
【アップデート】信頼できないコードをサンドボックス環境で検証するためのAWS Lambda MicroVMsが利用可能になりました
リテールアプリ共創部@大阪の岩田です。
6/22付でLambdaに何やら面白そうなアップデートがありました。
AIが生成したコードなど、信頼できないコードを実行するための環境としてFirecrackerのMicroVMによって隔離されたサンドボックス環境が利用できるようになったというものです。
FirecrackerのMicroVM自体は従来からLambda実行環境の裏側で利用されていましたが、利用者側ではそれを意識することがありませんでした。詳しくは以下のブログを参照してください。
今回のアップデートによって何が変わるのでしょうか?さっそく内容を確認していきましょう。
アップデートの概要
前述の通りAIが生成したコードなど、開発者が自分自身で書いていないコード = 信頼できないコード を安全に実行するための分離された環境を提供するためのアップデートです。この環境はFirecrackerのMicroVMをベースとした環境になっています。
従来型のVMによる環境分離はどうしてもオーバーヘッドが大きくなりがちです。一方でコンテナ技術のみを利用した環境分離はオーバーヘッドが小さく高速に動作しますが、カーネルを共有するため、コンテナランタイムに脆弱性があった場合に被害が拡大しやすいというトレードオフがあります。AWS Lambdaというサービスが抱えていたこれらのジレンマを解消するために開発されたFirecrackerはハイパーバイザレベルの強力な環境分離を提供しつつも、数100msレベルで仮想マシンを起動できる軽量なVMMです。
昨今のAIの台頭によって、いかに安全なコード実行環境を用意するか?が課題となる中でFirecrackerが再注目されているわけですね。
公式ドキュメントではClaudeのSelf-hosted sandboxesの実行基盤としてLambda MicroVMsを利用するユースケースが紹介されており、GitHubリポジトリでリファレンスアーキテクチャ用のSAMテンプレートも公開されています。
GitHub - aws-samples/sample-lambda-microvm-claude-managed-agents · GitHub
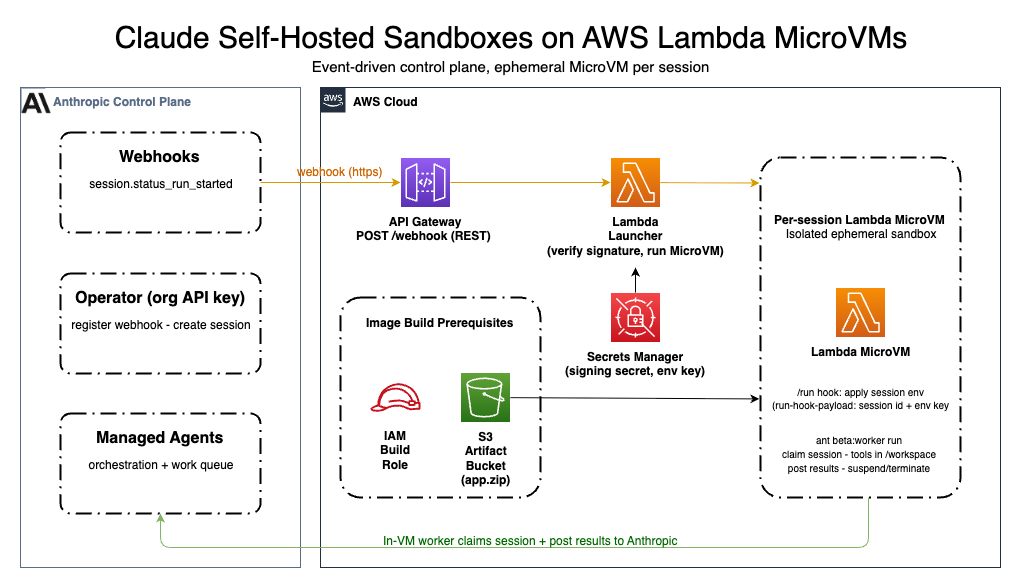
※上記の画像は公式ドキュメントより引用
MicroVMのイメージはDockerfileをもとにビルドされ、Firecrackerのスナップショットとして管理されます。これにより、MicroVMの起動/停止 = スナップショットのresume/suspendとなるため、開発のライフサイクルが高速化されます。
従来のLambda Functionとは何が違うのか
簡単にではありますが、Lambda MicroVMsを触ってみたので、ドキュメントの記載と合わせて従来のLambda Functionとの違いについて私の見解を書きます。
コンセプトの通りですが、Lambda MicroVMsは従来のLambda Functionのような「関数」を実行するための環境ではなく、インタラクティブにアプリケーションコードを実行しながらテストするための環境という位置づけと認識しています。Lambda MicroVMs上で本番環境向けのアプリケーションを稼働させることは想定されておらず、あくまで開発やテストを実行するための環境であり、動作確認がとれたコードは従来通りLambda FunctionやECSタスクとして実行することを想定しているように感じました。
通常のLambda Functionとは異なり、何かしらのイベントをトリガーにしてhandler内のコードを実行したり、リクエスト数に応じてオンデマンドに自動でスケールアウトするといったことはありません。Lambdaというサービスの名前を冠してはいますが、Lambda Functionとは全くの別物と捉えた方が理解しやすいと思います。
他にもLinux Capabilitiesが指定できるという特徴もあり、eBPFプログラムのテスト目的にも利用可能です。
MicroVM上で稼働するアプリケーションへのアクセス
MicroVM上で稼働するアプリケーションはAWSが管理するHTTPSエンドポイントを経由してアクセス可能です。このエンドポイントは一時トークンを用いて認証し、認証されたリクエストをMicroVM上の指定されたポートへトラフィックを転送します。サポートされているプロトコルは以下の通りです。
- HTTP/1.1
- HTTP/2
- WebSockets
- gRPC
- Server-Sent Events (SSE)
一時トークン発行時にはトークンの有効期限、トラフィックの転送を許可するMicroVM上のポート番号が指定可能です。
利用可能なリージョン
本日時点でLambda MicroVMsが利用可能なリージョンは以下の通りです。
- バージニア(us-east-1)
- オハイオ(us-east-2)
- オレゴン(us-west-2)
- アイルランド(eu-west-1)
- 東京(ap-northeast-1)
料金
Lambda MicroVMはコンピューティングリソース、スナップショットのストレージおよび読み書き操作、AWS標準のデータ転送量に対して料金が発生します。東京リージョンの場合は以下の料金体系です。
コンピューティングリソース
| 項目 | 料金 |
|---|---|
| vCPU | 1秒あたり $0.0000322421 |
| メモリ | 1GB・1秒あたり $0.0000042688 |
スナップショット
| 項目 | 料金 |
|---|---|
| Snapshotのストレージ | 1GB ・1ヶ月あたり $0.09600 |
| Snapshotの読み取り | 1GBあたり $0.00185 |
| Snapshotの書き込み | 1GBあたり $0.00466 |
詳細は以下の公式ページを参照してください。
やってみる
それではさっそくやっていきます。以下AWSブログの内容に沿ってMicroVM上でアプリケーションを稼働させ、Postmanからリクエストを発行するまで一連の流れを試してみます。
大まかな流れは以下の通りです。
- ソースコードの準備とS3へのアップロード
- MicroVMイメージのビルド
- MicroVMの起動
ソースコードの準備
まずFlaskアプリのソースコードを準備します。
import logging
from flask import Flask, jsonify
app = Flask(__name__)
logging.basicConfig(level=logging.INFO)
@app.route("/")
def hello():
app.logger.info("Received request to hello world endpoint")
return jsonify(message="Hello, World!")
