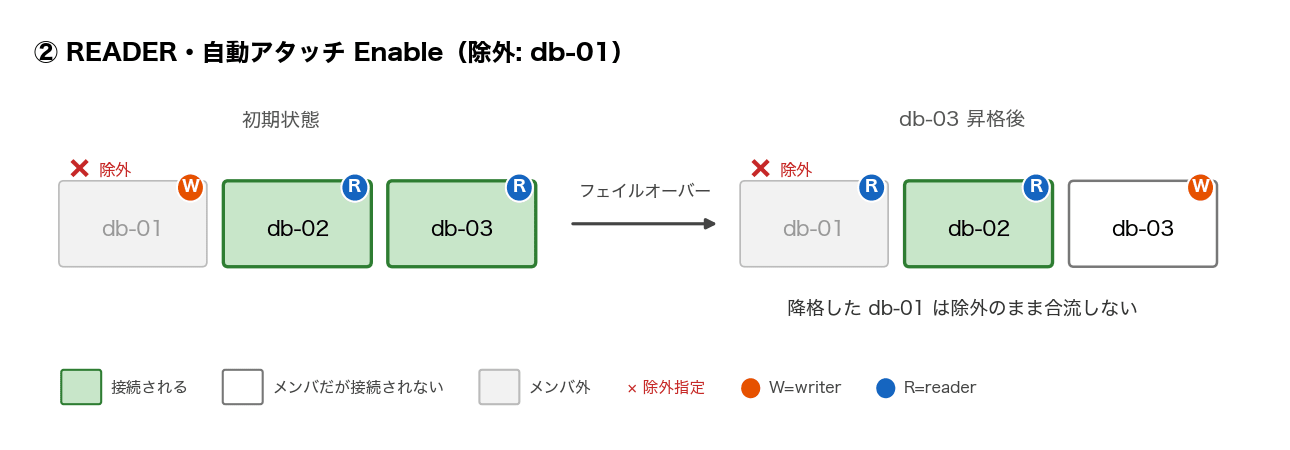
例えば②は「reader にだけ繋ぐ・db-01 を除外」という設定なので、db-03 が writer に昇格すると、writer になった db-03 は対象から外れ、db-01 は除外されたまま残り、結果として db-02 だけに繋がります。
| No | TYPE | 自動アタッチ | 初期メンバ / 除外 | db-03 昇格後の接続先(メンバ内昇格) | db-02 昇格後の接続先(メンバ外昇格) |
|---|---|---|---|---|---|
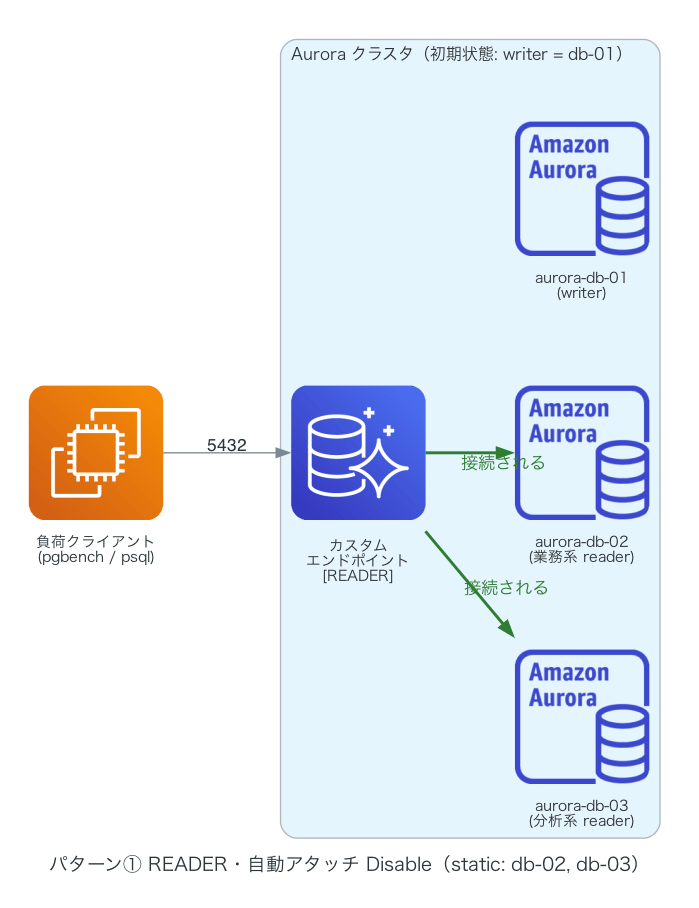
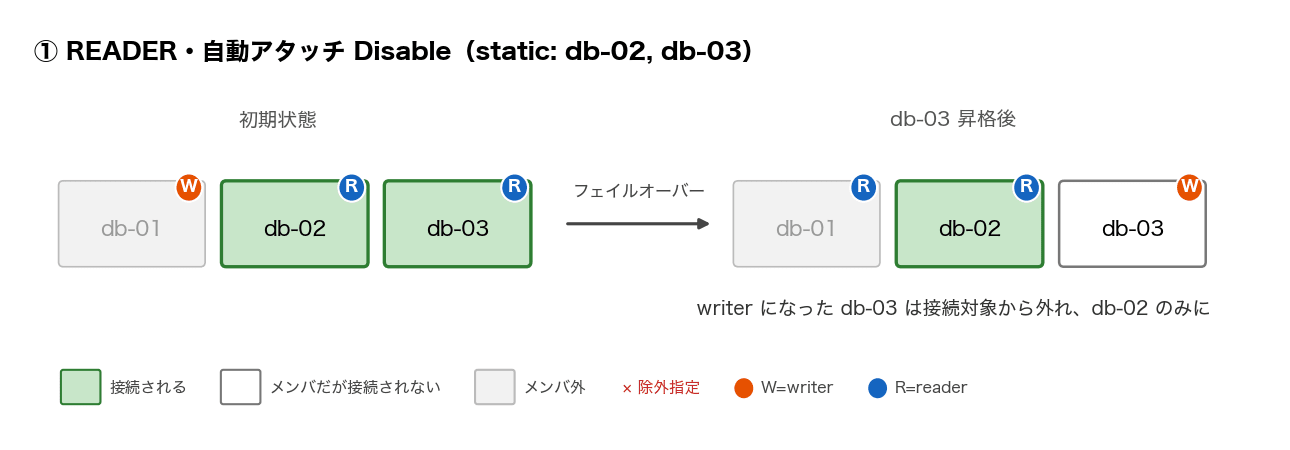
| ① | READER | Disable(静的リスト) | db-02, db-03 | db-02 のみ | db-03 のみ |
| ② | READER | Enable(除外リスト) | db-01 を除外 | db-02 のみ(降格した db-01 は合流しない) | db-03 のみ(同左) |
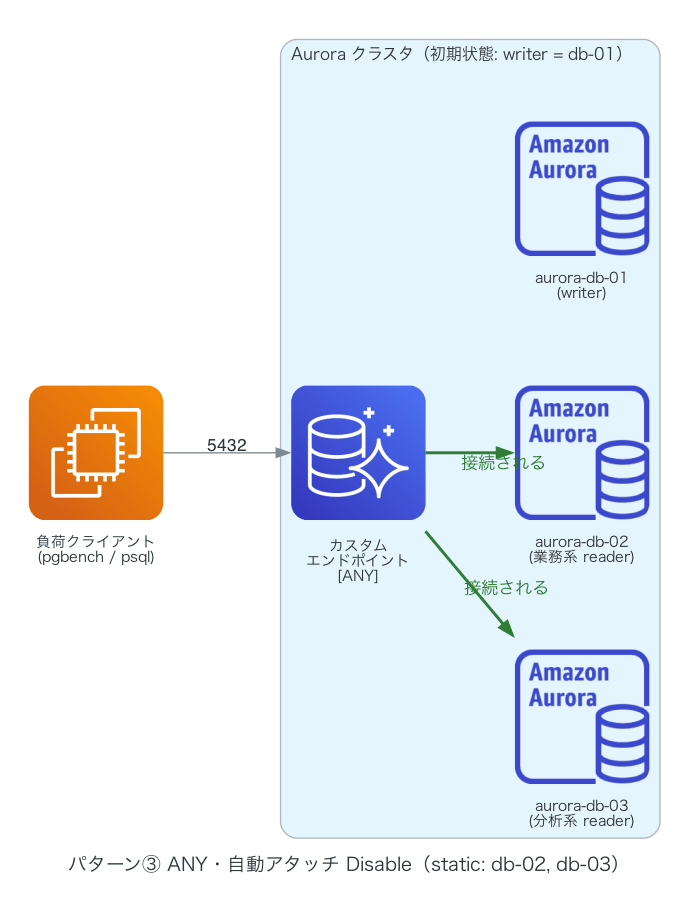
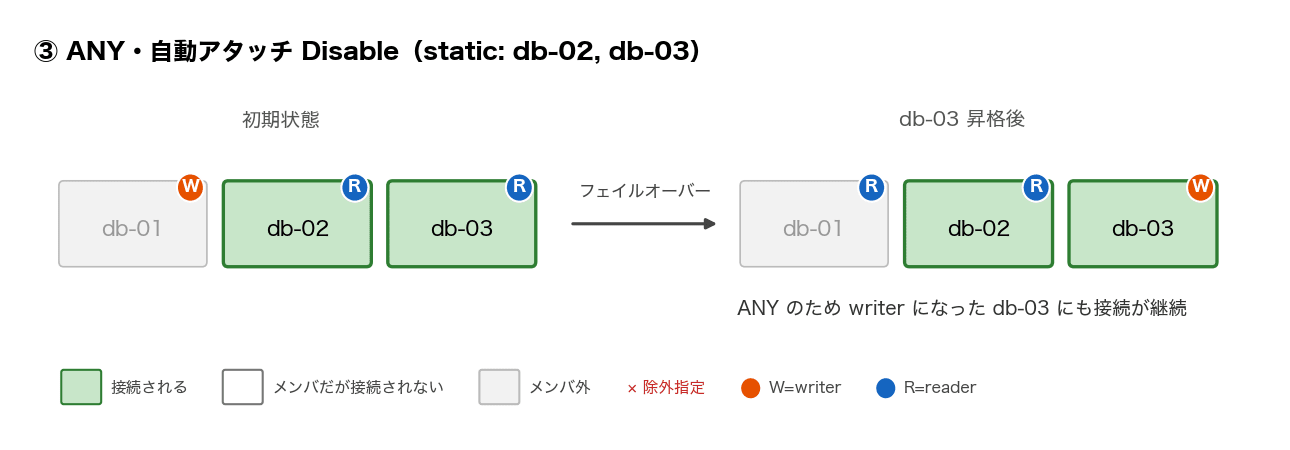
| ③ | ANY | Disable(静的リスト) | db-02, db-03 | db-02 + db-03(writer) のまま継続 | db-02(writer) + db-03 のまま継続 |
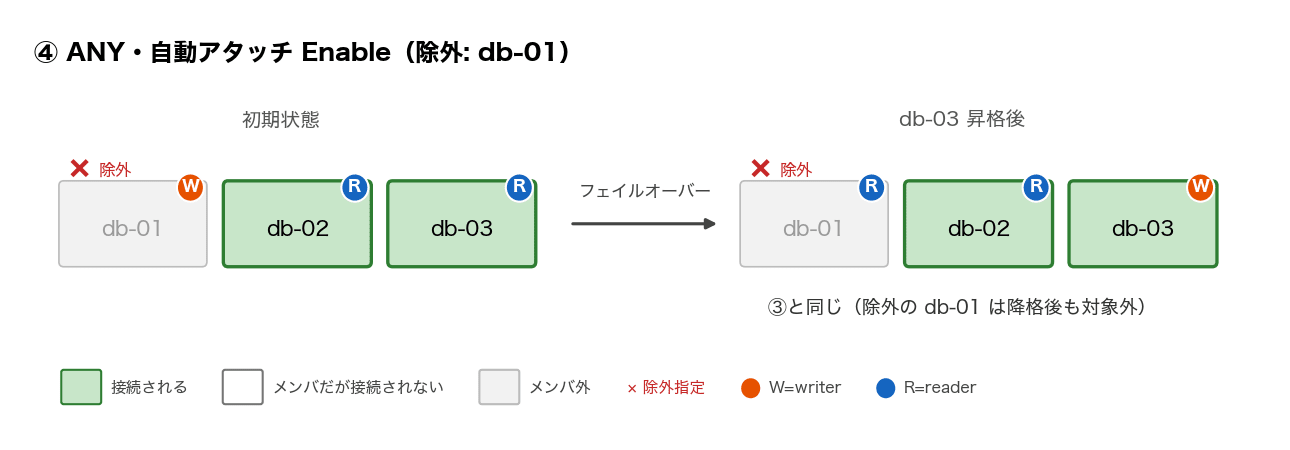
| ④ | ANY | Enable(除外リスト) | db-01 を除外 | ③と同じ | ③と同じ |
| ⑤ | READER | Disable(静的リスト) | db-01, db-03 | 降格した db-01 のみ | db-01 + db-03 の 2 台に分散 |
| ⑥ | READER | Enable(除外リスト) | db-02 を除外 | 降格した db-01 のみ(⑤と同型) | db-01 + db-03 の 2 台に分散 |
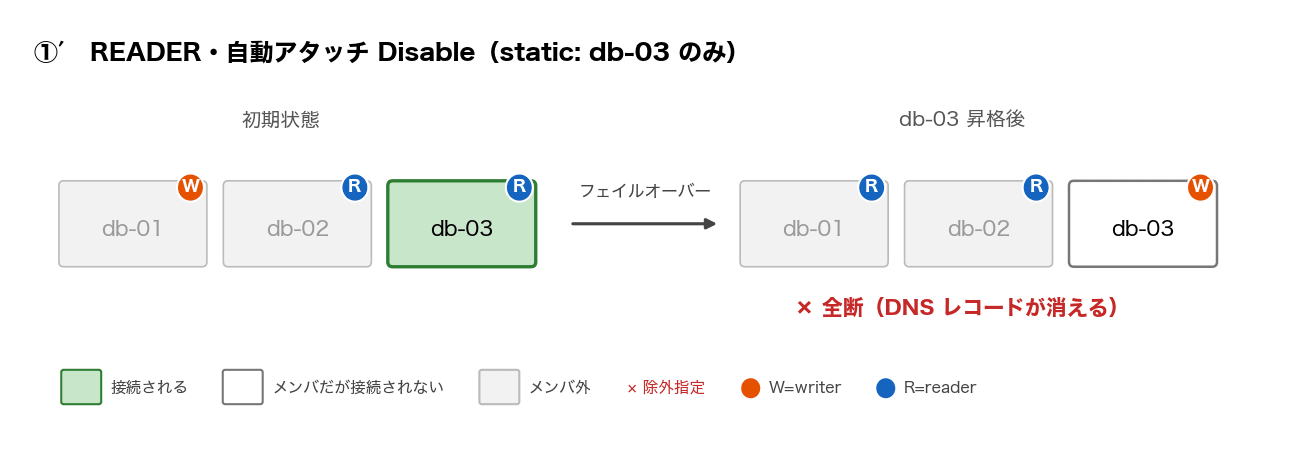
| ①′ | READER | Disable(静的リスト) | db-03 のみ | 全断が継続(DNS レコードが消える) | - |
| ②′ | READER | Enable(除外リスト) | 除外なし(全台) | 降格した db-01 が自動で合流 | - |
検証してみて特に重要だと感じた点は次の 3 つです。
1. 自動アタッチの除外指定は、ロールではなくインスタンス ID に張り付く
つまり「writer を除外したい」と思って設定しても、実際に除外されるのは「db-01 という名前のインスタンス」であって、「writer という役割」ではありません。
②(除外リストに db-01 を指定)では、フェイルオーバーで除外対象の db-01 が reader に降格しても、エンドポイントの接続先には合流しませんでした。降格したインスタンスが合流したのは、除外を指定しなかった②′だけでした。db-01 は reader になっても名前が db-01 のままなので、除外され続けたわけです。除外を使うかどうかで挙動が変わる、という点は構成を選ぶうえで重要です。
