![[アップデート] Amazon Bedrock Data Automation がカスタムボキャブラリーに対応し、業界固有の用語を正確に認識できるようになりました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-e3065182082062711612153bbdcf1d96/c04359de689df2f56eb066576ab63fb5/amazon-bedrock?w=3840&fm=webp)
[アップデート] Amazon Bedrock Data Automation がカスタムボキャブラリーに対応し、業界固有の用語を正確に認識できるようになりました
いわさです。
Amazon Bedrock Data Automation(以後、BDA)は、ドキュメント・画像・音声・動画などの非構造化コンテンツから生成 AI を活用して構造化データへ変換するサービスです。
例えば音声ファイルを渡すと文字起こしや要約を自動生成してくれたり、ドキュメントからテーブルやテキストを抽出してくれたりします。
BDA で音声や動画を処理する際、業界固有の専門用語やブランド名、略語などが正しく認識されないケースがありました。
例えば医療分野の薬品名や、社内で使われる独自の略語などは、汎用的な音声認識モデルでは誤認識されやすい部分です。
今回のアップデートで、BDA に「Data Automation Library」という新機能が追加され、カスタムボキャブラリーを登録できるようになりました。
ドメイン固有の単語やフレーズのリストを BDA に提供することで、音声・動画コンテンツの認識精度を向上させることができます。
また、表示形式の制御も可能で、例えば「electrocardiogram」を「ECG」と表示させるといった使い方もできるようです。
