
BigQuery の AI.AGG 関数で非構造化データを意味的に集約してみた
こんにちは!エノカワです。
BigQuery には、Vertex AI の Gemini モデルを SQL から呼び出せるマネージド AI 関数として、AI.GENERATE や AI.CLASSIFY、AI.SCORE、AI.IF といった関数が提供されています。
そのラインナップに、自然言語の指示で非構造化データを意味的に集約できる AI.AGG 関数がプレビュー追加されました。
You can now use the
AI.AGGfunction to semantically aggregate unstructured input data based on natural language instructions.
SUM や COUNT のように GROUP BY と組み合わせて使える集約関数でありながら、集約のロジックを自然言語で記述できる点が特徴です。
今回は、この AI.AGG 関数を実際に触ってみましたので、その内容をご紹介します。
AI.AGG 関数とは
AI.AGG は、Vertex AI の Gemini モデルを使って、非構造化データを自然言語の指示に基づいて集約するマネージド AI 関数です。
通常の集約関数(SUM、COUNT、STRING_AGG など)は数値や文字列を機械的にまとめるのに対し、AI.AGG は「レビュー全体の傾向を要約する」「ログから利用者の傾向をまとめる」といった意味のある集約を SQL の中で完結させることができます。
主なユースケース
公式ドキュメントでは、以下のようなユースケースが挙げられています。
