
BigQuery の AI 関数を自分なりに整理してみた
こんにちは!エノカワです。
BigQuery には、Gemini モデルなどを SQL から直接呼び出せるマネージド AI 関数が次々と追加されています。
2026 年に入ってから AI.GENERATE、AI.CLASSIFY、AI.SIMILARITY、AI.FORECAST など多くの関数が GA となり、ラインナップがかなり充実してきました。
一方で、関数の数が増えたことで「どの関数が何をするものなのか」「どんなときに使えばよいのか」が把握しづらくなってきたと感じています。
そこで今回は、現在提供されている BigQuery の AI 関数を自分なりにカテゴリ分けして整理し、各カテゴリから 1 つずつ実際に試してみました。
一覧で整理するだけでなく、実際に公開データセットで動かした結果もあわせてご紹介します。
なお、個別の関数としては AI.AGG 関数を以前ご紹介しています。
こちらもあわせてご覧ください。
AI 関数とは
BigQuery の AI 関数は、Gemini モデルや埋め込みモデルなどを SQL から呼び出せる関数群です。
テキストの生成・分類・要約や、ベクトルによる類似度計算、時系列予測といった処理を、SQL の中に書くだけで実行できます。
旧来の ML 関数との違い
以前から BigQuery には ML.GENERATE_TEXT のような生成系の関数がありました。
これらは利用前に CREATE MODEL でリモートモデルを作成しておく必要がありました。
これに対して、今回ご紹介する AI.* 関数の多くは、モデルの事前作成が不要で、SQL に関数を書くだけで利用できます。
よりシンプルに使えるようになっている点が、旧来の関数との大きな違いです。
ちなみに、旧来の ML.GENERATE_TEXT を使った日本語のテキスト生成・感情分析については、過去に検証記事があります。
AI 関数の一覧と分類
現在提供されている主な AI 関数を、用途別に 4 つのカテゴリに分けて整理してみました。
あわせて、どのカテゴリにも当てはまらない補助的な関数も最後に紹介します。
生成・抽出
プロンプトをもとに、テキストや構造化データを生成・抽出する関数です。
| 関数 | 概要 | ステータス |
|---|---|---|
AI.GENERATE |
プロンプトから自由形式のテキストや構造化データを生成する | GA |
AI.GENERATE_BOOL |
True / False を生成する(判定向け) | Preview |
AI.GENERATE_INT |
整数を抽出・生成する | Preview |
AI.GENERATE_DOUBLE |
小数(FLOAT64)を抽出・生成する | Preview |
AI.GENERATE_TABLE |
1 つのプロンプトから構造化テーブルを生成する(リモートモデルの事前作成が必要) | GA |
AI.GENERATE_TEXT |
テーブルのテキスト・非構造化データに対して生成タスクを実行する(テーブル値関数、リモートモデルの事前作成が必要) | GA |
判定・分類・スコア
データを振り分けたり、点数を付けたりする関数です。
| 関数 | 概要 | ステータス |
|---|---|---|
AI.IF |
「〜なデータか?」を自然言語で尋ね、True / False で絞り込む(WHERE 句などで利用) | GA |
AI.CLASSIFY |
テキストを、あらかじめ指定したカテゴリのいずれかに振り分ける | GA |
AI.SCORE |
「1〜10 で評価して」のように尋ねて点数を付ける(ORDER BY などで利用) | GA |
埋め込み・類似
テキストなどをベクトル化し、意味的な近さを扱う関数です。
| 関数 | 概要 | ステータス |
|---|---|---|
AI.EMBED |
テキスト・画像などを埋め込みベクトルに変換する | GA |
AI.GENERATE_EMBEDDING |
埋め込みベクトルを生成する(リモートモデルの事前作成が必要) | GA |
AI.SIMILARITY |
2 つの入力の意味的な類似度を計算する | GA |
AI.SEARCH |
埋め込みを自動生成したテーブルに対してセマンティック検索を行う | GA |
集計・分析・予測
データ分析を自動化する関数です。
| 関数 | 概要 | ステータス |
|---|---|---|
AI.AGG |
複数行をまとめて「全体を要約して」のように集約する | Preview |
AI.FORECAST |
時系列データから将来の値を予測する | GA |
AI.KEY_DRIVERS |
売上などの増減が「どのセグメントによるものか」を自動で特定する | Preview |
AI.DETECT_ANOMALIES |
時系列データから異常な値を検知する | GA |
AI.EVALUATE |
生成結果やモデルの精度を評価する | GA |
