
Amazon Bedrock Managed Knowledge Base を触ってみた
はじめに
こんにちは、ドライブ練習中のコンサル部の神野(じんの)です。
2026年6月17日、Amazon Bedrock Managed Knowledge Base がリリースされました!ベクトルストアの構築もデータパイプラインの管理も不要で、フルマネージドな RAG を使用できるびっくりなサービスです。
概要やコンソールからの操作については下記の記事で紹介されています。
色々と便利そうだなーと思いつつ何が今までのRAGと違うのかは確認してみたく、今回は API(Boto3)を中心に検証していきます。Knowledge Base の作成からデータソース接続、ドキュメント投入、検索モードの比較、そして Agentic Retrieval による複数 Knowledge Bases の横断検索など色々と試してみました!
本記事で使用したスクリプトとテストデータは GitHub リポジトリで公開しています。uv sync で環境構築して 01_setup.py から順に実行すれば、記事の検証をそのまま再現できます。
前提
今回は下記バージョンを使用しました。
| 項目 | バージョン / 値 |
|---|---|
| Python | 3.12 |
| uv | 0.7+ |
| boto3 / botocore | 1.43.32 |
| リージョン | us-east-1 |
Managed Knowledge Base
まずは今回リリースされた Managed Knowledge Base がどういったものか確認してみます。
Managed Knowledge Base は従来の Self-managed Knowledge Base と比較して、以下の点が異なります。
| 項目 | Managed | Self-managed |
|---|---|---|
| ベクトルストア | AWS が完全管理(構築・運用不要) | ユーザーが選択・管理(OpenSearch, Aurora, S3 Vectors 等) |
| 埋め込みモデル | マネージドモデル(無料)or Bedrock モデルから選択 | ユーザーが指定 |
| リランキング | マネージドリランカー内蔵(無料) | 別途設定が必要 |
| Agentic Retrieval | 対応 | 非対応 |
| AgentCore Gateway 連携 | ネイティブ対応 | 非対応 |
従来の Self-managed ではベクトルストアを OpenSearch Serverless や S3 Vectors などから選んで自分で構築・管理する必要がありましたが、Managed ではその辺りがすべてサービス側で提供されます。
特に嬉しいのは AgentCore Gateway のネイティブ連携でしょうか。Agent と RAG を繋げたいのはあるあるだと思うので、接続が簡単になるのは良きですね。
ここからは特徴を詳しくみてみます。
埋め込みモデルの選択肢
埋め込みモデルは2つの選択肢があります。
- Managed embeddings model(推奨)
- AWS が管理する埋め込みモデルを使用します。追加コストなしで利用でき、チャンキング戦略も自動で最適化されます。コンソール上ではこちらの使用が推奨されていました。
- Bedrock embeddings model
- Amazon Nova Multimodal Embeddings、Titan Text Embeddings、Cohere Embed などから選択できます。こちらを選ぶとチャンキング戦略(Default chunking / Fixed-size chunking / No chunking)やチャンクサイズを自分で設定できますが、モデル利用料が別途かかります
今回の検証ではマネージドモデルを使用しています。自分でチャンキング戦略を制御する要件がなければ、無料で手間もかからないマネージドモデルから始めるのが良さそうですね。
マネージドパーサー(Smart Parsing)
ドキュメントの解析にはマネージドパーサー(Smart Parsing)が使われます。.txt / .md / .csv / .html / .pdf / .pptx / .docx を自動判別して処理し、テーブル構造の維持や埋め込み画像の解釈も行います。こちらも追加コストなしで利用できます。
従来だとデフォルトパーサーでは図などの情報は読み取れないため、基盤モデルパーサーを使う必要があったのですがこちらもマネージドに対応しているんですね!嬉しい!
検索 API
Managed Knowledge Base では主に2種類の検索 API が用意されています。単純にドキュメントを取得するRetrieveに加えて、AgenticRetrieveStreamといった強そうなAPIも用意されています。
| API | 用途 | 特徴 |
|---|---|---|
| Retrieve | シンプルなベクトル検索 | チャンクを返却する。マネージドリランカーの有無を切り替え可能 |
| AgenticRetrieveStream | LLM を使った高度な検索 | クエリを分解して複数回検索し、回答をストリーミング生成。複数 Knowledge Bases の横断検索にも対応 |
従来の RetrieveAndGenerate API は Managed Knowledge Base では非対応ですが、AgenticRetrieveStream が回答生成まで含めてカバーしています。
AgenticRetrieveStreamは少しお値段が通常のRetrieveに比べてかかる代わりに複数のKnowledge Basesを参照できるのは嬉しいですね。
S3、Confluence、SharePointなどデータソースを分割しても横断検索できるのは嬉しいポイントかと思いました。
料金
| 機能 | 料金 |
|---|---|
| インデックスストレージ | $5.00 / GB(生データ)/ 月 |
| マルチモーダルパース(マネージドパーサー) | 無料 |
| 埋め込み生成(マネージドモデル) | 無料 |
| リランキング(マネージドリランカー) | 無料 |
| Standard Retrieval(Retrieve API) | $1.00 / 1,000 API コール |
| Agentic Retrieval(AgenticRetrieveStream) | $4.00 / 1,000 Agentic API コール + $1.00 / 1,000 Retrieve コール |
インデックスストレージに料金がかかるため、大量のデータを使用する場合は注意ですね。一方でパース・埋め込み・リランキングが無料なのは嬉しいですね。
上記はすべてマネージドモデルを使用した場合の料金です。埋め込みやリランキングにカスタムモデルを選択した場合は、別途モデル費用がかかります。
Agentic Retrieval は LLM がクエリを分解して複数回検索し、回答を生成してくれる仕組みです。このクエリ分解・回答生成に使う LLM はマネージド(AWS 側で選択)か、任意の Bedrock モデルを指定するか選べます。任意のモデルを指定した場合は $4.00 の Agentic API コール料金が不要になり、$1.00 / 1,000 Retrieve コール + 選択した LLM のモデル料金という構成になります。具体的な使い方は後半の AgenticRetrieveStream セクションで検証しています。
10GB / 月間10,000検索のケースで $60/月。Self-managed で OpenSearch Serverless(Classic)を使うと最低約 $300/月かかることを考えると、小〜中規模ではコスト効率が良さそうです。
早速試してみます。
Managed Knowledge Base を API で作成する
IAM ロール・S3 バケット・Knowledge Base・データソースの作成と同期は 01_setup.py にまとめています。
uv run scripts/01_setup.py
以下、各ステップのポイントを解説します。
IAM ロールと S3 バケットの準備
Managed Knowledge Bases 用の IAM ロールと、テストデータ用の S3 バケットを作成します。IAM ロールには Bedrock サービスからの AssumeRole を許可する信頼ポリシーと、S3 読み取り + Bedrock モデル呼び出しのインラインポリシーを設定します。
01_setup.py より抜粋(IAM ロール + S3 バケット作成)
import boto3
import json
iam = boto3.client('iam')
sts = boto3.client('sts')
account_id = sts.get_caller_identity()['Account']
ROLE_NAME = 'AmazonBedrockManagedKBRole-blog-test'
BUCKET_NAME = f'managed-kb-blog-test-{account_id}'
trust_policy = {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {"Service": "bedrock.amazonaws.com"},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {"aws:SourceAccount": account_id},
"ArnLike": {
"aws:SourceArn": f"arn:aws:bedrock:us-east-1:{account_id}:knowledge-base/*"
},
},
}
],
}
role = iam.create_role(
RoleName=ROLE_NAME,
AssumeRolePolicyDocument=json.dumps(trust_policy),
)
inline_policy = {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["s3:GetObject", "s3:ListBucket"],
"Resource": [
f"arn:aws:s3:::{BUCKET_NAME}",
f"arn:aws:s3:::{BUCKET_NAME}/*",
],
},
{
"Effect": "Allow",
"Action": ["bedrock:InvokeModel", "bedrock:InvokeModelWithResponseStream"],
"Resource": "*",
},
],
}
iam.put_role_policy(
RoleName=ROLE_NAME,
PolicyName='ManagedKBAccess',
PolicyDocument=json.dumps(inline_policy),
)
s3 = boto3.client('s3', region_name='us-east-1')
s3.create_bucket(Bucket=BUCKET_NAME)
Knowledge Base の作成
Managed Knowledge Bases の作成もシンプルです。knowledgeBaseConfiguration で type: 'MANAGED' を指定し、embeddingModelType: 'MANAGED' にすると、埋め込みモデルもサービス側で自動選択してくれます。
