
【AWS CDK】EC2にGrafanaをインストールして、DuckDBでS3データを可視化してみた
はじめに
こんにちは、コンサルティング部の神野です。
前回、Azure Blob StorageのデータをローカルのGrafanaとDuckDBで可視化する記事を書きました。今回は、同じような可視化をAWS環境で実現してみたいと思います!
ただ前回同様にローカル環境で実装すると、アクセスキーベースの認証になるので、サクッとAWS CDK(以下CDK)を使ってEC2上にGrafanaを構築し、IAMロールによる認証でS3にアクセスする構成で作成してみました。
構成するシステム
今回構築するシステムの全体像は以下の通りです。
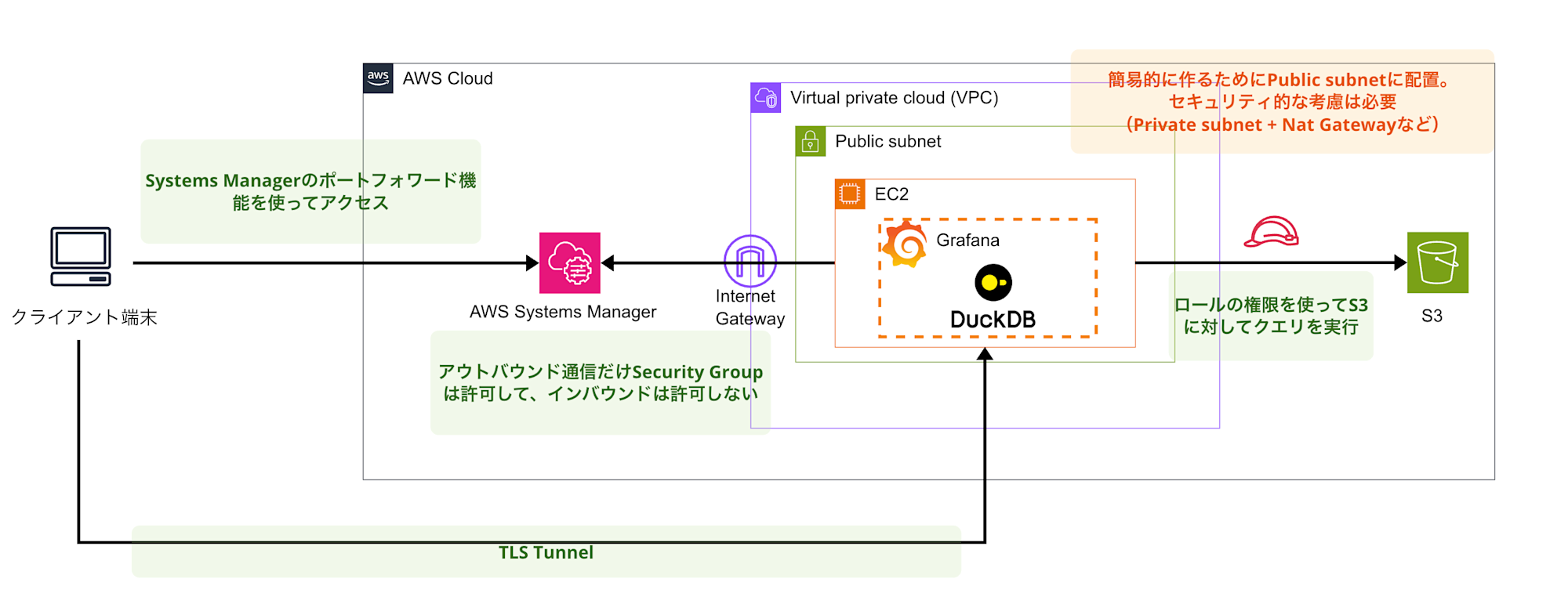
EC2インスタンス上でGrafana OSSとDuckDBプラグインを動かして、S3バケットに保存されたデータ(Parquet形式)を可視化する仕組みにしました。
EC2からS3へのアクセスにはIAMロールを使用し、外部からのアクセスはAWS Systems Manager Session Manager(以下SSM)を通じてセキュアに行います。VPCはデフォルトのものを使用し、セキュリティグループではインバウンドルールを開放しない設計にしました。
前提条件・環境
使用したソフトウェア・サービス
- AWS CDK: 2.1004.0
- Node.js: v20.16.0
- Amazon Linux 2023
- Grafana OSS: 最新版
- DuckDB Plugin: v0.2.0
- AWS CLI: 2.17.27
事前準備
- AWS CLIが設定済みでCDKデプロイ権限があること
- CDKがブートストラップ済みであること
- 適切なIAM権限(EC2、S3、IAM関連のリソース作成権限)
- AWS CLIでSSM Session Manager使用権限があること
CDKによるインフラ構築
ソースコード全体は下記レポジトリに格納しているので、必要に応じてご参照ください。
ディレクトリ構成
ディレクトリの構造は以下のようになります。
grafana-duckdb-aws/
├── lib/
│ └── grafana-duckdb-stack.ts
├── scripts/
│ └── setup-grafana.sh
├── bin/
│ └── grafana-duckdb-aws.ts
├── package.json
└── cdk.json
CDKスタックの実装
メインのスタック定義です。EC2、S3、IAMロールを一括で構築します。
import * as cdk from "aws-cdk-lib";
import * as ec2 from "aws-cdk-lib/aws-ec2";
import * as iam from "aws-cdk-lib/aws-iam";
import * as s3 from "aws-cdk-lib/aws-s3";
import { Construct } from "constructs";
import * as fs from "fs";
import * as path from "path";
export class GrafanaDuckdbStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// VPC設定
const vpc = ec2.Vpc.fromLookup(this, "DefaultVPC", {
isDefault: true,
});
// S3バケット
const dataBucket = new s3.Bucket(this, "GrafanaDataBucket", {
bucketName: `grafana-duckdb-data-${cdk.Aws.ACCOUNT_ID}-${cdk.Aws.REGION}`,
removalPolicy: cdk.RemovalPolicy.DESTROY, // 開発環境用
autoDeleteObjects: true, // 開発環境用
});
// セキュリティグループ
const grafanaSecurityGroup = new ec2.SecurityGroup(
this,
"GrafanaSecurityGroup",
{
vpc,
description: "Security Group for Grafana instance",
allowAllOutbound: true,
}
);
// IAM ロール
const grafanaRole = new iam.Role(this, "GrafanaInstanceRole", {
assumedBy: new iam.ServicePrincipal("ec2.amazonaws.com"),
description: "IAM role for Grafana EC2 instance",
managedPolicies: [
iam.ManagedPolicy.fromAwsManagedPolicyName(
"AmazonSSMManagedInstanceCore"
),
],
});
// S3バケットへのアクセス権限を追加
dataBucket.grantReadWrite(grafanaRole);
grafanaRole.addToPolicy(
new iam.PolicyStatement({
effect: iam.Effect.ALLOW,
actions: [
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:ListBucketMultipartUploads",
],
resources: [dataBucket.bucketArn],
})
);
grafanaRole.addToPolicy(
new iam.PolicyStatement({
effect: iam.Effect.ALLOW,
actions: [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:GetObjectVersion",
"s3:ListMultipartUploadParts",
"s3:AbortMultipartUpload",
],
resources: [`${dataBucket.bucketArn}/*`],
})
);
// UserData - セットアップスクリプトの読み込み
const userDataScript = fs.readFileSync(
path.join(__dirname, "../scripts/setup-grafana.sh"),
"utf8"
);
const userData = ec2.UserData.forLinux();
userData.addCommands(userDataScript);
// キーペア
const keyPair = new ec2.KeyPair(this, "KeyPair", {
type: ec2.KeyPairType.ED25519,
format: ec2.KeyPairFormat.PEM,
});
// EC2インスタンス
const grafanaInstance = new ec2.Instance(this, "GrafanaInstance", {
vpc,
vpcSubnets: { subnetType: ec2.SubnetType.PUBLIC },
instanceType: ec2.InstanceType.of(
ec2.InstanceClass.T3,
ec2.InstanceSize.MICRO
),
machineImage: ec2.MachineImage.latestAmazonLinux2023(),
securityGroup: grafanaSecurityGroup,
role: grafanaRole,
userData: userData,
keyPair: keyPair,
});
// Outputs
new cdk.CfnOutput(this, "GrafanaInstanceId", {
value: grafanaInstance.instanceId,
