
AWS ParallelCluster で利用中の Aurora Serverless v2 を停止開始でプラットフォーム 4 にアップグレードをしてみた
はじめに
AWS ParallelCluster の Slurm Accounting (ジョブ実行履歴の収集・保存) のバックエンド DB に私は Aurora Serverless v2 を使っています。先日、Aurora Serverless v2 のプラットフォームバージョン 4 がリリースされました。
プラットフォームバージョン 3 比で最大 30% の性能向上を謳っており、既存の Aurora クラスターも停止→開始の操作だけでアップグレードできます。以前、プラットフォームバージョン 2→3 のアップグレードを同じ手順で検証しました。
今回は ParallelCluster のクラスターから接続している Aurora Serverless v2 を対象に、停止開始でプラットフォームバージョン 4 にアップグレードしました。アップグレード中の業務継続性と過去ジョブ履歴の保持を確認しています。
確認結果
- DB の停止→開始でプラットフォームバージョンが 3 から 4 に変わった
- DB 停止中に実行・完了したジョブの履歴は、DB 再開後に
sacctで正常に参照できた - DB 停止中は
sacctがエラーになるが、sbatchでのジョブ投入・実行は継続できた - 停止に約 9 分、起動に約 6 分かかった
検証環境
ParallelCluster の Slurm Accounting は、ジョブの実行履歴をデータベースに記録する機能です。sacct コマンドで過去の実行時間・リソース使用量を照会できます。ヘッドノード上の slurmdbd がデータベースへの書き込みを中継します。
| 項目 | 値 |
|---|---|
| リージョン | ap-northeast-1 (東京) |
| ParallelCluster | v3.15.0、Amazon Linux 2023 |
| ヘッドノード | t3a.small |
| コンピュートノード | c5n.18xlarge × 最大 2、EFA、オンデマンド |
| Aurora | Aurora MySQL 互換、Serverless v2、プラットフォームバージョン 3 |
アップグレード手順