2. READER タイプは writer にフォールバックしない。接続先が 1 台もなくなると DNS レコードごと消える
①′(メンバが reader 1 台のみ)でそのメンバが writer に昇格すると、接続先がなくなり全断が継続します。やっかいなのは、エンドポイントの DNS レコード自体が消えて名前解決に失敗するようになる一方、RDS API 上のステータスは available のままという点です。つまりこの状態は RDS API の監視では検知できず、DNS や接続レベルの外形監視が必要になります。
3. フェイルオーバーで、つなぎっぱなしの接続は全切断される。新規接続は数秒で復帰する
接続の種類によって影響が大きく異なりました。
| 観点 | 実測値 |
|---|---|
| 新規接続の断 | 最長で約 7 秒(接続先の reader が昇格したとき。無傷なら 0〜数秒) |
| つなぎっぱなしの接続(アプリが開いたまま使い回す接続) | 全切断(pgbench の 8 クライアントが全滅、自力復帰なし) |
| 昇格直後、新 writer に接続されてしまう時間(DNS の切り替え待ち) | 約 37〜50 秒 |
| クラスタとしてのフェイルオーバー完了(API 上) | 約 40〜60 秒 |
| reader 単体障害(再起動)時の断 | 約 14 秒(フェイルオーバーは発生せず自動復旧) |
ここからは、上記の実測結果をもとにした、構成選びの私見です。どのパターンが向くかはワークロード次第ですが、目安として次のように考えています。
- 分析・外部連携系など、特定 reader への固定を最優先したい場合は⑤型(READER + 静的リスト、writer もメンバに含めておく)が堅いです。フェイルオーバー時は降格した旧 writer が受け皿になるため、分離したい相手(db-02)に流れることがありません
- サービス向け読み取りなど可用性を優先したい場合は、writer 込みで接続が継続する③型(ANY + 静的リスト)か、降格したインスタンスが自動で合流する②′型(READER + 除外リスト・除外なし)が向いています
- READER + 静的リストで単一 reader だけをメンバにする構成(①′型)は避けたほうがよいです。その reader の昇格や障害で全断するうえ、RDS API の監視では気づけません
最後に、本番導入前のチェックリストです。今回の検証で実際に引っかかったポイントに絞っています。
- アプリ側は接続エラー時に、開いたままの接続(アプリが持つコネクションプール)を作り直してリトライできるか(フェイルオーバーでつなぎっぱなしの接続は全切断されます)
- 全ワークロードの接続先をカスタムエンドポイントで明示したか(標準 reader エンドポイント任せの接続が残ると分離が崩れます)
- エンドポイントへの外形監視(DNS・接続レベル)があるか(RDS API のステータスでは検知できない異常があります)
- フェイルオーバー直後の約 1 分間は READER タイプでも writer に接続されうることを、ワークロードが許容できるか
- min 0 ACU を使う場合、復帰の 12〜15 秒を本番が許容できるか(難しければ min 0.5 以上に)
検証内容
検証環境
AWS CDK で以下の検証環境を構築しました。
