
Azure Blob StorageのデータをGrafanaとDuckDBで可視化してみた
はじめに
こんにちは、コンサルティング部の神野です。
今回は、Azure Blob Storageに保存されたデータを、GrafanaとDuckDBを組み合わせて可視化してみました。最近、DuckDBの人気が高まっていることもあり、気になって検証してみました!
下記記事でS3に対してGrafanaとDuckDBでデータの可視化が実現できることが書いてあったので、全く同じ要領でAzure Blob Storageに対しても可視化できるのでは??と思い実際にやってみました!
構成するシステム
今回構築するもののイメージは以下の通りです。
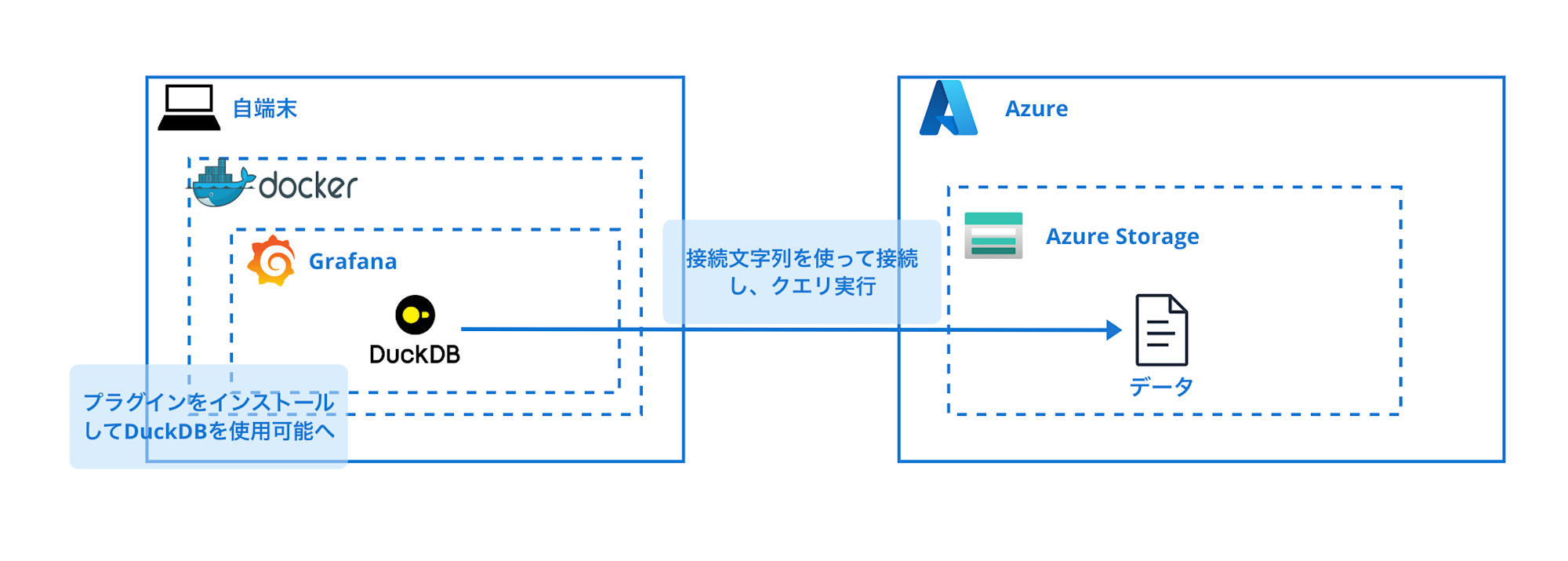
ダミーのセンサーデータを作成してAzure Blob Storageに格納し、そのデータをGrafanaで可視化してみます。
前提条件・環境
今回はコンテナを使用するためDockerを使用します。未インストールの場合はインストールしておきましょう。
使用したソフトウェア
- Grafana: ubuntu-latestイメージ
- motherduck-duckdb-datasource: v0.2.0
- Python: 3.10
- Docker: Docker version 27.1.1-rd, build cdc3063
Azure環境
- Azure Storageアカウントが作成済み
- ストレージアカウントへは接続文字列が利用可能
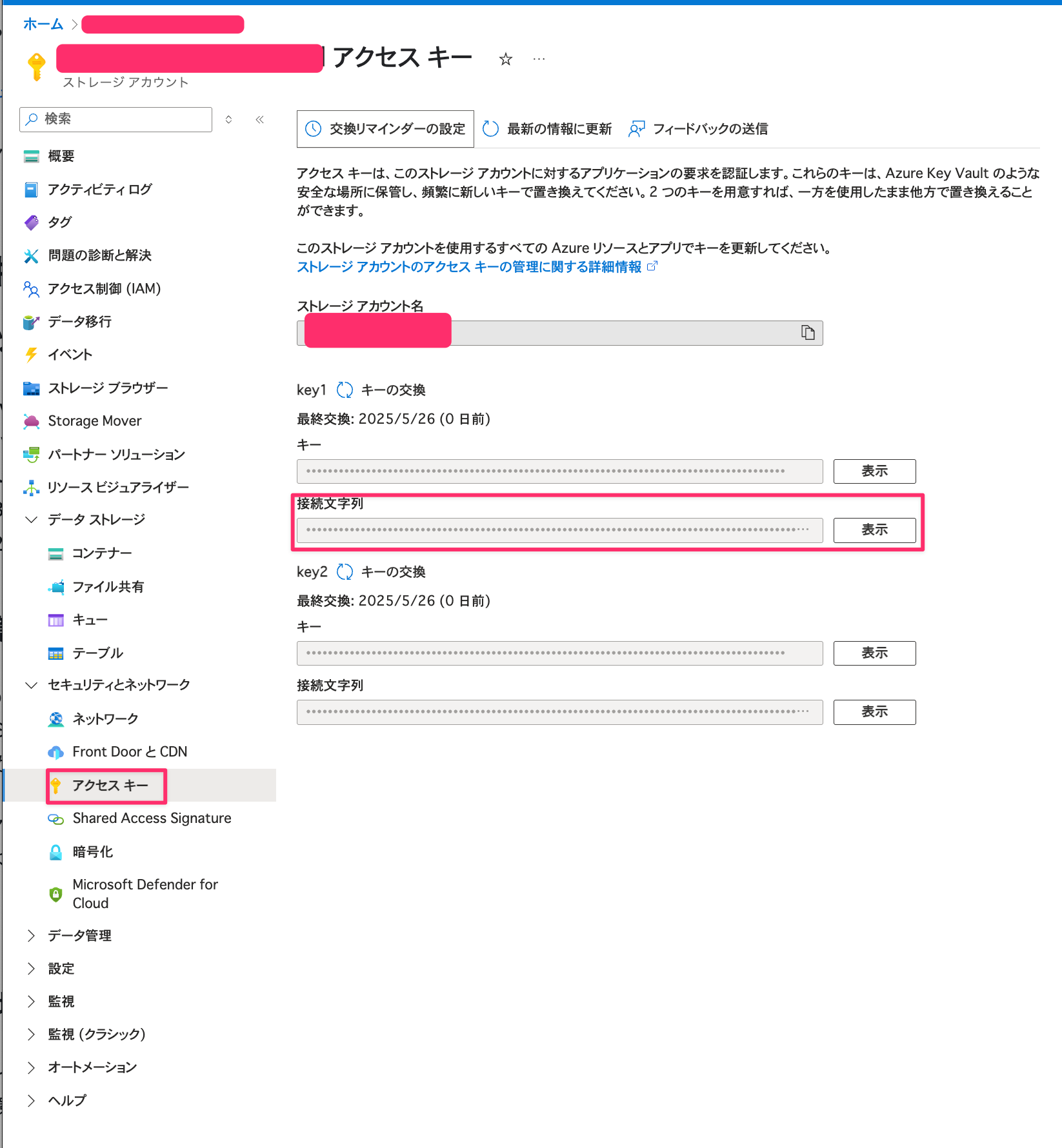
ストレージアカウントへの接続は今回、接続文字列を使用します。
接続文字列は下記のようにストレージアカウントのアクセスキータブを選択して、コピー可能です。
やってみた
サンプルIoTセンサーデータの準備
まず、検証用のセンサーデータを作成しました。実際のセンサーデータの形式を想定して、以下のような構造のCSVデータを生成し、Parquet形式でAzure Blob Storageに保存します。
timestamp,sensor_id,temperature,humidity,location
2024-01-01 00:00:00,SENSOR_001,18.45,75.23,Office_Room_A
2024-01-01 00:10:00,SENSOR_001,17.89,77.84,Office_Room_A
2024-01-01 00:20:00,SENSOR_001,16.23,81.45,Office_Room_A
2024-01-01 00:30:00,SENSOR_001,15.67,83.12,Office_Room_A
2024-01-01 00:40:00,SENSOR_001,14.98,85.78,Office_Room_A
2024-01-01 00:50:00,SENSOR_001,14.23,88.34,Office_Room_A
2024-01-01 01:00:00,SENSOR_001,13.89,89.67,Office_Room_A