その他(ユーティリティ)
上記 4 カテゴリには当てはまらない、補助的な関数です。
| 関数 | 概要 | ステータス |
|---|---|---|
AI.COUNT_TOKENS |
プロンプトのトークン数を推定する(コスト見積りなどに利用) | Preview |
実際に試してみる
ここからは、4 つのカテゴリから 1 つずつ関数をピックアップして、実際に動かしてみます。
各カテゴリの代表的な関数として、AI.GENERATE・AI.CLASSIFY・AI.SIMILARITY・AI.FORECAST を選びました。
データは BigQuery の一般公開データセットを使用します。
なお、今回試す 4 関数は、いずれも接続(connection)の作成などの事前準備をすることなく、SQL を実行するだけで動かすことができました。
生成・抽出:AI.GENERATE
まずは生成・抽出カテゴリから AI.GENERATE を試します。
今回使用する bigquery-public-data.bbc_news.fulltext は、BBC のニュース記事のタイトル(title)・本文(body)・カテゴリ(category)が格納された一般公開データセットです。
イメージをつかむため、まず数件だけ中身を見てみます。
SELECT title, category, body
FROM `bigquery-public-data.bbc_news.fulltext`
LIMIT 3;
実行結果は以下のとおりです。
body は本文全体が格納されており長いため、ここでは先頭部分のみを抜粋して掲載します。
| title | category | body(先頭部分を抜粋) |
|---|---|---|
| News Corp eyes video games market | business | News Corp, the media company controlled by Australian billionaire Rupert Murdoch, is eyeing a move into the video games market... |
| Millions 'to lose textile jobs' | business | Millions of the world's poorest textile trade workers will lose their jobs under new trade rules to be introduced in the new year, a charity has warned... |
| Share boost for feud-hit Reliance | business | The board of Indian conglomerate Reliance has agreed a share buy-back, to counter the effects of a power struggle in the controlling family... |
このように、記事ごとにタイトル・本文・カテゴリが格納されています。
ここからは、tech カテゴリの記事本文を対象に、登場する固有名詞・主なトピック・感情・1 文要約を AI.GENERATE でまとめて抽出してみます。
output_schema で出力したいフィールドの名前と型を指定すると、1 回の呼び出しで複数の項目を構造化して取得できます。
SELECT
title,
AI.GENERATE(
body,
output_schema => "key_entities ARRAY<STRING>, main_topics ARRAY<STRING>, sentiment STRING, summary_one_sentence STRING"
).* EXCEPT (full_response, status)
FROM `bigquery-public-data.bbc_news.fulltext`
WHERE category = 'tech'
LIMIT 3;
実行結果は以下のとおりです。
key_entities と main_topics は配列で横に長くなるため、ここでは title / sentiment / summary_one_sentence を抜粋して掲載します。
| title | sentiment | summary_one_sentence |
|---|---|---|
| Security warning over 'FBI virus' | negative | The FBI is warning the public about a computer virus being spread via fraudulent emails disguised as official FBI communications, which instruct recipients to open a malicious attachment. |