response = client.create_knowledge_base(
name='managed-kb-blog-test',
description='Managed Knowledge Base verification',
roleArn=ROLE_ARN,
knowledgeBaseConfiguration={
'type': 'MANAGED',
'managedKnowledgeBaseConfiguration': {
'embeddingModelType': 'MANAGED'
}
}
)
ステータスは約40秒で CREATING → ACTIVE に遷移しました。
データソースの接続
今までの違いとして、Managed Knowledge Bases のデータソースは従来の type: 'S3' ではなく type: 'MANAGED_KNOWLEDGE_BASE_CONNECTOR' を使います。従来の type: 'S3' を指定すると Unsupported data source type for MANAGED knowledge base type というエラーになるので注意してください。
connectorParameters の type で S3 / Confluence / SharePoint 等を切り替える設計になっています。
01_setup.py より抜粋(S3 データソースの接続)
ds_resp = client.create_data_source(
knowledgeBaseId=KB_ID,
name='blog-test-s3-docs',
dataSourceConfiguration={
'type': 'MANAGED_KNOWLEDGE_BASE_CONNECTOR',
'managedKnowledgeBaseConnectorConfiguration': {
'deletionProtectionConfiguration': {
'deletionProtectionStatus': 'DISABLED'
},
'connectorParameters': {
'type': 'S3',
'version': '1',
'connectionConfiguration': {
'bucketName': BUCKET_NAME,
'bucketOwnerAccountId': ACCOUNT_ID
}
}
}
},
dataDeletionPolicy='DELETE'
)
テストデータの投入
今回は Smart Parsing の検証を兼ねて、さまざまなフォーマットのドキュメントを用意しました。
| ファイル | フォーマット | 内容 |
|---|---|---|
| aws-overview.txt | テキスト | AWS サービス概要 |
| bedrock-details.txt | テキスト | Bedrock 詳細ガイド |
| pricing-comparison.md | Markdown | 料金比較表(テーブル含む) |
| agentcore-guide.txt | テキスト | AgentCore ガイド |
| aws-services.csv | CSV | サービス料金一覧 |
| well-architected.html | HTML | W-A Framework 説明(テーブル含む) |
| lambda-guide.pdf | Lambda ガイド(アーキテクチャ図入り) | |
| bedrock-managed-kb.pptx | PPTX | Managed Knowledge Bases スライド(アーキテクチャ図 + ユースケース) |
| ecs-vs-eks.docx | DOCX | ECS vs EKS 比較ガイド(比較テーブル入り) |
PDF にはサーバーレスアーキテクチャの構成図を、PPTX には Managed Knowledge Bases のアーキテクチャ図を埋め込んでいます。図の中のテキスト要素がちゃんと抽出されるかが気になるところです。
S3 にアップロードして同期を実行します。
import os
s3 = boto3.client('s3', region_name='us-east-1')
for fname in os.listdir('test-data'):
s3.upload_file(f'test-data/{fname}', BUCKET_NAME, f'documents/{fname}')
client.start_ingestion_job(knowledgeBaseId=KB_ID, dataSourceId=DS_ID)
Status: COMPLETE
{
"numberOfDocumentsScanned": 9,
"numberOfNewDocumentsIndexed": 9,
"numberOfDocumentsFailed": 0
}
9ドキュメント全てが失敗なくインデックスされました。Smart Parsing が .txt / .md / .csv / .html / .pdf / .pptx / .docx を自動判別して処理してくれています。
なお、データソース側のファイル変更を検知して自動的に同期が走るわけではなく、同期は StartIngestionJob API やコンソールから明示的に実行する必要があります。同期はインクリメンタル方式で、前回からの差分のみが処理されます。ここは従来と一緒みたいですね。
Each time you add, modify, or remove files from your data source, you must sync the data source so that it is re-indexed to the knowledge base. Syncing is incremental, so Amazon Bedrock only processes added, modified, or deleted documents since the last sync.
検索テスト
Standard Retrieve
まずは Retrieve API の基本的な使い方から見ていきます。以降の検索テストは 02_retrieve.py で再現できます。
Managed Knowledge Bases では検索時の設定に従来の vectorSearchConfiguration ではなく managedSearchConfiguration を使います。また、検索は常にハイブリッド検索(セマンティック + キーワード)で動作し、セマンティックのみの検索はできません。
Retrieval always uses hybrid search, which combines keyword and semantic search. Semantic-only search is not available for fully managed knowledge bases.
uv run scripts/02_retrieve.py
runtime = boto3.client('bedrock-agent-runtime', region_name='us-east-1')
response = runtime.retrieve(
knowledgeBaseId=KB_ID,
retrievalQuery={'text': 'Managed Knowledge Bases の料金体系と Self-managed との比較'}
)
for r in response['retrievalResults']:
score = r['score']
text = r['content']['text'][:100]
print(f"score={score:.4f} | {text}")
score=0.5596 | = $60/月 - Self-managed (OpenSearch): $700+ (OCU) + モデル費用 = $700+/月 → 小〜中規模では Managed Knowledge Bases が圧倒的にコスト効率が良い
score=0.4925 | - 埋め込み生成(マネージドモデル): 無料 - Standard Retrieval: $1.00 / 1,000 API コール...
score=0.2991 | Self-managed Knowledge Base: - ベクトルストアを自分で管理 (OpenSearch, Aurora, Pinecone等)...
料金比較のクエリに対して、pricing-comparison.md と bedrock-details.txt の関連チャンクが適切に返ってきていますね。
managedSearchConfiguration によるリランキング比較
Managed Knowledge Bases では retrievalConfiguration に managedSearchConfiguration を指定できます。rerankingModelType で MANAGED / NONE を切り替えて、スコアの違いを比較してみました。
def retrieve_with_reranking(query, reranking_type):
return runtime.retrieve(
knowledgeBaseId=KB_ID,
retrievalQuery={'text': query},
retrievalConfiguration={
'managedSearchConfiguration': {
'numberOfResults': 5,
'rerankingModelType': reranking_type # 'MANAGED' or 'NONE'
}
}
)
Standard Retrieve と同じ Managed Knowledge Base の料金体系と Self-managed との比較 というクエリで、MANAGED / NONE を比較します。
MANAGED リランキング(デフォルト)
score=0.5596 | pricing-comparison.md | コスト比較シナリオ...
score=0.4925 | pricing-comparison.md | Managed Knowledge Base 料金...
score=0.2991 | bedrock-details.txt | Self-managed Knowledge Base...
score=0.2302 | pricing-comparison.md | Bedrock モデル料金...
score=0.2079 | bedrock-details.txt | Managed Knowledge Base (新機能)...
NONE(リランキングなし)
score=1.0000 | pricing-comparison.md | コスト比較シナリオ...
score=0.9253 | pricing-comparison.md | Managed Knowledge Base 料金...
score=0.9040 | bedrock-details.txt | Self-managed Knowledge Base...
score=0.8145 | bedrock-details.txt | Managed Knowledge Base (新機能)...
score=0.7660 | pricing-comparison.md | Bedrock モデル料金...
