
AWS DevOps Agent(Preview)のPrevention(予防)機能を使ってみた #AWSreInvent
こんにちは。大阪オフィスの林です。
はじめに
re:Invent 2025のキーノートで AWS DevOps Agent のプレビューが発表されました
弊社ブログでも AWS DevOps Agent に関連する記事がいくつか投稿されています
今回は AWS DevOps Agent で用意されている『 Prevention 』という機能にフォーカスを当てて検証してみたいと思います
Prevention(予防)機能 とは?
『 Prevention 』をひと言でいうと 過去のインシデント調査を分析して、将来のインシデントを防ぐための改善策を提案する機能 といったところでしょうか
① インシデント発生 → ② Investigation で調査 → ③ Prevention が複数の調査結果を分析 → ④ 推奨事項を生成 といったような流れで活用する機能です
Prevention での分析は毎週自動的に実行されるのに加えて、任意のタイミングで手動で分析を実行することも可能です
予防のカテゴリ
Prevention では下記のような改善のカテゴリが用意されています
運用上の改善が最も必要な領域を把握できるので、対応の優先順位付けにも活用できます
| カテゴリ | 内容 |
|---|---|
| 可観測性 | 監視・アラート・ログの強化でシステムの可視性を向上し、問題を迅速かつ正確に検出 |
| コードの最適化 | アプリケーションコードの品質・パフォーマンス・エラー処理・回復力の向上 |
| インフラストラクチャ | リソース最適化・自動スケーリング・容量調整・アーキテクチャの回復力向上 |
| ガバナンス | デプロイパイプラインのテスト・検証プロセス・運用管理の強化 |
Prevention を使うメリット
ここまでで何となく Prevention の有用性が把握できたと思います
改めて Prevention を使うメリットをまとめておきましょう
| 利点 | 内容 |
|---|---|
| 再発するインシデントを防ぐ | 根本原因を体系的に解決し、同じ問題の繰り返しを排除 |
| 運用上の負担を軽減 | 反復的な問題解決から解放され、イノベーションと戦略的改善に集中 |
| システムの回復力の向上 | 実際のインシデントデータに基づいてインフラ・可観測性・デプロイプロセスを強化 |
| 過去のパターンから学ぶ | 過去のインシデントの洞察を活用し、最も効果の高い改善に集中 |
やってみた
今回は簡単に Prevention の機能を使っていきましょう
今回は下記の順序で検証してみたいと思います
- 検証環境のデプロイ
- 疑似インシデント発生
- Investigation の実行
- Prevention で評価
- 検証環境の削除
1. 検証環境のデプロイ
今回の検証で作る環境はこんな感じのライトなものです
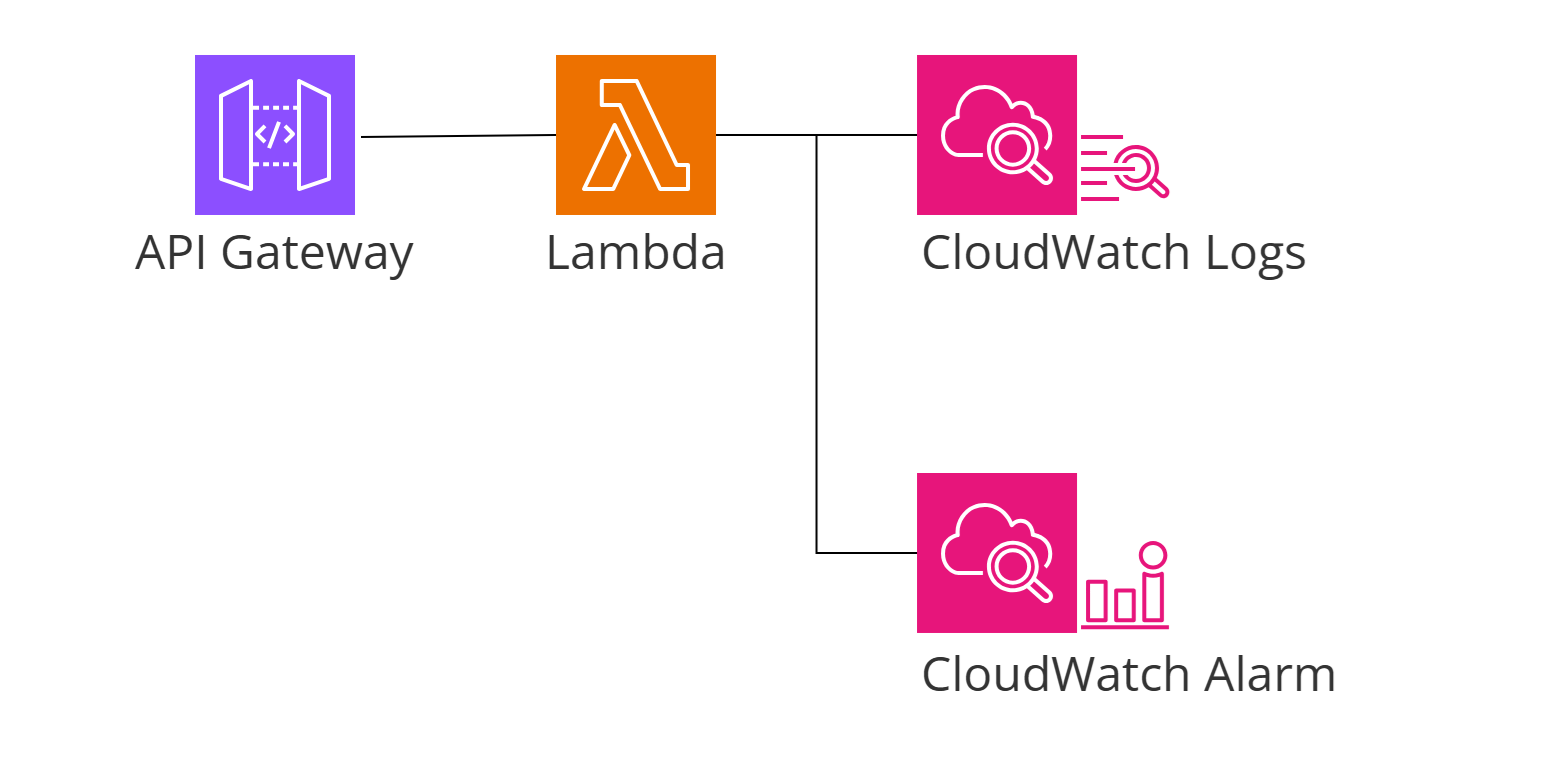
SAM を使ってテスト用の環境をデプロイします
使ったシェルスクリプトはこちらに貼っておきます
デプロイ用シェルスクリプト
#!/bin/bash
# DevOps Agent Prevention Test - Deployment Script (SAM)
set -e
# Configuration
STACK_NAME="${STACK_NAME:-devops-agent-prevention-test}"
REGION="${AWS_REGION:-us-east-1}"
ENVIRONMENT="${ENVIRONMENT:-dev}"
