![[参加レポート] 流しのエバンジェリストシリーズ AWSを中心として色んなサービスの基礎を学ぼう 「Amazon S3 Tables + Amazon Athena / Apache Iceberg」 #awsbasics](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-066beb776f0c57ce64255fadcc072f60/82b2f6687ab5774cd73f9176dcac7855/amazon-s3?w=3840&fm=webp)
[参加レポート] 流しのエバンジェリストシリーズ AWSを中心として色んなサービスの基礎を学ぼう 「Amazon S3 Tables + Amazon Athena / Apache Iceberg」 #awsbasics
コーヒーが好きな emi です。
最近データ分析分野を頑張っているのですが、実はいまだにしっかり S3 Tables を操作できていませんでした。
そんな折、2 年 4 ヶ月ぶりに以下のエバンジェリストシリーズで S3 Tables を扱っていただけるとのことで、参加しました。
座学を聞いてハンズオンを実施したのですが、ハンズオン部分でところどころつまづいたので復習も兼ねて実施したことを書いておきます。
座学の復習
座学パートの資料は以下で公開されています。
後でコメントなど追記できたらと思いますが、特に印象的だったのは、テーブルの特定の行だけを簡単に操作できる仕組みです。
メンテナンスの重要性
大量のデータが含まれるテーブルから特定の 1 行を削除するのは通常困難です。特定の行を見つけるために大量の行をスキャンしなければならないからです。
しかし、Iceberg ではなぜこれが可能なのでしょうか?
実は、物理的にデータを削除しているわけではありません。代わりに 「この行を削除しました」 というメタデータを追加で書き込んでいるのです。
このように、Iceberg はデータの差分情報をメタデータとして管理しています。
ただし、このような更新操作を繰り返し行うと、メタデータのフラグメントが大量に発生します。そのため、コンパクションのようなメンテナンス作業が必要になります。S3 Tables では、このメンテナンス作業を自動的に裏側で処理してくれます。
また、すべての更新操作にはタイムスタンプが記録されるため、過去の任意の時点のデータスナップショットに簡単にアクセスできる 「タイムトラベルクエリ」 が実行可能になります。
ハンズオン
手順は以下となります。
私が一部つまづいたり混乱した部分があるので、そこも含めて本ブログで改めて記載します。
構成図
図が無いと私がイメージしにくいので描いてみました。ほぼ このドキュメント の図を日本語で書き直したようなものなのですが、イメージいただけたら幸いです。
ポイントは、S3 Tables というサービスの中に以下 3 つのコンポーネントが存在する点です。
- テーブルバケット
- 名前空間(namespace)
- テーブル
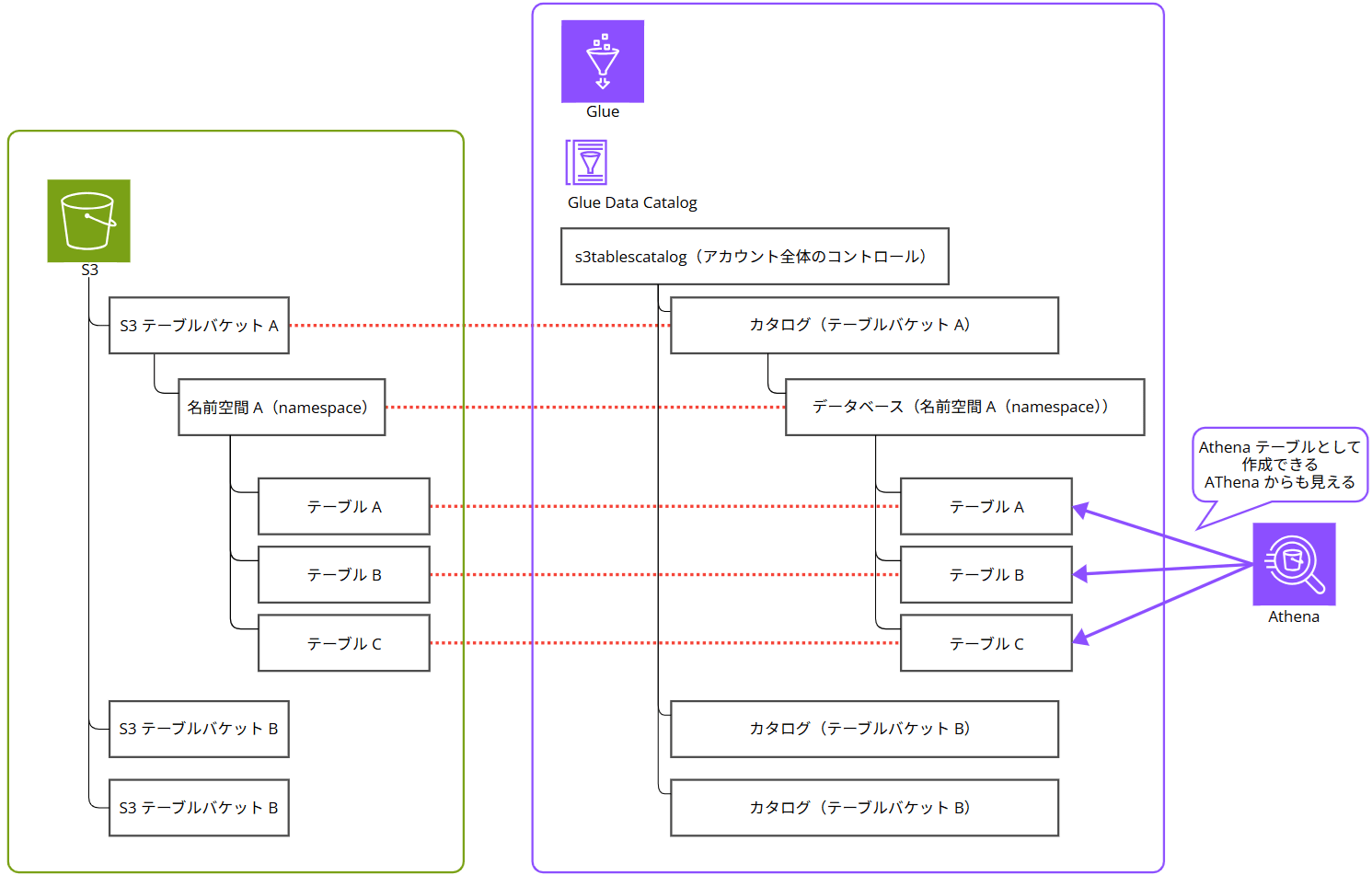
テーブルバケットの中に名前空間、名前空間の中にテーブルがある、という階層構造になっています。
また、カタログは Glue Data Catalog として管理されていて、Glue とは上記図のように対応しています。
作成したテーブルは Athena から確認できます。
1. S3 Tables の作成
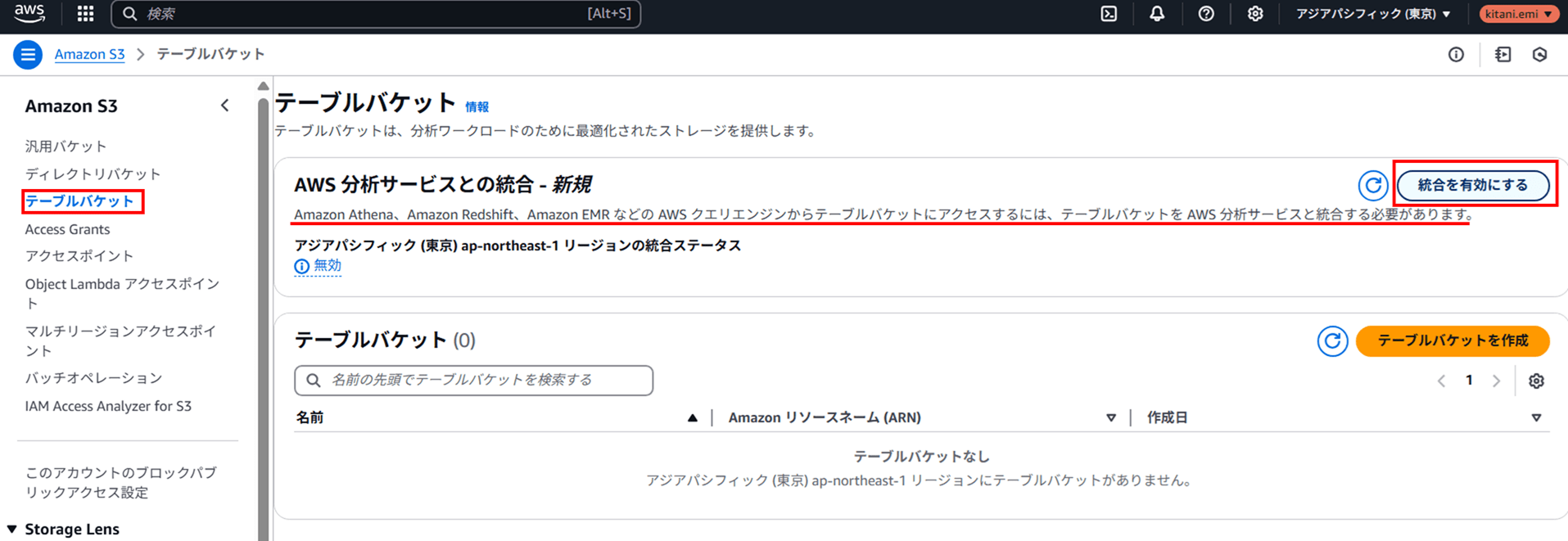
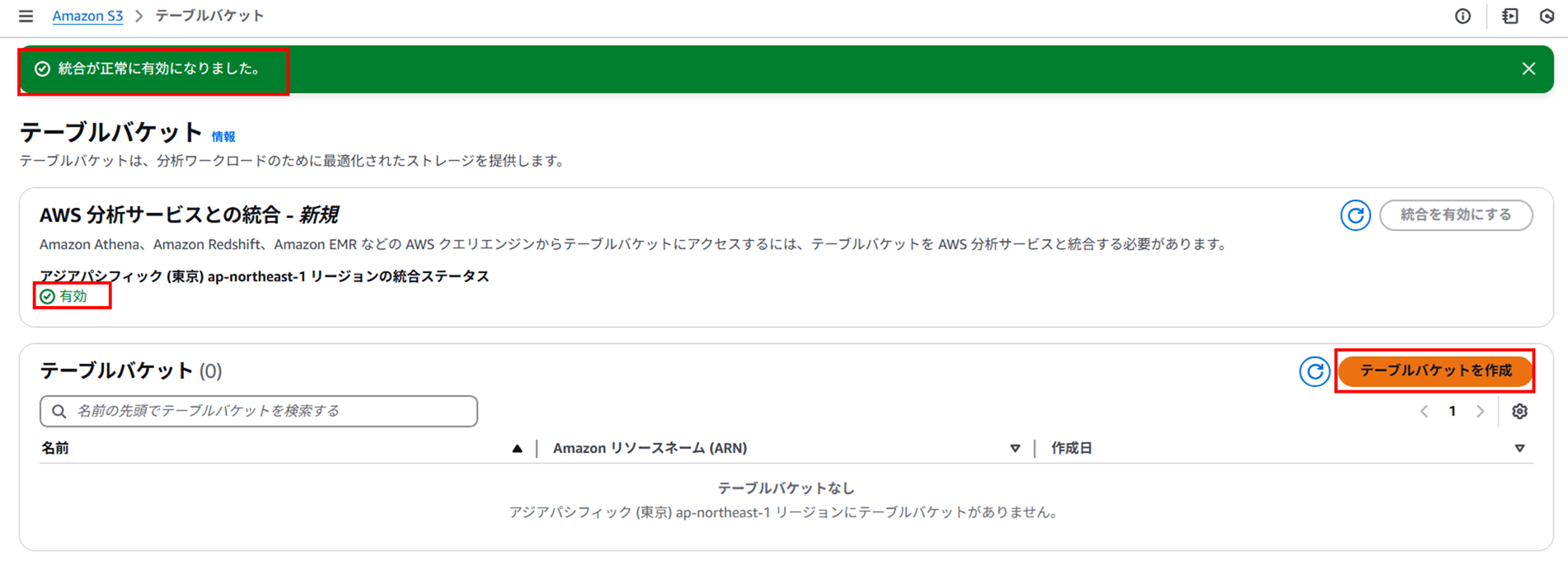