- ユーザーレビューのセンチメント分析(肯定的・否定的な意見の整理)
- マルチモーダルデータのコンテンツ要約(画像群のカテゴリ要約など)
- AI エージェントのパフォーマンス分析
- ログ分析
構文
基本的な構文は以下のとおりです。
AI.AGG(
input_data,
instruction,
connection_id => 'CONNECTION',
endpoint => 'ENDPOINT'
)
主な引数は以下のとおりです。
| 引数 | 説明 |
|---|---|
input_data |
集約対象のカラム(テキスト、または画像などの非構造化データ) |
instruction |
自然言語の集約指示(プロンプト) |
connection_id |
Vertex AI と通信するための Cloud リソース接続。[PROJECT_ID.]LOCATION.CONNECTION_ID 形式 |
endpoint |
使用する Gemini モデル |
戻り値は STRING 型です。
GROUP BY と組み合わせた場合は、グループごとに1つの文字列が返ります。
制限事項
ドキュメントに記載されている主な制限事項は以下のとおりです。
- 1クエリあたり 2,000 万行以下、1,000 グループ以下が推奨
- 1行に画像が10枚以上含まれる場合、その行はスキップされる可能性がある
OBJ.GET_ACCESS_URLを呼ぶObjectRefRuntime配列を含む行はスキップされる可能性がある
また、執筆時点では Preview ステータスのため、本番利用は慎重に判断する必要があります。
環境準備