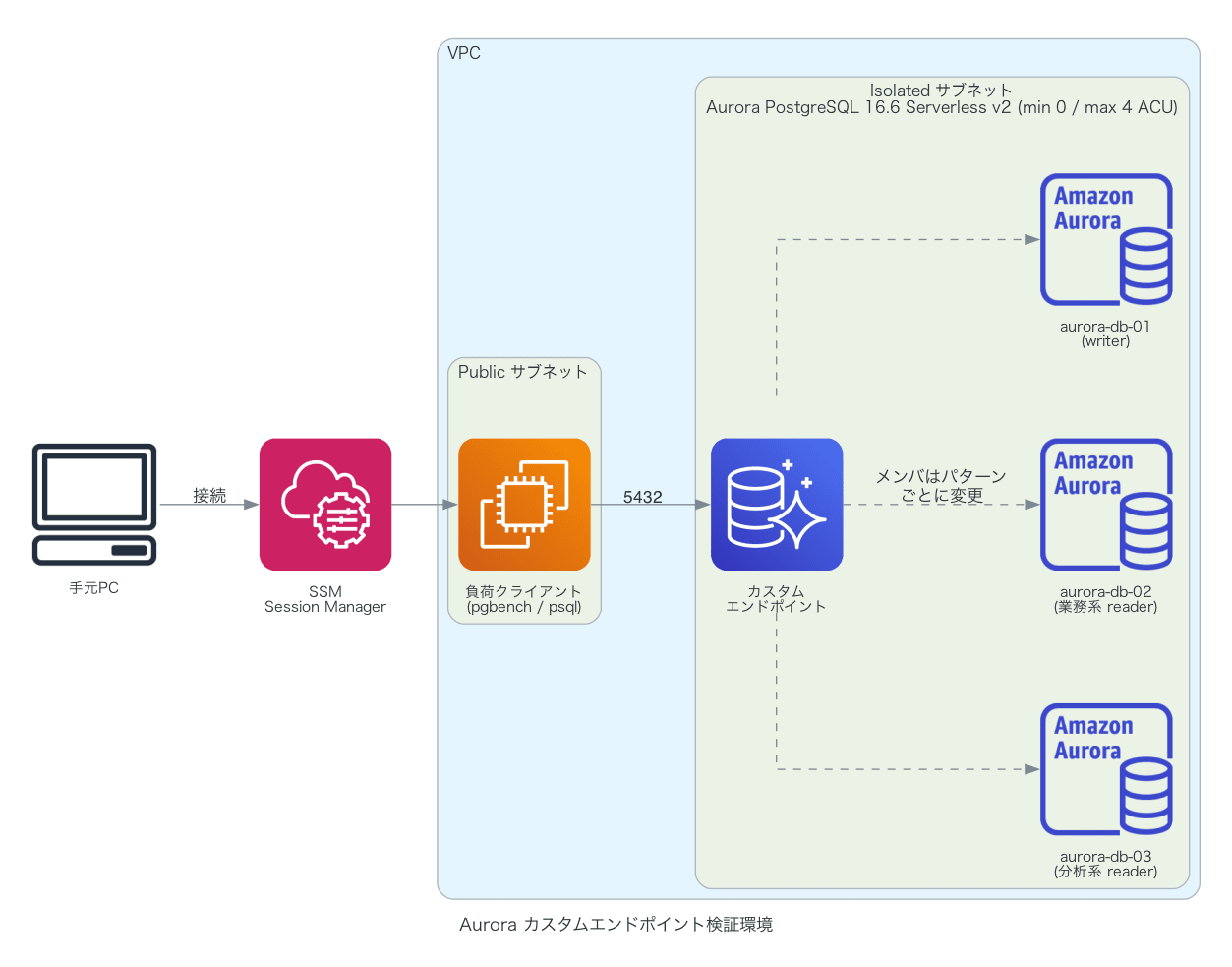
- NAT Gateway なしの最小コスト構成です。アイドル時は ACU 0 へオートポーズするため、検証の合間はほぼストレージ費のみで済みます
- カスタムエンドポイントは config で宣言的に切り替えられるようにし、パターンごとにデプロイし直す方式にしました
検証方法
フェイルオーバー前後の挙動を、次の 3 つの観測を組み合わせて記録しました。
1 つ目は psql の 1 秒ループです。毎回新規接続するため、「いまエンドポイントの DNS がどのインスタンスを向いているか」と「新規接続が何秒断するか」を観測できます。例えば次のようなスクリプトを EC2 上で動かして記録しました(実際にはタグや実行時間を引数で渡す形にしていますが、要点だけ抜き出すと以下のイメージです)。
while true; do
echo "$(date '+%T') $(psql -h <カスタムエンドポイント> -tAc \
"select inet_server_addr(), pg_is_in_recovery()" 2>&1 | head -1)"
sleep 1
done
inet_server_addr() で接続先インスタンス、pg_is_in_recovery() で接続先が writer(f)か reader(t)かが分かります。
2 つ目は pgbench の持続接続です。アプリが接続を開いたまま使い回すケース(いわゆるアプリ側のコネクションプール)を模して、フェイルオーバー時にその接続がどうなるかを観測します。
3 つ目は RDS API のポーリング(describe-db-cluster-endpoints / describe-db-clusters)で、メンバリストとロールの変化を 5 秒間隔で記録します。
この状態で aws rds failover-db-cluster --db-cluster-identifier <クラスタ識別子> --target-db-instance-identifier <昇格先> を実行します。カスタムエンドポイントはクラスタあたり最大 5 個まで作れるので、複数パターンをまとめてデプロイしておけば、1 回のフェイルオーバーで全パターンを同時観察できます。
Aurora のプロビジョニングされたクラスターまたは Aurora serverless クラスターごとに最大 5 つのカスタムエンドポイントを作成できます。
フェイルオーバー挙動の結果
結果の全体像は冒頭の早見表の通りですので、ここでは興味深かったポイントに絞ります。
まず、②(writer の db-01 を除外リストに指定した構成)の挙動です。検証した構成はこちらです。
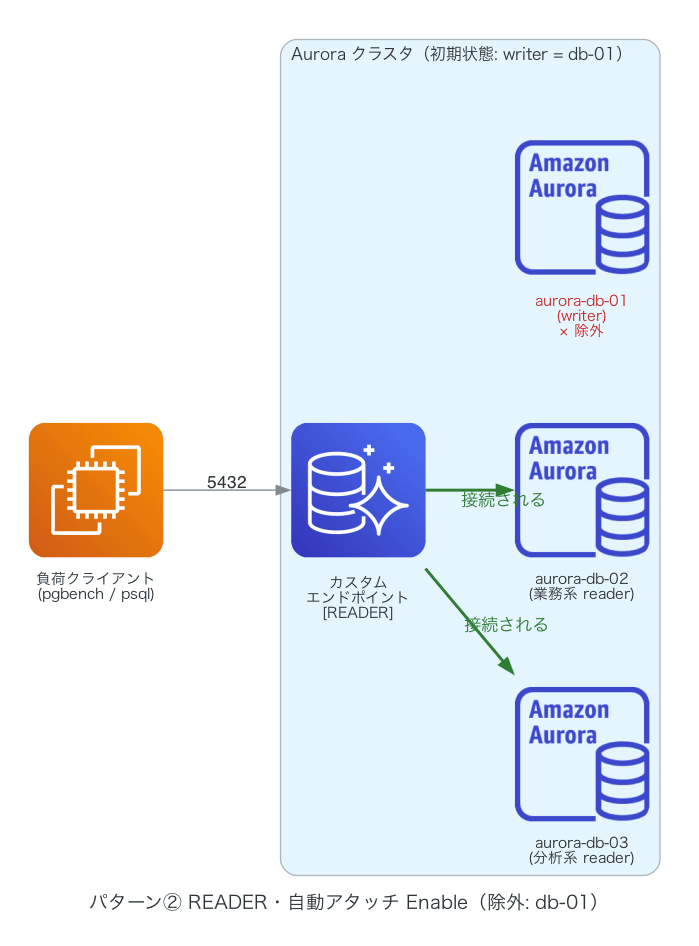
2019 年の検証記事では、自動アタッチ Enable のエンドポイントには降格したインスタンスがメンバイン(メンバに追加される、の意)する、という結果が報告されています。
②の構成でカスタムエンドポイントを作ることで、フェイルオーバー時に降格したインスタンスがカスタムエンドポイントに追加されることが確認出来ました。
一方、今回の②では、フェイルオーバー後も降格した db-01 への接続は 0 件でした。