description: "EC2 Instance ID for Grafana",
});
new cdk.CfnOutput(this, "DefaultCredentials", {
value: "Username: admin, Password: GrafanaAdmin2025!",
description: "Default Grafana login credentials",
});
}
}
セットアップスクリプトの実装
EC2インスタンス起動時に自動実行されるスクリプトです。GrafanaのインストールおよびDuckDBのプラグインmotherduck-duckdb-datasourceのセットアップも行います。
/var/log/grafana-setup.logにログを出力するようにしているので、セットアップがうまくいっていない場合はログを確認してみましょう。
#!/bin/bash
set -e # エラー時に停止
echo "=== Grafana OSS + DuckDB セットアップ開始 ==="
# ログファイルの設定
LOGFILE="/var/log/grafana-setup.log"
exec 1> >(tee -a $LOGFILE)
exec 2>&1
echo "$(date): セットアップ開始"
# ==============================================================================
# 1. システムの更新と基本パッケージのインストール
# ==============================================================================
echo "=== システム更新とパッケージインストール ==="
# システム更新
dnf update -y --skip-broken
# curl-minimalが既にインストールされている場合の競合を解決
dnf install -y wget unzip jq net-tools --skip-broken
# ==============================================================================
# 2. Grafanaリポジトリの追加とインストール
# ==============================================================================
echo "=== Grafana OSS インストール ==="
# GPGキーのインポート
wget -q -O gpg.key https://rpm.grafana.com/gpg.key
rpm --import gpg.key
# Grafanaリポジトリの追加
cat > /etc/yum.repos.d/grafana.repo << 'EOF'
[grafana]
name=grafana
baseurl=https://rpm.grafana.com
repo_gpgcheck=1
enabled=1
gpgcheck=1
gpgkey=https://rpm.grafana.com/gpg.key
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
EOF
# Grafanaのインストール
dnf install -y grafana
echo "Grafana インストール完了"
# ==============================================================================
# 3. プラグインディレクトリの作成
# ==============================================================================
echo "=== プラグインディレクトリ作成 ==="
# プラグインディレクトリを事前に作成
mkdir -p /var/lib/grafana/plugins
chown -R grafana:grafana /var/lib/grafana
chmod -R 755 /var/lib/grafana
# ==============================================================================
# 4. DuckDBプラグインのダウンロードとインストール
# ==============================================================================
echo "=== DuckDB プラグイン インストール ==="
# プラグインディレクトリへ移動
cd /var/lib/grafana/plugins
# DuckDBプラグインのダウンロード
PLUGIN_VERSION="v0.2.0"
PLUGIN_URL="https://github.com/motherduckdb/grafana-duckdb-datasource/releases/download/${PLUGIN_VERSION}/motherduck-duckdb-datasource-0.2.0.zip"
echo "プラグインダウンロード: $PLUGIN_URL"
wget -O duckdb-plugin.zip "$PLUGIN_URL"
# プラグインの展開
unzip duckdb-plugin.zip
rm duckdb-plugin.zip
# DuckDB用の作業ディレクトリを作成
echo "=== DuckDB 作業ディレクトリ作成 ==="
mkdir -p /var/lib/grafana/duckdb
# 権限設定
chown -R grafana:grafana /var/lib/grafana/plugins
chown -R grafana:grafana /var/lib/grafana/duckdb
chmod -R 755 /var/lib/grafana/plugins
chmod -R 755 /var/lib/grafana/duckdb
echo "DuckDB プラグイン インストール完了"
# ==============================================================================
# 5. Grafana設定ファイルの作成
# ==============================================================================
echo "=== Grafana 設定ファイル作成 ==="
# 元の設定ファイルをバックアップ
cp /etc/grafana/grafana.ini /etc/grafana/grafana.ini.backup
# 新しい設定ファイルを作成
cat > /etc/grafana/grafana.ini << 'EOF'
##################### Grafana Configuration #####################
[DEFAULT]
instance_name = grafana-duckdb
#################################### Server ##############################
[server]
# HTTP Serverの設定
http_addr = 0.0.0.0
http_port = 3000
domain = localhost
root_url = http://localhost:3000/
# セキュリティ設定
enforce_domain = false
cookie_secure = false
cookie_samesite = lax
#################################### Security ##############################
[security]
# 管理者設定
admin_user = admin
admin_password = GrafanaAdmin2025!