MANAGED ではスコアが 0.21〜0.56 の範囲に正規化され、関連度の差がより明確に出ています。NONE では生のベクトル類似度スコア(0.77〜1.00)がそのまま返るため、上位の差が小さくなっています。
また、4位と5位の順序が入れ替わっているのも注目ポイントです。MANAGED リランカーが意味的な関連度で再評価した結果、Bedrock モデル料金テーブル(pricing-comparison.md)の方がクエリとの関連度が高いと判断しています。
ハイブリッド検索の効果
ハイブリッド検索の効果を確認してみます。キーワードマッチが効果的な固有名詞・数値系のクエリと、セマンティック検索が得意な言い換え・概念系のクエリを投げてみました。
queries = [
'Karpenter',
'provided.al2023',
'サーバーを管理せずにコードを実行する方法',
'データの暗号化と鍵の管理',
]
for q in queries:
resp = runtime.retrieve(
knowledgeBaseId=KB_ID,
retrievalQuery={'text': q},
retrievalConfiguration={
'managedSearchConfiguration': {'numberOfResults': 3, 'rerankingModelType': 'MANAGED'}
}
)
top = resp['retrievalResults'][0]
doc = top.get('documentId', '').split('/')[-1]
print(f"Q: {q}\n→ score={top['score']:.4f} | {doc} | {top['content']['text'][:80]}...\n")
Q: "Karpenter"
→ score=0.8714 | ecs-vs-eks.docx (EKS の Auto Scaling 比較テーブルにヒット)
Q: "provided.al2023"
→ score=0.8177 | lambda-guide.pdf (Lambda カスタムランタイムの記述にヒット)
Q: "サーバーを管理せずにコードを実行する方法"
→ score=0.6277 | lambda-guide.pdf ("serverless compute service that runs code in response to events")
Q: "データの暗号化と鍵の管理"
→ score=0.6663 | aws-overview.txt ("AWS KMS: 暗号化キー管理サービス")
Karpenter や provided.al2023 のような固有名詞はセマンティック検索だけだとヒットしづらいですが、ハイブリッド検索のおかげで正しいドキュメントにヒットしています。一方で「サーバーを管理せずにコードを実行」のような言い換えクエリも、セマンティック検索でちゃんと Lambda に到達しています。
両方の検索が常に併用されるので、キーワードの正確さが求められるケース(型番、エラーコード、固有名詞)でもセマンティックな質問でも、バランスよく検索できるのは嬉しいですね。
メタデータフィルタリング
ドキュメントにメタデータを付与して、検索時にフィルタリングすることもできます。S3 の場合、ドキュメントと同じパスに .metadata.json ファイルを配置します。
You can attach metadata to each document by uploading a sidecar file alongside it. For each document, create a file named
filename.extension.metadata.jsonin the same Amazon S3 path.
Managed KB のメタデータファイルは以下の形式です。
{
"metadataAttributes": {
"category": {
"value": {"type": "STRING", "stringValue": "overview"}
},
"year": {
"value": {"type": "NUMBER", "numberValue": 2026}
},
"language": {
"value": {"type": "STRING", "stringValue": "ja"}
}
}
}
uv run scripts/02c_metadata_filter.py
managedSearchConfiguration の filter でフィルタリング条件を指定します。
resp = runtime.retrieve(
knowledgeBaseId=KB_ID,
retrievalQuery={'text': 'AWS のサービス料金'},
retrievalConfiguration={
'managedSearchConfiguration': {
'numberOfResults': 5,
'rerankingModelType': 'MANAGED',
'filter': {
'equals': {'key': 'category', 'value': 'pricing'}
}
}
}
)
いくつかのフィルタ演算子を試してみました。
equals
Q: AWS のサービス料金
フィルタ: category = "pricing"
A[1] score=0.4096 | aws-services.csv (category=pricing, year=2026, language=ja)
A[2] score=0.3599 | pricing-comparison.md (category=pricing, year=2026, language=ja)
category = "pricing" でフィルタした結果、料金関連の2ドキュメントだけがヒットしました。
in
Q: AWS のアーキテクチャ
フィルタ: category in ["compute", "architecture"]
A[1] score=0.4959 | well-architected.html (category=architecture, year=2024)
A[2] score=0.4775 | well-architected.html (category=architecture, year=2024)
A[3] score=0.3283 | lambda-guide.pdf (category=compute, year=2025)
greaterThan
Q: AWS のサービス概要
フィルタ: year > 2025
A[1] score=0.6490 | aws-overview.txt (year=2026)
A[2] score=0.5643 | aws-overview.txt (year=2026)
A[3] score=0.5535 | aws-overview.txt (year=2026)
2025年以前のドキュメント(lambda-guide.pdf, ecs-vs-eks.docx 等)が除外されています。
andAll(複合フィルタ)
Q: AI サービス
フィルタ: category = "ai" AND year = 2026
A[1] score=0.5385 | bedrock-details.txt (category=ai, year=2026)
A[2] score=0.5013 | agentcore-guide.txt (category=ai, year=2026)
A[3] score=0.2267 | bedrock-managed-kb.pptx (category=ai, year=2026)
startsWith(Managed KB では非対応)
Q: AWS
フィルタ: category startsWith "ai"
エラー: STARTS_WITH operation type is not supported for managed store.
Managed KB では startsWith と stringContains は使えません。equals、in、greaterThan、lessThan、notEquals、notIn を使う必要があります。
The
startsWithandstringContainsmetadata filters are not supported for managed knowledge bases.
Self-managed の OpenSearch Serverless では startsWith も使えたので、Managed KB に移行する際はフィルタ演算子の制約に注意してください。
フォーマット別の検索精度
Smart Parsing がどの程度うまく機能するか、フォーマット別にクエリを投げて確認しました。各フォーマットに対して Standard Retrieve + MANAGED リランキングで検索します(同じく 02_retrieve.py で実行)。
結果は一部抜粋していますが気になる方はぜひ実際に試してみてください。
HTML テーブル
resp = runtime.retrieve(
knowledgeBaseId=KB_ID,
retrievalQuery={'text': 'Well-Architected Framework のセキュリティの柱はどんな説明ですか?'},
retrievalConfiguration={
'managedSearchConfiguration': {'numberOfResults': 3, 'rerankingModelType': 'MANAGED'}
}
)
Q: Well-Architected Framework のセキュリティの柱はどんな説明ですか?
score=0.7543 | well-architected.html
→ "柱 説明 運用の優秀性 ワークロードの効果的な運用と継続的改善 セキュリティ データ・システム・資産の保護..."
HTML の <table> タグがプレーンテキストに変換された上で正しく検索できています。テーブルの構造(柱名と説明の対応)も維持されていますね。
CSV
Q: Amazon OpenSearch Serverless の月額最低料金はいくらですか?
score=0.6167 | aws-services.csv
→ "Amazon OpenSearch Serverless,分析,700,ベクトル検索対応"
CSV ファイルからも正しくヒットしています。カンマ区切りのまま検索されていますが、セマンティック検索でちゃんと関連チャンクとしてヒットしていますね。
Markdown テーブル
Q: Claude Haiku 4.5 の入力トークンの料金は?