日本語を含む 11 言語に対応しており、追加料金なしで利用できます。
今回こちらを確認してみたので紹介します。
実際に確認してみる
なお、本日時点では本機能はまだ東京リージョンでは利用できないみたいなので、今回はバージニア北部リージョンで検証してみます。
Data Automation Library を作成する
まずは Data Automation Library を作成します。Amazon Bedrock のコンソールからサイドバーの「データオートメーション」を選択します。
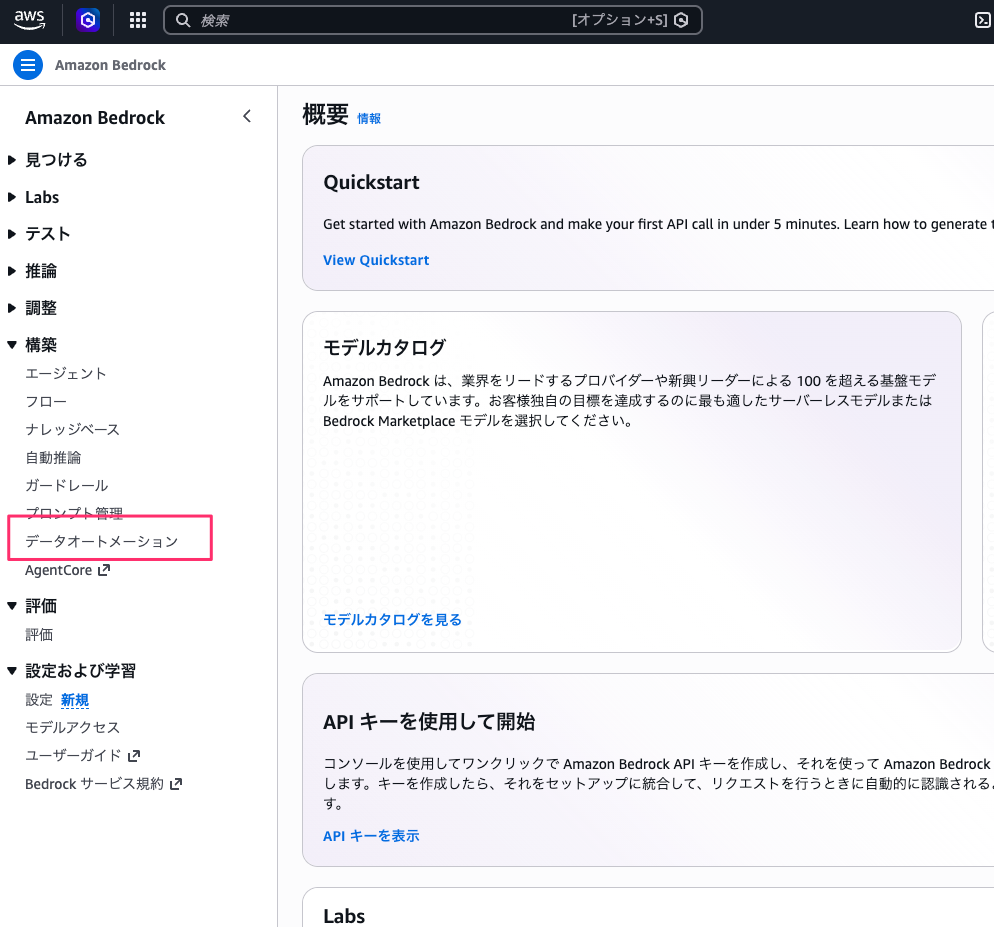
データオートメーションの画面を開くと、概要セクションの中に「Libraries - 新規」というセクションが追加されています。
「ライブラリの管理」を選択します。
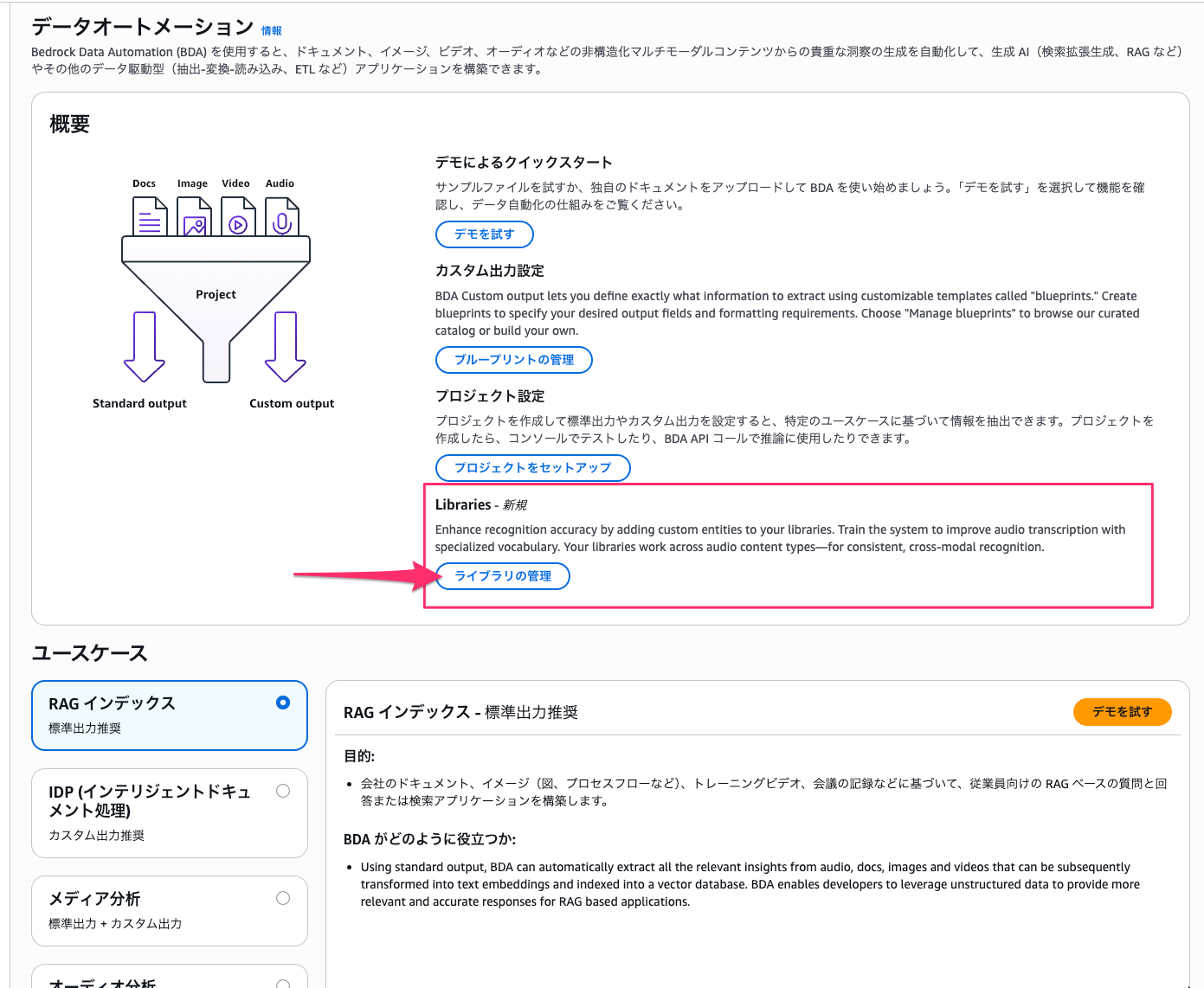
「ライブラリを作成」を選択します。
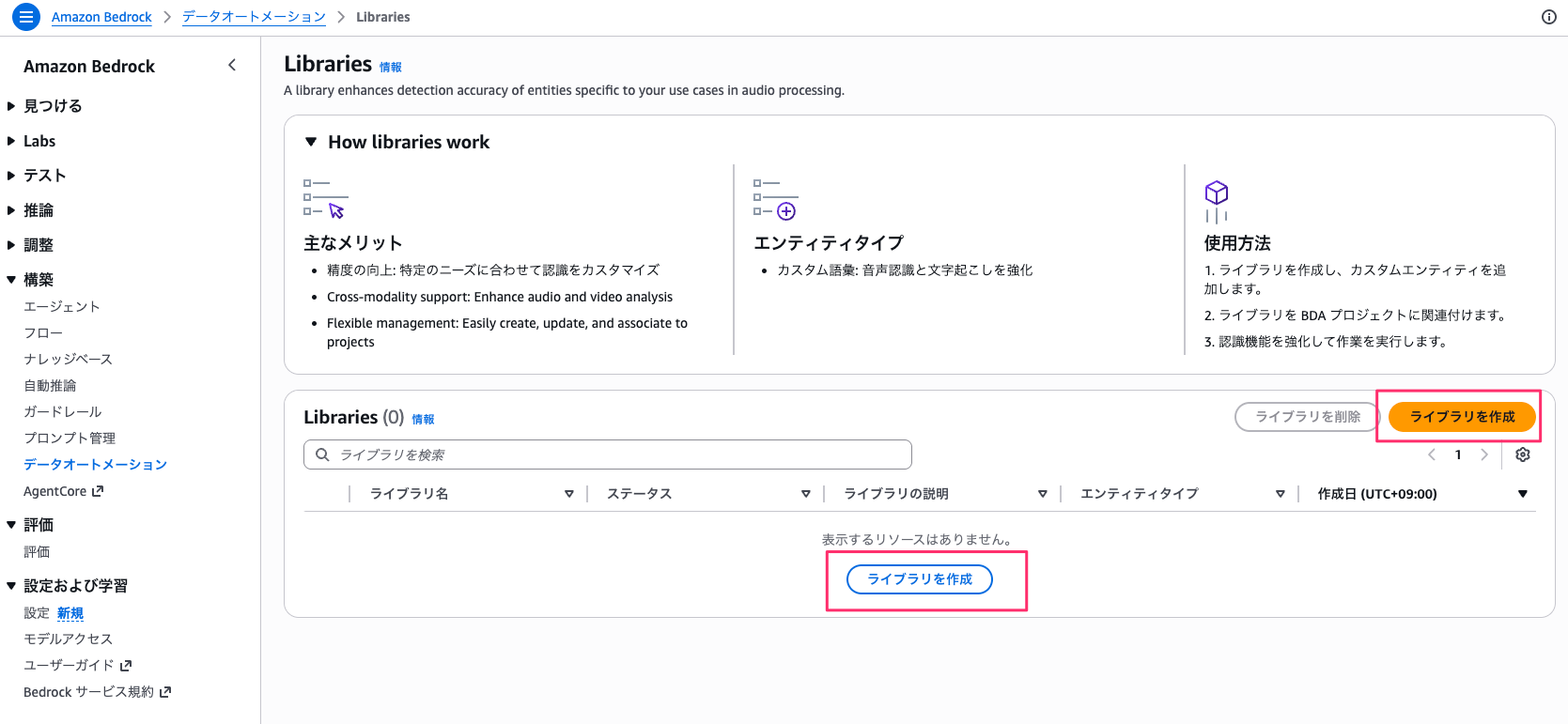
ライブラリ名と説明を入力して「ライブラリを作成」を選択します。
オプションで KMS キーによる暗号化設定やタグの設定も可能です。
カスタムボキャブラリーを追加する
ライブラリが作成できたら、次にカスタムボキャブラリーを追加します。
ライブラリの詳細画面の「カスタム語彙」タブから「カスタム語彙リストを追加」を選択します。
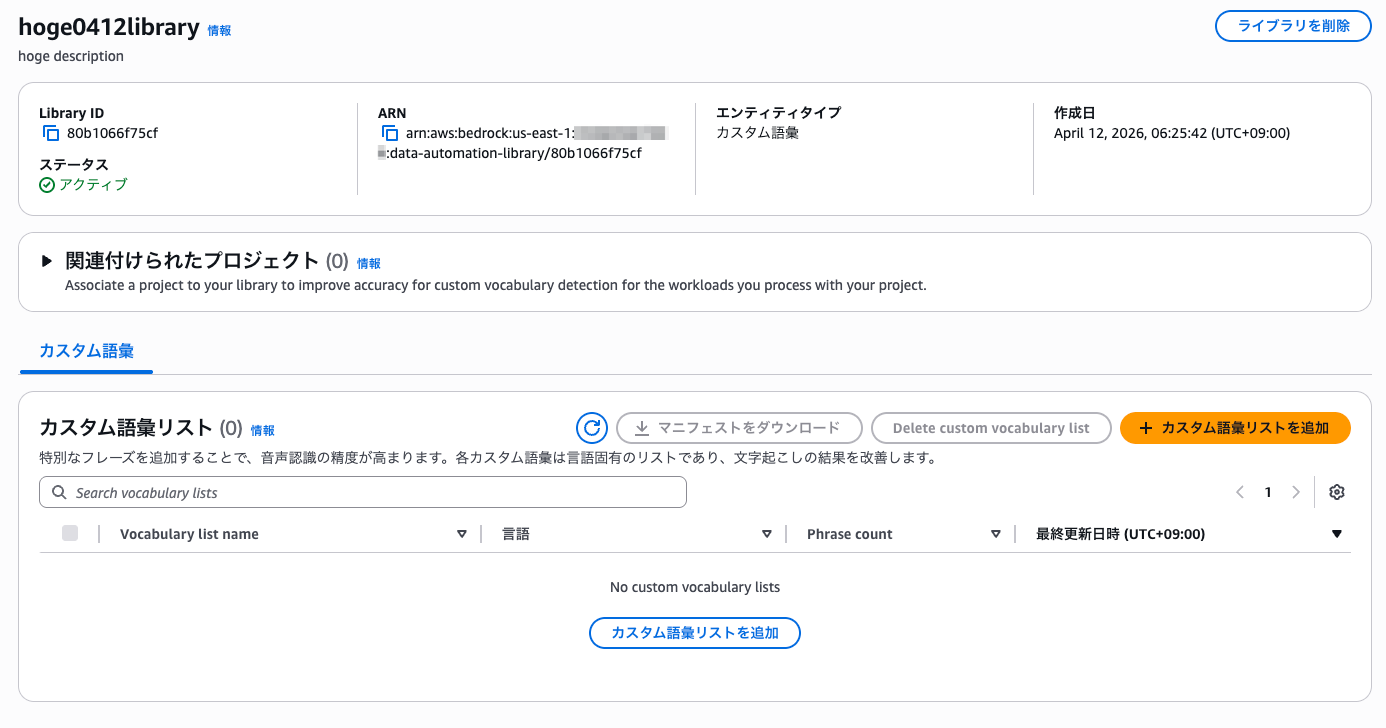
ボキャブラリーの追加方法は「マニフェストをアップロード/選択」と「手動で追加」の 2 つがあります。
You can provide vocabulary through an S3 manifest file or inline payload.