そこで対照実験として、除外リストを空にした②′(真の自動アタッチ)を用意しました。
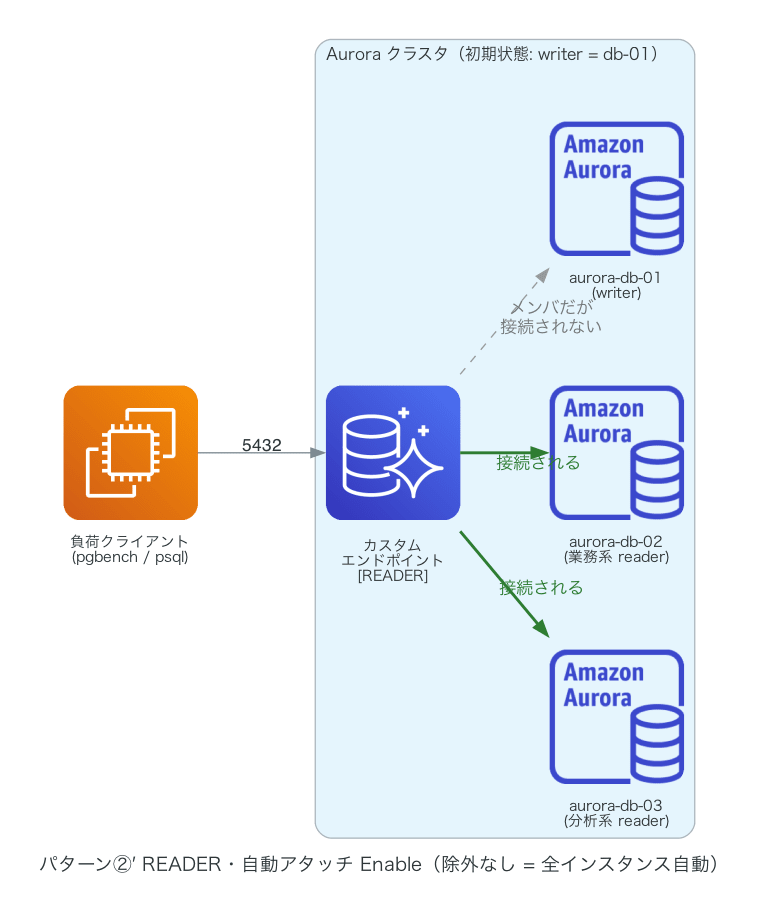
こちらは降格した db-01 がきちんと接続先に追加されました。
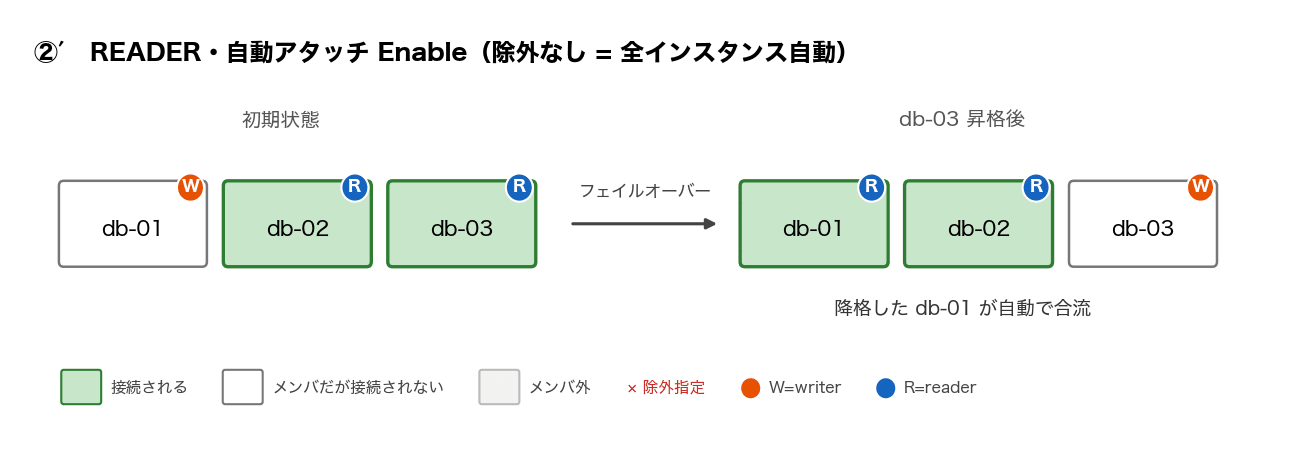
この 2 つの結果から、現在の仕様では次のように整理できます。
- 「自動アタッチ Enable」の実態は「除外リスト方式」であり、除外指定はロールではなくインスタンス ID に永続的に張り付く
- 降格したインスタンスの自動合流が起きるのは、そのインスタンスが除外指定にかかっていない場合のみ
これは公式ドキュメントの説明とも整合します。除外リストはロールではなくインスタンスの名前で管理されるため、現 writer を除外していても、フェイルオーバーで reader に降格しただけでは除外は外れません。
逆に、エンドポイントに除外リストが含まれている場合、新しく追加された Aurora レプリカは、この除外リストに名前が存在せず、ロールがカスタムエンドポイントのタイプと一致すれば、エンドポイントに追加されます。
約 7 年の間に仕様が変わった可能性もあるため当時の結果との単純な比較はできませんが、少なくとも現在の仕様では「現 writer を除外リストに入れておけば reader 専用になる」という発想で組むと、フェイルオーバー 1 回でその前提が崩れます。除外したインスタンスは reader に降格しても使われないままです。
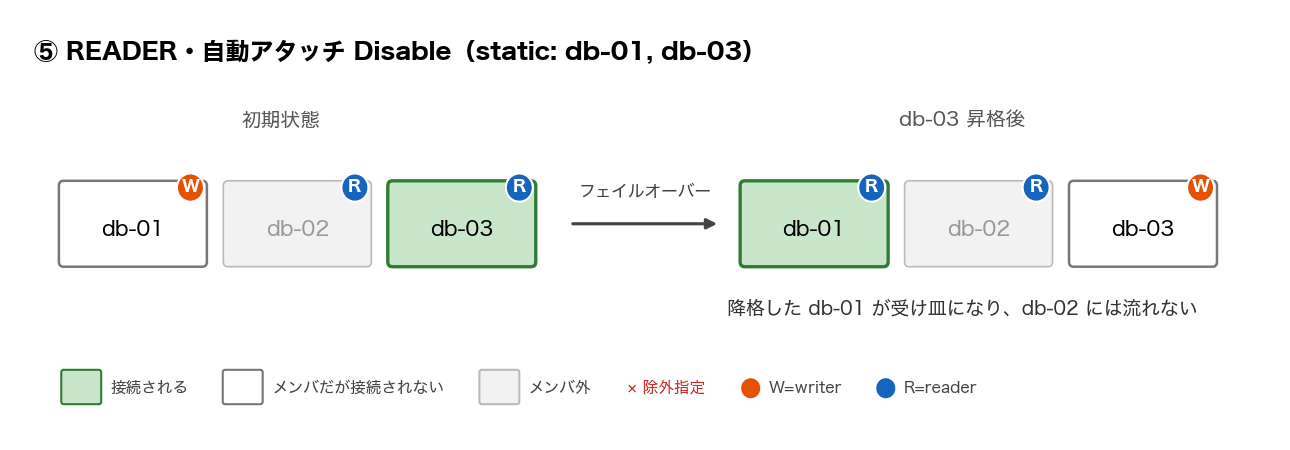
次に、フェイルオーバーの昇格先によって結果が変わる件です。2 台構成では昇格先が 1 つに決まりますが、3 台構成では「カスタムエンドポイントのメンバ内の reader が昇格する」場合と「メンバ外の reader が昇格する」場合で結果が分かれます。本命視していた⑤(READER + 静的リスト = [writer, db-03])の例です。構成はこちらです。
writer の db-01 もメンバに入れてあるのがポイントです。READER タイプのため普段は接続されませんが、降格したときの受け皿になります。
| 昇格先 | 結果 |
|---|---|
| db-03(メンバ内) | 新規接続が約 7 秒断した後、降格した db-01 だけが接続を受ける状態に。db-02 への接続は 0 件 |
| db-02(メンバ外) | 接続断ゼロ(接続を受けていた db-03 が無傷のため)。約 75 秒後に降格した db-01 が合流して 2 台分散に |
メンバ内昇格(db-03 を昇格、フェイルオーバー発行は 02:18:18)のときの psql ループの実測ログがこちらです。
02:18:26 db-03|t ← 発行後もしばらくは db-03(reader)に接続できていた
02:18:27 psql: error: connection to server at "analytics.cluster-custom-xxxx
(中略。02:18:27〜02:18:33 のエラーは計 6 回)
02:18:33 psql: error: connection to server at "analytics.cluster-custom-xxxx
02:18:34 db-03|f ← 約 7 秒で復帰。ただし接続先は writer になった db-03