# セキュリティ設定
allow_embedding = false
cookie_secure = false
strict_transport_security = false
# セッション設定
login_remember_days = 7
disable_gravatar = false
#################################### Plugins ##############################
[plugins]
# プラグイン設定
enable_alpha = false
allow_loading_unsigned_plugins = motherduck-duckdb-datasource
#################################### Logging ##############################
[log]
# ログ設定
mode = console file
level = info
filters = rendering:debug
[log.console]
level = info
format = console
[log.file]
level = info
format = text
log_rotate = true
max_lines = 1000000
max_size_shift = 28
daily_rotate = true
max_days = 7
#################################### Analytics ##############################
[analytics]
# 使用統計の無効化
reporting_enabled = false
check_for_updates = false
#################################### Users ##############################
[users]
# ユーザー管理
allow_sign_up = false
allow_org_create = false
auto_assign_org = true
auto_assign_org_role = Viewer
#################################### Auth ##############################
[auth]
# 認証設定
disable_login_form = false
disable_signout_menu = false
EOF
echo "Grafana 設定ファイル作成完了"
# ==============================================================================
# 6. Grafanaサービスの設定と開始
# ==============================================================================
echo "=== Grafana サービス設定 ==="
# systemdサービスファイルのカスタマイズ
echo "=== systemd サービスファイル設定 ==="
mkdir -p /etc/systemd/system/grafana-server.service.d
# DuckDB用の環境変数を設定するdropinファイルを作成
cat > /etc/systemd/system/grafana-server.service.d/duckdb.conf << 'EOF'
[Service]
Environment="HOME=/var/lib/grafana/duckdb"
EOF
# systemdデーモンの再読み込み
systemctl daemon-reload
# Grafanaサービスの有効化(起動時に自動開始)
systemctl enable grafana-server
# Grafanaサービスの開始
systemctl start grafana-server
# サービス状態の確認
sleep 5
if systemctl is-active --quiet grafana-server; then
echo "✅ Grafana サービス正常起動"
else
echo "❌ Grafana サービス起動失敗"
systemctl status grafana-server --no-pager
fi
デプロイの実行
# CDKスタックをデプロイ
cdk deploy
# デプロイ完了後の出力例
✅ GrafanaDuckdbStack
Outputs:
GrafanaDuckdbStack.DefaultCredentials = Username: admin, Password: GrafanaAdmin2025!
GrafanaDuckdbStack.GrafanaInstanceId = i-xxx
デプロイが完了すると、EC2インスタンスが起動し、UserDataスクリプトが自動実行されてGrafanaとDuckDBプラグインがセットアップされます。
接続に必要なインスタンスIDや、Grafanaの認証情報も固定で出力されるのでメモしておきましょう!
セキュアなアクセス方法
SSM Session Managerによるポートフォワーディング
今回の構成では、インバウンドポートは開放していません。代わりに、SSMを使用してアクセスします。
ポートフォワード接続
デプロイ時に出力されたインスタンスIDを使用してポートフォワードを開始します。
CDK実行時に出力されたインスタンスIDをtarget引数で指定します。
aws ssm start-session \
--target i-xxx \
--document-name AWS-StartPortForwardingSession \
--parameters '{"portNumber":["3000"],"localPortNumber":["3000"]}'
実行すると下記のようにWaiting for connections...と出力されていればOKです!
Starting session with SessionId: botocore-session-xxx-xxx
Port 3000 opened for sessionId botocore-session-xxx-xxx
Waiting for connections...
これでlocalhost:3000で接続できるようになったので、接続してみます!
接続確認
ポートフォワーディングが開始されたら、ブラウザで以下にアクセスします。
http://localhost:3000
接続できました!!簡単にアクセスできて嬉しいですね!
ログインする際はCDKで出力された情報を使ってログイン可能なので、ログインしておきましょう。
補足: シェルアクセス
必要に応じて、SSH接続のようにシェルアクセスも可能です。もしセットアップがうまくいかない場合はこちらで接続して調査も可能です。
aws ssm start-session --target i-xxx
S3データの準備
サンプルIoTデータの作成とアップロード
前回と同様のデータを作成し、今度はS3バケットにアップロードします。
データのイメージは下記です。
timestamp,sensor_id,temperature,humidity,location
2024-01-01 00:00:00,SENSOR_001,18.45,75.23,Office_Room_A
2024-01-01 00:10:00,SENSOR_001,17.89,77.84,Office_Room_A
2024-01-01 00:20:00,SENSOR_001,16.23,81.45,Office_Room_A
2024-01-01 00:30:00,SENSOR_001,15.67,83.12,Office_Room_A
2024-01-01 00:40:00,SENSOR_001,14.98,85.78,Office_Room_A
2024-01-01 00:50:00,SENSOR_001,14.23,88.34,Office_Room_A
2024-01-01 01:00:00,SENSOR_001,13.89,89.67,Office_Room_A
2024-01-01 01:10:00,SENSOR_001,13.45,91.23,Office_Room_A
...
2024-01-01 12:00:00,SENSOR_001,28.45,52.34,Office_Room_A
2024-01-01 12:10:00,SENSOR_001,29.12,49.78,Office_Room_A
2024-01-01 12:20:00,SENSOR_001,30.23,46.89,Office_Room_A
...
