![[アップデート] AgentCore Optimization (preview) の Recommendation機能を試してみた](https://images.ctfassets.net/ct0aopd36mqt/7M0d5bjsd0K4Et30cVFvB6/5b2095750cc8bf73f04f63ed0d4b3546/AgentCore2.png?w=3840&fm=webp)
[アップデート] AgentCore Optimization (preview) の Recommendation機能を試してみた
はじめに
コンサルティング部の神野です。
2026年5月、Amazon Bedrock AgentCore に Optimization (preview) という新機能が発表されました!
どんどん新機能が追加されますね。びっくりだ・・・ブログ執筆スピードが追いつかない、嬉しい悲鳴をあげています。
このアップデートは本番で動いているAIエージェントのトレースを分析して、システムプロンプトやツール説明を改善したバージョンを自動で提案してくれる機能です。
エージェントを開発していて「なんか応答品質が安定しないな」「プロンプトをどう直せば良くなるんだろう」と試行錯誤した経験のある方、多いんじゃないでしょうか。私もそうです。これまでは評価結果を見て手作業でプロンプトを書き直して、また評価して……と地道に回していたので、その辺をAIに任せられるような機能みたいです。どんどんAIエージェントを成熟させるための機能が出てきましたね。
今回はこの Optimization の中でも特に手軽な Recommendations をマネジメントコンソールから試してみました。
