
AWS Batch のフェアシェアスケジューリングでマルチテナントなジョブ配分を検証してみた
はじめに
複数顧客のジョブを 1 つの AWS Batch キューでさばくとき、契約プランなど何らかの理由で優先度を付けたい場面があります。優遇したい顧客を優先しつつも、それ以外の顧客のジョブが完全にスタックするのは避けたい。 コンピュート環境を契約プランや顧客ごとに分ければ単純ですが、計算リソースのコスト効率は落ちます。その他にはサービスクォータの上限もあります。そして、悩ましいことにコストの問題がいつもつきまといます。
AWS Batch のフェアシェアスケジューリングポリシーがこのような要件に対応する仕組みです。
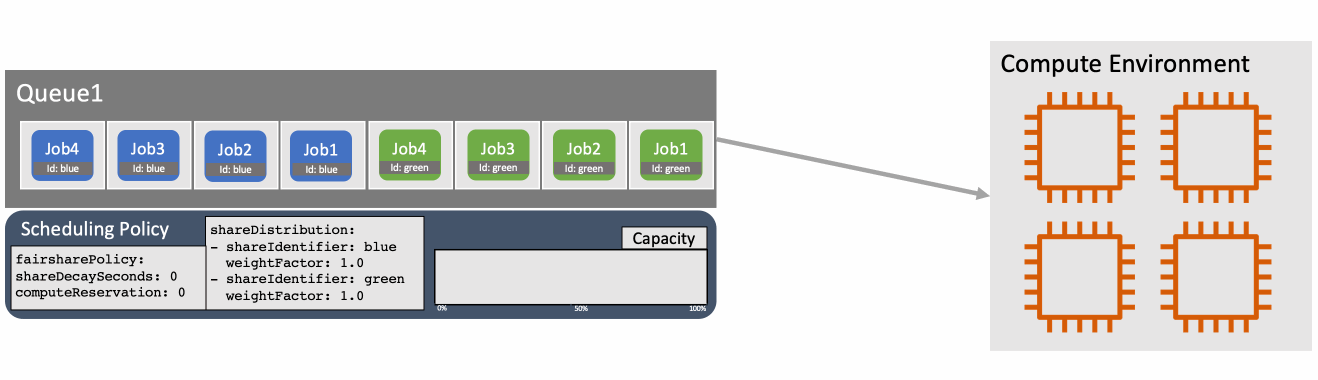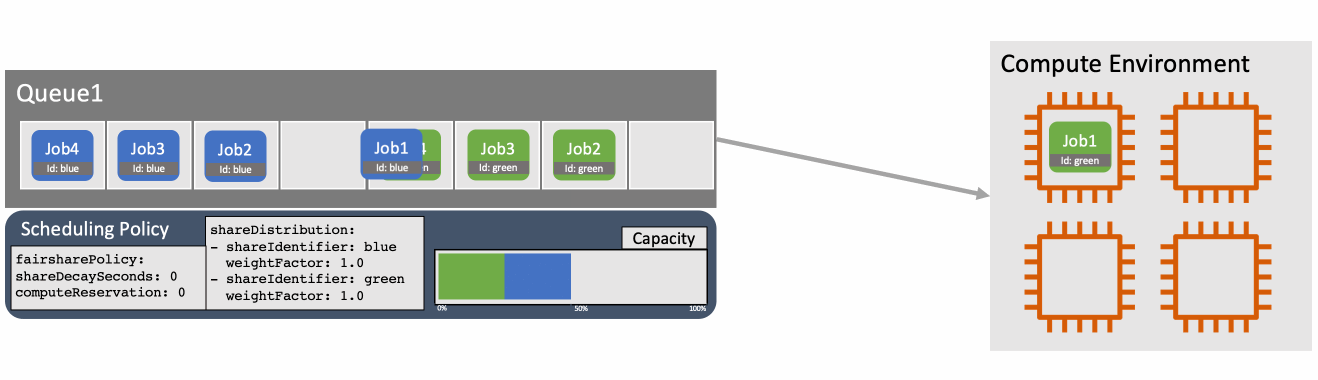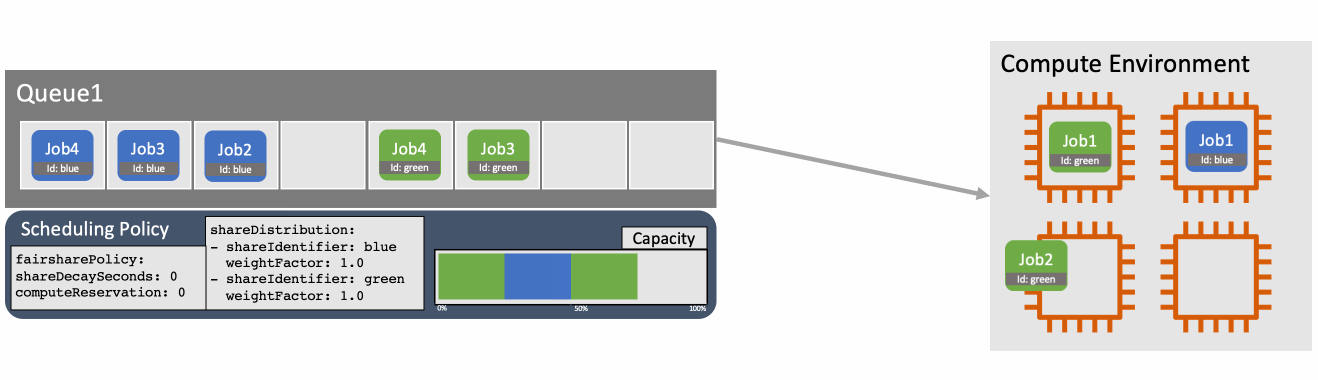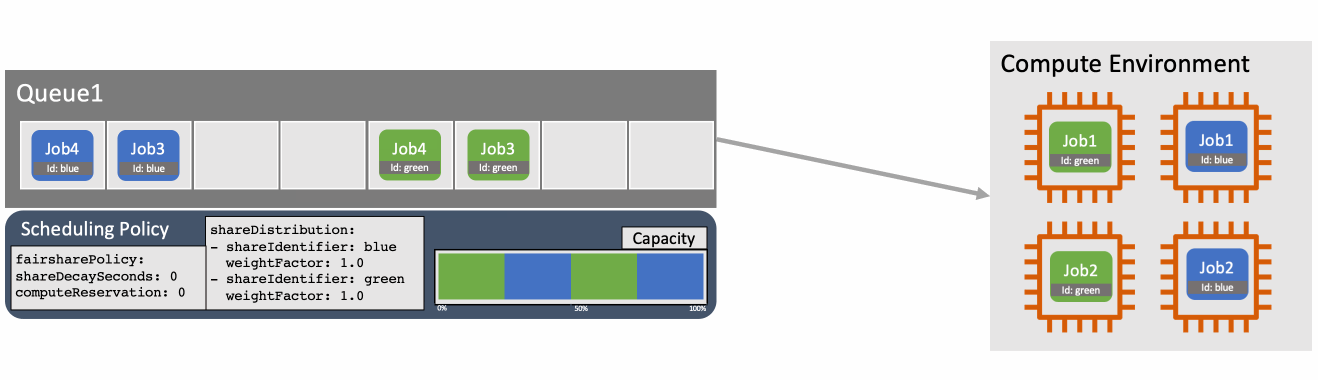
画像引用: Introducing fair-share scheduling for AWS Batch | AWS HPC Blog
フェアシェアの設定でジョブをさばく挙動をタイムライン上で確認したかったので計測しました。実行結果の 1 例として紹介します。
確認結果
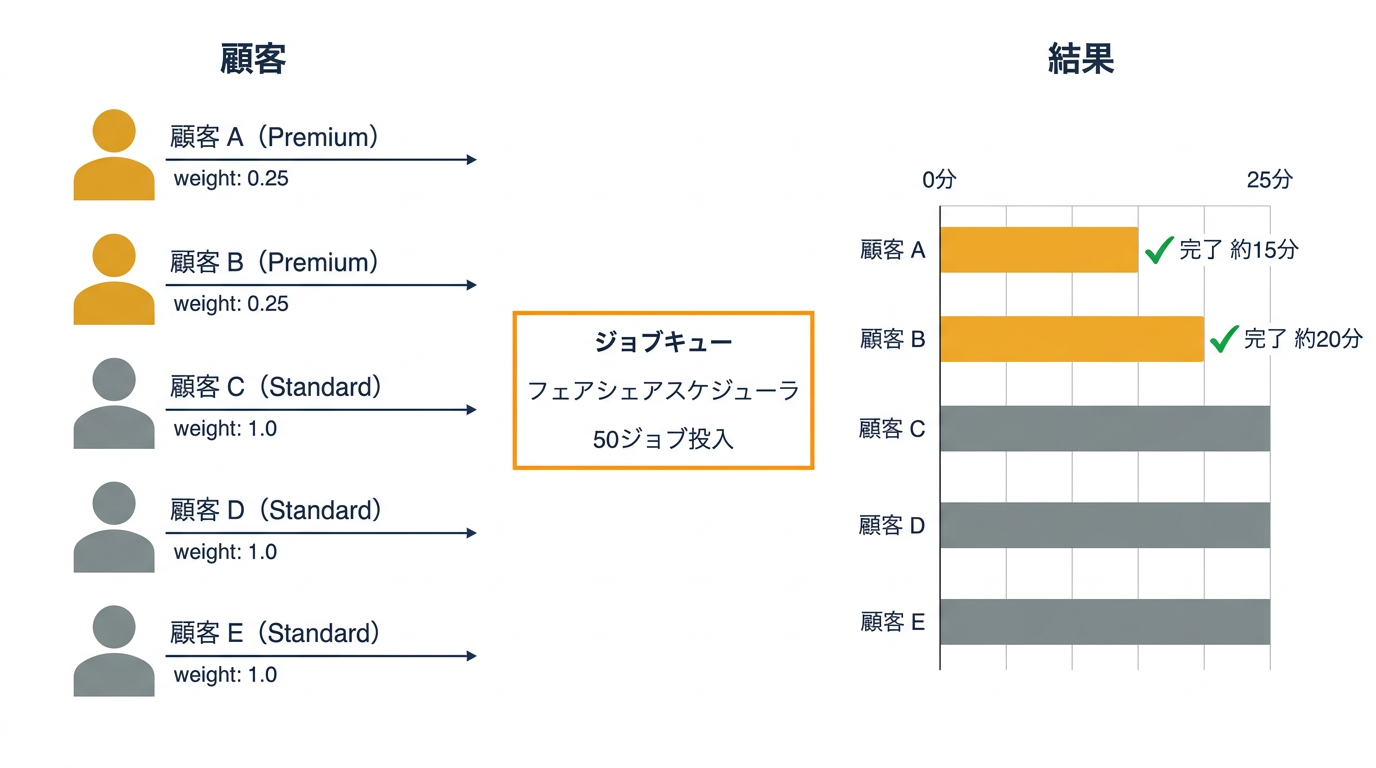