ベースライン確認
現在のプラットフォームバージョンは 3 です。
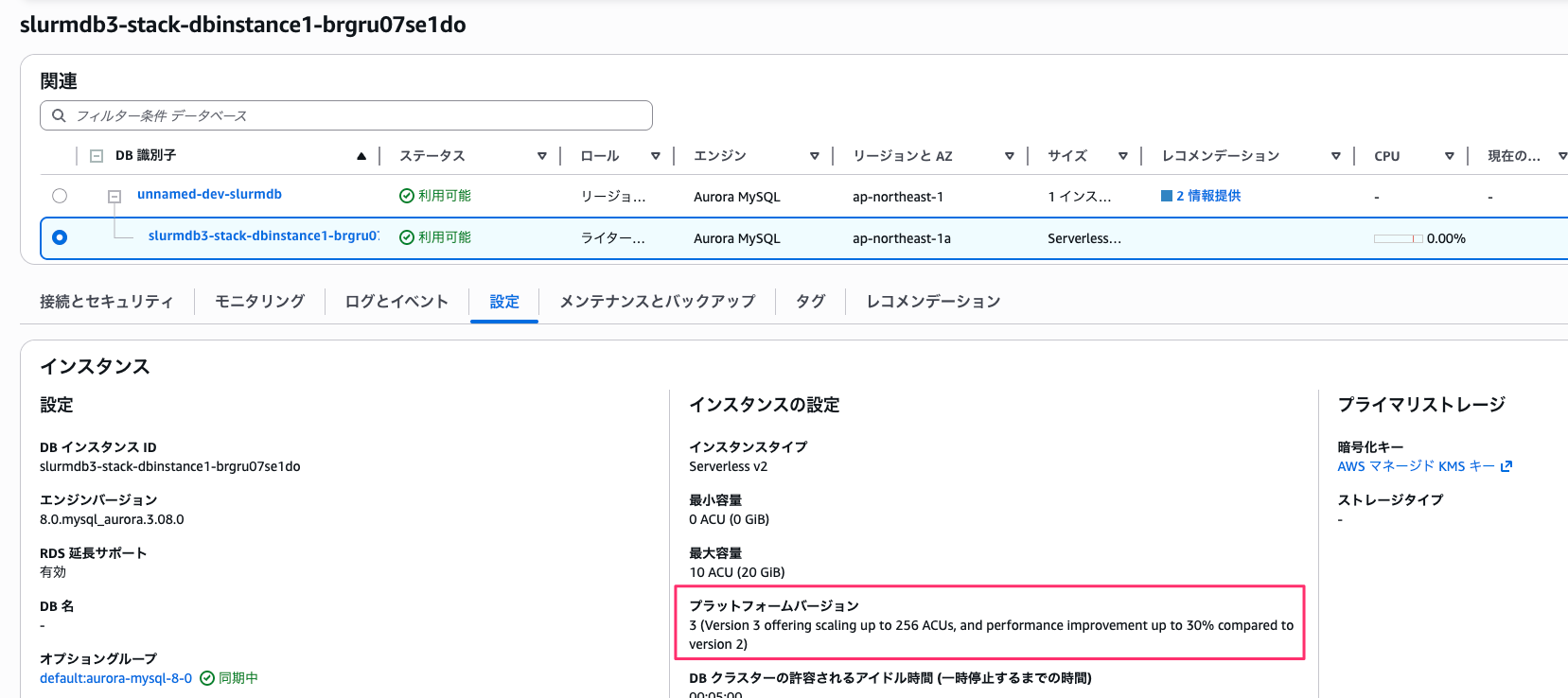
ヘッドノードに Session Manager で接続し、sacct で過去のジョブ履歴を確認しておきます。アップグレード後に同じ履歴が参照できるかの比較用です。
$ sacct
JobID JobName Partition Account AllocCPUS State ExitCode
------------ ---------- ---------- ---------- ---------- ---------- --------
1 test.sh efa pcdefault 1 COMPLETED 0:0
1.batch batch pcdefault 1 COMPLETED 0:0
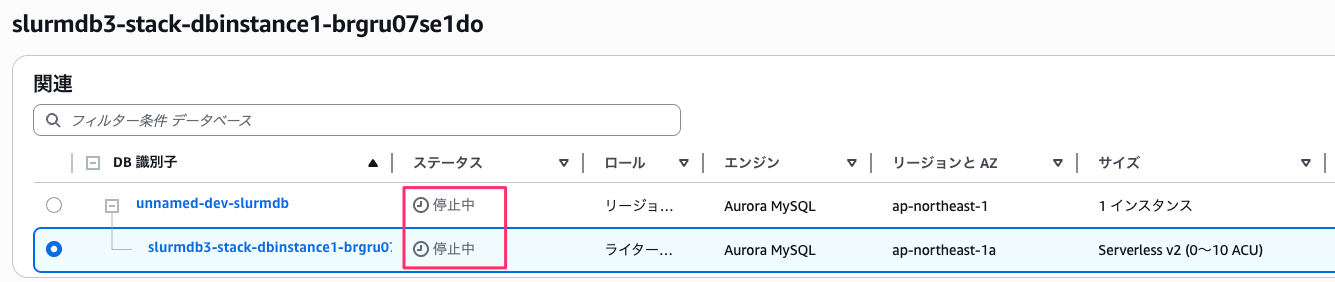
Aurora クラスターの停止
stop-db-cluster で停止を発行します。停止時間を計測するため、describe-db-clusters で Status をポーリングし stopped になるまで監視します。
DB_CLUSTER=unnamed-dev-slurmdb
REGION=ap-northeast-1
aws rds stop-db-cluster --db-cluster-identifier $DB_CLUSTER --region $REGION
START=$SECONDS
while :; do
STATUS=$(aws rds describe-db-clusters --db-cluster-identifier $DB_CLUSTER \
--region $REGION --query 'DBClusters[0].Status' --output text)
printf '[%s] Status=%s elapsed=%ss\n' "$(date +%T)" "$STATUS" "$((SECONDS-START))"
[[ "$STATUS" == stopped ]] && break
sleep 30
done
echo "Stop completed in $((SECONDS-START))s"
[10:04:15] Status=stopping elapsed=1s