最初にテーブルバケットを作成します。S3 コンソールで 「テーブルバケット」 をクリックします。
以下のように 「AWS 分析サービスとの統合」 という表示があります。今回は S3 テーブルバケットに対して Athena からクエリするので、この統合が必要です。「統合を有効にする」 をクリックします。
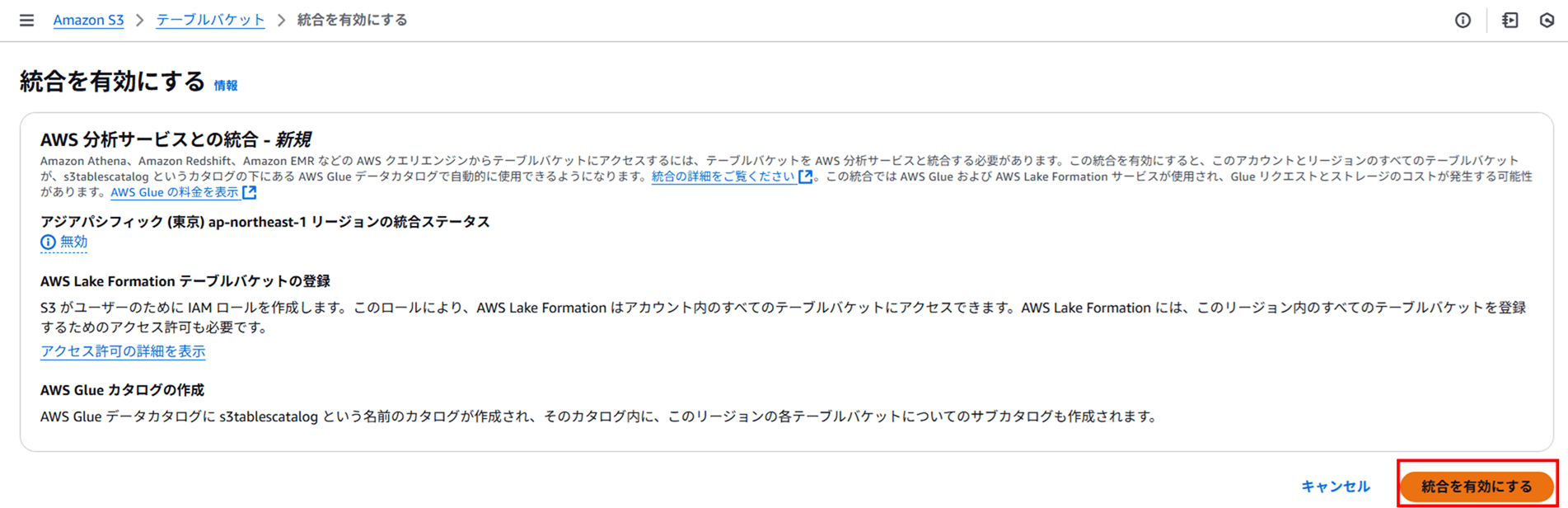
この統合を有効にすると、操作中のリージョンのテーブルバケットが s3tablescatalog というカタログの下にある Glue データカタログで自動的に使用できるようになると書かれています。統合の詳細は以下のドキュメントに記載があります。
上記ドキュメントの図を以下に引用します。S3 Tables 内のデータが裏では Glue Data Catalog で自動管理されていて、そのおかげで Athena など他の AWS サービスからクエリできるということですね。
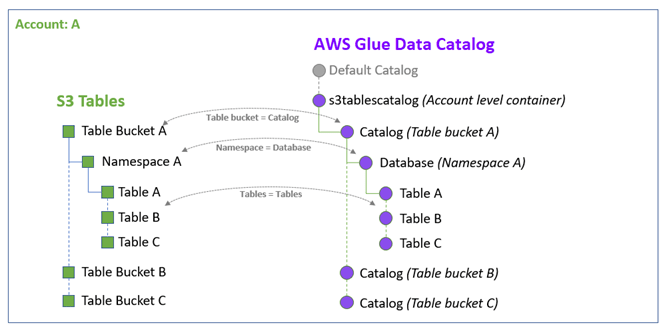
私も理解が難しかったのですが、この後 Lake Formation コンソールで操作する手順がありまして、私たちは Lake Formation を使っているように感じますが、裏で作成されるリソースの実態は Glue なのだそうです。
「AWS Lake Formation テーブルバケットの登録」 の部分を読むと、Lake Formation 用の IAM ロールが作成されるようです。この IAM ロールによって、Lake Formation がアカウント内のすべてのテーブルバケットにアクセスし、このリージョン内のすべてのテーブルバケットを登録する権限を得ます。
権限をクリックして見てみると以下のようになっていました。
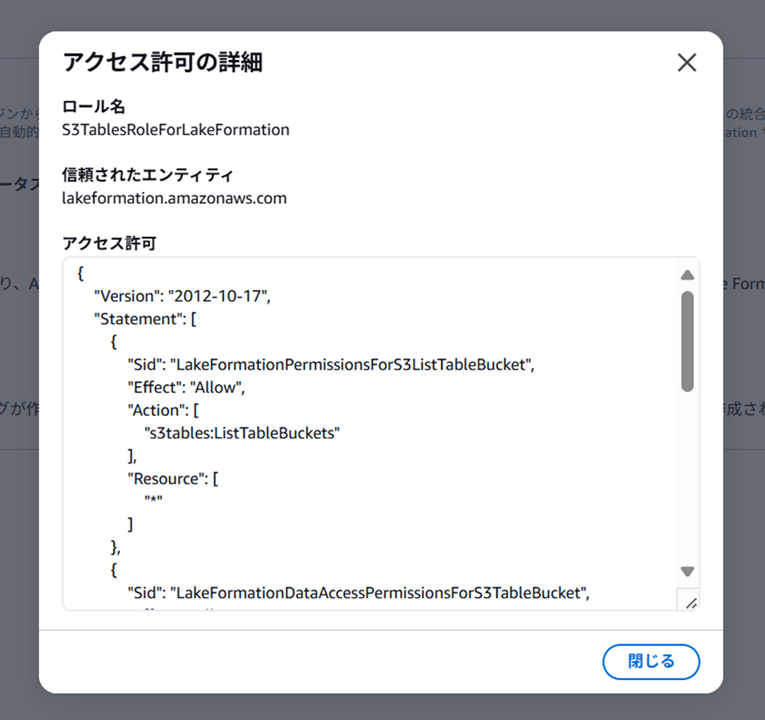
S3TablesRoleForLakeFormation
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "LakeFormationPermissionsForS3ListTableBucket",
"Effect": "Allow",
"Action": [
"s3tables:ListTableBuckets"
],
"Resource": [
"*"
]
},
{
"Sid": "LakeFormationDataAccessPermissionsForS3TableBucket",
"Effect": "Allow",
"Action": [
"s3tables:CreateTableBucket",
"s3tables:GetTableBucket",
"s3tables:CreateNamespace",
"s3tables:GetNamespace",
"s3tables:ListNamespaces",
"s3tables:DeleteNamespace",
"s3tables:DeleteTableBucket",
"s3tables:CreateTable",
"s3tables:DeleteTable",
"s3tables:GetTable",
"s3tables:ListTables",
"s3tables:RenameTable",
"s3tables:UpdateTableMetadataLocation",
"s3tables:GetTableMetadataLocation",
"s3tables:GetTableData",
"s3tables:PutTableData"
],
"Resource": [