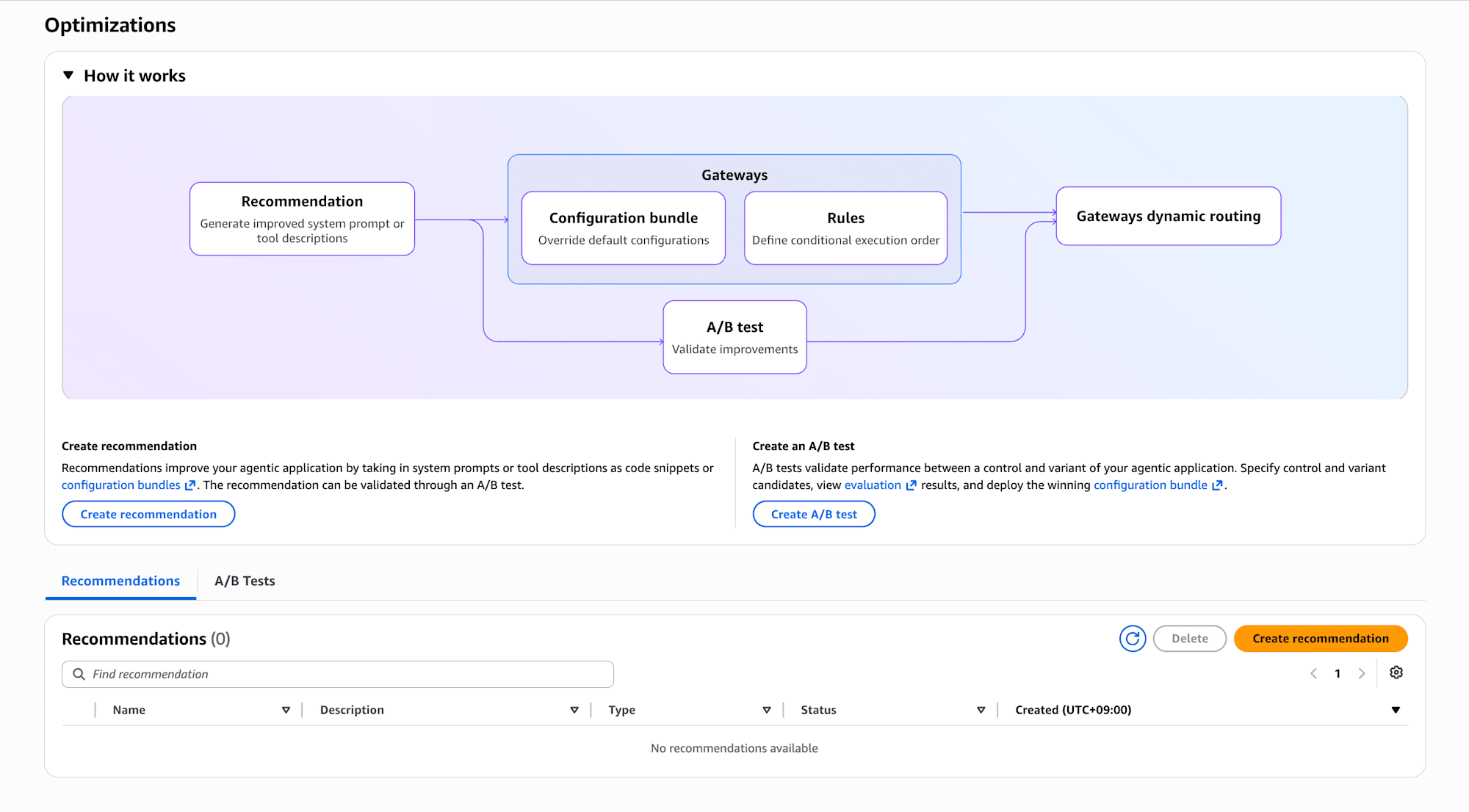
AgentCore Optimization の全体像
公式コンソールの「How it works」がわかりやすいので引用します。
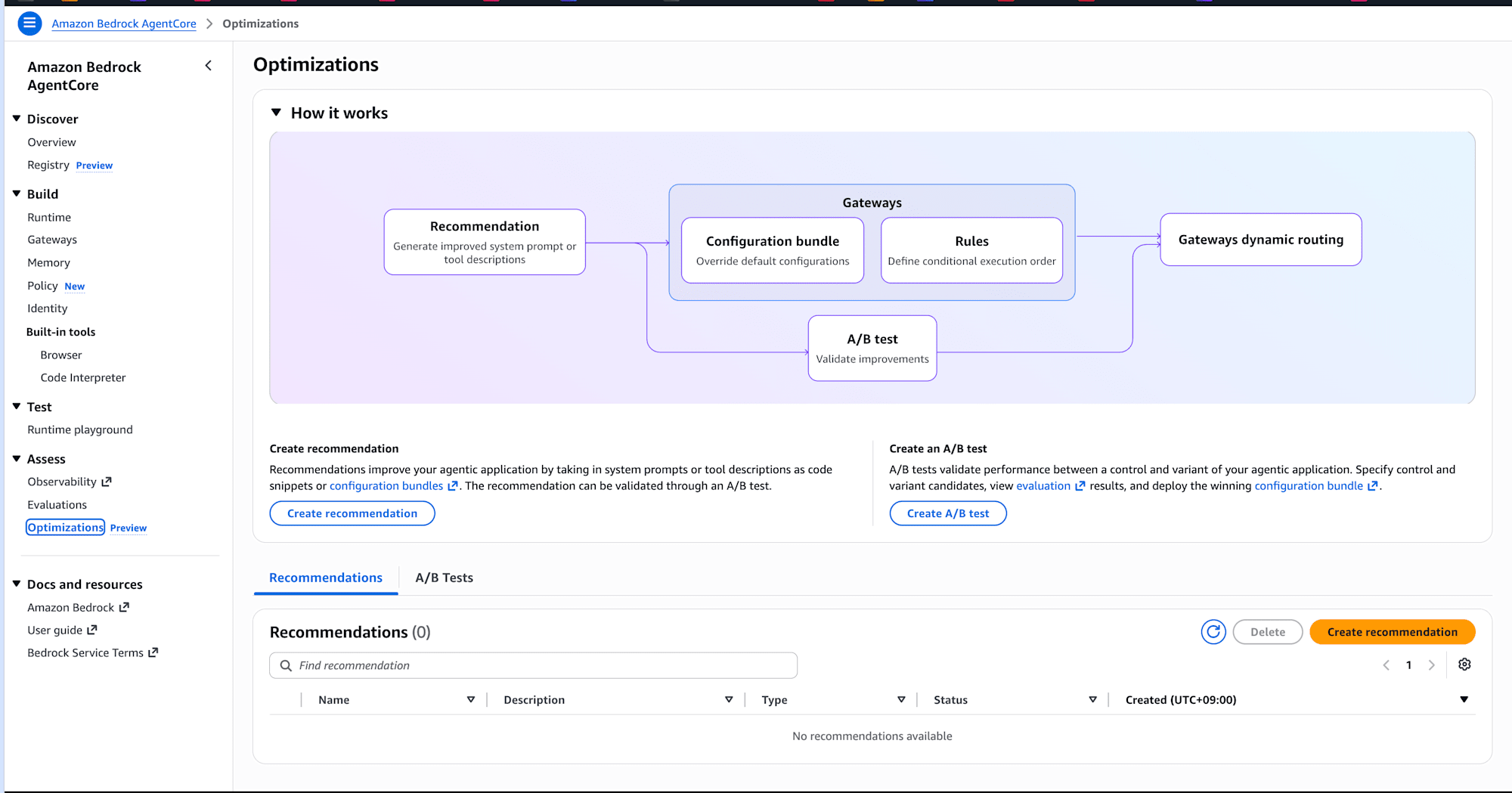
3つのコンポーネントが連携する仕組みです。
| コンポーネント | 役割 |
|---|---|
| Recommendation | エージェントのトレースから改善されたシステムプロンプトやツール説明を生成する |
| Configuration bundle | 改善された設定をバージョン管理されたスナップショットとしてパッケージング |
| A/B test | 元の設定 (Control) と改善版 (Treatment) でゲートウェイのトラフィックを分割し、統計的有意性を見ながら検証 |
公式ドキュメントの How it works から、Recommendation の挙動について引用しておきます。
Point the Recommendations API at agent traces in CloudWatch Logs and specify the evaluator you want to optimize for. The service analyzes failure patterns and returns an optimized system prompt or set of tool descriptions, along with an explanation of what changed and why.