| DVD copy protection strengthened | neutral | Macrovision has developed new RipGuard technology to combat DVD piracy by thwarting most ripping programs, aiming to reduce illegal copying and support legitimate online transactions. |
| Google's toolbar sparks concern | negative | Google's new AutoLink trial feature, which automatically links content on web pages to pre-selected commercial sites like Amazon, is raising concerns among net users and critics about competitive fairness and publisher control. |
key_entities と main_topics についても、たとえば 1 件目の「Security warning over 'FBI virus'」では以下のように抽出されました。
key_entities: FBI, computer virus, e-mails, Internet Fraud Complaint Center, phishing scammain_topics: Cybersecurity warning, Email scam, Malware distribution, FBI impersonation
固有名詞の抽出・トピックの整理・感情の判定・要約を、1 回の AI.GENERATE 呼び出しでまとめて取得できました。
要約も記事の内容と大きくずれておらず、実用に足る結果だと感じました。
複数の処理を別々の関数に分けず、output_schema を指定するだけで一度に取得できる点は便利ですね。
判定・分類・スコア:AI.CLASSIFY
次に、判定・分類・スコアカテゴリから AI.CLASSIFY を試します。
同じ BBC ニュースデータの本文を、あらかじめ指定したカテゴリに分類してみます。
categories に分類したいラベルを配列で渡します。
ここでは GROUP BY と組み合わせて、AI.CLASSIFY が分類したカテゴリごとの記事件数を集計してみます。
SELECT
AI.CLASSIFY(
body,
categories => ['tech', 'sport', 'business', 'politics', 'entertainment']
) AS category,
COUNT(*) AS num_articles
FROM `bigquery-public-data.bbc_news.fulltext`
GROUP BY category;
実行結果は以下のとおりです。
| category | num_articles |
|---|---|
| business | 486 |
| politics | 486 |
| entertainment | 392 |
| sport | 516 |
| tech | 345 |
指定した 5 つのカテゴリに、それぞれ記事が分類されました。
元のカテゴリと突き合わせて精度を確認する
ここで 1 つ気になるのが、「AI.CLASSIFY の分類は実際に正しいのか」という点です。
件数の集計結果を眺めるだけでは、分類が妥当かどうかは判断できません。
幸い、今回のデータセットには元から category 列(記事が本来属するカテゴリ)が含まれています。
そこで、AI.CLASSIFY の分類結果と元の category 列を突き合わせて、どのくらい一致するかを確認してみます。
WITH classified AS (
SELECT
category AS actual_category,
AI.CLASSIFY(
body,
categories => ['tech', 'sport', 'business', 'politics', 'entertainment']
) AS predicted_category
FROM `bigquery-public-data.bbc_news.fulltext`
)
SELECT
COUNTIF(actual_category = predicted_category) AS matched,
COUNT(*) AS total,
ROUND(COUNTIF(actual_category = predicted_category) / COUNT(*) * 100, 1) AS accuracy_percent
