
AWS BatchとAWS Step Functionsで疎なジョブの並列実行をする際のMapステートと配列ジョブの使い分けを整理した
本記事について
データ事業本部の鈴木です。
機械学習などのユースケースで、多数のデータを対象にバッチ処理したい場合に、AWSで提供されているサービスの一つとしてAWS Batchがあると思います。
AWS Batch自身もバッチ処理向けに便利なオーケストレーション機能を備えていますが、ほかのAWSサービスと連携する場合はAWS Step Functionsなどのオーケストレーターから実行することが多いと思います。
互いに独立した処理を複数に分けて並列処理したい場合、AWS Step FunctionsのMapステートを使うと複数のジョブを同時に起動して実行できますが、これはAWS Batchの配列ジョブという機能と重複する面があり、どういう場面だとどちらを使うとよいか整理したく、機能を調べてみました。
なお、今回紹介するAWS BatchとAWS Step Functionsの組み合わせだと、基本的にはどちらの機能を採用してもあまり変わらないかなと思いました。
この記事で想定する内容はAWS Batchを使ったいわゆる疎結合HPCワークロードのみになります。
疎結合な並列処理のための仕組み
AWS BatchとAWS Step Functionsの組み合わせの場合、以下の2つの方法を使うことが一般的と思います。
1. AWS Step FunctionsのMapステートを使う方法
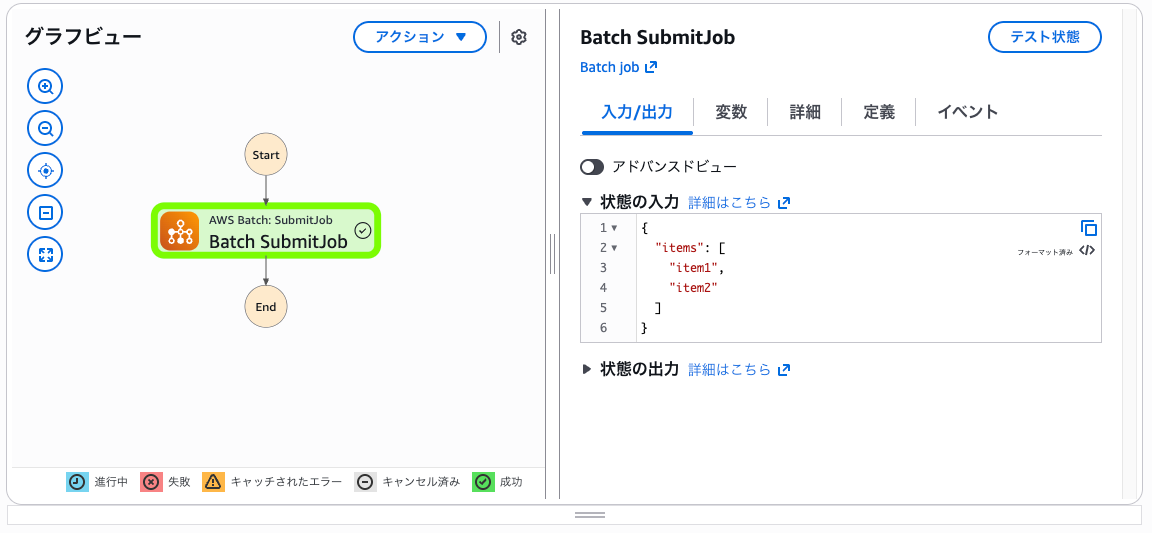
以下のようにMapステートの反復ごとに、AWS BatchへのBatch: SubmitJobをリクエストできます。
▼ AWS BatchへのSubmit JobにMapステートを使う例
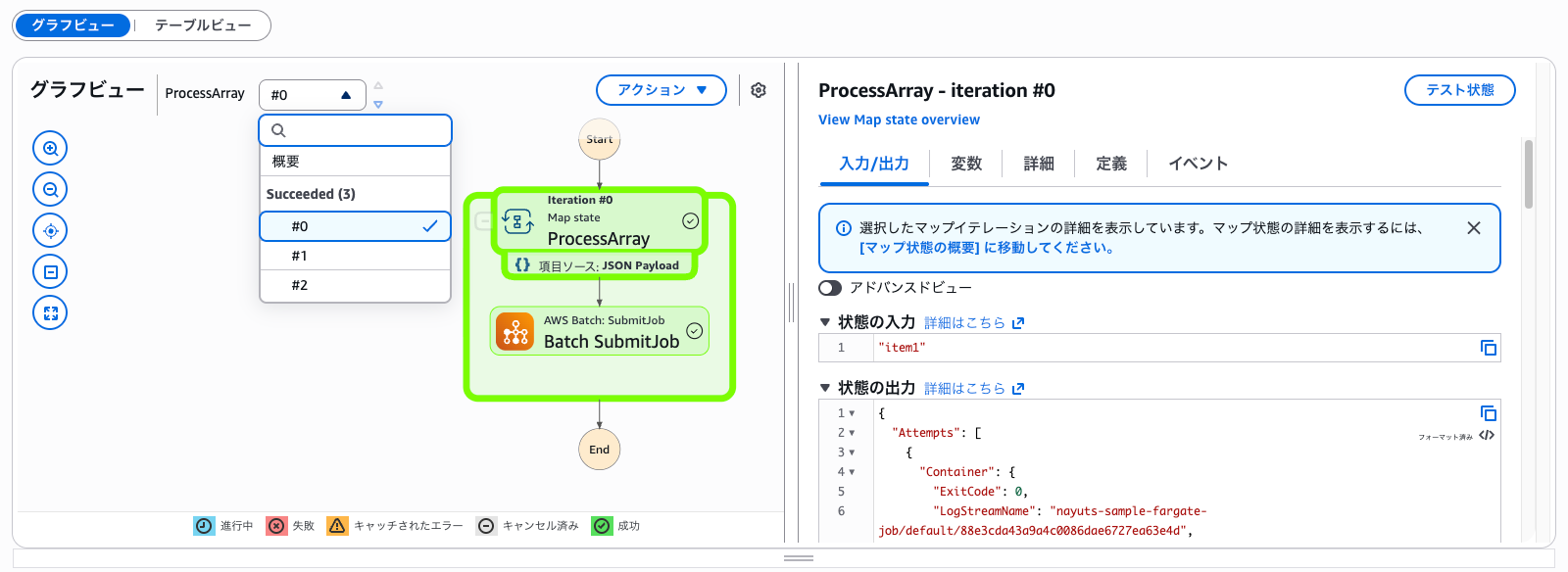
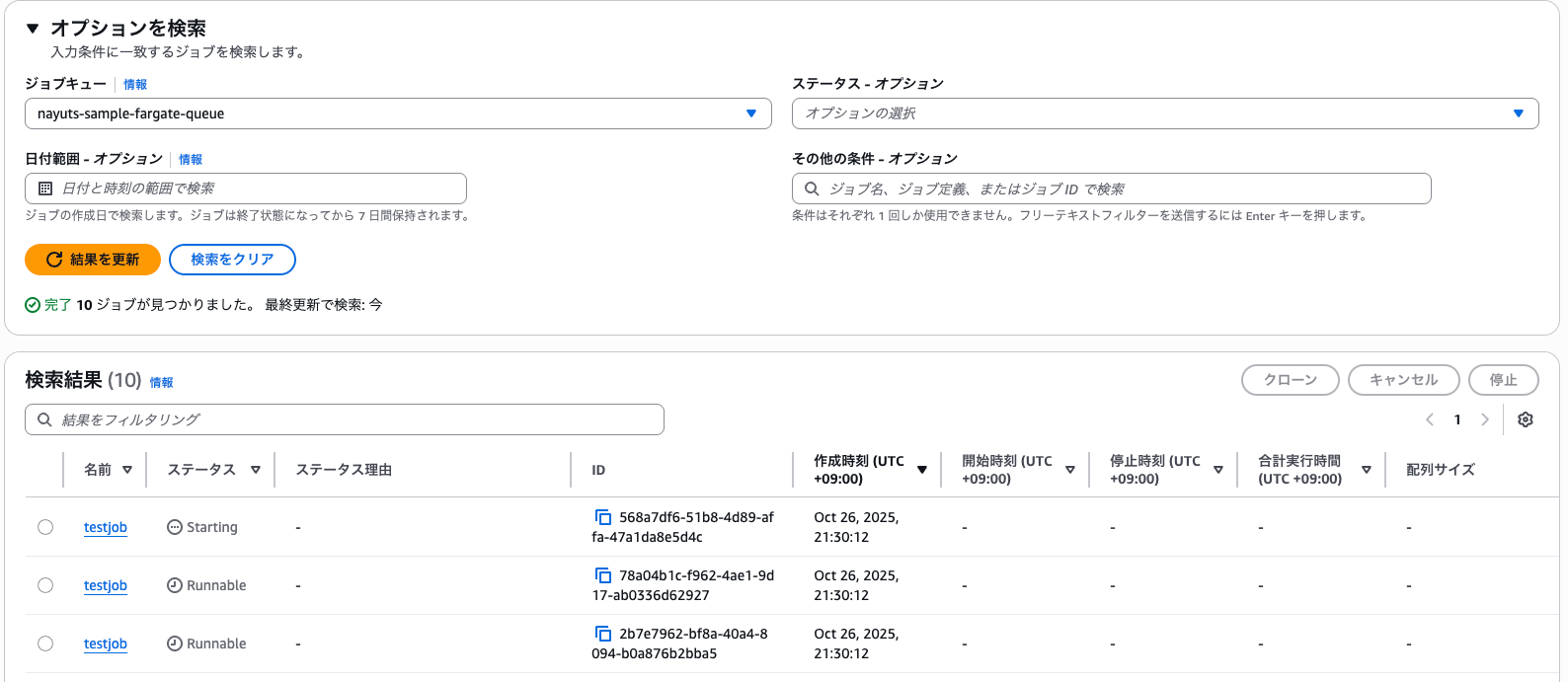
ジョブは指定したジョブキューに個別に投入されます。
▼ Submitされたジョブ
▼ ステートマシンの定義例
ジョブキューを挟むものの、.syncをつけることでステートマシンからジョブの終了を待つこともできます。
