
Bedrock Knowledge BasesのRetrieve APIはOpenSearch Serverless NextGenで動かない — 原因と回避策
はじめに
OpenSearch Serverless NextGenのscale-to-zero機能でコスト削減を検討していたところ、思わぬ落とし穴にはまりました。
「Bedrock Knowledge BasesでNextGenコレクションを作成し、データを同期(Ingest)するところまでは成功する。でもRetrieve API(検索)を呼ぶと403エラーになる」
という現象です。結論から言うと、Bedrock KBのRetrieve APIはOpenSearch Serverless NextGenと互換性がありません。インジェストは動くのにリトリーブだけ壊れているという、なかなか気づきにくい問題でした。
この記事では、この問題に気づくまでの経緯、原因の調査、そして最終的にとった回避策(opensearch-pyによる直接クエリ)を共有します。
セットアップの流れ — どこまで上手くいくか
NextGenコレクションをBedrock KBのベクトルストアとして使うまでの手順を整理します。ここまでは順調に進むので、余計に問題に気づきにくいです。
1. OpenSearch Serverless NextGenコレクションの作成
OpenSearch Serverlessのコンソールで、コレクショングループを作成します。
- コレクションタイプ: Vector search
- Collection creation method: Express create
コレクショングループ内にコレクションを作成します。NextGenでは「コレクショングループ」の配下にコレクションを置く構成です(Classicとは異なります)。
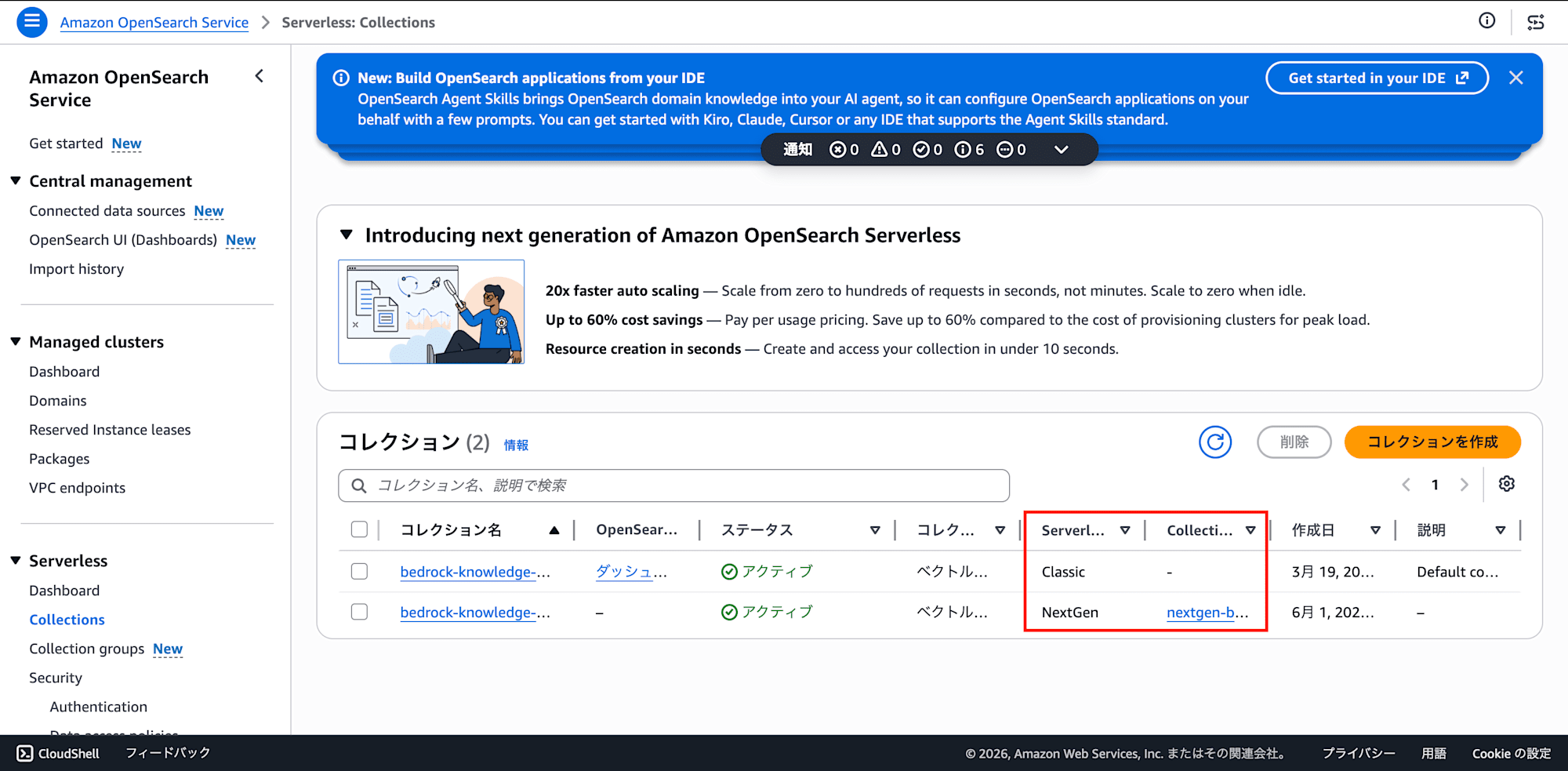
2. ベクトルインデックスを手動で作成する
NextGenコレクションが作成されたら、コレクションの詳細画面から インデックス > インデックス作成を選択します。
JSONモードに切り替え、以下を貼り付けます。
{
"settings": {
"index": {
"knn": true
}
},
"mappings": {
"properties": {
"bedrock-knowledge-base-default-vector": {
"type": "knn_vector",
"dimension": 1024,
"method": {
"name": "hnsw"
}
},
"AMAZON_BEDROCK_METADATA": {
"type": "text",
"index": false
},
"AMAZON_BEDROCK_TEXT_CHUNK": {
