![【セッションレポート】 AI エージェントのオブザーバビリティ実践 [CNS317]](https://images.ctfassets.net/ct0aopd36mqt/545yz8YCuTICrExgjAVcya/aefd7665232e9fccd1c828e92f5006e3/aws-summit-japan2026_session_e.png?w=3840&fm=webp)
【セッションレポート】 AI エージェントのオブザーバビリティ実践 [CNS317]
こんにちは。
RFC からハミ出る人生
クラウド事業本部のかわいです。
AWS Summit 2026 も2日目となり、今日で最終日となりました。朝9時頃でも超満員の大盛況です。
今回の記事では、1日目に開催されたセッション「AI エージェントのオブザーバビリティ実践」を紹介したいと思います。
セッションについて
セッションタイトル:AI エージェントのオブザーバビリティ実践
セッションスピーカー:ソリューションアーキテクト, AWS Japan 大石美緒氏
AI エージェントを活用したアプリケーションの開発が進む一方、オブザーバビリティをどう実現するかは多くのエンジニアが直面する課題です。AI エージェントは非決定的に動作し、LLM やツールの呼び出しが複数ステップにまたがるため、従来のアプリケーション監視では十分ではありません。本セッションでは、OpenTelemetry をベースとした計装から、Amazon CloudWatch generative AI observability によるメトリクス・トレース・ログの可視化、Amazon Bedrock AgentCore Evaluations を用いた応答品質の評価まで、AI エージェントのオブザーバビリティについて解説します。
セッションの概要
- AI エージェントを安心して本番運用するために必要な可観測性を解説
- ログ、メトリクス、トレースを活用し、問題の早期発見と継続的な改善につなげる方法を紹介
- Amazon Bedrock Agentcore、Bedcrock Agentcore Evaluations を使用した実装例