"arn:aws:s3tables:ap-northeast-1:123456789012:bucket/*"
]
}
]
}
統合を有効にすると以下のように 「統合が正常に有効になりました。」 と表示されます。
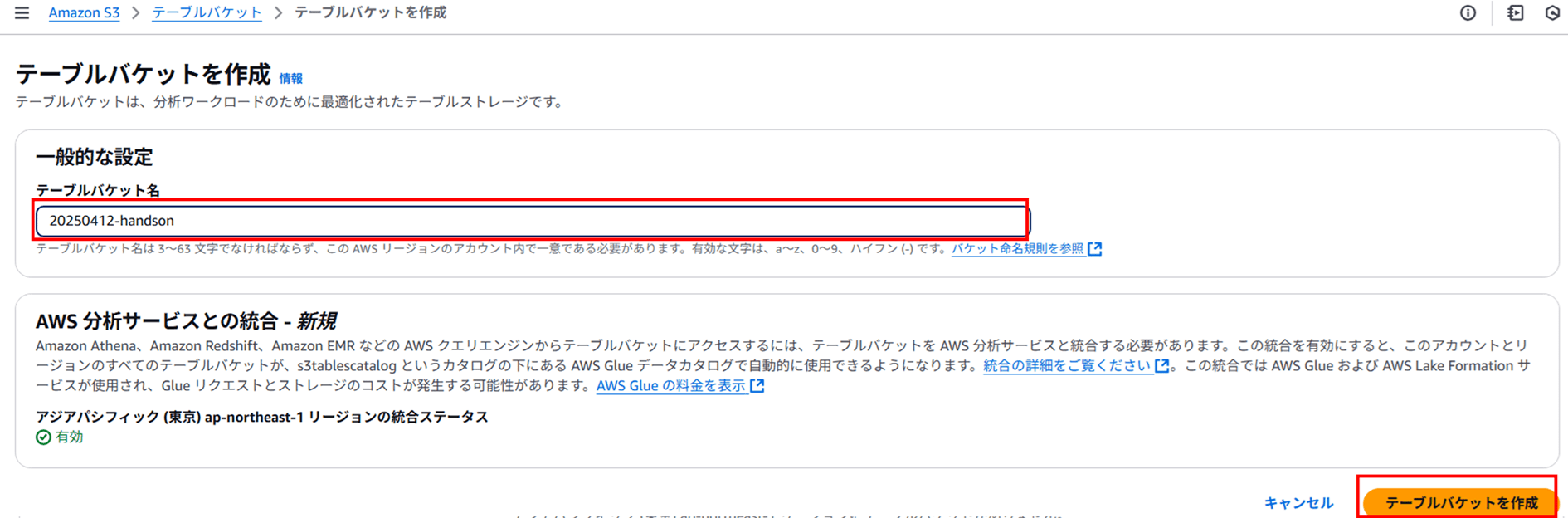
では、テーブルバケットを作成していきます。
ここではテーブルバケット名を指定するだけです。
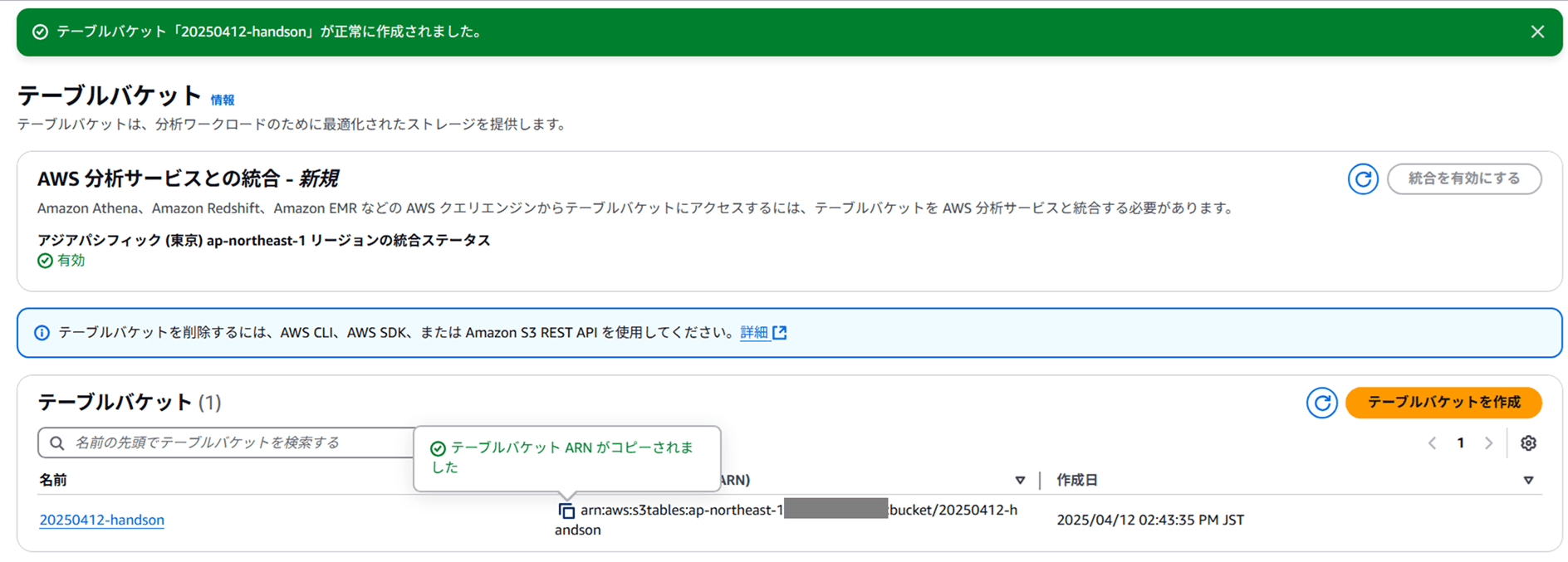
できました。テーブルバケット ARN をコピーしておきます。
作成したテーブルバケットをクリックして見ると、まだ 「テーブル (0)」 となっており中身は空っぽです。
2. テーブルと名前空間(namespace)の作成
このまま S3 Tables の画面から 「Athena でテーブルを作成」 をクリックし Athena でテーブルと名前空間(namespace)を作成することもできるのですが、ハンズオン手順に合わせて AWS CLI で作成します。CloudShell から CLI コマンドを実行します。
まずは create-namespace コマンドで名前空間(namespace)を作成します。
aws s3tables create-namespace --table-bucket-arn <s3 tables バケットarn> --namespace <名前空間の名前>
名前空間(namespace)の名前を 20250412-handson-ns としてコマンドを実行すると…
▼実行結果
[cloudshell-user@ip-10-132-81-204 ~]$ aws s3tables create-namespace --table-bucket-arn arn:aws:s3tables:ap-northeast-1:123456789012:bucket/20250412-handson --namespace 20250412-handson-ns
An error occurred (BadRequestException) when calling the CreateNamespace operation: The specified namespace name is not valid.
[cloudshell-user@ip-10-132-81-204 ~]$
おっと…エラーになってしまいました。The specified namespace name is not valid.(指定されたネームスペース名が有効ではありません。)ということで、名前空間(namespace)の命名規則に決まりがあるようです。
上記ドキュメントを見ると、ハイフンはダメでした。名前空間(namespace)の名前を handson_namespace として再度コマンドを実行します。
▼実行結果
[cloudshell-user@ip-10-132-81-204 ~]$ aws s3tables create-namespace --table-bucket-arn arn:aws:s3tables:ap-northeast-1:123456789012:bucket/20250412-handson --namespace "handson_namespace"
{
"tableBucketARN": "arn:aws:s3tables:ap-northeast-1:123456789012:bucket/20250412-handson",
"namespace": [
"handson_namespace"
]
}
[cloudshell-user@ip-10-132-81-204 ~]$