2024-01-01 01:10:00,SENSOR_001,13.45,91.23,Office_Room_A
...
2024-01-01 12:00:00,SENSOR_001,28.45,52.34,Office_Room_A
2024-01-01 12:10:00,SENSOR_001,29.12,49.78,Office_Room_A
2024-01-01 12:20:00,SENSOR_001,30.23,46.89,Office_Room_A
...
2024-01-30 23:40:00,SENSOR_001,19.67,73.45,Office_Room_A
2024-01-30 23:50:00,SENSOR_001,18.89,75.12,Office_Room_A
データの特徴
- 期間: 2024年1月1日 00:00:00 ~ 2024年1月30日 23:50:00
- 頻度: 10分間隔でデータ取得(1日あたり144レコード)
- 総レコード数: 4,320件(30日分)
データを作成してAzure Blob Storageに格納する処理のソースコードは下記となります。全体は長いので折りたたんでいます。
ソースコード全体
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
from azure.storage.blob import BlobServiceClient
import os
import argparse
from azure.core.exceptions import AzureError
import tempfile
def setup_azure_client(connection_string=None):
"""
Azure Blob Storageクライアントを安全に設定
"""
try:
if not connection_string:
connection_string = os.getenv('AZURE_STORAGE_CONNECTION_STRING')
if not connection_string:
raise ValueError("Azure Storage接続文字列が設定されていません")
blob_service_client = BlobServiceClient.from_connection_string(connection_string)
# 接続テスト
account_info = blob_service_client.get_account_information()
print(f"Azure Storage接続成功")
print(f"アカウント種別: {account_info.get('account_kind', 'Unknown')}")
return blob_service_client
except AzureError as e:
print(f"Azure接続エラー: {e}")
raise
except Exception as e:
print(f"予期しないエラー: {e}")
raise
def generate_iot_data(start_date, days=30):
"""IoTセンサーデータを生成"""
data = []
current_time = start_date
for i in range(days * 24 * 6): # 10分間隔でデータ取得
# 温度データ(季節変動 + 日内変動 + ノイズ)
temp_base = 20 + 10 * np.sin(2 * np.pi * i / (24 * 6)) # 日内変動
temperature = temp_base + np.random.normal(0, 2)
# 湿度データ(温度と逆相関 + ノイズ)
humidity = 70 - (temperature - 20) * 2 + np.random.normal(0, 5)
humidity = max(10, min(90, humidity)) # 10-90%の範囲
data.append({
'timestamp': current_time,
'sensor_id': 'SENSOR_001',
'temperature': round(temperature, 2),
'humidity': round(humidity, 2),
'location': 'Office_Room_A'
})
current_time += timedelta(minutes=10)
return pd.DataFrame(data)
def upload_to_blob_storage(df, connection_string, container_name, blob_name):
"""Azure Blob Storageにデータをアップロード"""
try:
blob_service_client = setup_azure_client(connection_string)
# コンテナ存在確認
try:
container_client = blob_service_client.get_container_client(container_name)
container_properties = container_client.get_container_properties()
print(f"コンテナ '{container_name}' への接続確認完了")
except Exception as e:
print(f"コンテナアクセスエラー: {e}")
raise
# 一時ファイルに保存してからアップロード
with tempfile.NamedTemporaryFile(suffix='.parquet', delete=False) as temp_file:
df.to_parquet(temp_file.name, index=False, engine='pyarrow')
temp_file_path = temp_file.name
