![[Amazon Bedrock] S3 Vectors + Rerank の Knowledge Base を CDK で一撃デプロイ ― ハマりどころと解決策](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-e3065182082062711612153bbdcf1d96/c04359de689df2f56eb066576ab63fb5/amazon-bedrock?w=3840&fm=webp)
[Amazon Bedrock] S3 Vectors + Rerank の Knowledge Base を CDK で一撃デプロイ ― ハマりどころと解決策
1 はじめに
製造ビジネステクノロジー部の平内(SIN)です。
Amazon Bedrock の Knowledge Bases は、ドキュメントをベクトル化して検索し、生成AIで回答を生成する RAG(Retrieval-Augmented Generation)を手軽に構築できるサービスです。ベクトルストアとしては OpenSearch Serverless や Aurora PostgreSQL などが利用可能ですが、2025年に登場した Amazon S3 Vectors を使用すると、別途ベクトルデータベースを構築する必要がなく、S3 の既存のセキュリティや耐久性をそのまま活用できます。
今回は、この S3 Vectors を使った Knowledge Base に、検索精度を向上させるリランカー(Amazon Rerank v1)を組み合わせた RAG 環境を、cdk deploy 一発で構築できる CDK を作成してみました。S3 にドキュメントをアップロードすると自動的に Knowledge Base が同期される仕組みも実装しているため、デプロイ後は S3 にデータを配置するだけですぐにクエリを試すことができます。
実装にあたっては、公式ドキュメントだけでは解決が難しい「ハマりどころ」にいくつか遭遇しました。本記事では、CDK の実装内容とともに、それらの問題と解決策をまとめて紹介します。
リポジトリは以下で公開しています。
https://github.com/furuya02/bedrock-kb-s3vectors-rerank-rag
2 アーキテクチャ
全体の構成図は以下のとおりです。
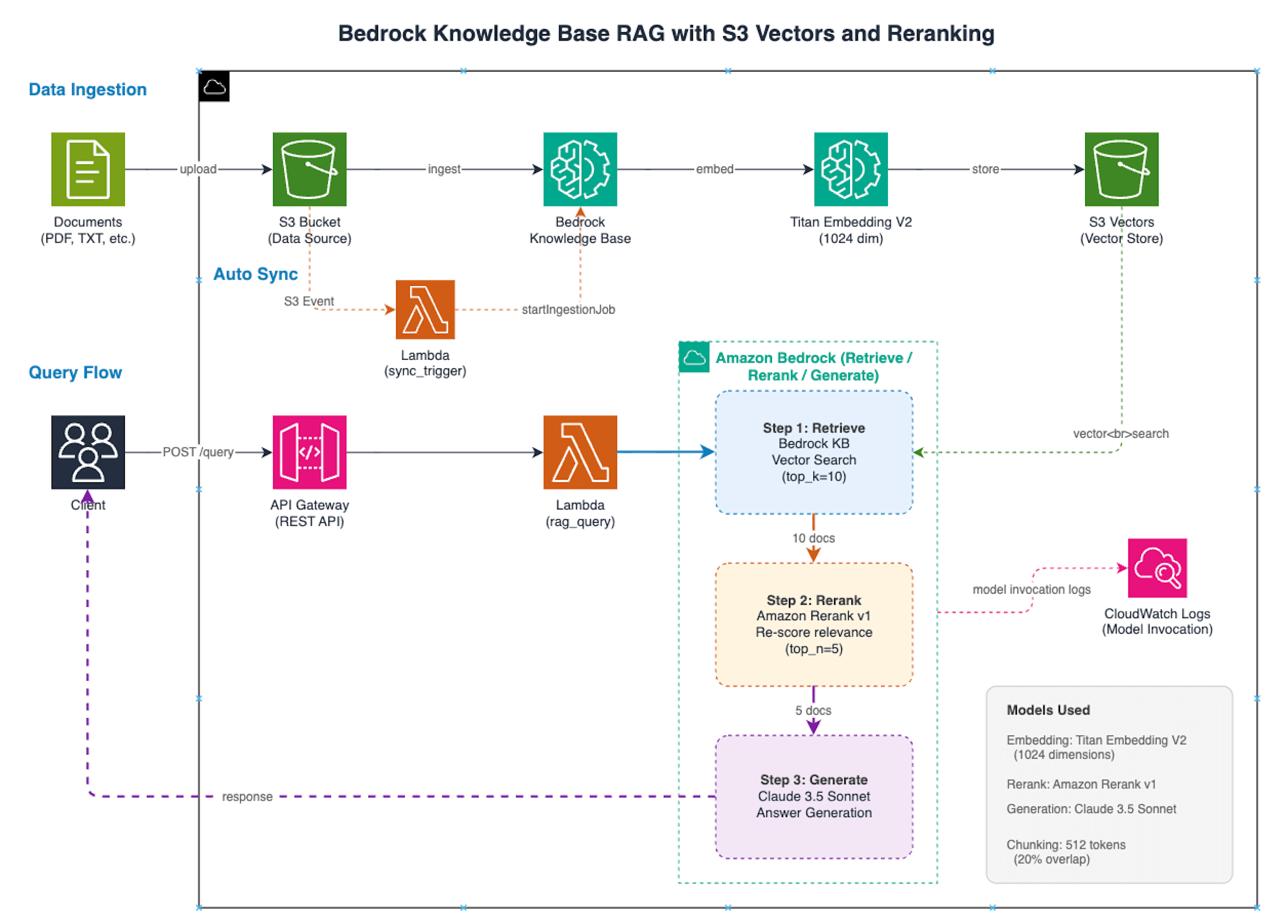
大きく3つのフローがあります。
Data Ingestion(データ取り込み)
S3 バケットにアップロードされたドキュメントを、Bedrock Knowledge Base が取り込みます。ドキュメントは512トークン(20%オーバーラップ)でチャンク分割され、Titan Embedding V2(1024次元)でベクトル化された後、S3 Vectors に格納されます。
Auto Sync(自動同期)
S3 バケットへのファイル追加・削除を S3 Event Notification で検知し、Lambda(sync_trigger)経由で startIngestionJob を自動的に呼び出します。手動で同期を実行する必要はありません。