# Colors
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
NC='\033[0m'
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
PROJECT_DIR="$(dirname "$SCRIPT_DIR")"
echo -e "${GREEN}=== DevOps Agent Prevention Test - Deployment (SAM) ===${NC}"
echo "Stack Name: ${STACK_NAME}"
echo "Region: ${REGION}"
echo "Environment: ${ENVIRONMENT}"
echo ""
# Check prerequisites
check_prerequisites() {
echo -e "${YELLOW}Checking prerequisites...${NC}"
if ! command -v aws &> /dev/null; then
echo -e "${RED}Error: AWS CLI is not installed${NC}"
exit 1
fi
if ! command -v sam &> /dev/null; then
echo -e "${RED}Error: AWS SAM CLI is not installed${NC}"
echo "Install: pip install aws-sam-cli"
exit 1
fi
if ! aws sts get-caller-identity &> /dev/null; then
echo -e "${RED}Error: AWS credentials not configured${NC}"
exit 1
fi
echo -e "${GREEN}Prerequisites OK${NC}"
echo ""
}
# Build
build() {
echo -e "${YELLOW}Building...${NC}"
cd "$PROJECT_DIR/cloudformation"
sam build
echo -e "${GREEN}Build completed${NC}"
echo ""
}
# Deploy
deploy() {
echo -e "${YELLOW}Deploying...${NC}"
cd "$PROJECT_DIR/cloudformation"
sam deploy \
--stack-name "$STACK_NAME" \
--region "$REGION" \
--capabilities CAPABILITY_IAM CAPABILITY_AUTO_EXPAND \
--parameter-overrides Environment="$ENVIRONMENT" ProjectName="$STACK_NAME" \
--resolve-s3 \
--no-fail-on-empty-changeset
echo -e "${GREEN}Deployment completed${NC}"
echo ""
}
# Get outputs
get_outputs() {
echo -e "${YELLOW}Stack Outputs:${NC}"
aws cloudformation describe-stacks \
--stack-name "$STACK_NAME" \
--region "$REGION" \
--query 'Stacks[0].Outputs[*].[OutputKey, OutputValue]' \
--output table