# Blob Storageにアップロード
blob_client = blob_service_client.get_blob_client(
container=container_name,
blob=blob_name
)
with open(temp_file_path, 'rb') as data:
blob_client.upload_blob(data, overwrite=True)
print(f"アップロード完了: {container_name}/{blob_name}")
# 一時ファイル削除
os.unlink(temp_file_path)
except Exception as e:
print(f"Blob Storageアップロードエラー: {e}")
raise
def main():
# コマンドライン引数の設定
parser = argparse.ArgumentParser(description='IoTセンサーデータをAzure Blob Storageにアップロード')
parser.add_argument('--connection-string', '-c',
help='Azure Storage接続文字列')
parser.add_argument('--container', '-n', default='iot-sensor-data',
help='Blob Storageコンテナ名 (デフォルト: iot-sensor-data)')
parser.add_argument('--days', '-d', type=int, default=30,
help='生成するデータの日数 (デフォルト: 30日)')
args = parser.parse_args()
# 設定
CONNECTION_STRING = args.connection_string or os.getenv('AZURE_STORAGE_CONNECTION_STRING')
CONTAINER_NAME = args.container
BLOB_NAME = 'sensor_data_2024_01.parquet'
if not CONNECTION_STRING:
print("エラー: Azure Storage接続文字列が必要です")
print("--connection-string オプションまたは環境変数 AZURE_STORAGE_CONNECTION_STRING を設定してください")
return
print("=== IoTセンサーデータ生成・アップロード ===")
print(f"コンテナ: {CONTAINER_NAME}")
print(f"データ期間: {args.days}日")
print()
# データ生成
start_date = datetime(2024, 1, 1)
df = generate_iot_data(start_date, days=args.days)
# タイムスタンプ型変換
df['timestamp'] = pd.to_datetime(df['timestamp'])