AI.AGG 関数を利用するために、Cloud リソース接続を作成し、サービスアカウントに Vertex AI を呼び出す権限を付与します。
Cloud リソース接続の作成
Google Cloud コンソールの BigQuery 画面から、エクスプローラの [接続] を開き、右上の [接続を作成] をクリックします。
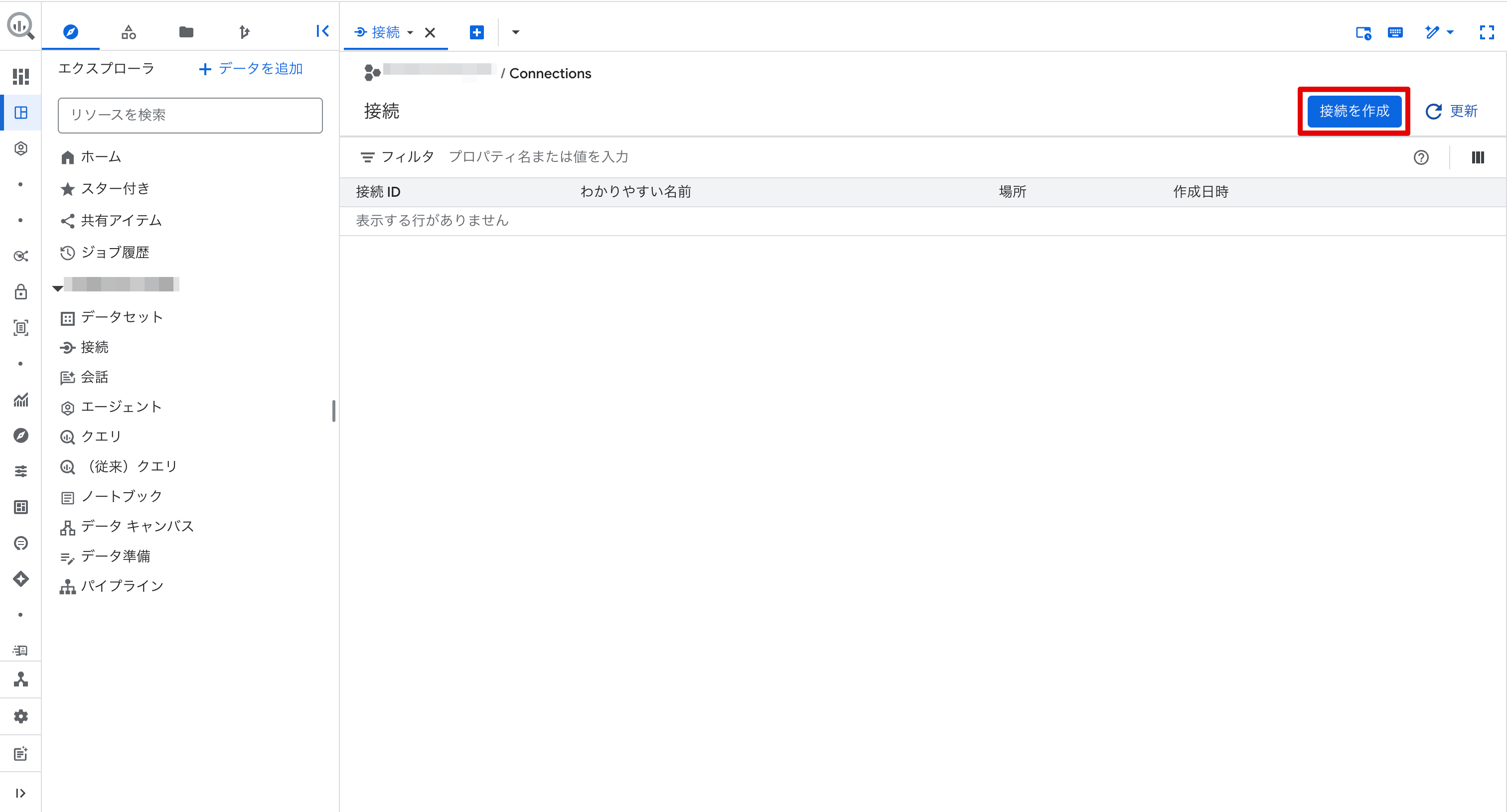
「外部データソース」のパネルが開くので、以下のように設定します。
| 項目 | 値 |
|---|---|
| 接続タイプ | Vertex AI リモートモデル、リモート関数、Lakehouse、Spanner(Cloud リソース) |
| 接続 ID | ai-agg-connection(任意) |
| ロケーション タイプ | マルチリージョン |
| マルチリージョン | US |
BigQuery では、クエリが参照するテーブルと接続のロケーションを一致させる必要があります。
今回サンプルとして使う bigquery-public-data.imdb.reviews は US マルチリージョンに配置されているため、接続も US で作成します。
接続が作成されると、画面下部に通知が表示されます。
[接続に移動] をクリックして、接続詳細画面を開きます。
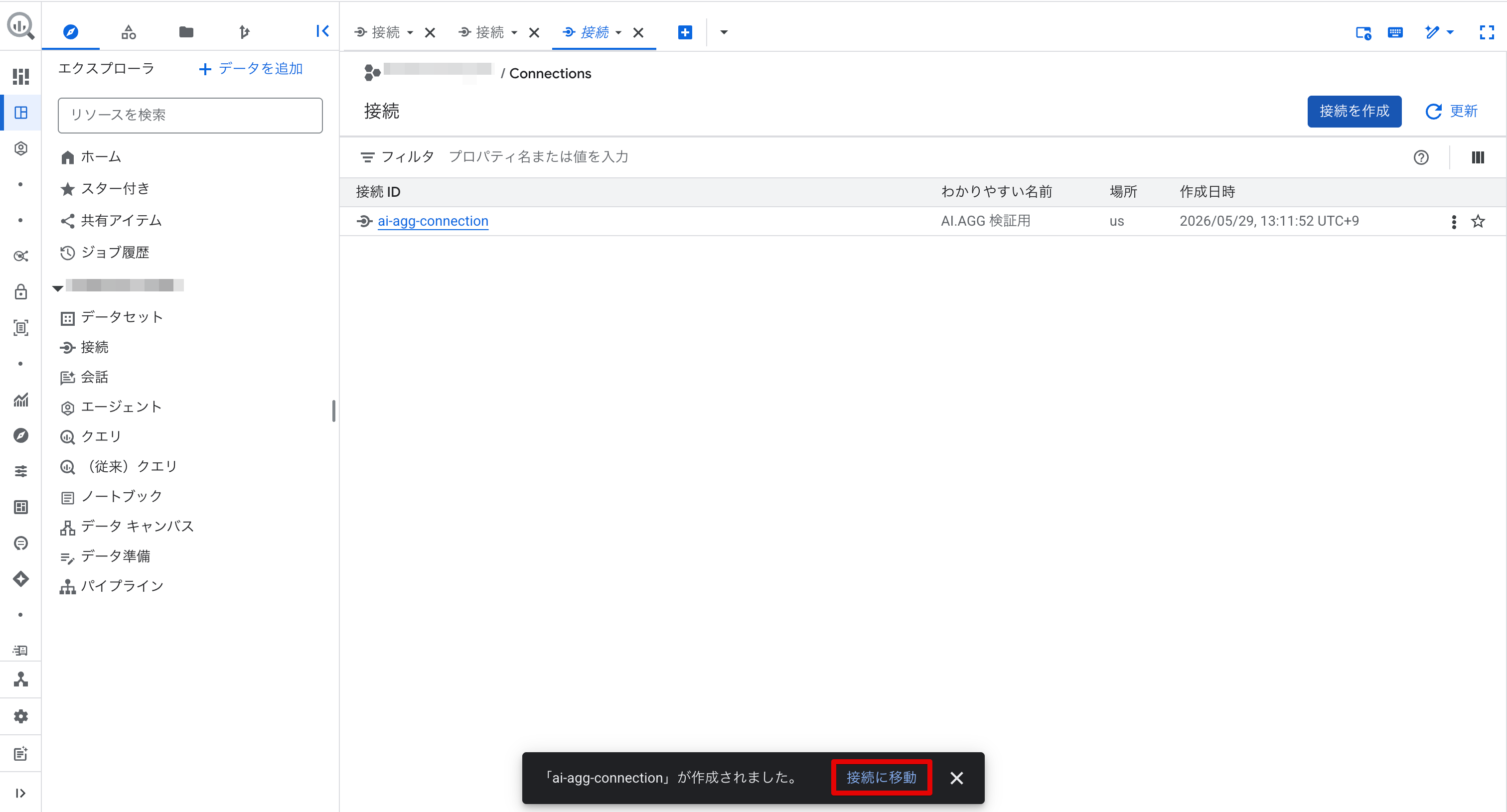
接続詳細画面の サービスアカウント ID をメモしておきます。
次の権限付与のステップで使います。
サービスアカウントへの権限付与
接続に紐づくサービスアカウントに、Vertex AI を呼び出す権限を付与します。
| ロール | 用途 |
|---|---|