今度は成功しました。
名前空間(namespace)ができたので、次は create-table コマンドでテーブルを作成します。
テーブルの作成と同時にスキーマも定義していきます。以下のブログも参照ください。
スキーマをコマンドの中で定義するのは大変なので、CLI スケルトンを使います。CLI スケルトンについては [AWS CLI] 長いパラメータの入力が不要になる CLI Skeleton が便利すぎる件 | DevelopersIO もご参照ください。
スキーマを定義するために、元になる JSON ファイルを作成していきます。vi コマンドで table.json というファイルを作成し開きます。
vi table.json
以下の JSON テキストで、<S3 tables バケットarn> と <先ほど作成した名前空間> を自分の環境に合わせて変更します。テーブル名は my_table としていますが、変えても OK です。
{
"tableBucketARN": "<S3 tables バケットarn>",
"namespace": "<先ほど作成した名前空間>",
"name": "my_table",
"format": "ICEBERG",
"metadata": {
"iceberg": {
"schema": {
"fields": [
{"name": "id", "type": "int","required": true},
{"name": "name", "type": "string"},
{"name": "value", "type": "int"}
]
}
}
}
}
:set paste と入力して Enter キーを押すと、貼り付けモードになります。Enter キーを押すと、カーソルが上にきます。
i を押下して編集モードに移行します。i を押下すると画面下部に --INSERT (paste)-- と表示されます。
上記で編集した JSON を貼り付けると、インデント崩れせずに貼り付けられます。
esc キーを押下して編集モードを抜け、:wq と入力して Enter キーを押すと、保存して終了します。
こちら で似たような操作を行っているので、画面イメージも確認されたい方は参照ください。
cat で編集内容が保存できたか確認します。
[cloudshell-user@ip-10-132-81-204 ~]$ cat table.json
{
"tableBucketARN": "arn:aws:s3tables:ap-northeast-1:123456789012:bucket/20250412-handson",
"namespace": "handson_namespace",
"name": "my_table",
"format": "ICEBERG",
"metadata": {
"iceberg": {
"schema": {
"fields": [
{"name": "id", "type": "int","required": true},
{"name": "name", "type": "string"},
{"name": "value", "type": "int"}
]
}
}
}
}
[cloudshell-user@ip-10-132-81-204 ~]$
保存できていますね。
では、テーブルを作成します。
aws s3tables create-table --cli-input-json file://table.json
▼実行結果