Query Flow(クエリ処理)
クライアントから API Gateway 経由で Lambda(rag_query)にリクエストが送られると、以下の3ステップで処理されます。
- Retrieve - Bedrock KB からベクトル検索で関連ドキュメントを取得(top_k=10)
- Rerank - Amazon Rerank v1 で関連度スコアを再評価し、順序を並び替え(top_n=5)
- Generate - リランク後のドキュメントをコンテキストとして Claude 3.5 Sonnet で回答を生成
これらの処理はすべて Amazon Bedrock の API として実行され、モデル呼び出しログは CloudWatch Logs に記録されます。
3 デプロイ
前提条件
デプロイにあたり、以下の Bedrock モデルアクセスを事前に有効化しておく必要があります。
- Amazon Titan Text Embeddings V2
- Amazon Rerank v1
- Anthropic Claude 3.5 Sonnet v2(APAC 推論プロファイル)
デプロイ手順
git clone https://github.com/furuya02/bedrock-kb-s3vectors-rerank-rag.git
cd bedrock-kb-s3vectors-rerank-rag/cdk
pnpm install
pnpm cdk bootstrap # 初回のみ
pnpm cdk deploy
デプロイが完了すると、以下が自動的に作成されます。
- S3 Vectors のベクトルバケットとインデックス
- Bedrock Knowledge Base
- S3 データソースバケット
- S3 イベントによる自動同期(Lambda)
- RAG クエリ API(Lambda + API Gateway)
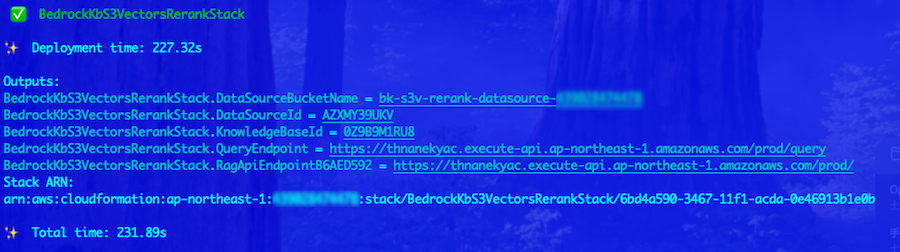
デプロイされるリソース
cdk deploy によって、以下のリソースが作成されます。
| リソース | 説明 |
|---|---|
| S3 Bucket | ドキュメントデータソース |
| S3 Vectors | ベクトルバケットとインデックス |
| Bedrock Knowledge Base | S3 Vectors を使用した RAG ナレッジベース |
| Bedrock Data Source | S3 データソース設定 |
| Lambda Function(rag_query) | RAG クエリハンドラー |
| Lambda Function(sync_trigger) | S3 イベントで KB 自動同期 |
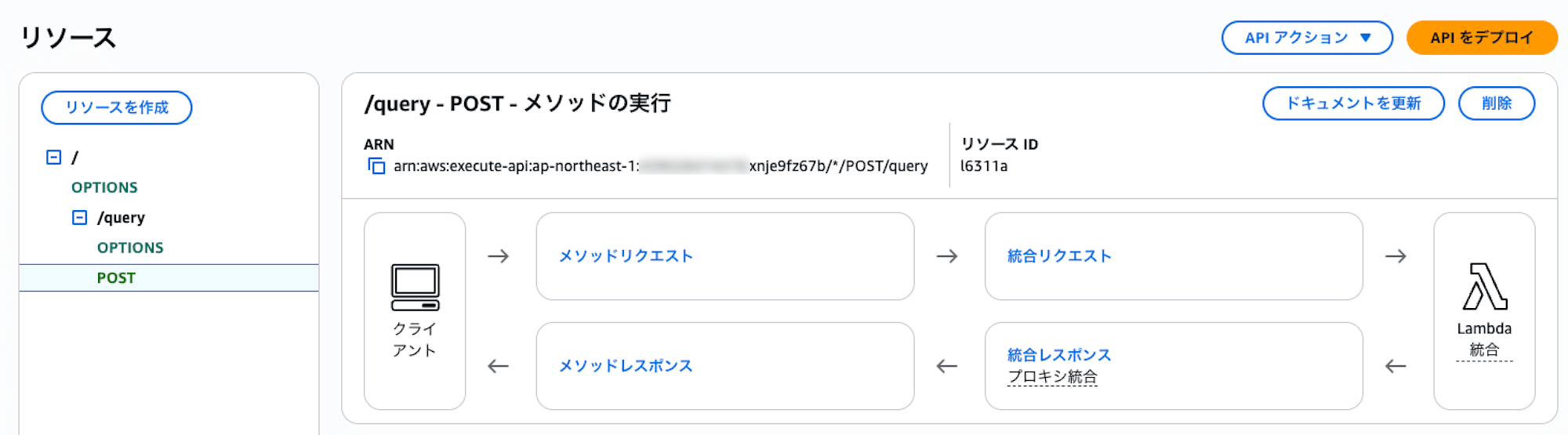
| API Gateway | REST API エンドポイント |
API Gateway には /query エンドポイントが作成され、POST リクエストで RAG クエリを実行できます。