{
"Comment": "シンプルなMapステートからBatch SubmitJobを実行する例",
"StartAt": "ProcessArray",
"States": {
"ProcessArray": {
"Type": "Map",
"ItemsPath": "$.items",
"Iterator": {
"StartAt": "Batch SubmitJob",
"States": {
"Batch SubmitJob": {
"Type": "Task",
"Resource": "arn:aws:states:::batch:submitJob.sync",
"Parameters": {
"JobDefinition": "arn:aws:batch:ap-northeast-1:アカウントID:job-definition/nayuts-sample-job-job",
"JobQueue": "arn:aws:batch:ap-northeast-1:アカウントID:job-queue/nayuts-sample-job-queue",
"JobName": "testjob"
},
"End": true
}
}
},
"End": true
}
}
}
メリット
- ステートマシンのMapステートの設定からジョブのリクエストを制御できるため、ステートマシン側で管理しやすい
- 個別にジョブの実行をリクエストするため、個々のジョブにパラメータを直接渡すことができ、ステートマシンから処理の全容が分かりやすい
デメリット
- Mapステートの反復数が増えた際にステートマシンの実行履歴も数が多くなり少し見づらい場合がある
- Batchへのリスエスト数は制御できるものの、実際の実行はBatch側で制御され若干直感的でなくなる
2. AWS Batchの配列ジョブを使う方法
AWS Batchでは配列ジョブを使うと、一つのジョブから子ジョブを作成して別々のコンピュートで実行することで、並列にジョブを実行できます。
配列ジョブについては以下のブログが分かりやすいです。
ステートマシンからは以下のようにBatch: SubmitJobをリクエストする1つのステートから配列ジョブを実行します。
▼ 配列ジョブをSubmitするステートマシン