セッションの内容
生成 AI オブザーバビリティ特有の課題とは?

生成 AI は急速に変化/進化しており、生成 AI エージェントから、エージェンティック AI システムに移行してきている。自律的に進むため、バックグラウンドで何をしているのかが、より人間から見えにくくなっているとの、新たな課題の投げかけからセッションは始まりました。
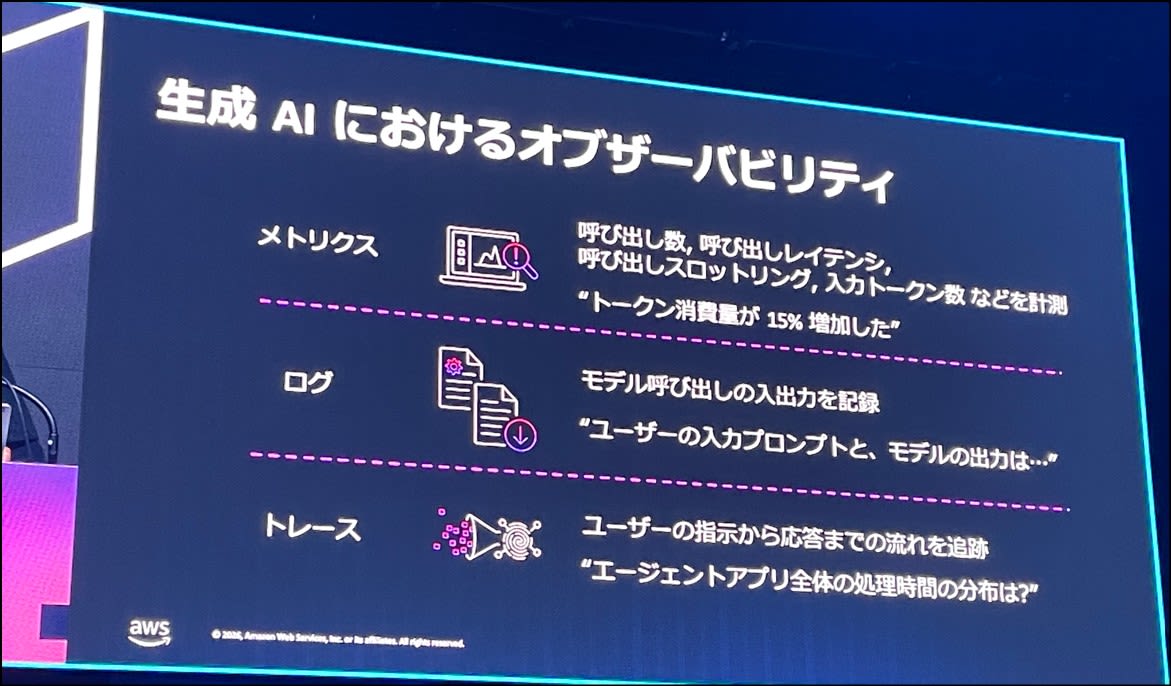
オブザーバビリティの面でも3つのシグナルが存在し、メトリクス、ログ、トレースに分けることができます。
そんな中、今までのオブザーバビリティにはなかった課題が浮き上がります。

従来の方法では、問題のあった箇所でエラーが出力され、ログから根本原因を特定する、といった流れを取っていましたが、生成 AI オブザーバビリティの文脈では、回答が適切か?の品質監視が重要です(例:英語で出力を要求したのに、日本語で回答が返ってきた)。
なかでも
1.同じ入力でも毎回異なる動き