マニフェストの方は JSONL 形式のファイルをローカルデバイスからアップロードするか、S3 から選択する方式です。
大量の用語を一括登録する場合に便利そうです。
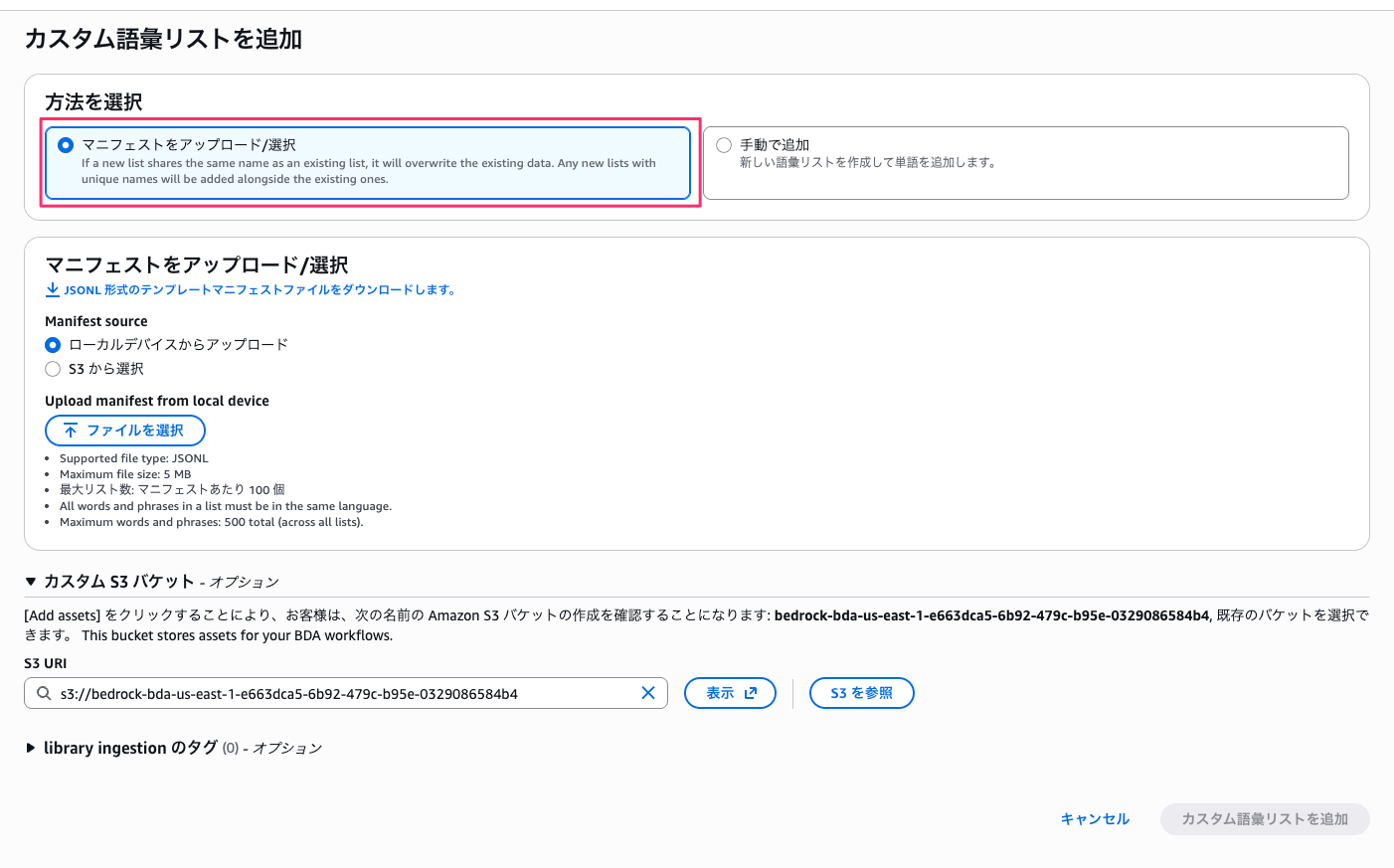
今回は「手動で追加」で試してみます。
各フレーズには「表示形式を追加」というオプションがあり、認識された用語をどのように表示するかを制御できます。
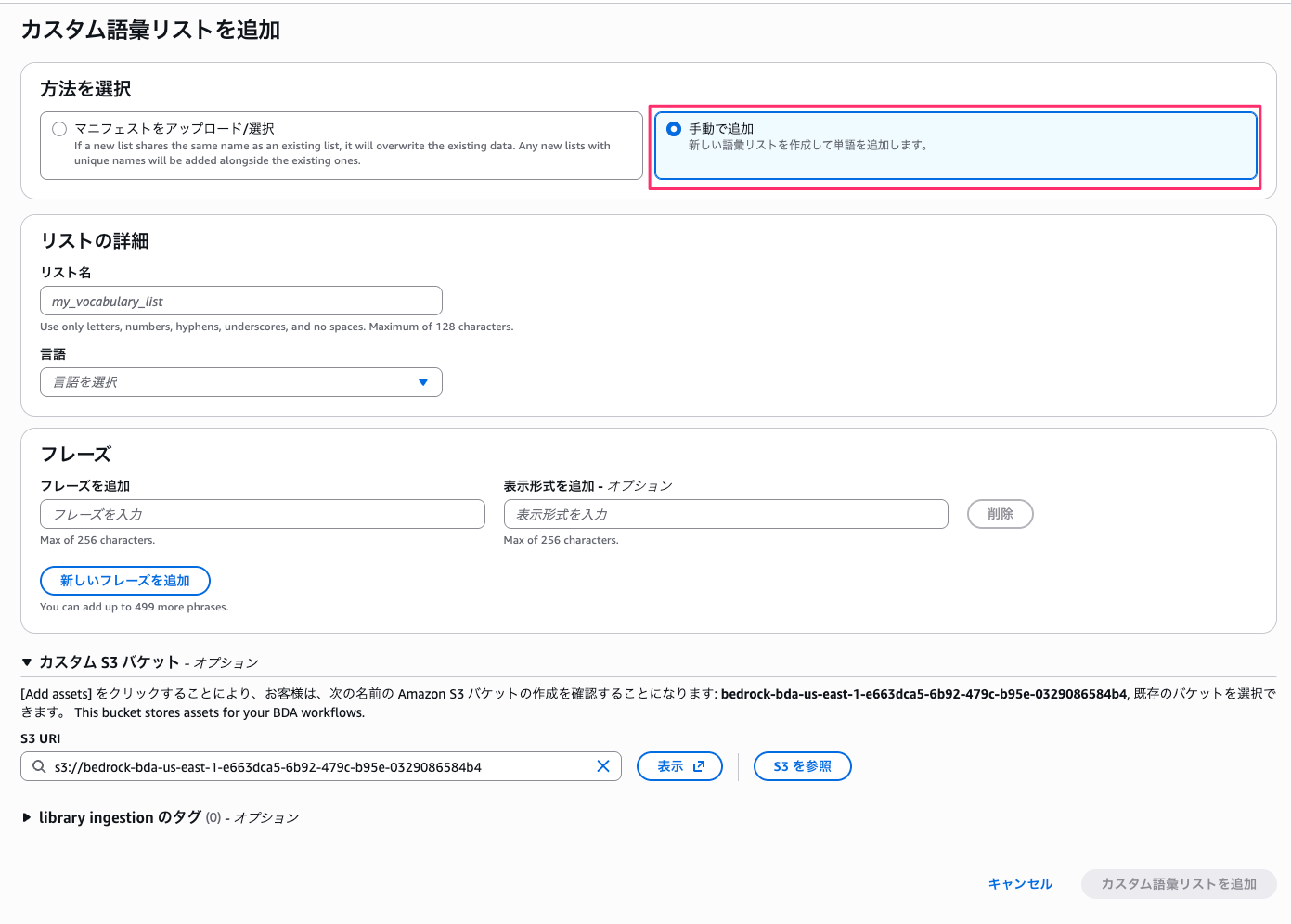
今回は日本語で AWS 関連の用語を登録してみます。
言語は Japanese を選択し、「大規模言語モデル」→「LLM」、「自然言語処理」→「NLP」のように表示形式を設定することで文字起こし結果での表記を制御できるはずです。
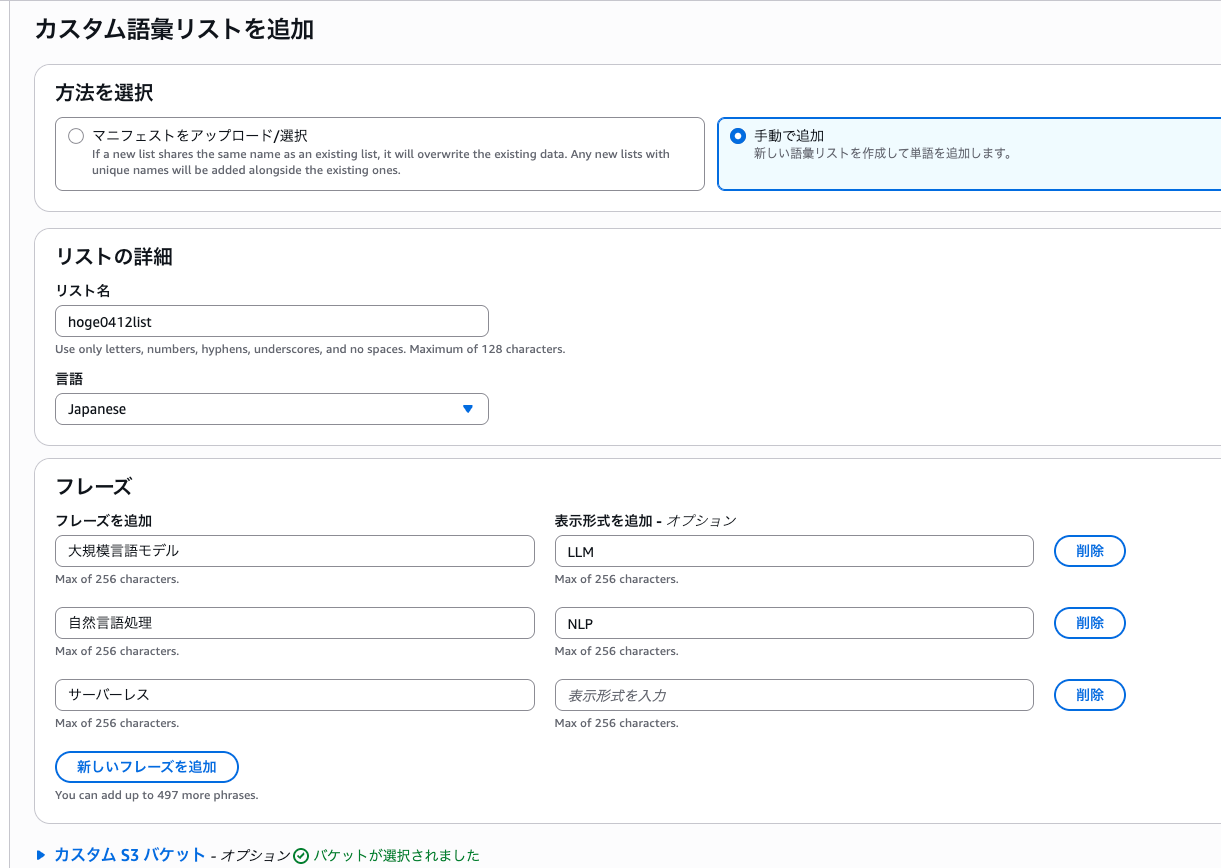
なお、最初は「Amazon Bedrock」「CloudFormation」「Kubernetes」などの英字フレーズも一緒に Japanese リストに登録しようとしたのですが、以下のエラーで失敗しました。
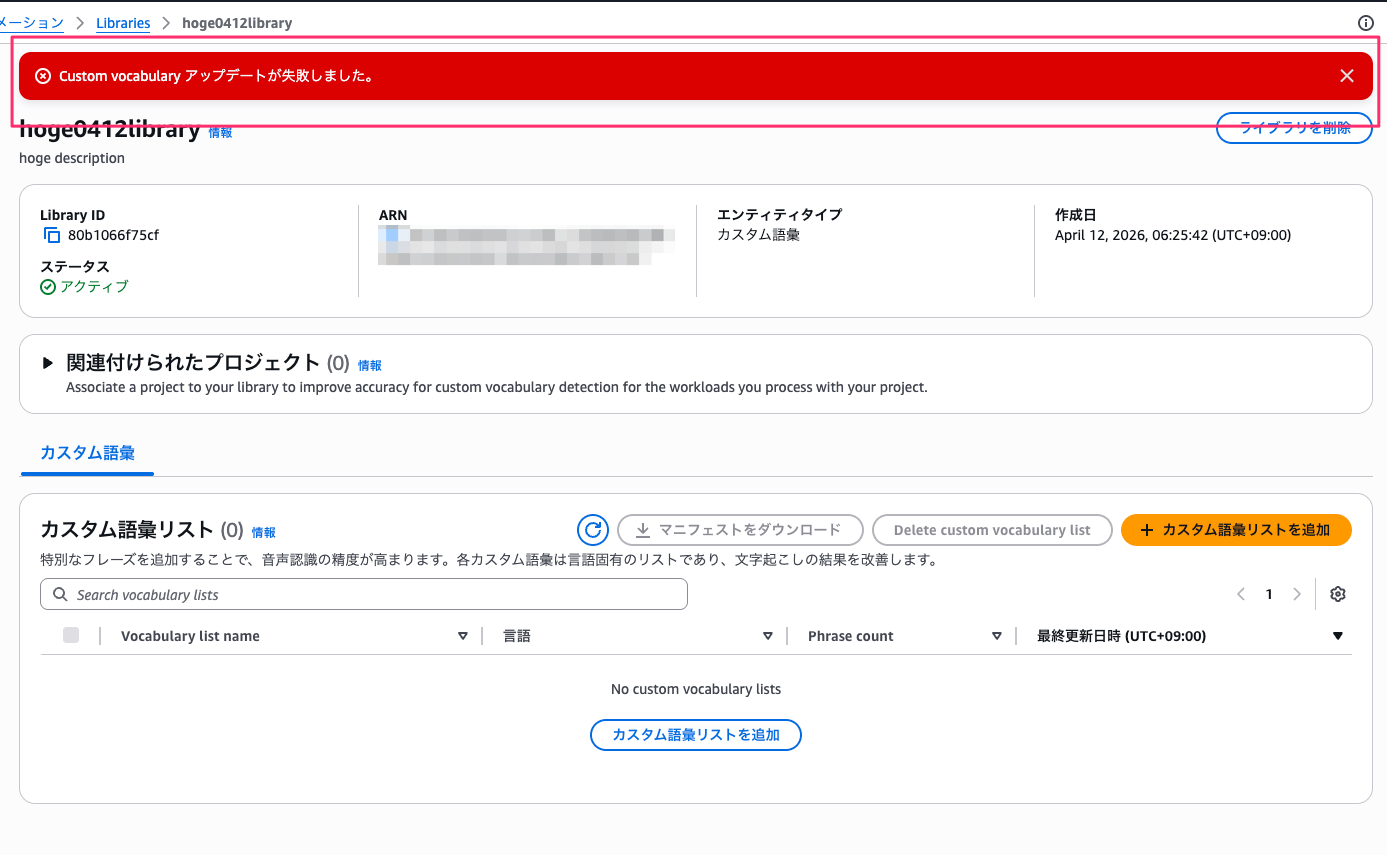