"type": "text",
"index": true
}
}
}
}
インデックス名は任意ですが、後でBedrock KBに指定するので控えておきます(例: bedrock-kb-index)。
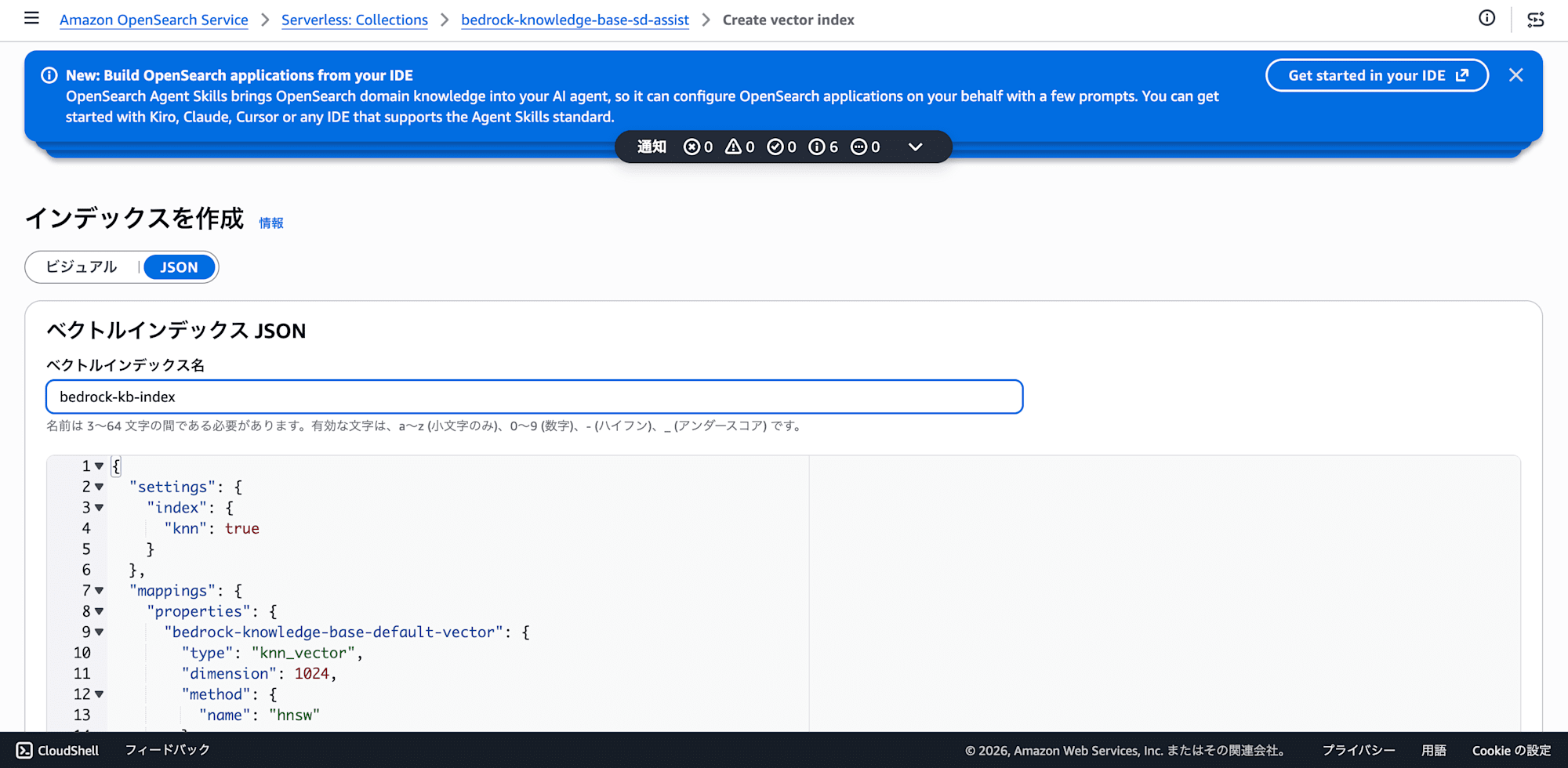
注意: dimension は使用する埋め込みモデルに合わせてください(Titan Embeddings V2の場合は1024)。また、OpenSearch Serverlessでは method に engine パラメータを指定するとエラーになります。"name": "hnsw" だけで十分です。
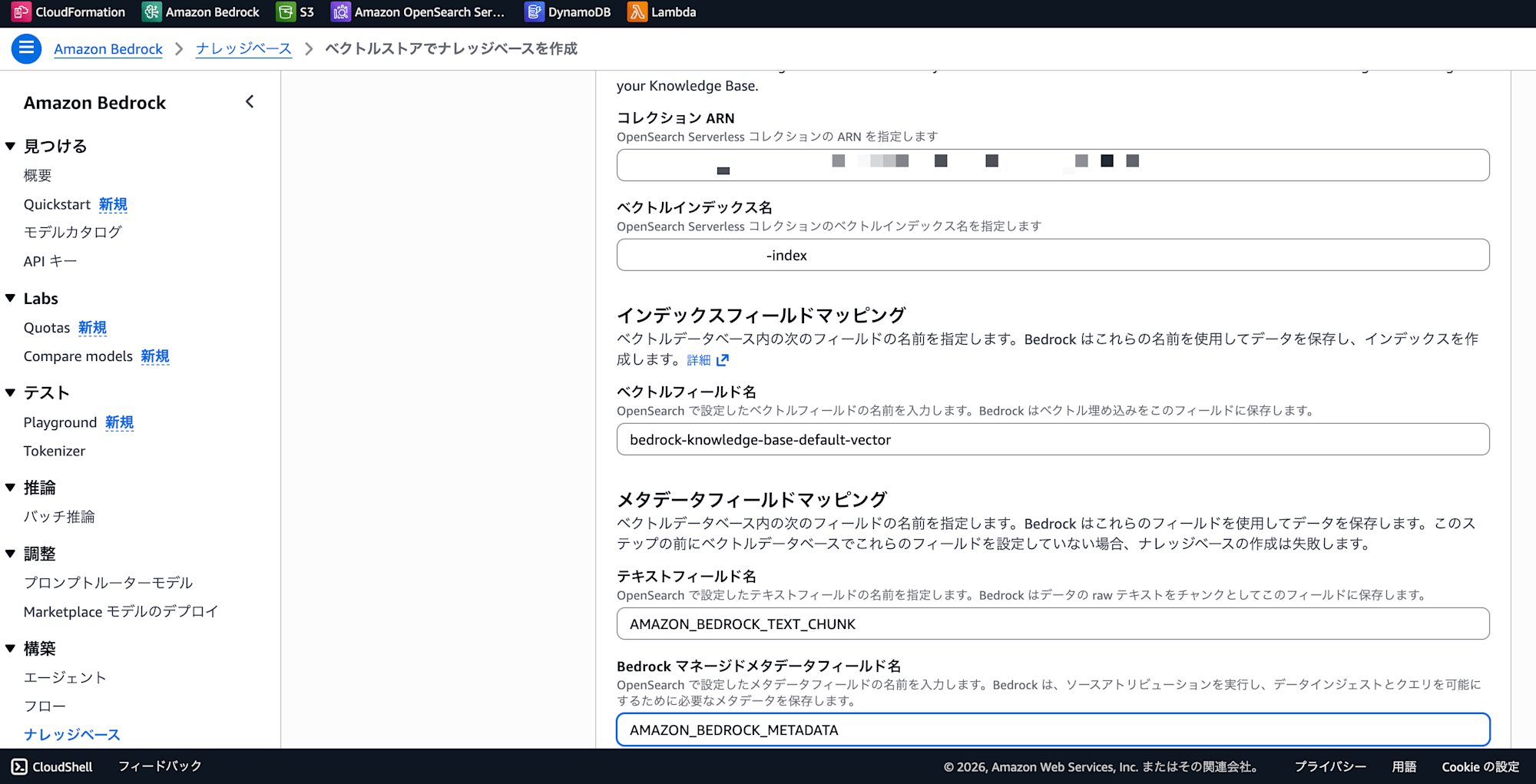
3. Bedrock Knowledge Baseから「既存のOpenSearchコレクションを使用」で接続
Bedrock KBのコンソールでナレッジベースを作成する際、ベクトルストアの選択画面で 「既存のOpenSearch Serverlessコレクションを使用」 を選び、先ほど作成したNextGenコレクションのARNと、手順2で作成したインデックス名を指定します。フィールドマッピングはインデックス作成時のフィールド名をそのまま指定します。
- データソース(S3 バケット等)を設定
- 埋め込みモデルとベクトルストア