2.複雑に連鎖する呼び出しから原因調査を実施
3.呼び出しの収取と分析が必要
4.パフォーマンスから応答品質まで網羅的に評価
が必要になってくる。
テレメトリデータ収集のおける課題
また、テレメトリデータ収集時にも課題があります。
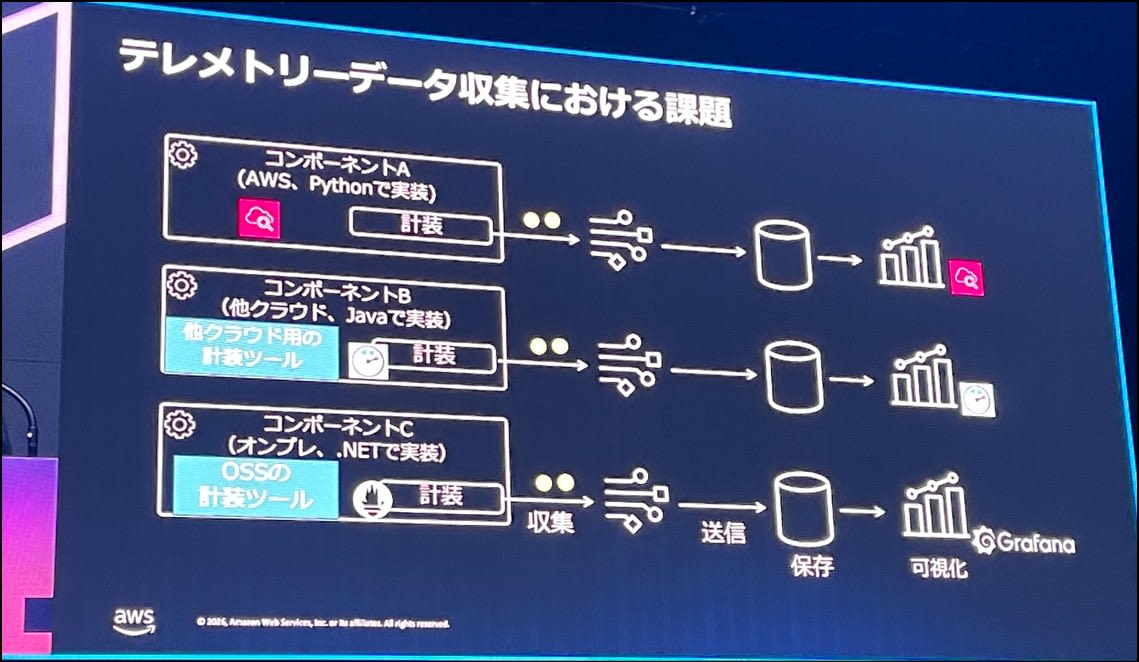
使用言語が違う等、様々なコンポーネントが混在しているような環境は往々にある。
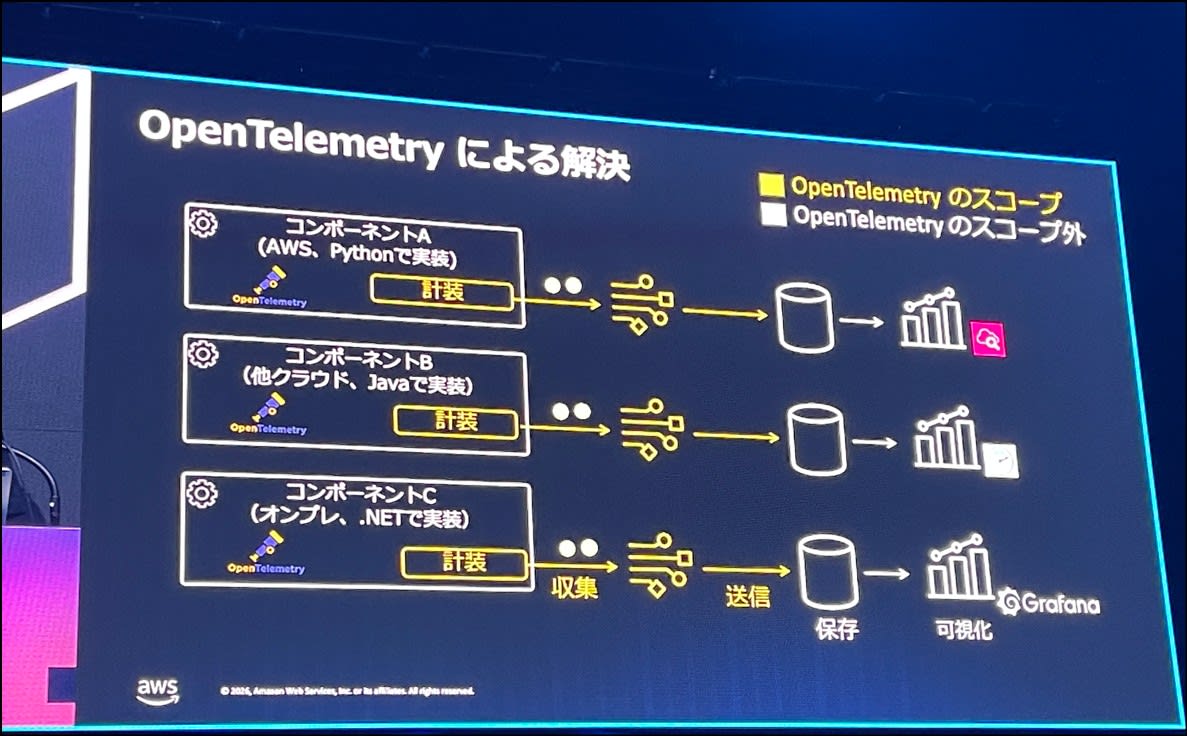
この課題を解決するのが、テレメトリデータの作成・送信の標準仕様を提供する OSS の OpenTelemetry。AWS では、AWS Distro for OpenTelemetry (ADOT) が提供されています。
これを導入することで、ベンダー依存せず、コンポーネントごとに仕様を統一し計装・送信・収集までを実現できます。
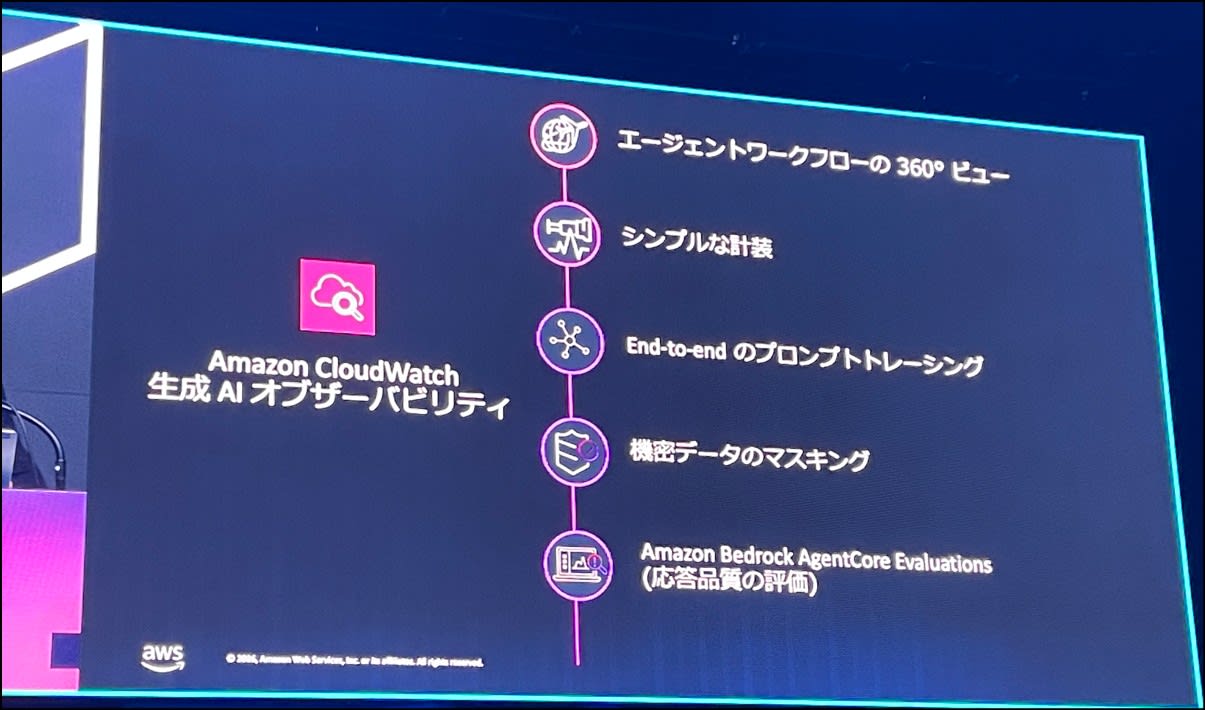
CloudWatch 生成AIオブザーバビリティの紹介と、課題へのソリューション