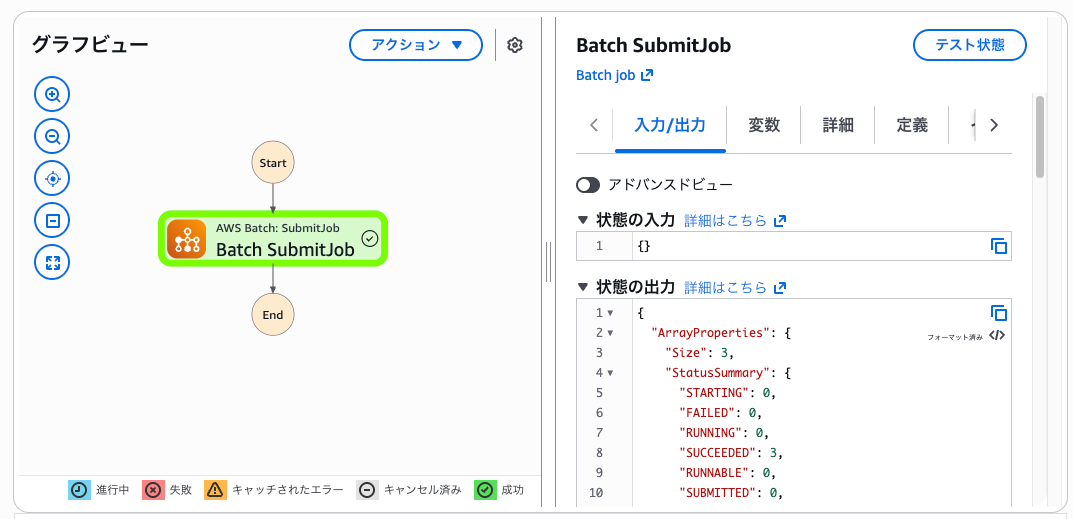
▼ 実行された配列ジョブ
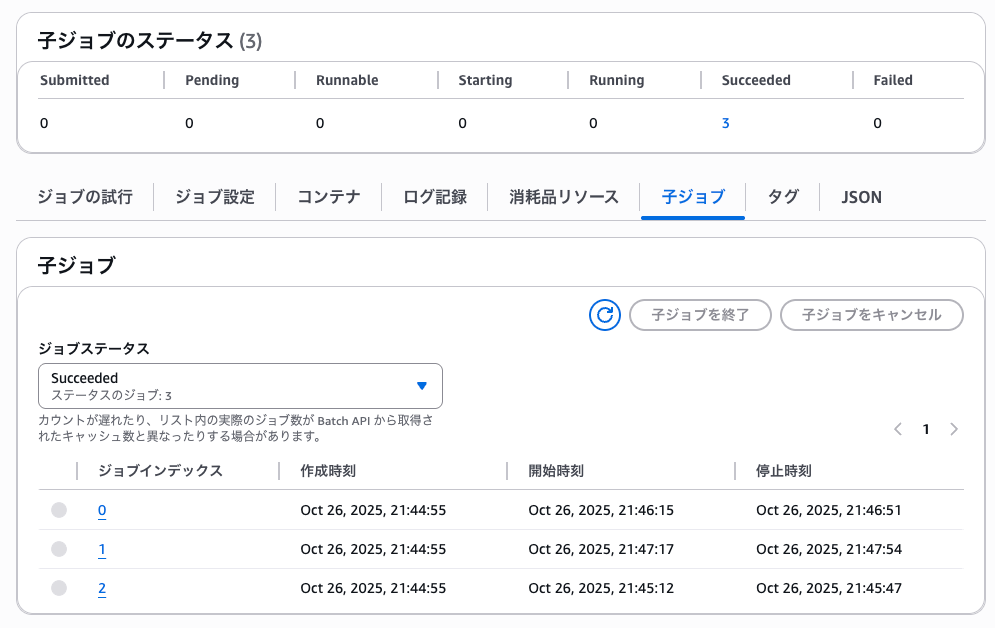
※最大4vCPUのFargateタイプのコンピューティング環境で4vCPUのジョブを実行したため順番に実行されています。
▼ ステートマシンの定義例
ArrayPropertiesを指定することで配列ジョブを作成できます。.syncをつけることで子ジョブ全ての完了を待つ挙動となります。
{
"Comment": "Batch SubmitJobで配列ジョブを実行する例",
"StartAt": "Batch SubmitJob",
"States": {
"Batch SubmitJob": {
"Type": "Task",
"Resource": "arn:aws:states:::batch:submitJob.sync",
"Arguments": {
"JobName": "testjob",
"JobDefinition": "arn:aws:batch:ap-northeast-1:アカウントID:job-definition/nayuts-sample-fargate-job",
"JobQueue": "arn:aws:batch:ap-northeast-1:アカウントID:job-queue/nayuts-sample-job-queue",
"ArrayProperties": {
"Size": 3
}
},
"End": true
}
},
"QueryLanguage": "JSONata"
}
メリット
- AWS Batchへのリクエストが単純なステートになり、ステートマシン側が簡潔になる
- 実行数の制御や失敗時のリトライなどをAWS Batch側に任せることで、役割分担が分かりやすい
デメリット
- オーケストレーションをAWS Batchに任せるため、ジョブの実行状況がステートマシンから若干見づらい
- ステートマシンから配列ジョブの子ジョブに直接パラメータを渡せない(ただし
AWS_BATCH_JOB_ARRAY_INDEXを使って子ジョブそれぞれにパラメータを割り振ることは可能)
2つの仕組みの違いについて