02:19:11 db-01|t ← 約 37 秒後、降格した db-01 に切り替わり、以降は安定
このログから 2 つのことが読み取れます。1 つは、新規接続の断が約 7 秒で済んでいることです。もう 1 つは、READER タイプであっても昇格直後の約 37 秒間は writer になった db-03 へ接続されていることです(pg_is_in_recovery() が f = writer)。これはエンドポイントの DNS の切り替えが追いつくまでの一時的な状態で、他のパターンでも 37〜50 秒程度この状態が続きました。「READER タイプなら必ず reader に接続される」は、この切り替え待ちの間は成立しません。読み取り専用クエリであれば実害は軽微ですが、知っておくべき挙動だと思われます。
なお、メンバリスト(StaticMembers / ExcludedMembers)自体はどのパターンでもフェイルオーバー前後で一切変化しませんでした。変わるのは「ロールと DNS」だけです。
①の派生パターン①′(メンバが db-03 の 1 台のみ)で db-03 を昇格させたときは、さらに特徴的な動きになりました。
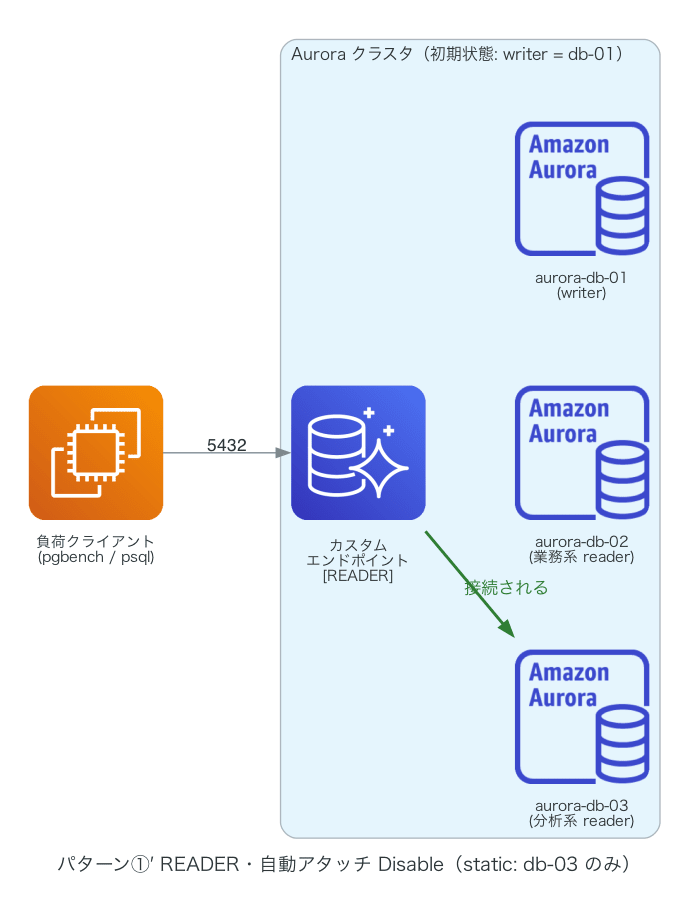
唯一のメンバである db-03 が writer に昇格すると、READER タイプの条件を満たすインスタンスがいなくなります。
03:45:15 db-03|t ← 平常時
03:45:54 psql: error: connection to server at "pattern1-single.cluster-custom-xxxx
03:46:05 db-03|f ← 一瞬だけ writer になった db-03 に接続
03:46:55 psql: error: could not translate host name "pattern1-single.cluster-custom-xxxx
(以降、終了まで同じエラーが継続)
最初は接続エラー(connection to server ... failed)だったものが、約 1 分後からは could not translate host name、つまり名前解決自体ができなくなっています。接続を受けられるメンバがいなくなると、エンドポイントの DNS レコードごと消えるようです。それでいて RDS API 上のステータスは available のままでした。
残りの ①③④⑥ も「構成 → 変化」の順で図を載せておきます。①は残った reader に接続が寄り、③④(ANY タイプ)は writer になった db-03 にも接続が継続、⑥は⑤と同型の動きでした。
最後に、つなぎっぱなしの接続側の観測です。フェイルオーバーの瞬間、カスタムエンドポイントに 8 本の接続を張りっぱなしにしていた pgbench は次のようになりました。
progress: 75.0 s, 14217.0 tps, lat 0.561 ms stddev 1.913, 0 failed
progress: 80.0 s, 14240.5 tps, lat 0.560 ms stddev 1.940, 0 failed
pgbench: error: client 5 aborted in command 1 (SQL) of script 0; perhaps the backend died while processing