echo ""
}
# Delete
delete() {
echo -e "${RED}Deleting stack: ${STACK_NAME}${NC}"
read -p "Are you sure? (y/N) " -n 1 -r
echo
if [[ $REPLY =~ ^[Yy]$ ]]; then
sam delete --stack-name "$STACK_NAME" --region "$REGION" --no-prompts
echo -e "${GREEN}Stack deleted${NC}"
else
echo "Cancelled"
fi
}
# Usage
usage() {
echo "Usage: $0 [command]"
echo ""
echo "Commands:"
echo " deploy - Build and deploy (default)"
echo " build - Build only"
echo " outputs - Show stack outputs"
echo " delete - Delete stack"
echo ""
echo "Environment variables:"
echo " STACK_NAME - Stack name (default: devops-agent-prevention-test)"
echo " AWS_REGION - Region (default: us-east-1)"
echo " ENVIRONMENT - Environment (default: dev)"
}
# Main
case "${1:-deploy}" in
deploy)
check_prerequisites
build
deploy
get_outputs
;;
build)
check_prerequisites
build
;;
outputs)
get_outputs
;;
delete)
delete
;;
help|--help|-h)
usage
;;
*)
echo -e "${RED}Unknown command: $1${NC}"
usage
exit 1
;;
esac
このシェルスクリプトで作成されるリソースは以下の通りです
| サービス | リソース名 | 説明 |
|---|---|---|
| Lambda | devops-agent-prevention-test-api | インシデント発生用の関数 |
| API Gateway | devops-agent-prevention-test-api | REST API エンドポイント |
| CloudWatch Logs | /aws/lambda/devops-agent-prevention-test-api | Lambda のログ |
| CloudWatch Alarm | devops-agent-prevention-test-lambda-errors | Lambda エラー検知 |
| CloudWatch Alarm | devops-agent-prevention-test-lambda-throttles | Lambda スロットリング検知 |
| CloudWatch Alarm | devops-agent-prevention-test-lambda-duration | Lambda 実行時間超過検知 |
| CloudWatch Alarm | devops-agent-prevention-test-api-5xx-errors | API 5xx エラー検知 |