コンソール上のエラーメッセージだけでは原因がわかりませんでしたが、Ingestion Job の出力先 S3 バケットに結果ファイルが出力されており、そちらを確認したところ以下のエラーが記録されていました。
{
"vocabulary": {
"successful": [],
"failed": [
{
"entityId": "hoge0412list",
"itemIndex": 0,
"errorType": "ValidationError",
"errorMessage": "Entity validation failed: One or more phrases contain unsupported character(s): , l"
}
]
}
}
各言語でサポートされている文字セットが決まっており、Japanese の文字セットにはアルファベットが含まれていないようです。(そうなのか...?)
英字のフレーズを登録したい場合は、別途 English のリストとして作成する必要があるみたいですね。
Note that only the characters listed in your language's character set can be used in a custom vocabulary.
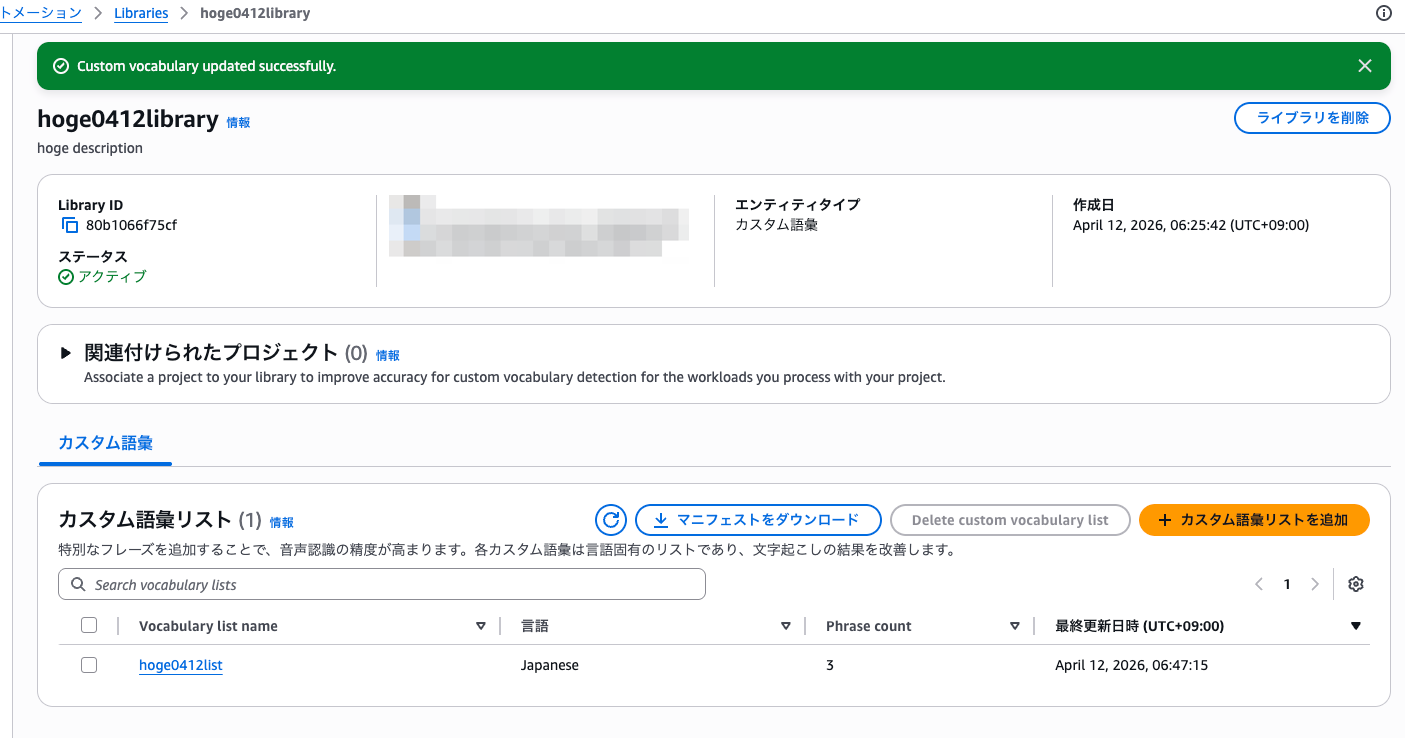
ためしに、日本語フレーズのみに絞って再登録したところ、無事に成功しました。
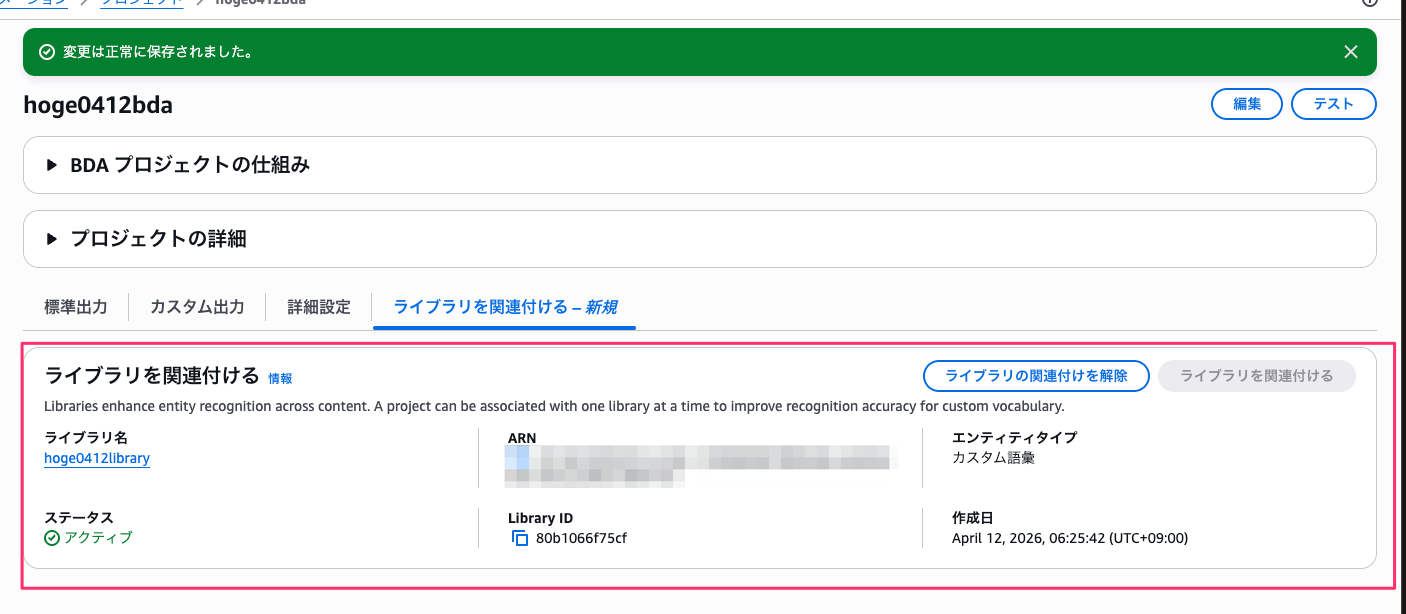
BDA プロジェクトに Library を関連付ける
次に、BDA プロジェクトに Library を関連付けます。カスタムボキャブラリーを適用するには、プロジェクトに Library を関連付ける必要があるみたいですね。
When you associate a library with a project, all jobs processed through that project apply the library's entities to improve extraction accuracy for your content. Note, that a project can only be associated with one library, but one library can be associated with multiple projects.
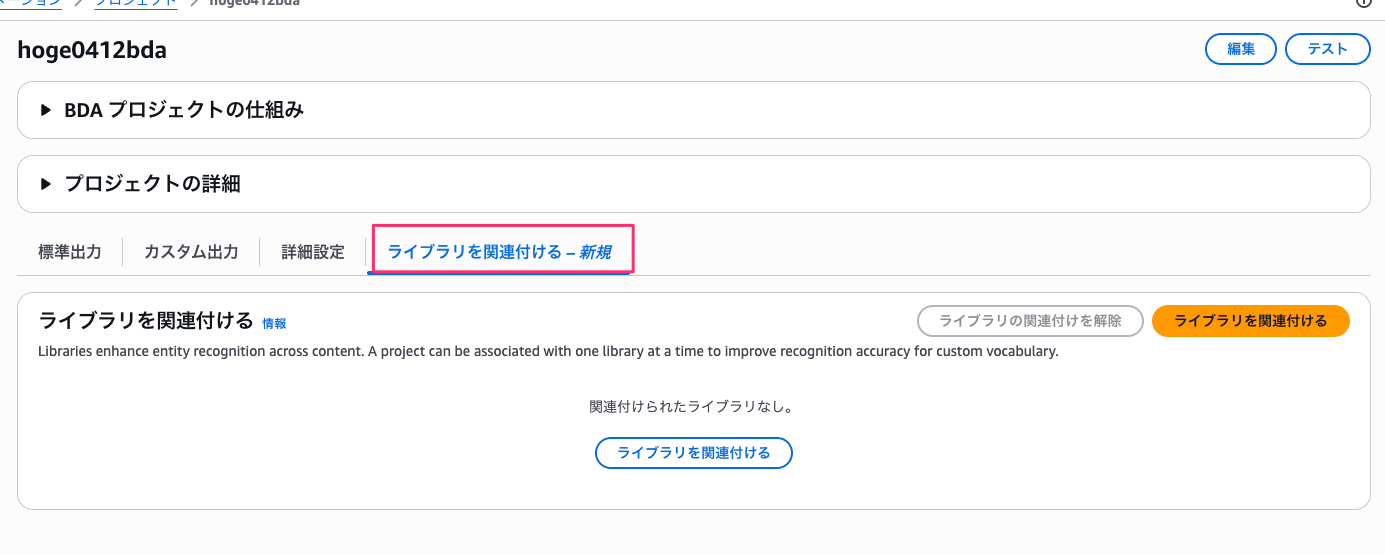
プロジェクトの詳細画面を開くと、「ライブラリを関連付ける – 新規」タブが追加されています。