CloudWatch の生成 AI オブザーバビリティでは、Bedrock Agentcore を使ったケースの紹介がありました。
こちらはフレームワーク。
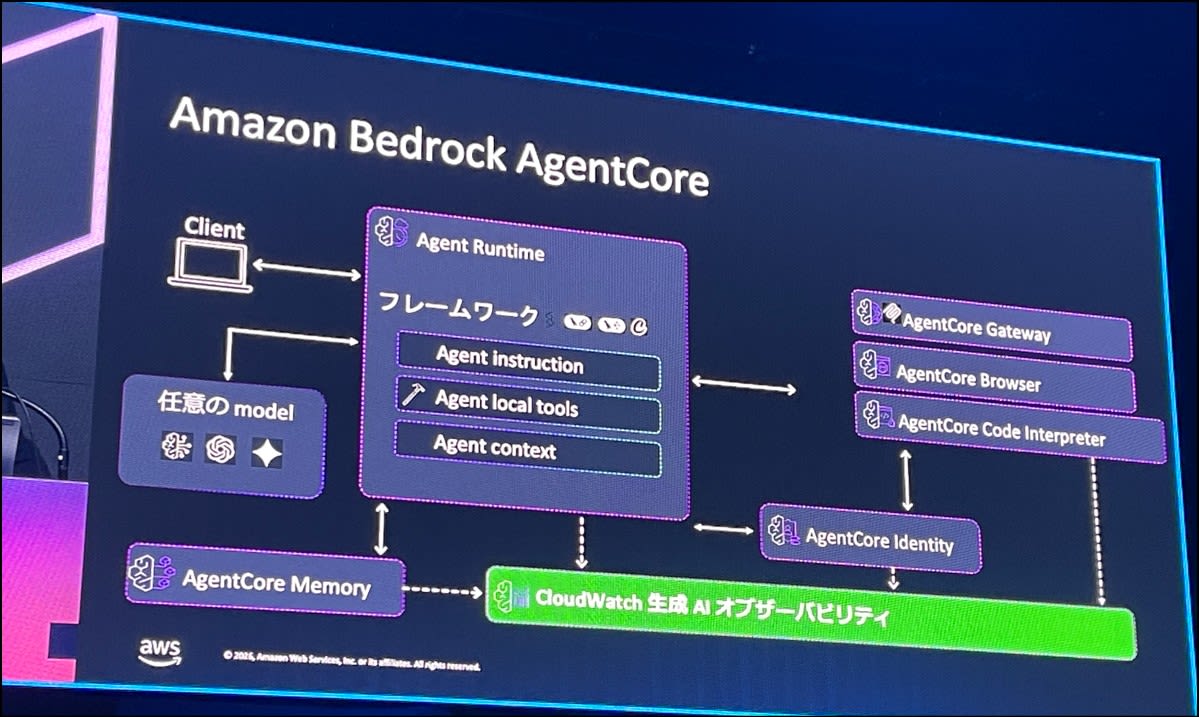
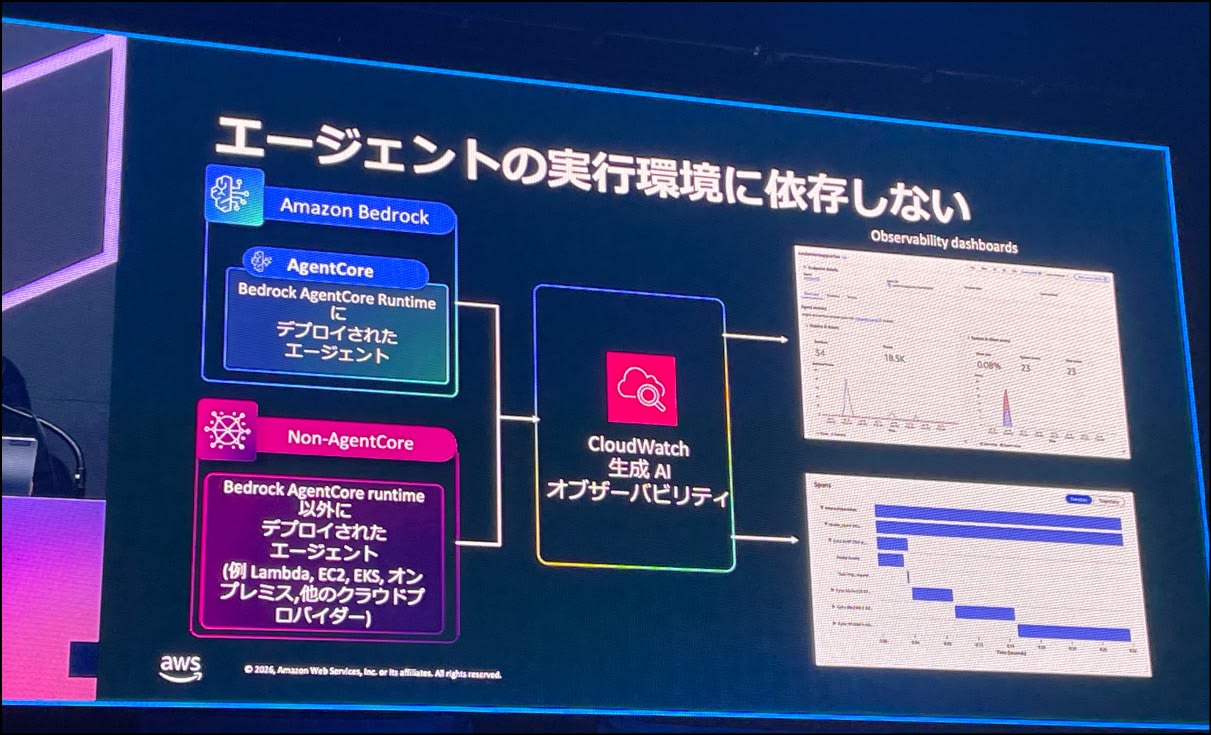
生成 AI オブザーバビリティは、エージェントの実行環境に依存しないため、色々な環境で採用できます。
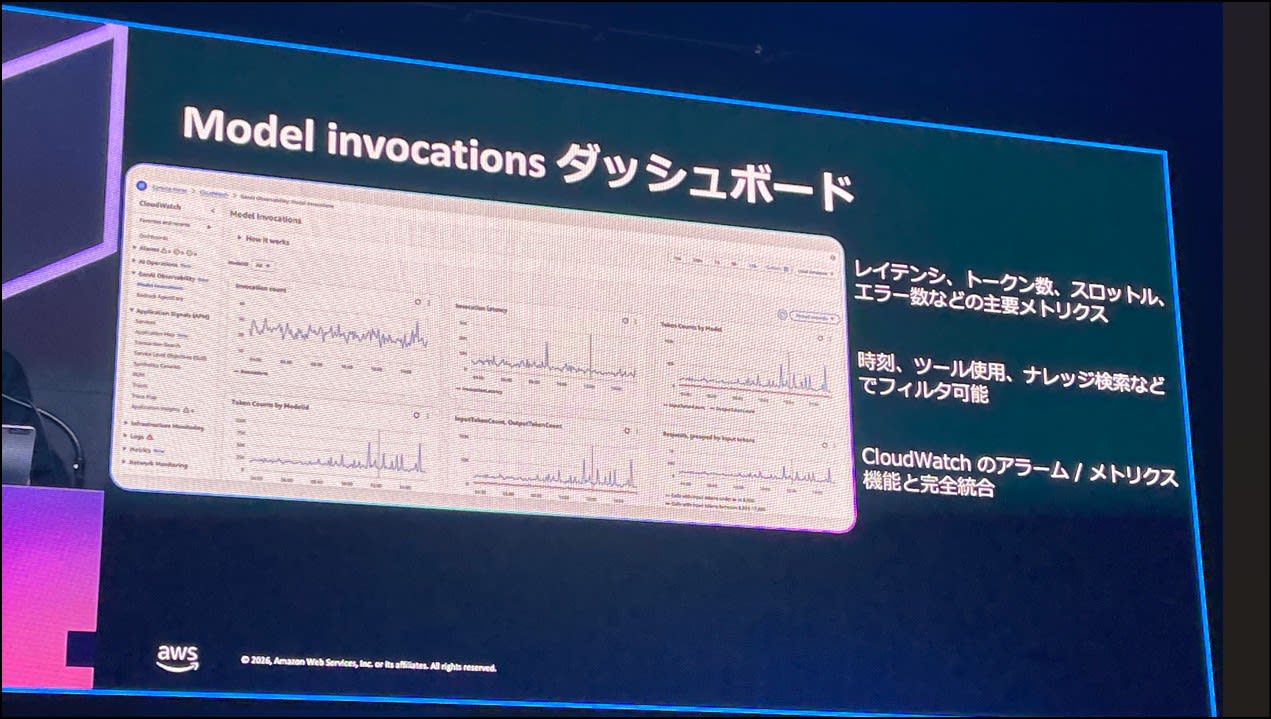
モニタリングにおける重要なメトリクス
重要なメトリクスは以下の4つ。
これらを詳細にトレースすることが、品質評価に繋がります。

メトリクスは Model Invocations ダッシュボードから確認ができます。
デフォルトで構築されており、日時やツール使用、ナレッジ検索などでフィルタも可能。
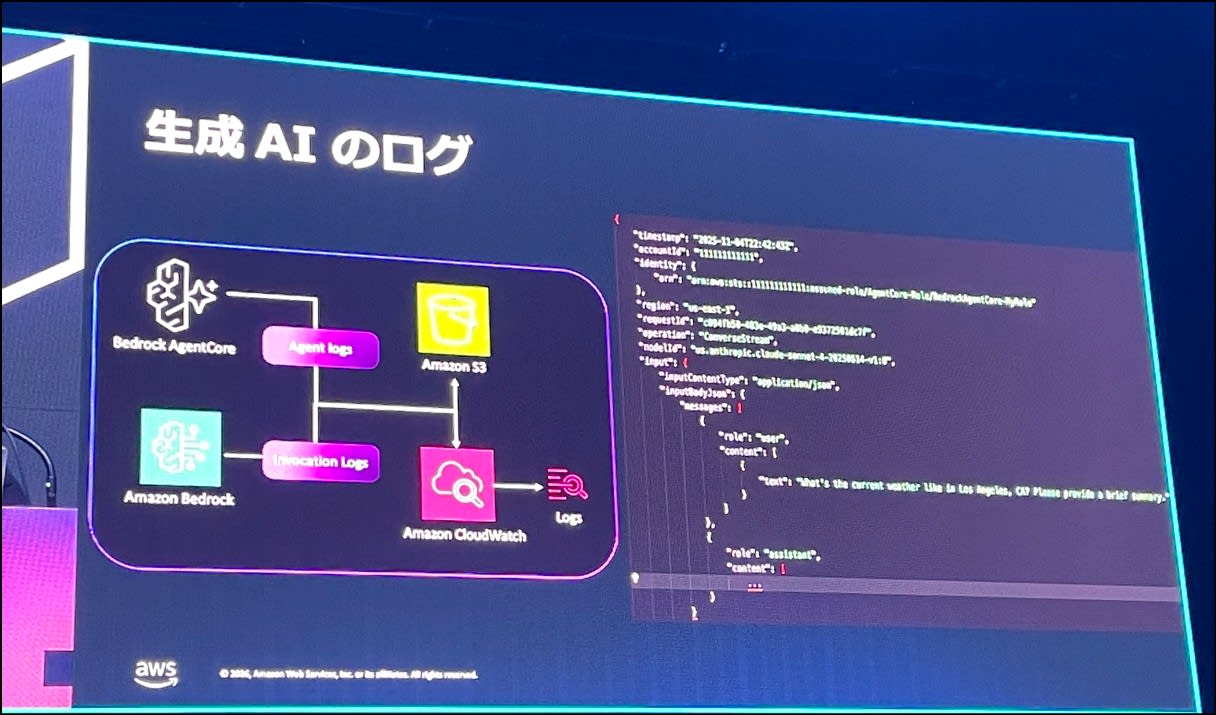
生成 AI のログ
