
AWS ParallelCluster Slurm アカウンティングのデータベース接続トラブルシューティングガイド
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS ParallelCluster でジョブ実行履歴を保存するには、Slurm と連携したデータベースが必要です。本記事では、クラスターの新規構築や、設定変更時に発生する接続トラブルの切り分け方法を紹介します。
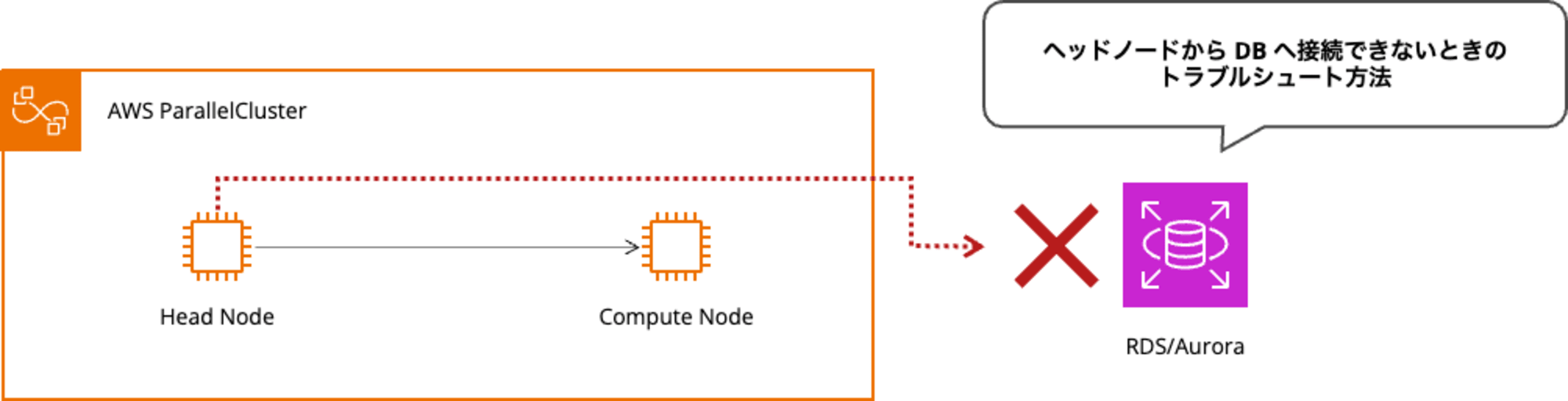
Slurm アカウンティングについて
Slurm アカウンティングはジョブ実行履歴を保存する機能です。この機能は以下の情報を記録します。
- ジョブの成功・失敗状況
- 実行時間
- 実行ユーザー
- その他の実行詳細
実行履歴保存には MySQL または MariaDB が必要です。これは Slurm の仕様であり AWS ParallelCluster 固有のものではありません。