| CloudWatch Alarm | devops-agent-prevention-test-api-4xx-errors | API 4xx エラー検知 |
| CloudWatch Alarm | devops-agent-prevention-test-api-latency | API レイテンシー検知 |
| S3 | SAM 管理バケット | Lambda コードの保存(自動作成) |
| IAM Role | Lambda 実行ロール | Lambda の実行権限 |
2. 疑似インシデント発生
API に HTTP リクエストを送って、意図的に下記のエラーを発生させるスクリプトで疑似的なインシデントを発生させます
| エンドポイント | 発生するインシデント |
|---|---|
| /error | Lambda で例外発生 → 500 エラー |
| /timeout | Lambda が 30 秒超過 → タイムアウト |
| /memory-issue | Lambda が 128MB 超過 → メモリ不足 |
| /process | ランダムに処理失敗 / 遅延 |
インシデント発生に使ったスクリプトはこちらに貼っておきます
インシデント発生用シェルスクリプト
#!/bin/bash
# DevOps Agent Prevention Test - Incident Generator Script
# This script generates various types of incidents for testing Prevention recommendations
set -e
# Configuration
STACK_NAME="${STACK_NAME:-devops-agent-prevention-test}"
REGION="${AWS_REGION:-ap-northeast-1}"
# Colors for output
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
NC='\033[0m' # No Color
echo -e "${GREEN}=== DevOps Agent Prevention Test - Incident Generator ===${NC}"
# Get API endpoint from CloudFormation outputs
get_api_endpoint() {
aws cloudformation describe-stacks \
--stack-name "$STACK_NAME" \
--region "$REGION" \
--query 'Stacks[0].Outputs[?OutputKey==`ApiEndpoint`].OutputValue' \
--output text
}
API_ENDPOINT=$(get_api_endpoint)
if [ -z "$API_ENDPOINT" ]; then
echo -e "${RED}Error: Could not get API endpoint. Is the stack deployed?${NC}"
exit 1
fi
echo -e "${GREEN}API Endpoint: ${API_ENDPOINT}${NC}"
echo ""
# Function to make requests and show results
make_request() {
local method=$1
local path=$2
local data=$3
local description=$4
echo -e "${YELLOW}>>> ${description}${NC}"