Knowledge Base は S3 Vectors をベクトルストアとして構成されます。

Data Source には、ドキュメント格納用の S3 バケットが紐づいています。

デプロイ後、S3 バケットにドキュメントをアップロードすると自動的に Knowledge Base の同期が実行されます。同梱のサンプルデータを使って動作確認できます。
aws s3 sync sample_data/ s3://<DataSourceBucketName>/
同期完了まで1〜2分待てば、クエリを実行できます。
なお、S3 バケットに配置できるドキュメントはテキストファイルに限りません。Bedrock Knowledge Base は以下の形式に対応しており、内容を自動的にテキスト抽出してベクトル化します。
- プレーンテキスト(.txt)、PDF(.pdf)、Word(.docx)、HTML(.html)、Markdown(.md)、CSV(.csv)、Excel(.xlsx)、PowerPoint(.pptx)
4 CDK の実装ポイント
CDK の実装について簡単に紹介させてください。
コードは GitHub リポジトリ をご参照ください。
S3 Vectors の作成
S3 Vectors のベクトルバケットとインデックスは、CDK の L1 コンストラクト(CfnVectorBucket / CfnIndex)で作成しています。
const vectorBucket = new s3vectors.CfnVectorBucket(this, "VectorBucket", {
vectorBucketName: vectorBucketName,
});
const vectorIndex = new s3vectors.CfnIndex(this, "VectorIndex", {
vectorBucketName: vectorBucketName,
indexName: vectorIndexName,
dimension: 1024,
distanceMetric: "cosine",
dataType: "float32",
metadataConfiguration: {
nonFilterableMetadataKeys: [
"AMAZON_BEDROCK_TEXT_CHUNK",
"AMAZON_BEDROCK_METADATA",
],
},
});
チャンキング設定
データソースの定義では、ドキュメントのチャンク分割方法を指定しています。今回は FIXED_SIZE(固定サイズ)を採用し、512トークンごとに分割、チャンク間で20%のオーバーラップを設けています。オーバーラップにより、チャンクの境界で文脈が途切れるのを緩和し、検索精度の向上が期待できます。
vectorIngestionConfiguration: {
chunkingConfiguration: {
chunkingStrategy: "FIXED_SIZE",
fixedSizeChunkingConfiguration: {
maxTokens: 512,
overlapPercentage: 20,
},
},
},