weightFactor0.25 のプレミアム顧客(A、B)が先に完走し、A は 15 分、B は 20 分で 10 ジョブを消化weightFactor1.0 の通常顧客(C、D、E)は 23 分頃から順次完走し、5 顧客 50 ジョブが 25 分で完走- 同じ重みのシェア間では
shareDecaySecondsの働きで実行時間帯がローテーションし、特定シェアの占有を防いだ - 平均的にはプレミアム顧客のジョブが優先されるが、短時間スケールでは通常顧客が一時的にプレミアム顧客の vCPU 数を上回る場面もあった(検証結果のグラフ参照)
フェアシェアスケジューリングの仕組み
フェアシェアスケジューリングポリシーは、ジョブキューの空きキャパシティを「シェア(share)」ごとにどう配分するかを決める設定です。シェアは share_identifier というラベルで区別され、ジョブをサブミットするときに --share-identifier で指定します。
ポリシーは 3 つのパラメータで挙動を制御します。
| パラメータ | 役割 | 検証時の設定値 |
|---|---|---|
weightFactor |
シェアごとの重みづけ | Premium=0.25、Standard=1.0 |
shareDecaySeconds |
過去の使用量を元に優先度決めるための期間 | 900(15 分) |
computeReservation |
未使用シェア用の予約枠(%) | 5 |
たとえば、優遇処置としてweightFactor 0.25 のシェアは 1.0 のシェアの 4 倍のリソースを獲得します。computeReservation の予約比率は (computeReservation / 100) ^ ActiveFairShares で算出されます。ActiveFairShares(アクティブなシェアの数)が多いほど予約比率は小さくなります。