score=0.8636 | pricing-comparison.md
→ "| Claude Haiku 4.5 | $0.0008 | $0.004 |"
Markdown テーブルも問題なく検索できました。スコアも 0.86 と高く、ピンポイントで該当行を含むチャンクが返ってきています。なお、ここで使っている料金データは検証用のサンプルデータです。実際の料金は 公式ページ をご確認ください。
PDF(図入り)
生成AIで作ったちゃちな絵を入れています。
これがどう解釈されるかみてみます。
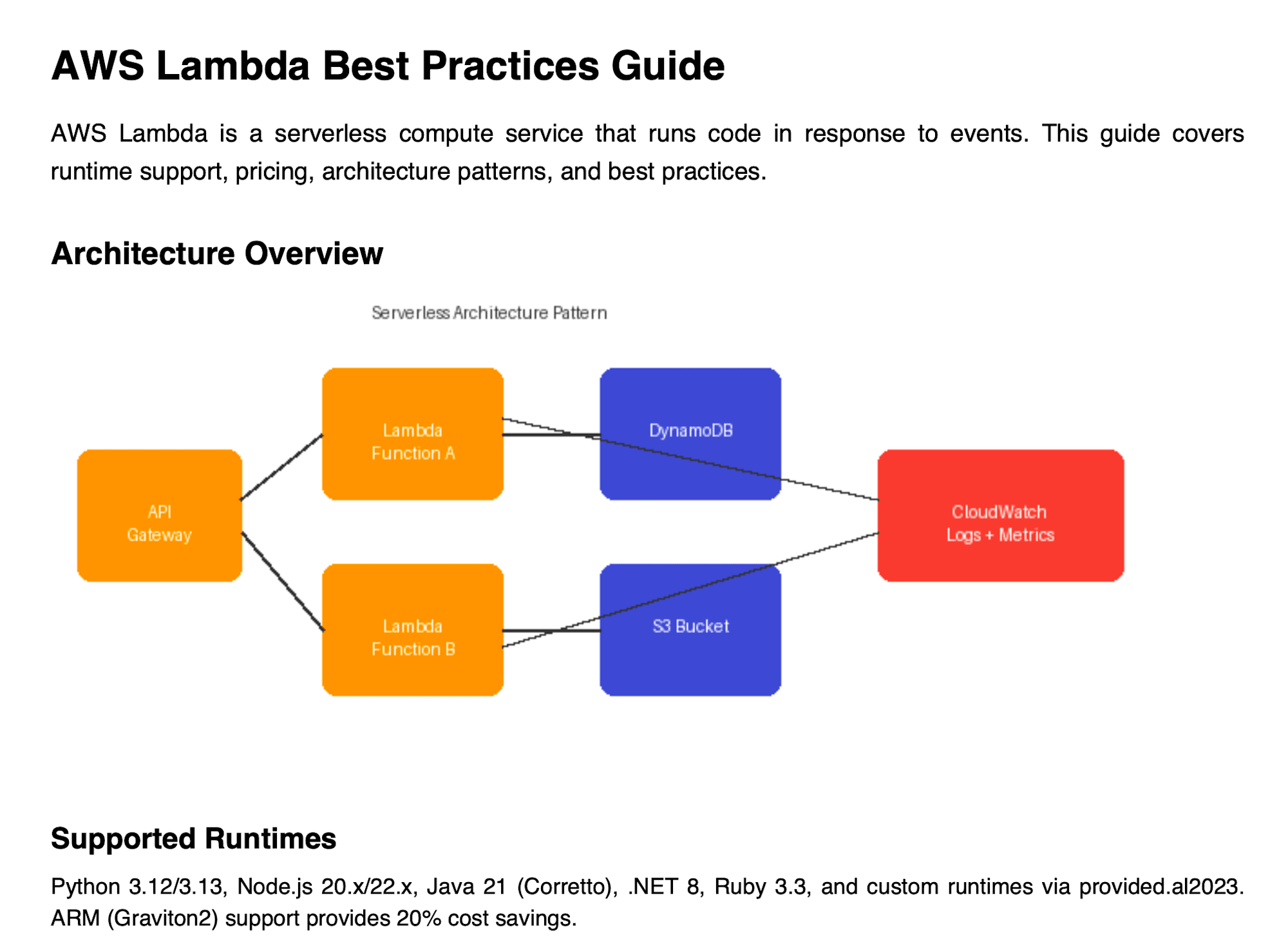
Q: Lambda のコールドスタート対策にはどんな方法がありますか?
[1] score=0.8173 | lambda-guide.pdf
→ "Best Practices 1. Single Responsibility: One function, one task. 2. Externalize config via
environment variables... 5. Mitigate cold starts with SnapStart (Java) or Provisioned Concurrency."
[2] score=0.6373 | lambda-guide.pdf
→ "Serverless Architecture Pattern Lambda DynamoDB Function A API CloudWatch Gateway Logs + Metrics
Lambda S3 Bucket Function B Supported Runtimes Python 3.12/3.13..."
[3] score=0.4782 | lambda-guide.pdf
→ "The diagram shows a complete event-driven workflow with the following components and flow:
Entry Point: The API Gateway (orange, left side) serves as the entry point..."
PDF 内のテキストが正しく抽出されて検索できています。1位にベストプラクティスの本文が、2位にランタイムや料金の記述がヒットしています。
3位の結果を見ると、これは PDF に埋め込んだアーキテクチャ図から Smart Parsing が自動生成した説明文で、"The diagram shows a complete event-driven workflow..." という内容は元の PDF テキストには存在しません。図のテキスト要素(API Gateway, Lambda Function A, DynamoDB 等)を読み取った上で、図全体の説明を生成してくれています。今まではこういったものを基盤モデルでパースして説明するようにしていたのでこの辺りまでカバーされているのですね。
PPTX(スライド + 図)
こちらもスライドに下記のような図を埋め込んでいます。
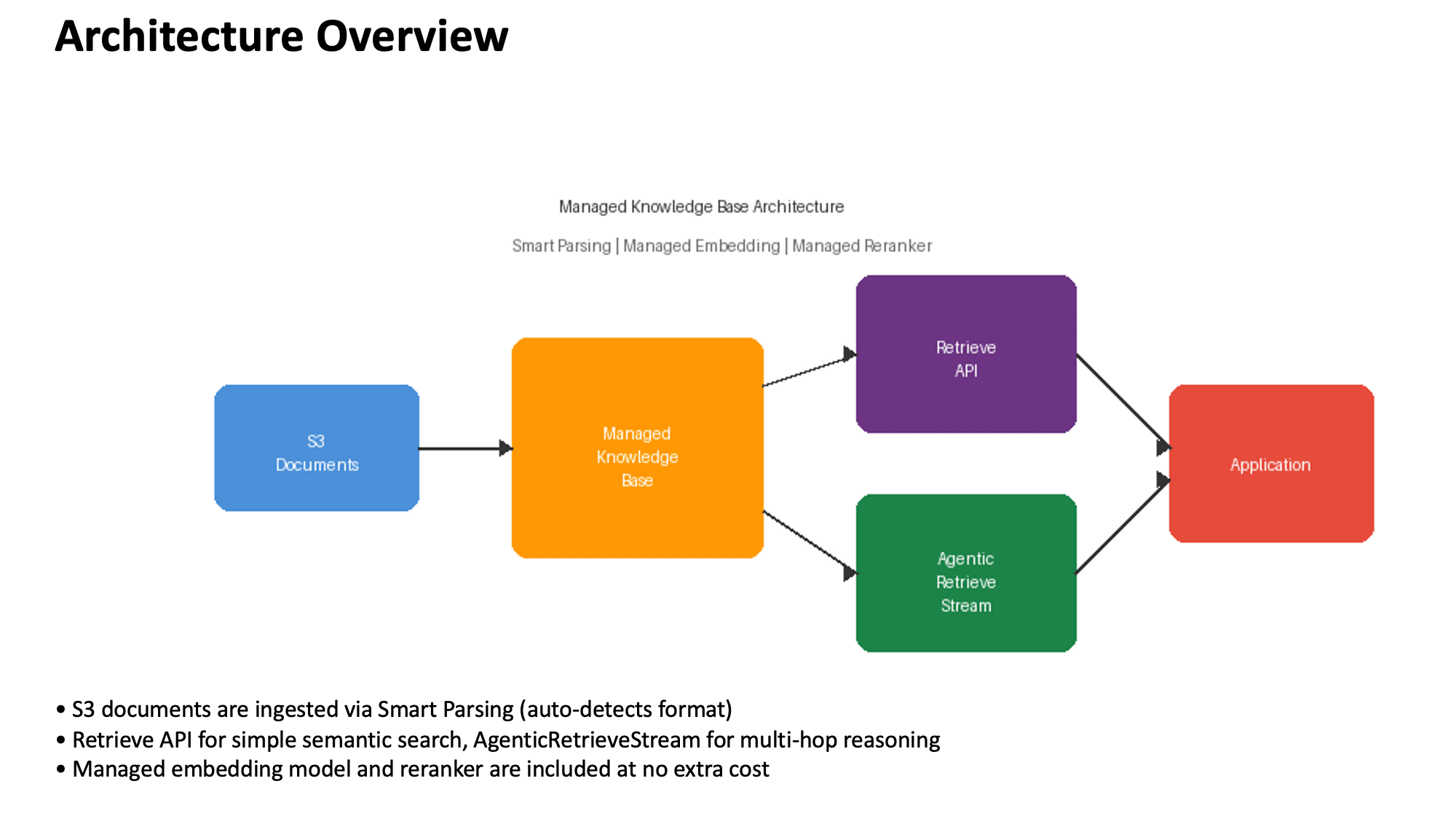
Q: Managed Knowledge Bases のアーキテクチャはどうなっていますか?