- 埋め込みモデル: 既存 KB と同じものを選択
- ベクトルストア: 「既存のベクトルストアを使用」
- OpenSearch Serverless を選択し、以下を入力
- Collection ARN: Step 1 でメモしたもの
- ベクトルインデックス名:
new-rag-index(Step 3 で作成した名前) - ベクトルフィールド名:
bedrock-knowledge-base-default-vector - テキストフィールド名:
AMAZON_BEDROCK_TEXT_CHUNK - メタデータフィールド名:
AMAZON_BEDROCK_METADATA
- 確認して作成
4. データソースの同期(Ingest)— 成功する
S3データソースを追加し、同期を実行します。チャンキング・ベクトル化・インデックス登録まで正常に完了します。
OpenSearchのダッシュボードからインデックスを確認すると、bedrock-kb-*-index という名前で実際にドキュメントが登録されていることが確認できます。フィールドには AMAZON_BEDROCK_TEXT_CHUNK、bedrock-knowledge-base-default-vector などのBedrock KB標準のフィールドが含まれています。
5. Retrieve API(検索)— ここで失敗する
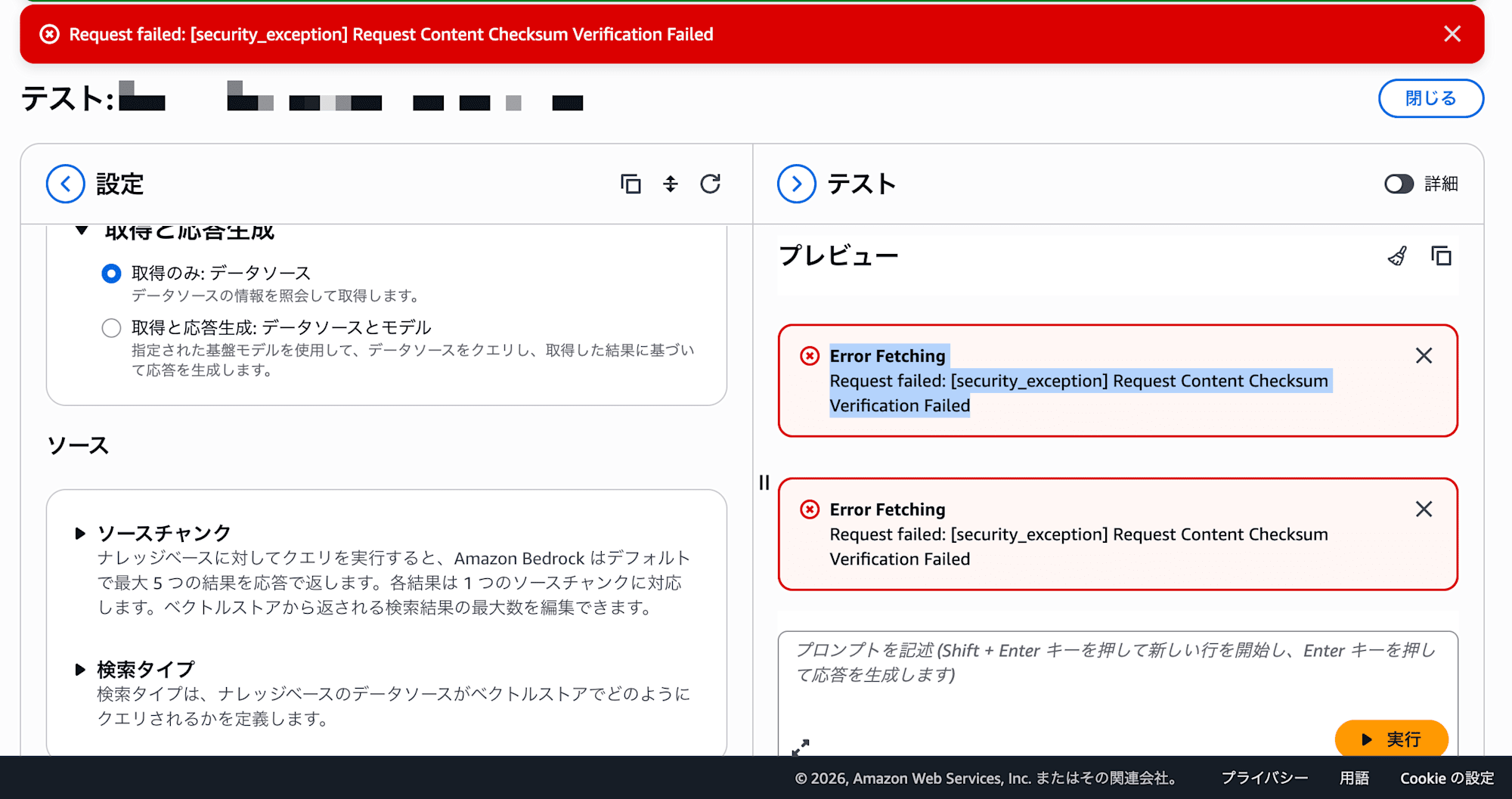
ここまで順調だったので検索も動くだろうと思いきや、Bedrock KBのRetrieve APIを呼び出すと以下のエラーが返ります。
Request failed: [security_exception] Request Content Checksum Verification Failed
Bedrock KBのPlayground(テスト検索機能)でも同様のエラーが発生します。データは確かにそこにあるのに、検索だけができないという状態です。
原因: SigV4署名のコンテンツチェックサム不整合
調査の結果、原因はBedrock KBの内部クライアントが行うSigV4署名と、OpenSearch Serverless NextGenが期待する署名の間にある不整合でした。
具体的には、POSTリクエスト時の x-amz-content-sha256 ヘッダー(リクエストボディのSHA256ハッシュ)の計算方法に差異があり、NextGen側がチェックサム検証で弾いてしまいます。
参考になった記事:
- 次世代 Amazon OpenSearch Serverless が一般提供開始、待機コストゼロになったのでベクトル検索を試してみた — Bedrock KBとOpenSearch Serverlessの組み合わせに関する調査
なぜインジェストは動くのか?