AWS Batchにさせたいジョブを複数と捉えられるか、単一と捉えられるかによって、どちらがよりしっくりくるか変わるかなと思いました。
- ジョブを複数と捉え、個々のジョブをステートマシンから直接的に制御したい → AWS Step FunctionsのMapステートを使う
- ジョブを単一と捉え、ジョブ内で複数に分割して実行し、その際のリソース管理をAWS Batchに任せたい → AWS Batchの配列ジョブを使う
また、Step Functionsを使ってジョブを制御する場合、AWS Batchへのリクエストを制御するイメージになります(ただし実際にいつ実行するかはBatch側で制御される)。
AWS Batchの配列ジョブを使って制御する場合は、AWS Batchが計算機資源の容量に合わせて実行を制御するイメージになります。
なお、今回はAWS Batchをワークロードのインフラストラクチャに使っており、AWS Batchの制御が支配的になります。大きな違いがあるというよりは、どちらのサービスが使い慣れているかや考えている設計のコンセプトによりしっくりくるかで選ぶので良いように思いました。
AWS Batch以外をジョブ実行に使う場合との比較
処理の実行基盤をAWS BatchではなくLambda関数やECSタスクにする場合は明示的なジョブキューの仕組みがないので、Mapステートを使った制御が第一候補になると思います。AWS Batchを基盤とした場合と比較して、AWS Batchの特徴との違いが分かりやすいため補足で記載します。
Lambda関数
ステートマシンからMapステートを使い直接Lambda関数を実行することが可能です。
また、ステートマシンからSQSにメッセージをキューイングし、SQSをイベントソースにLambda関数を起動することも可能です。ただしLambda関数のスケーリング動作はSQSイベントソース向けの仕様があるため、考慮した設計が必要です。
機械学習などの場合には予測結果やモデルアーティファクトの保存にも注意が必要です。S3バケットへのAPIリクエストは安価なものの、回数が非常に多い場合には無視できない料金になります。