echo "Request: ${method} ${API_ENDPOINT}${path}"
if [ "$method" == "GET" ]; then
response=$(curl -s -w "\n%{http_code}" "${API_ENDPOINT}${path}" 2>/dev/null || echo "error")
else
response=$(curl -s -w "\n%{http_code}" -X "${method}" \
-H "Content-Type: application/json" \
-d "${data}" \
"${API_ENDPOINT}${path}" 2>/dev/null || echo "error")
fi
body=$(echo "$response" | head -n -1)
status=$(echo "$response" | tail -n 1)
if [ "$status" -ge 200 ] && [ "$status" -lt 300 ]; then
echo -e "${GREEN}Status: ${status}${NC}"
else
echo -e "${RED}Status: ${status}${NC}"
fi
echo "Response: ${body}"
echo ""
}
# Generate incidents based on type
generate_errors() {
echo -e "${RED}=== Generating Error Incidents ===${NC}"
# Runtime errors
for i in {1..5}; do
make_request "GET" "/error?type=runtime" "" "Generating runtime error ($i/5)"
sleep 1
done
# Value errors
for i in {1..3}; do
make_request "GET" "/error?type=value" "" "Generating value error ($i/3)"
sleep 1
done
# Key errors
for i in {1..3}; do
make_request "GET" "/error?type=key" "" "Generating key error ($i/3)"
sleep 1
done
}
generate_timeouts() {
echo -e "${RED}=== Generating Timeout Incidents ===${NC}"
# These will cause Lambda timeouts (30s timeout configured)
for i in {1..3}; do
echo -e "${YELLOW}>>> Generating timeout incident ($i/3)${NC}"
echo "Request: GET ${API_ENDPOINT}/timeout?duration=35"
# Use timeout to avoid waiting too long
timeout 40 curl -s "${API_ENDPOINT}/timeout?duration=35" 2>/dev/null || echo -e "${RED}Timeout occurred (expected)${NC}"
echo ""
sleep 2
done
}
generate_processing_failures() {
echo -e "${RED}=== Generating Processing Failures ===${NC}"