検証構成
コンピュート環境
EC2 Spot で構成しました。インスタンスタイプは C 系のファミリーを指定し、世代横断で在庫を確保しやすくしています。
| 項目 | 値 |
|---|---|
| インスタンスタイプ | c6i / c6a / c7i / c7a / c8i / c8a |
| 配分戦略 | SPOT_PRICE_CAPACITY_OPTIMIZED |
| 最小 vCPU | 0 |
| 最大 vCPU | 10 |
| AZ | ap-northeast-1a / 1c / 1d(パブリックサブネット) |
最大 vCPU を 10 に絞ることでキューに滞留するジョブが生まれる状態を作っています。最大値上げすぎると全ジョブが滞留せずに一気に走ってしまい、フェアシェアの挙動が観察できません。
スケジューリングポリシー
5 顧客分のシェアを明示的に指定しました。実運用ではポリシーを毎回変更する負荷が大きいですが、検証のため明示指定にしています。顧客 A と B がプレミアム契約として、他の顧客に比べ 4 倍リソース獲得を優先する設定です。
shareDecaySeconds は 900 秒(15 分)に設定しました。短期間に大量のジョブを投入したシェア(ノイジーネイバー)の使用履歴を直近 3 ジョブ分(5 分 × 3)の時間枠で保持し、次のスケジューリング判断で他のシェアへ優先権を渡す狙いです。過去の負荷が長く尾を引かない設計です。