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000)
flaskをインストールするためにrequirements.txtも用意します。
gunicorn
flask
イメージをビルドするためのDockerfileを準備します。
FROM public.ecr.aws/lambda/microvms:al2023-minimal
RUN dnf install -y python3 python3-pip && dnf clean all
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY app.py .
EXPOSE 5000
CMD ["gunicorn", "--bind", "0.0.0.0:5000", "app:app"]
上記3つのファイルが準備できたらZIPに圧縮して適当なS3バケットにアップロードします。
MicroVMイメージのビルド
続いてMicroVMのイメージをビルドします。LambdaのマネコンにMicroVMsというメニューが増えているので、ここからMicroVMイメージを選択し「作成」ボタンをクリックします。
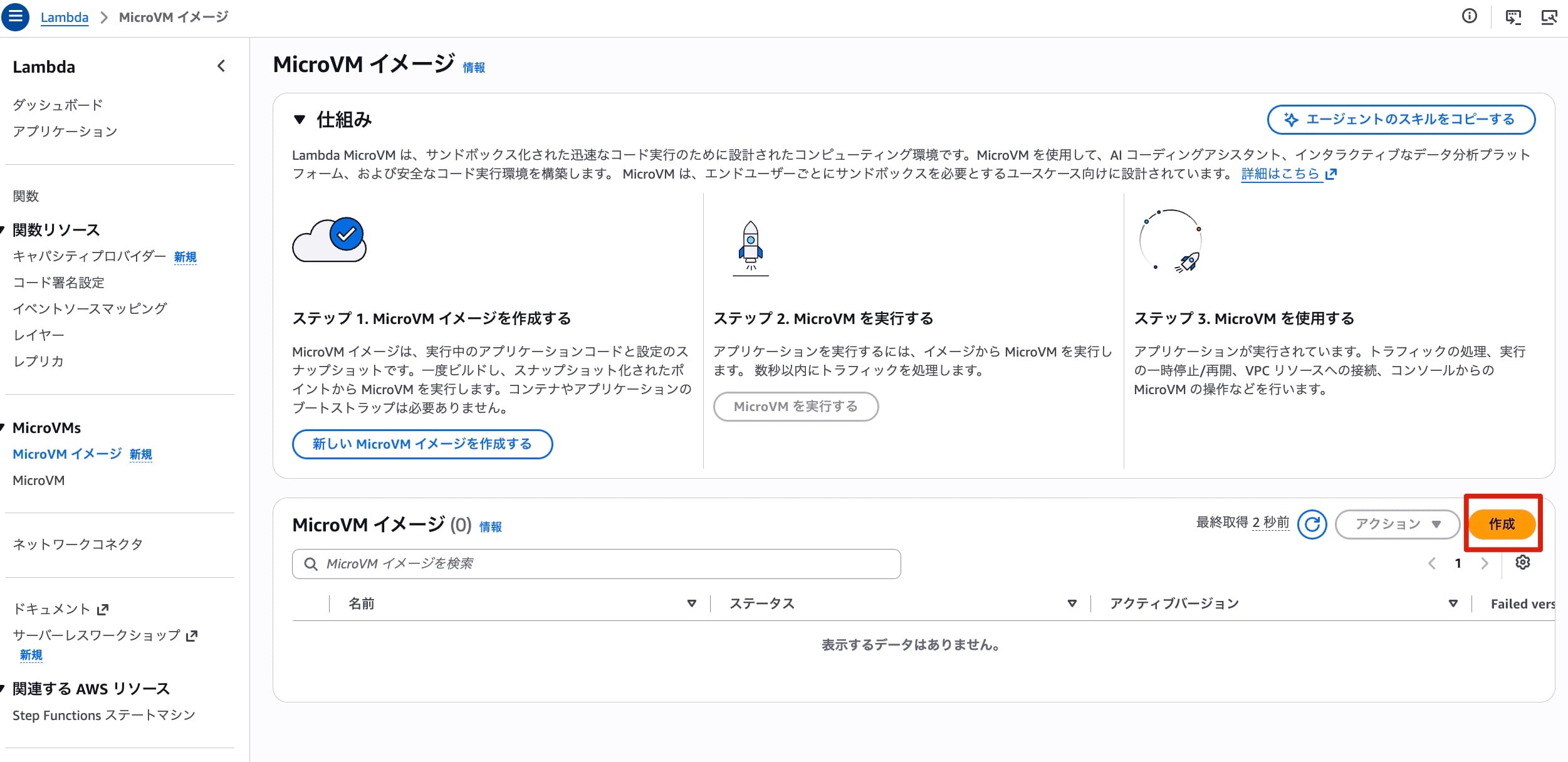
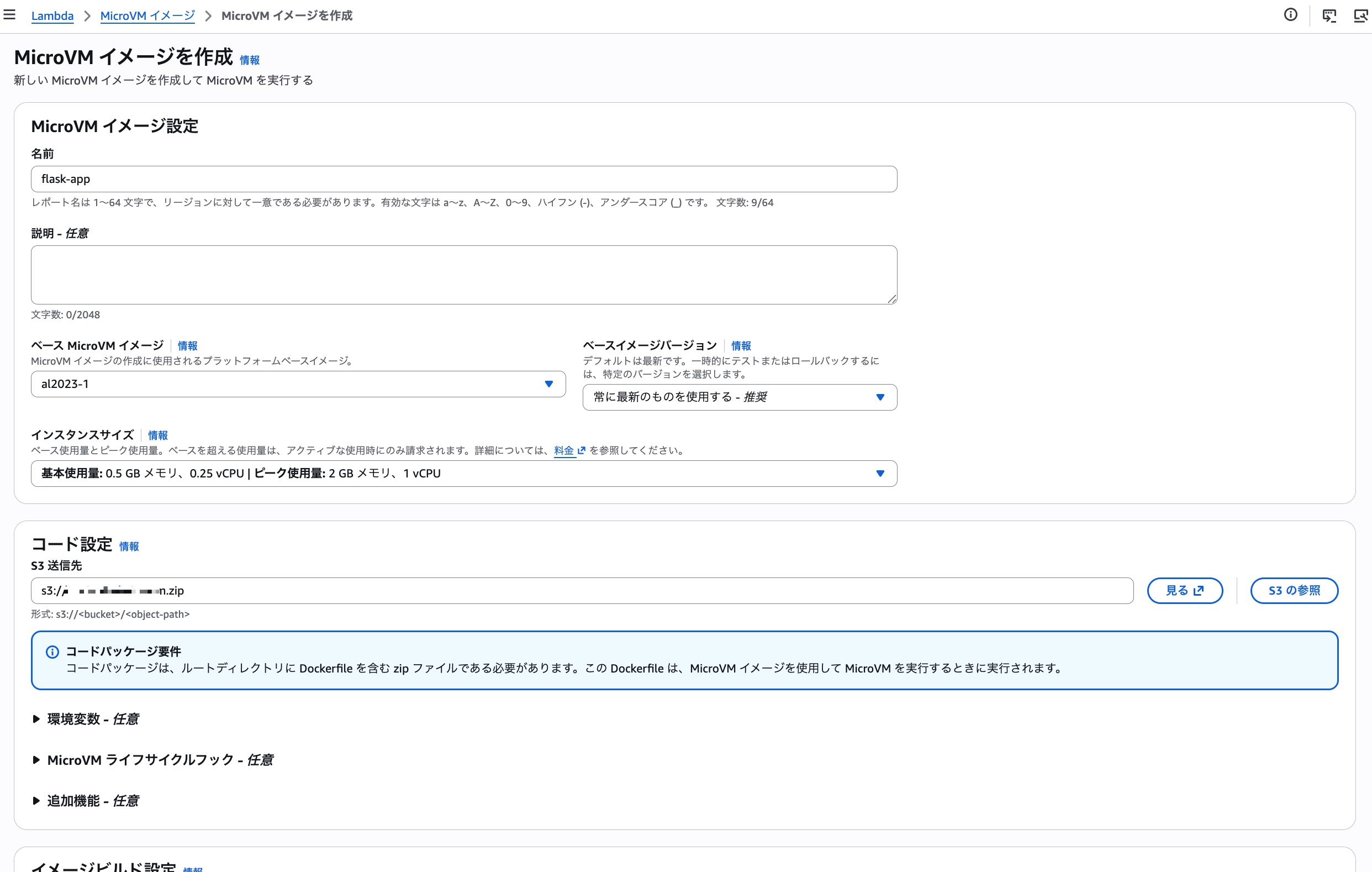
続いてMicroVMイメージの詳細を指定します。今回は先ほどS3にアップロードしたオブジェクトのキーを指定し、あとはデフォルトの設定のままでビルドを進めます。