Recommendation は CloudWatch Logs に溜まったトレースを直接インプットにして、指定したevaluatorをもとに失敗パターンを分析し、改善案を「変更内容と理由」とともに返してくれる、というのが正式な定義です。実際にエージェントを再実行して試すわけではない点がポイントですね。
実トラフィックを使って検証するのは次の A/B test の役割です。
Split production traffic between the current agent (control) and the improved version (treatment) through AgentCore Gateway. Online evaluation scores each session and reports results with statistical significance.
要点は、評価結果を見るだけでなく次にどう改善すればよいかまでAgentCoreが踏み込んでくれるようになった、ということですね。
今回はRecommendation だけを試します。
前提
- AgentCore Runtime にエージェントがデプロイされていて、Observability が有効になっていること
- CloudWatch Transaction Search が有効化されていて、トレースが取り込まれていること
- AgentCore Evaluations が利用できるリージョンであること
リージョンについては、Evaluationsと同じとWhat's New 記事に下記の記載があります。
You can use optimization capabilities in all AWS Regions where AgentCore Evaluations is available.
今回は us-east-1 で進めます。
検証用エージェントを Quick create harness でサクッと用意する
検証ターゲットのエージェントは、AgentCoreの Managed Harness (preview) を使ってマネジメントコンソールからサクッと作ります。
AgentCore コンソールの左メニュー Build > Runtime の中に Harness セクションがあります。右上の Quick create harness を押すと、すぐに使える状態でAIエージェントが出来上がります。
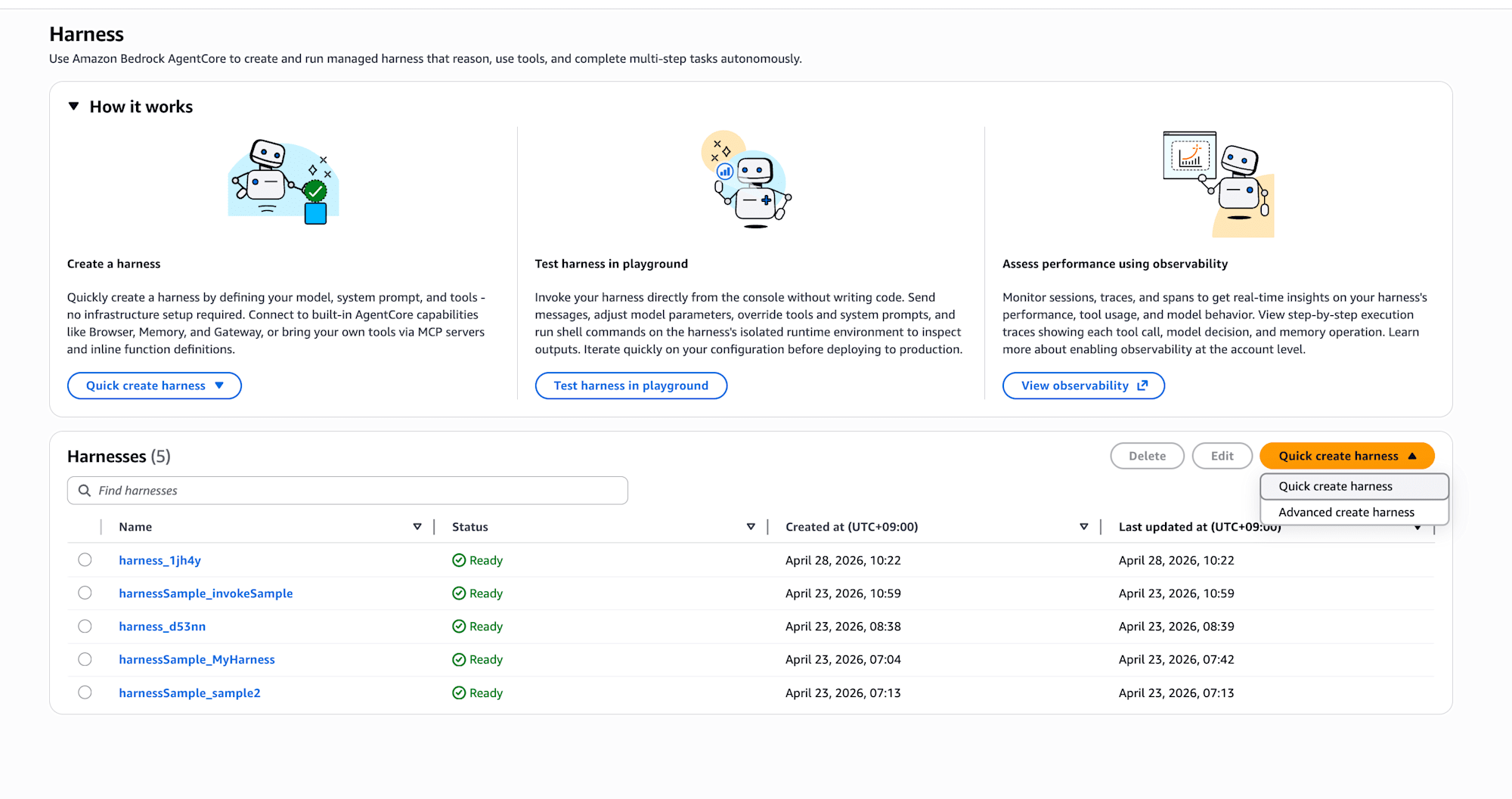
数十秒待つと Status が Ready になり、すぐに Playground でテストできる画面に遷移します。
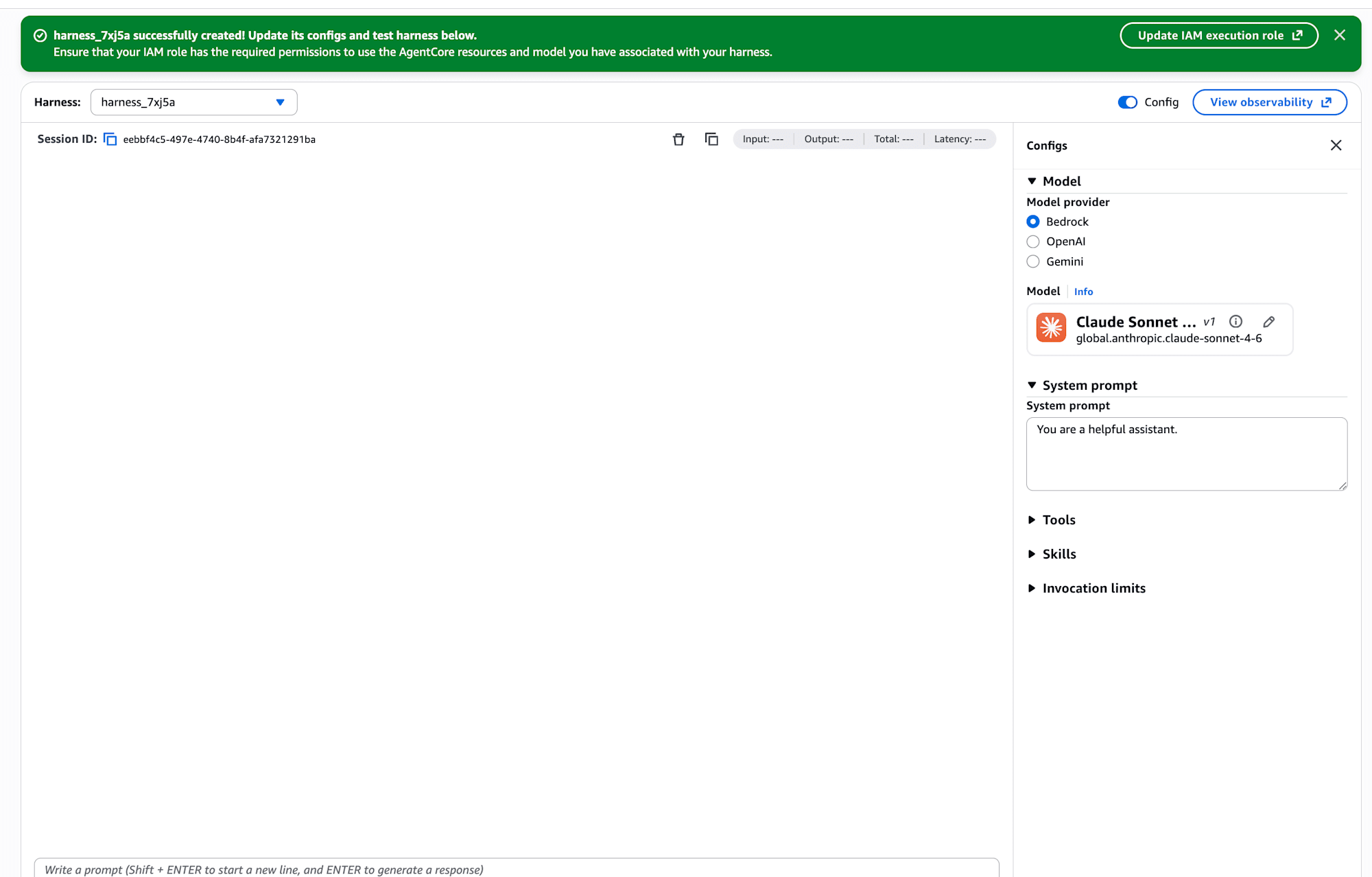
右側の Configs パネルでモデル・システムプロンプト・ツールが宣言的に設定できます。今回はデフォルトのまま、システムプロンプトは You are a helpful assistant.、モデルは Bedrock の Claude Sonnet 4.6 (global.anthropic.claude-sonnet-4-6) で進めます。
Playground でセッションを溜める
画面下の Write a prompt... 雑な依頼を日本語でいくつか質問してみます。
25 + 17 はいくつ?
今日の調子はどう?
宿題を手伝って(会話に続けて英語をかな。Be動詞がわからん)
ジョークを一つお願い
セッションを実行するとログが自動で出力されます。2〜5分ほど待ってからRecommendationに進みます。
Recommendation を作ってみる
ちなみに、前提条件のドキュメントにはトレース取り込みについて以下の記載があります。
Invoke your agent and wait 2–5 minutes for CloudWatch to ingest the telemetry before starting a recommendation or A/B test.