[1] score=0.7059 | bedrock-managed-kb.pptx
→ "Managed Knowledge Base Architecture Smart Parsing | Managed Embedding Managed Reranker
Retrieve API S3 Managed Documents Knowledge Application Base Agentic Retrieve Stream
S3 documents are ingested via Smart Parsing..."
[2] score=0.6503 | bedrock-managed-kb.pptx
→ "Processing Layer: The central component is the Managed Knowledge Base, which processes
incoming documents from S3. This component incorporates three key managed services..."
[3] score=0.6293 | bedrock-managed-kb.pptx
→ "S3 Documents flows into the Managed Knowledge Base (solid arrow pointing right)
Managed Knowledge Base connects to two retrieval mechanisms:
Upper path: Managed Knowledge Base → Retrieve API..."
PPTX もスライド内のテキストがすべて抽出されています。1位はスライドのテキスト要素がそのまま検索にヒットした結果です。
2位と3位は PDF と同様に、埋め込み画像(アーキテクチャ図)に対して Smart Parsing が自動生成した説明文です。"Processing Layer: The central component is..." や "S3 Documents flows into the Managed Knowledge Base..." といった内容は元のスライドテキストにはなく、図の構造を解釈して生成されたものです。
DOCX(テーブル入り)
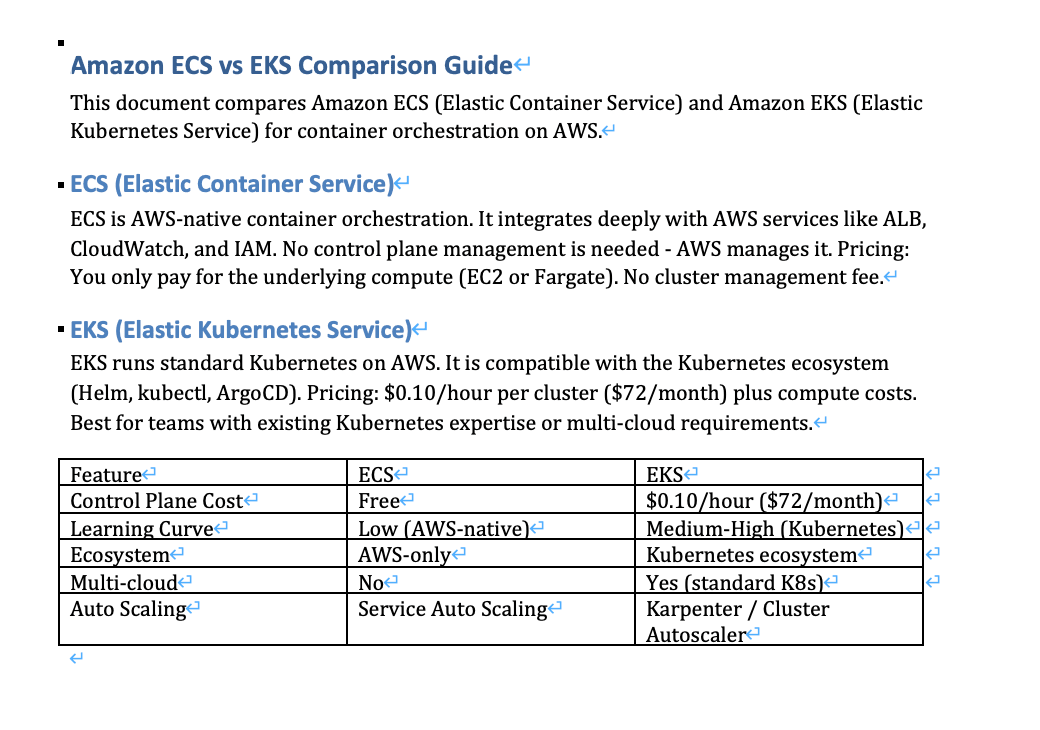
Q: ECS と EKS のコントロールプレーンのコストの違いを教えてください
score=0.8937 | ecs-vs-eks.docx
→ "Amazon ECS vs EKS Comparison Guide This document compares Amazon ECS (Elastic Container Service)
and Amazon EKS (Elastic Kubernetes Service)... Pricing: $0.10/hour per cluster ($72/month)..."
Q: マルチクラウド対応が必要な場合、ECS と EKS どちらを選ぶべきですか?
score=0.9021 | ecs-vs-eks.docx
→ "EKS runs standard Kubernetes on AWS. It is compatible with the Kubernetes ecosystem
(Helm, kubectl, ArgoCD)... Best for teams with existing Kubernetes expertise or multi-cloud requirements."
DOCX 内のテーブルデータ(ECS: Free vs EKS: $0.10/hour)も含めてインデックスされ、スコア 0.89 / 0.90 と高精度でヒットしています。
フォーマット別まとめ
| フォーマット | インデックス | テーブル抽出 | 図の解釈 | 備考 |
|---|---|---|---|---|
| .txt | OK | - | - | |
| .md | OK | OK | - | |
| .csv | OK | OK | - | カンマ区切りのまま |
| .html | OK | OK | - | タグ除去 + 構造維持 |
| OK | OK | OK | 図のテキスト要素抽出 + 説明文自動生成 | |
| .pptx | OK | - | OK | スライドテキスト + 埋め込み画像の説明文生成 |
| .docx | OK | OK | - | テーブル構造を維持 |
今回の検証では、PDF / PPTX の図に対する説明文も生成されていました。なお、画像・音声・動画の抽出を明示的に制御したい場合は、データソース作成時に mediaExtractionConfiguration を設定できます(音声: .mp3, .wav, .m4a, .flac, .ogg、動画: .mp4, .mov, .m4v)。
ドキュメントに含まれるアーキテクチャ図や構成図の内容も検索対象になるのは、実務でかなり役立ちそうです。
ページ数が多いドキュメントでの検証
ここまではテスト用に作った小さなドキュメントでの検証でしたが、実際に業務で使うようなボリュームのドキュメントではどうでしょうか。以前作成した164ページの日本語スライド PDF(「2025年 Amazon Bedrock AgentCoreまとめ」、11MB)をインデックスして試してみました。
02b_large_doc.py に任意の PDF パスを渡すと、アップロード → 同期 → 検索まで一括で実行できます。
uv run scripts/02b_large_doc.py /path/to/agentcore-matome.pdf
同期は問題なく完了。164ページの PDF でも特にエラーなくインデックスされています。
Q: Amazon Bedrock AgentCore とは何ですか?どんな機能がありますか?
[1] score=0.6307 | agentcore-matome.pdf
→ "Amazon Bedrock AgentCore とは
● AIエージェントのホスティング
○ Strands Agents、LangGraphなど多様なエージェントフレームワークに対応
● 便利なマネージドサービス
○ AIエージェントを使用する上で認証・ツール連携など便利な機能がマネージドサービスとして提供(Id..."