[cloudshell-user@ip-10-132-81-204 ~]$ aws s3tables create-table --cli-input-json file://table.json
{
"tableARN": "arn:aws:s3tables:ap-northeast-1:123456789012:bucket/20250412-handson/table/7e011d9d-94ef-49ca-a299-110ac1b365d6",
"versionToken": "cc531d8d123530d30d09"
}
[cloudshell-user@ip-10-132-81-204 ~]$
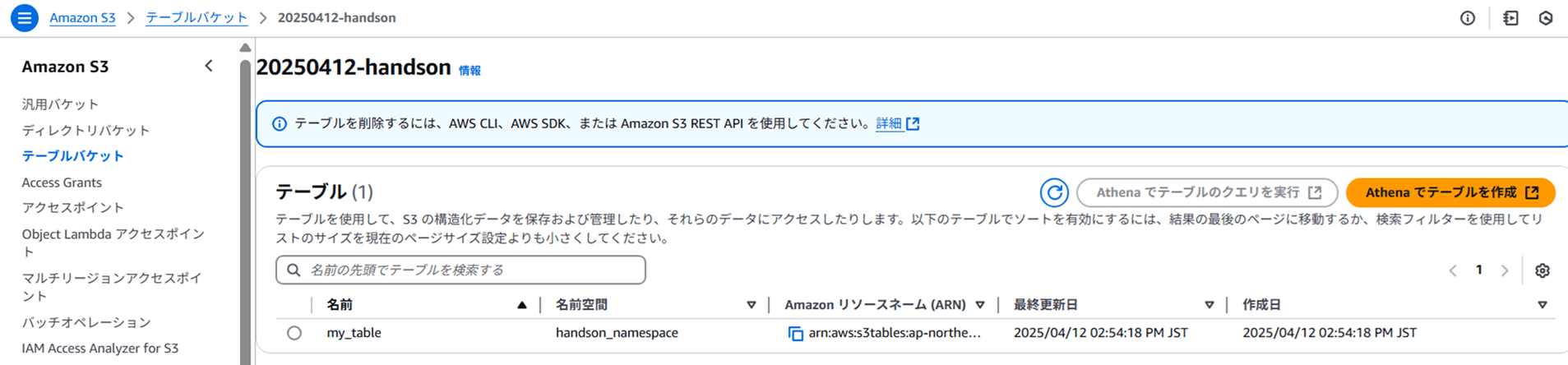
S3 コンソールに戻って確認すると、テーブル my_table と名前空間 handson_namespace ができているのが分かります。
3. Lake Formation の設定
さて、CLI で S3 テーブルの作成はできました。Athena コンソールからも S3 テーブルの作成ができるのでやってみます。
S3 コンソールで 「Athena でテーブルを作成」 をクリックしてみます。
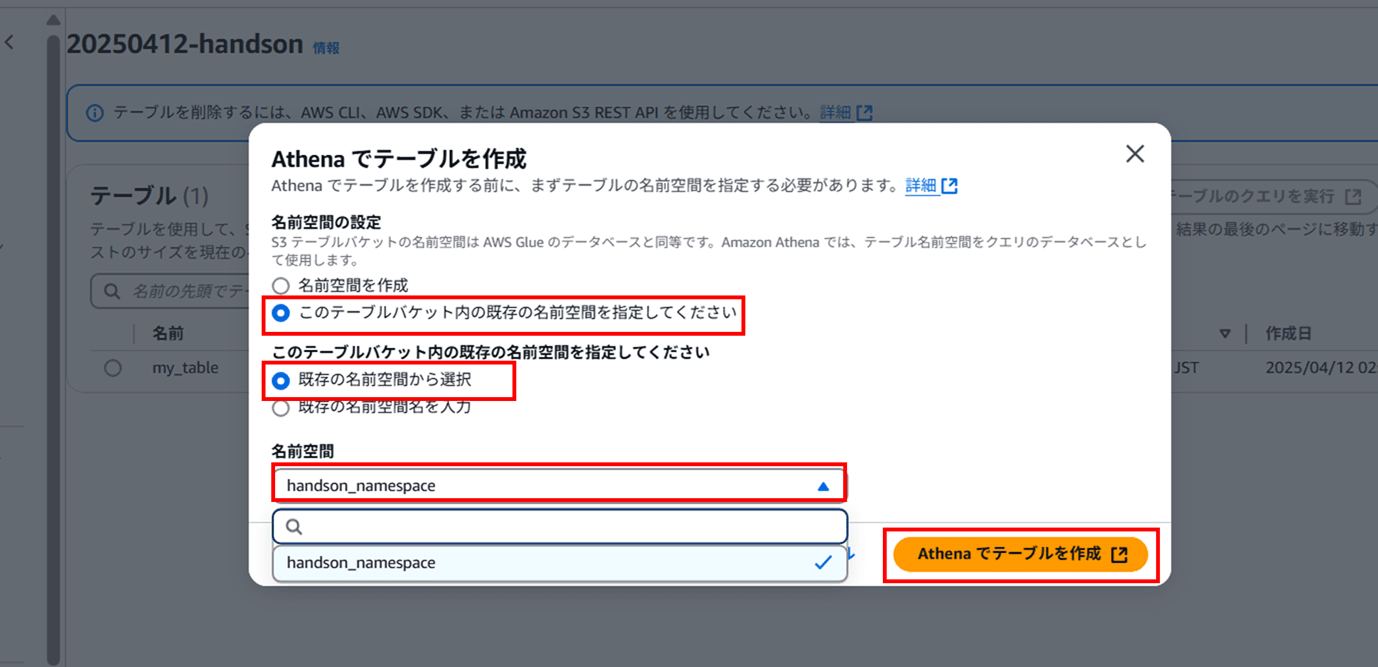
画面遷移すると、このように名前空間の指定を促されます。先ほど CLI で作成した名前空間を指定して 「Athena でテーブルを作成」 をクリックします。
Athena の画面に遷移します。ここで、私は Athena を仕事でよく使うので、ワークグループやデータソースがデフォルトではないものになっていました。以下のように変更します。
- ワークグループ:primary
- データソース:AWSDataCatalog
- カタログ:s3tables/<テーブルバケット名>
- データベース:default
「S3 テーブルを作成」 というクエリが表示されているので、このタブを選択した状態で 「実行」 をクリックします。
すると、以下のようにエラーになりました。
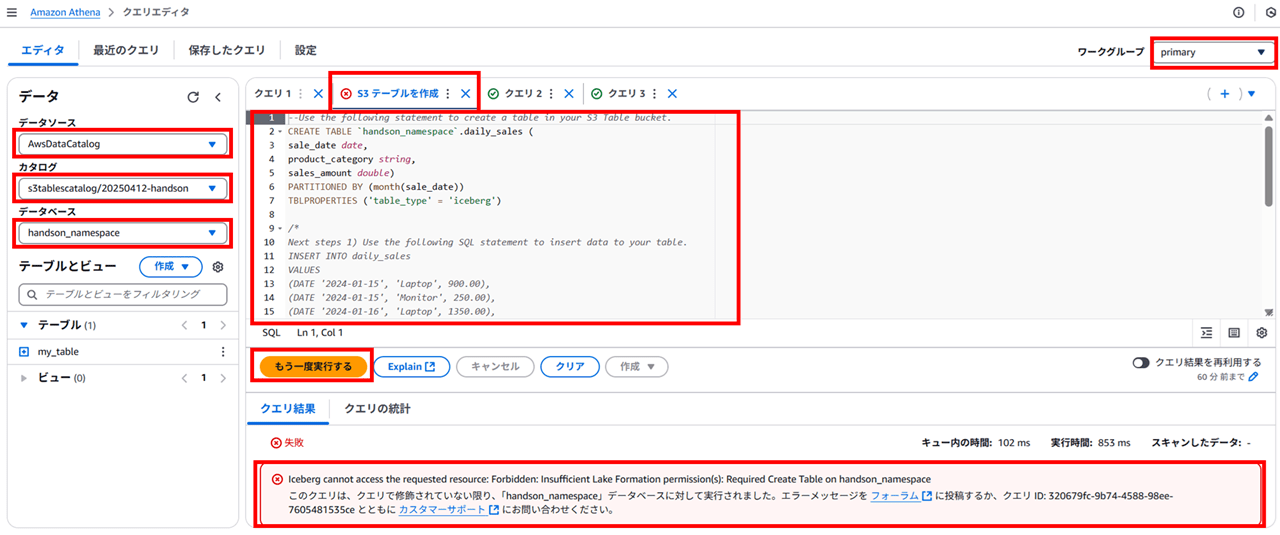
Iceberg cannot access the requested resource: Forbidden: Insufficient Lake Formation permission(s): Required Create Table on handson_namespace
Athena から S3 テーブルの作成をするには、Lake Formation 側から権限の設定が必要です。
ここから Lake Formation での操作は、Athena から S3 テーブルを作成するために必要な権限の設定です。先ほど CLI で作成済みのテーブルへの INSERT や SELECT は実行できたので、早くデータを入れたり SELECT したりしたい方は飛ばして 4. Athena から S3 テーブルへのクエリ発行 へ進んでください。
では、Lake Formation コンソールを開きます。Lake Formation の操作が初めての場合は以下のように権限を付与する旨のダイアログが出ます。
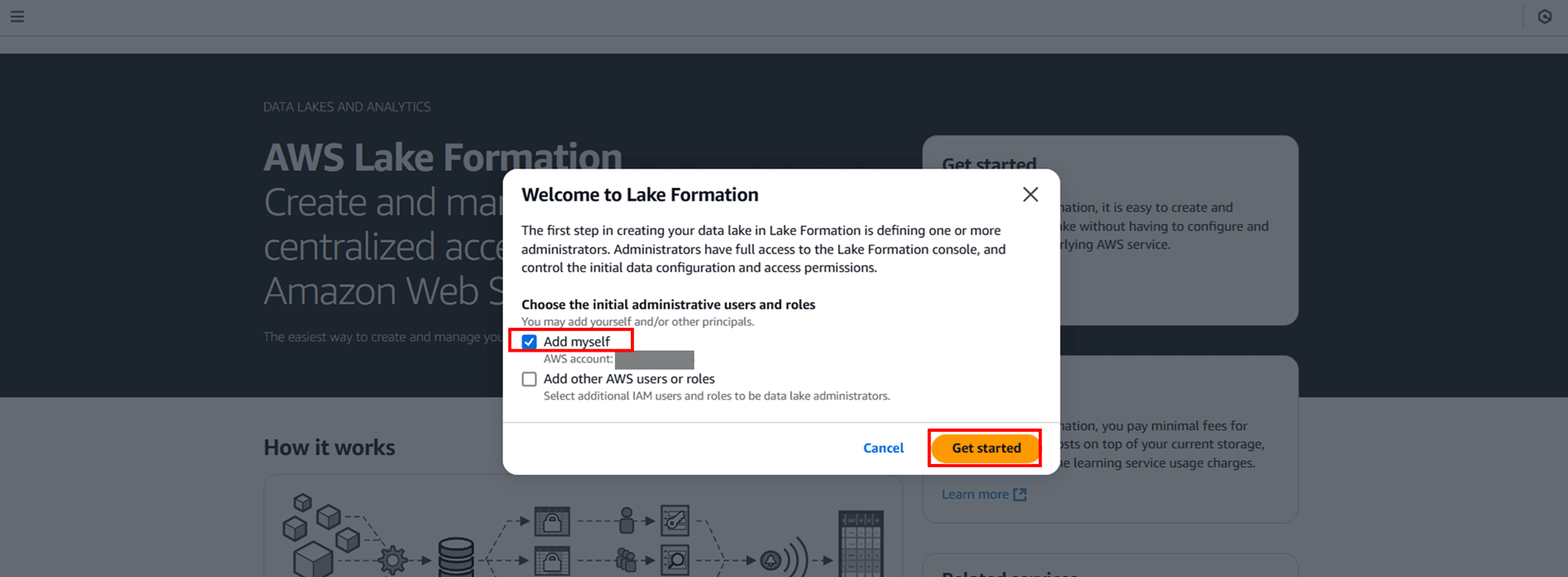
ここでは Lake Formation コンソールへのフルアクセス権を持つ管理者の設定が必要です。
- 「Add myself」(自分自身を追加):現在ログインしているユーザーを管理者として設定
- 「Add other AWS users or roles」(他のAWSユーザーまたはロールを追加):別の IAM ユーザーやロールを管理者として設定