FIXED_SIZE 以外にも以下の戦略が選択できます。
| 戦略 | 説明 |
|---|---|
| FIXED_SIZE | 固定トークン数で分割 |
| HIERARCHICAL | 親チャンク・子チャンクの階層構造で分割 |
| SEMANTIC | 意味的なまとまりで分割 |
| NONE | チャンク分割しない |
S3 イベントによる自動同期
S3 バケットへのファイル追加・削除時に、Lambda を経由して自動的にインジェストジョブを開始しています。
dataBucket.addEventNotification(
s3.EventType.OBJECT_CREATED,
new s3n.LambdaDestination(syncTriggerLambda)
);
dataBucket.addEventNotification(
s3.EventType.OBJECT_REMOVED,
new s3n.LambdaDestination(syncTriggerLambda)
);
sync_trigger Lambda は、startIngestionJob を呼び出すだけのシンプルな実装です。
def lambda_handler(event: dict, context: object) -> None:
client.start_ingestion_job(
knowledgeBaseId=os.environ["KNOWLEDGE_BASE_ID"],
dataSourceId=os.environ["DATA_SOURCE_ID"],
)
5 RAG クエリの処理フロー
Lambda(rag_query)では、3段階のパイプラインで RAG クエリを処理しています。完全なコードは GitHub リポジトリ を参照してください。
Step 1: Knowledge Base からの検索
response = bedrock_agent.retrieve(
knowledgeBaseId=KNOWLEDGE_BASE_ID,
retrievalQuery={"text": query},
retrievalConfiguration={
"vectorSearchConfiguration": {"numberOfResults": top_k}
},
)
Step 2: リランクによる関連度の再評価
response = bedrock_agent.rerank(
queries=[{"type": "TEXT", "textQuery": {"text": query}}],
sources=text_sources,
rerankingConfiguration={
"type": "BEDROCK_RERANKING_MODEL",
"bedrockRerankingConfiguration": {
"modelConfiguration": {
"modelArn": f"arn:aws:bedrock:{REGION}::foundation-model/{RERANK_MODEL_ID}",
},
"numberOfResults": min(top_n, len(documents)),
},