任意で指定可能な項目にも色々面白そうな設定があるので、今後深堀りしていきたいですね。
しばらく待つとビルドが完了します。
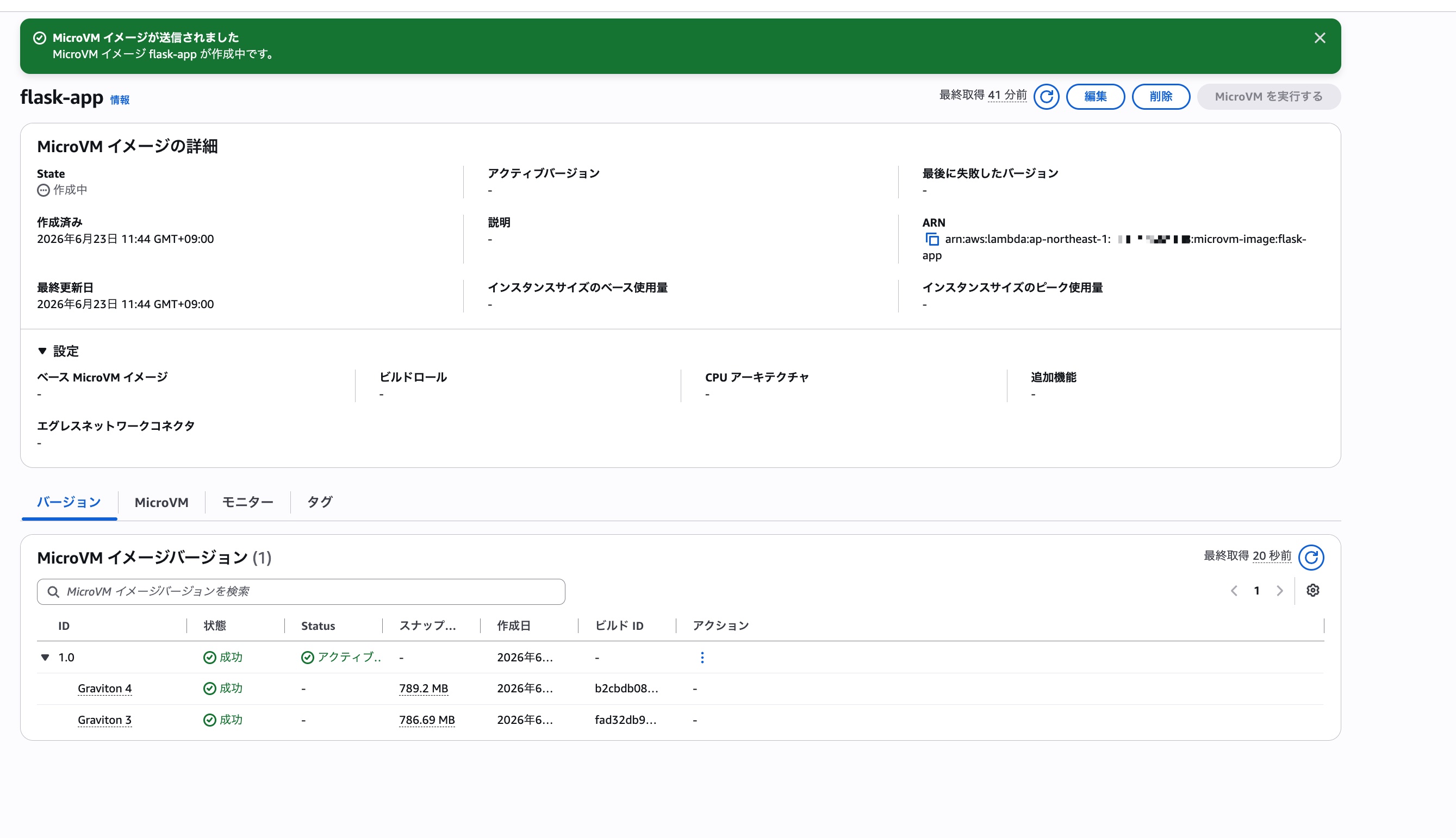
ビルドのログはCW Logsのロググループ/aws/lambda/<MicroVMイメージ名>に出力されるので、ビルドがうまくいかない場合はこのロググループを確認すると良いでしょう。
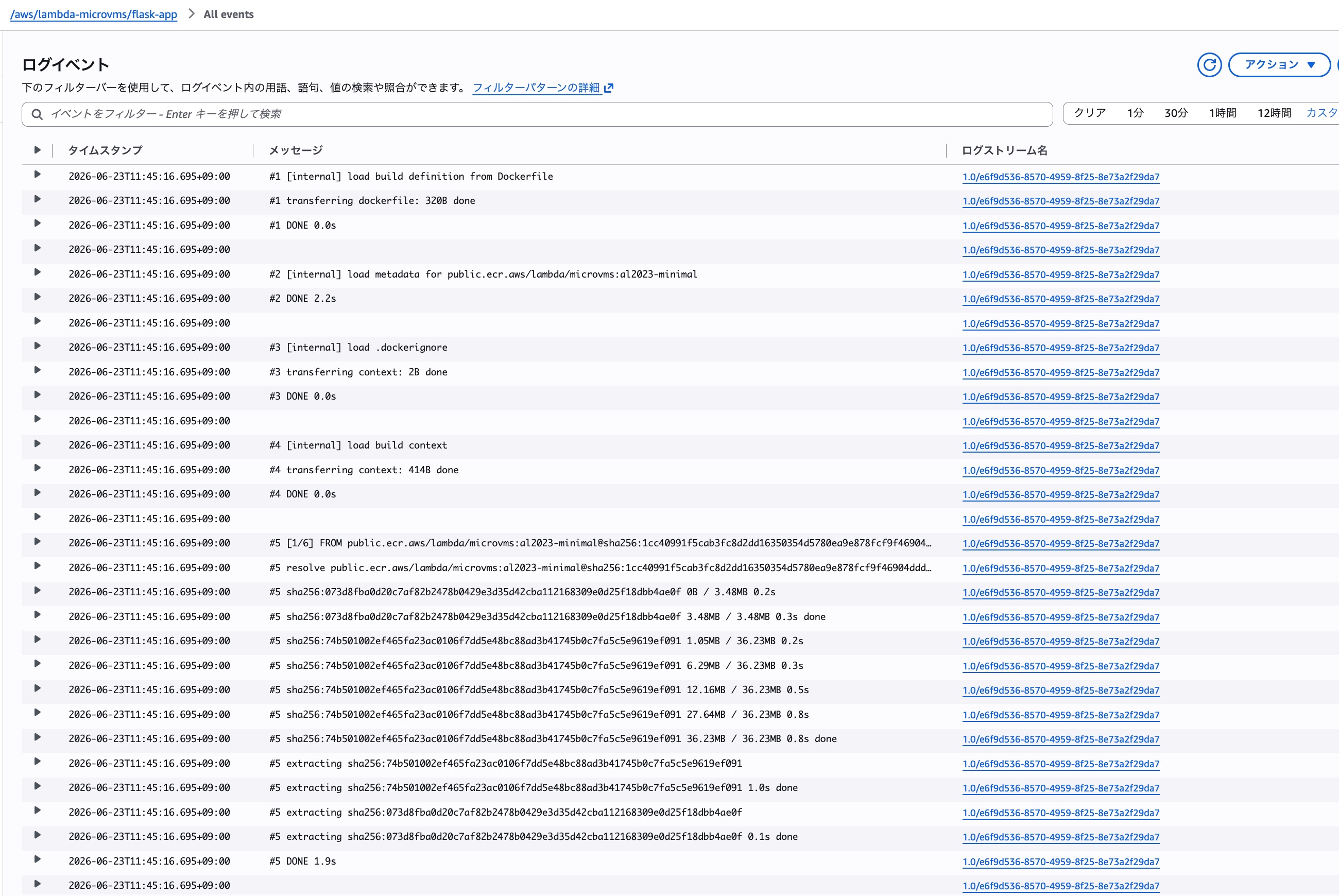
MicroVMの起動
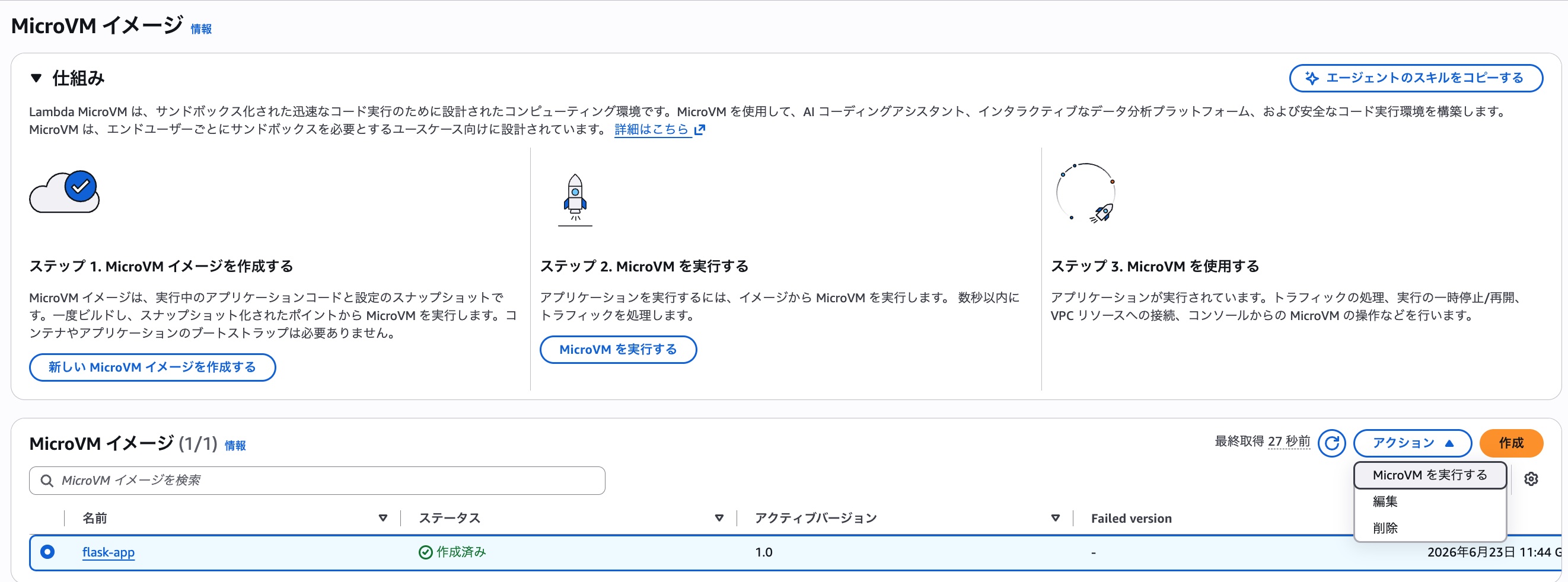