セッションを実行してから2〜5分待ってからRecommendationを始めるのが推奨されています。
Optimizations を開いて Create recommendation
AWSマネジメントコンソールで Amazon Bedrock AgentCore を開き、左側メニューの Assess > Optimizations を選択します(Preview タグが付いているのが今回の新機能です)。
中央上部の「How it works」に Recommendation → Configuration bundle → A/B test という流れが図示されています。先ほど貼った全体像のスクリーンショットそのものですね。
オレンジ色の Create recommendation ボタンを押すと、入力フォームが開きます。フォームは大きく Recommendation details / Define system prompt / Data source / Select a reward signal の4ブロックに分かれています。
Recommendation details
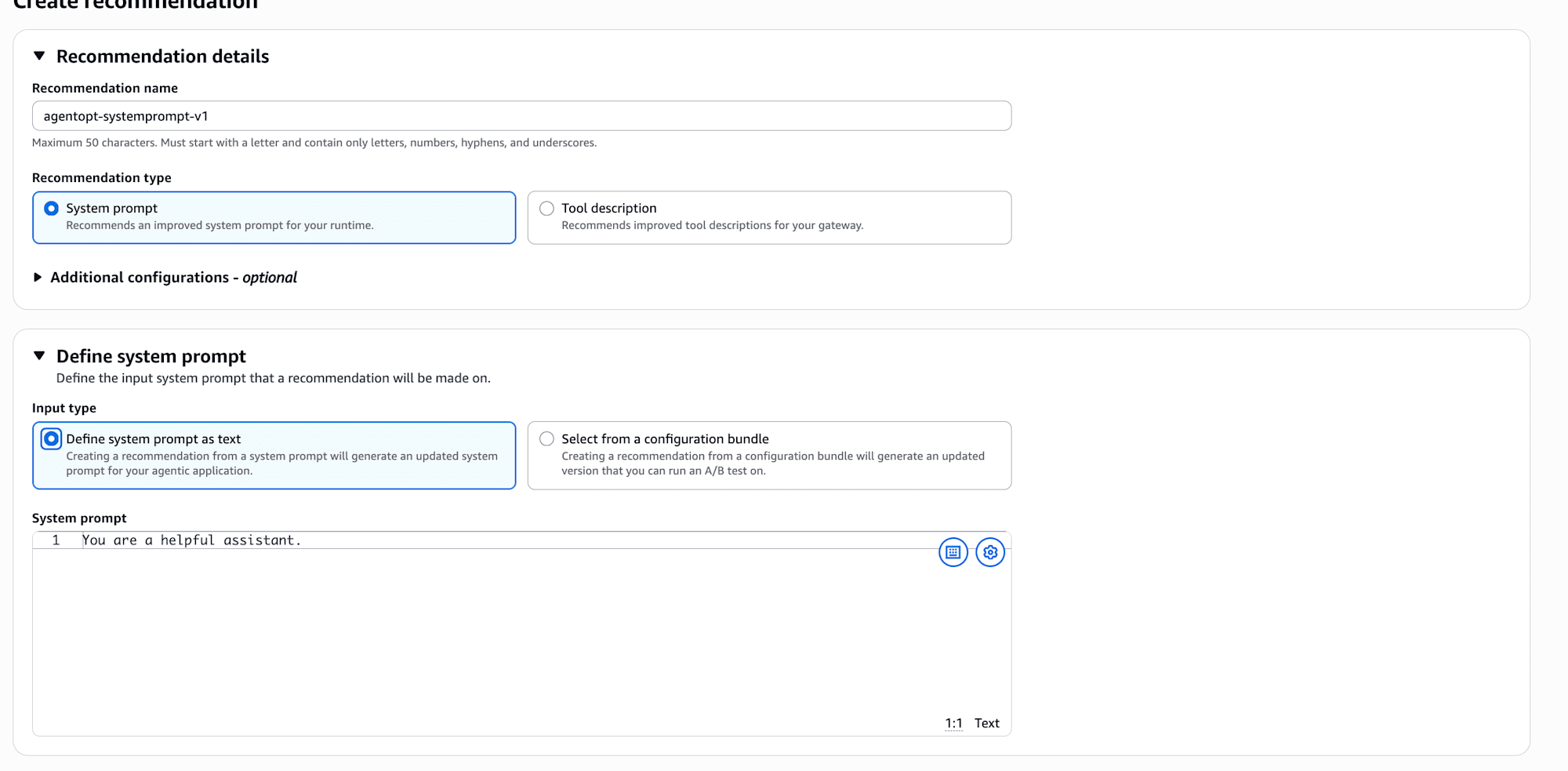
| 項目 | 入力値 |
|---|---|
| Recommendation name | agentopt-systemprompt-v1 |
| Recommendation type | System prompt |
Recommendation type は System prompt(システムプロンプトの最適化)と Tool description(ツール説明の最適化)の2択です。今回はプロンプトを改善したいので System prompt を選びます。
Define system prompt
Input type は2つあります。
- Define system prompt as text: 改善したいシステムプロンプトをそのままテキストで貼る方式
- Select from a configuration bundle: AgentCore の Configuration bundle に登録済みのバージョンを選んで改善案を作る方式(生成された改善版もバンドルに新バージョンとして書き込まれ、そのまま A/B test に流せる)