2024-01-30 23:40:00,SENSOR_001,19.67,73.45,Office_Room_A
2024-01-30 23:50:00,SENSOR_001,18.89,75.12,Office_Room_A
データの特徴
- 期間: 2024年1月1日 00:00:00 ~ 2024年1月30日 23:50:00
- 頻度: 10分間隔でデータ取得(1日あたり144レコード)
- 総レコード数: 4,320件(30日分)
- 形式: Parquet形式
作成したデータをCDKで作成したS3(grafana-duckdb-data-{アカウントID}-{リージョン名})にアップロードしておきます!
下記のように保存されていればOKです。
DuckDBデータソースの設定
Grafanaへのアクセスと初期設定
ポートフォワーディング接続後、Grafanaの初期設定を行います。
初回ログイン
- ユーザー名:
admin - パスワード:
GrafanaAdmin2025!
パスワードは変更したい場合は変更しておきましょう。
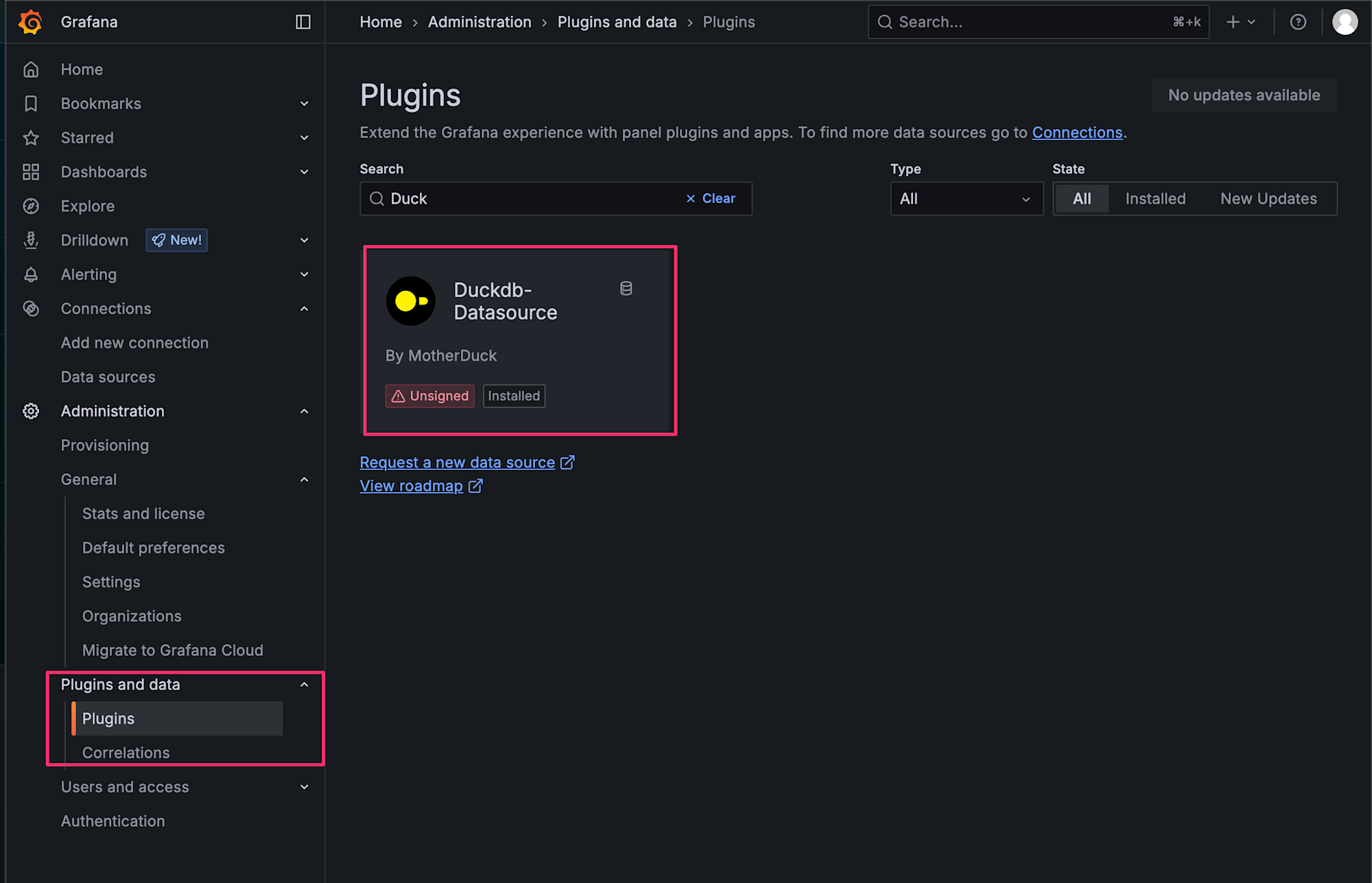
DuckDBプラグインの確認
左側メニューからAdministration > Pluginsを選択し、Duckで検索してプラグインが正常にインストールされていることを確認します。
データソース追加と設定
データソース追加手順
- 左側メニューから
Connections>Add new connectionを選択 - Searchバーで
Duckと検索し、Duckdb-Datasourceを選択 Add new data sourceを選択
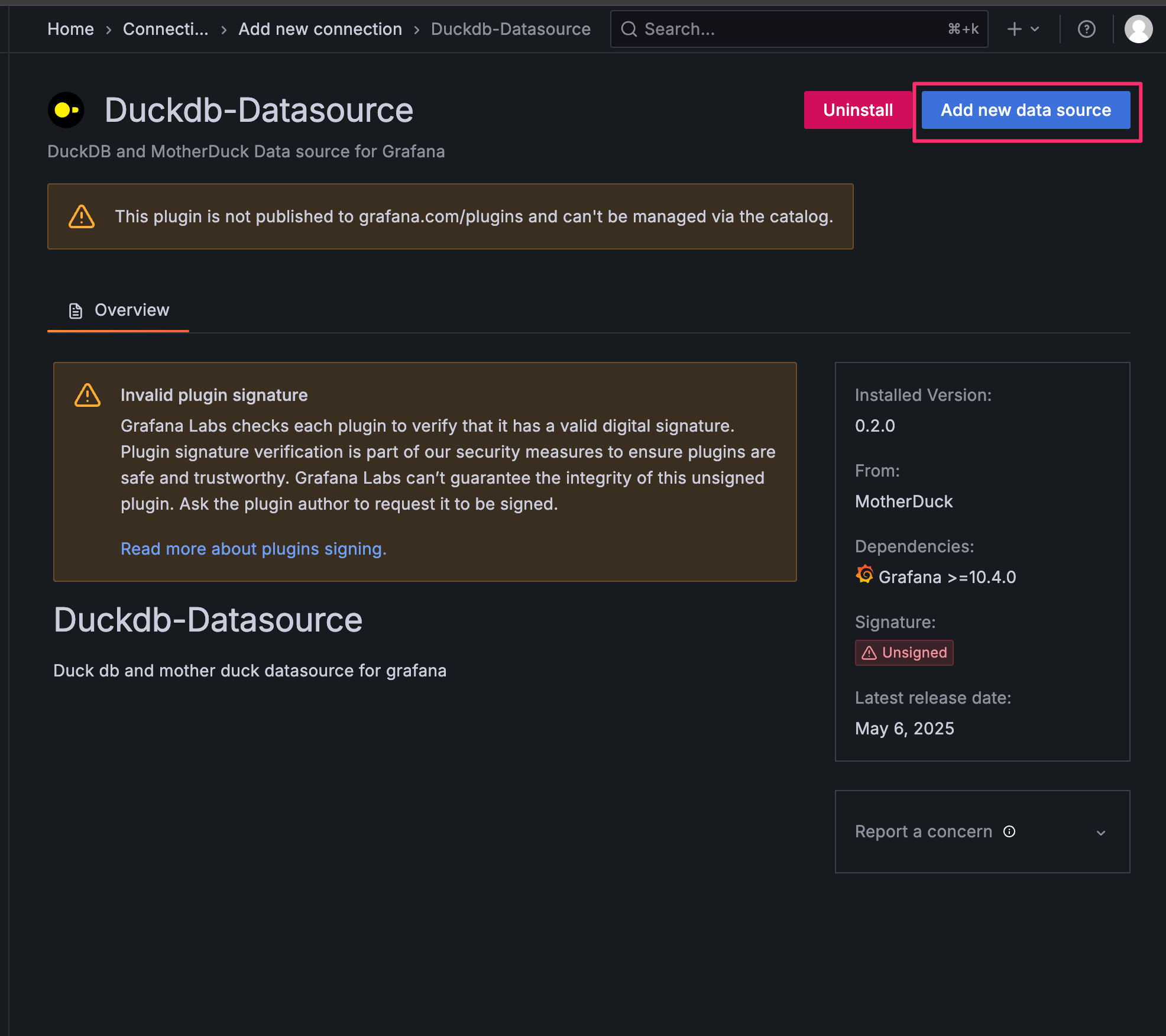
データソース設定項目
以下の設定を入力します。
- Name:
AWS S3 IoT Data - Path: 空白(インメモリモードで使用)
- Init SQL: S3接続のための初期設定
INSTALL httpfs;
LOAD httpfs;
CREATE OR REPLACE secret (