},
)
Step 3: 回答生成
リランク後の上位ドキュメントをコンテキストとして、Claude 3.5 Sonnet で回答を生成します。
response = bedrock.invoke_model(
modelId=GENERATION_MODEL_ID, # apac.anthropic.claude-3-5-sonnet-20241022-v2:0
contentType="application/json",
accept="application/json",
body=body,
)
6 動作確認
クエリの実行
デプロイ出力に表示される QueryEndpoint を使用してクエリを実行します。
curl -X POST <QueryEndpoint> \
-H "Content-Type: application/json" \
-d '{"query": "S3 Vectorsとは何ですか?"}'
以下のようなレスポンスが返ります。リランクのスコア(rerank_score)とともに、ソース情報も確認できます。
{
"answer": "コンテキストによると、S3 Vectorsは2025年に発表された、Amazon S3の新機能で、以下の特徴があります...",
"sources": [
{
"content": "S3 Standardの場合、東京リージョンでは最初の50TBまで1GBあたり...",
"rerank_score": 0.9603611826896667,
"location": {"s3Location": {"uri": "s3://bk-s3v-rerank-datasource-XXXXXXXXXXXXXXXX/amazon_s3.txt"}}
}
],
"retrieved_count": 10,
"reranked_count": 5
}
CloudWatch Logs でのリランク動作確認
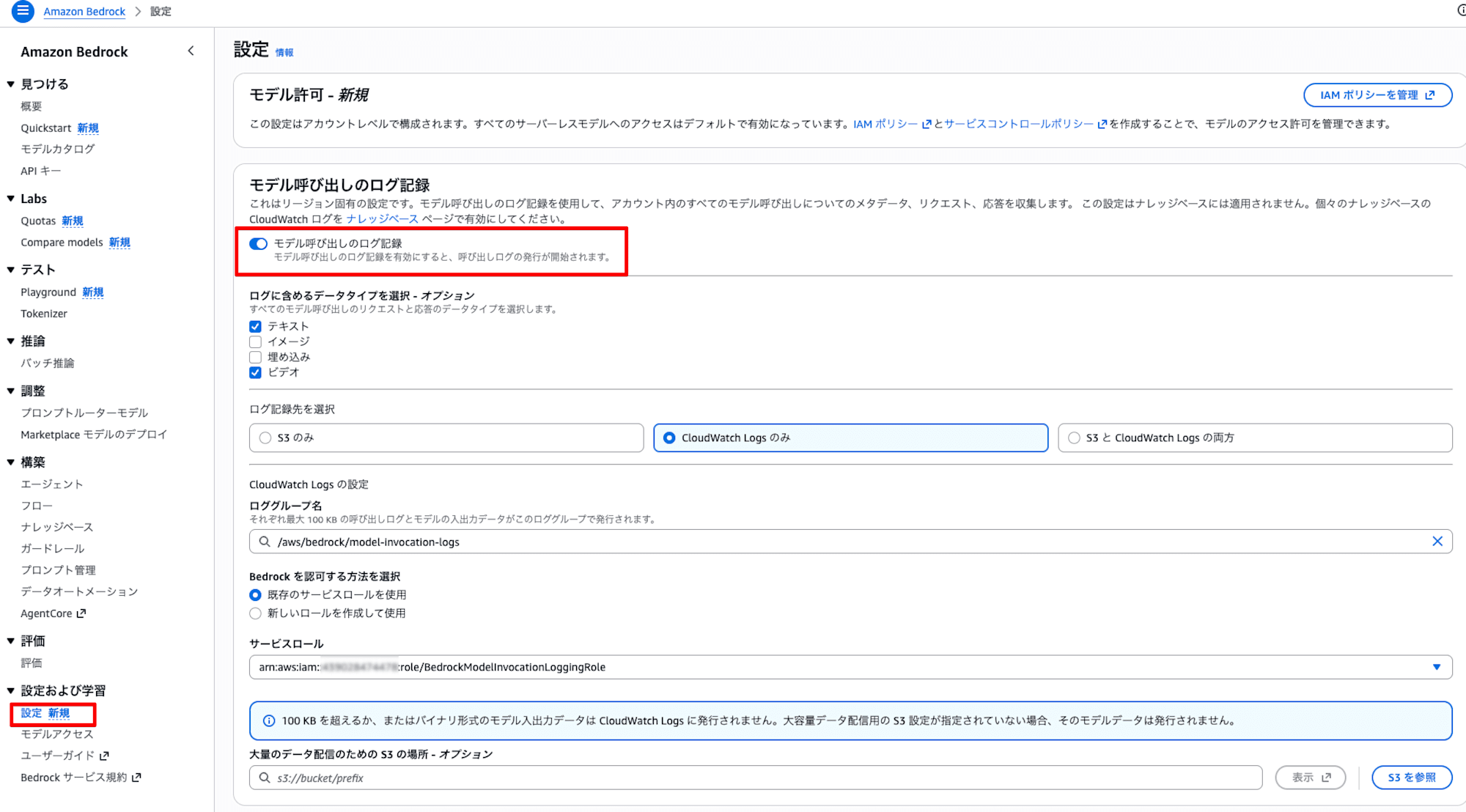
Bedrock のモデル呼び出しログを有効にすると、CloudWatch Logs でリランクの入出力を詳細に確認できます。
Bedrock コンソールの Settings から Model invocation logging を有効化し、以下のコマンドでログを確認します。
aws logs filter-log-events \
--log-group-name /aws/bedrock/model-invocation-logs \
--filter-pattern '"amazon.rerank"' \
--region ap-northeast-1
ログには、ベクトル検索でヒットしたドキュメント一覧(inputBodyJson.documents)と、リランク後の各ドキュメントの関連度スコア(outputBodyJson.results)が記録されています。
{
"input": {
"inputBodyJson": {
"documents": ["ドキュメント1...", "ドキュメント2...", "..."],
"query": "S3 Vectorsとは何ですか?"