resource "aws_batch_scheduling_policy" "fss" {
name = "batch-fairshare-demo-fss-v2"
fair_share_policy {
compute_reservation = 5
share_decay_seconds = 900
share_distribution {
share_identifier = "premiumCustomerA"
weight_factor = 0.25
}
share_distribution {
share_identifier = "premiumCustomerB"
weight_factor = 0.25
}
share_distribution {
share_identifier = "standardCustomerC"
weight_factor = 1.0
}
share_distribution {
share_identifier = "standardCustomerD"
weight_factor = 1.0
}
share_distribution {
share_identifier = "standardCustomerE"
weight_factor = 1.0
}
}
}
ジョブ定義とサブミット
ジョブ定義は vCPU=1、memory=512、コマンドは sleep 300 のシンプルなものです。1 ジョブが 1 vCPU を 5 分間消費します。
ジョブのサブミットはスクリプトで 5 顧客 x 10 ジョブの合計 50 ジョブを並列でほぼほぼ同時に投げました。なので、今回の検証はcomputeReservationの未使用シェアに対する予約枠の挙動は観察対象としていません。
for share in premiumCustomerA premiumCustomerB standardCustomerC standardCustomerD standardCustomerE; do
for i in $(seq 1 10); do
aws batch submit-job \
--job-name "${share}-job-$(printf '%02d' "$i")" \
--job-queue "$QUEUE" \
--job-definition "$JOBDEF" \
--share-identifier "$share" &
done
done
wait
検証手順
- スケジューリングポリシー、ジョブキュー、コンピュート環境などの検証環境を構築
- スクリプトで 50 ジョブを一気に投入
- 60 秒間隔のジョブの実行状況を記録
- ジョブ完走まで観測
ジョブ実行状況の記録スクリプト
キュー名と、ジョブ定義は環境変数に入れておきます。
QUEUE="batch-fairshare-demo-queue"
JOBDEF="batch-fairshare-demo-job:1"
実行中のシェアごとの vCPU 消費量は get-job-queue-snapshot の queueUtilization から取得しました。2026 年 2 月のアップデートで追加された機能です。詳細は別記事で紹介しています。
60 秒間隔で記録し続けるスクリプトです。
while true; do