指定された管理者が Lake Formation を通じてデータレイクの管理を開始できるようになります。今回は今ログインしている IAM ロールにこのまま Lake Formation の操作権限を付与しますので、「Add myself」 にチェックして進めます。
以下のように画面が遷移しますので、左上のハンバーガーメニューをクリックしてナビゲーションペインを開きます。
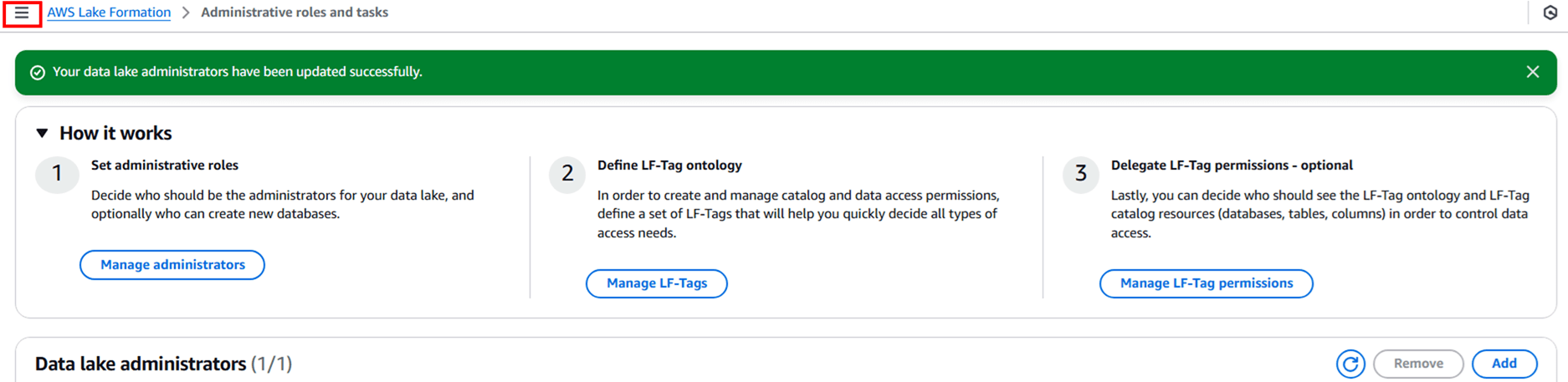
Data Permission を開きます。私は普段 Athena を仕事でよく使うので既に権限がたくさんありますね。
「Grant」 をクリックして権限を作成します。
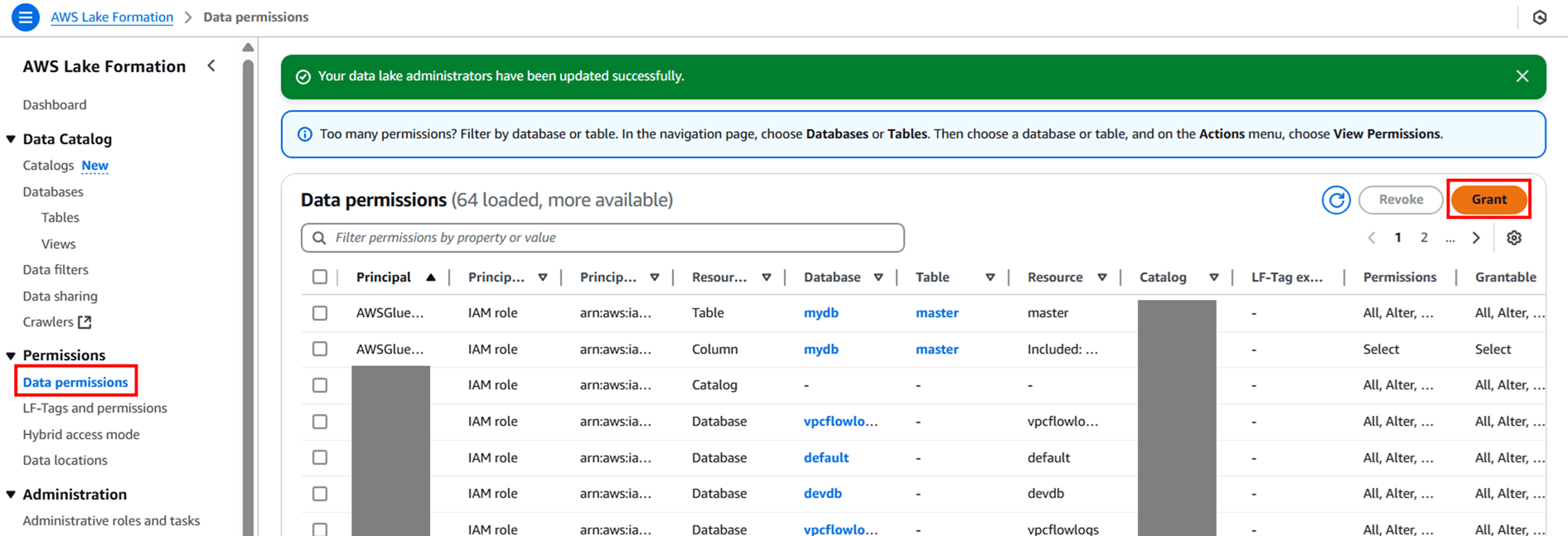
権限を設定していきます。現在ログインしている私の IAM ロールに権限を付与したいので、以下のように設定します。
- Principals:IAM users and roles
- IAM users and roles:<今ログインしている自分の IAM ロール>
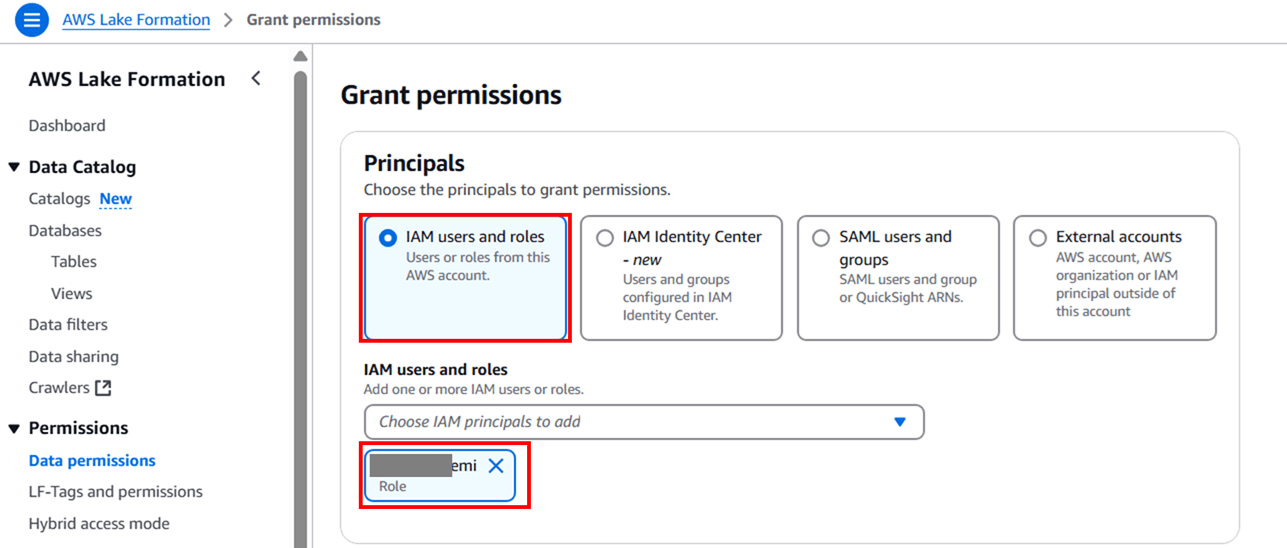
LF-Tags or catalog resources では 「Named Data Catalog Resources」 を選択し、Catalogs では先ほど作成した S3 テーブルバケット名が含まれたカタログを選択します。
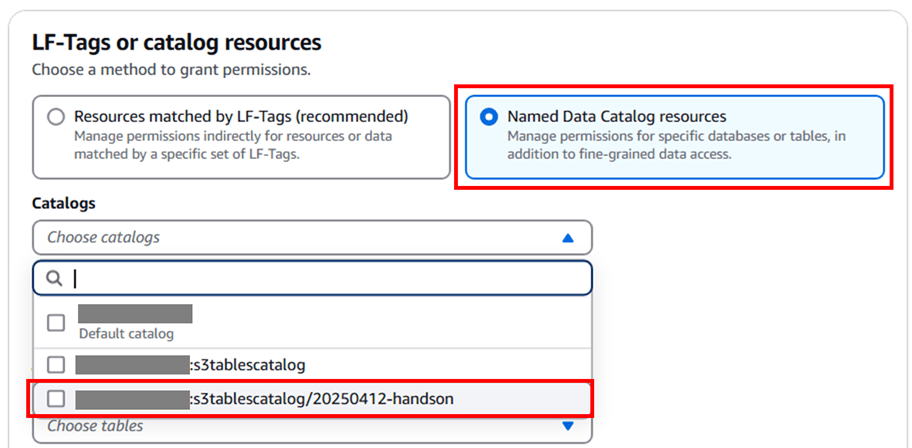
Databases では作成した名前空間(namespace)を選択します。
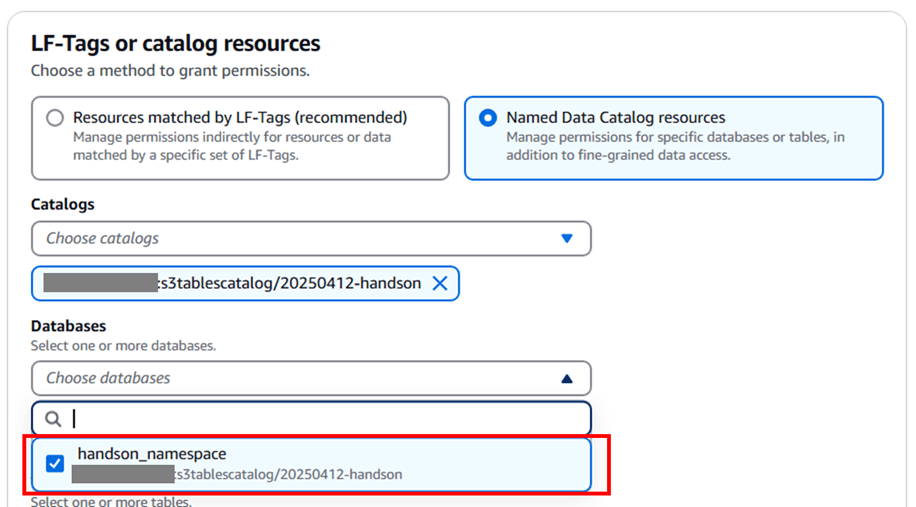
Tables では CLI で作成したテーブルを選択します。
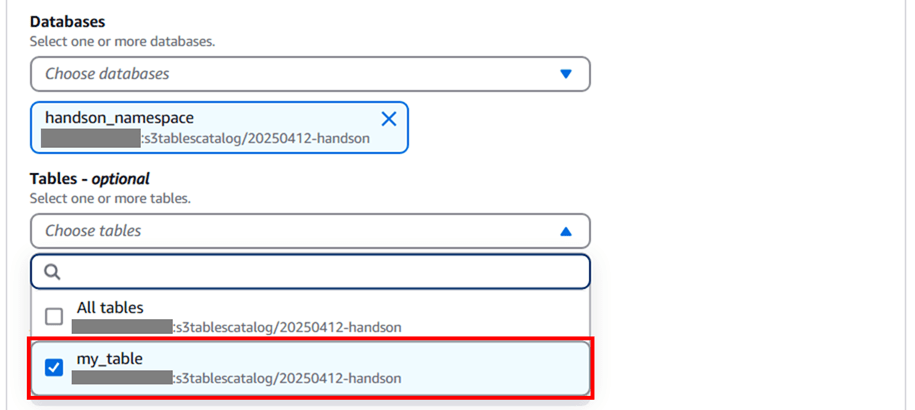
Tables Permissions で Super を選択して 「Grant」 をクリックします。
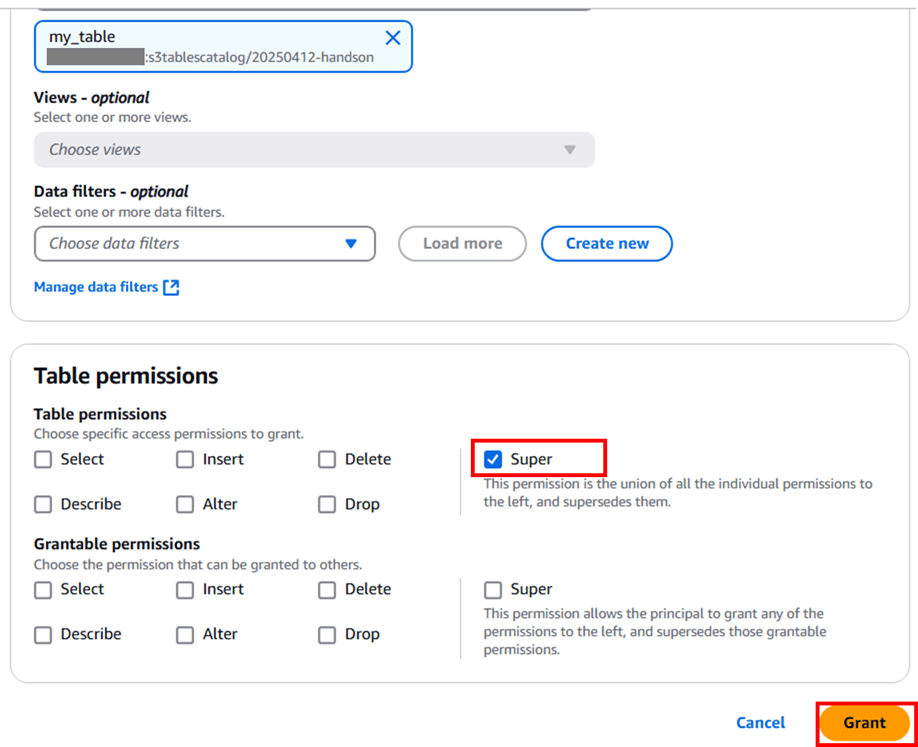
権限付与できました。これで、今ログインしている IAM ロールで Athena 経由のテーブル作成ができるようになりました。
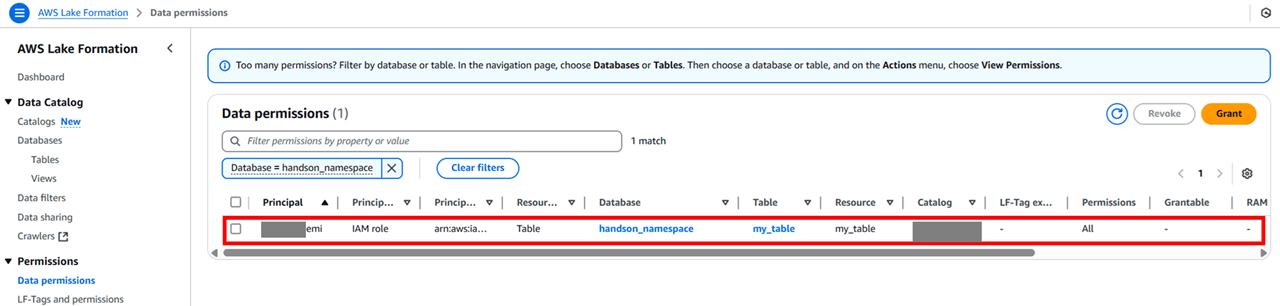
4. Athena から S3 テーブルへのクエリ発行
さて、Athena 画面に戻ります。Athena クエリエディタで以下を確認すると、JSON で設定したスキーマ通りにテーブル(my_table)が構成されているのが分かります。
- ワークグループ:primary
- データソース:AWSDataCatalog
- カタログ:s3tables/<テーブルバケット名>
- データベース:default
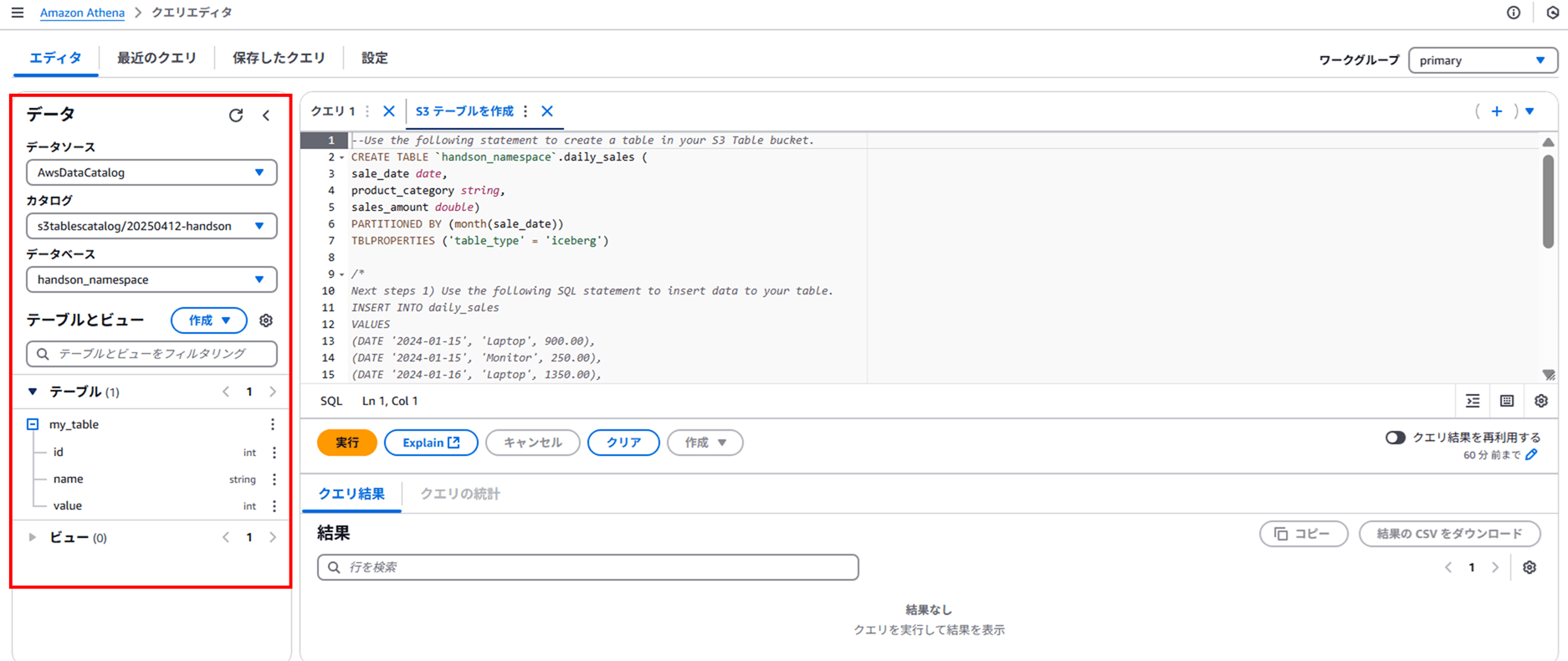
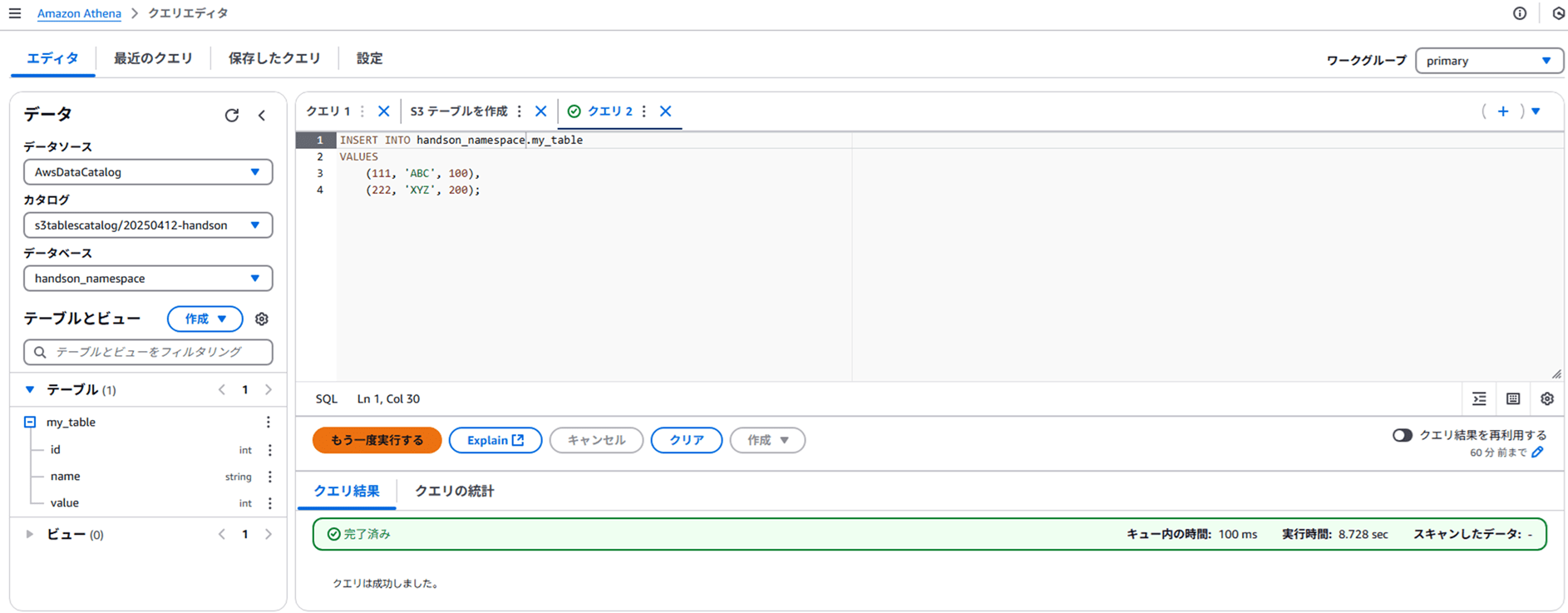
以下のクエリでデータを INSERT します。
INSERT INTO handson_namespace.my_table
VALUES
(111, 'ABC', 100),
(222, 'XYZ', 200);
クエリエディタに上記クエリを入力して実行すると、成功するはずです。
以下 SELECT クエリでテーブルの中身を確認します。
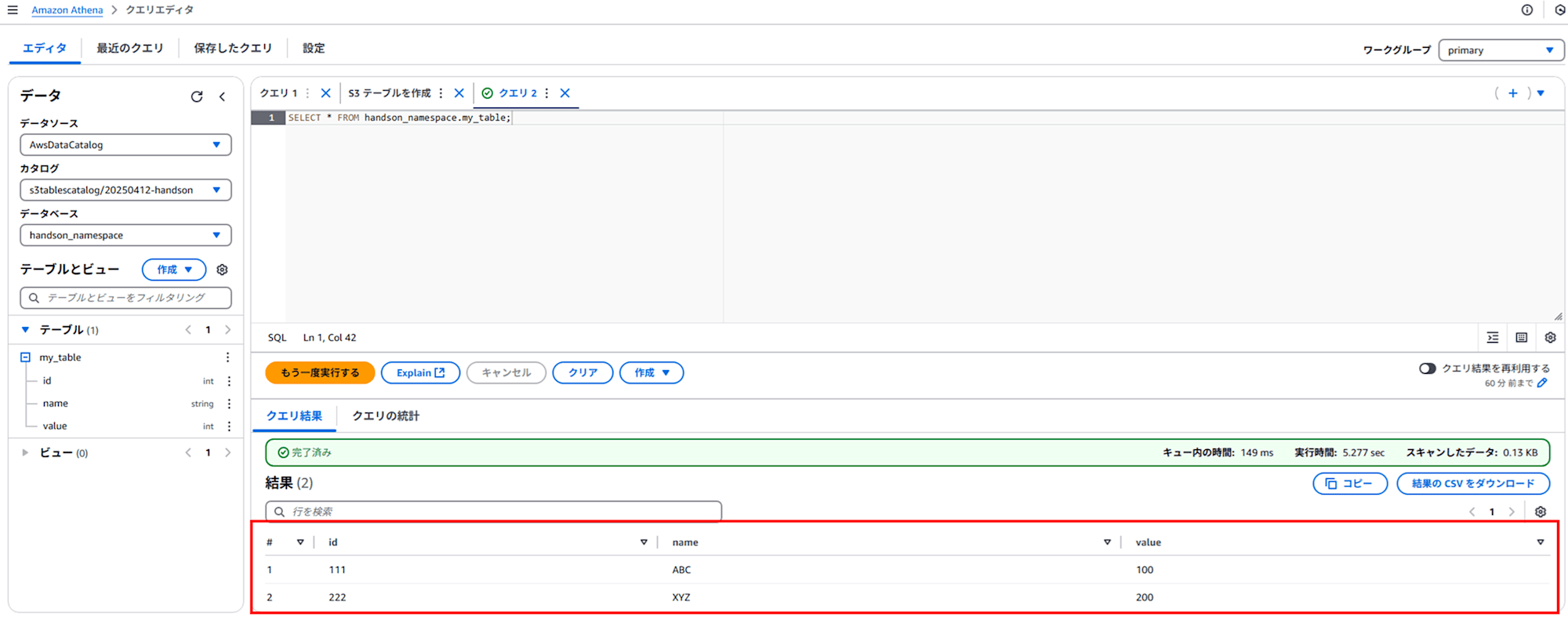
SELECT * FROM handson_namespace.my_table;
INSERT した 2 行が表示されました!