# Processing with high failure rate
for i in {1..10}; do
make_request "POST" "/process" '{"data": "test data for processing", "fail_rate": 0.7}' "Processing with 70% failure rate ($i/10)"
sleep 1
done
}
generate_slow_responses() {
echo -e "${YELLOW}=== Generating Slow Response Incidents ===${NC}"
# Slow processing requests
for i in {1..5}; do
make_request "POST" "/process" '{"data": "test data", "slow_rate": 1.0}' "Generating slow response ($i/5)"
done
}
generate_memory_issues() {
echo -e "${RED}=== Generating Memory Issues ===${NC}"
# Memory allocation beyond limit (128MB)
for i in {1..3}; do
make_request "GET" "/memory-issue?size_mb=200" "" "Generating memory issue ($i/3)"
sleep 2
done
}
# Health check
health_check() {
echo -e "${GREEN}=== Health Check ===${NC}"
make_request "GET" "/health" "" "Checking API health"
}
# Show usage
usage() {
echo "Usage: $0 [command]"
echo ""
echo "Commands:"
echo " all - Generate all types of incidents"
echo " errors - Generate error incidents (500 errors)"
echo " timeouts - Generate timeout incidents"
echo " failures - Generate processing failures"
echo " slow - Generate slow response incidents"
echo " memory - Generate memory issues"
echo " health - Check API health"
echo ""
echo "Environment variables:"
echo " STACK_NAME - CloudFormation stack name (default: devops-agent-prevention-test)"
echo " AWS_REGION - AWS region (default: ap-northeast-1)"
}
# Main
case "${1:-all}" in
all)
health_check
generate_errors
generate_processing_failures
generate_slow_responses
generate_timeouts
generate_memory_issues
echo -e "${GREEN}=== All incidents generated ===${NC}"