roles/aiplatform.user |
Vertex AI モデルの呼び出し |
Google Cloud コンソールの [IAM と管理] → [IAM] から [アクセスを許可] をクリックします。
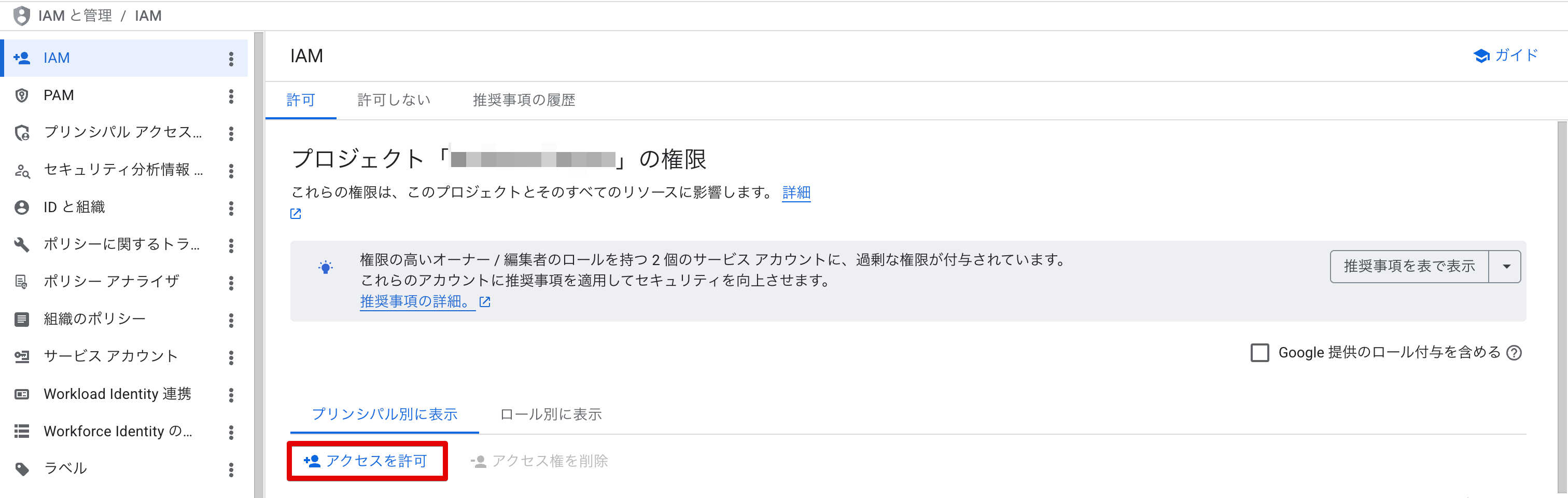
「アクセス権を付与します」のパネルが開くので、以下を設定して [保存] をクリックします。
- 新しいプリンシパル: 接続詳細画面で確認したサービスアカウント ID
- ロール:
roles/aiplatform.user
ちなみに、執筆時点のコンソール UI ではこのロールの表示名が 「Agent Platform ユーザー」 になっており、「Vertex AI ユーザー」で検索しても見つからない場合があります。
ロール ID の aiplatform.user で検索すると確実です。
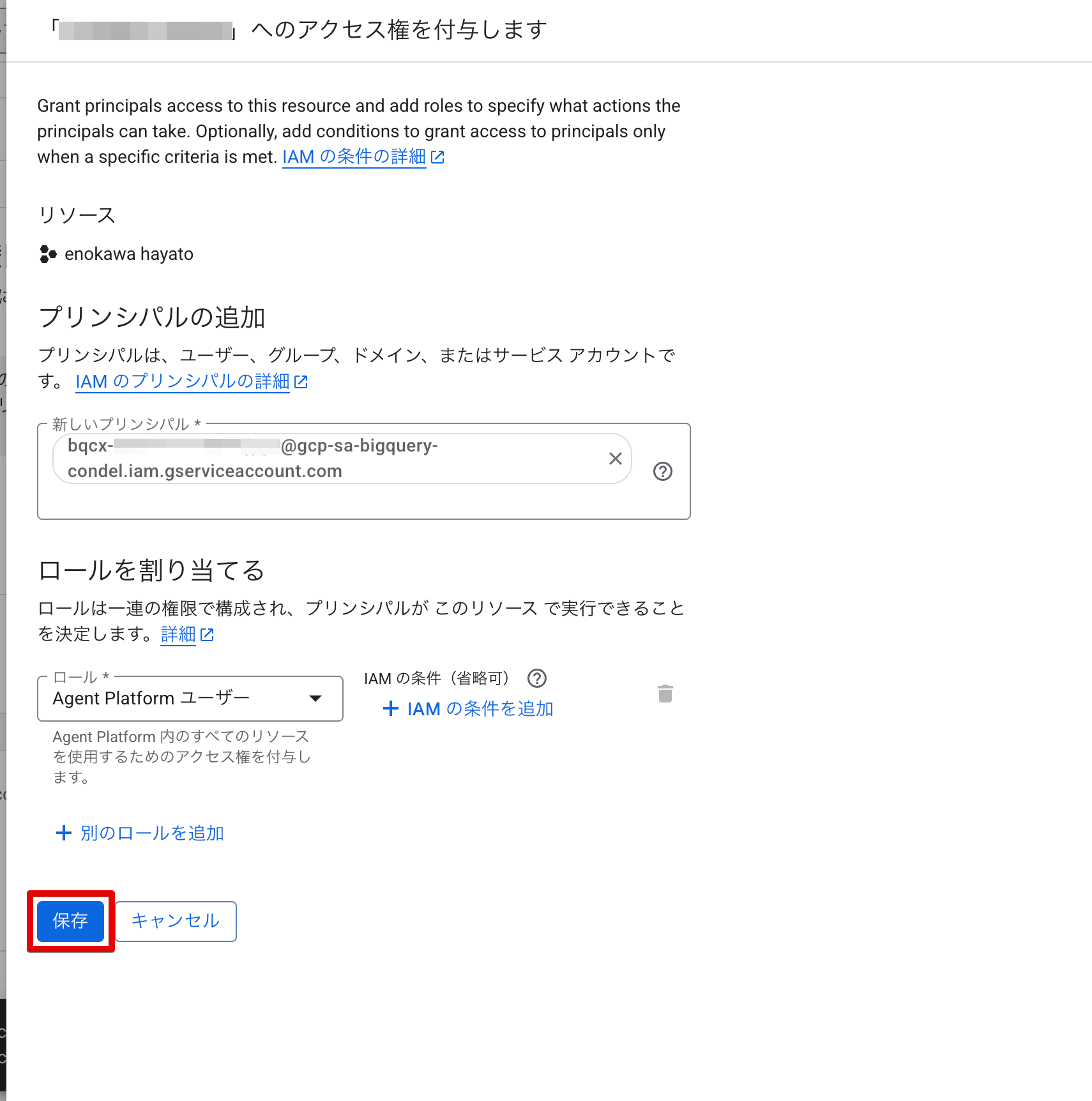
権限付与後、IAM 一覧でサービスアカウントに Agent Platform ユーザー ロールが付いていることを確認します。
なお、この権限が付与されていない状態で AI.AGG を実行すると、以下のエラーが返ってきました。
The user does not have the permission to access resources used by AI.AGG(). Please follow https://docs.cloud.google.com/bigquery/docs/permissions-for-ai-functions to set up permissions.