FROM classified;
実行結果は以下のとおりです。
| matched | total | accuracy_percent |
|---|---|---|
| 2097 | 2225 | 94.2 |
全 2,225 件のうち 2,097 件が元のカテゴリと一致し、一致率は 94.2% でした。
集計結果の件数だけでは分類の妥当性を判断しづらいですが、このように元の正解データと突き合わせることで、分類精度を数値で確認できました。
AI.CLASSIFY は GROUP BY と組み合わせて集計に使えるだけでなく、既存のラベル付きデータがあれば精度の評価まで SQL だけで行える点が便利だと感じました。
埋め込み・類似:AI.SIMILARITY
埋め込み・類似カテゴリからは AI.SIMILARITY を試します。
AI.EMBED でベクトルそのものを出すと結果が分かりにくいため、ここでは類似度を直接計算してくれる AI.SIMILARITY を使います。
引き続き BBC ニュースデータを使い、「housing market downward trends(住宅市場の下落傾向)」という検索文に、意味的に近い記事を上位に表示してみます。
endpoint には、使用するテキスト埋め込みモデルを指定します。
ここで指定している text-embedding-005 は、テキストをベクトルに変換するための埋め込み専用モデルで、AI.GENERATE などで使う Gemini(生成モデル)とは別物です。
AI.SIMILARITY は、2 つの入力(検索文と記事本文)をそれぞれこのモデルでベクトル化し、その近さ(コサイン類似度)を計算しています。
SELECT
title,
AI.SIMILARITY(
"housing market downward trends",
body,
endpoint => "text-embedding-005"
) AS similarity_score
FROM `bigquery-public-data.bbc_news.fulltext`
ORDER BY similarity_score DESC
LIMIT 5;
実行結果は以下のとおりです。
| title | similarity_score |
|---|---|
| House prices suffer festive fall | 0.7326 |
| House prices drop as sales slow | 0.7296 |
| UK house prices dip in November | 0.7251 |
| No seasonal lift for house market | 0.7189 |
| Survey confirms property slowdown | 0.7142 |
検索文に含まれる「housing market」や「downward」といった単語が記事タイトルにそのまま含まれていなくても、住宅価格の下落に関する記事が上位に並びました。
キーワードの完全一致ではなく、意味的な近さで記事を取得できていることが分かります。
全文検索では拾いづらい、表現の異なる関連記事を探したいときに活用できそうだと感じました。
集計・分析・予測:AI.FORECAST
最後に、集計・分析・予測カテゴリから AI.FORECAST を試します。
この関数は時系列データを対象とするため、ここだけはここまでのニュースデータではなく、時系列の公開データを使用します。
サンフランシスコの自転車シェアの利用データ(bigquery-public-data.san_francisco_bikeshare.bikeshare_trips)を使い、時間帯ごとの利用件数を集計したうえで、将来の利用件数を予測してみます。
このデータセットには 1 回ごとの乗車記録が格納されているため、まず「時刻ごとの乗車件数」という時系列の形に集計します。
そのうえで、data_col に予測対象の値、timestamp_col に時刻の列を指定し、horizon で予測する期間(ここでは 24 時間先まで)を指定します。
SELECT *
FROM
AI.FORECAST(
(
SELECT
TIMESTAMP_TRUNC(start_date, HOUR) AS ts,
COUNT(*) AS num_trips
FROM `bigquery-public-data.san_francisco_bikeshare.bikeshare_trips`
GROUP BY ts
),
data_col => 'num_trips',
timestamp_col => 'ts',
horizon => 24,
confidence_level => 0.95
);
実行結果は以下のとおりです。
24 時間分が出力されますが、ここでは傾向が分かりやすいよう一部の時間帯を抜粋して掲載します。