(8 クライアントすべてが同様に abort)
pgbench: error: Run was aborted; the above results are incomplete.
直前まで 14,000 TPS 超で安定していた接続が、フェイルオーバーの数秒後に 8 本まとめて切断されました。pgbench はリトライしないため、そのまま停止しています。コネクションプールを使うアプリケーションでは、フェイルオーバー時にプール内の全接続が無効になる前提で、エラー時の再接続とリトライを実装しておく必要があります。
reader 単体障害(再起動)の挙動
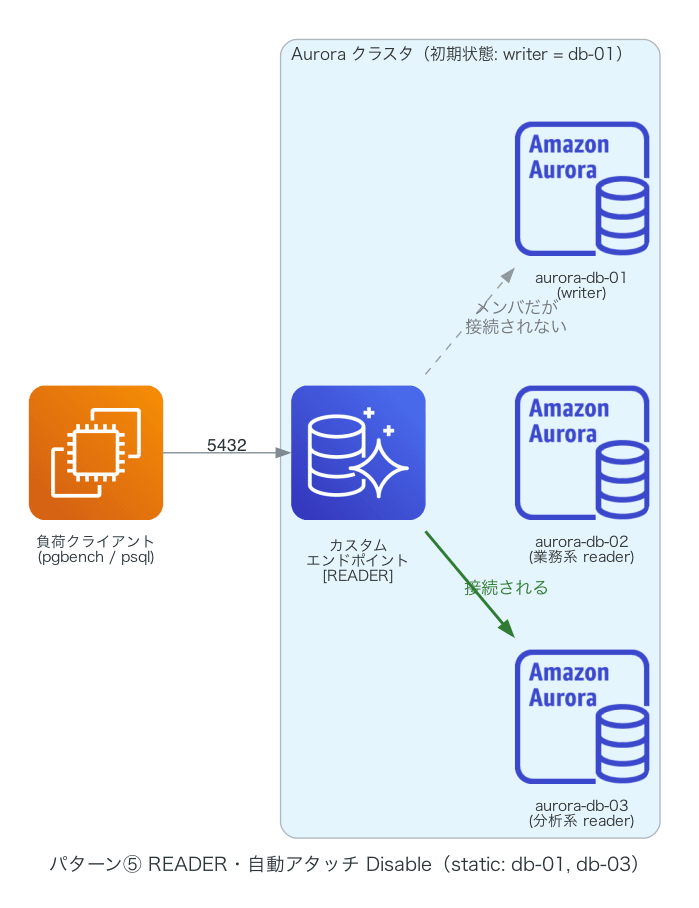
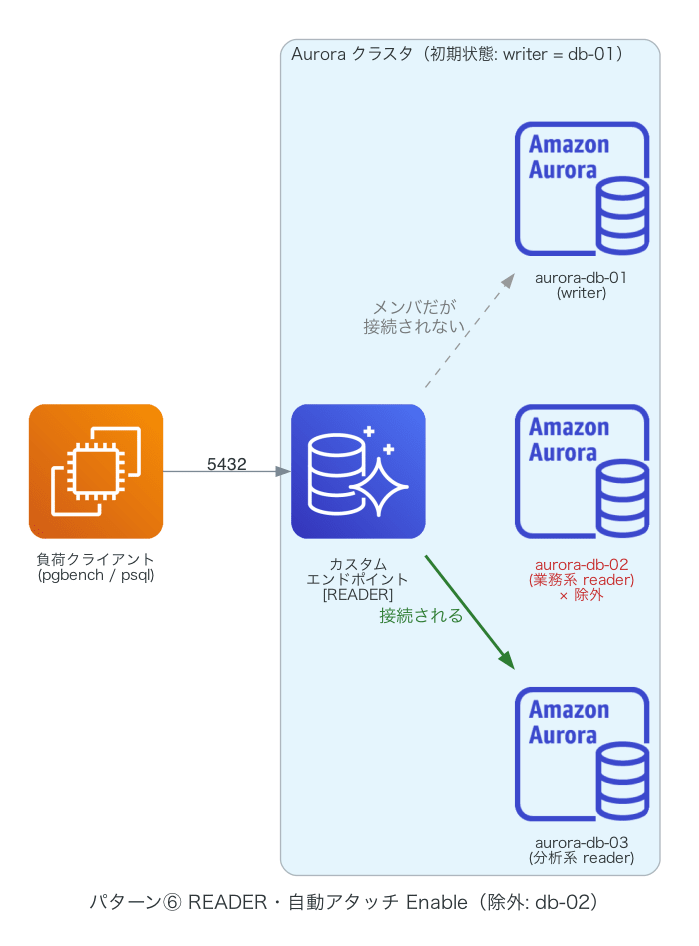
カスタムエンドポイント配下の reader が予期せぬ障害で落ちた場合を、reboot-db-instance で模擬しました。⑤構成で唯一接続を受けている db-03 を再起動した結果です。
- クラスタのフェイルオーバーは発生しません(writer は db-01 のまま)。reader は自動復旧し、カスタムエンドポイントの接続先も操作不要で元に戻ります
- READER タイプは writer にフォールバックしないため、ダウン中の分析系は全断します。ただし再起動級の障害なら実際の接続断は約 14 秒でした(RDS API 上の
rebooting表示は約 1 分 50 秒続くため、実際の断より長く見えます) - 降格と異なり、一時的な障害ではメンバ状態も変わらないため、復旧後の手作業は一切不要です
メンバが使用不可になった場合について、公式ドキュメントには次の記述があります。
グループ内のいずれかの DB インスタンスが使用不可になると、Aurora は以降のカスタムエンドポイント接続を、同じエンドポイントに関連付けられている他のいずれかの DB インスタンスに振り向けます。
今回の⑤はメンバに writer(db-01)と reader(db-03)の 2 台を含んでいました。この記述だけ読むと、唯一接続を受けていた db-03 がダウンしたら、残るメンバの db-01 に振り向けられそうに思えます。しかし実際には db-01 への振り向けは起きず、全断しました(ダウン中の db-01 への接続は 0 件)。db-01 は writer で、READER タイプのエンドポイントは reader にしか繋がないため、メンバではあっても振り向け先になれなかったからです。「他のいずれかの DB インスタンス」は、あくまでエンドポイントタイプ(READER / ANY)の制約の範囲内で選ばれる、と理解しておくのがよさそうです。
なお、この全断は分析用 reader が 1 台だけだったために起きたものです。可用性を重視するなら、分析用のカスタムエンドポイントに reader を 2 台以上持たせる構成も検討の余地があります。Aurora はストレージを共有するため reader を増やしてもストレージ費は増えず、Serverless v2 なら負荷が分散して総 ACU も大きくは変わりません。今回は挙動の根本をパターン別に確かめることを主眼にしたため 1 台構成で検証しましたが、本記事の結果をもとに、それぞれのワークロードに合った冗長構成を設計していただければと思います。