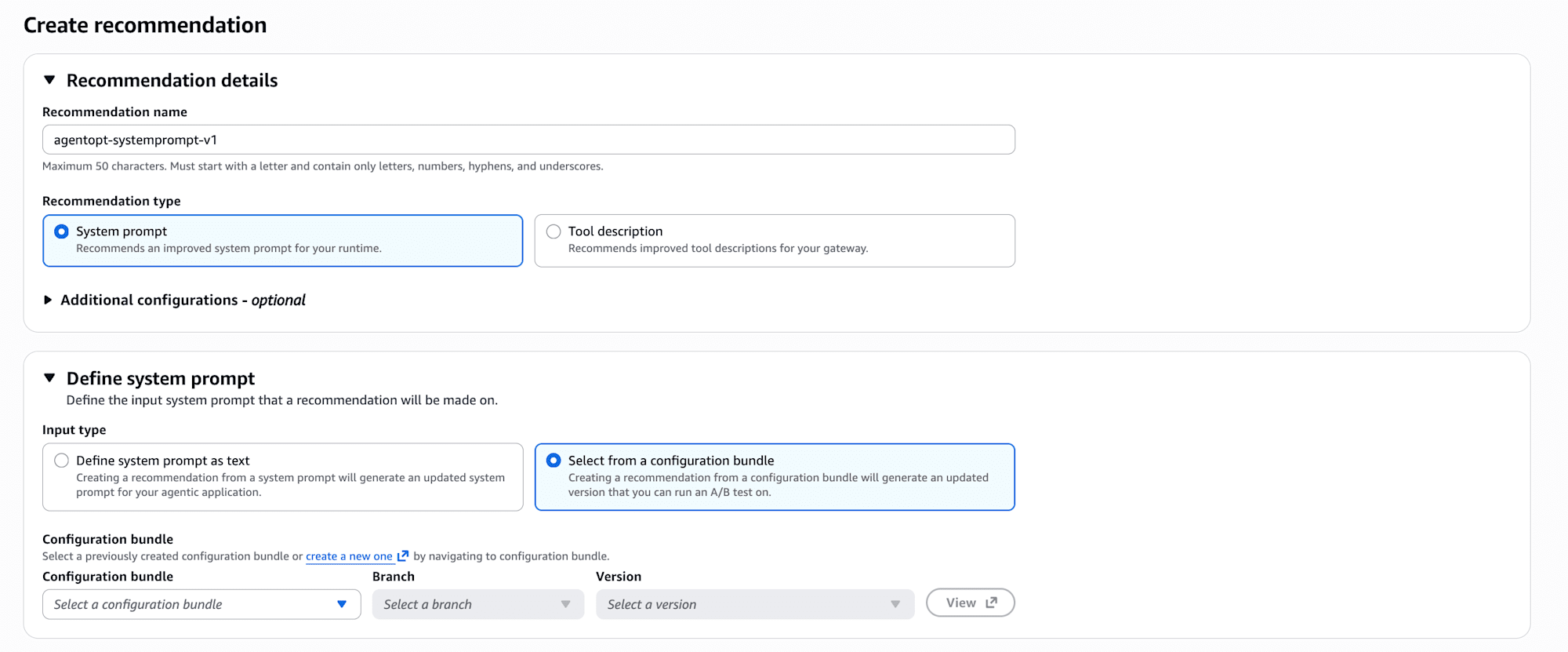
Configuration bundle はシステムプロンプト・モデルID・ツール説明などをバージョン管理するスナップショットの仕組みで、A/B test とセットで使うと、改善ループ全体をバンドルのバージョン履歴として残せます。
今回はサクッと試したいので Define system prompt as text を選んで、Harness に入っているデフォルトの You are a helpful assistant. をそのままテキスト欄に貼ります。
Data source
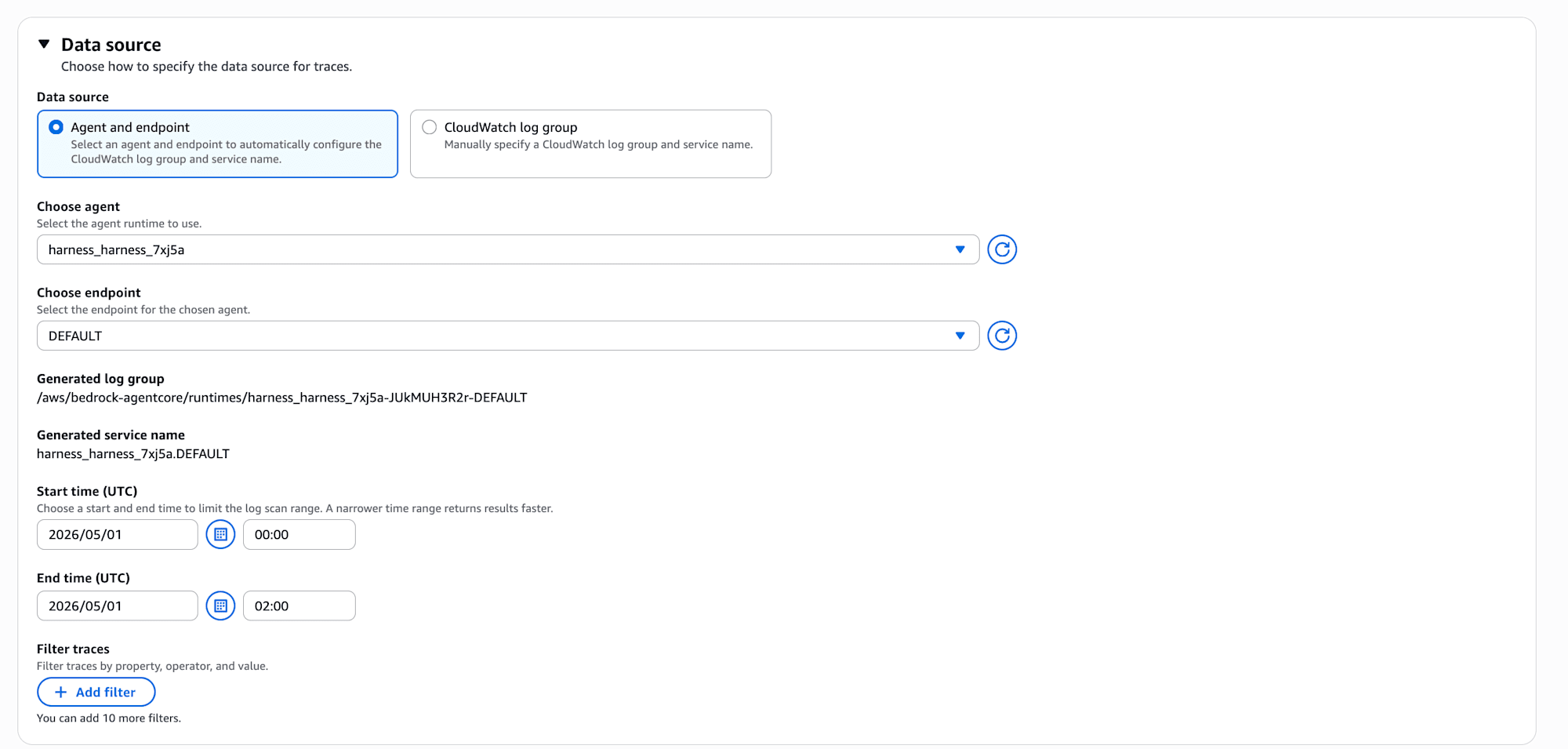
| 項目 | 入力値 |
|---|---|
| Data source | Agent and endpoint |
| Choose agent | harness_harness_7xj5a |
| Choose endpoint | DEFAULT |
| Start time / End time (UTC) | Playground でセッションを投げた時間帯 |
ここは Agent and endpoint を選ぶと、ロググループとサービス名を裏でいい感じに解決してくれます (/aws/bedrock-agentcore/runtimes/harness_harness_7xj5a-XXXX-DEFAULT と harness_harness_7xj5a.DEFAULT が自動で埋まる)。AgentCore Evaluations を触ったことがある方は気付くと思いますが、Recommendation のデータソース指定は Evaluations と同じ操作感ですね!
Select a reward signal

最後に評価器を選びます。
| カテゴリ | 例 |
|---|---|
| Response Quality (8) | Correctness / Helpfulness / Faithfulness / Conciseness / Coherence / Instruction following / Refusal / Response relevance |