イメージが準備できたのでMicroVMを起動してみましょう。先ほど作成したMicroVMイメージを選択し、「アクション」から「MicroVMを実行する」を選択します。
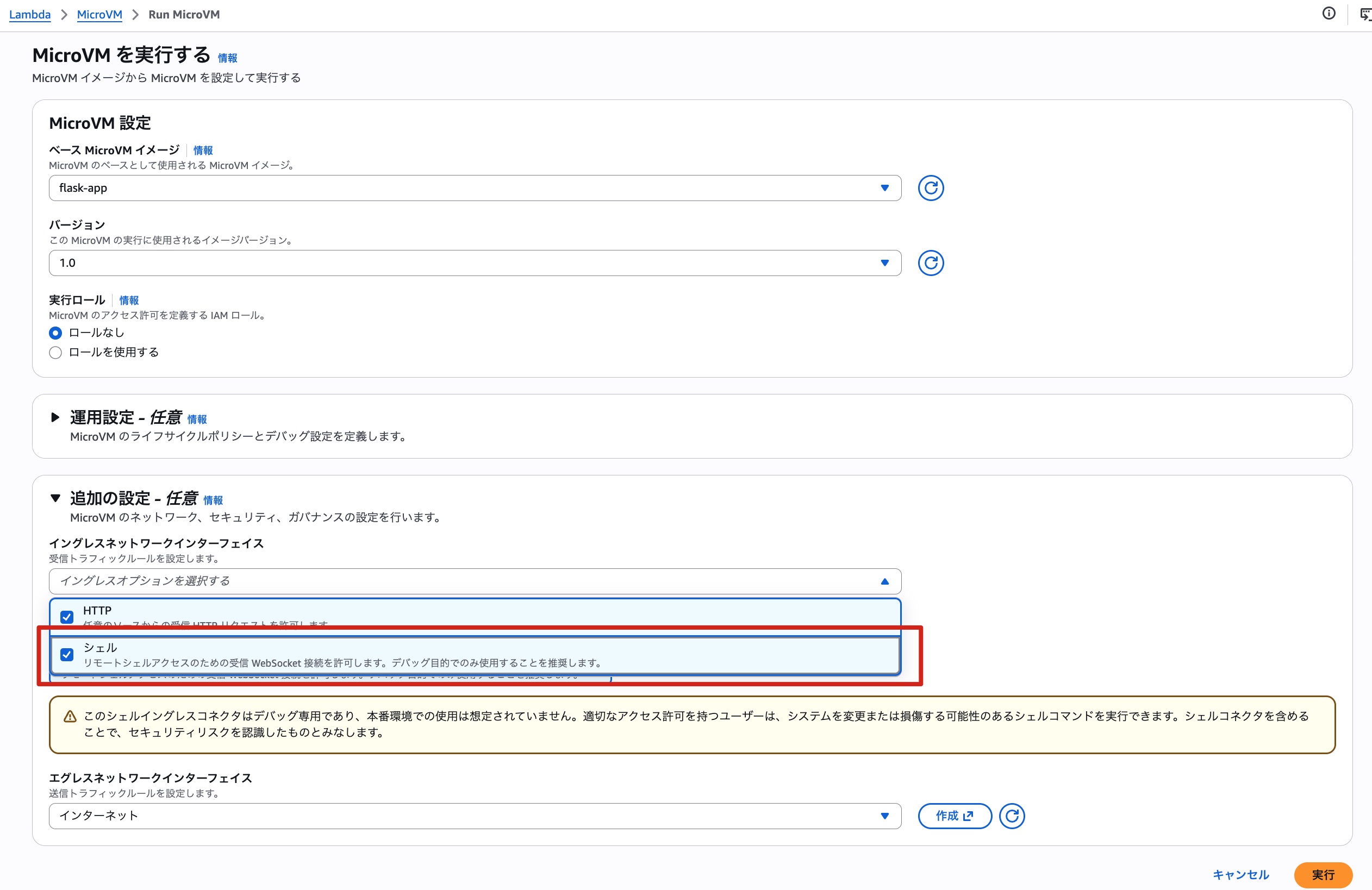
詳細画面が開くので、ここからMicroVMの設定を指定します。今回はせっかくなのでデフォルトの設定に加え、「イングレスネットワークインターフェース」に「シェル」も選択してみました。
「実行」ボタンをクリックすると一瞬でMicroVMが起動します。さすがFirecracker!!早い!!
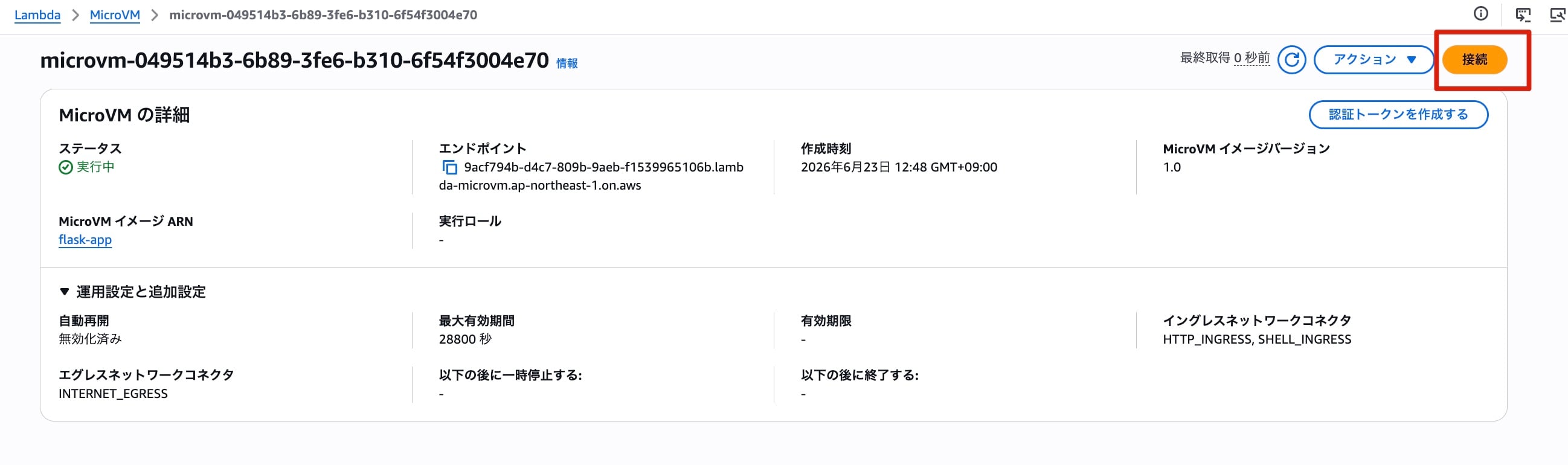
先ほどシェルを許可していたので、「接続」ボタンが利用可能になっています。このボタンをクリックするとSSM Session ManagerのようにブラウザからMicroVMのシェルが操作できます。