}
},
"output": {
"outputBodyJson": {
"results": [
{"index": 0, "relevance_score": 0.9604},
{"index": 3, "relevance_score": 0.0062},
{"index": 1, "relevance_score": 0.0007}
]
}
}
}
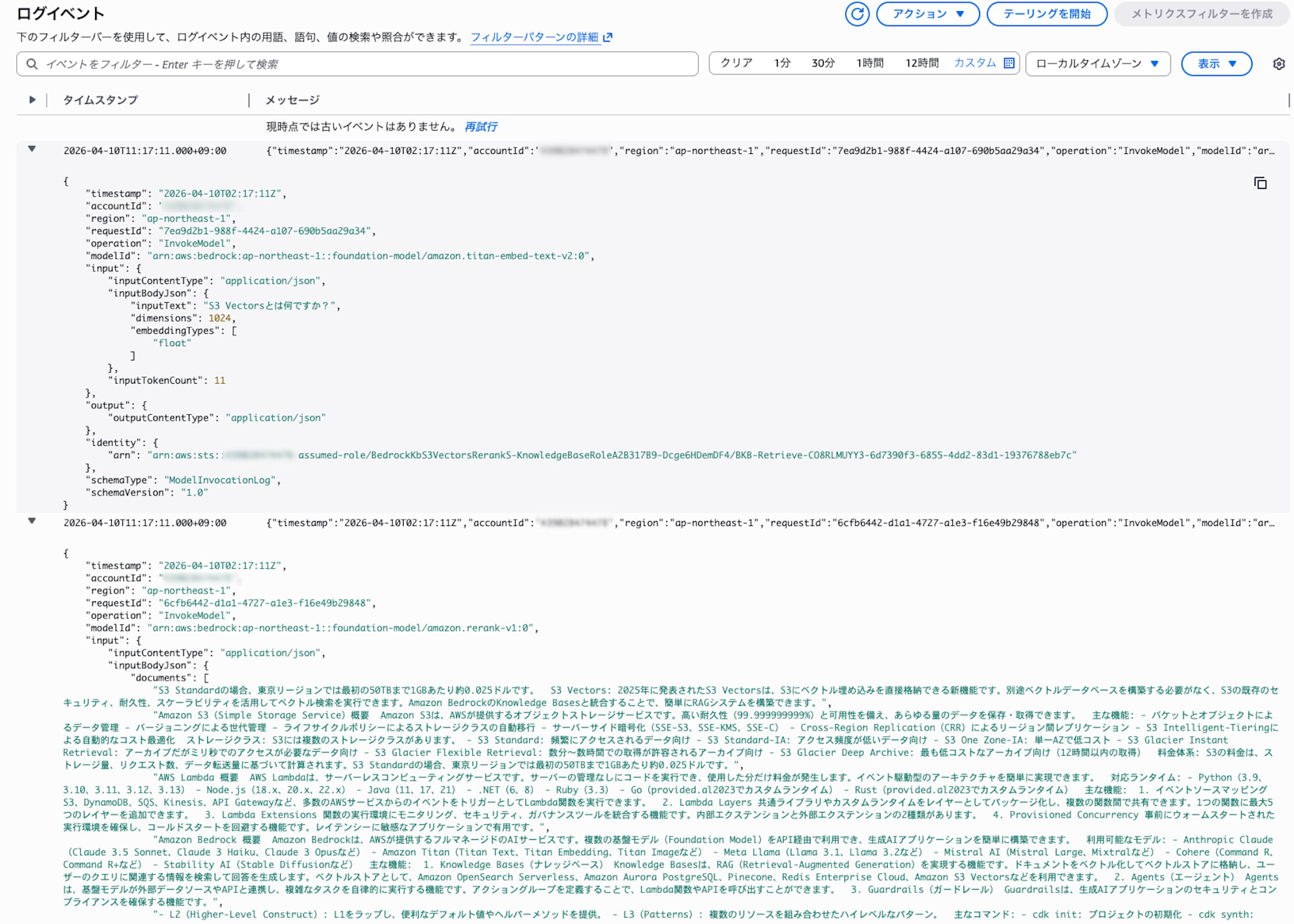
このログから、リランクによって relevance_score: 0.9604 のドキュメントが最上位に選ばれ、関連度の低いドキュメント(0.0007 等)が下位に再配置されていることがわかります。ベクトル検索だけでは捉えきれない意味的な関連性を、リランクが補完していることを確認できます。
なお、モデル呼び出しログはアカウントレベルの設定であり、今回の CDKデプロイでは有効化されません。無効になっている場合は、手動で設定が必要です。
7 ハマりどころと解決策
CDK の実装にあたり、いくつかのハマりどころを感じたので共有させてください。
(1) Claude 3.5 Sonnet v2 の推論プロファイル
東京リージョン(ap-northeast-1)で Claude 3.5 Sonnet v2 を InvokeModel で呼び出したところ、「on-demand throughput isn't supported」というエラーが発生しました。この場合、推論プロファイル経由での呼び出しが必要です。
apac.anthropic.claude-3-5-sonnet-20241022-v2:0
利用可能なプロファイルは以下のコマンドで確認できます。
aws bedrock list-inference-profiles --region ap-northeast-1
(2) クロスリージョン推論の IAM 権限
APAC 推論プロファイルは、ルーティング先のリージョンが動的に決まります(ap-northeast-1、ap-northeast-2、ap-southeast-1 等)。IAM ポリシーで基盤モデルのリソース ARN を特定リージョンに限定すると、ルーティング先で AccessDeniedException が発生しました。
今回は基盤モデルのリージョンをワイルドカードにすることで対応しました。なお、AWS の公式ドキュメントでは、推論プロファイル ARN、リージョン別基盤モデル ARN、グローバル基盤モデル ARN の3つを個別に指定する方法も紹介されています。
// 特定リージョンのみだとルーティング先で権限エラー
`arn:aws:bedrock:ap-northeast-1::foundation-model/anthropic.claude-3-5-sonnet-20241022-v2:0`
// リージョンをワイルドカードにすることで対応
`arn:aws:bedrock:*::foundation-model/anthropic.claude-3-5-sonnet-20241022-v2:0`
(3) bedrock:Rerank の IAM 権限
bedrock:Rerank アクションは、特定のリソース ARN に紐づけると権限エラーになります。bedrock:Retrieve や bedrock:InvokeModel と同じ IAM ステートメントに含めるのではなく、resources: ["*"] で別ステートメントとして定義する必要があります。