動作確認
サンプルデータとして、bigquery-public-data.imdb.reviews を使います。
このデータセットに含まれているスタジオジブリ作品3本を対象に、作品ごとに「観客に共通する感想」を AI.AGG で要約してみます。
対象とする映画は以下の3作品です。
movie_id |
作品名 |
|---|---|
tt0092067 |
天空の城ラピュタ |
tt0095327 |
火垂るの墓 |
tt0876563 |
崖の上のポニョ |
日本でもおなじみのジブリ作品ですが、bigquery-public-data.imdb.reviews には英語圏の観客によるレビューが格納されているので、英語レビューを AI.AGG で日本語要約してみるという流れになります。
データの確認
まずは対象データをのぞいてみます。
SELECT
movie_id,
title,
SUBSTR(review, 1, 200) AS review_excerpt
FROM
`bigquery-public-data.imdb.reviews`
WHERE
movie_id IN ('tt0092067', 'tt0095327', 'tt0876563')
LIMIT 5;
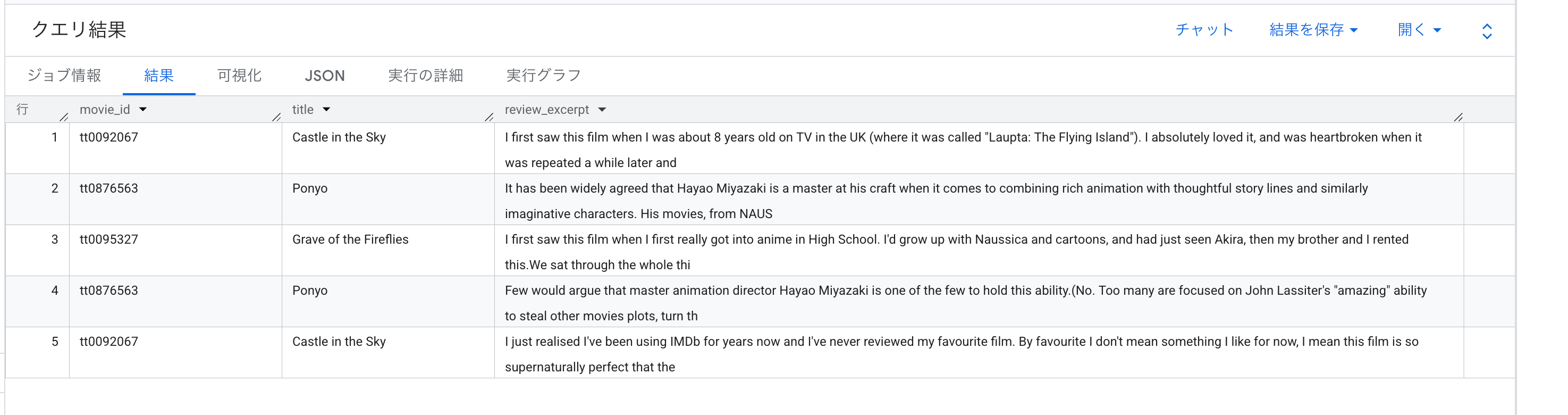
review カラムに英語のレビュー本文が、title カラムに作品名が格納されています。
ちなみに、bigquery-public-data.imdb.reviews は IMDb の英語レビューを集めたデータセットです。
なお、公式ドキュメントにも bigquery-public-data.imdb.reviews を使ったセンチメント分析のサンプルがあります。
今回は、対象作品を変えて、日本語で要約する形で試してみます。
AI.AGG で作品ごとにレビューを要約
3作品のレビューを AI.AGG で要約します。
SELECT
movie_id,
title,
AI.AGG(
review,
'これらの映画レビューに共通する観客の感想を、日本語で3〜5行に要約してください。',
connection_id => 'PROJECT_ID.us.ai-agg-connection',
endpoint => 'gemini-2.5-flash'
) AS review_summary
FROM
`bigquery-public-data.imdb.reviews`
WHERE
movie_id IN ('tt0092067', 'tt0095327', 'tt0876563')
GROUP BY
movie_id, title;
クエリのポイントは以下のとおりです。
WHERE movie_id IN (...)で対象作品を3本に絞り、データ量とコストを抑制GROUP BY movie_id, titleで作品ごとにグループ化し、AI.AGGでレビュー群を要約- プロンプトには出力形式(日本語で3〜5行)を明示