TYPE s3,
PROVIDER credential_chain
);
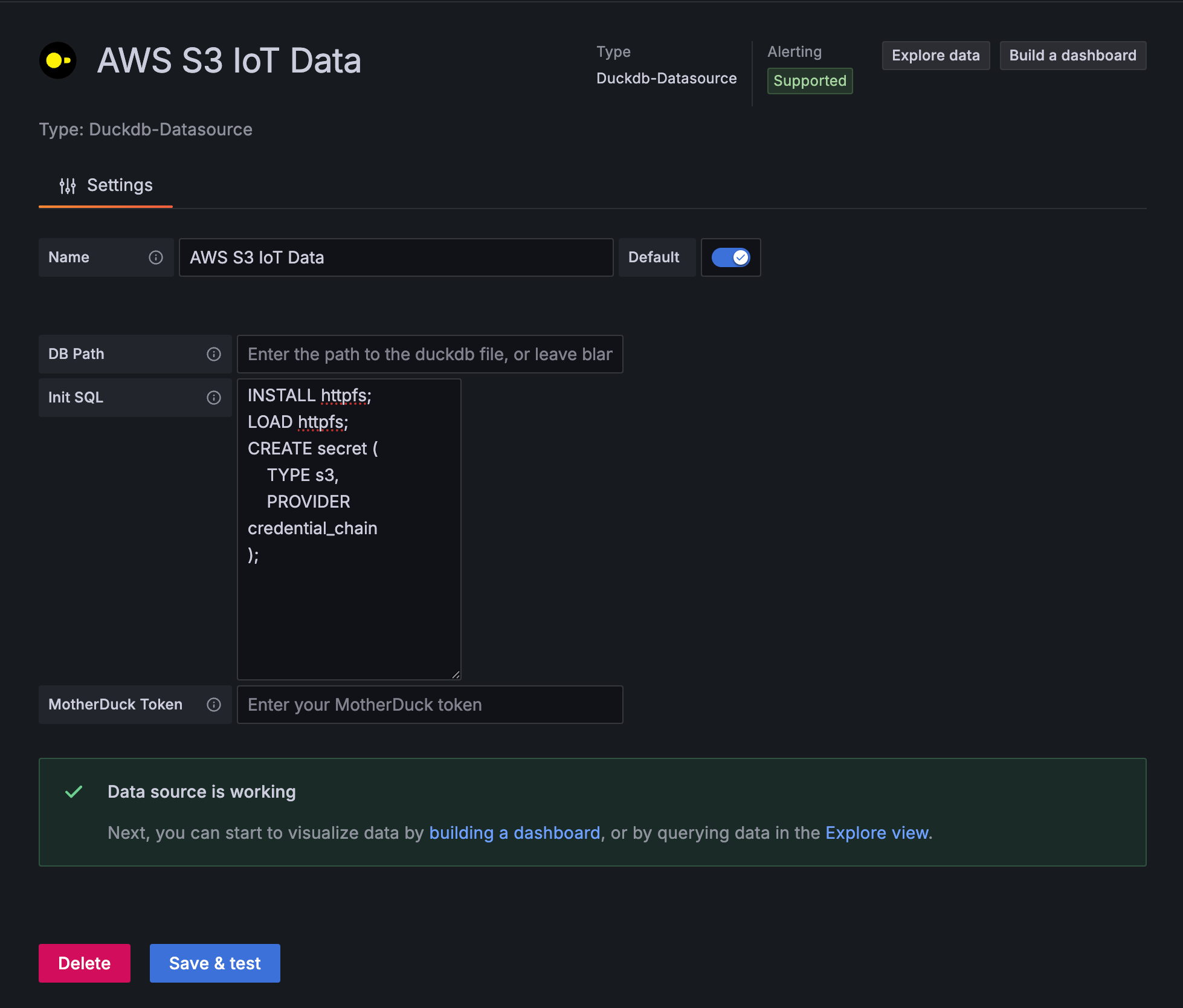
credential_chainは、AWS SDKの標準的な認証情報チェーンを利用します。この方法では認証情報を自動的に探索するので、EC2インスタンスプロファイルの認証を使用します。
Save & Testを選択して、問題なければExplore dataを選択します。
データ確認クエリ
まずはExploreでS3上のデータが正常に読み取れるか確認しましょう。
基本的なデータ確認
バケット名は自身のバケット名を指定します。
SELECT * FROM 's3://grafana-duckdb-data-123456789012-ap-northeast-1/iot-data/sensor_data_2024_01.parquet';
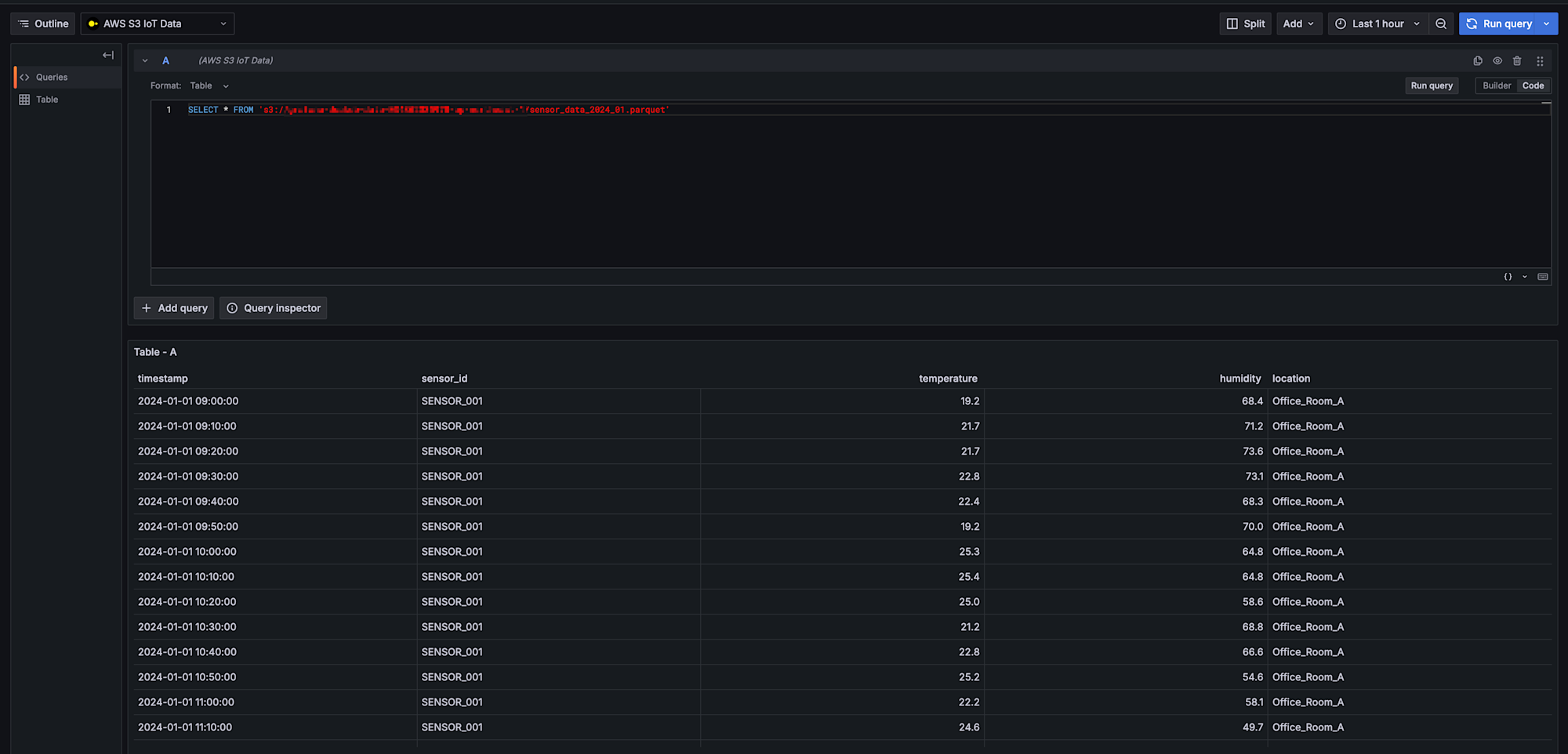
無事データを取得できましたね!