forecast_value が予測値、prediction_interval_lower_bound / prediction_interval_upper_bound が予測区間(信頼度 95%)の下限・上限です。
| forecast_timestamp | forecast_value | prediction_interval_lower_bound | prediction_interval_upper_bound |
|---|---|---|---|
| 2018-05-01 03:00 UTC | 23.7 | -10.0 | 18.2 |
| 2018-05-01 08:00 UTC | 741.4 | 542.0 | 938.8 |
| 2018-05-01 12:00 UTC | 219.5 | 140.4 | 307.5 |
| 2018-05-01 17:00 UTC | 717.3 | 555.8 | 889.0 |
| 2018-05-01 23:00 UTC | 48.7 | 24.0 | 50.5 |
予測値(forecast_value)を見ると、早朝(3 時台)は少なく、通勤時間帯の 8 時台と 17 時台に大きく増えるという、自転車シェアの利用傾向に沿った予測になっていることが分かります。
予測結果は数値の表よりもグラフのほうが傾向を把握しやすいため、BigQuery Studio のクエリ結果の [可視化] 機能で折れ線グラフにしてみます。
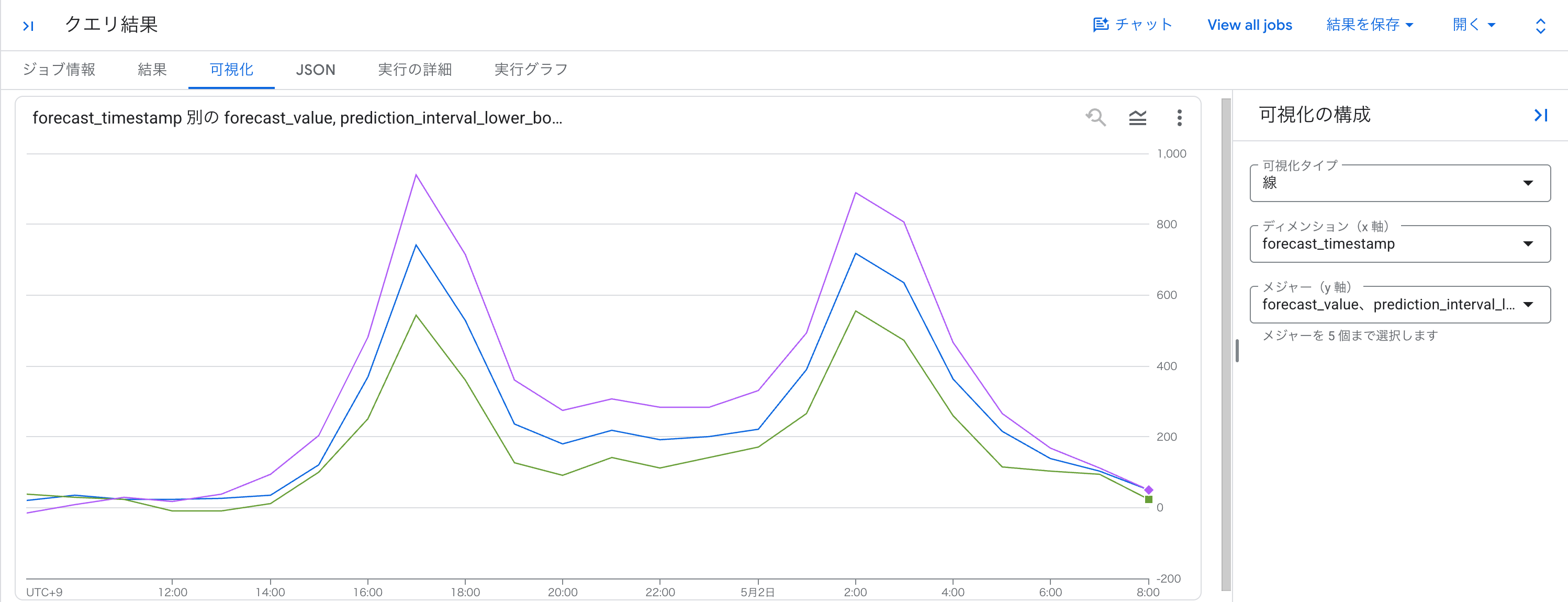
CREATE MODEL でモデルを作成することなく、SQL 関数を呼び出すだけで時系列予測ができました。
朝夕のピークといった時間帯ごとの傾向も捉えられており、手軽に予測の当たりを付けたいときに便利だと感じました。
なお、今回は予測の手軽さの確認にとどめましたが、直近の一定期間を学習対象から除外して予測し、除外した期間の実績と突き合わせれば、予測と実績を比較して精度を確認することもできます。
使い分けの指針
実際に試してみて、自分なりに整理した使い分けの指針を、カテゴリ単位でまとめると以下のようになります。
- テキストを生成・加工・抽出したいとき → 生成・抽出カテゴリ(
AI.GENERATEなど。要約・翻訳・抽出をまとめて実行できる) - データを振り分け・採点したいとき → 判定・分類・スコアカテゴリ(
AI.CLASSIFY/AI.IF/AI.SCORE。WHERE や GROUP BY、ORDER BY と組み合わせやすい) - 意味の近さで検索・比較したいとき → 埋め込み・類似カテゴリ(
AI.SIMILARITYなど。キーワード一致ではなく意味で探せる) - データ分析を自動化・予測したいとき → 集計・分析・予測カテゴリ(
AI.FORECASTなど。モデル作成なしで予測や要因分析ができる)
今回は各カテゴリから 1 つずつ試しましたが、同じカテゴリの関数は入力や出力の型が違うだけで、考え方は共通しています。
そのため、まず「やりたいことがどのカテゴリに当てはまるか」を考え、その中から目的に合う関数を選ぶ、という流れで使い分けると迷いにくいと感じました。
まとめ
以上、BigQuery の AI 関数を 4 つのカテゴリに整理し、各カテゴリから 1 つずつ実際に試してみました。
実際に動かしてみると、今回試した 4 関数はいずれも事前準備なく SQL を実行するだけで結果が得られ、想像していたよりも手軽に使えました。
今回触れなかった関数も多くありますので、機会があれば個別に試してみようと思います。
SQL だけで AI を活用できるようになってきていますので、ぜひ皆様の業務でも活用してみてはいかがでしょうか?
参考
- Introduction to AI in BigQuery | BigQuery
- Generative AI overview | BigQuery
- SQL reimagined for the AI era with BigQuery AI functions | Google Cloud Blog
- New BigQuery gen AI functions for better data analysis | Google Cloud Blog
- The AI.GENERATE function | BigQuery
- The AI.CLASSIFY function | BigQuery
- The AI.SIMILARITY function | BigQuery
- The AI.FORECAST function | BigQuery
- BigQuery public datasets | BigQuery
- BigQuery の AI.AGG 関数で非構造化データを意味的に集約してみた | DevelopersIO
- BigQueryからML.GENERATE_TEXT関数を使ってtext-bisonによる日本語のテキスト生成と感情分析をしてみる | DevelopersIO