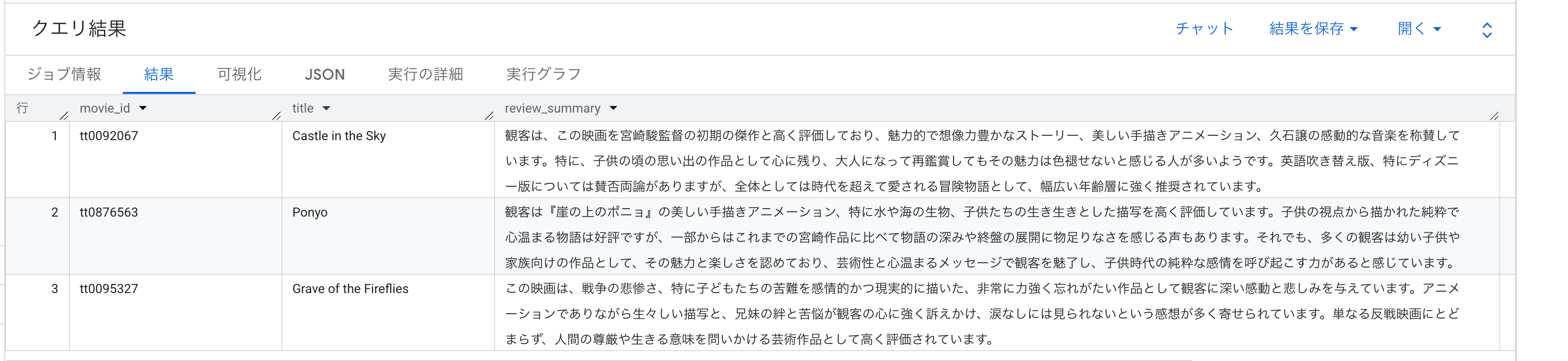
実際に返ってきた要約は以下のとおりです。
天空の城ラピュタ(tt0092067):
観客は、この映画を宮崎駿監督の初期の傑作と高く評価しており、魅力的で想像力豊かなストーリー、美しい手描きアニメーション、久石譲の感動的な音楽を称賛しています。特に、子供の頃の思い出の作品として心に残り、大人になって再鑑賞してもその魅力は色褪せないと感じる人が多いようです。英語吹き替え版、特にディズニー版については賛否両論がありますが、全体としては時代を超えて愛される冒険物語として、幅広い年齢層に強く推奨されています。
崖の上のポニョ(tt0876563):
観客は『崖の上のポニョ』の美しい手描きアニメーション、特に水や海の生物、子供たちの生き生きとした描写を高く評価しています。子供の視点から描かれた純粋で心温まる物語は好評ですが、一部からはこれまでの宮崎作品に比べて物語の深みや終盤の展開に物足りなさを感じる声もあります。それでも、多くの観客は幼い子供や家族向けの作品として、その魅力と楽しさを認めており、芸術性と心温まるメッセージで観客を魅了し、子供時代の純粋な感情を呼び起こす力があると感じています。
火垂るの墓(tt0095327):
この映画は、戦争の悲惨さ、特に子どもたちの苦難を感情的かつ現実的に描いた、非常に力強く忘れがたい作品として観客に深い感動と悲しみを与えています。アニメーションでありながら生々しい描写と、兄妹の絆と苦悩が観客の心に強く訴えかけ、涙なしには見られないという感想が多く寄せられています。単なる反戦映画にとどまらず、人間の尊厳や生きる意味を問いかける芸術作品として高く評価されています。
3作品とも、各レビュアーが個別に語っていた内容が、作品の特徴をうまく捉えた1つの要約にまとまっていますね。
特に作品ごとにトーンが大きく異なる点が興味深く、『天空の城ラピュタ』は冒険物語としての称賛、『崖の上のポニョ』は子供向け作品としての評価と物語の深みへの賛否、『火垂るの墓』は反戦と人間ドラマとしての重みが、それぞれの観点で要約されています。
英語吹き替え版への言及など、英語圏の観客ならではの視点も含まれているのが面白いところです。
プロンプトを変えて切り口を変える
AI.AGG の良さは、同じデータに対してプロンプトを変えるだけで集約の切り口を変えられるところです。
試しに、「この映画の魅力」という切り口で要約してみます。
最初は「これらのレビューから、この映画の魅力を3つ、日本語で箇条書きにまとめてください。」というシンプルなプロンプトで試したところ、以下のように作品ごとにフォーマットがバラついていました。
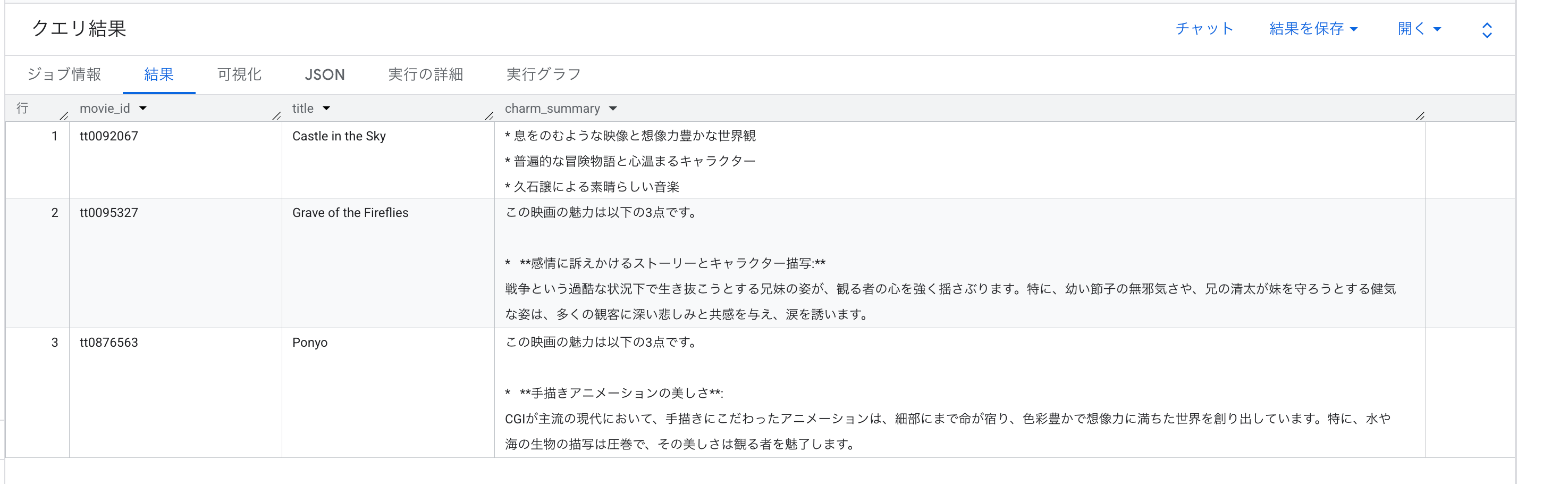