負荷分離と ACU スケーリングの実測
カスタムエンドポイントが負荷の分離として実際に機能するかを pgbench で確認しました。⑤構成の分析系エンドポイント(接続先は db-03 のみ)に対し、32 クライアントで 10 分間の読み取り負荷をかけた結果です。
| 観点 | 結果 |
|---|---|
| スループット | 平均 10,637 TPS(失敗 0、平均レイテンシ 3.0 ms) |
| 接続先 | 期間中の psql ループ 491 回すべてが db-03 |
| db-03 の ACU | 負荷開始 1 分以内に 0.5 → 4.0(max)へスケールし維持 |
| db-02 の ACU | 負荷中は 0.5 のままフラット |
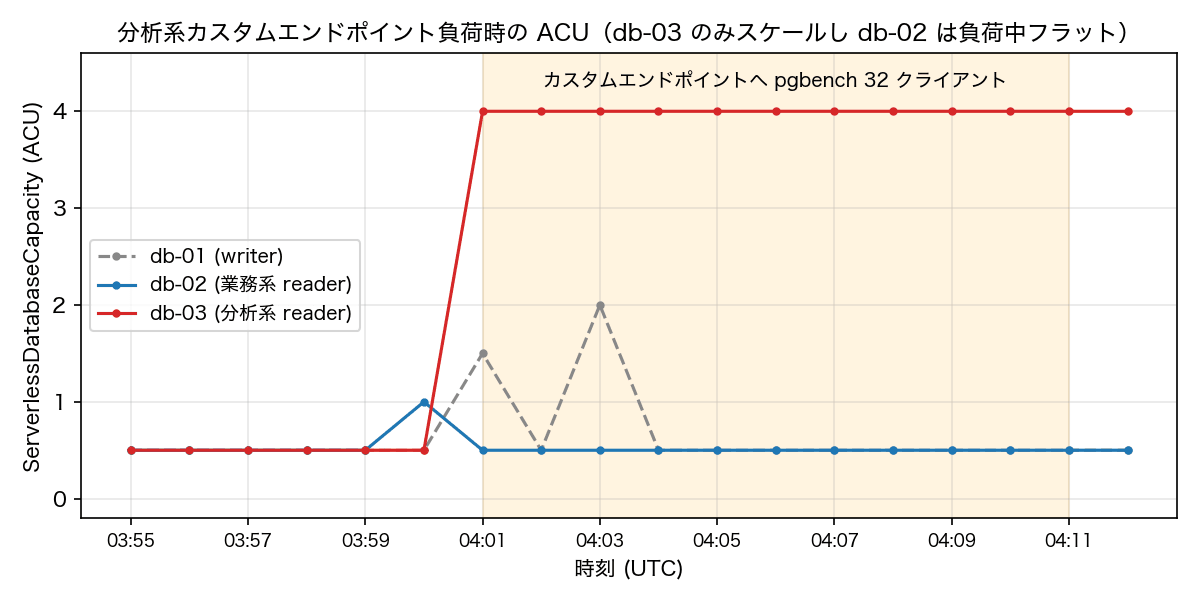
負荷開始直後に db-03 だけが 4.0 ACU へ立ち上がり、db-02 は負荷の間ずっと 0.5 のまま動いていません(グラフ左端、負荷開始前の 1 点だけ db-02 が 1.0 に見えますが、これは負荷とは無関係の値です)。接続レベルでもメトリクスレベルでも、完全な分離が確認できました(writer の db-01 が負荷開始直後に一時的に 1.5〜2.0 へ上がっていますが、すぐ 0.5 へ戻りました。レプリケーション関連のオーバーヘッドと思われます)。
なお、スループットの絶対値は pgbench の単純な SELECT(-S)を scaling factor 100(-i -s 100)で初期化したデータに対して実行したときのものなので、実ワークロードではクエリ内容次第で大きく変わります。ここで見たいのは数値そのものではなく、スケールと分離の挙動です。
一方で、クラスタ標準の reader エンドポイントに同じ負荷をかけると、psql ループの接続先は db-02 が 107 回、db-03 が 123 回(約 46% : 54%)と、2 台の reader にほぼ半々で分散しました。reader エンドポイントの仕様通りの動きです。
Aurora は、すべての Aurora レプリカ間で接続バランシングを自動的に実行します。
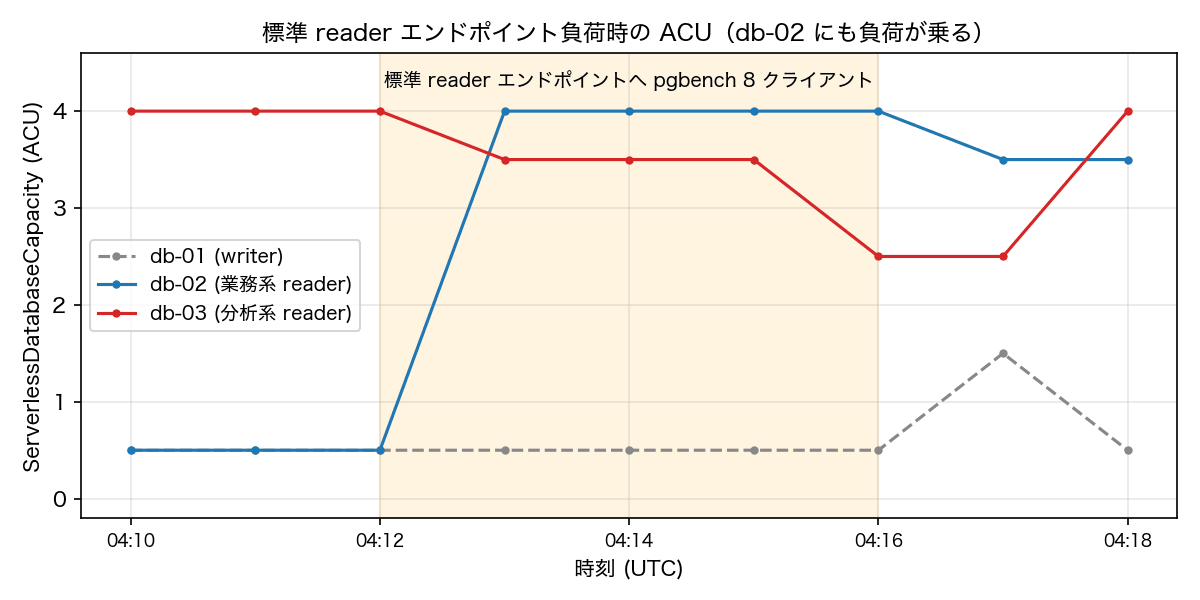
この標準 reader エンドポイント負荷のグラフでは、先ほどの分析系カスタムエンドポイントのとき(db-03 だけがスケール)と違って、db-02 が 4.0 ACU まで上がっています(db-03 が 2.5〜3.5 で推移しているのは直前の試験のスケールダウン途中のためで、右端で再び上がっているのは次の試験の負荷が始まったためです)。
当然の仕様ではありますが、これは分離の落とし穴になります。例えば分析用に db-03 を増やしてカスタムエンドポイント(db-03 のみ)で分けても、業務系が標準 reader エンドポイントを使ったままだと、標準 reader エンドポイントは全 reader に分散するため、業務系のクエリが db-02 だけでなく db-03 にも流れてしまいます。せっかく分析専用に空けたはずの db-03 に業務系の負荷が乗り、分離が崩れるわけです。用途分離を完全にするには、業務系にも db-02 だけに繋ぐカスタムエンドポイントを用意し、全ワークロードの接続先をカスタムエンドポイントで明示するのが安全です。