データが正常に取得できることを確認できたら、次はダッシュボードを作成していきます。
ダッシュボードの作成
時系列可視化の設定
左側メニューからDashboards > Create dashboardを選択し、Add Visualizationを選択します。
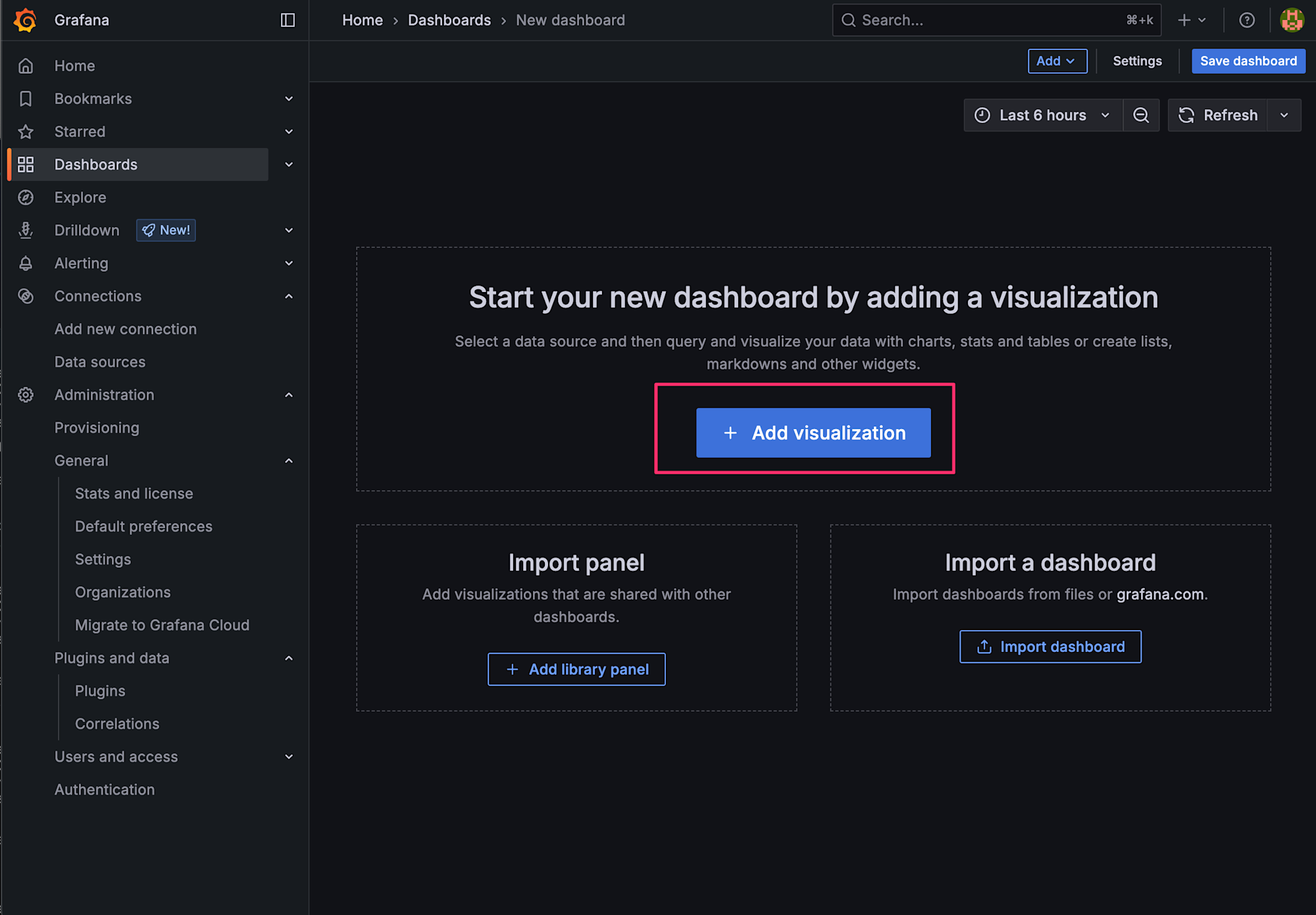
温度データの可視化パネル
Codeを選択して、以下のSQLを入力します。
SELECT
timestamp as time,
temperature as value,
'temperature' as metric
FROM 's3://grafana-duckdb-data-123456789012-ap-northeast-1/iot-data/sensor_data_2024_01.parquet'
WHERE $__timeFilter(timestamp)