[2] score=0.5772 | agentcore-matome.pdf
→ "Amazon Bedrock AgentCoreが持つ機能群
● Runtime:AIエージェントの実行環境
● Identity:認証機能
● Gateway:MCPツールの集約機能、外部サービスのMCPツール化機能
● Memory:記憶機能
● Observability:AIエージェントの挙動を可視化
● Evaluations:AIエージェントの評価機能(Preview)"
Q: AI エージェントの自律性と知性について教えてください
[1] score=0.8248 | agentcore-matome.pdf
→ "自律性により、エージェントは人間の指示を待たずに目標に向かって自ら動き続けることを可能にし、
知性により、複雑な状況を理解し、推論し、最適な判断を下すことを可能とします。"
問題なく動いていそうですね。
GetDocumentContent ― ソースドキュメントの取得
Retrieve API で見つけたチャンクの元ドキュメントをダウンロードしたいケースがあります。GetDocumentContent API を使うと、元ファイルやパース済みテキストを presigned URL 経由で取得できます。
uv run scripts/03_get_document_content.py
Retrieve の結果に含まれる documentId と _data_source_id をそのまま渡すだけです。
result = retrieve_response['retrievalResults'][0]
# RAW: 元のファイル(PDF, DOCX 等)をそのまま取得
doc_raw = runtime.get_document_content(
knowledgeBaseId=KB_ID,
dataSourceId=result['metadata']['_data_source_id'],
documentId=result['documentId'],
outputFormat='RAW'
)
# EXTRACTED: Smart Parsing でパースされた後のテキストを JSON で取得
doc_extracted = runtime.get_document_content(
knowledgeBaseId=KB_ID,
dataSourceId=result['metadata']['_data_source_id'],
documentId=result['documentId'],
outputFormat='EXTRACTED'
)
# presigned URL でダウンロード(有効期限 5分)
import requests
download = requests.get(doc_raw['presignedUrl'])
outputFormat は RAW と EXTRACTED の2種類があります。
| outputFormat | 内容 | 用途 |
|---|---|---|
| RAW | 元のファイル(PDF, DOCX 等)をそのまま | ユーザーに元ファイルを見せたい場合 |
| EXTRACTED | Smart Parsing 後のテキストを JSON 形式で | パース結果の確認、アプリ側での二次加工 |
164ページの PDF(11MB)で試したところ、RAW では元の PDF がそのまま 11MB で返り、EXTRACTED ではパース済みの JSON が 1MB で返りました。presigned URL の有効期限は5分です。
Retrieve で「このチャンクの元ネタが見たい」というケースは RAG アプリでよくあるので、presigned URL でサッと取得できるのは便利ですね。
AgenticRetrieveStream からも使える
GetDocumentContent は Retrieve 専用ではなく、AgenticRetrieveStream の結果からも利用できます。ただしフィールド名が少し異なります。
| API | documentId の取得元 | dataSourceId の取得元 |
|---|---|---|
| Retrieve | result['documentId'] |
result['metadata']['_data_source_id'] |
| AgenticRetrieveStream | result['metadata']['_document_id'] |
result['metadata']['_data_source_id'] |
Retrieve では結果に documentId フィールドが直接ありますが、AgenticRetrieveStream では metadata._document_id に S3 URI 形式で入っています。
# AgenticRetrieveStream の結果から GetDocumentContent を呼ぶ
for result in agentic_results:
meta = result['metadata']
doc = runtime.get_document_content(
knowledgeBaseId=KB_ID,
dataSourceId=meta['_data_source_id'],
documentId=meta['_document_id'], # s3://bucket/key 形式
outputFormat='RAW',
)
print(doc['presignedUrl'])
AgenticRetrieveStream で回答を生成しつつ、ユーザーが「出典を確認したい」と言ったときに元ファイルのリンクを返す、といった使い方ができそうです。
ACL によるドキュメントレベルのアクセス制御
Managed Knowledge Bases では ACL(Access Control List)を使って、ドキュメント単位でアクセス制御ができます。Retrieve 時に userContext でユーザーの ID を渡すと、そのユーザーが閲覧可能なドキュメントだけが検索結果に返却されます。
uv run scripts/06_acl.py
S3 コネクタの場合は、Global ACL 設定ファイルを S3 に配置して、データソース作成時に aclEnabled: true と ACL ファイルの URI を指定します。
[
{
"keyPrefix": "s3://my-bucket/engineering/",
"aclEntries": [
{"Name": "engineer@example.com", "Type": "USER", "Access": "ALLOW"}
]
},
{
"keyPrefix": "s3://my-bucket/sales/",
"aclEntries": [
{"Name": "sales@example.com", "Type": "USER", "Access": "ALLOW"}
]
}
]
実際に3つのドキュメント(エンジニアリング限定 / 営業限定 / 全社公開)で試してみました。Retrieve の userContext にユーザー ID を渡すだけです。
query = '社内の価格表や API 設計ガイドについて教えてください'
for user, label in [
('engineer@example.com', 'エンジニア'),
('sales@example.com', '営業'),
('admin@example.com', '管理者'),
('nobody@example.com', '権限なし'),
]:
resp = runtime.retrieve(
knowledgeBaseId=KB_ID,
retrievalQuery={'text': query},
retrievalConfiguration={
'managedSearchConfiguration': {'numberOfResults': 5, 'rerankingModelType': 'MANAGED'}
},
userContext={'userId': user},
)
acl_results = [r for r in resp.get('retrievalResults', []) if 'acl-docs' in r.get('documentId', '')]
sources = sorted({r.get('documentId', '').split('/')[-1] for r in acl_results})
print(f"[{label}] {user} → {sources if sources else 'ヒットなし'}")
Q: 社内の価格表や API 設計ガイドについて教えてください
[エンジニア] engineer@example.com → api-internal.txt のみヒット
[営業] sales@example.com → pricing-internal.txt のみヒット
[管理者] admin@example.com → 両方ヒット
[権限なし] nobody@example.com → ヒットなし
ユーザーごとに見えるドキュメントがきちんとフィルタリングされていますね。ACL の評価は deny が常に allow より優先される設計です。SharePoint / OneDrive / Google Drive / Confluence ではリアルタイム ACL 検証も対応しています。
ACL はあくまでフィルタリングであり、認証の代わりにはなりません。ユーザーの認証はアプリケーション側で行い、検証済みの ID を userContext に渡す必要があります。
この辺もアプリケーション側で制御すればロールベースでのアクセス制限もできてよいですね。
データソースの設定オプション
ここまでの検証ではデフォルト設定で進めてきましたが、データソース作成時にはいくつかの設定オプションがあります。
S3 コネクタのフィルタリング
S3 コネクタでは、メタデータファイルのプレフィックスや Include / Exclude パターンでインデックス対象のファイルを絞り込めます。拡張子で対象を絞りたい場合(例: PDF だけインデックスしたい)に便利です。パターンは最大25個まで指定可能で、Include と Exclude が競合する場合は Exclude が優先されます。
Advanced Indexing
デフォルトではテキストベースのコンテンツのみがインデックスされますが、Advanced Indexing を有効にすると追加のモダリティに対応できます。
| モダリティ | 対象フォーマット | 説明 |
|---|---|---|
| Visual content in documents | .pdf, .docx, .ppt, .pptx | ドキュメント内の埋め込み画像を処理 |
| Audio files | .mp3, .wav, .m4a, .flac, .ogg | 音声ファイルを文字起こし・インデックス |
| Video files | .mp4, .mov, .m4v | 動画ファイルからテキスト・シーン情報を抽出 |
最大ファイルサイズは 500MB まで設定可能です。
Document deletion safeguard
同期時にデータソース側でファイルが大量削除されていた場合、インデックスからの一括削除をスキップする安全装置です。managedKnowledgeBaseConnectorConfiguration 直下に deletionProtectionConfiguration を設定します。
'deletionProtectionConfiguration': {
'deletionProtectionStatus': 'ENABLED', # ENABLED or DISABLED
'deletionProtectionThreshold': 15 # 削除許容割合(0-100%、デフォルト15)
}
しきい値を超える削除が発生した場合、同期の削除フェーズがスキップされます。誤操作による大量削除を防ぎたい場合に有効にしておくと安心です。
RetrieveAndGenerate は非対応
Managed Knowledge Bases で retrieve_and_generate を呼ぶと下記のエラーになります。
ValidationException: This operation is not supported for managed knowledge bases.