なお Serverless v2 の min 0 ACU 設定では、無活動から約 6 分で全インスタンスが ACU 0(オートポーズ)に到達し、復帰(ポーズ状態への新規接続)には 12〜15 秒かかりました。復帰時間は公式ドキュメントの記述ともよく一致します。
通常、再開までの時間は約 15 秒になる可能性があるため、クライアントのタイムアウト設定は 15 秒より長く調整することをお勧めします。
検証環境のコスト削減には大変有効ですが、この復帰遅延を許容できない本番ワークロードでは min 0.5 以上が無難です。
まとめ
Aurora カスタムエンドポイントのフェイルオーバー挙動を、Serverless v2 + 3 台構成の 8 パターンで検証しました。
- 性能対策なら ACU の引き上げや reader 追加、分離対策ならカスタムエンドポイント、という使い分けがまず前提
- メンバリスト(静的リスト / 除外リスト)はフェイルオーバーで変化しない。変わるのは「ロールと DNS」
- 除外指定はインスタンス ID に永続的に張り付く。降格したインスタンスの自動合流が起きるのは、除外指定にかかっていない場合のみ
- READER タイプは writer にフォールバックしない。接続先が 1 台もなくなると DNS レコードごと消えるが、API ステータスは
availableのままなので外形監視が必要 - つなぎっぱなしの接続はフェイルオーバーで全切断されるため、アプリ側の再接続(コネクションプールの作り直し)とリトライ実装は必須
- 用途分離を完全にするなら、全ワークロードの接続先をカスタムエンドポイントで明示する
カスタムエンドポイントは、設定はシンプルですが、障害時の挙動はパターンによって大きく違う機能でした。採用の際は、冒頭の早見表を参考に、固定を取るか可用性を取るかというワークロードの優先順位に合わせて TYPE とメンバ指定方式を選んでいただければと思います。
この記事が誰かのお役に立てば幸いです。
参考情報
- Amazon Aurora のカスタムエンドポイント - Amazon Aurora
- Amazon Aurora のカスタムエンドポイントに関する考慮事項 - Amazon Aurora
- Amazon Aurora エンドポイント接続 - Amazon Aurora
- Aurora serverless の自動一時停止と再開によるゼロ ACU へのスケーリング - Amazon Aurora
- AmazonAurora カスタムエンドポイントのフェールオーバー時の挙動についての検証 - コネヒト開発者ブログ
クラスメソッドオペレーションズ株式会社について
クラスメソッドグループのオペレーション企業です。
運用・保守開発・サポート・情シス・バックオフィスの専門チームが、IT・AI をフル活用した「しくみ」を通じて、お客様の業務代行から課題解決や高付加価値サービスまでを提供するエキスパート集団です。
当社は様々な職種でメンバーを募集しています。
「オペレーション・エクセレンス」と「らしく働く、らしく生きる」を共に実現するカルチャー・しくみ・働き方にご興味がある方は、クラスメソッドオペレーションズ株式会社 コーポレートサイト をぜひご覧ください。※2026 年 1 月 アノテーション㈱から社名変更しました