print(f"生成されたデータ: {len(df)} レコード")
print(f"期間: {df['timestamp'].min()} ~ {df['timestamp'].max()}")
print()
# Azure Blob Storageにアップロード
upload_to_blob_storage(df, CONNECTION_STRING, CONTAINER_NAME, BLOB_NAME)
if __name__ == "__main__":
main()
作成できたら、取得した接続文字列を引数に渡してデータを送信を実行します。
python send_data_azure.py --connection-string "<Connection String>"
実行すると下記のようにログが出力されます。
エラーなく完了したら次に進みましょう!
=== IoTセンサーデータ生成・Azure Blob Storageアップロード ===
コンテナ: iot-sensor-data
Blob名: sensor_data_2024_01.parquet
データ期間: 30日
生成されたデータ: 4320 レコード
期間: 2024-01-01 00:00:00 ~ 2024-01-30 23:50:00
認証成功: Azure Storage アカウント
アカウント種別: StorageV2
SKU名: Standard_LRS
コンテナ 'iot-sensor-data' が見つかりません。作成します...
コンテナ 'iot-sensor-data' を作成しました
アップロード完了: https://xxx.blob.core.windows.net/iot-sensor-data/sensor_data_2024_01.parquet
ファイルサイズ: 74,951 bytes
最終更新: 2025-05-25 22:29:10+00:00
DuckDBプラグインのインストール
DuckDBプラグインgrafana-duckdb-datasourceをダウンロードしてインストールの準備を進めていきます。
GitHubのReadmeに導入方法は記載があるので参考にして進めました。
プラグインのダウンロードと準備
まずはReleasesから最新バージョンv0.2.0をダウンロードして解凍しておきます。
# ホスト側でプラグインディレクトリを作成・ダウンロード
mkdir -p ~/grafana-plugins
cd ~/grafana-plugins
# curlでプラグインをダウンロード
curl -L -o motherduck-duckdb-datasource.zip \
https://github.com/motherduckdb/grafana-duckdb-datasource/releases/download/v0.2.0/motherduck-duckdb-datasource-0.2.0.zip
# 展開
unzip motherduck-duckdb-datasource.zip
# ディレクトリ構造確認
ls -la motherduck-duckdb-datasource/