更にもう 2 行 INSERT します。
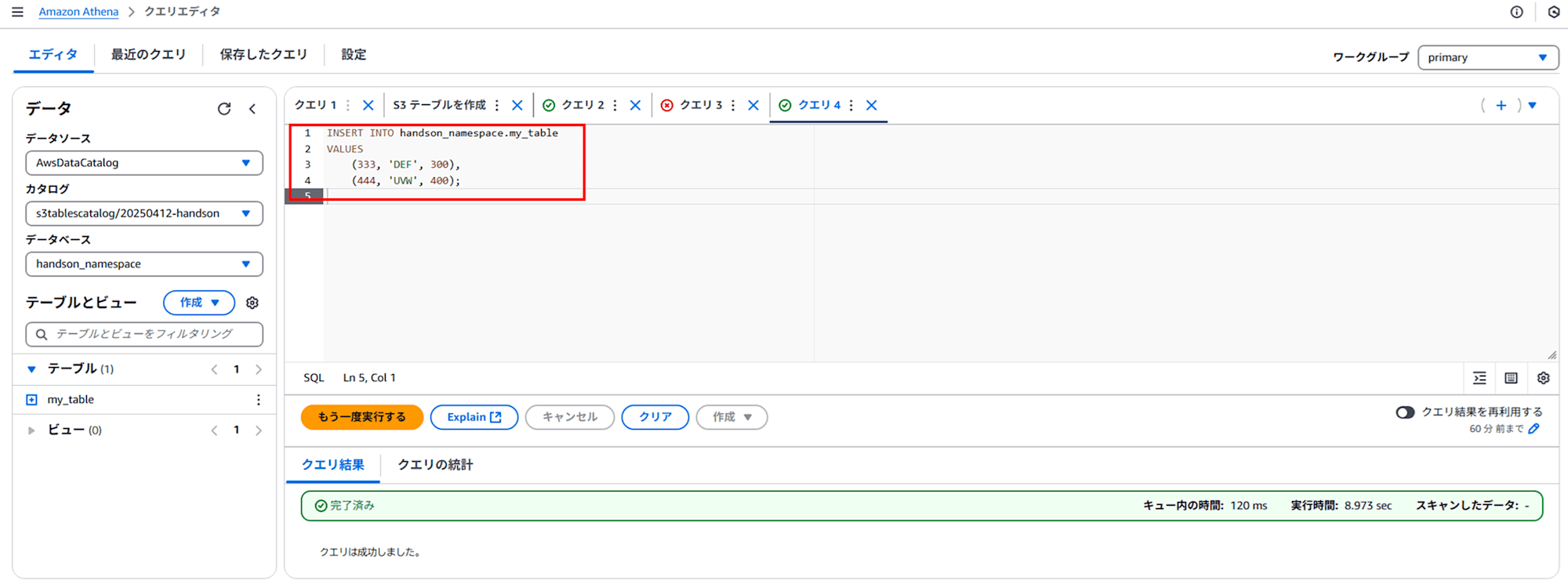
INSERT INTO handson_namespace.my_table
VALUES
(333, 'DEF', 300),
(444, 'UVW', 400);
以下 SELECT クエリでテーブルの中身を確認します。
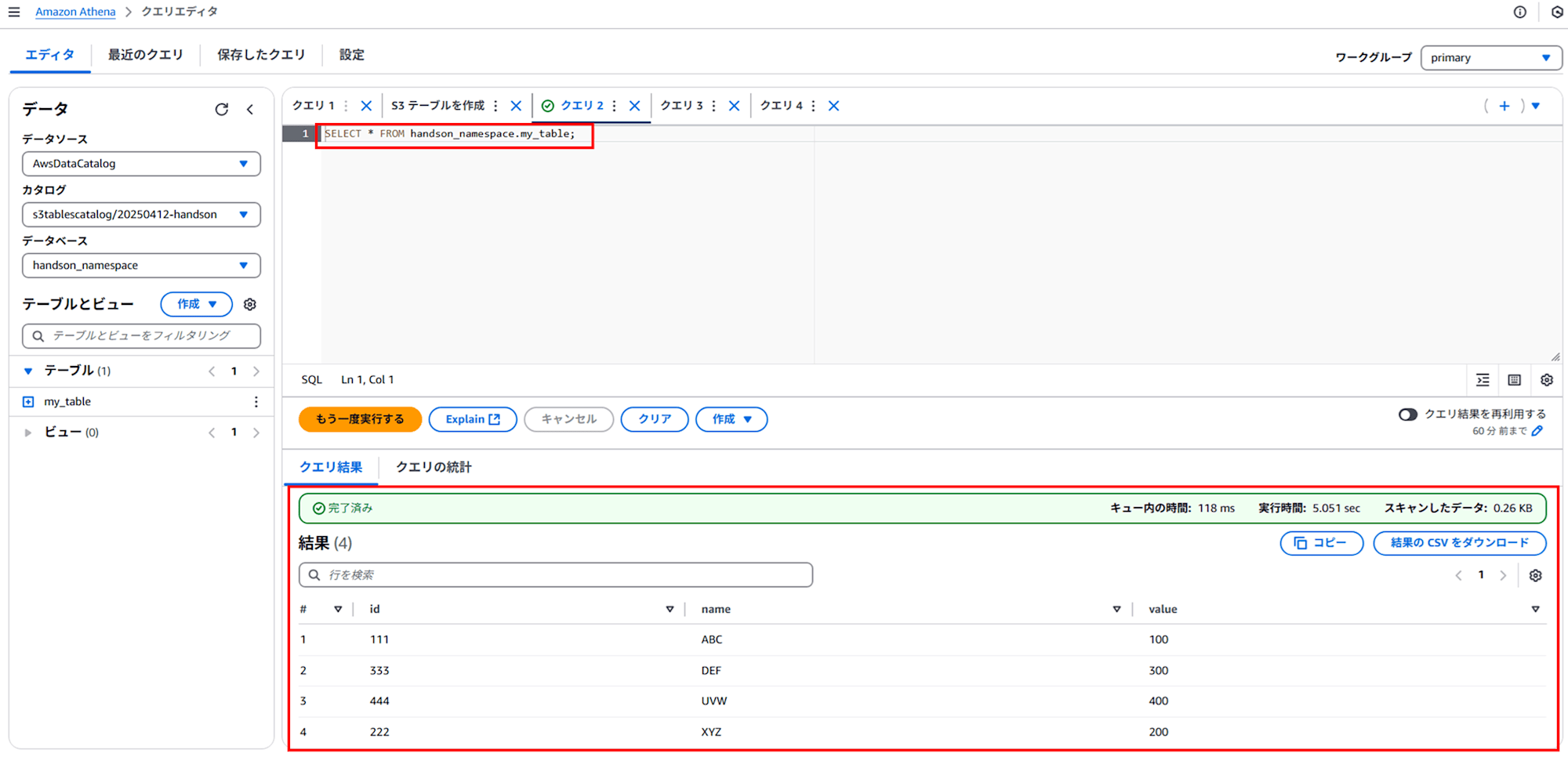
SELECT * FROM handson_namespace.my_table;
INSERT した 4 行が表示されました!