ORDER BY timestamp
タイムレンジの設定
ダミーデータは2024年1月のデータなので、タイムレンジを適切に設定します。
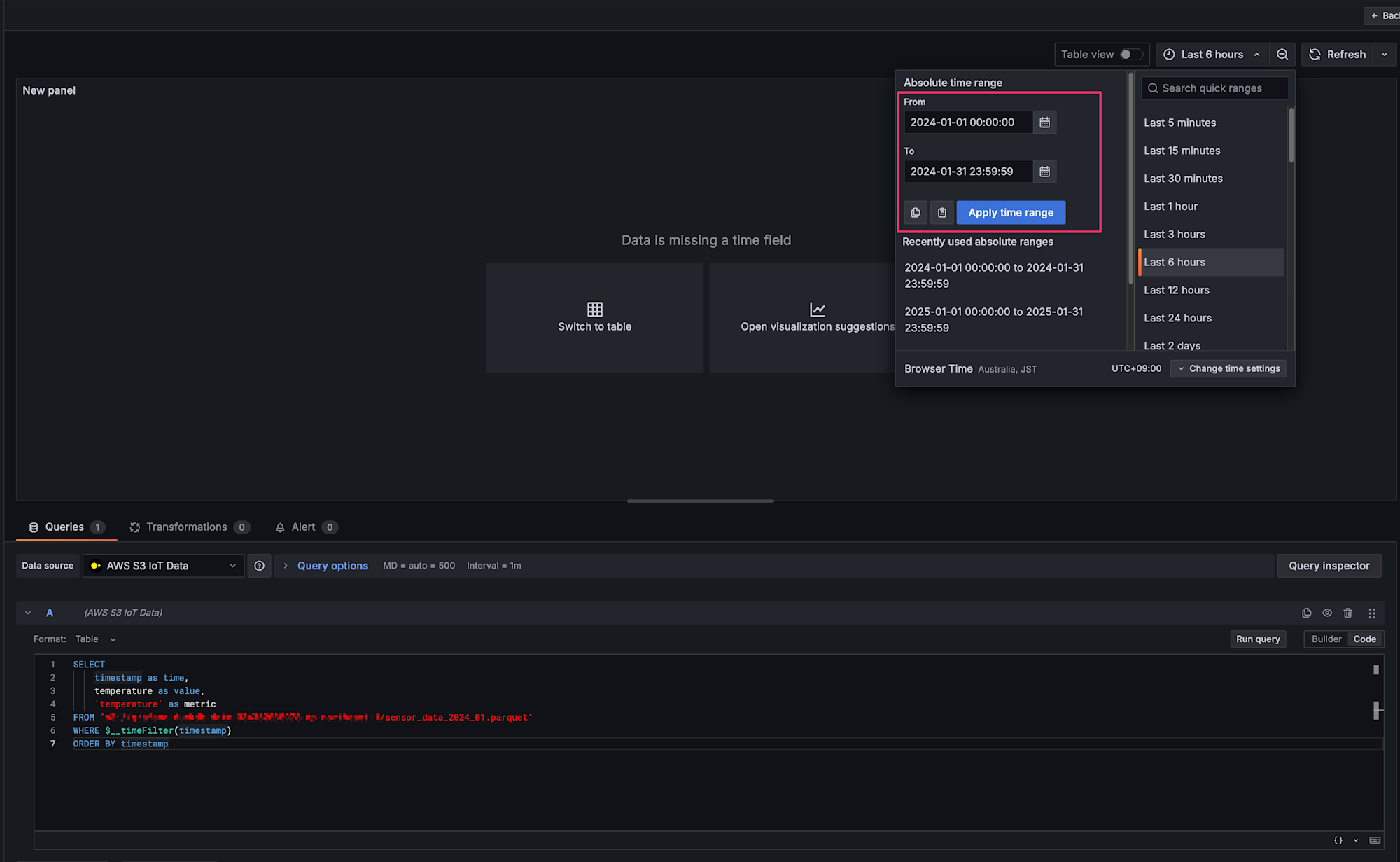
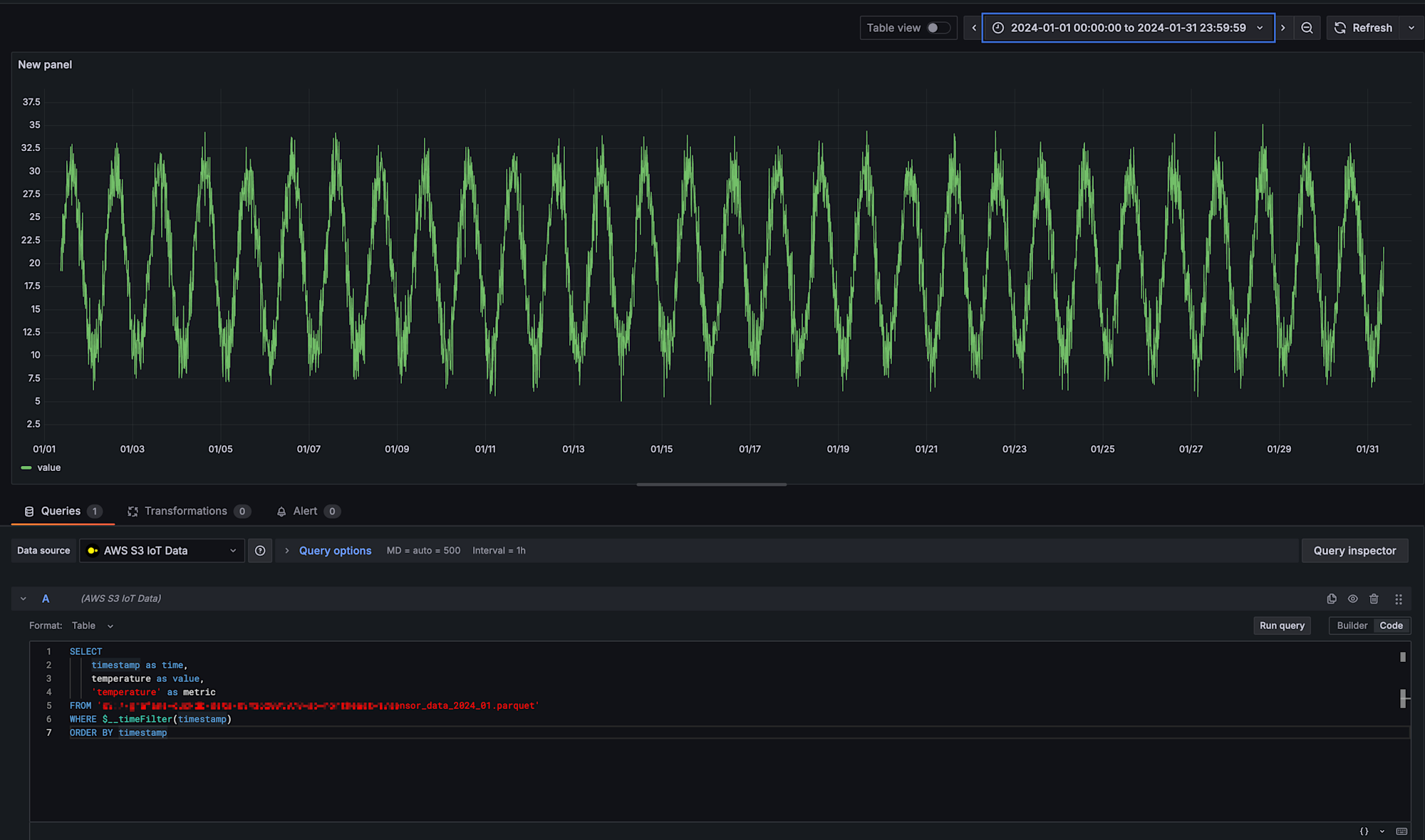
クエリを入力して、Apply time range を押下すると無事可視化されます!
おわりに
今回、CDKでサクッとEC2上にGrafanaとDuckDBを構築し、IAMロール認証でS3データを可視化する仕組みを試してみました。
個人的な検証などで可視化する環境を作るにはサクッとできるし、DuckDBと連携してS3の各種データに対してクエリおよび可視化できるので良きだなと感じました!
本記事が少しでも参考になりましたら幸いです!最後までご覧いただきありがとうございました!