このような理由から、実行数が多い場合にはコンピュートの起動のオーバーヘッドや結果の同期の時間やコストも含めて考える必要があります。ある程度の粒度で処理単位をまとめ、ECSタスクやAWS Batchで処理する方が扱いやすい場合もあります。
ECSタスク
AWS Batchを挟まず、直接ステートマシンからECSタスクを実行することも可能です。この場合、ECSタスクの同時実行数はステートマシンから直接制御することになります。
ECSタスクの場合はLambda関数と違って実行時間の制限がないため、タスクあたりの処理時間が大きくなることを気にする必要がありません。
ただしECSタスクの起動にもオーバーヘッドやリクエストレートがあります。大量のタスクを起動する際にはクォータ内でどの程度のパフォーマンスが出せるかは試算する必要があります。
配列ジョブの子ジョブそれぞれにパラメータを渡す例
配列ジョブを使うと簡単に疎に処理を行える子ジョブを作成できることは分かりましたが、Mapステートと異なりステートマシン側で管理しているパラメータを個々に子ジョブに渡すといったことが直接的にはできません。
ジョブごとに特定のパラメータを渡して処理を実行させたいときは少し不便な印象があります。
ただし、AWS_BATCH_JOB_ARRAY_INDEXに格納されたインデックス番号と環境変数を使って少し工夫をすれば、子ジョブが自身の処理に必要な値を取得させることが可能なため、実現方法を確認しました。
今回はステートマシンの入力に渡されたリストの要素を各子ジョブから認識させる例を試してみました。
子ジョブにはステートマシンからリスト全体を渡し、コンテナ側の実装でAWS_BATCH_JOB_ARRAY_INDEXを元に必要な要素を取得させます。
配列サイズも渡すリストのサイズを元に動的に制御します。
▼ステートマシンの定義例
子ジョブに渡したい値はContainerOverridesのEnvironmentから渡しました。配列サイズもJSONataを使えばステートマシン側のパラメータを参照して動的に変えることが可能です。
{
"Comment": "入力のリストを擬似的に子ジョブに配分して処理する",
"StartAt": "Batch SubmitJob",
"States": {
"Batch SubmitJob": {
"Type": "Task",