Grafanaコンテナの起動
GrafanaのイメージをPULLして起動します。
起動する際はダウンロードしたプラグインをコンテナにマウントします。
ubuntuでないとプラグインが追加できないので、必ずubuntu版を指定しましょう。
違うものを使用して、プラグインが追加されず若干ハマってしまいました・・・
また未署名のプラグインのため、GF_PLUGINS_ALLOW_LOADING_UNSIGNED_PLUGINSに今回使用するプラグインmotherduck-duckdb-datasourceを記載します。
このパラメータを設定することで未署名であっても、使用することが可能となります。
# イメージをPULL
docker pull grafana/grafana:latest-ubuntu
# Grafanaコンテナを起動(プラグインディレクトリをマウント)
docker run -d \
--name=grafana-azure \
-p 3000:3000 \
-v ~/grafana-plugins/motherduck-duckdb-datasource:/var/lib/grafana/plugins/motherduck-duckdb-datasource \
-e "GF_PLUGINS_ALLOW_LOADING_UNSIGNED_PLUGINS=motherduck-duckdb-datasource" \
grafana/grafana:latest-ubuntu
コンテナが立ち上がったらアクセスしてみます。
Grafanaへのアクセス
# ブラウザで以下にアクセス
http://localhost:3000
初回ログインはadminでログイン可能です。
パスワード変更を求められますので、適切なパスワードを設定してください。
- ユーザー名:
admin - パスワード:
admin
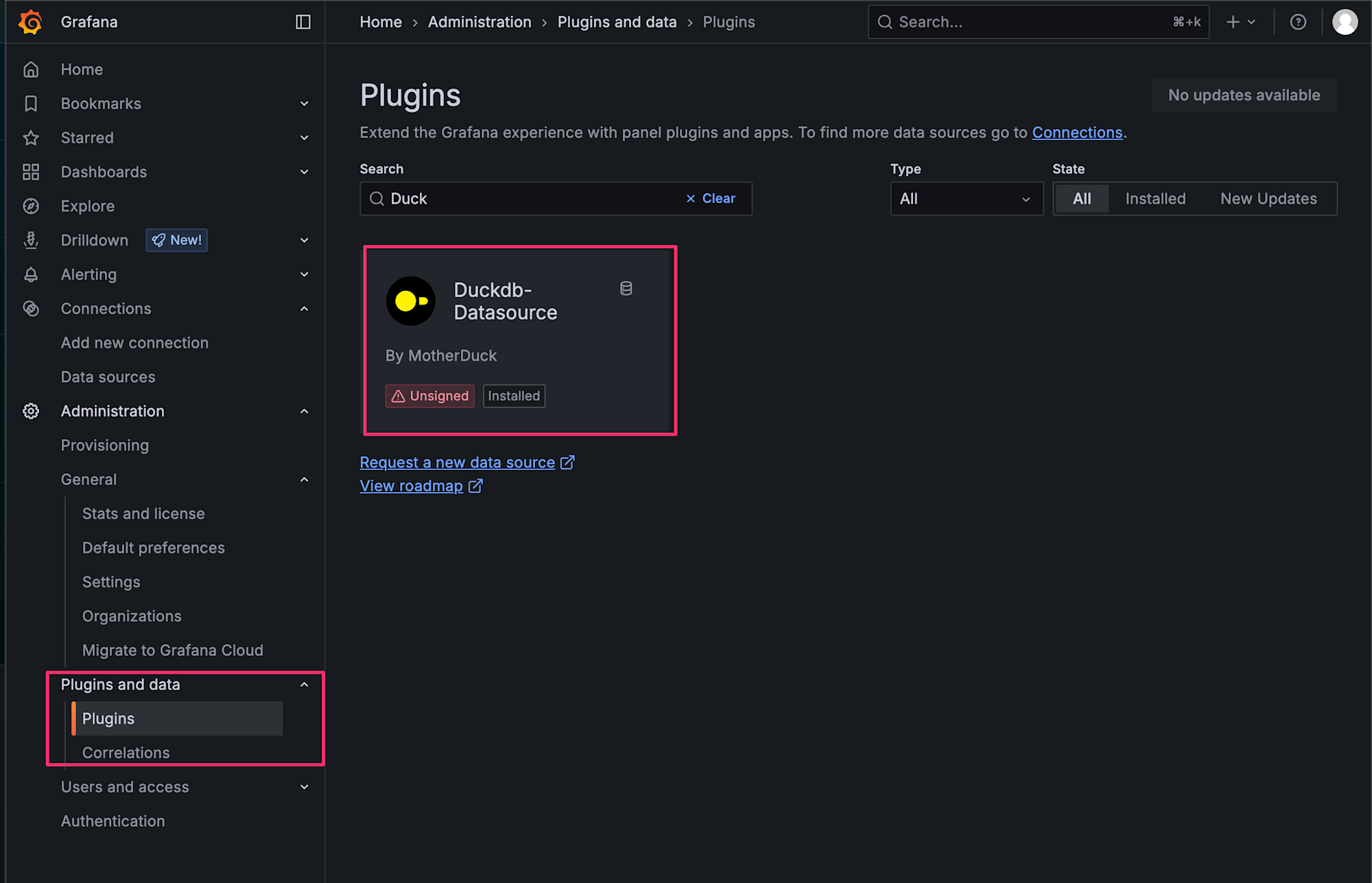
ログイン完了後は、プラグインが追加されているか確認してみます。
左側メニューからAdministration > Pluginsを選択します。
選択した上でDuckとSearchバーに入力して、下記のようにプラグインが表示されれば追加されています!
DuckDBデータソースの設定
続いてGrafanaの管理画面からDuckDBデータソースを追加します。
データソース追加の手順
- 左側メニューから
Connections>Add new connectionを選択 - Searchバーで
Duckと検索し、Duckdb-Datasourceを選択
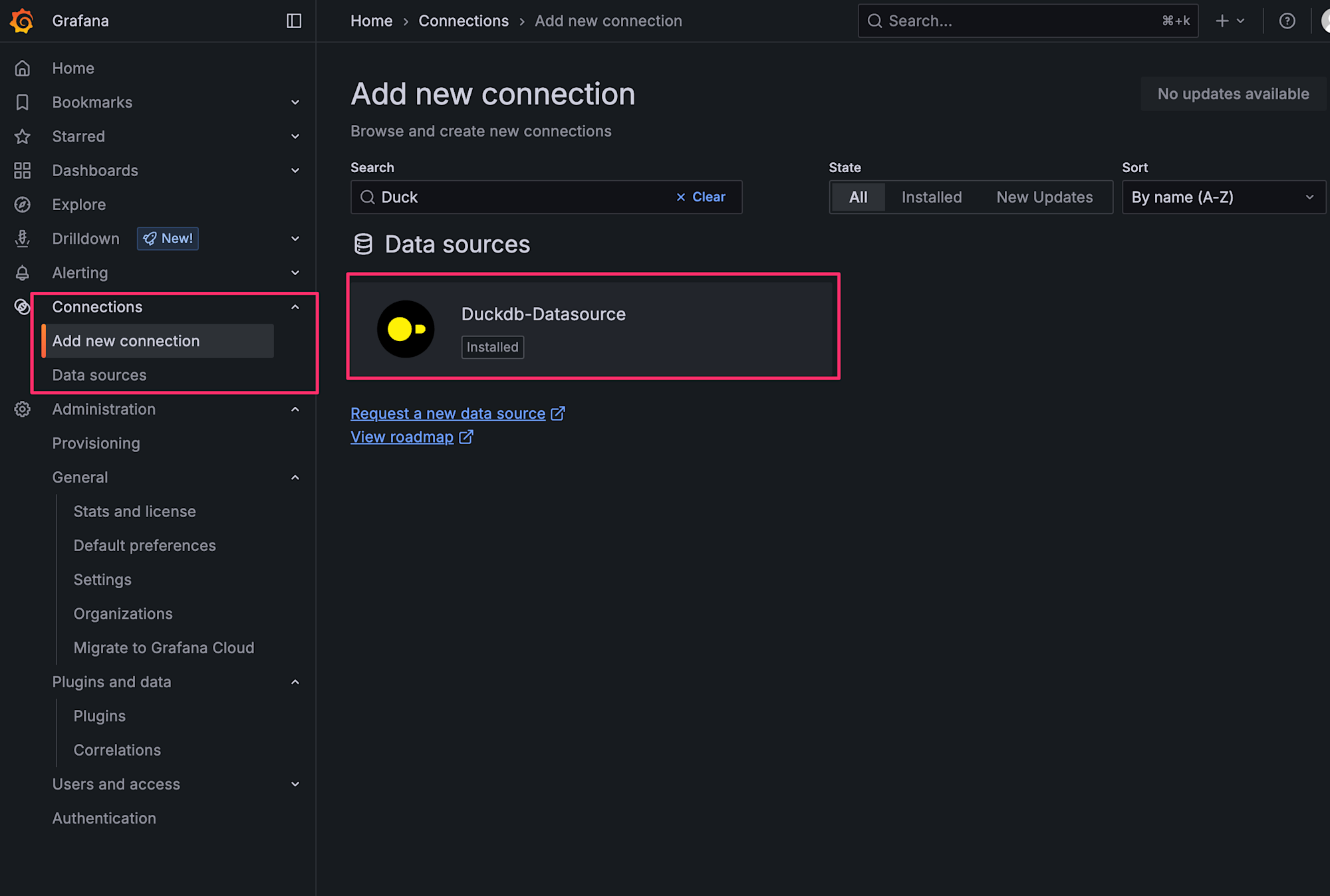
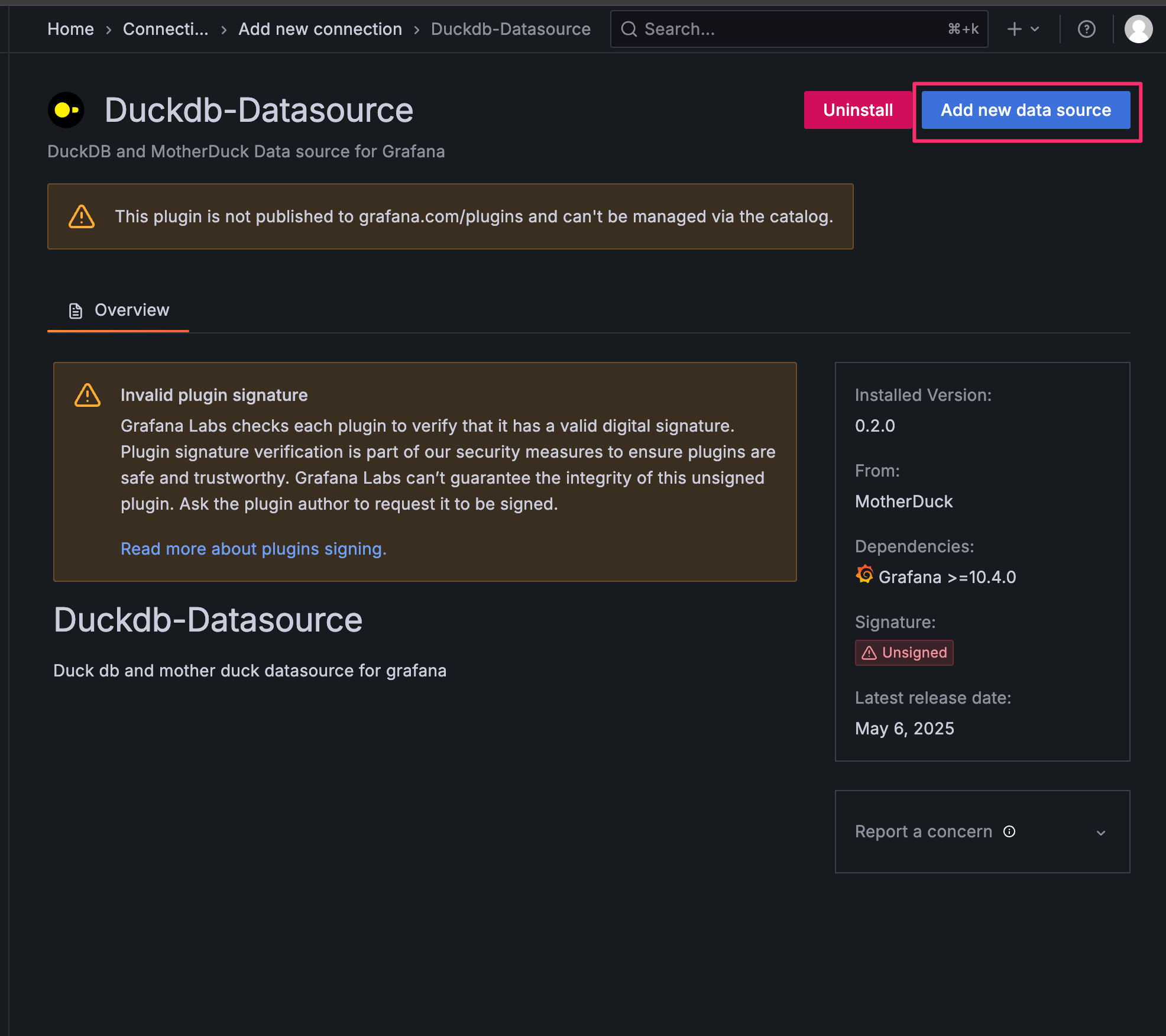
選択後はAdd new data sourceを選択します。
データソース設定項目
以下の設定を入力します。
- Name
Azure DuckDB IoT Data
- Path
- 空白(インメモリモードで使用)