AWS ParallelCluster 3.3.0 以降、DB への接続設定が簡素化されました。
詳細は以下の記事をご参照ください。
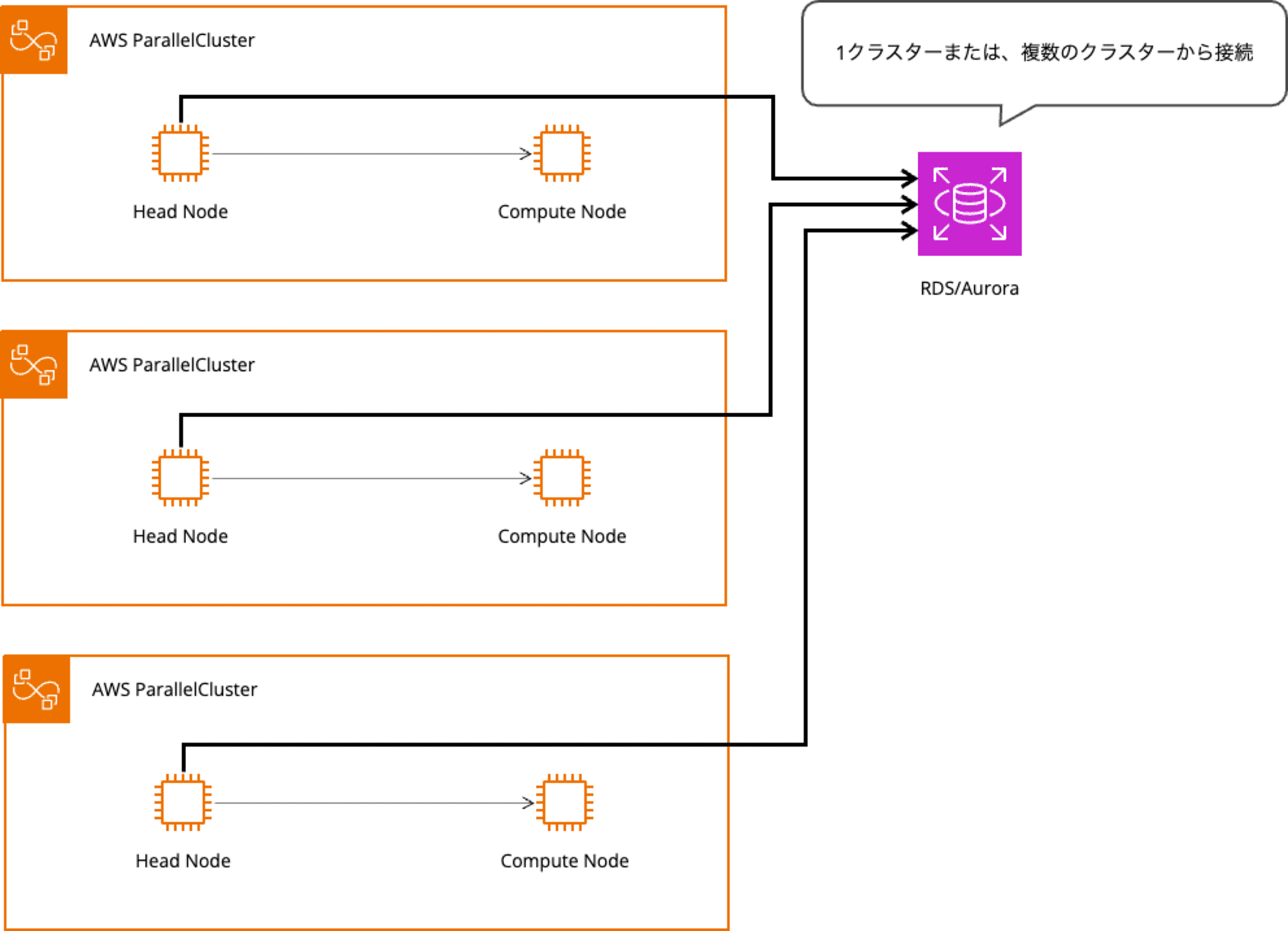
想定するデータベースへの接続構成
ランニングコスト削減のため、複数のクラスター(ヘッドノード)から共通のマネージド DB サービスへ接続する構成を想定しています。
DB 選定については以下の記事をご参照ください。
slurmdbdについては以下を参考にしてください。
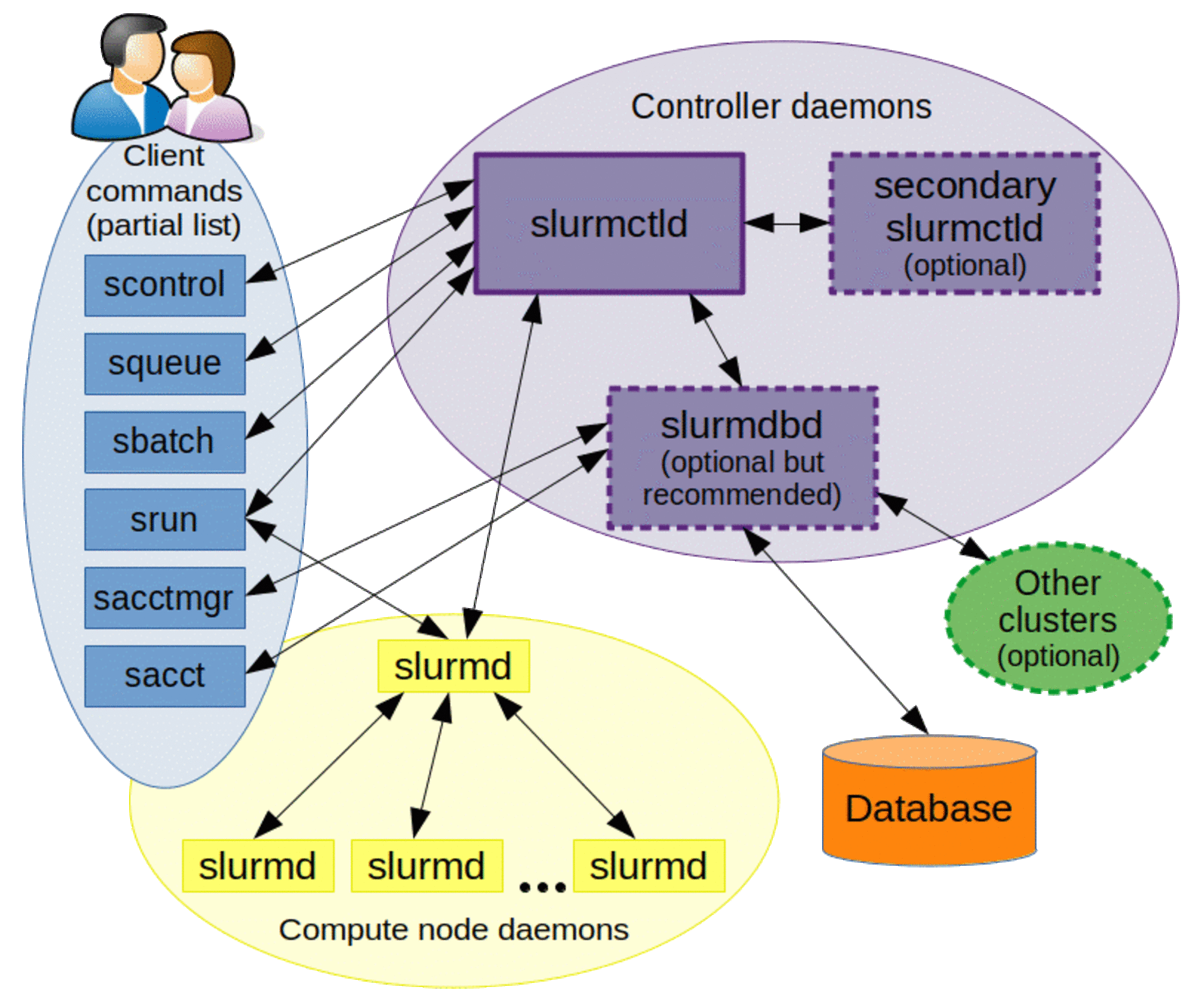
画像引用: Slurm Workload Manager - Quick Start User Guide
DB 接続設定は、AWS ParallelCluster v3.3.0 からサポートされたクラスターのコンフィグファイルに直接記述する方式を採用します。
Scheduling:
Scheduler: slurm
SlurmSettings:
ScaledownIdletime: 10
# Slurm Accounting 設定
Database:
Uri: slumdb.hogehoge.ap-northeast-1.rds.amazonaws.com:3306
UserName: admin
PasswordSecretArn: arn:aws:secretsmanager:ap-northeast-1:123456789012:secret:slurmdb-hoge
DB へ接続失敗と気がつくタイミング
初回の DB 接続失敗は以下の 2 つのタイミングで発覚します。
- クラスター新規作成時
- クラスター設定更新時
クラスター新規作成時の症状
クラスターのデプロイに失敗します。ヘッドノードが起動するところまでは進みますが、DB との接続ができないためにタイムアウト後ヘッドノードが終了します。
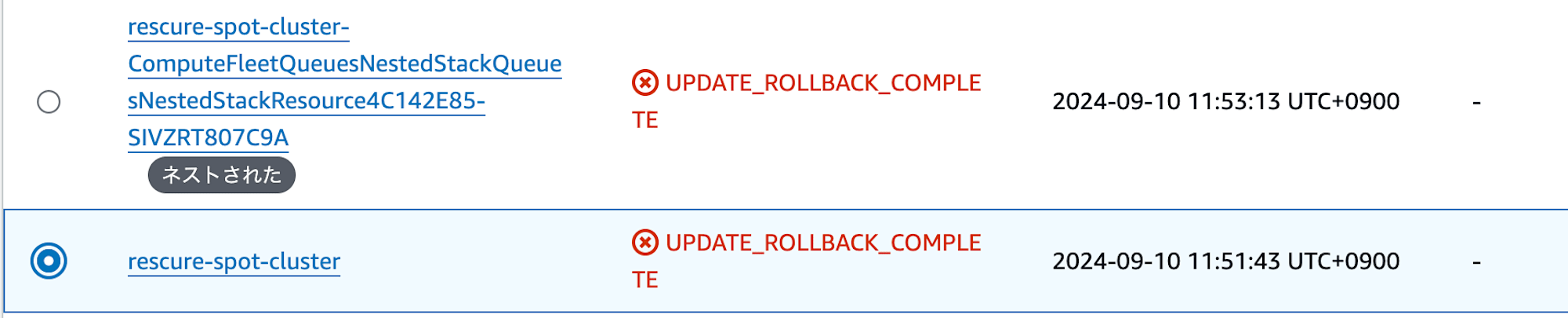
クラスター設定更新時の症状
更新プロセスに失敗し、自動的にロールバックします。