先ほど作成したライブラリを選択して関連付けます。
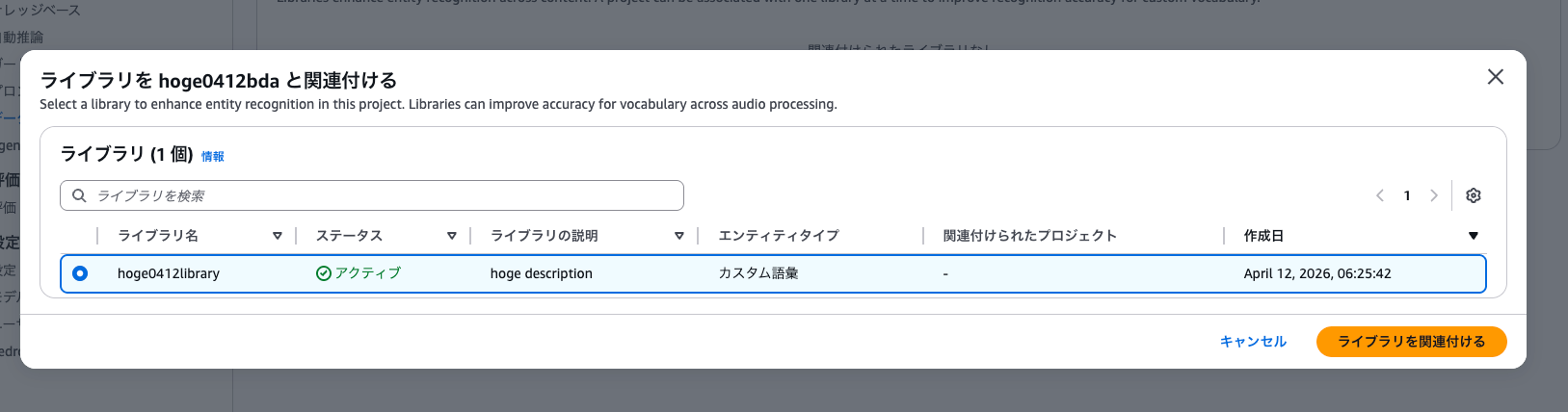
関連付けが完了しました。
音声ファイルを処理してカスタムボキャブラリーの効果を確認する
では、実際に音声ファイルを処理してカスタムボキャブラリーの効果を確認してみましょう。
テスト用の音声ファイルは Amazon Polly で生成しました。プロジェクトの詳細画面右上の「テスト」から音声ファイルをアップロードして処理できます。
日本語で試してみる
まずは日本語の音声ファイルで試してみます。以下の文章を Polly で読み上げた MP3 を用意しました。
「Amazon Bedrock の大規模言語モデルを活用して、自然言語処理の機能を実装しました。CI/CD パイプラインには AWS CloudFormation を使用し、サーバーレスアーキテクチャで構築しています。Kubernetes クラスターとの連携も検討中です。」
ライブラリを関連付けた状態でテストした結果がこちらです。
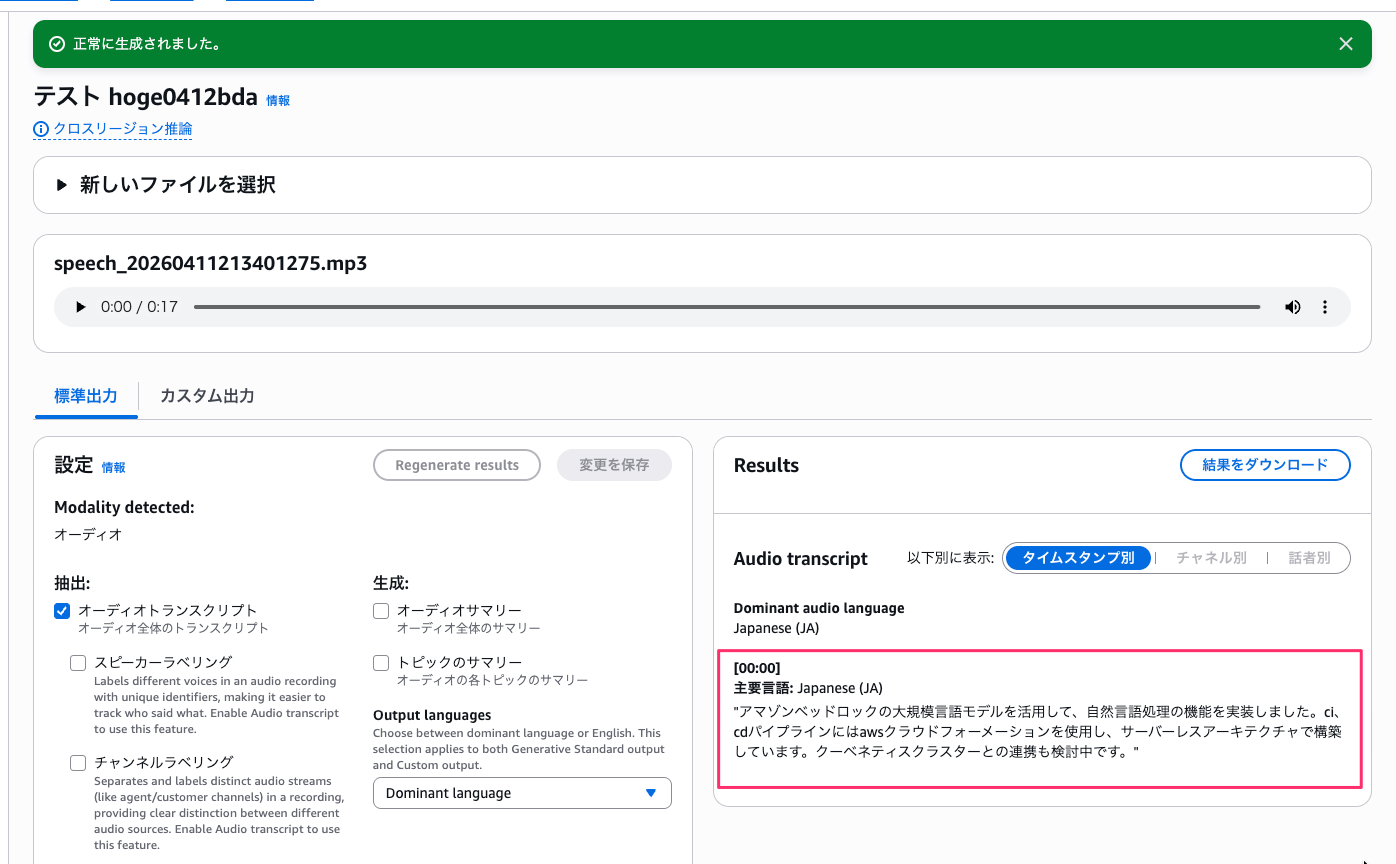
日本語の用語自体は正しく認識されていますが、表示形式の変換(「大規模言語モデル」→「LLM」、「自然言語処理」→「NLP」)は適用されていませんでした。