また、ログは最も重要な要素のひとつで、生成 AI の性質として、同じ入力でも毎回異なる回答が返るため、生成 AI ワークロードは再現性がありません。
そのため「何を入力し、何が返ったか?」を記録することが大切です。
ログは CloudWatch Logs と S3 に出力されます。
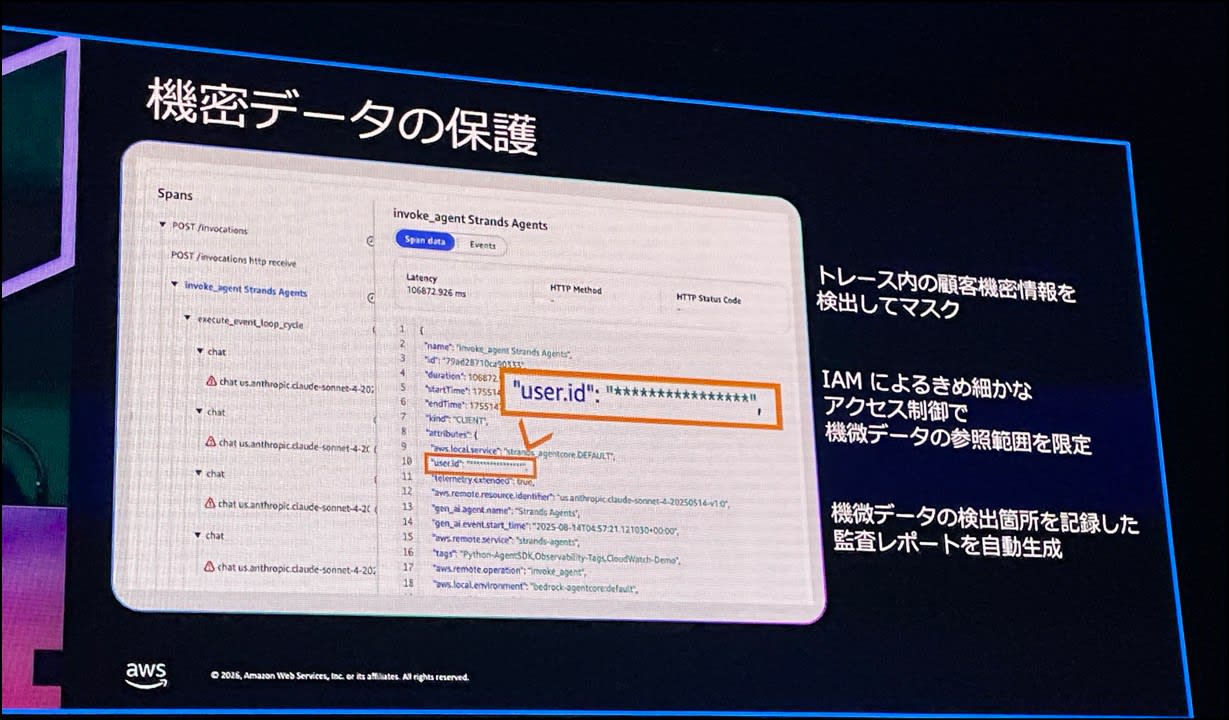
加えて、ログ内の機密情報は自動検出・マスクされます。
ただ、その情報を閲覧できる必要もあるため、マスク前の情報のアクセスには
特定の IAM ユーザのみに権限を絞ることも可能です。
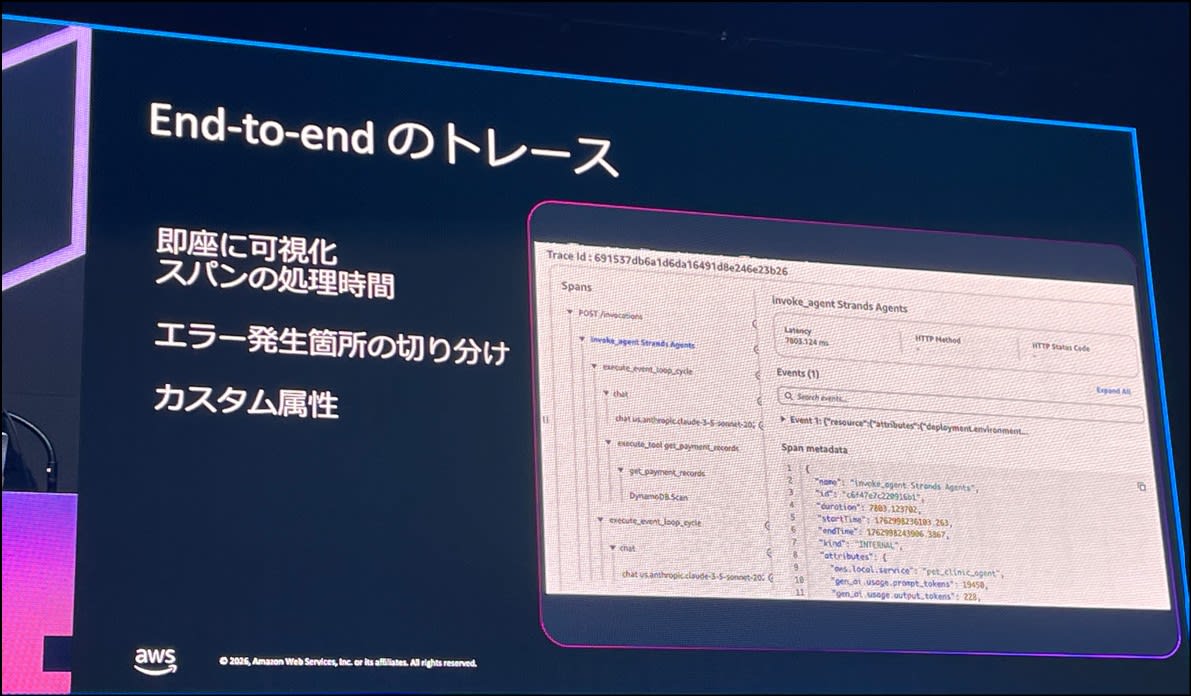
トレースの構造と End-to-end トレース
トレースは以下の構造から成り立っています。
- セッション:一連の会話
- トレース:1度のユーザの指示・応答のかたまり
- スパン:トレース内の1つの作業単位
- サブスパン:更に詳細な作業単位