天空の城ラピュタ:
- 息をのむような映像と想像力豊かな世界観
- 普遍的な冒険物語と心温まるキャラクター
- 久石譲による素晴らしい音楽
崖の上のポニョ:
この映画の魅力は以下の3点です。
- 手描きアニメーションの美しさ: CGIが主流の現代において、手描きにこだわったアニメーションは、細部にまで命が宿り、色彩豊かで想像力に満ちた世界を創り出しています。…(以下略)
- 純粋な友情と愛の物語: 5歳の少年宗介と、人間になりたいと願う魚の子ポニョの間に育まれる純粋な友情と愛が、観る者の心を温かくします。…(以下略)
- 環境問題への示唆と普遍的なメッセージ: 海の汚染や自然との共存といった環境問題が背景にありながらも、説教臭くなく、子供にも理解しやすい形で提示されています。…(以下略)
火垂るの墓:
この映画の魅力は以下の3点です。
- 感情に訴えかけるストーリーとキャラクター描写: 戦争という過酷な状況下で生き抜こうとする兄妹の姿が、観る者の心を強く揺さぶります。…(以下略)
- 戦争の悲惨さをリアルに描く: 戦争の直接的な暴力だけでなく、食料不足や人々の心の荒廃など、戦争が一般市民にもたらす影響を、子供たちの視点を通して生々しく描写しています。…(以下略)
- アニメーション表現の可能性: アニメーションという手法を用いることで、実写では表現しにくい感情の機微や、火垂るの光のような幻想的な美しさを描き出しています。…(以下略)
天空の城ラピュタは短い箇条書きだけが返ってきた一方で、他2作品では前置き文と太字付きの詳細説明が付いており、同じプロンプト・同じクエリでも作品ごとに出力形式が揃わない結果になりました。
そこで、前置きや説明文を含めず、各項目は短いタイトルだけにするよう指示することで、出力を揃えるようにします。
SELECT
movie_id,
title,
AI.AGG(
review,
'これらのレビューから、この映画の魅力を日本語で3つ、箇条書きで簡潔にまとめてください。各項目は20文字以内のタイトルのみで、前置きや説明文は含めないでください。',
connection_id => 'PROJECT_ID.us.ai-agg-connection',
endpoint => 'gemini-2.5-flash'
) AS charm_summary
FROM
`bigquery-public-data.imdb.reviews`
WHERE
movie_id IN ('tt0092067', 'tt0095327', 'tt0876563')
GROUP BY
movie_id, title;
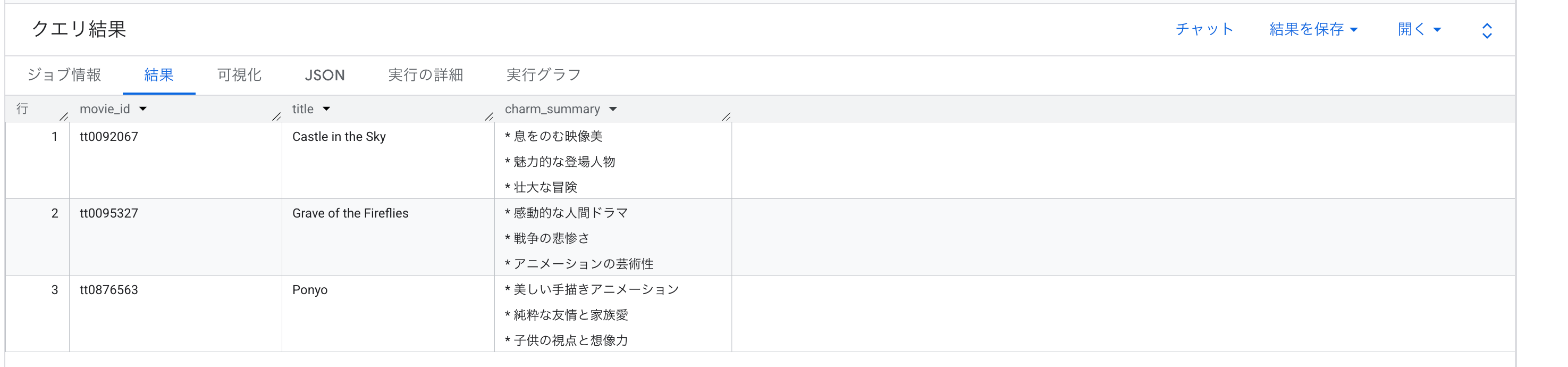
こちらも、返ってきた要約を引用しておきます。
天空の城ラピュタ(tt0092067):
- 息をのむ映像美