;;
errors)
generate_errors
;;
timeouts)
generate_timeouts
;;
failures)
generate_processing_failures
;;
slow)
generate_slow_responses
;;
memory)
generate_memory_issues
;;
health)
health_check
;;
help|--help|-h)
usage
;;
*)
echo -e "${RED}Unknown command: $1${NC}"
usage
exit 1
;;
esac
インシデント発生用シェルスクリプトに all の引数を付けることで上記のインシデントを全て発生させることができます
generate-incidents.sh all
3. Investigation の実行
下記のプロンプトで調査を依頼してみます
「devops-agent-prevention-test」アプリケーションで繰り返し発生する問題を調査してください。
システムでは、Lambdaエラー、タイムアウト、メモリの問題、API Gateway 5xxエラーなど、複数の種類の障害が発生しています。
パターンを分析し、根本原因を特定してください。
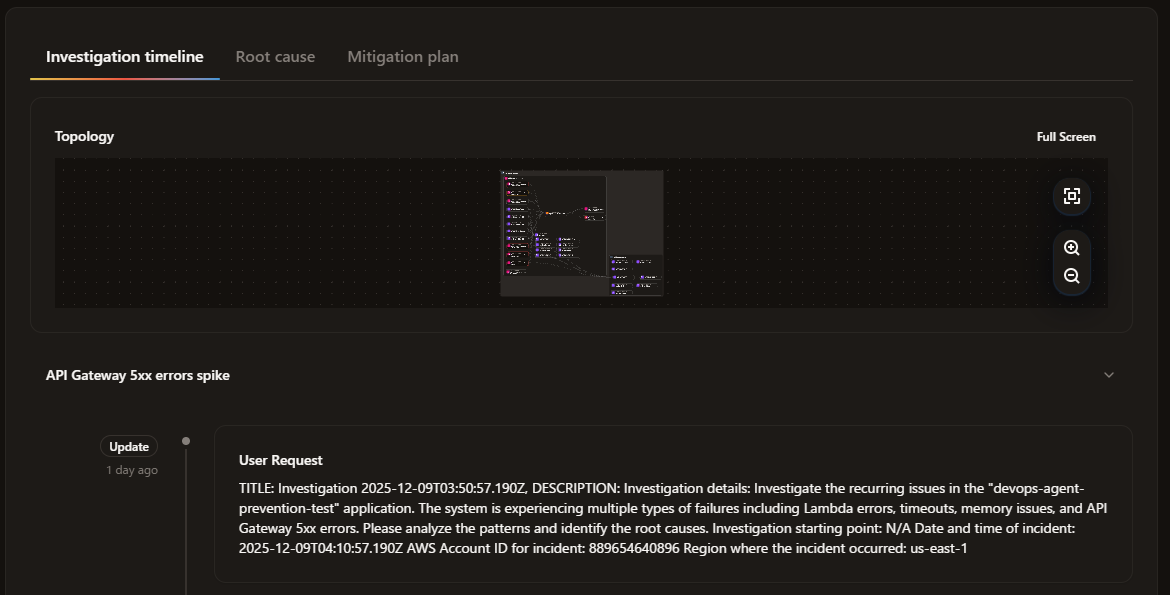
4. Prevention で評価
暫くしてから Prevention を見ていきます
今回は手動で分析を掛けていくので Prevention タブの Run now を実行します

暫く処理が走ったのち、Recommendations に何か出てきました
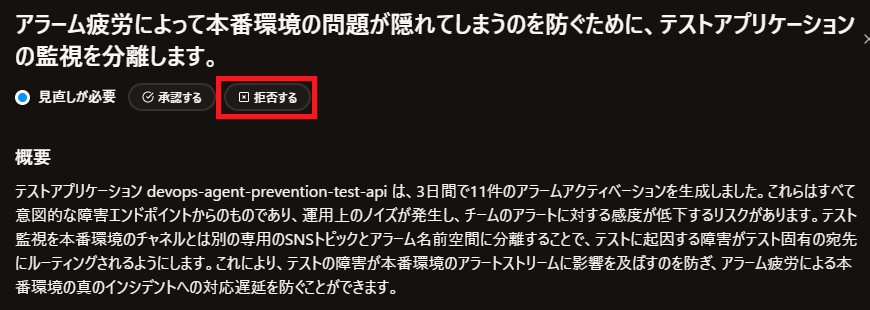
『テストの意図的なエラーが本番アラートに混ざって、本当に重要な障害を見逃すリスクがあるよ!』 と、まさにそれっぽいことを言ってくれています
クリックしてみると詳細が参照できます
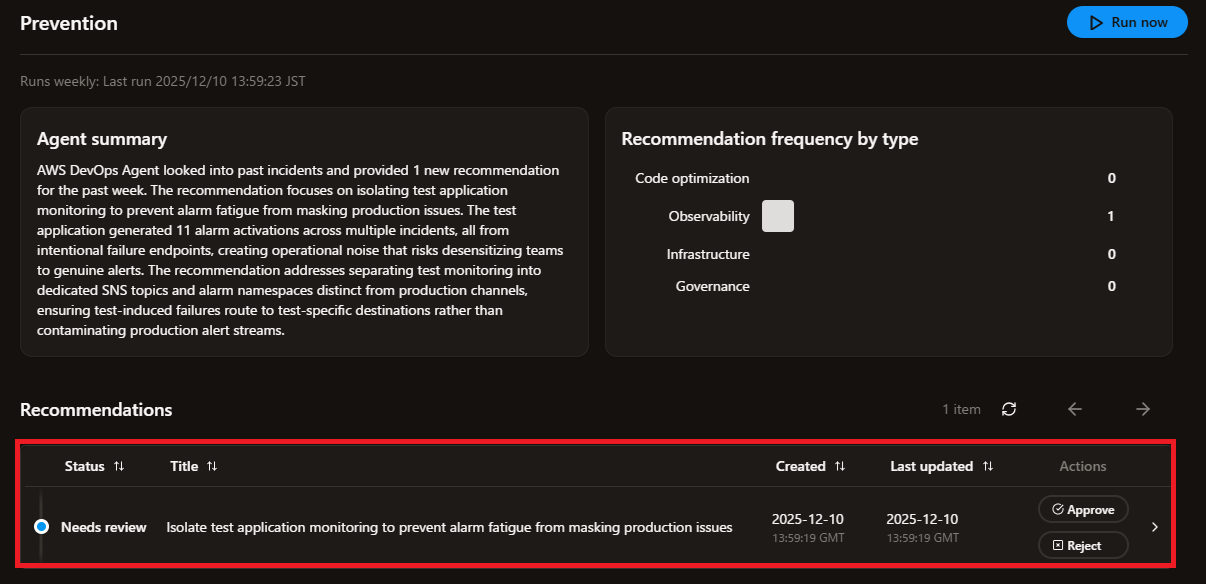
詳細では、根拠となったインシデント / 影響 / 次のステップなどの情報を確認できます

このレコメンデーションには 承認する 拒否する のボタンが用意されており、分析されたレコメンデーションをどう扱うかのフラグを付けることもできます
承認すると推奨事項がテーブルに残り、実装予定の改善内容を追跡でき、拒否する際は理由を記述し、エージェントはこのフィードバックから学習して将来のレコメンデーションを改善します
承認されなかったレコメンデーションは約6週間後に自動削除され、関連する新しいインシデントが発生すると、推奨事項の優先度や内容が更新されるとのことです
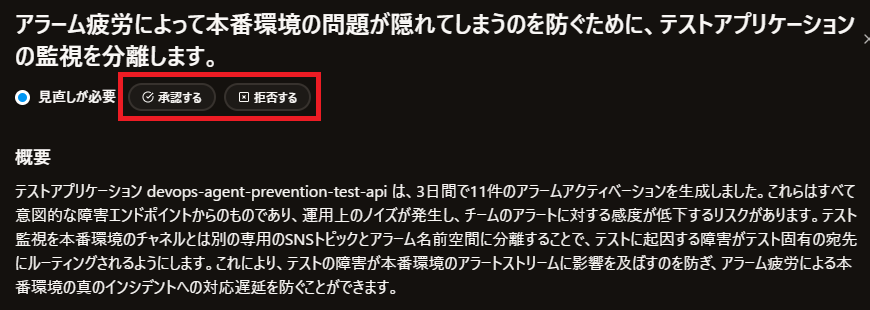
今回はテストなので 拒否する で進めてみましょう
適当な理由を書いて 提出する を選択します
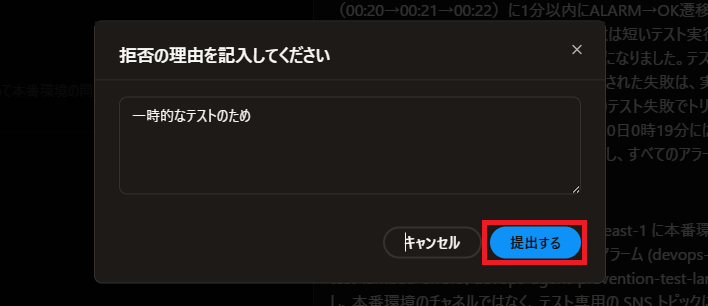
ステータスが Rejected になりました

Undo をクリックするとステータスを戻すこともできます

戻りました

5. 検証環境の削除
デプロイした検証環境は削除しておきましょう
デプロイ用シェルスクリプトに delete の引数を付けることでサクッと環境削除できます
deploy.sh delete
まとめ
Prevention は過去のインシデントパターンからの学習によって、根本的な原因解決を期待できる魅力的な機能であることが分かりました。奥が深そうなのでまだまだ色々と試してみたいものです
以上、大阪オフィスの林がお送りしました