ユーザのリクエストが入ってから最終的な応答が返るまでの処理全体を、最初から最後まで追跡できる仕組みが End-to-end トレース。トレースの観点としては以下の3つが重要。
Amazon Bedrock Agentcore Evaluations
このトレースを CloudWatch 生成 AI オブザーバビリティと組み合わせて実現できるのが Amazon Bedrock Agentcore Evaluations です。
AI エージェントの挙動分析や、14種類の組み込み Evaluator により、継続的な品質評価を
行います。

主な評価観点としては以下4点。

いわゆる LLM as a Judge として、自動リスク評価を行います。
評価スコアが閾値を下回った場合に CloudWatch アラームで通知することもできます。
トレースのデモ
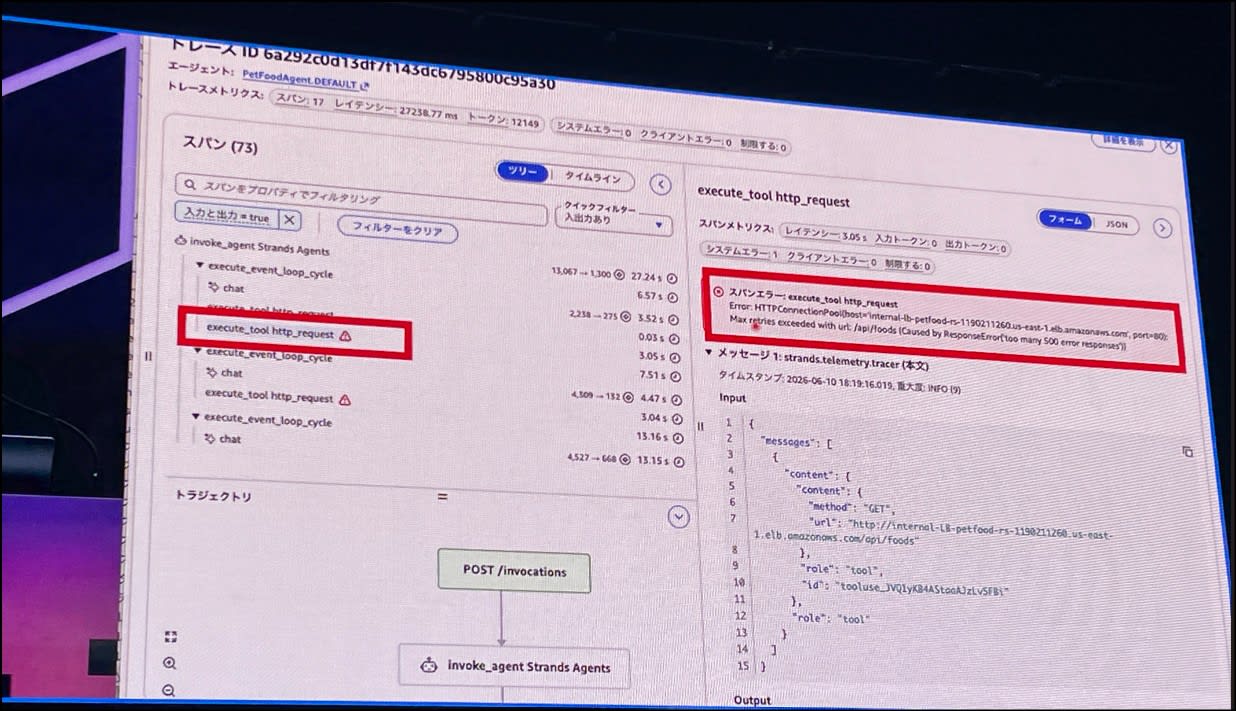
「おすすめのペットフードを提案してくれる AI エージェント」を題材に、トレースデモを紹介してくれました。
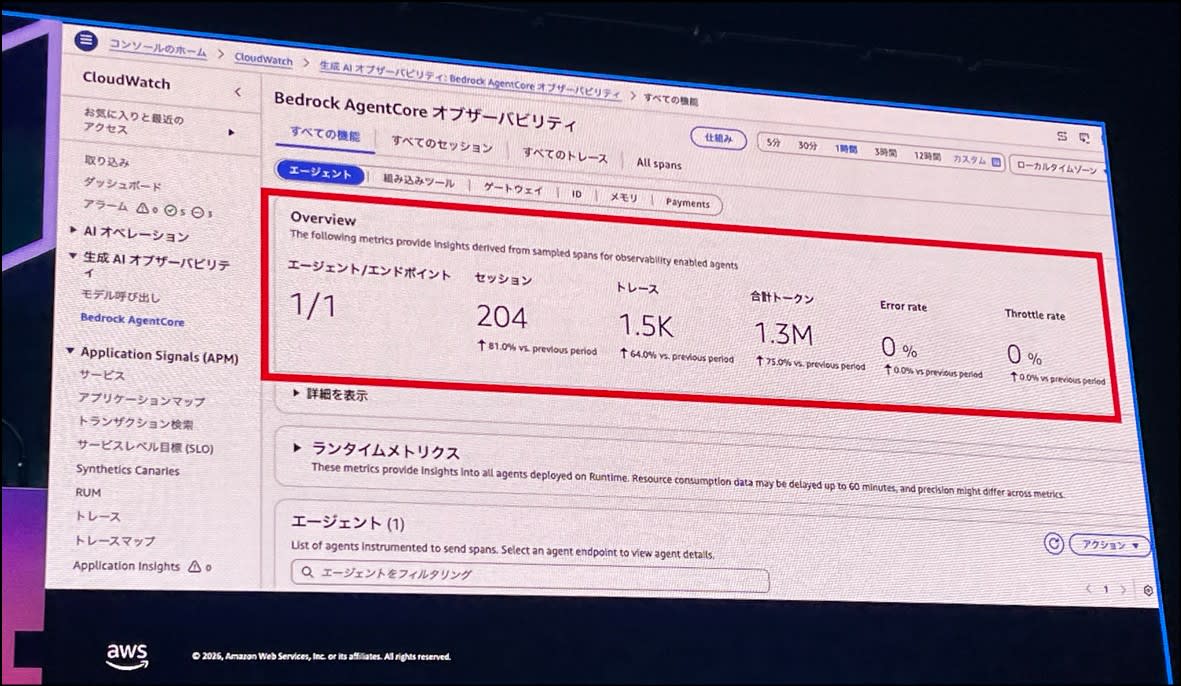