- Init SQL
- Azure Blob Storage接続のための初期設定
- azureモジュールのインストールと接続情報用のシークレットを作成します
- Azure Blob Storage接続のための初期設定
INSTALL azure;
LOAD azure;
CREATE SECRET secret1 (
TYPE azure,
CONNECTION_STRING 'DefaultEndpointsProtocol=xxx'
);
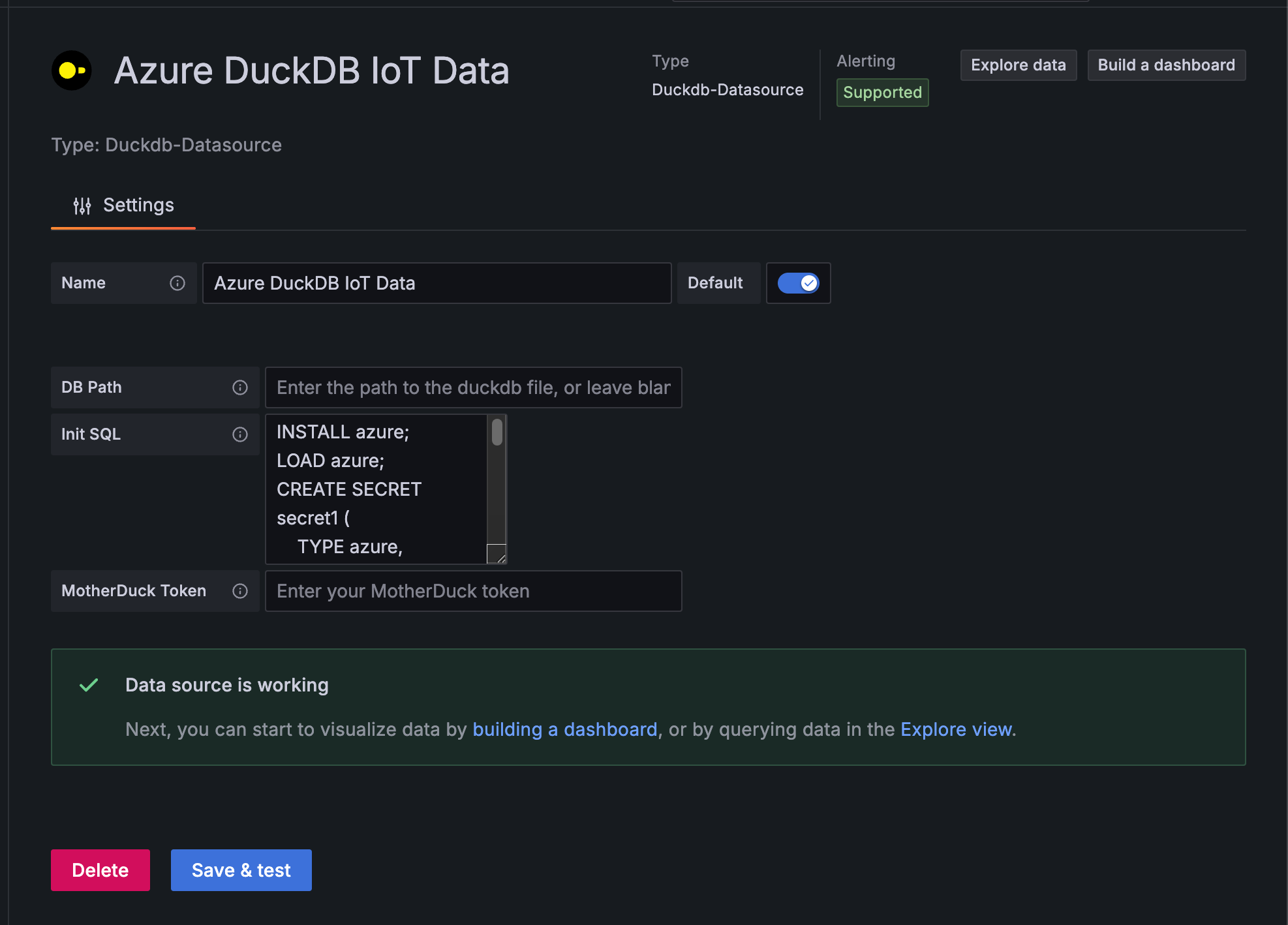
CONNECTION_STRINGには実際のAzure Storageアカウントの接続文字列を入力してください。
Savte & Testを選択して、問題なければ、Explore dataを選択します!
補足1:他の接続方法
補足ですが、接続文字列以外にも接続する方法はあります。
credential_chainを使えば、DefaultAzureCredentialで指定された順序に従って資格情報を試行するチェーンが使用されます。
CREATE SECRET secret (
TYPE azure,
PROVIDER credential_chain,
ACCOUNT_NAME 'storage_account_name'
);
service_principalを使用すればAzureサービスプリンシパルに基づいた、接続も可能です。
CREATE SECRET azure_spn (
TYPE azure,
PROVIDER service_principal,
TENANT_ID 'tenant_id',
CLIENT_ID 'client_id',
CLIENT_SECRET 'client_secret',
ACCOUNT_NAME 'storage_account_name'
);
今回はローカルのコンテナで使用するため、一番シンプルな接続文字列によるやり方を選択しましたが、使用される環境に応じて接続方法はご検討ください。
補足2:S3への接続
さらに補足で全く同じ要領でS3への接続も可能です。
S3に繋ぎたい場合は下記のように記載します。
CREATE SECRET secret (
TYPE S3,
KEY_ID 'AccessKey',
SECRET 'SecretAccessKey',
REGION 'REGION'
);
アクセスキーを使用しないケースだと、credential_chainを使用して、AWS SDKが提供するメカニズムを使用して認証情報を自動的に取得することを可能ですし、プロファイルを読み込んで認証することも可能です。
CREATE secret (
TYPE s3,
PROVIDER credential_chain
);
--プロファイルを指定する場合
CREATE SECRET secret (
TYPE s3,
PROVIDER credential_chain,
CHAIN config,
PROFILE 'my_profile'
);
詳細は下記ドキュメントをご参照ください。