[10:04:45] Status=stopping elapsed=31s
[10:05:16] Status=stopping elapsed=62s
[10:05:47] Status=stopping elapsed=93s
[10:06:18] Status=stopping elapsed=124s
[10:06:48] Status=stopping elapsed=154s
[10:07:19] Status=stopping elapsed=185s
[10:07:50] Status=stopping elapsed=216s
[10:08:21] Status=stopping elapsed=247s
[10:08:51] Status=stopping elapsed=277s
[10:09:22] Status=stopping elapsed=308s
[10:09:53] Status=stopping elapsed=339s
[10:10:23] Status=stopping elapsed=369s
[10:10:54] Status=stopping elapsed=400s
[10:11:25] Status=stopping elapsed=431s
[10:11:55] Status=stopping elapsed=461s
[10:12:26] Status=stopping elapsed=492s
[10:12:57] Status=stopping elapsed=523s
[10:13:27] Status=stopped elapsed=553s
bash-3.2$ echo "Stop completed in $((SECONDS-START))s"
Stop completed in 553s
今回の停止所要時間は約 9 分 (553 秒) でした。
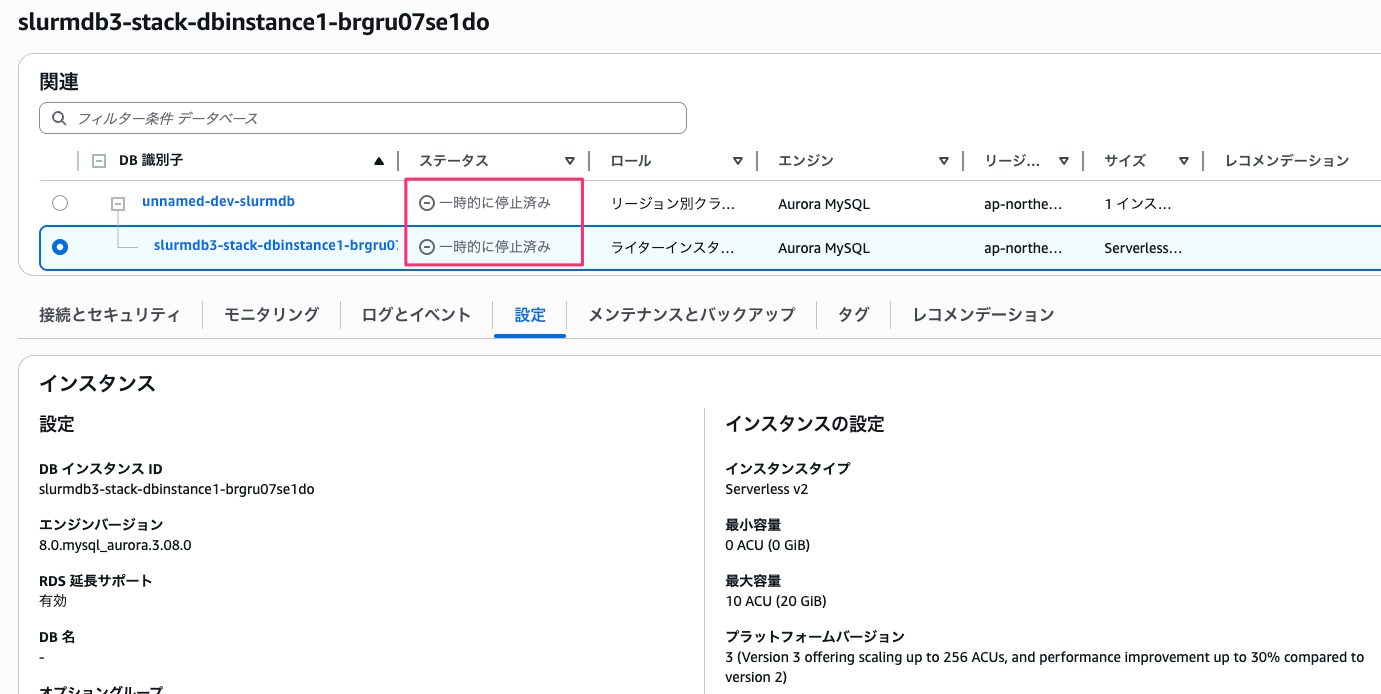
DB が停止すると slurmdbd が接続できなくなり、sacct を実行するとエラーになります。
$ sacct
sacct: error: slurm_persist_conn_open: Something happened with the receiving/processing of the persistent connection init message to ip-10-0-0-122:6819: Unable to connect to database