DB 接続問題の切り分け方法
DB 接続の問題を効率的に特定するには以下の手順を推奨します。
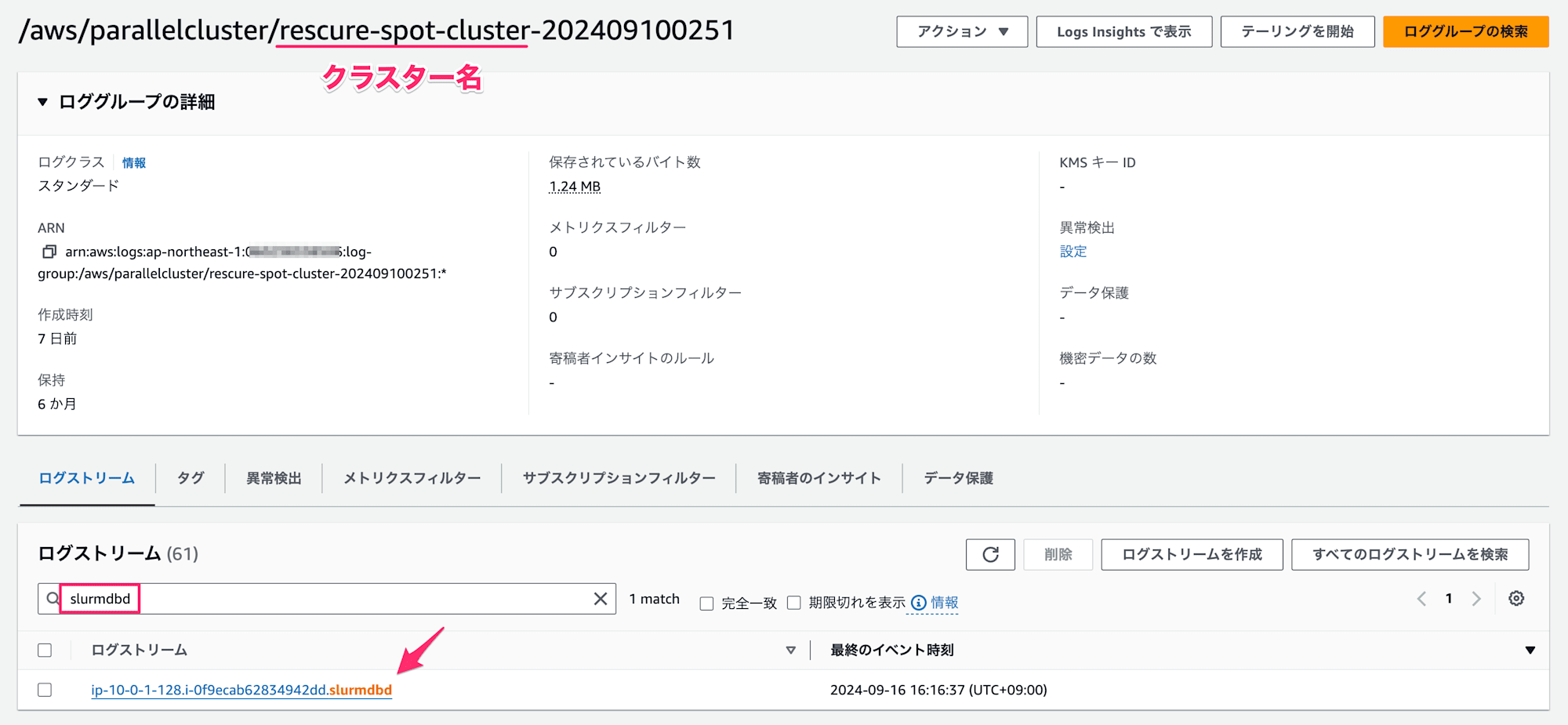
CloudWatch Logs の確認
slurmdbdのログに DB 接続エラーが記録されるはずです。原因を特定できる可能性が高いです。

よくある接続問題の確認
RDS/Aurora への接続が失敗する主な原因として以下が挙げられます。
-
セキュリティグループ設定の誤り
- インバウンドルールが適切に設定されていない
- ヘッドノードのセキュリティグループか、VPC の CIDR からアクセスが許可されていない
- 必要なポートが開放されていない
-
DB 接続ユーザー名の誤り
- クラスターコンフィグでの指定ミス
- RDS/Aurora 側で設定されているユーザー名との不一致
-
DB 接続パスワードの誤り
- クラスターコンフィグでの指定ミス
- Secrets Manager に保存したパスワードのミス
-
DB が停止している