いくつかコマンドを叩いてみました。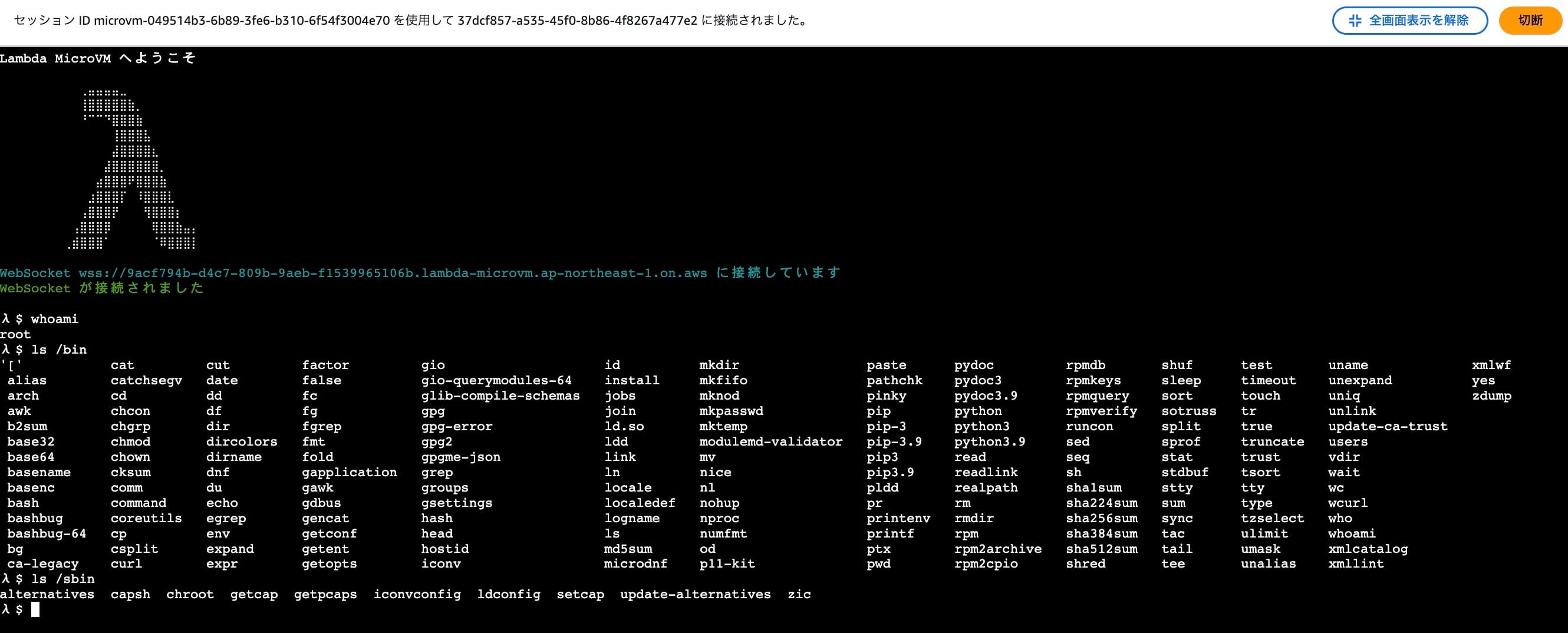
Lambda Functionの実行環境とは色々と差異がありますね。個人的にはプロンプトのλ $が好きです。
認証トークンを作成してPostmanからアクセス
MicroVMが起動したので、最後にflaskアプリにアクセスしてみましょう。先程の詳細画面から「認証トークンの作成」をクリックし、トークンを作成します。
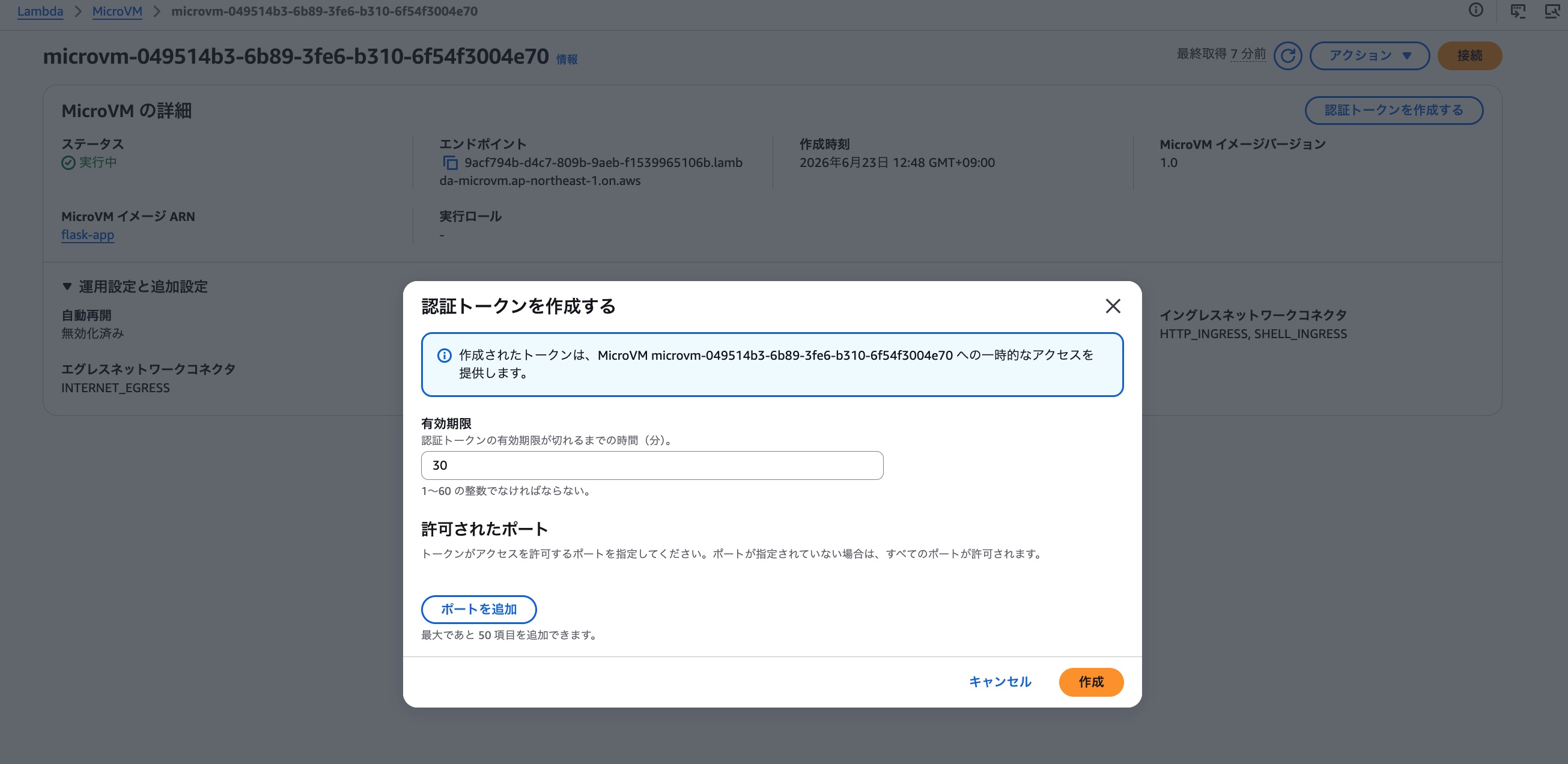
発行されたエンドポイントとトークンを利用してPostmanからMicroVMにリクエストを発行してみます。この際リクエストヘッダを以下の通り設定します。
-
X-aws-proxy-auth: 発行されたトークン-
JWE形式のトークンが発行されていました。ヘッダ部をデコードすると以下の通りになりました。
{ "kid": "91ea60c2-ecf2-4bc8-a6e7-10850a647641", "alg": "dir", "enc": "A256GCM" }
-
-
X-aws-proxy-port: 5000- MicroVM上で稼働するアプリケーションのポート番号を指定します。このヘッダが指定されていない場合はデフォルトで8080ポートが利用されます。
- このポートがトークン発行時に許可されたポート番号に含まれていない場合は403エラーとなります。
リクエストを実行すると...