表示形式の値がアルファベットだから効かないのかを切り分けるために、表示形式も日本語(「大規模言語モデル」→「だいきぼげんごもでる」)に変更して試してみましたが、こちらも変換は適用されませんでした。
なぜだかよくわからないのですが、日本語では表示形式の変換自体がまだ効かないのかもしれません...。
英語で試してみる
日本語では表示形式の変換が効かなかったので、英語で試してみます。アナウンスの原文に electrocardiogram → ECG、discounted cash flow → DCF という例が紹介されていたので、こちらをそのままやってみましょう。
以下の English リストを追加しました。
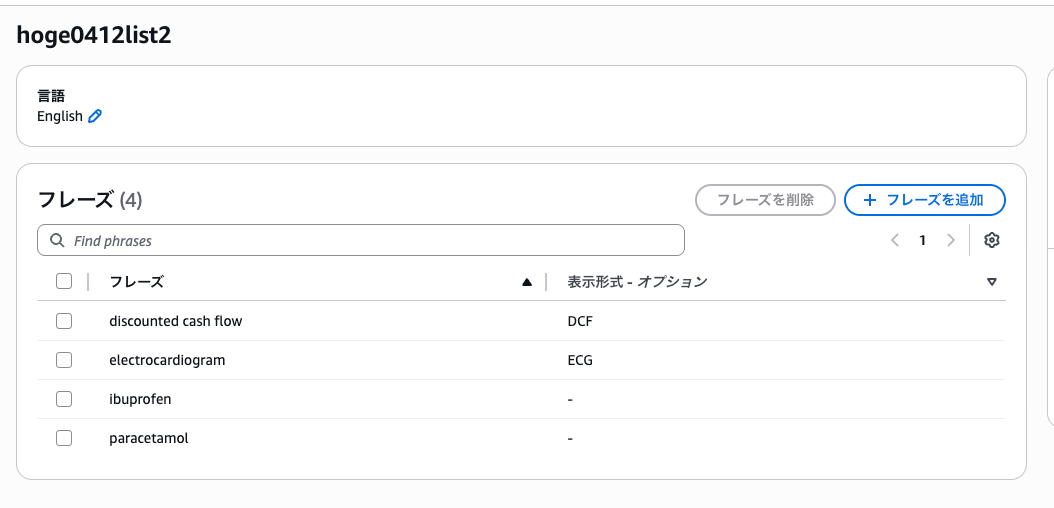
Polly で以下の英語音声を生成しました。
"The patient was prescribed paracetamol and ibuprofen after the electrocardiogram showed normal results. The discounted cash flow analysis was completed last week."