DuckDBでAzure Blob Storageデータの確認
データソースの設定後、まずはExploreで実際にAzure Blob Storage上のデータが読み取れるかを確認します。
データサンプル確認クエリ
データを格納しているBlob Storageに対してクエリを実行してみましょう。
xxxの箇所は自身のAzure Storageアカウント名にしましょう。
SELECT * FROM 'azure://xxx.blob.core.windows.net/iot-sensor-data/sensor_data_2024_01.parquet'
LIMIT 10;
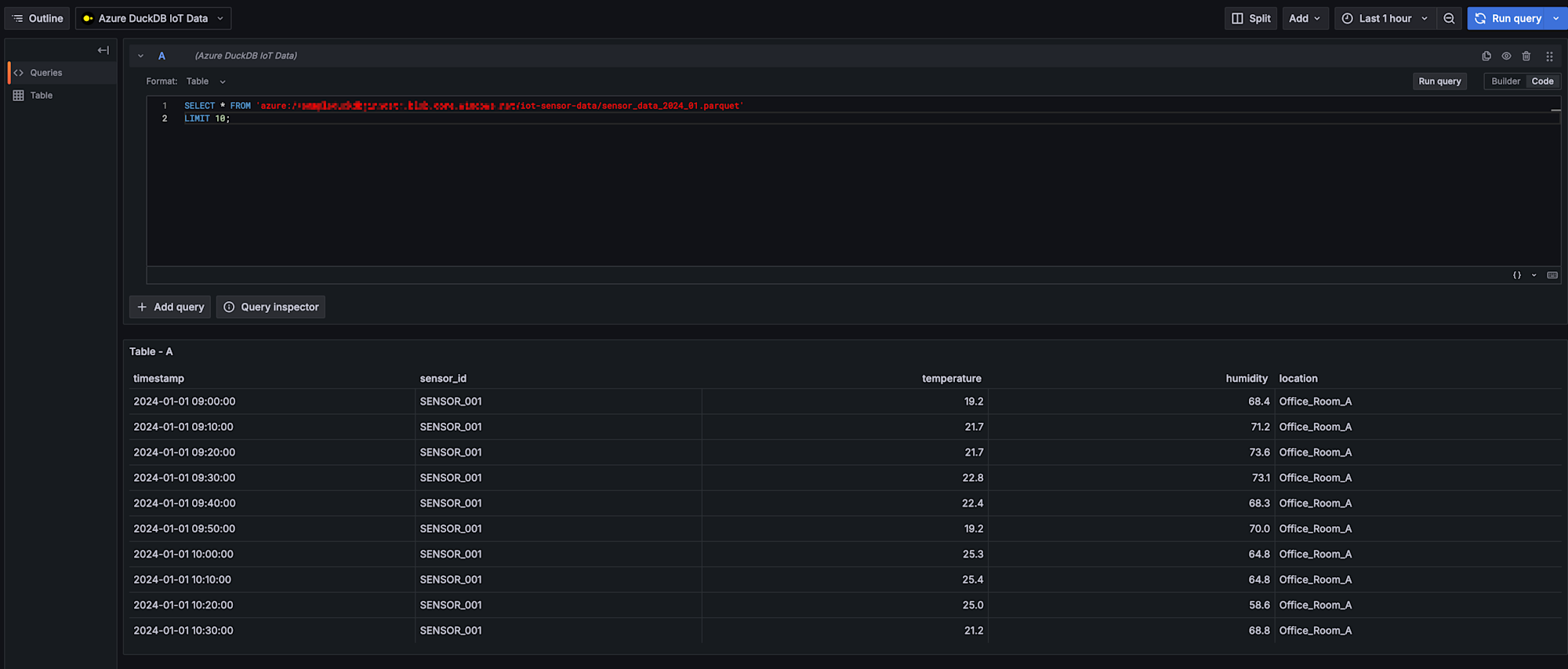
お、問題なくデータは取得できてそうですね!
次はダッシュボード作成をやってみましょう。
ダッシュボードの作成
時系列可視化用のダッシュボードを作成します。左側メニューからDashboards > Create dashboardを選択します。
Add Visualizationを選択します。
温度データの可視化パネル
Codeを選択して、下記SQLをコピーして実行します。
指定したタイムスタンプの期間での温度を表示するクエリとなります。
ダミーデータは2024年1月中の温度データなため、指定するタイムスタンプは1月任意の値とします。
実行クエリ
SELECT
timestamp as time,
temperature as value,
'temperature' as metric
FROM 'azure://sampleduckdbjinnostr.blob.core.windows.net/iot-sensor-data/sensor_data_2024_01.parquet'
WHERE $__timeFilter(timestamp)
ORDER BY timestamp
対象期間設定
2024年1月を対象期間としました。
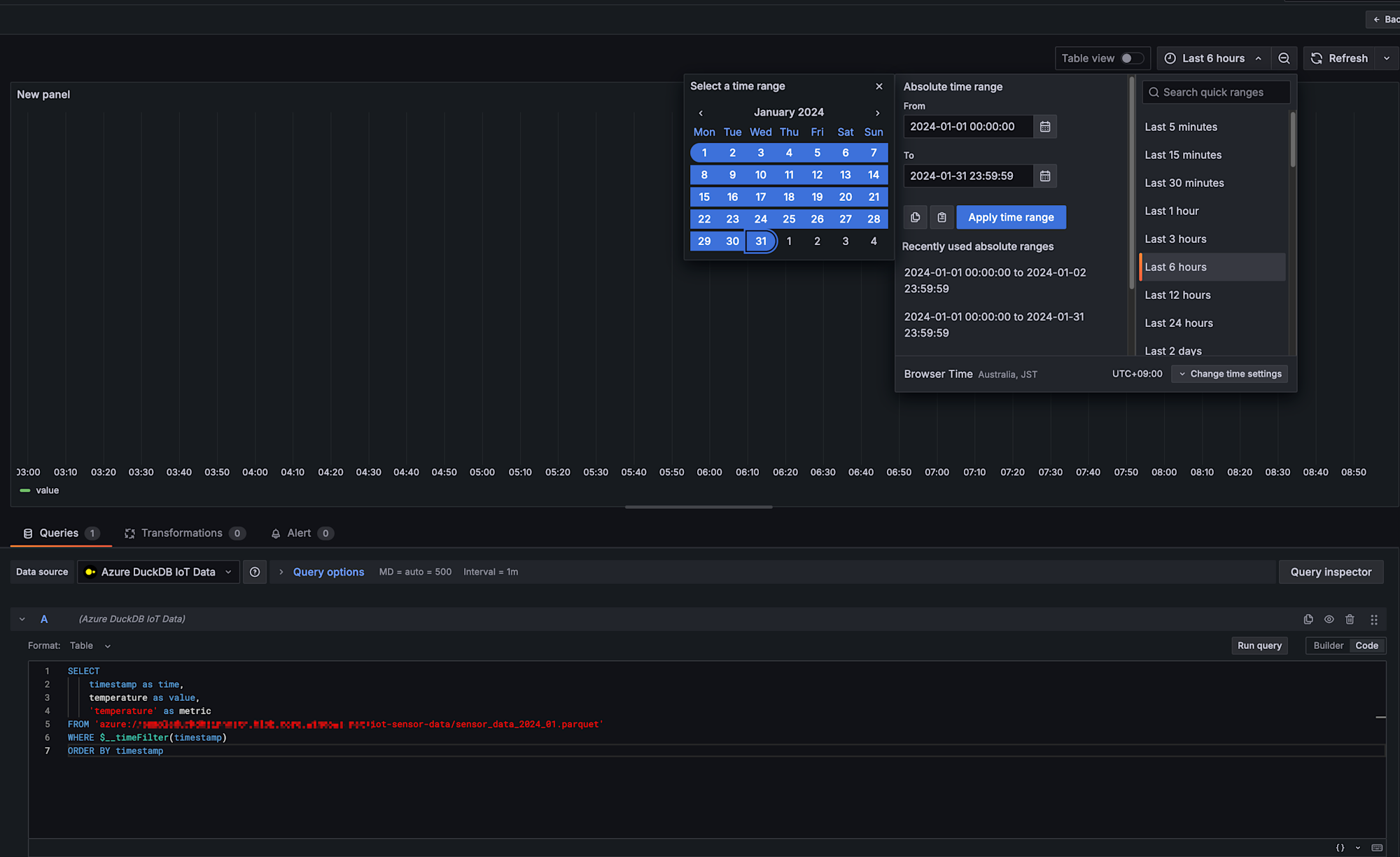
Run queryを選択して、実行してみます。
実行結果
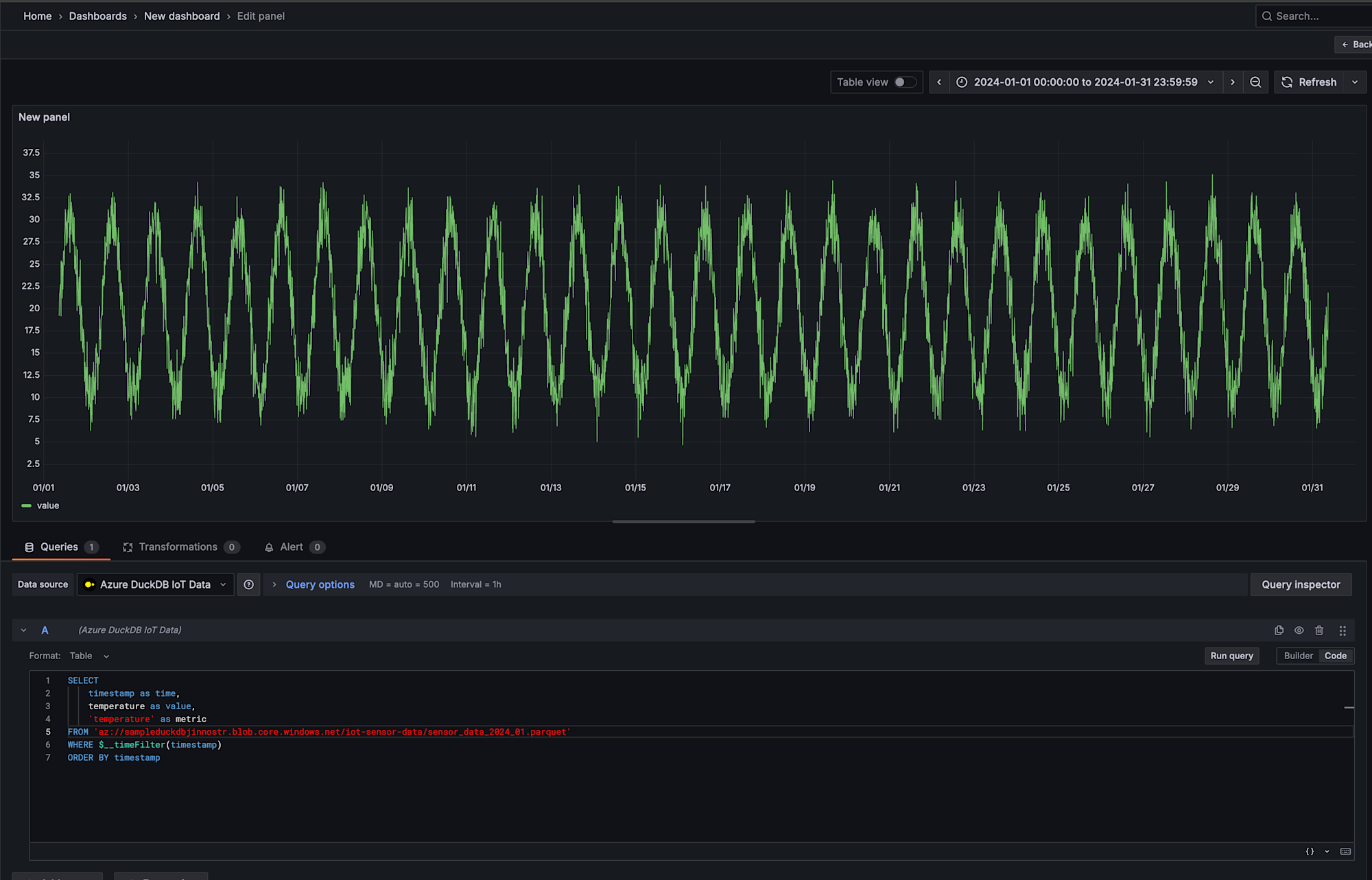
おお、しっかり可視化できましたね!!
今回はシンプルなデータを使って確認してみましたが、色々と活用できそうで良いですね!!
おわりに
今回、GrafanaとDuckDBを組み合わせてAzure Blob Storage上のデータを可視化してみました。Azure Blob Storageでの事例は少なかったため、実際に動作することが確認できて良かったです!
手順もシンプルにプラグインを入れるだけだったので、手軽にローカルで可視化できて良いですね!Azure Blob Storageに格納している各種ログデータの可視化が捗りそうです!
今後は実践的なデータや、よりインフラもローカルではなくクラウドでとなった際の検証を記事にしていこうと思います!
本記事が少しでも参考になりましたら幸いです!最後までご覧いただきありがとうございましたー!!