sacct: error: Sending PersistInit msg: Unable to connect to database
sacct: error: Problem talking to the database: Unable to connect to database
slurmctld はアカウンティングレコードをローカルにキャッシュするため、ジョブの投入・実行は継続できます。
$ sbatch stop-test.sh
Submitted batch job 2
$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
2 efa stop-tes ec2-user CF 0:02 1 efa-dy-c5n18xl-1
If SlurmDBD is configured for use but not responding then slurmctld will utilize an internal cache until SlurmDBD is returned to service. The cached data is written by slurmctld to local storage upon shutdown and recovered at startup. Job and step accounting records generated by slurmctld will be written to a cache as needed and transferred to SlurmDBD when returned to service.
Aurora クラスターの開始
ステータスが stopped になったら、start-db-cluster で開始を発行します。同様にポーリングで available になるまでの時間を計測します。
DB_CLUSTER=unnamed-dev-slurmdb
REGION=ap-northeast-1
aws rds start-db-cluster --db-cluster-identifier $DB_CLUSTER --region $REGION
START=$SECONDS
while :; do
STATUS=$(aws rds describe-db-clusters --db-cluster-identifier $DB_CLUSTER \
--region $REGION --query 'DBClusters[0].Status' --output text)
printf '[%s] Status=%s elapsed=%ss\n' "$(date +%T)" "$STATUS" "$((SECONDS-START))"
[[ "$STATUS" == available ]] && break
sleep 30
done
echo "Start completed in $((SECONDS-START))s"
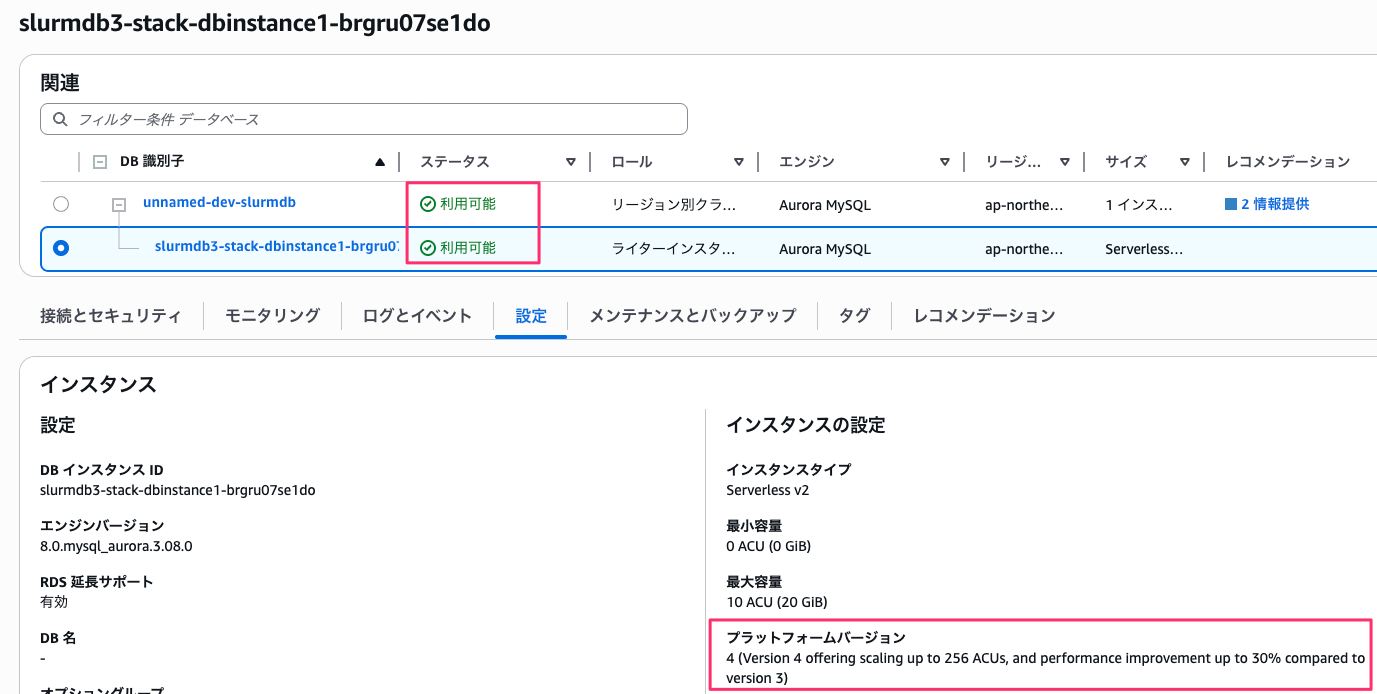
起動と同時にプラットフォームバージョンが 4 に変わります。
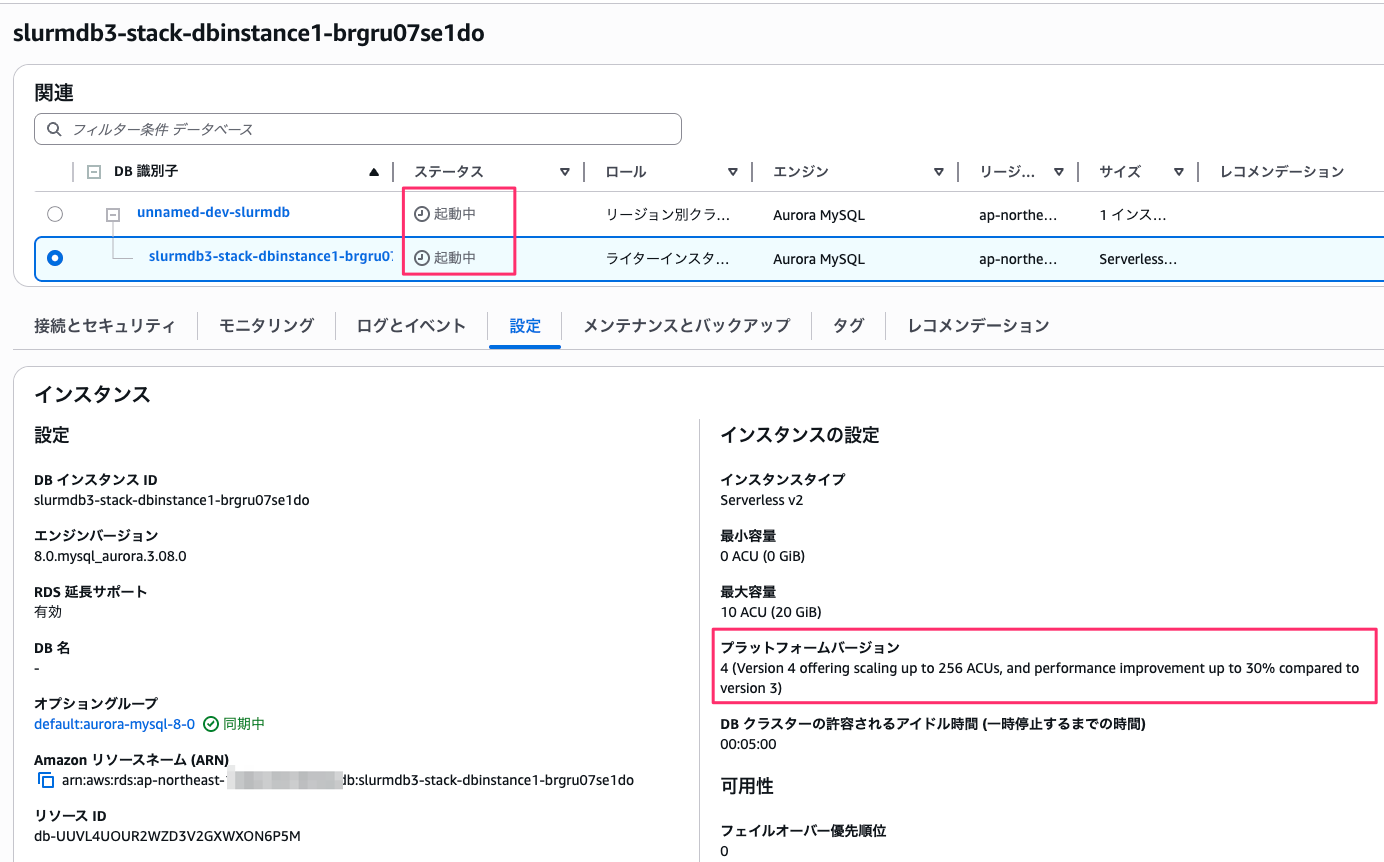
今回の起動所要時間は約 6 分でした。
プラットフォームバージョンの確認
問題なく起動しました。
検証結果
過去のジョブ履歴の保持
sacct で DB 停止中に実行したジョブ履歴を確認します。
$ sacct
JobID JobName Partition Account AllocCPUS State ExitCode
------------ ---------- ---------- ---------- ---------- ---------- --------
1 test.sh efa pcdefault 1 COMPLETED 0:0
1.batch batch pcdefault 1 COMPLETED 0:0
2 stop-test+ efa pcdefault 1 COMPLETED 0:0
2.batch batch pcdefault 1 COMPLETED 0:0
JobID 1 はアップグレード前に投入したジョブ、JobID 2 は DB 停止中に投入した stop-test.sh です。DB 停止中、slurmctld がキャッシュしていたレコードも、DB 再開後に slurmdbd へフラッシュされ、sacct で参照できました。