Managed Knowledge Bases では回答生成に RetrieveAndGenerate は使えません。代わりに次のセクションで紹介する AgenticRetrieveStream を使うか、Retrieve で取得したチャンクをアプリケーション側で LLM に渡す形になります。
AgenticRetrieveStream ― Agentic Retrieval
どういう API か
AgenticRetrieveStream は Managed Knowledge Bases 専用の新しい API です。従来の Retrieve がシンプルにベクトル検索してチャンクを返すのに対して、AgenticRetrieveStream は LLM を使ってクエリを分解し、複数回の検索を反復的に実行した上で回答を生成します。
処理の流れはこのようになっています。
まずクエリをそのまま使って関連ドキュメントを先行取得(SpeculativeRetrieval)し、LLM が取得した情報で足りるか判断(Planning)します。不足していればサブクエリを生成して追加検索を繰り返し、十分な情報が集まったら回答をストリーミング生成します。まさにエージェンティックに動いていて面白いですね。
traceEvent で各ステップの進捗が確認できるのも面白いポイントです。Planning の判断や、どのサブクエリでどの Knowledge Base を検索したかトレースとして返却されます。
リクエストの構造
runtime = boto3.client('bedrock-agent-runtime', region_name='us-east-1')
response = runtime.agentic_retrieve_stream(
messages=[
{
'content': {'text': 'Managed Knowledge Bases の料金体系を教えてください'},
'role': 'user'
}
],
retrievers=[
{
'description': 'AWS and Bedrock knowledge base',
'configuration': {
'knowledgeBase': {
'knowledgeBaseId': KB_ID
}
}
}
],
agenticRetrieveConfiguration={
'foundationModelType': 'MANAGED',
'rerankingModelType': 'MANAGED'
},
generateResponse=True
)
for event in response['stream']:
if 'traceEvent' in event:
attrs = event['traceEvent']['attributes']
print(f"[{attrs['step']}] {attrs['status']}")
elif 'responseEvent' in event:
print(event['responseEvent']['text'], end='')
elif 'result' in event:
print(f"\nResults: {len(event['result']['results'])} chunks")
| フィールド | 必須 | 説明 |
|---|---|---|
| messages | Yes | 会話メッセージ。マルチターンにも対応 |
| retrievers | Yes | 検索対象の Knowledge Base リスト。複数指定で横断検索が可能 |
| agenticRetrieveConfiguration | Yes | LLM / リランカーの設定(MANAGED / CUSTOM / NONE) |
| generateResponse | No | 回答生成の有無。false にすると検索結果のみ返る |
agenticRetrieveConfiguration の foundationModelType でクエリ分解・回答生成に使う LLM を選択できます。
| foundationModelType | 説明 | 料金 |
|---|---|---|
MANAGED |
AWS 側でモデルを自動選択 | $4.00 / 1,000 Agentic API コール |
CUSTOM |
任意の Bedrock モデルを ARN で指定 | LLM のモデル料金のみ(Agentic API コール料金は不要) |
CUSTOM の場合は foundationModelConfiguration で ARN を指定します。
agenticRetrieveConfiguration={
'foundationModelType': 'CUSTOM',
'foundationModelConfiguration': {
'type': 'BEDROCK_FOUNDATION_MODEL',
'bedrockFoundationModelConfiguration': {
'modelConfiguration': {
'modelArn': 'arn:aws:bedrock:us-east-1::foundation-model/us.anthropic.claude-sonnet-4-5-20250929-v1:0'
}
}
},
'rerankingModelType': 'MANAGED'
}
今回の検証では MANAGED を使用しています。
単一 Knowledge Base での検証
「Managed Knowledge Base と Self-managed Knowledge Base の料金を比較して、どちらがコスト効率が良いか教えてください」というクエリを投げてみます。
uv run scripts/04_agentic_retrieve.py
実行すると traceEvent で各ステップの進捗が返ってきます。実際の traceEvent は JSON 形式ですが、スクリプトでは step(SpeculativeRetrieval / Planning / Retrieval)と message(サブクエリの内容)、retrievalMetadata(対象 KB)を抽出して日本語で整形表示しています。
[投機的検索] クエリでまず先行検索...
[投機的検索] 3 チャンク取得 → bedrock-details.txt, pricing-comparison.md
[計画] 追加検索不要 → 回答生成へ
今回はシンプルなクエリだったので、投機的検索で取得した情報だけで十分と判断され、追加検索なしで回答生成に進んでいます。
生成された回答はこのようなものでした(抜粋)。
## Managed Knowledge Base の料金体系
- **インデックスストレージ**: $5.00/GB(生データ)/月
- **Standard Retrieval**: $1.00/1,000 API コール
- **Agentic Retrieval**: $4.00/1,000 Agentic API コール + $1.00/1,000 Retrieve コール
- **マルチモーダルパース / 埋め込み生成 / リランキング**: 無料
## コスト比較シナリオ
10GB のドキュメント、月間 10,000 検索の場合:
- Managed KB: $50(ストレージ)+ $10(検索)= **$60/月**
- Self-managed(OpenSearch): $700+(OCU)+ モデル費用 = **$700+/月**
小〜中規模では Managed KB が圧倒的にコスト効率が良いです。
引用一覧:
- pricing-comparison.md
- bedrock-details.txt
- bedrock-managed-kb.pptx
Markdown テーブル形式で料金比較表を構築し、引用付きで回答を生成してくれています。RetrieveAndGenerate が使えない代わりに、AgenticRetrieveStream がその役割を十分カバーしています。
複数 Knowledge Bases 横断検索
Agentic Retrieval の本領は複数 Knowledge Bases を跨いだ検索です。ドメインの異なる2つの Knowledge Bases を用意して検証しました。
uv run scripts/05_multi_kb_agentic.py
- KB1(一般ドキュメント)
- AWS サービス概要・Bedrock 詳細・料金比較など 9 ドキュメント
- KB2(セキュリティ)
- セキュリティベストプラクティス(IAM 最小権限・MFA・暗号化・CloudTrail)、コンプライアンスフレームワーク(ISMAP・FISC・PCI DSS)、インシデントレスポンスガイドの 3 ドキュメント
KB2 は KB1 と同じ手順で作成しています。別の S3 バケットにセキュリティ関連ドキュメントをアップロードし、新しい Managed Knowledge Base を作成してデータソースを接続します。
01_setup.py より抜粋(KB2 セキュリティドメインのセットアップ)
# 2つ目の Knowledge Base を作成
resp = client.create_knowledge_base(
name='managed-kb-security-test',
description='Security and compliance KB',
roleArn=ROLE_ARN,
knowledgeBaseConfiguration={
'type': 'MANAGED',
'managedKnowledgeBaseConfiguration': {'embeddingModelType': 'MANAGED'}
},
)
KB2_ID = resp['knowledgeBase']['knowledgeBaseId']
# セキュリティドキュメントを S3 にアップロード
docs = {
'security-best-practices.txt': 'AWS セキュリティベストプラクティス\n1. 最小権限の原則...',
'compliance-frameworks.txt': 'AWS コンプライアンスフレームワーク対応状況\nISMAP, FISC, PCI DSS...',
'incident-response.txt': 'AWS インシデントレスポンスガイド\nフェーズ1: 準備...',
}
for fname, content in docs.items():
s3.put_object(Bucket=BUCKET2, Key=f'documents/{fname}', Body=content.encode('utf-8'))
# データソース接続 + 同期(KB1 と同じ手順)
ds_resp = client.create_data_source(
knowledgeBaseId=KB2_ID, name='security-docs',
dataSourceConfiguration={
'type': 'MANAGED_KNOWLEDGE_BASE_CONNECTOR',
'managedKnowledgeBaseConnectorConfiguration': {
'deletionProtectionConfiguration': {'deletionProtectionStatus': 'DISABLED'},
'connectorParameters': {
'type': 'S3', 'version': '1',
'connectionConfiguration': {'bucketName': BUCKET2, 'bucketOwnerAccountId': ACCOUNT_ID},
}
}
},
dataDeletionPolicy='DELETE',
)
client.start_ingestion_job(knowledgeBaseId=KB2_ID, dataSourceId=ds_resp['dataSource']['dataSourceId'])
retrievers に2つの Knowledge Bases を指定して、「Managed Knowledge Base の料金体系と、セキュリティのベストプラクティス(暗号化・IAM・監査)、金融業界でのコンプライアンス対応」という両方のドメインにまたがるクエリを投げます。
retrievers の description には各 Knowledge Base がどんなドメインの情報を持っているかを記述しておきました。
05_multi_kb_agentic.py(複数 Knowledge Bases 横断検索)
response = runtime.agentic_retrieve_stream(
messages=[
{
'content': {
'text': 'Amazon Bedrock を使って RAG を構築する場合、Managed Knowledge Base の'
'料金体系と、セキュリティのベストプラクティス(暗号化・IAM・監査)を'
'教えてください。また、金融業界で利用する場合のコンプライアンス対応に'
'ついても教えてください。'
},
'role': 'user'
}
],
retrievers=[
{
'description': 'AWS サービスと Bedrock の一般ドキュメント(料金・機能)',
'configuration': {
'knowledgeBase': {'knowledgeBaseId': KB1_ID}
}
},
{
'description': 'AWS セキュリティベストプラクティスとコンプライアンスフレームワーク',
'configuration': {
'knowledgeBase': {'knowledgeBaseId': KB2_ID}
}
}
],
agenticRetrieveConfiguration={
'foundationModelType': 'MANAGED',
'rerankingModelType': 'MANAGED'
},
generateResponse=True
)
トレース(JSON の traceEvent をスクリプトで日本語に整形したもの)を見ると、Planning でクエリが分解されて各 KB に振り分けられる様子がわかります。
[投機的検索] クエリでまず先行検索...