これは推測になりますが、インジェスト処理はBedrock KB側の異なる内部パス(おそらくバッチ処理用の別クライアント)を通っており、そちらではSigV4署名が正しく行われているためと考えられます。一方、Retrieve APIはリアルタイム検索用の別のクライアント経由でOpenSearchにアクセスしており、こちらのSigV4署名実装がNextGenの検証と合致しません。
この問題はAWS側の内部実装に起因するため、将来的にAWSのアップデートで解消される可能性があります。
回避策: opensearch-pyでリトリーブだけ直接クエリする
Bedrock KBのRetrieve APIが使えないなら、検索部分だけ自前でOpenSearchに直接クエリすればいい — というのが今回とった回避策です。
重要なのは、インジェスト(データ同期)はBedrock KBのまま使い続けるという点です。壊れているのはRetrieve APIだけなので、変更が必要なのもリトリーブ部分だけです。ドキュメントの再インジェストは不要で、Bedrock KBが既にNextGenコレクションに入れてくれたデータをそのまま検索できます。
アーキテクチャの変更
インジェスト(変更なし):
S3 → Bedrock KB Ingest → OpenSearch NextGen ← これはそのまま動く
リトリーブ(ここだけ変更):
変更前: アプリ → Bedrock KB Retrieve API → OpenSearch NextGen ← ❌ 壊れている
変更後: アプリ → [クエリをembed] → opensearch-py → OpenSearch NextGen ← ✅
(Titan V2) (SigV4 / aoss)
Bedrock KBのRetrieve APIが内部で行っていた処理(クエリの埋め込み → KNN検索 → 結果の返却)を、自分のアプリケーション側で再現します。全ドキュメントの埋め込みやインデックス作成は不要 — 検索クエリ1件ごとにTitan V2でベクトル化するだけです。
実装のポイント
1. 検索クエリの埋め込み(Embedding)
Bedrock KBが内部で使っていたのと同じモデル(Amazon Titan Embeddings V2、1024次元)を bedrock-runtime のInvoke Model APIで直接呼び出します。検索のたびにクエリテキストをベクトル化します(1回のAPI呼び出し、数十ミリ秒)。
import boto3, json
client = boto3.client("bedrock-runtime", region_name="ap-northeast-1")
def embed_text(text: str) -> list[float]:
response = client.invoke_model(
modelId="amazon.titan-embed-text-v2:0",
body=json.dumps({
"inputText": text,
"dimensions": 1024,
"normalize": True,
}),
)
return json.loads(response["body"].read())["embedding"]
2. OpenSearch接続(SigV4認証)
opensearch-pyの AWSV4SignerAuth を使い、サービス名 aoss で署名します。
from opensearchpy import OpenSearch, RequestsHttpConnection, AWSV4SignerAuth
credentials = boto3.Session().get_credentials()
auth = AWSV4SignerAuth(credentials, "ap-northeast-1", "aoss")
client = OpenSearch(
hosts=[{"host": "<collection-id>.aoss.ap-northeast-1.on.aws", "port": 443}],
http_auth=auth,
use_ssl=True,
verify_certs=True,
connection_class=RequestsHttpConnection,
)
ここで重要なのは、opensearch-pyのSigV4署名はNextGenで正しく動作するということです。Bedrock KBの内部クライアントの署名だけが壊れているので、自前で正しくSigV4署名すれば問題ありません。
3. KNN検索(既存インデックスのフィールド名をそのまま使う)
Bedrock KBがインジェスト時に作成したインデックスには、Bedrock KB独自のフィールド名が使われています。直接クエリする場合はこれらのフィールド名をそのまま指定します。
search_body = {
"size": 5,
"_source": [
"AMAZON_BEDROCK_TEXT_CHUNK",
"AMAZON_BEDROCK_METADATA",
"x-amz-bedrock-kb-source-uri",
],
"query": {
"knn": {
"bedrock-knowledge-base-default-vector": {
"vector": query_embedding,
"k": 5,
}
}
},
}
response = client.search(index="bedrock-kb-<your>-index", body=search_body)