"Resource": "arn:aws:states:::batch:submitJob.sync",
"Arguments": {
"JobName": "testjob",
"JobDefinition": "arn:aws:batch:ap-northeast-1:アカウントID:job-definition/nayuts-sample-fargate-job",
"JobQueue": "arn:aws:batch:ap-northeast-1:アカウントID:job-queue/nayuts-sample-job-queue",
"ArrayProperties": {
"Size": "{% $count($states.input.items) %}"
},
"ContainerOverrides": {
"Environment": [
{
"Name": "ITEMS",
"Value": "{% $string($states.input.items) %}"
}
]
}
},
"End": true
}
},
"QueryLanguage": "JSONata"
}
▼コンテナで実行する処理
環境変数から必要な値を読み込みます。
import json
import os
def main():
idx = os.environ.get('AWS_BATCH_JOB_ARRAY_INDEX', 100)
idx = int(idx)
items = os.environ.get('ITEMS', '[]')
items = json.loads(items)
print(f"idx: {idx}, items: {items}")
print(f"My item: {items[idx]}")
if __name__ == '__main__':
main()
▼2番目の子ジョブのログ
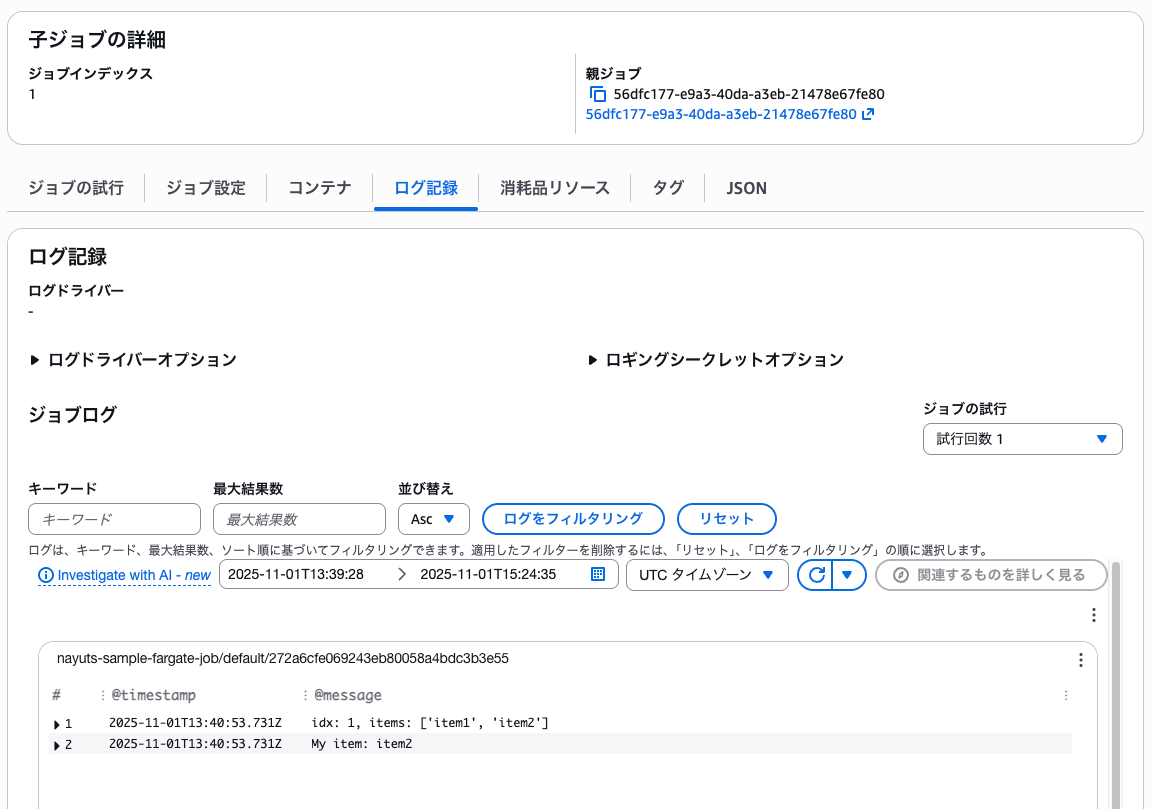
上記のように、ステートマシンの入力から、子ジョブが自身の使う値を取得することができました。
最後に
AWS BatchとAWS Step Functionsで疎結合HPCワークロード実行する際に、Mapステートと配列ジョブのそれぞれを使った比較について整理してみました。参考になりましたら幸いです。