新規ジョブの投入と Accounting 記録
アップグレード後に新規ジョブを投入し、sacct に記録されることを確認します。
$ sbatch updated-test.sh
Submitted batch job 3
$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
3 efa updated- ec2-user CF 0:45 1 efa-dy-c5n18xl-1
$ sacct
JobID JobName Partition Account AllocCPUS State ExitCode
------------ ---------- ---------- ---------- ---------- ---------- --------
1 test.sh efa pcdefault 1 COMPLETED 0:0
1.batch batch pcdefault 1 COMPLETED 0:0
2 stop-test+ efa pcdefault 1 COMPLETED 0:0
2.batch batch pcdefault 1 COMPLETED 0:0
3 updated-t+ efa pcdefault 1 RUNNING 0:0
新規ジョブ JobID 3 が squeue でキューに入り、sacct でも RUNNING ステータスで記録されています。アップグレード後の Slurm Accounting も問題なく動作することを確認できました。
さいごに
AWS ParallelCluster で稼働中の Aurora Serverless v2 をプラットフォームバージョン 4 にアップグレードしました。DB が停止中も Slurm のジョブ投入・実行は継続できます。sbatch・squeue は通常通り動作し、sacct だけが DB 接続エラーになります。停止中の履歴は DB 再起後に反映されます。停止から開始まで合計約 15 分でしたが、所要時間はクラスター規模やデータ量によって異なります。ジョブ実行中でも Slurm の機能への影響を抑えたまま、計画的にアップグレードできます。
パフォーマンスが良くなっているため、課金単位の ACU を抑えられる可能性があります。経済的に運用したい場合はアップグレードをご検討ください。