TS=$(date -u +%Y-%m-%dT%H:%M:%SZ)
aws batch get-job-queue-snapshot --job-queue "$QUEUE" --output json \
| jq -r --arg ts "$TS" '
.queueUtilization.fairshareUtilization.topCapacityUtilization[]?
| "\($ts),\(.shareIdentifier),\([.capacityUsage[]? | select(.capacityUnit == "VCPU") | .quantity] | add // 0)"
'
sleep 60
done
検証結果
50 ジョブを投入してから全シェア(5 顧客)完走までの 25 分かかりました。シェアごとの vCPU 消費量の時系列で観察しました。
実行結果を元に何個かグラフを作成したのですが、最初に載せた積み上げ面グラフが一番見やすかったかもと思いつつ考察を書いていきます。
vCPU 使用量のタイムライン
合計の vCPU 使用量が立ち上がり直後からプレミアム顧客の A と B が完走するまで上限の 10 vCPU 付近で張り付きます。
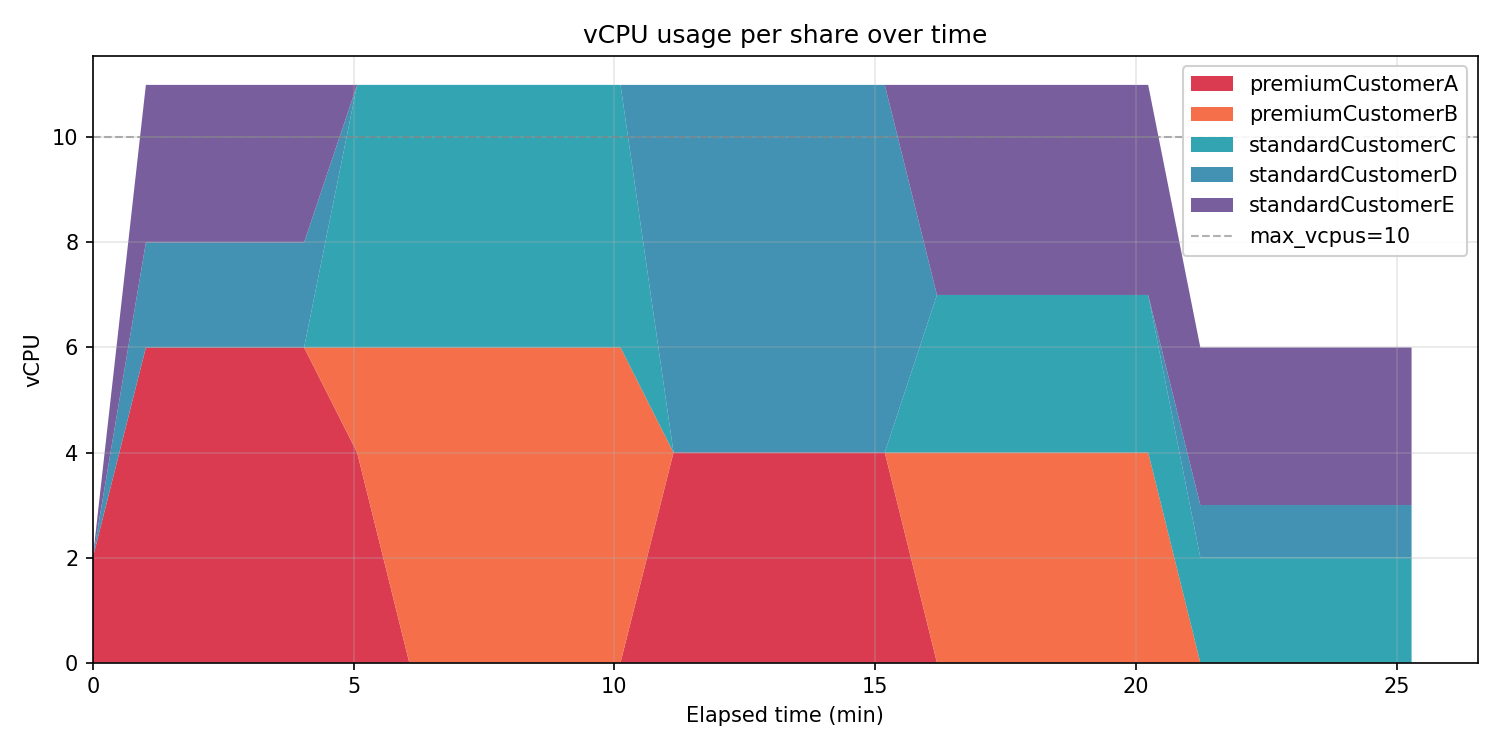
最大 vCPU は 10 指定ですが、配分戦略の関係で起動したインスタンス上で 11 vCPU を使っていた状況が長く続きました。中途半端な vCPU 数でありますが。
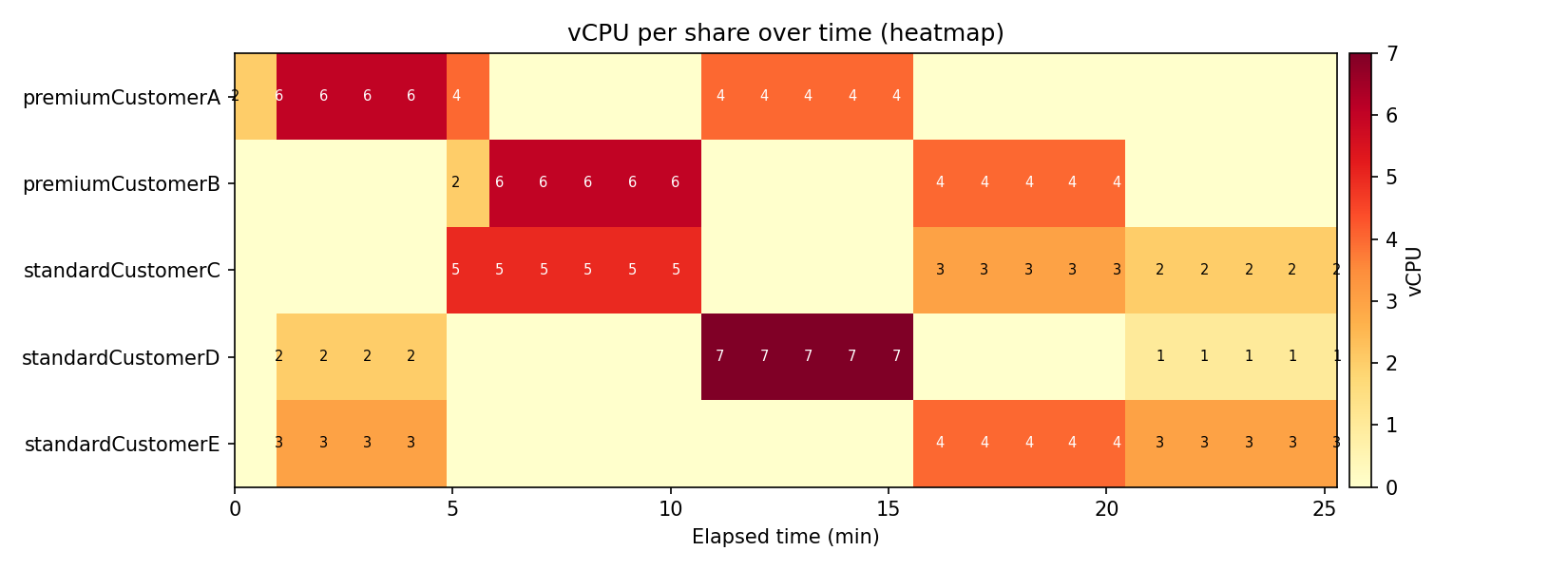