[投機的検索] 2 チャンク取得 → bedrock-managed-kb.pptx, security-best-practices.txt
[計画] 追加検索 4 件:
→ "Amazon Bedrock Managed Knowledge Base 料金 pricing cost" → 一般ドキュメント
→ "Bedrock Knowledge Base セキュリティ 暗号化 encryption" → 一般ドキュメント
→ "IAM セキュリティベストプラクティス 最小権限 暗号化" → セキュリティ
→ "金融業界 コンプライアンス 監査 CloudTrail" → セキュリティ
[検索完了] 一般ドキュメント: bedrock-details.txt, bedrock-managed-kb.pptx, pricing-comparison.md (10 チャンク)
[検索完了] 一般ドキュメント: aws-overview.txt, aws-services.csv, bedrock-details.txt, bedrock-managed-kb.pptx (10 チャンク)
[検索完了] セキュリティ: compliance-frameworks.txt, security-best-practices.txt (2 チャンク)
[検索完了] セキュリティ: security-best-practices.txt (1 チャンク)
[計画] 追加検索 2 件:
→ "FISC 金融情報システムセンター 安全対策基準" → セキュリティ
→ "Bedrock IAM ポリシー アクセス制御 権限" → 一般ドキュメント
[検索完了] セキュリティ: compliance-frameworks.txt, security-best-practices.txt (2 チャンク)
[検索完了] 一般ドキュメント: agentcore-guide.txt, aws-overview.txt, bedrock-details.txt, bedrock-managed-kb.pptx (10 チャンク)
[計画] 追加検索不要 → 回答生成へ
Planning の振り分けが面白いです。「料金」「暗号化」は一般ドキュメント KB に、「IAM ベストプラクティス」「コンプライアンス」はセキュリティ KB に、とクエリの内容に応じて適切な KB にルーティングされています。さらに1回目の検索で情報が足りないと判断し、「FISC 安全対策基準」「IAM アクセス制御」で2回目の追加検索を実行しています。
AIエージェントらしく必要な情報がとれるまで計画を立てて検索してくれるのはよいですね。
retrievers の description について、公式 API Reference では「retriever の目的を説明する文字列」(AgenticRetriever)とされています。ルーティングに使われるかどうかは明記されていないため、description の有無でサブクエリの振り分けがどう変わるかは別途検証してみたいところです。
生成された回答はドメインごとに整理されていました(抜粋)。
## Managed Knowledge Base の料金体系
- **インデックスストレージ**: $5.00/GB(生データ)/月
- **Standard Retrieval**: $1.00/1,000 API コール
- **Agentic Retrieval**: $4.00/1,000 Agentic API コール + $1.00/1,000 Retrieve コール
- **マルチモーダルパース / 埋め込み生成 / リランキング**: 無料
## セキュリティのベストプラクティス
### 1. 暗号化
- S3: デフォルト暗号化を有効化、EBS/RDS: AWS KMS で暗号化
- 転送時: TLS 1.2 以上を使用
### 2. IAM(アクセス制御)
- 最小権限の原則: すべての IAM ポリシーは必要最小限の権限のみを付与する
### 3. 監査とログ管理
- CloudTrail: 全リージョンで有効化し、API コールの監査ログを記録
- GuardDuty: 脅威自動検出
## 金融業界でのコンプライアンス対応
- **FISC 安全対策基準**: AWS は対応リファレンスを公開
- **PCI DSS**: AWS は Level 1 認定を取得
- **ISMAP**: AWS は登録済み
引用一覧:
[一般ドキュメント] bedrock-managed-kb.pptx, pricing-comparison.md, bedrock-details.txt, aws-overview.txt, aws-services.csv
[セキュリティ] security-best-practices.txt, compliance-frameworks.txt
チャンク数: 一般ドキュメント: 45, セキュリティ: 7
料金は KB1(一般ドキュメント)から、セキュリティベストプラクティスと金融コンプライアンスは KB2(セキュリティ)から情報収集して、1つの回答にまとめてくれています。
使い分け
Managed Knowledge Bases の検索 API は Retrieve と AgenticRetrieveStream の2つがあります。使い分けの目安はこのあたりです。
| 用途 | API | 料金 |
|---|---|---|
| シンプルなキーワード・意味検索 | Retrieve | $1/1,000回 |
| チャンクだけ取得してアプリ側で LLM に回答を作らせたい | Retrieve | $1/1,000回 |
| 回答生成まで API 側でやりたい | AgenticRetrieveStream | $4/1,000回 + $1/1,000回 |
| 複数 Knowledge Bases を横断して検索したい | AgenticRetrieveStream | $4/1,000回 + $1/1,000回 |
| マルチホップ推論が必要な複雑なクエリ | AgenticRetrieveStream | $4/1,000回 + $1/1,000回 |
AgenticRetrieveStream は1回あたりの料金が Retrieve の5倍ですが、複雑なクエリの分解・複数 Knowledge Bases の横断・回答生成を API 側で完結できるのは便利です。単純な FAQ やキーワード検索なら Retrieve で十分ですし、社内ドキュメントの横断検索やカスタマーサポートのように複合的な情報が必要な場合は AgenticRetrieveStream を試してみるのも良いですね。
クリーンアップ
検証が終わったらリソースを削除します。
uv run scripts/99_cleanup.py
データソース → Knowledge Base → S3 バケット → IAM ロールの順で削除していきます。
99_cleanup.py(リソース削除)
import boto3
client = boto3.client('bedrock-agent', region_name='us-east-1')
s3 = boto3.client('s3', region_name='us-east-1')
iam = boto3.client('iam')
# データソース → Knowledge Base の順で削除
for kb_id, ds_id in [(KB1_ID, DS1_ID), (KB2_ID, DS2_ID)]:
client.delete_data_source(knowledgeBaseId=kb_id, dataSourceId=ds_id)
client.delete_knowledge_base(knowledgeBaseId=kb_id)
# S3 バケット削除
for bucket in [BUCKET1, BUCKET2]:
objects = s3.list_objects_v2(Bucket=bucket)
for obj in objects.get('Contents', []):
s3.delete_object(Bucket=bucket, Key=obj['Key'])
s3.delete_bucket(Bucket=bucket)
# IAM ロール削除
iam.delete_role_policy(RoleName=ROLE_NAME, PolicyName='ManagedKBAccess')
iam.delete_role(RoleName=ROLE_NAME)
おわりに
Managed Knowledge Base は、Self-managed と比べてセットアップが楽で色々とできることが多くなっていてびっくりしました。
AgenticRetrieveStream といったAPIも面白く、複数のデータソースを探索して検索するのは今まで自前でやる必要があったのが、マネージドな機能で吸収されたのは面白く、今後RAGの選択肢として考えておきたいです。また、AgentCore Gateway経由でAIエージェントから簡単に接続しやすくなったのは嬉しいポイントかと思います。今度はHarnessやRuntimeから呼び出しをやってみたいと思います!
まずはRAGを作りたい!!となったときに試すのは良いなと思ったので、ぜひみなさんも触ってみてください!
ただPDFの日本語の挙動が気になったので、そこは注意が必要です・・・テキストファイルとかに事前に変換して試すのが良いかもしれません。
本記事が少しでも参考になりましたら幸いです。最後までご覧いただきありがとうございました!