// Retrieve / InvokeModel のステートメント
ragQueryLambda.addToRolePolicy(new iam.PolicyStatement({
actions: ["bedrock:Retrieve", "bedrock:InvokeModel"],
resources: [knowledgeBase.attrKnowledgeBaseArn, /* ... */],
}));
// Rerank は別ステートメントで resources: ["*"]
ragQueryLambda.addToRolePolicy(new iam.PolicyStatement({
actions: ["bedrock:Rerank"],
resources: ["*"],
}));
(4) S3 Vectors のメタデータ上限(2048バイト)
S3 Vectors のデフォルト設定では、すべてのメタデータがフィルタリング可能(filterable)として扱われます。フィルタリングメタデータの上限は2048バイトです。Bedrock KB はチャンクのテキストやソース情報をメタデータとして格納するため、この上限を容易に超過し、インジェストが失敗します。
対策として、インデックス作成時に metadataConfiguration で nonFilterableMetadataKeys を指定します。今回は以下の設定でインジェストが成功しました。
metadataConfiguration: {
nonFilterableMetadataKeys: [
"AMAZON_BEDROCK_TEXT_CHUNK",
"AMAZON_BEDROCK_METADATA",
],
},
なお、AWS ドキュメントでは AMAZON_BEDROCK_TEXT というキー名で紹介されている箇所もあります。環境やバージョンによって異なる可能性がありますので、インジェスト失敗時はエラーメッセージを確認の上、適切なキー名を設定してください。
(5) Rerank API の numberOfResults 制限
Rerank API の numberOfResults がソースドキュメント数を超えると、ValidationException が発生します。インジェスト直後やドキュメント数が少ない環境で発生しやすい問題です。
# 誤: 固定値
"numberOfResults": top_n
# 正: ドキュメント数でクランプ
"numberOfResults": min(top_n, len(documents))
8 最後に
S3 Vectors を使用した Knowledge Base は、OpenSearch Serverless や Aurora PostgreSQL と比較して、追加のベクトルデータベースが不要なため、構成がシンプルでコスト面でもメリットがあります。リランクを組み合わせることで、ベクトル検索だけでは難しい意味的な関連性の補完も可能です。
今回作成した CDK は以下のリポジトリで公開しています。cdk deploy で RAG 環境が構築でき、S3 にドキュメントをアップロードするだけで自動的に同期されますので、ぜひお試しください。