オブザーバビリティダッシュボードから、サマリが確認できます。
特定のエージェントを選択し、セッションごとのログを確認します。
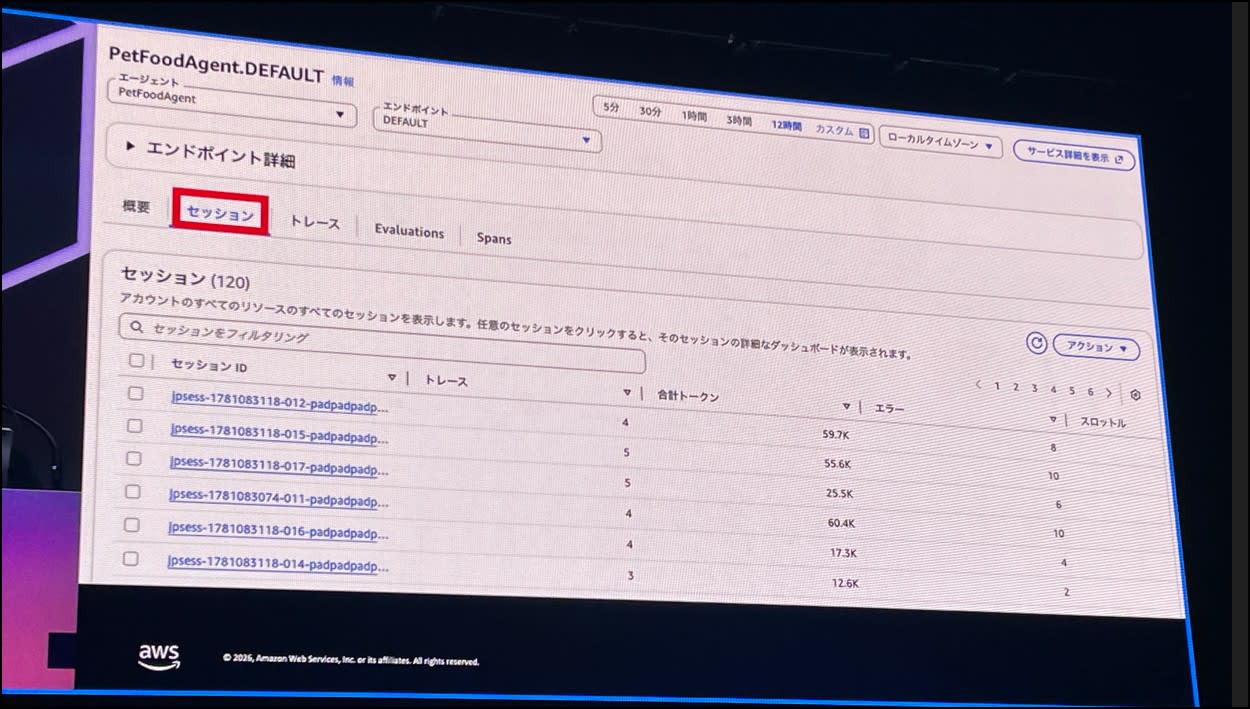
セッション詳細を開くと、スパンの詳細や、出力メッセージの詳細等が表示されます。
「!」マークの部分で何らかのエラーが出ているようです。
エラー内容を見ると、エージェントがツールとして GET /api/foods を呼び出したが、内部 ALB 配下の API が HTTP 500 を連続で返したため、リトライ上限に達して失敗した、と分かります。
まとめ
- OpenTelemer\try で計装し、CloudWatch 生成 AI オブザーバビリティで挙動を可視化
- Bedrock Agentcore Evaluations を設定し、AI エージェントの品質を継続的に評価する

基礎から応用的な部分まで網羅されており、すごく聞きやすいセッションでした!
完