- 魅力的な登場人物
- 壮大な冒険
崖の上のポニョ(tt0876563):
- 美しい手描きアニメーション
- 純粋な友情と家族愛
- 子供の視点と想像力
火垂るの墓(tt0095327):
- 感動的な人間ドラマ
- 戦争の悲惨さ
- アニメーションの芸術性
SQL の構造はそのままに、プロンプトの変更だけで観点を切り替えられるのは便利ですね。
3作品とも、最初の「観客の感想」プロンプトでは数行の文章だったのが、今回は3つの短いキーワードに集約されていて、同じデータに対する切り口とアウトプットの粒度が大きく変わっているのが分かります。
注意点
実際に試してみて感じた注意点をいくつかまとめます。
コストとデータ量
AI.AGG は内部的に Vertex AI の Gemini モデルを呼び出すため、通常の BigQuery クエリの料金に加えて Vertex AI の利用料金が発生します。
データ量が多いほど呼び出し回数も増えるため、検証時は LIMIT や WHERE で対象を絞ってから試すのが安心です。
ドキュメントでも、1クエリあたり 2,000 万行以下、1,000 グループ以下が推奨されています。
Preview ステータス
執筆時点で AI.AGG は Preview ステータスです。
仕様変更や一時的な提供停止の可能性もあるため、本番ワークロードへの組み込みは GA を待つのが無難です。
実際、2026年4月13日にサポートが一時無効化されたあと、5月20日に再有効化されたとリリースノートに記載があります。
画像など他の入力にも対応
今回はテキストデータを対象としましたが、AI.AGG は画像など他の非構造化データも入力にできます。
Object Table と OBJ.GET_ACCESS_URL を組み合わせることで、画像群をまとめてカテゴリ要約するといった使い方もできるので、機会があれば触ってみようと思います。
まとめ
以上、BigQuery の AI.AGG 関数を使って、IMDb のスタジオジブリ作品のレビューを作品ごとに要約してみました。
AI.AGGはGROUP BYと組み合わせて使える、意味的な集約のためのマネージド AI 関数- 自然言語のプロンプトで集約のロジックを記述でき、SQL の中で完結する
- プロンプトを切り替えるだけで、同じデータに対して異なる観点の要約が得られる
- Preview ステータスのため、本番利用は GA を待ちつつ、まずは検証から始めるのが良い
ちなみに、AI.AGG 以外のマネージド AI 関数(AI.IF、AI.CLASSIFY、AI.SCORE など)も同様に SQL から呼び出せるので、組み合わせると非構造化データに対する処理の幅がぐっと広がります。
非構造化データの集約処理を SQL で完結させたいという方は、ぜひ皆様の業務でも活用してみてはいかがでしょうか?