| Task Completion (1) | Goal success rate |
| Component Level (2) | Tool selection accuracy / Tool parameter accuracy |
| Safety (2) | Harmfulness / Stereotyping |
| Trajectory (3) | Trajectory exact order match / in order match / any order match |
| Custom evaluators | 自分で定義した評価器 |
Evaluationsと同じ定義ですね。今回はシンプルに全体的にタスクをいい感じにこなしてくれたかを見る、Goal Success Rateを選択しました。
自分が改善したい基準を選ぶ感じですね。
入力できたら右下の Create recommendation ボタンを押します。
結果を待つ
数分待つと Status が Completed になります。
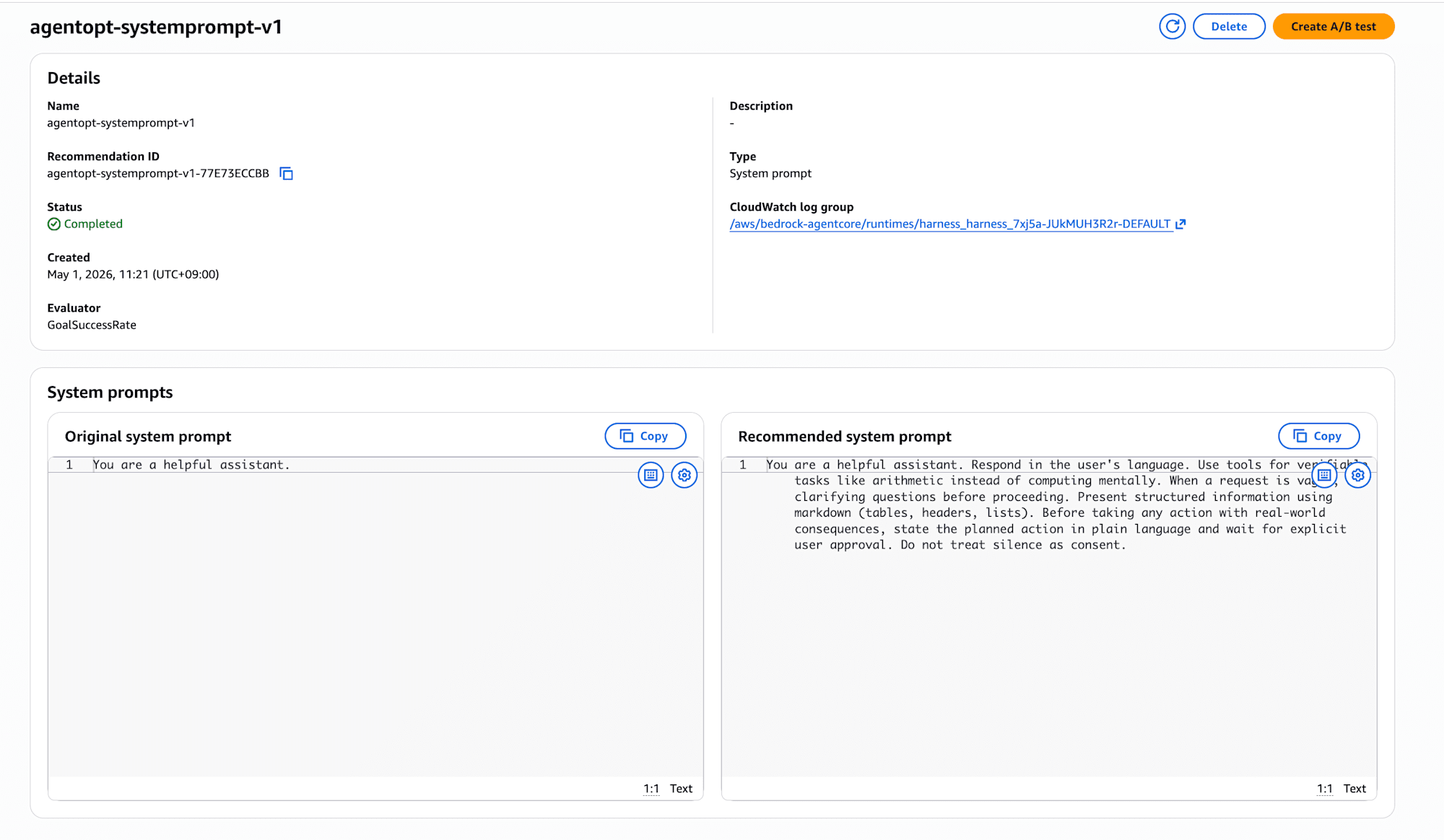
左に「Original system prompt」、右に「Recommended system prompt」が並ぶUIです。比較しやすくていいですね!
Original:
You are a helpful assistant.
Recommended:
You are a helpful assistant. Respond in the user's language. Use tools for verifiable tasks like arithmetic instead of computing mentally. When a request is vague, ask clarifying questions before proceeding. Present structured information using markdown (tables, headers, lists). Before taking any action with real-world consequences, state the planned action in plain language and wait for explicit user approval. Do not treat silence as consent.