- RDS/Aurora を停止したまま忘れている
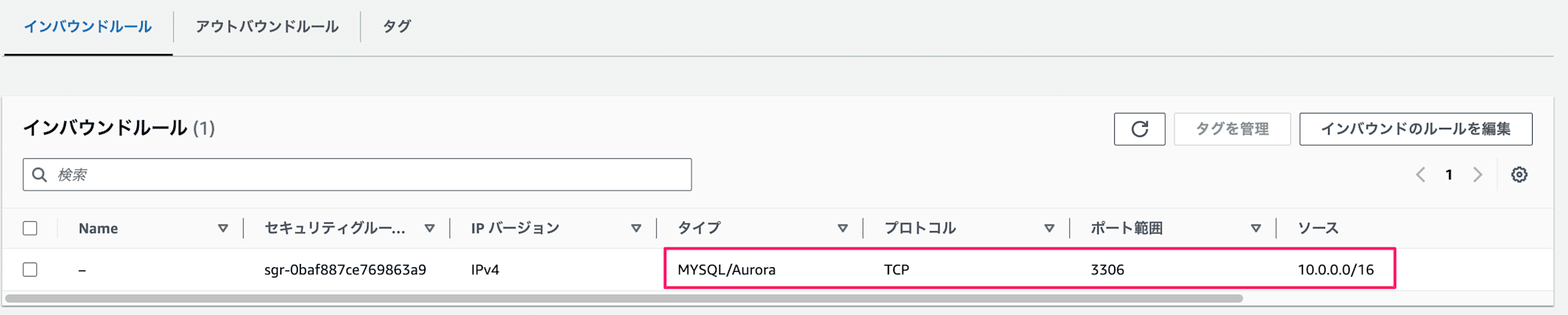
2.1 ヘッドノードのセキュリティグループをインバウンドの許可に追加
デフォルト設定だとクラスターの新規構築時にヘッドノード用のセキュリティグループが作成されます。そのため、DB のセキュリティグループは同じ VPC の CIDR ないし、ヘッドノードを起動するサブネットからのアクセスを許可しておくのが無難です。
3.1 パスワードの確認方法
ヘッドノードにログインすると、Secrets Manager に保存したパスワードが、プレーンテキストで Slurm の設定ファイルに書き込まれているので確認できます。
DbdHost=ip-10-0-1-128
StorageHost=slumdb.hogehoge.ap-northeast-1.rds.amazonaws.com
StoragePort=3306
StorageLoc=rescure_spot_cluster