顧客別の vCPU 使用率ヒートマップ
プレミアム顧客 A と B は同じ重み付けで優先はされていますが、実行する時間帯が交互に切り替わりるのはshareDecaySeconds の設定で優先度が変化した結果です。
通常顧客の C、D、E も時間帯によって実行されるシェアが入れ替わりました。11〜15 分の 顧客 D は 7 vCPU で、プレミアム顧客の A を一時的に上回るときもありました。これもshareDecaySeconds の設定で優先度が変化した結果と考えています。
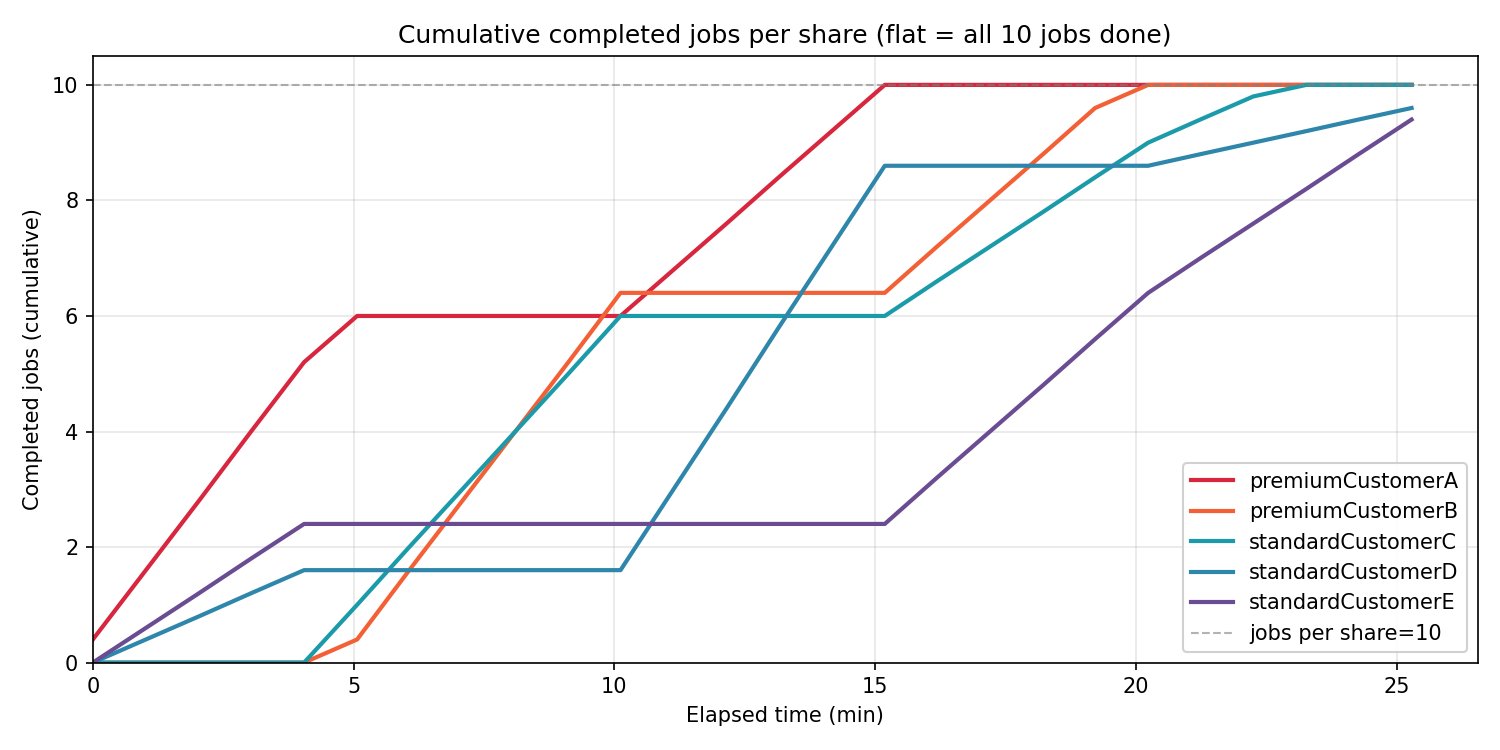
プレミアム顧客がちゃんと優先され先に完走してくれた
weightFactor の比率 0.25 対 1.0(4:1)の効果で、プレミアム顧客の各社が早く 10 ジョブを消化します。プレミアム顧客 A は 15 分、B は 20 分で完走。通常顧客の 3 シェアは 23 分頃から順次完走し、25 分過ぎにすべて終わります。こうみると重み付けによりフェアシェア内で優先されていることがわかります。
フェーズ別 RUNNING 分布の詳細
各行は投入開始からの経過時間帯です。premA〜stdE 列の数値は、その時間帯にそのシェアで RUNNING になっているジョブ数(= 消費 vCPU 数)です。
| フェーズ | 経過時間 | premA | premB | stdC | stdD | stdE | 合計 | 観測 |
|---|---|---|---|---|---|---|---|---|
| 1 | 〜5 分 | 6 | 0 | 0 | 2 | 3 | 11 | 初動: A、D、E が先行 |