まずはライブラリの関連付けを解除した状態でテストします。
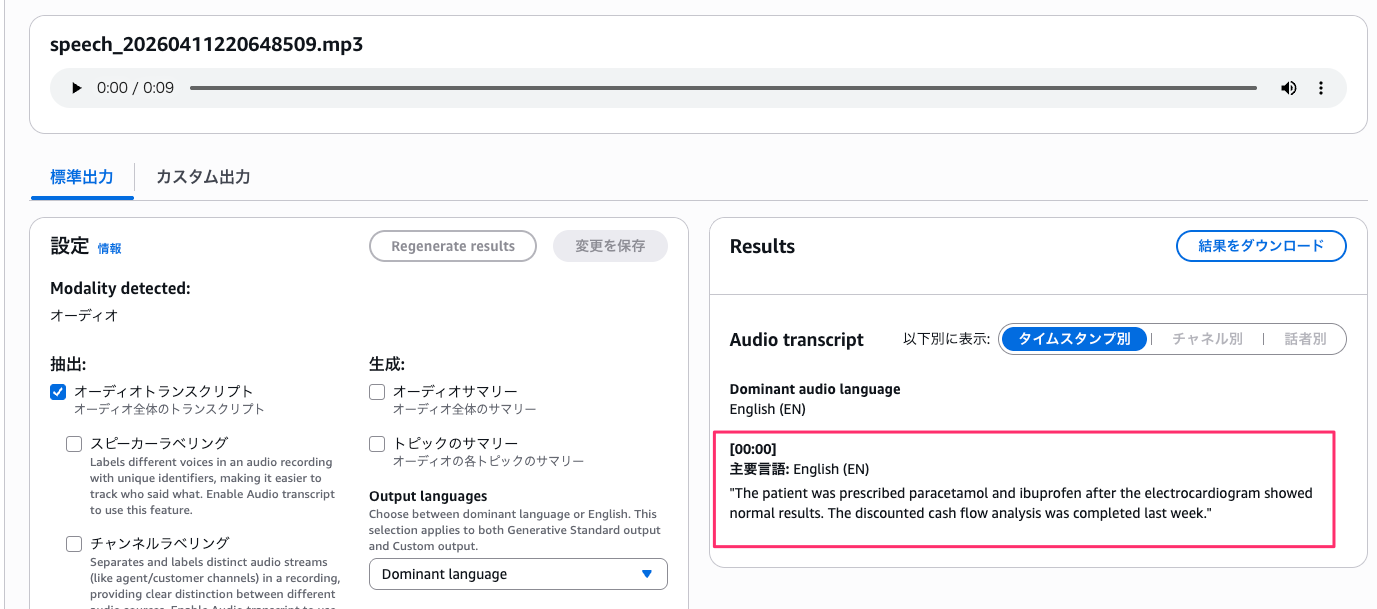
ライブラリなしの場合、文字起こし結果は以下のとおりです。
"The patient was prescribed paracetamol and ibuprofen after the electrocardiogram showed normal results. The discounted cash flow analysis was completed last week."
用語がそのまま認識されています。
次に、ライブラリを関連付けた状態で同じ音声をテストします。
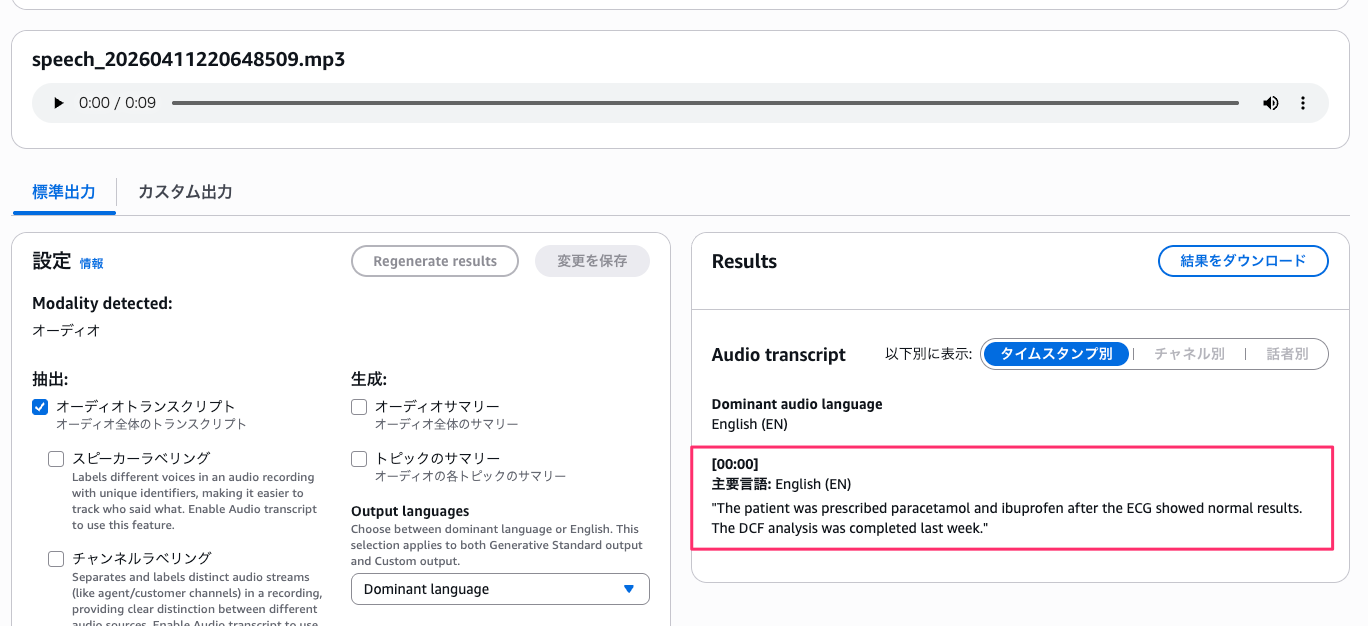
ライブラリありの場合、文字起こし結果は以下のとおりです。
"The patient was prescribed paracetamol and ibuprofen after the ECG showed normal results. The DCF analysis was completed last week."
electrocardiogram が ECG に、discounted cash flow が DCF に変換されていることが確認できます。
良いですね!表示形式の変換がしっかり動いています。
さいごに
本日は Amazon Bedrock Data Automation に Data Automation Library によるカスタムボキャブラリー機能が追加されたので確認してみました。
英語では表示形式の変換(electrocardiogram → ECG など)がしっかり動作することが確認できました。
一方で、日本語リストに英字フレーズを混ぜると文字セットの制約でエラーになったり、日本語フレーズの表示形式に英字を指定しても変換が効かなかったりと、日本語での利用にはまだ制約がありそうです。
医療・法務・金融など専門用語が多い英語コンテンツを扱う場合には便利な機能だと思います。
追加料金なしで使えるのも良いですね。
東京リージョンへの対応も待ちたいところです。