| Bedrock KBフィールド名 | 用途 |
|---|---|
bedrock-knowledge-base-default-vector |
ベクトル埋め込み(KNN検索対象) |
AMAZON_BEDROCK_TEXT_CHUNK |
チャンクのテキスト内容 |
AMAZON_BEDROCK_METADATA |
メタデータ |
x-amz-bedrock-kb-source-uri |
ソースファイルのS3 URI |
ハマりポイント: OpenSearch Serverlessの二層認証
直接クエリの実装後、最初のテストで403 Forbiddenが返りました。OpenSearchのデータアクセスポリシーにEC2ロールを追加済みだったので、なぜ403なのか分からず混乱しました。
原因は、OpenSearch Serverlessには二層の認証が必要だったことです。両方設定しないと403になります。
| レイヤー | 設定場所 | 必要な権限 |
|---|---|---|
| IAMポリシー | IAMロール(EC2等)にアタッチ | aoss:APIAccessAll |
| データアクセスポリシー | OpenSearch Serverlessコンソール | aoss:ReadDocument, aoss:DescribeIndex 等 |
レイヤー1: IAMポリシー
EC2インスタンスロール(またはアプリケーションが使用するIAMロール)に、以下のインラインポリシーをアタッチします。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "aoss:APIAccessAll",
"Resource": "arn:aws:aoss:ap-northeast-1:<account-id>:collection/*"
}
]
}
レイヤー2: データアクセスポリシー
OpenSearch Serverlessのコンソールで、コレクションの データアクセスポリシー を設定します。
[
{
"Rules": [
{
"ResourceType": "index",
"Resource": ["index/<collection-name>/*"],
"Permission": [
"aoss:ReadDocument",
"aoss:DescribeIndex"
]
}
],
"Principal": [
"arn:aws:iam::<account-id>:role/<your-ec2-role>"
]
}
]
注意: Bedrock KBでナレッジベースを作成した際に、Bedrock用のデータアクセスポリシーは自動的に設定されますが、それはBedrock KBのサービスロール用です。アプリケーションから直接クエリする場合は、アプリケーションのIAMロールを別途Principalに追加する必要があります。
デバッグのコツ
403が返った場合、opensearch-pyのエラーオブジェクトから詳細を取得できます。
try:
client.search(index=index_name, body=search_body)
except Exception as e:
detail = getattr(e, "info", None) or getattr(e, "body", None)
logger.error("OpenSearch failed: %s | detail=%s", e, detail)
これで {'status': 403, 'error': {'reason': '403 Forbidden', 'type': 'Forbidden'}} のような詳細が取れます。残念ながらOpenSearch Serverlessの403はIAM側の問題かデータアクセスポリシー側の問題か区別がつかないので、両方確認してください。
まとめ
| 項目 | 状況 |
|---|---|
| Bedrock KB → NextGen インジェスト | ✅ 動作する |
| Bedrock KB → NextGen リトリーブ | ❌ SigV4チェックサムエラーで失敗 |
| opensearch-py → NextGen 直接クエリ | ✅ 動作する |
Bedrock Knowledge BasesのRetrieve APIはOpenSearch Serverless NextGenで現時点では動作しません。データの同期(インジェスト)は正常に行えるため、「データは入ったのに検索できない」という紛らわしい状態になります。
回避策のポイントは、変更が必要なのはリトリーブ部分だけということです。
- インジェスト: Bedrock KBのまま使い続ける(NextGenでも正常に動作)
- リトリーブ: opensearch-pyで検索クエリをTitan V2でベクトル化 → KNN検索
Bedrock KBが作成したインデックスとフィールド名をそのまま使うため、データの再インジェストは不要です。検索クエリのベクトル化(1回数十ミリ秒)を追加するだけで、既存のデータをそのまま活用できます。
なお、opensearch-pyから直接クエリする際はOpenSearch Serverlessの二層認証(IAMポリシー + データアクセスポリシー)の設定が必要です。片方だけでは403になるので注意してください。
この問題はAWS側の対応で将来的に解消される可能性がありますが、現時点(2026年6月1日)ではNextGenでBedrock KBを使う場合はリトリーブの直接クエリが必要です。