StorageUser=admin
StoragePass=slurm-pass
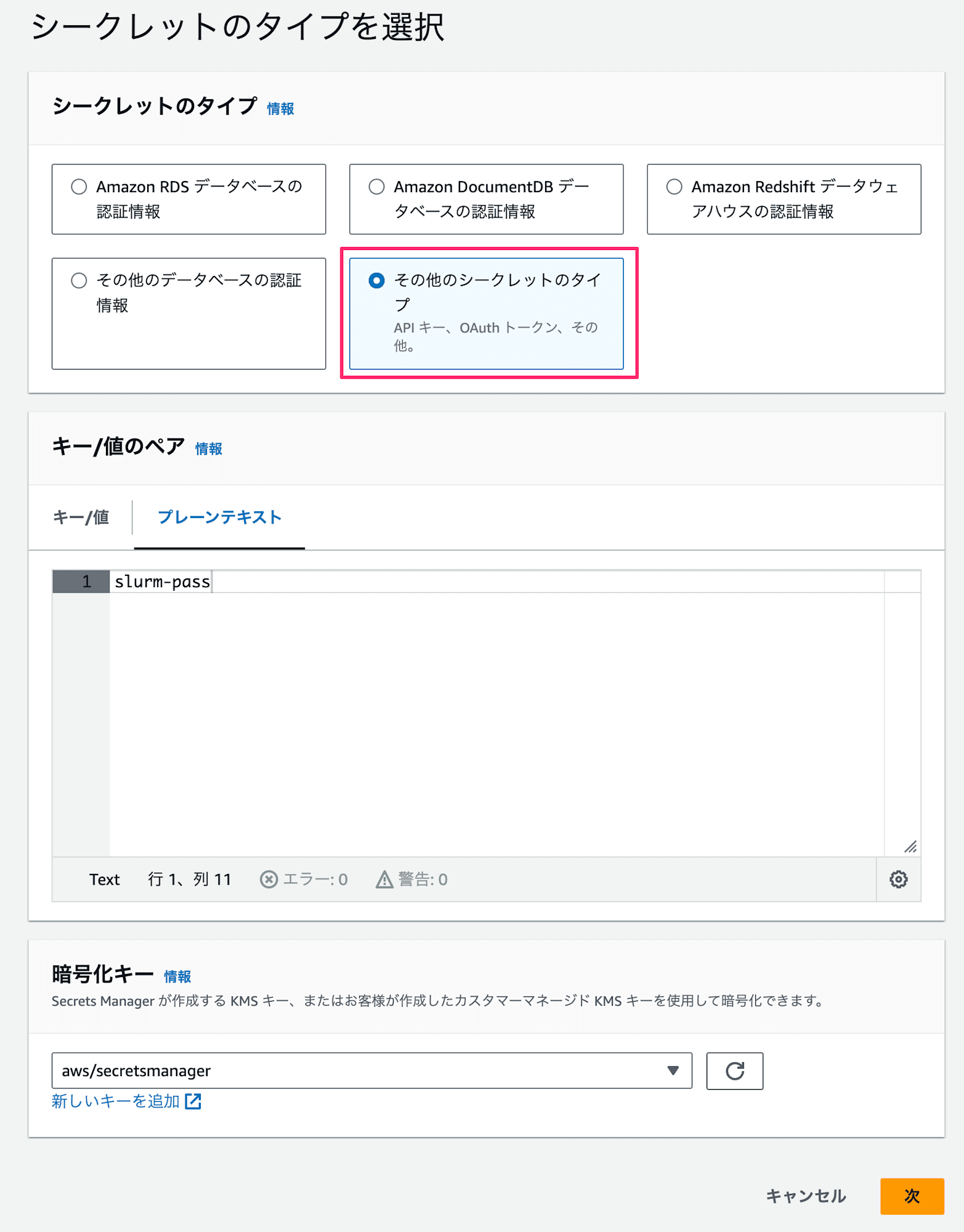
3.2 Secrets Manger に登録したパスワード確認
パスワードはプレーンテキストですと以下の形式で保存します。
まとめ
AWS ParallelCluster で Slurm アカウンティングを使用する際のデータベース接続トラブルについて以下の点を解説しました。
- Slurm アカウンティングの概要
- データベース接続の構成方法
- 接続失敗の症状と発見のタイミング
- 問題の切り分け方法と主な原因
CloudWatch Logs の確認や、セキュリティグループ設定、ユーザー名、パスワードの確認など、具体的な対処方法を紹介しました。効率的にトラブルシューティングできるのではないでしょうか。
おわりに
トラブルシュートに想定より時間かかりました。なので、切り分けポイントをまとめておきました。どなたかのお役になれば幸いです。