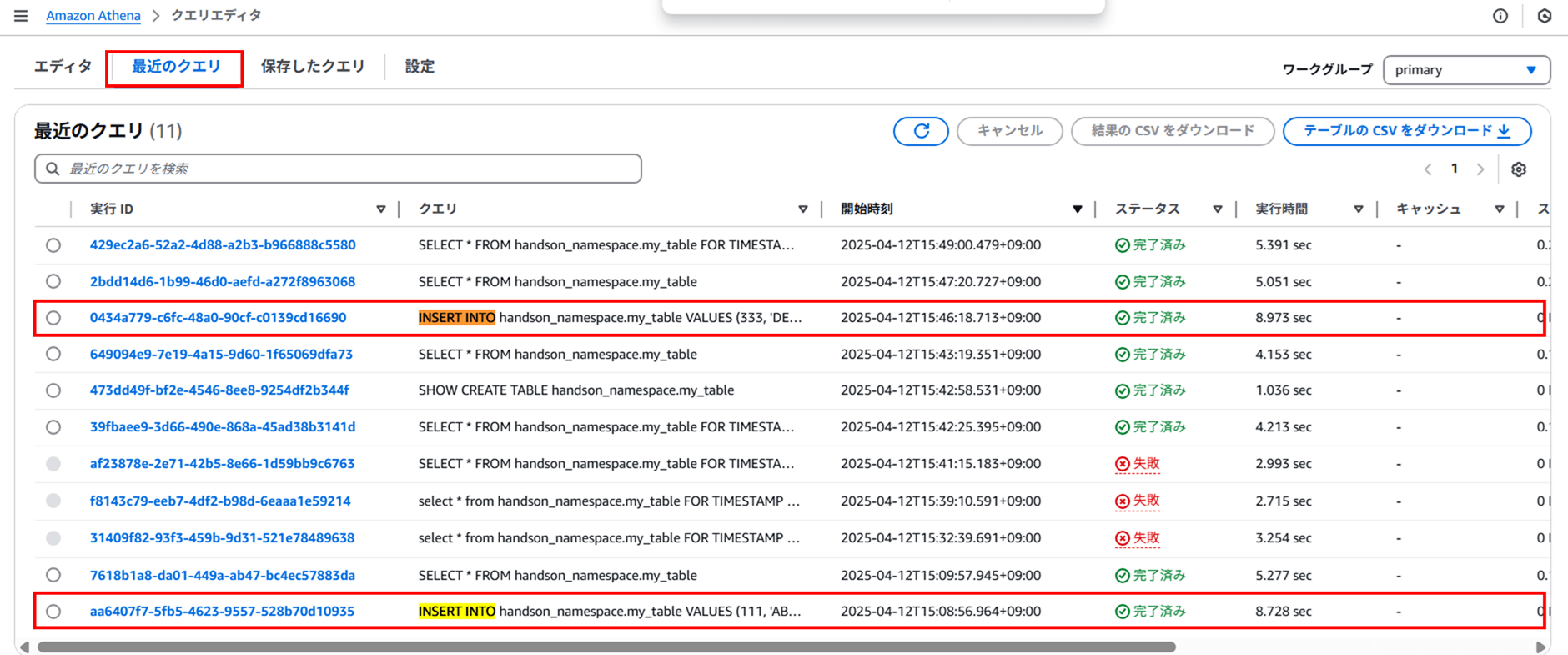
ここでクエリの履歴を確認します。「最近のクエリ」 タブで INSERT した時間を確認します。
ここで表示されているのは日本時間(JST)であることに注意してください。
では、タイムトラベルクエリを試してみます。
-
- 最初の INSERT の時刻:2025-04-12T15:08:56.964+09:00 (UTC:2025-04-12 06:08:56.964)
INSERT INTO handson_namespace.my_table VALUES (111, 'ABC'...)
-
- 2 番目の INSERT の時刻:2025-04-12T15:46:18.713+09:00 (UTC:2025-04-12 06:46:18.713)
INSERT INTO handson_namespace.my_table VALUES (333, 'DEF'...)
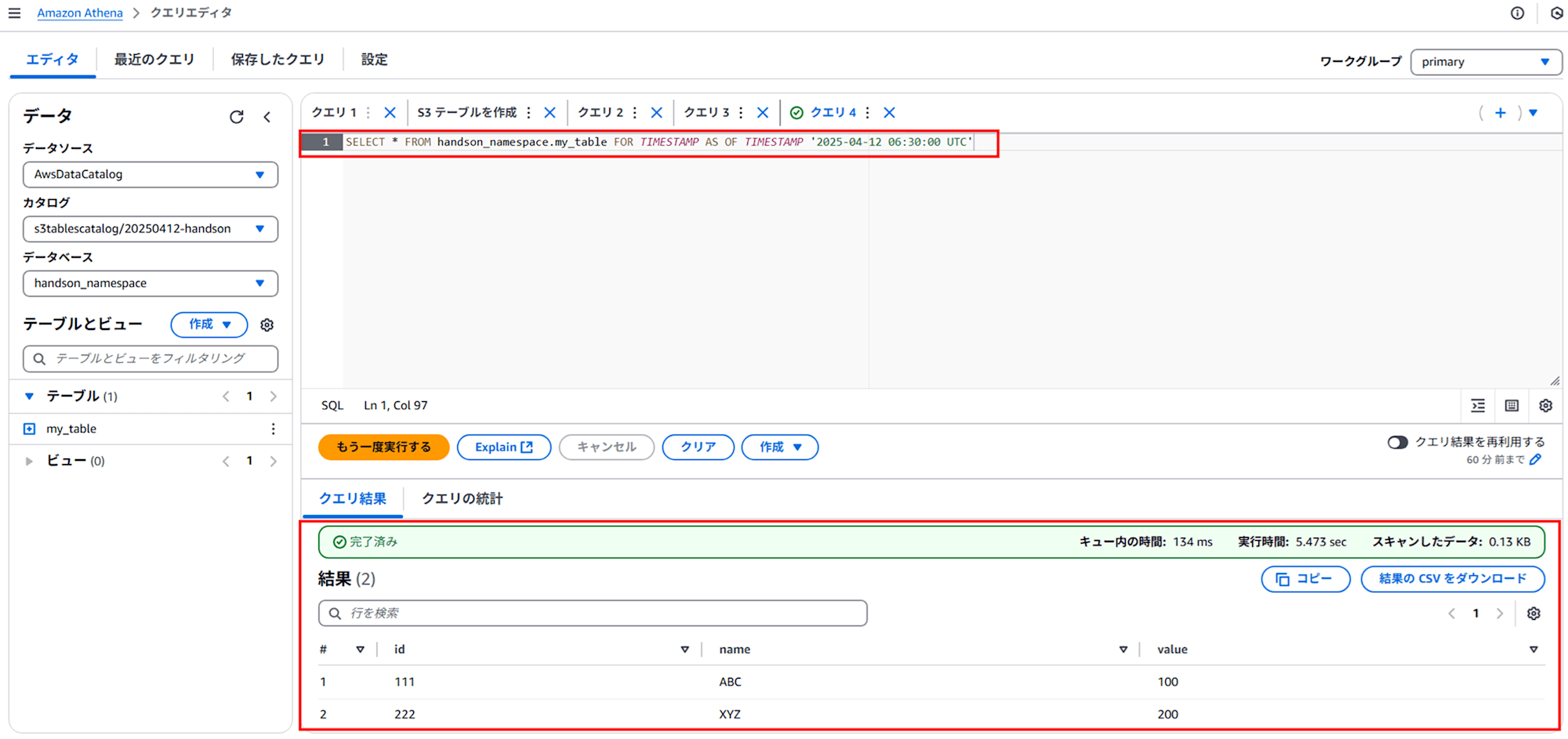
最初の INSERT の後、2番目の INSERT の前のデータを取得するために、以下のタイムトラベルクエリを実行します。1 つめのクエリ(UTC:2025-04-12 06:08)と 2 つめのクエリ(UTC:2025-04-12 06:08)の間の時刻(2025-04-12 06:30:00 UTC)を指定しました。
SELECT * FROM handson_namespace.my_table FOR TIMESTAMP AS OF TIMESTAMP '2025-04-12 06:30:00 UTC'
以下のように、最初に INSERT した 2 行のみの結果が取得できました!
5. 削除
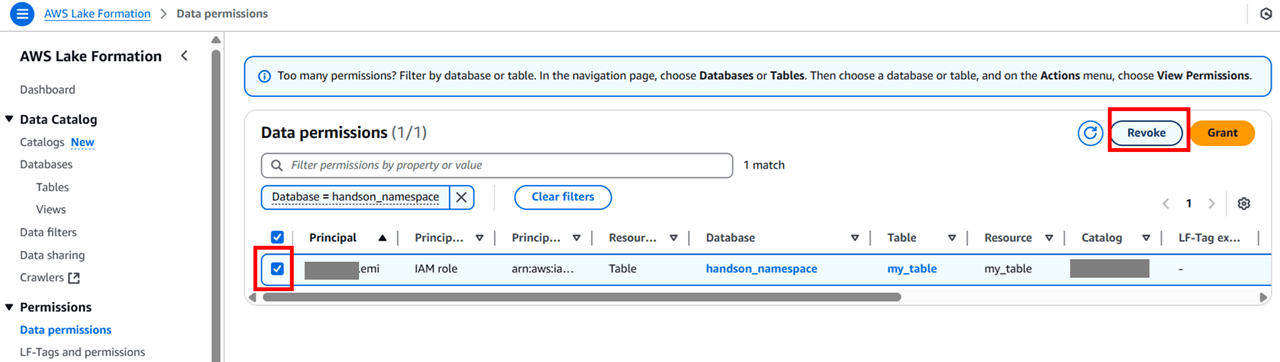
Lake Formation で Grant を削除します。作成した Grant をチェックして 「Revoke」 をクリックしてください。
AWS CLI で、テーブル、名前空間、テーブルバケットの順番に削除します。コンソールからは削除できません。
本ブログの冒頭で記載したように S3 Tables は階層構造になっているため、階層の一番下のテーブルから順番に削除していく必要があります。
delete-table コマンドでテーブルを削除します。
aws s3tables delete-table --table-bucket-arn <bucket arn> --namespace my_namespace --name my_table
▼実行結果
[cloudshell-user@ip-10-134-16-93 ~]$ aws s3tables delete-table --table-bucket-arn arn:aws:s3tables:ap-northeast-1:123456789012:bucket/20250412-handson --namespace handson_namespace --name my_table
[cloudshell-user@ip-10-134-16-93 ~]$
delete-namespace コマンドで名前空間を削除します。
aws s3tables delete-namespace --table-bucket-arn <bucket arn> --namespace my_namespace
▼実行結果
[cloudshell-user@ip-10-134-16-93 ~]$ aws s3tables delete-namespace --table-bucket-arn arn:aws:s3tables:ap-northeast-1:123456789012:bucket/20250412-handson --namespace handson_namespace
[cloudshell-user@ip-10-134-16-93 ~]$
delete-table-bucket コマンドでテーブルバケットを削除します。
aws s3tables delete-table-bucket --region ap-northeast-1 --table-bucket-arn <bucket arn>
▼実行結果
[cloudshell-user@ip-10-134-16-93 ~]$ aws s3tables delete-table-bucket --region ap-northeast-1 --table-bucket-arn arn:aws:s3tables:ap-northeast-1:123456789012:bucket/20250412-handson
[cloudshell-user@ip-10-134-16-93 ~]$
おわりに
S3 Tables の概要はドキュメントで確認していたのですが、ようやく自分で操作することで腹落ちしました。座学パートも分かりやすくて大変勉強になりました。
本記事への質問やご要望については画面下部のお問い合わせ「DevelopersIO について」からご連絡ください。記事に関してお問い合わせいただけます。
参考