| 2 | 6〜11 分 | 0 | 6 | 5 | 0 | 0 | 11 | ローテーション: A→B、D/E→C |
| 3 | 12〜16 分 | 4 | 0 | 0 | 7 | 0 | 11 | A 復帰、Standard D が突出 |
| 4 | 17〜21 分 | 0 | 4 | 3 | 0 | 4 | 11 | B、E、C が混在 |
| 5 | 22〜26 分 | 0 | 0 | 2 | 1 | 3 | 6 | Premium 完走、Standard のみ |
| 6 | 27 分〜 | 0 | 0 | 0 | 0 | 0 | 0 | 全ジョブ完走 |
まとめ
5 顧客 50 ジョブの検証から、フェアシェアスケジューリングの設計時に押さえておくべき点をまとめます。
weightFactorの比率がジョブ完走時刻の差に直結する。契約プランに応じて値を分けると優先度を付けられるshareDecaySecondsで過去使用量の影響期間を制御できる。値を変えると同じ重み内のローテーションの周期や、ノイジーネイバー抑制の長さを調整できる- 平均的には優先したシェアを多めを保つが、短時間スケールでは通常のシェアが瞬間的に上回ることがある
1 つのキューで複数契約プランを混在運用するには十分な公平性を確保できます。
おわりに
デフォルトでこういった機能が用意されているのがありがたいですね。さすがマネージドサービス。パラメータの調整は実際にワークロードに合わせて必要ですが、そこだけやれば仕組みから作る必要がないので助かります。