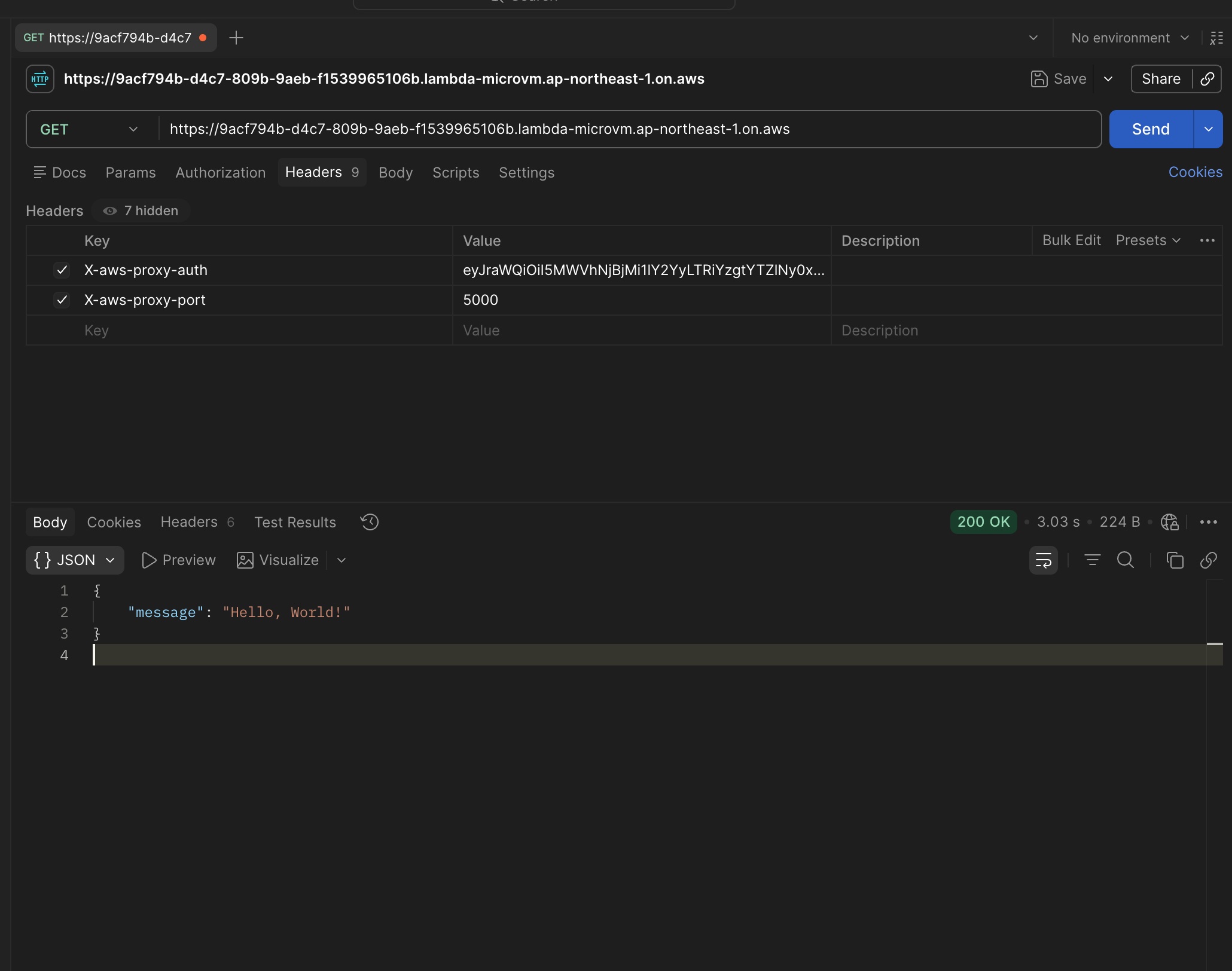
無事にリクエストに成功しました!!
まとめ
また面白そうな機能が出てきましたね。今回は簡単に検証しただけですが、他にもライフサイクル管理やネットワークコネクタなど色々なオプションがサポートされており、なかなか奥が深そうです。また色々と検証していきたいです。
参考
- Run isolated sandboxes with full lifecycle control: AWS Lambda introduces MicroVMs | AWS News Blog
- AWS introduces Lambda MicroVMs for isolated execution of user and AI-generated code - AWS
- AWS Lambda MicroVMs - AWS Lambda
- aws-samples/sample-lambda-microvm-claude-managed-agents
- Self-hosted sandboxes - Claude API Docs