おお、いい感じに修正されていますね!
「Use tools for verifiable tasks like arithmetic instead of computing mentally」は、ツールが使える場合はツールをしっかり使ってLLM自体の力で解決しないでと即していますね。
また、「When a request is vague, ask clarifying questions before proceeding」は、「宿題を手伝って」のような漠然とした依頼に対していい感じに聞き返すよう促す方向ですね。
「Present structured information using markdown (tables, headers, lists)」と「Before taking any action with real-world consequences, state the planned action in plain language and wait for explicit user approval. Do not treat silence as consent.」あたりは明示的に投げた質問の中には含まれない観点ですが、見やすさと安全性のベストプラクティスとして加えてくれています。
ふわっとしたプロンプトをログから改善点を分析して良い感じにしてくれていますね。実践レベルでもどう化けてくれるのか気になるので今後試していきたいです。
おわりに
割とお手軽に分析してくれて使いやすい印象でした。これを起点にどう改善するか手掛かりが掴めそうですね。
自分でログを取得して分析するのは少し手間なので、この辺りをマネージドに対応してくれるのは良い印象です。
今回は省略しましたが、生成された Recommendation から続けて A/B test を作って Control / Treatment のトラフィック分割と統計的有意性検証まで一気通貫でや検証できるみたいです。A/Bテストの方は別途試してまたご紹介していきたいと思います!
本記事が少しでも参考になりましたら幸いです。最後までご覧いただきありがとうございました!










